技术特征:
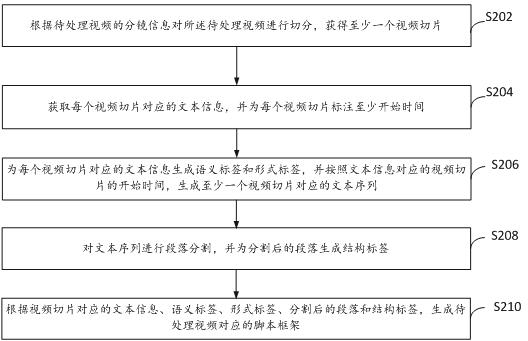
1.一种文本查重方法,其特征在于,包括:获取待查重文本;对所述待查重文本进行粒度分割生成第一待查文本数据和第二待查文本数据;根据所述第一待查文本数据在预设文本数据库中进行粗粒度检索得到第一文本集合,所述第一文本集合为具有与第一待查文本数据相似内容的多个第一对比文本构成的集合;在所述第一信息范围内,根据所述第二待查文本数据进行细粒度检索得到第二文本集合,所述第一文本集合为具有与第一待查文本数据相似内容的多个第二对比文本构成的集合,所述第二对比文本的数量少于所述第一对比文本的数量;根据所述第二文本集合和所述查重文本计算确定所述查重文本的查重结果。2.根据权利要求1所述的文本查重方法,其特征在于,所述对所述待查重文本进行粒度分割生成第一待查文本和第二待查文本,包括:将所述待查重文本转化为文本格式文件;根据预设分割规则提取第一待查文本,将所述待查重文本中的剩余内容记为第二待查文本;分别对所述第一待查文本和所述第二待查文本进行预处理得到所述第一待查文本数据和所述第二待查文本数据。3.根据权利要求2所述的文本查重方法,其特征在于,所述分别对所述第一待查文本和所述第二待查文本进行预处理得到所述第一待查文本数据和所述第二待查文本数据,包括:对所述第一待查文本进行分词得到对应的词汇文本;去除所述词汇文本中包含的停用词,得到目标文本;按所述目标文本的词汇序列将所述目标文本向量化,得到所述目标文本对应的数字向量,并将所述数字向量作为第一待查文本数据。4.根据权利要求1所述的文本查重方法,其特征在于,所述根据所述第一待查文本数据在预设文本数据库中进行粗粒度检索得到第一文本集合,包括:调用fnn数学模型,所述fnn数学模型为经过所述预设文本数据库为数据源训练后的数学模型,所述预设文本数据库包括所述预设文本数据库中每篇文本的特征向量信息;将所述第一待查文本数据作为所述fnn数学模型的输入信息,求解所述fnn数学模型得到第二数据信息,所述第二数据信息为所述第一待查文本数据进行特征提取后的信息;分别计算所述第二数据信息与所述预设文本数据库中每篇文本的第一距离值;在所述预设文本数据库中按照所述第一距离值由大到小的顺序提取第一预设数量篇文本,并作为第一文本集合。5.根据权利要求1所述的文本查重方法,其特征在于,所述在所述第一信息范围内,根据所述第二待查文本数据进行细粒度检索得到第二文本集合,包括:调用cnn数学模型,所述cnn数学模型为经过所述预设文本数据库为数据源训练后的数学模型;将所述第二待查文本数据和所述第一信息中每篇文本的特征向量信息作为所述cnn数学模型的输入信息,求解所述cnn数学模型得到第三数据信息,所述第三数据信息包括所述第二待查文本数据和所述第一信息中每篇文本在语义关系上的相识度;
在所述第三数据信息中按照所述相识度由大到小的顺序提取第二预设数量篇文本,并作为第二文本集合。6.一种文本查重装置,其特征在于,包括:获取单元,用于获取待查重文本;分割单元,用于对所述待查重文本进行粒度分割生成第一待查文本数据和第二待查文本数据;第一检索单元,用于根据所述第一待查文本数据在预设文本数据库中进行粗粒度检索得到第一文本集合,所述第一文本集合为具有与第一待查文本数据相似内容的多个第一对比文本构成的集合;第二检索单元,用于在所述第一信息范围内,根据所述第二待查文本数据进行细粒度检索得到第二文本集合,所述第一文本集合为具有与第一待查文本数据相似内容的多个第二对比文本构成的集合,所述第二对比文本的数量少于所述第一对比文本的数量;查重单元,用于根据所述第二文本集合和所述查重文本计算确定所述查重文本的查重结果。7.根据权利要求6所述的文本查重装置,其特征在于,所述分割单元包括:格式转化单元,用于将所述待查重文本转化为文本格式文件;划分单元,用于根据预设分割规则提取第一待查文本,将所述待查重文本中的剩余内容记为第二待查文本;预处理单元,用于分别对所述第一待查文本和所述第二待查文本进行预处理得到所述第一待查文本数据和所述第二待查文本数据。8.根据权利要求7所述的文本查重装置,其特征在于,所述预处理包括:分词单元,用于对所述第一待查文本进行分词得到对应的词汇文本;剔除单元,用于去除所述词汇文本中包含的停用词,得到目标文本;向量单元,用于按所述目标文本的词汇序列将所述目标文本向量化,得到所述目标文本对应的数字向量,并将所述数字向量作为第一待查文本数据。9.根据权利要求6所述的文本查重装置,其特征在于,所述第一检索单元包括:第一调用单元,用于调用fnn数学模型,所述fnn数学模型为经过所述预设文本数据库为数据源训练后的数学模型,所述预设文本数据库包括所述预设文本数据库中每篇文本的特征向量信息;特征提取单元,用于将所述第一待查文本数据作为所述fnn数学模型的输入信息,求解所述fnn数学模型得到第二数据信息,所述第二数据信息为所述第一待查文本数据进行特征提取后的信息;第一计算单元,用于分别计算所述第二数据信息与所述预设文本数据库中每篇文本的第一距离值;第一提取单元,用于在所述预设文本数据库中按照所述第一距离值由大到小的顺序提取第一预设数量篇文本,并作为第一文本集合。10.根据权利要求6所述的文本查重装置,其特征在于,所述第二检索单元包括:第二调用单元,用于调用cnn数学模型,所述cnn数学模型为经过所述预设文本数据库为数据源训练后的数学模型;
语义关系单元,用于将所述第二待查文本数据和所述第一信息中每篇文本的特征向量信息作为所述cnn数学模型的输入信息,求解所述cnn数学模型得到第三数据信息,所述第三数据信息包括所述第二待查文本数据和所述第一信息中每篇文本在语义关系上的相识度;第二提取单元,用于在所述第三数据信息中按照所述相识度由大到小的顺序提取第二预设数量篇文本,并作为第二文本集合。
技术总结
本发明提供了一种文本查重方法及装置、设备及可读存储介质,涉及数据查重技术领域,包括获取待查重文本;对待查重文本进行粒度分割生成第一待查文本数据和第二待查文本数据;根据第一待查文本数据在预设文本数据库中进行粗粒度检索得到第一文本集合;在第一信息范围内,根据第二待查文本数据进行细粒度检索得到第二文本集合,第二对比文本的数量少于第一对比文本的数量;根据第二文本集合和查重文本计算确定查重文本的查重结果,利用项目申报中部分特点在数据中进行粗粒度检索高效率地扩大搜索广度,然后进一步地通过细粒度检索缩小需要详细对比检索与分析的范围,最终通过在“少量”的对比文本中进行精细的对比,完成整个文本查重工作。本查重工作。本查重工作。
技术研发人员:王东晋 翟夏普 杨苗苗 安源 罗逸文 高浩翔 周欣燕 尉永哲 王洪岩 舒阳 常雪娇
受保护的技术使用者:中国铁道科学研究院集团有限公司科学技术信息研究所
技术研发日:2021.10.18
技术公布日:2021/11/14
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。