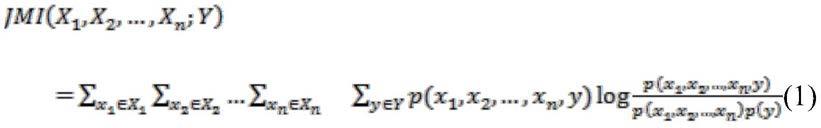
1.本发明属于数据挖掘技术领域,涉及一种基于联合互信息和条件熵的视图构建方法。
背景技术:
2.随着信息社会的快速发展,各个领域的数据规模也在快速增长,如何在这些海量的数据中找到我们需要的信息就显得尤为重要。数据挖掘技术是我们最常使用的方法之一,但是实际数据中往往存在缺失值的情况。如果直接使用这些不完整的数据进行分类/预测,就会影响到分类/预测结果。因此有必要对这些不完整数据进行处理。
3.目前,对于不完整数据的分类方法主要有两种。第一种是直接忽略掉那些具有缺失值的样本,然后用处理完整数据的方法对剩下的样本进行处理。这样做虽然很简单,但是如果缺失值样本比例过高时,就会严重影响实际数据的分类效果。
4.第二种方法是使用统计模型或机器学习方法对缺失值进行填充,然后使用处理完整数据的方法对不完整数据进行处理。这种方法可能会引进新的数据误差,并且在填充的过程中会增加大量的时间和空间消耗。
技术实现要素:
5.本发明的目的是提供一种基于联合互信息和条件熵的视图构建方法,解决了现有技术中存在的对于不完整数据分类效果差的问题。
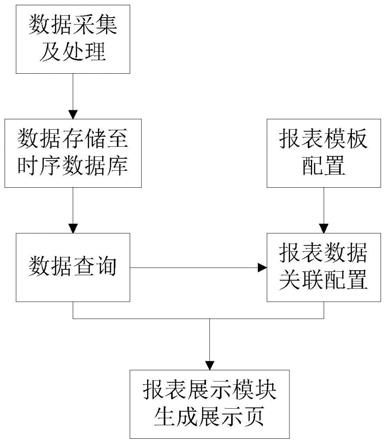
6.本发明所采用的技术方案是,一种基于联合互信息和条件熵的视图构建方法,具体按照以下步骤实施:
7.步骤1、对数据集d进行预处理,数据集d(f1,f2,...,f
k
,label),其中f1,f2,...,f
k
为k个特征,label为所属的类别;
8.步骤2、将经过预处理的数据集d划分为训练集d1和测试集d2;
9.步骤3、对训练集d1使用基于联合互信息和条件熵的视图构建方法来构建视图,用构建出的视图训练分类器得到训练模型;
10.步骤4、利用测试集对模型进行测试。
11.本发明的特点还在于:
12.步骤1具体为,若数据集不是缺失的,则采用完全随机缺失的准则将数据集d变为不完全数据集,若数据集d是缺失的则不变。
13.步骤3具体按照以下步骤实施:
14.步骤3.1、生成一个节点node,该节点包含的样本集合为a,若为根节点,则a等于d1;
15.步骤3.2、若a中的样本纯度小于设定的purity值或a中的样本数目小于设置的n值时,将node设置为叶子节点,并将该节点的类别设为a中出现次数最多的类别,否则进入步骤3.3;
16.步骤3.3、选出a中的特征集合c以及特征集合c对应的完整视图v;
17.步骤3.4、使用完整视图v来训练k近邻分类器,将a中的样本分为m种类别,每一种类别的样本集合为a
k
,k=1,2
…
m,对于每一个a
k
,返回步骤3.1,此时步骤3.1中的a为a
k
,循环步骤3.1~3.4,直到整棵分类树生成,进入步骤4。
18.步骤3.2中样本纯度的计算公式为:
[0019][0020]
其中,|y|为a中的类别数目,p
k
为第k个类别出现的概率。
[0021]
步骤3.3具体按照以下步骤实施:
[0022]
步骤3.3.1、对于样本集合为a的节点,先令特征集合c的完整视图v为空集,然后计算该节点的祖先节点未曾选过的特征相对于c的联合互信息jmi和相对于类别的条件熵ce;
[0023]
步骤3.3.2、将计算的每个特征的jmi和ce求和;
[0024]
步骤3.3.3、将特征的jmi和ce之和从小到大排序;
[0025]
步骤3.3.4、选出和最小的特征c
i
,将c
i
加入到c中;
[0026]
步骤3.3.5、重复3.3.1~3.3.4,直到c中的特征数目达到待选特征数目的一半时停止;
[0027]
步骤3.3.6、对于样本集合a中的每一个样本a
i
,若a
i
在特征集合c中是完整的,那么将a
i
添加到v中,将c和v返回即可。
[0028]
本发明的有益效果是:本发明一种基于联合互信息和条件熵的视图构建方法(jcvs)与基于对称不确定性的视图构建方法(suvs)相比,在使用相同分类器的情况下,分类精确率、回归率方面有所提升,在稳定性方面也有所提高;本发明的方法在选择视图对应的特征时,既考虑了待选特征对于分类效果的提升程度,又考虑了待选特征和整个已选特征集合的冗余关系;结果显示,在大部分数据集下,本发明提出的视图构建方法相比基于对称不确定性的视图构建方法而言,评估指标更优。
附图说明
[0029]
图1是本发明一种基于联合互信息和条件熵的视图构建方法的流程图;
[0030]
图2是本发明的方法和基于对称不确定性的视图构建方法在iris数据集上进行对比实验的精确率、回归率结果;
[0031]
图3是本发明的方法和基于对称不确定性的视图构建方法在ecoli数据集上进行对比实验的精确率、回归率结果;
[0032]
图4是本发明的方法和基于对称不确定性的视图构建方法在breastcancer数据集上进行对比实验的精确率、回归率结果;
[0033]
图5是本发明的方法和基于对称不确定性的视图构建方法在glass数据集上进行对比实验的精确率、回归率结果;
[0034]
图6是本发明的方法和基于对称不确定性的视图构建方法在horse colic数据集上进行对比实验的精确率、回归率结果;
[0035]
图7是本发明的方法和基于对称不确定性的视图构建方法在glass数据集上在不同缺失率下进行对比实验的精确率结果;
[0036]
图8是本发明的方法和基于对称不确定性的视图构建方法在glass数据集上在不同缺失率下进行对比实验的回归率结果;
[0037]
图9是本发明的方法和基于对称不确定性的视图构建方法在ecoli数据集上在不同缺失率下进行对比实验的精确率结果;
[0038]
图10是本发明的方法和基于对称不确定性的视图构建方法在ecoli数据集上在不同缺失率下进行对比实验的回归率结果。
具体实施方式
[0039]
下面结合附图和具体实施方式对本发明进行详细说明。
[0040]
本发明中的相关定义如下:
[0041]
定义1(联合互信息):联合互信息表示的是随机变量集合和某个变量的关系,值越小,则代表关系越小。联合互信息(joint mutual information)计算公式如下:
[0042][0043]
在这个式子中,x1,x2,...,x
n
中的每一个都是已选特征集合中的一个特征,而y是候选的某个特征,p(x1,x2,...,x
n
,y)是x1,x2,
…
,x
n
,y的联合概率,p(x1,x2,...,x
n
)是x1,x2,
…
,x
n
的联合概率,p(y)是y的概率。
[0044]
定义2(条件熵):条件熵指的是在已知一个变量的情况下,另一个变量的不确定性。在已知变量x的情况下,变量y的条件熵(condition entropy)h(y|x)定义为:
[0045]
p(x
i
,y
j
)指的是x
i
和y
j
的联合概率,p(y
j
|x
i
)指的是在已知x=x
i
的条件下y=y
j
的条件概率,m是变量y的取值数目,n是变量x的取值数目。
[0046]
定义3(不完整数据集):不完整数据集指的是那些具有缺失值的数据集。
[0047]
定义4(视图):视图是一组数据的逻辑表示,视图中的字段就是来自一组数据中的字段,其作用类似于筛选。从用户角度来看,一个视图是从一个特定的角度来查看一组数据中的数据。
[0048]
定义5(精确率):在二类或多类的数据集中,每次将一组类别的样本作为一类,将其他类别的样本作为另一类,计算精确率。精确率(precision)计算公式如下:
[0049][0050]
tp为预测为正例,实际上是正例的个数,fp为预测为正例,实际上是负例的个数。
[0051]
定义6(回归率):在二类或多类的数据集中,每次将一组类别的样本作为一类,将其他类别的样本作为另一类,计算回归率。回归率(recall)计算公式如下:
[0052][0053]
tp为预测为正例,实际上是正例的个数,fn为预测为负例,实际上是正例的个数。
[0054]
本发明一种基于联合互信息和条件熵的视图构建方法,如图1所示,具体按照以下
步骤实施:
[0055]
步骤1:给出一个数据集d(f1,f2,...,f
k
,label),其中f1,f2,...,f
k
为k个特征,label为所属的类别,假如d不是缺失的,那么我们采用完全随机缺失的准则把d变为缺失率为某个值的不完全数据集,假如d是缺失的则不变;
[0056]
步骤2:把不完整的数据集d分成10份,其中的9份作为训练集d1,另外1份作为测试集d2;
[0057]
步骤3:将训练集d1使用分类器进行训练,得到训练模型;具体步骤如下:
[0058]
步骤3.1:首先生成一个节点node,该节点包含的样本集合为a(如果是根节点,则a等于d1);
[0059]
步骤3.2:假如a中的样本纯度小于我们设定的purity值或者a中的样本数目小于我们设置的n值时,我们把node设置为叶子结点,并把该节点的类别设为a中出现次数最多的类别;否则转向步骤3.3;纯度公式为:
[0060][0061]
|y|为a中的类别数目,p
k
为第k个类别出现的概率;
[0062]
步骤3.3:接着我们要选出a中的特征集合c以及特征集合对应的完整视图v(过程见步骤:3.5~3.10);
[0063]
步骤3.4:选择完成后,使用v来训练k近邻分类器,该分类器会把a中的样本分为m种类别,每一种类别的样本集合为a
k
(其中k=1,2
…
m),对于每一个a
k
,返回步骤3.1,此时步骤3.1中的a就为a
k
。不断执行3.1~3.4,直到整棵树生成,转向步骤4;
[0064]
步骤3.5:对于样本集合为a的节点,我们先让已选特征集合c视图v为空集,然后计算该节点的祖先节点未曾选过的特征相对于c的联合互信息(jmi)和相对于类别的条件熵(ce);
[0065]
步骤3.6:把所计算的每个特征的jmi和ce相加;
[0066]
步骤3.7:把特征的jmi和ce之和从小到大排序;
[0067]
步骤3.8:选出和最小的特征c
i
,把c
i
加入到c中;
[0068]
步骤3.9:重复3.5~3.8,直到c中的特征数目达到待选特征数目的一半时停止;
[0069]
步骤3.10:对于样本集合a中的每一个样本a
i
,如果a
i
在已选特征集合c是完整的,那么把a
i
添加到v中,把c和v返回即可。
[0070]
步骤4:使用建立的分类器对测试数据进行测试,并使用精确率、回归率、稳定性作为评价标准对结果进行评估。
[0071]
本发明中视图构建伪代码如表1所示:
[0072]
表1视图构建算法伪代码
[0073][0074]
本发明的性能评价:
[0075]
为验证本发明中算法的有效性,使用该方法(jcvs)与基于对称不确定性的视图构建方法(suvs)进行比较。在6个数据集上分别使用这两个算法去训练分类器。通过对比实验,从图2、图3、图4可以看到,基于联合互信息和条件熵的视图构建方法在精确率、回归率
的性能要优于其他对比算法;从图6可以看到我们的方法在horsecolic数据集上的表现不如suvs;从图7—图10可以看出随着缺失率的增长,我们的方法在精确率、回归率的稳定性方面要好于对比方法。通过实验说明我们的算法是有效和稳定的。
[0076]
表2数据集信息
[0077]
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。