1.本发明属于一种基于特征分布对齐和样本均衡的域自适应跨库语音情感识别方法。
背景技术:
2.情感是人类智能的重要组成部分,赋予计算机识别情感的能力,是当前深度学习的前沿课题。目前,情感识别的研究主要集中在语言情感识别、面部表情识别和文本情感识别等。语音作为人类交流情感和思想的最便捷有效的方式之一,是情感识别领域研究的重点课题,当训练和测试数据同分布时,语音情感识别系统可以获得很高的精度,但在许多语音情感识别领域的实践中,这个假设往往不成立,ser(speech emotion recognition)系统在处理意外数据(即和训练集数据不同分布的测试集数据)时精度下降非常明显,设计出健壮的ser模型具有一定的挑战性,目前这一技术的局限也限制了语音情感识别在实际应用中的发展。
3.若要解决未标记语音数据的情感分类问题,则最有效的方法应是人工标注相当一部分语音数据后进行训练,然后使用训练好的模型对大批量的语音进行分类,但是语音情感数据标注困难,尤其是在上下文语境未知的情况下,因此,如何解决利用已有的有标签数据集来对无标签数据集进行分类成为了研究重点,如何克服两个数据集之间存在的差异性,例如,发音者的音质,发音环境以及语种的不同,对于这个问题,越来越多的研究者尝试引入迁移学习的概念,在特征分布的层面上将两个数据库的特征对齐以训练出高效的模型,目前已经取得了一定的成果,利用迁移学习完成跨库语音情感识别成为一个重要的研究方向。
4.迁移学习可以被用来改善机器学习模型在跨领域任务上的性能,当目标领域中无法获得大量带标签的数据用以训练具有良好性能的机器学习模型时,可以考虑在不同但相关的有大量带标签数据的源域进行模型的预训练,将预训练模型进行调整后应用于目标域,这克服了实际应用中目标域数据标签难以获取的困境。然而,跨域的数据分布差异成为了模型迁移的障碍。领域自适应(domain adaptation)旨在学习一个模型使得在源域学习到的知识能够在目标域很好的泛化,引入领域自适应技术可以减小源域目标域的数据分布差异,从而实现领域不变知识的跨域迁移和复用。
5.因此,本发明主要关注如何解决样本分布差异和样本不均衡问题,进一步提高跨库语音情感识别效果,目标域和源域存在数据分布差异,目标域的各个类别样本不均衡会让数据误分类问题更加严重,可以通过特征分布对齐和增强模糊样本判别能力来加强模型的学习能力,深度学习模型对输入进行分类后,往往会输出一个概率矩阵,分类器只会根据其属于各类的概率进行分类,然而,样本数多的类别会逐渐主导模型,因此选择一个参数来调节样本不平衡的问题至关重要,本发明在传统域自适应的基础上,使用了mmd距离来对齐源域和目标域的特征分布,同时选用了frobenius范数来调节模型的预测能力,既能保证模型对样本的判别性,又能保证模型预测样本的多样性,实现了更有效的领域自适应过程。
技术实现要素:
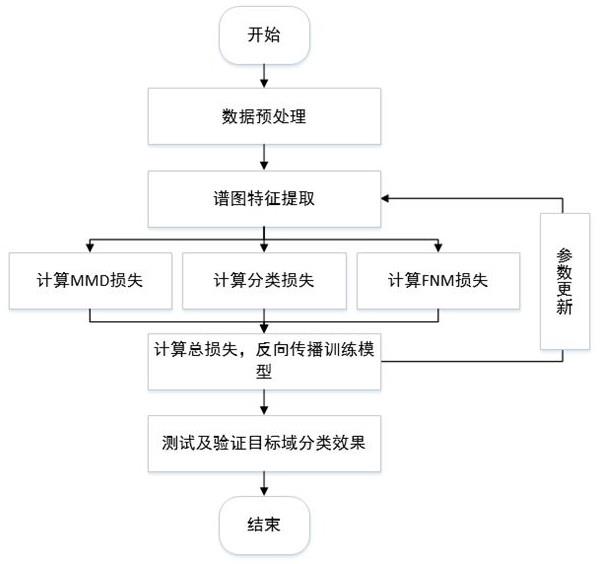
6.对于跨库语音情感识别,目前存在两大问题,第一,源域与目标域间的数据分布不同。第二,在目标域上的各个类别间样本不均衡。本方法针对问题一利用mmd距离对齐不同数据库的特征分布,针对问题二利用frobenius范数最大化来保证预测的多样性,具体步骤如下:
7.(1)语音预处理:对时域连续采样的语音信号进行分帧、加窗及短时离散傅里叶变换处理,提取语谱图,语谱图直观的反映了各个时刻语音频率成分的能量强弱,包含了丰富的语音情感信息;
8.(2)特征提取:步骤(1)提取到的语谱图是一维语音信号在二维时域和频域上的展开,利用alexnet在语谱图上提取深度特征;
9.(3)特征对齐:将步骤(2)中生成的特征矩阵输入mmd模块,此模块将源域和目标域特征映射到再生希尔伯特空间(reproducing kernel hilbert space,rkhs),寻找映射函数使得变换后的源域和目标域距离最小,源域目标域距离定义如下:
[0010][0011]
(4)样本均衡:步骤(2)中的特征矩阵在经过softmax处理后成为预测概率矩阵p
i,j
,对其进行双重frobenius范数最大化处理,首先,在使用熵最小化法来保证模型预测准确性的方法中,frobenius范数和熵h(x)具有严格相反的单调性,因此,frobenius范数最大化可以保证h(x)最小化,增加模型预测准确性,与此同时,为了弥补因熵最小化法带来的模糊样本误判,计算输出预测矩阵中的每一行与其下方所有行的差值,构造样本间距度量矩阵d,此时,最大化矩阵d的frobenius范数可以在保证模型预测精度的同时使得预测类别更丰富,保护了决策边界上的模糊样本,过程如下:
[0012][0013][0014][0015][0016]
其中,q为batchsize除以分类数j所得的商,r为batchsize除以分类数j所得的余数,d的维度为分类数j列乘以行;
[0017]
(5)模型训练:将步骤(1)得到的语谱图直接输入alexnet网络,将源域和目标域的特征进行mmd度量,得到特征分布差异损失l
mmd
,有标签的源域数据经过分类器后得到分类
损失l
cls
,将无标签的目标域数据经过特征提取网络后得到的预测矩阵转化为样本间距度量矩阵,对度量矩阵进行frobenius范数最大化操作,得到损失为l
fnm
,利用反向传播算法对模型进行训练,总损失如下:
[0018]
l
all
[0019]
=l
cls
l
mmd
l
fnm
ꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0020]
(6)重复步骤(2)(3)(4),优化网络模型参数;
[0021]
(7)经过一定轮次的迭代后,得到本方法指导下的最优模型,实现跨库语音情感识别性能的提升。
附图说明
[0022]
如附图所示,图1为本发明的实现流程图,图2为一种基于样本均衡和最大均值差异的跨库语音情感识别方法模型框架图。
具体实施方式
[0023]
下面结合具体实施方式对本发明做更进一步的说明。
[0024]
(1)特征提取,将语音建模为图像,采用图像特征描述语音情感相关的信息,语音的频谱图反映了语音信号的动态频谱过程,突破了传统谱相关特征的单一性,从谱的的频域和时域两方面综合考虑,用二维平面来表达三维的信息,提取到更多与情感有关的信息。对语音信号分帧加窗,然后计算各帧的短时傅里叶变换,得到频率能量二维矩阵,进而对矩阵进行处理,得到不同的谱图。
[0025]
(2)将步骤(1)得到的语谱图数据分好类后,输入预训练好的alexnet网络中,进行特征提取,alexnet网络包括五个卷积层与三个全连接层,由于谱图特征更多的体现在特征纹理而非背景信息,所以采用最大池化,避免平均池化的模糊化效果,并令步长比池化核尺寸小,从而在池化层输出间产生重叠,提升特征的丰富性,减少信息丢失。
[0026]
(3)将经过alexnet网络提取后的源域和目标域特征输入mmd模块,将两个特征矩阵映射到再生希尔伯特空间(reproducingkernelhilbertspace,rkhs),这样两个域的分布就可以用两个点的内积来表示,寻找映射函数,使得变换后的源域和目标域特征分布距离最小,计算源域与目标域间的特征分布距离,构造mmd损失l
mmd
,反向传播对特征提取网络进行训练,让网络提取出分布距离更小的源域目标域特征。
[0027]
(4)将alexnet网络提取到的源域特征进行softmax处理后进行分类,与源域标签进行对比得到分类损失l
cls
,目标域特征进行softmax处理后,得到一个batch的预测概率矩阵,结合熵最小化法,对预测概率矩阵p进行frobenius范数最大化处理,以使得矩阵p的熵值最小,从而保证模型的预测准确性,针对熵最小化法带来的模糊样本误判,使用输出的预测概率矩阵p构造样本间距度量矩阵d,如下:
[0028]
[0029][0030]
可以看出矩阵d能够有效的度量样本间间距,对矩阵d进行frobenius范数最大化操作,可以有效的增加预测样本的间距,因此在不影响分类性能的前提下,最大化frobenius范数可以对样本较少的类别起到一定的保护作用。构造frobenius范数最大化损失函数,可以保证预测多样性,避免模型的预测坍缩到仅有大样本的类别。
[0031]
(5)结合模型中的源域分类器损失l
cls
、特征分布差异损失l
mmd
和frobenius范数最大化损失l
fnm
,对模型进行反向传播训练,迭代优化网络参数,提高跨库语音情感识别性能。
[0032]
本发明请求保护的范围并不仅仅局限于本具体实施方式的描述。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。