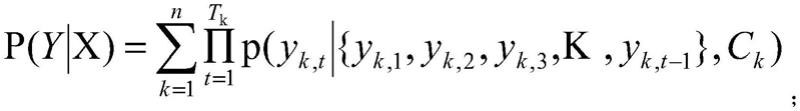
一种基于语境和transformer的多语言对话机器人系统及其对话方法
技术领域
1.本发明涉及智能语音技术领域,具体涉及一种基于语境和transformer的多语言对话机人系统及其对话方法。
背景技术:
2.智能问答(question answering,qa)是指利用计算机自动回答用户所提出的问题以满足用户知识需求的问答系统。不同于现有的搜索引擎,问答系统是信息服务的一种高级形式,系统返回用户的不再是基于关键词匹配排序的文档列表,而是精准的自然语言答案。近年来,随着人工智能的飞速发展,智能问答已经成为备受关注且发展前景广泛的研究方向。现代的问答系统是融合知识库、信息检索、机器学习、自然语言理解等技术的人机对话服务。智能问答系统在很多方面不同于传统的信息检索系统:
3.1)系统的输入、输出都是自然语言;
4.2)需要考虑用户对话的上下文,即语境;
5.3)在不能理解用户意图的情况下,会请求用户补充信息。目前智能问答系统存在数据难收集(尤其是小语种)、跨语言能力差、多轮问答任务场景难度大等问题。
6.得益于深度学习、自然语言处理和机器翻译的快速发展,智能问答系统迎来了新的机遇和挑战。目前的智能问答系统性能,与人工智能的其他领域还存在很大的差距。虽然人工智能技术得到了长足的发展,但目前智能问答系统还存在着不够稳定、不够智能、跨语言对话能力不足等缺点。
7.而人工翻译来辅助人工客服或智能客服完成跨语言对话,具有翻译成本高,回答质量受个人影响大,主观性强等弱点。
8.因此,现有技术存在缺陷,需要进一步改进。
技术实现要素:
9.针对现有技术存在的问题,本发明提供一种基于语境和transformer的多语言对话机人系统及其对话方法。
10.为实现上述目的,本发明的具体方案如下:
11.本发明提供一种基于语境和transformer的多语言对话机器人系统,包括:目标语种识别器模块、语音识别模块、语音情绪识别模块、语音多语言融合器模块以及语音合成模块;
12.所述目标语种识别器模块用朴素贝叶斯分类器对不同的语种进行识别;
13.所述语音识别模块是根据目标语种选择不同的语音识别引擎并得到识别后的文本问句;
14.所述语音情绪识别模块基于多模态语音情感分类算法对语音进行情绪识别;
15.所述语音多语言融合器模块是基于transformer的端到端神经网络机器翻译引擎
将不同语种的源语言文本翻译成不同语种的目标语言并结合语音情绪特征和多语言融合文本答案进行分类输出情绪化翻译结果;
16.所述语音合成模块将目标语言答案文本通过语音合成输出语音答案。
17.优选地,所述目标语种识别器模块用朴素贝叶斯分类器对不同的语种进行识别。
18.优选地,所述语音识别模块识别语音过程中将多语言融合文本经过bert文本语义特征编码器处理得到文本语义特征向量。
19.优选地,所述语音情绪识别模块对语音进行情绪识别具体是将音频文件经过mdre语音情感分类器处理得到音频情绪特征。
20.本发明还提供一种采用基于语境和transformer的多语言对话机器人系统的对话方法,包括如下步骤:
21.s1:目标语种识别器模块,将客户的声音信息或文本信息通过目标语种识别器识别出目标语种;
22.s2:语音识别模块,根据目标语种选择不同的语音识别引擎并得到识别后的文本问句;
23.s3:语音情绪识别模块,对语音进行情绪识别,输出音频情绪特征向量;
24.s4:语音多语言融合器模块,将步骤s2中语音识别的结果先通过基于transformer的基准语言翻译模块得到不同目标语言的答案文本并将多语言答案进行融合,最后融合步骤s3中得到音频情绪特征向量输出目标语言答案文本,即情绪化翻译结果;
25.s5:语音合成模块,将目标语言答案文本通过语音合成输出语音答案。
26.优选地,步骤s4具体包括:
27.s41,多语言融合文本经过文本语义特征编码器得到文本语义特征向量;
28.s42,对应音频文件经过语音情感分类器得到音频情绪特征向量;
29.s43,文本语义特征向量和音频情绪特征向量融合,得到融合后的特征;
30.s44,融合后的特征经过情绪化翻译器得到目标语言答案文本。
31.优选地,步骤s41具体包括:
32.s411,输入源语言通过通用表征器得到源语言句子的通用特征向量;
33.s412,源语言句子的通用特征向量通过transformer编码器得到编码器输出向量;
34.s413,输入目标语言token,判断目标语言(解码时根据目标语言token来选择不同的语种解码器来进行解码得到翻译结果);
35.s414,根据不同的目标语言,将编码器输出向量c送到对应的transformer解码器进行解码,得到目标译文;
36.具体算法如下:
[0037][0038]
其中,
[0039]
k(如1,2,3,
…
,n)表示语种编号,比如中文(k=1),英文(k=2),
[0040]
t(1,2,3,
…
,t
k
)表示目标语言的序列长度,
[0041]
y
k
为对应语种k的参考译文,
[0042]
c
k
为语种k对应的上下文向量。
[0043]
优选地,步骤s43具体算法如下:
[0044][0045]
其中,
[0046]
a,是音频情绪特征向量;
[0047]
t,是文本语义特征向量。
[0048]
优选地,步骤s44具体算法如下:
[0049]
c2=encodertransformer(concat(z,t));
[0050][0051]
其中,
[0052]
m为目标语言答案文本的序列长度,
[0053]
θ为模型参数,
[0054]
y
<t
表示y1,y2,
…
,y
t
‑1;
[0055]
c为编码器输出向量c(上下文特征)。
[0056]
采用本发明的技术方案,具有以下有益效果:
[0057]
本发明提供一种基于语境和transformer的多语言对话机器人系统及其对话方法,包括:目标语种识别器模块、语音识别模块、语音情绪识别模块、语音多语言融合器模块和语音合成模块;其中,目标语种识别器模块对不同的语种进行识别;语音识别模块是得到识别后的文本问句;语音情绪识别模块对语音进行情绪识别;语音多语言融合器模块将目标语言结合语音情绪特征和多语言融合文本答案输出情绪化翻译结果;语音合成模块将答案文本通过语音合成输出语音答案。本发明通过自动识别目标语种和语音情绪,进行语义多语言融合进行答案选择,并通过基于语境的答案翻译,能够智能回答多语言的问题,降低了采用人工客服的时间成本和资金成本,提高了对话机器人回答能力,从而支撑面向国际用户的对话机器人的应用研发。
附图说明
[0058]
图1是基于语境和transformer的跨语言对话机器人框图;
[0059]
图2是语音多语言融合器示意图;
[0060]
图3是基于transformer的基准语言翻译引擎;
[0061]
图4是基于transformer目标语言情绪化翻译模块。
具体实施方式
[0062]
以下结合附图和具体实施例,对本发明进一步说明。
[0063]
结合图1
‑
图4对本发明进行具体说明。
[0064]
本技术针对目前智能问答系统面临的对话数据难收集、不支持跨语言问答等痛
点,解决各种业务场景中的智能客服问题。随着人工智能技术和自然语言技术发展,特别是随着深度学习技术的发展,自然语言理解得到长足的方法,使用在保险专业场景这个垂直领域,机器智能客服已经显示了它众多的优点,如知识丰富、客观性强、回复快速和低成本等优点,但也同时存在稳定性不足,跨语言对话能力弱以及语料缺乏等不足。
[0065]
本发明能够将智能问答、语音情绪识别和机器翻译进行有机结合,能够克服智能问答系统现有的不足,同时能够最大限度的利用智能问答和机器翻译的优点。不但能够提升智能客服的稳定性,也能够利用机器翻译技术提高机器智能客服的跨语言对话能力。本发明通过自动识别目标语种和语音情绪,利用语音多语言融合器和自动化的基于语境的答案翻译,能够智能地回答跨语言的问题,降低了采用人工客服的时间成本和资金成本,提高了对话机器人回答能力,从而支撑面向国际用户的对话机器人的应用研发。
[0066]
本技术可以为客户提供售前、售后咨询,产品推荐以及常见知识问题等能力。能够同时达到高准确率、快速回答、高可靠性、以及跨语言交互等优点。
[0067]
如图1所示,本技术提出的基于语境和transformer的跨语言对话机器人系统包含五大模块,包括目标语种识别器模块、语音识别模块、语音情绪识别模块、语音多语言融合器模块以及语音合成模块。其中,
[0068]
目标语种识别器模块用的是朴素贝叶斯分类器对不同的语种进行识别;
[0069]
语音识别模块是根据目标语种选择不同的语音识别引擎并得到识别后的文本问句;
[0070]
语音情绪识别模块基于多模态语音情感分类算法对语音进行情绪识别;
[0071]
语音多语言融合器模块是基于transformer的端到端神经网络机器翻译引擎将不同语种的源语言文本翻译成不同语种的目标语言并结合语音情绪特征和多语言融合文本答案进行分类输出情绪化翻译结果;
[0072]
语音合成模块将目标语言答案文本通过语音合成输出语音答案。
[0073]
采用基于语境和transformer的跨语言对话机器人系统,进行对话的方法,步骤如下:
[0074]
s1:目标语种识别器模块,将客户的声音信息或文本信息通过目标语种识别器(朴素贝叶斯分类器)识别出目标语种;
[0075]
s2:语音识别模块,根据目标语种选择不同的语音识别引擎并得到识别后的文本问句;
[0076]
s3:语音情绪识别模块,对语音进行情绪识别,输出音频情绪特征向量;
[0077]
s4:语音多语言融合器模块,将步骤s2中语音识别的结果先通过基于transformer的基准语言翻译模块得到不同目标语言的答案文本并将多语言答案进行融合,最后融合步骤s3中得到音频情绪特征向量输出目标语言答案文本,即情绪化翻译结果;
[0078]
s5:语音合成模块,将目标语言答案文本通过语音合成输出语音答案。
[0079]
具体的,步骤4中基于transformer目标语言情绪化翻译模块,流程如图4所示:
[0080]
s41,多语言融合文本经过文本语义特征编码器(如bert)得到文本语义特征向量t;
[0081]
text_ans=concat(y1,y2,k,y
n
);
[0082]
t=bert(text_ans);
[0083]
s42,对应音频文件audio_vec经过语音情感分类器(如mdre)得到音频情绪特征向量a;
[0084]
a=mdre(audio_vec);
[0085]
s43,文本语义特征向量和音频情绪特征向量融合,得到融合后的特征;
[0086]
具体算法如下:
[0087][0088]
其中,
[0089]
a,是音频情绪特征向量;
[0090]
t,是文本语义特征向量;
[0091]
s44,融合后的特征经过情绪化翻译器得到目标语言答案文本;
[0092]
具体算法如下:
[0093]
c2=encodertransformer(concat(z,t));
[0094][0095]
其中,
[0096]
m为目标语言答案文本的序列长度,
[0097]
θ为模型参数,
[0098]
y
<t
表示y1,y2,
…
,y
t
‑1。
[0099]
更具体的说,步骤4中的基于transformer的基准语言翻译引擎内部实现如图3所示:
[0100]
s411,输入源语言(中、英或其他语言)通过通用表征器得到源语言句子的通用特征向量f(不同语言中具有相同意义的句子都表示成相同的特征向量);
[0101]
s412,源语言句子的通用特征向量f通过transformer编码器得到编码器输出向量c(上下文特征);
[0102]
具体算法如下:
[0103]
c=encodertransformer(x1,x2,x3,k,x
m
);
[0104]
s413,输入目标语言token,,判断目标语言,(根据目标语言token,选择对应的语种解码器);
[0105]
s414,根据不同的目标语言,将编码器输出向量c送到对应的transformer解码器进行解码,得到目标译文;
[0106]
具体算法如下:
[0107][0108]
其中,
[0109]
k(如1,2,3,
…
,n)表示语种编号,比如中文(k=1),英文(k=2),
[0110]
t(1,2,3,
…
,t
k
)表示目标语言的序列长度,
[0111]
y
k
为对应语种k的参考译文,
[0112]
c
k
为语种k对应的上下文向量。
[0113]
本技术具有如下创新点:
[0114]
1)基于transformer结构提出了多语言互译架构:不同语种的源语言句子通过通用表征器可以得到通用特征向量(不同语言中具有相同意义的句子都表示成相同的特征向量),因而对于不同语种的输入句子共享transformer编码,解码时根据目标语言token来选择不同的语种解码器来进行解码得到翻译结果。
[0115]
2)神经机器翻译与智能对话系统有机结合。缓和了智能问答系统数据难收集(尤其是小语种)的问题,本技术在训练智能对话系统时,只需要中文对话数据就行,而中文数据相对其他多数语种而言要更易于收集。而和对话数据收集相比,收集用于神经机器翻译训练的各国平行语料要简单很多。
[0116]
3)在生成目标语言答案文本前融合了多语言答案以及语音情绪特征,得到的答案文本更准确,更符合对话情景。
[0117]
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是在本发明的发明构思下,利用本发明说明书及附图内容所作的等效结构变换,或直接/间接运用在其他相关的技术领域均包括在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。