基于smaa
‑
ds的信用等级与违约损失率相匹配的评级系统及方法
技术领域
1.本发明涉及信用评估技术领域,尤其涉及一种基于smaa
‑
ds的信用等级与违约损失率相匹配的评级系统及方法。
背景技术:
2.信用评分是评估借款人信用状况的主要工具,金融机构或贷款人根据信用评分和信用等级做出相应的信贷决策,有效分配信贷资源,包括是否贷款、贷款利率和贷款金额等。具体做法是分析历史上违约和不违约客户的若干样本,从已知的数据中挖掘影响借款人是否违约的关键特征,建立数学模型并测量借款人的违约风险。
3.当前关于信用评分的研究中,一般是直接综合使用所有指标信息计算借款人的信用评分。近年来,一些学者根据信息能否被准确量化和可信地传递,将指标分为硬信息和软信息。软信息可在一定程度上减少借款人和出借人之间的信息不对称,进而使得出借人和贷款平台能够更好地评估借款认的违约风险和贷款利率。区分软信息和硬信息也缓解金融市场带来的逆向选择问题,提高借贷市场的运作效率。具体而言,对于借款者提高了其贷款可得性,对于投资者降低了其投资风险。
4.针对借款人,软信息包括借款人的性别、年龄、贷款描述中的文本信息、社交网络发布的照片、在线行为、人格和道德等指标。硬信息包括年收入、工作年限、负债收入比、fico评分和循环贷款利用率等指标。针对小微企业,硬信息包括税前利润/总资产(roa,profit before taxes/total assets),短期债务/股东权益(short
‑
term debt/equity),和现金/总资产(cash/total asset)等指标,软信息包括无形资产/固定资产(intangible assets/fixed assets),研发支出/销售额(r&d/sales)和潜在的市场情况(potential market)指标。
5.由于文本信息包含了借款人的文字组织能力,拼写错误的单词的百分比,借款目的和债务状况等信息,还款能力和还款意愿,所以被广泛研究。rientsgalema(2020)为考察熟悉借款人的投资者在p2p贷款中信贷配给的作用,通过荷兰的p2p借贷数据进行实证,结果表明,熟悉借款人的投资者可以在其他p2p投资者之前进行投资,并且该笔贷款具有较低的违约概率。weiguo zhang等(2020)提出了一种充分挖掘贷款描述中的文本信息的新方法。通过美国lendingclub和中国人人贷的贷款数据进行实证,结果表明,在贷款预测的auc和g
‑
mean的指标上,考虑贷款描述文本信息的软信息和硬信息的组合模型优于仅考虑硬信息的模型。区分指标类型的统计计量模型考虑了软信息和硬信息对违约概率的不同影响,提高了违约判别的准确率。
6.但是,现有研究忽略了从指标变化方式和变化幅度的角度探索离散指标和连续指标对违约概率的不同影响。在数学上,离散型指标是一个仅有可数个取值的变量,连续型指标是在一定区间内有无限个取值的变量。在信用评分领域中,典型的离散型指标是信用卡账户的数量,典型的连续型指标是年收入。软信息和硬信息与离散型和连续型指标有交叉,
例如“年收入”这个指标,从硬信息和软信息的分类上属于硬信息,从离散型指标和连续型指标的分类上属于连续型指标。从指标类型的角度看,不同指标类型与违约状态之间的映射关系不同,不同指标类型的违约鉴别能力也不同。
7.在很多实际的决策问题中,决策者很难知道精确的相关信息,或者很多决策需要的信息可能存在缺失。随机多属性可接受度分析方法(stochastic multi
‑
criteria acceptability analysis,smaa)就是为了帮助决策者不确定情景下进行多属性决策的一种决策方法。通过逆权重空间分析的方法可以在不知道精确的属性值和决策者偏好信息的情况下,帮助决策者找出最好的方案。通过逆权重空间分析的方法,会得到很多信息,决策者可以根据这些信息,判断出最优的方案。
8.证据理论由美国哈佛大学数学家dempster于1967年提出的,他的学生shafer对其进行推广和完善,所以证据理论又称为dempster
‑
shafer理论(简称d
‑
s理论)。证据理论是一种不确定性推理方法,它允许把问题当作一个证据,把问题的描述情况当作支持证据的命题,所有可能出现命题的集合当作支持证据的幂集。例如,换句话说,支持证据的命题是幂集的子集。比如:法官断案某个嫌疑犯,则该嫌疑犯的描述情况一定是幂集{有罪}{无罪}和{不确定}的子集。由于问题的复杂性或主观判定的不确定性,证据理论对各个命题采用置信度的形式表示。比如m(a)=0.5,m(b)=0.2,m(c)=0.3,它表示本证据说明有罪的置信度为化0.5,无罪的置信度为0.2,不确定的置信度为0.3。但是,在实际应用中,证据间存在冲突问题,d
‑
s理论有时无法融合出合理效果,特别是在1984年zadeh提出d
‑
s理论存在悖论现象,这在很大程度上制约了它的应用。为解决冲突问题,杨剑波、王应明等提出了证据推理(evidential reasoning,er)方法,该方法引入了证据权重,并在d
‑
s理论基础上采用了er组合规则,有效地解决了证据合成时出现悖论问题。
技术实现要素:
9.针对现有技术存在的问题,本发明提供一种基于smaa
‑
ds的信用等级与违约损失率相匹配的评级系统及方法。
10.为了解决上述技术问题,本发明采用以下的技术方案:
11.一方面,一种基于smaa
‑
ds的信用等级与违约损失率相匹配的评级系统,包括:用户登录注册模块,用户数据管理模块,用户信用评级模块。
12.所述用户登录注册模块,借款人通过用户页面进行注册自己的个人信息,包括手机号和姓名,注册成功后进入登录页面进行账号登录;
13.所述用户数据管理模块,借款人登录后点击借款按钮进入借款详细信息页面,在借款详细信息页面添加和修改借款人指标数据;
14.所述用户信用评级模块,借款人登录后点击信用评级按钮进入信用评级信息页面,进行信用评级,并进行显示。
15.另一方面,一种基于smaa
‑
ds的信用等级与违约损失率匹配的信用评级调整方法,基于前述一种基于smaa
‑
ds的信用等级与违约损失率匹配的信用评级系统实现,具体包括以下步骤:
16.步骤1:对金融机构积累的信用贷款业务的所有借款人历史数据进行预处理;
17.步骤1.1:将定量指标值采取最大最小标准化方法进行标准化处理;
18.步骤1.2:将定性指标值的打分结果与违约状态,根据定性指标取值对应的打分结果越大违约概率越低的原则相匹配,利用excel的数据透视图工具统计出定性指标取值与违约概率的对应关系,其中违约概率同一个定性指标取值对应的违约人数除以总人数;
19.步骤1.3:使用功效系数法对定性指标值进行打分,如下式所示:
20.设x
ij
表示第i个借款人第j个指标的隶属度值;v
ij
表示第i个借款人第j个指标的值,则功效系数法公式(1):
[0021][0022]
其中:和是第j个指标的满意值和不允许值,c,d为常数;
[0023]
步骤:2:构建单个定性指标与违约状态间的二元logistic回归模型,使用wald统计量筛选具有违约判别能力的单个指标,再将保留的单个指标按照指标性质区分成离散型指标和连续型指标;
[0024]
所述二元logistic回归模型中,假设一组独立同分布的观测数据(x,y),其中y为因变量,y=(y1,y2,
…
,y
n
),y
n
表示第n个借款人的违约状态,n表示一共有n个观测数据,即借款人,x为j维向量的自变量,x=(x
i1
,x
i2
,
…
,x
ij
…
,x
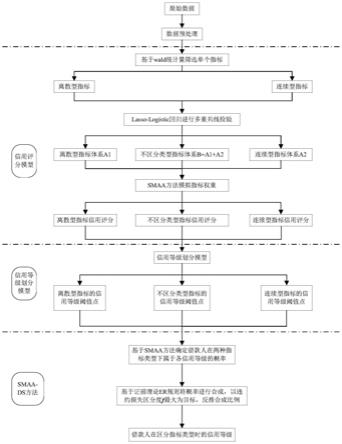
ij
),x
ij
表示第i个借款人的第j个指标的取值,j表示一共有j个维度(指标),y
i
∈{0,1}。设定y
i
=1表示借款人违约,y
i
=0表示借款人没有违约,p(y
i
=1|x
i
)=p
i
表示在x
i
已知的情况下y
i
=1的概率,x
i
表示第i个借款人,p
i
如式(2)所示,其中β为系数向量。
[0025][0026]
通过式(2)对进行变换可以得到logistic模型,如式(3)所示。
[0027][0028]
构建wald统计量,对单个指标的回归系数做显著性检验;设w
j
为第j个指标的wald统计量值,为第j个指标的系数估计值,se
βj
为系数β
j
的标准误差,故第j个指标的wald统计量w
i
如式(4)所示。
[0029][0030]
步骤3:使用lasso
‑
logistic模型对离散型指标和连续型指标进行多重共线性检验,构建两种指标类型下具有最优整体违约判别能力的信用评分指标体系,分别以lasso
‑
logistic的回归系数作为指标权重大小的依据,设置权重约束,利用随机多属性可接受度分析方法smaa求解两种指标类型下的最优权重,计算借款人在两种指标类型下的信用评分;
[0031]
所述lasso
‑
logistic模型中,假设一组独立同分布的观测数据(x,y),其中y为因变量,y=(y1,y2,
…
,y
n
),x为p维向量的自变量,x=(x
i1
,x
i2
,
…
,x
ip
),共n组数据,每组数据包含p个自变量和1个因变量。当因变量为二分类变量时,因变量是借款人表现为违约或是非违约两种情况的还款状态,使用lasso
‑
logistic回归模型进行拟合;
[0032]
lasso
‑
logistic回归对n个自变量x的系数β的参数估计具体如式(5)所示。
[0033][0034]
其中,λ为调节压缩系数的参数,表示模型拟合程度,是对模型中变量系数的惩罚,由于各观测数据独立同分布,则它们的联合分布可用各边际分布的乘积来表示,即n个观测值(借款人)的似然函数用l(θ)表示。
[0035]
利用特征组合内的指标评分和指标权重,以线性加和方式计算借款人的信用评分。假设表示第j个指标第k次模拟的权重(j=1,2,3,
…
,j),(k=1,2,3,
…
,k,),u
ij
表示第i个借款人在指标j下的标准化数值,第i个借款人在第k次模拟的信用评分如式(6)所示:
[0036][0037]
第i个借款人在k次模拟的信用评分均值如式(7)所示:
[0038][0039]
步骤4:建立信用等级划分优化模型,优化模型是由1个目标函数和2个约束条件组成,以相邻信用等级间违约损失率之差的平方和最大为目标函数,以信用等级越高违约损失率越低为约束条件1,以相邻等级违约损失率差值约束,后一个违约损失率差值为前一个差值的a至b倍范围为约束条件2,确定借款人在两种指标类型下的信用等级。
[0040]
步骤4.1:目标函数f的建立;
[0041]
将借款人划分为l个信用等级,lgd
l
为第l个信用等级的违约损失率,则目标函数如式(8)所示。
[0042]
obj:maxf=(lgd
l
‑
lgd
l
‑1)2 (lgd
l
‑1‑
lgd
l
‑2)2 ... (lgd2‑
lgd1)2ꢀꢀꢀꢀ
(8)
[0043]
步骤4.2:约束条件1以及约束条件2的建立
[0044]
约束条件1:各信用等级违约损失率随信用等级降低而递增,如式(9)所示:
[0045]
s.t.:0<lgd1<lgd2<...<lgd
l
≤1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0046]
约束条件2:相邻等级违约损失率差值约束,后一个违约损失率差值为前一个差值的a至b倍范围。
[0047]
设δlgd
l,l 1
为第l个信用等级lgd
l
与第l 1个信用等级lgd
l 1
的违约损失率差值,即相邻等级间的差值表示如式(10)所示。
[0048]
δlgd
l,l 1
=lgd
l 1
‑
lgd
l
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)则设置相邻等级间的违约损失率差值关系如式(11)所示。
[0049]
δlgd
l,l 1
=[a,b]
×
δlgd
l
‑
1,l
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)其中,第l个信用等级的违约损失率lgd
l
如式(12):
[0050][0051]
其中,g
l
表示第l个信用等级的借款人样本个数;g
l
表示前l
‑
1个信用等级的借款人样本个数总和,g
l
=g
1
g2
…
g
l
‑1;l
li
表示第l个信用等级中第i个借款人的违约损失金额(loss);r
li
表示第l个信用等级中第i个借款人的应收本息和(receivables)。
[0052]
步骤5:在两种指标类型下基于smaa方法分别确定借款人的t次信用评分,进而将t次信用评分与各个信用等级的阈值点进行比较,确定各借款人属于不同信用等级的概率;
[0053]
将t次评分的均值作为借款人的信用评分,记为信用评分均值,通过信用评分均值确定借款人的信用等级;模拟t次信用评分,然后把t次信用评分和各个信用等级的阈值点进行比较,确定各借款人属于不同信用等级的概率;
[0054]
步骤6:对两种指标类型进行不同比例组合,使用证据理论er组合规则将两种指标类型下的借款人信用等级进行集成,通过计算比较不同组合比例下的违约损失区分度f的大小,即步骤4.1中的目标函数f,以区分度f最大为依据,得到离散型指标和连续型指标的最佳组合比例,作为smaa
‑
ds模型中两种指标类型的最终组合比例,并将此比例输入证据理论er合成规则确定借款人的信用等级信息;
[0055]
所述证据理论er组合规则如下所示:
[0056]
步骤d1:求出各证据在合成之前的bpa值,其中各证据是指借款人分别在离散型指标和连续型指标中属于所有等级的概率
[0057]
设θ为识别框架,2个证据m1、m2:2θ
→
[0,1]。
[0058][0059][0060][0061][0062]
其中w
o
为证据o的相对权重,且o为证据的个数。β
o
(h
n
)和β
o
(h)分别代表焦元和的置信度,是证据o的bpa值,l表示第l个等级,一共有l个等级。
[0063]
步骤d2:利用证据理论er组合规则将证据进行合成,求出合成后各个证据的bpa值。
[0064][0065][0066][0067][0068]
其中m
12
(h
l
)表示借款人组合后属于第l个等级的bpa值;k为证据冲突系数,k越大
表明证据之间的冲突越大;b和c表示为借款人在离散型指标类型下和连续型指标类型下分别属于某个等级;为过程参数;分别表示离散型,连续型,离散型和连续型指标中待分配信念比例(概率);m1(b),m2(c)分别表示b和c在组合前的bpa(mass函数)。
[0069]
步骤d3:将合成后各个证据的bpa值转换成置信度bel,即借款人在smaa
‑
ds模型中属于信用等级h
l
的概率。
[0070][0071][0072]
步骤7:用户在用户登录模块登录,然后在用户数据管理模块填写和修改个人信息。对借款人在用户数据管理模块输入的数据输入到用户信用评级模块,用户点击用户信用评级模块,显示信用评级。
[0073]
本发明所产生的有益效果在于:
[0074]
本发明提出一种基于smaa
‑
ds的评级与违约损失率匹配的信用评级系统及方法,具备以下有益效果:
[0075]
1、本发明从指标变化幅度和方式的角度将离散型和连续型指标以非线性方式构建的信用评级模型满足“信用等级越高违约损失率越低”的标准,且其区分不同违约可能性借款人的能力较强。
[0076]
2、本发明为金融机构或贷款人信用评级与信贷决策提供重要参考,有效分配信贷资源,包括是否贷款、信用评级等。
附图说明
[0077]
图1为本发明实施例中信用评级系统总体结构框图;
[0078]
图2为本发明实施例中信用评级方法的总体流程图;
[0079]
图3为本发明实施例中不同模型信用等级划分结果对比图。
具体实施方式
[0080]
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
[0081]
一方面,一种基于smaa
‑
ds的信用等级与违约损失率相匹配的评级系统,如图1所示,包括:用户登录注册模块,用户数据管理模块,用户信用评级模块。
[0082]
所述用户登录注册模块,借款人通过用户页面进行注册自己的个人信息,包括手机号和姓名,注册成功后进入登录页面进行账号登录;
[0083]
所述用户数据管理模块,借款人登录后点击借款按钮进入借款详细信息页面,在借款详细信息页面添加和修改借款人指标数据;
[0084]
所述用户信用评级模块,借款人登录后点击信用评级按钮进入信用评级信息页面,进行信用评级,并进行显示。
[0085]
另一方面,一种基于smaa
‑
ds的信用等级与违约损失率匹配的信用评级调整方法,
基于前述一种基于smaa
‑
ds的信用等级与违约损失率匹配的信用评级系统实现,如图2所示,具体包括以下步骤:
[0086]
步骤1:对金融机构积累的信用贷款业务的所有借款人历史数据进行预处理;
[0087]
步骤1.1:将定量指标值采取最大最小标准化方法进行标准化处理;其中指标值为全是数字的指标;
[0088]
步骤1.2:将定性指标值的打分结果与违约状态根据定性指标取值对应的打分结果越大违约概率越低的原则相匹配,利用excel的数据透视图工具统计出定性指标取值与违约概率的对应关系,其中违约概率同一个定性指标取值对应的违约人数除以总人数;例如家庭住址是某市的有10000人,其中10000人违约,则借款人在家庭住址这个定性指标中取值是某市,其对应的违约概率是0.1;
[0089]
其中违约状态是历史样本中每一条数据自带的指标;
[0090]
步骤1.3:使用功效系数法对定性指标值进行打分,如下式所示:
[0091]
设x
ij
表示第i个借款人第j个指标的隶属度值;v
ij
表示第i个借款人第j个指标的值,则功效系数法公式(1):
[0092][0093]
其中:和是第j个指标的满意值和不允许值,c,d为常数,c的作用是对变换后的值进行平移,d的作用是对变换后的值进行放大或者缩小。此时设定c=0.5,d=0.5。根据初始指标体系中定性指标各分类的违约情况,对定性指标进行打分处理,6个定性指标的标准化处理过程如表1所示。
[0094]
表1定性指标标准化处理过程
[0095][0096]
本实施例中使用某平台2012年三年期的43471个贷款数据进行实证,经过数据清洗之后剩余了16574个贷款数据作为样本。
[0097]
步骤:2:构建单个定性指标与违约状态间的二元logistic回归模型,使用wald统计量筛选具有违约判别能力的单个指标,去除wald统计量小于3.841的指标,保留wald统计量大于3.841的指标,再将保留的单个指标按照指标性质区分成离散型指标和连续型指标;
[0098]
离散型指标包括年龄,学历,婚姻状况,房屋所有权状况,有无贷款记录,是否有未
归还的银行借款等。连续型指标包括月收入,每月还款金额占月收入的比例,每月日常支出等。
[0099]
logistic回归是常用的分类模型,该模型中因变量为离散变量,以二元变量为主。
[0100]
所述二元logistic回归模型中,假设一组独立同分布的观测数据(x,y),其中y为因变量,y=(y1,y2,
…
,y
n
),y
n
表示第n个借款人的违约状态,n表示一共有n个观测数据,即借款人,x为j维向量的自变量,x=(x
i1
,x
i2
,
…
,x
ij
…
,x
ij
),x
ij
表示第i个借款人的第j个指标的取值,j表示一共有j个维度(指标),y
i
∈{0,1}。设定y
i
=1表示借款人违约,y
i
=0表示借款人没有违约,p(y
i
=1|x
i
)=p
i
表示在x
i
已知的情况下y
i
=1的概率,x
i
表示第i个借款人,p
i
如式(2)所示,其中β为系数向量。
[0101][0102]
通过式(2)对进行变换可以得到logistic模型,如式(3)所示。
[0103][0104]
构建wald统计量,对单个指标的回归系数做显著性检验;设w
j
为第j个指标的wald统计量值,为第j个指标的系数估计值,se
βj
为系数β
j
的标准误差,故第j个指标的wald统计量w
i
如式(4)所示。
[0105][0106]
由于是对单个指标进行wald统计量检验,故服从自由度为1的χ2分布,由χ2分布表知,此时满足显著性水平α=0.05下的χ2临界值为χ
0.052
(1)=3.841,即当指标i的wald统计量大于3.841认为该指标具有显著违约判别能力。
[0107]
步骤3:使用lasso
‑
logistic模型对离散型指标和连续型指标进行多重共线性检验,构建两种指标类型下具有最优整体违约判别能力的信用评分指标体系,分别以lasso
‑
logistic的回归系数作为指标权重大小的依据,设置权重约束,确定指标权重合理区间,利用随机多属性可接受度分析方法smaa求解两种指标类型下的最优权重,计算借款人在两种指标类型下的信用评分;
[0108]
其中合理区间为,考虑指标回归系数受数据变化的影响,导致部分指标权重过大或过小,干扰信用评分的准确性,通过设置权重约束n为指标个数,来减少客观数据变化对指标权重的影响。即当指标权重小于时,该指标的权重调整为当指标权重大于时,该指标的权重调整为
[0109]
所述信用评分的计算如下面所示。
[0110]
lasso
‑
logistic模型是通过在最小二乘法的基础上添加系数惩罚进行系数收缩,从而实现变量选择的技术。所述lasso
‑
logistic模型中,假设一组独立同分布的观测数据(x,y),其中y为因变量,y=(y1,y2,
…
,y
n
),x为p维向量的自变量,x=(x
i1
,x
i2
,
…
,x
ip
),共n组数据,每组数据包含p个自变量和1个因变量。当因变量为二分类变量时,因变量是借款人表现为违约或是非违约两种情况的还款状态,使用lasso
‑
logistic回归模型进行拟合;
[0111]
lasso
‑
logistic回归对n个自变量x的系数β的参数估计具体如式(5)所示。
[0112][0113]
其中,λ为调节压缩系数的参数,表示模型拟合程度,是对模型中变量系数的惩罚,由于各观测数据独立同分布,则它们的联合分布可用各边际分布的乘积来表示,即n个观测值(借款人)的似然函数用l(θ)表示。
[0114]
利用特征组合内的指标评分和指标权重,以线性加和方式计算借款人的信用评分。假设表示第j个指标第k次模拟的权重(j=1,2,3,
…
,j),(k=1,2,3,
…
,k,),u
ij
表示第i个借款人在指标j下的标准化数值,第i个借款人在第k次模拟的信用评分如式(6)所示:
[0115][0116]
第i个借款人在k次模拟的信用评分均值如式(7)所示:
[0117][0118]
步骤4:建立信用等级划分优化模型,优化模型是由1个目标函数和2个约束条件组成,以相邻信用等级间违约损失率之差的平方和最大为目标函数,以信用等级越高违约损失率越低为约束条件1,以相邻等级违约损失率差值约束,后一个违约损失率差值为前一个差值的a至b倍范围为约束条件2,确定借款人在两种指标类型下的信用等级。
[0119]
步骤4.1:目标函数f的建立;
[0120]
将借款人划分为l个信用等级,lgd
l
为第l个信用等级的违约损失率loss given default,则目标函数如式(8)所示。
[0121]
obj:max f=(lgd
l
‑
lgd
l
‑1)2 (lgd
l
‑1‑
lgd
l
‑2)2 ... (lgd2‑
lgd1)2ꢀꢀꢀꢀ
(8)
[0122]
通过计算所有两两相邻信用等级之间的违约损失率差值平方和的总和,选取所有信用等级划分方案中该值最大的方案,保证了筛选出的信用等级划分结果的各信用等级违约损失区分度最大,较好地区分不同信用状况的借款人,实现合理有效的信用等级划分,进而确定各等级间的阈值点。
[0123]
步骤4.2:约束条件1以及约束条件2的建立
[0124]
约束条件1:各信用等级违约损失率随信用等级降低而递增,如式(9)所示:
[0125]
s.t.:0<lgd1<lgd2<...<lgd
l
≤1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0126]
约束条件2:相邻等级违约损失率差值约束,后一个违约损失率差值为前一个差值的a至b倍范围。为避免违约损失率变化过于敏感,且由于目标函数是求最大,盲目追求等级间的违约损失率差值容易导致划分结果的不合理,通过设置合理的区间范围,既保证划分结果的区分度也可保证其合理性。本实施例中设置相邻等级违约损失率差值区间范围为[1,1.2]。
[0127]
设δlgd
l,l 1
为第l个信用等级lgd
l
与第l 1个信用等级lgd
l 1
的违约损失率差值,即相邻等级间的差值表示如式(10)所示。
[0128]
δlgd
l,l 1
=lgd
l 1
‑
lgd
l
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)则设置相邻等级间的违约损失率差值关系如式(11)所示。
[0129]
δlgd
l,l 1
=[a,b]
×
δlgd
l
‑
1,l
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)其中,第l个信用等级的违约损失率lgd
l
如式(12):
[0130][0131]
其中,g
l
表示第l个信用等级的借款人样本个数;g
l
表示前l
‑
1个信用等级的借款人样本个数总和,g
l
=g
1
g2
…
g
l
‑
1;l
li
表示第l个信用等级中第i个借款人的违约损失金额(loss);r
li
表示第l个信用等级中第i个借款人的应收本息和(receivables)。
[0132]
该模型可以输出每个等级的信用评分阈值点、违约损失金额、应收本息、人数和违约损失率。
[0133]
步骤5:在两种指标类型下基于smaa方法分别确定借款人的t次信用评分,进而将t次信用评分与各个信用等级的阈值点进行比较,确定各借款人属于不同信用等级的概率;
[0134]
将t次评分的均值作为借款人的信用评分,记为信用评分均值,通过信用评分均值确定借款人的信用等级;模拟t次信用评分,然后把t次信用评分和各个信用等级的阈值点进行比较,确定各借款人属于不同信用等级的概率;
[0135]
例如模拟1000次信用评分,第1个借款人被划分到第一、二、三、四、五、六、七个等级的次数分别为0、0、817、183、0、0、0,用划分为每个等级的次数分别除以1000得到的比例是0、0、0.817、0.183、0、0、0,则该借款人属于第一、二、三、四、五、六、七个等级的概率分别为0、0、0.817、0.183、0、0、0。将借款人在离散型指标和连续型指标类型下属于每个等级的概率分别放入表2中的第2列到第15列,表2中的第1列为借款人的序号。
[0136]
表2借款人在两种指标类型下属于不同信用等级的概率
[0137][0138][0139]
步骤6:对两种指标类型进行不同比例组合,使用证据理论er组合规则将两种指标类型下的借款人信用等级进行集成,通过计算比较不同组合比例下的违约损失区分度f的大小,即步骤4.1中的目标函数f,以区分度f最大为依据,得到离散型指标和连续型指标的最佳组合比例,作为smaa
‑
ds模型中两种指标类型的最终组合比例,并将此比例输入证据理论er合成规则确定借款人的信用等级信息;
[0140]
以违约损失区分度f最大为0.0086时对应的w1=0.54,w2=0.46为例介绍er规则在表2第1个借款人在smaa
‑
ds模型中信用等级的计算过程,算例中h
l
分别取值为a,b,c,d,e,f
和g等级,h取a,b,c,d,e,f和g等级的集合。
[0141]
步骤d1:构造mass函数m1,m2,求出离散型指标类型(简记为1)和连续型指标类型(简记为2)的bpa值
[0142]
将表2第一行数字和w1=0.54,w2=0.46代入公式13可以得到:
[0143]
m1({a})=w1*β1({a})=0.54*0=0
[0144]
m1({b})=w1*β1({b})=0.54*0=0
[0145]
m1({c})=w1*β1({c})=0.54*0.8170=0.4412
[0146]
同理,m1({d})=0.0988,m1({e})=0,m1({f})=0,m1({g})=0。
[0147]
m2({a})=w2*β2({a})=0.46*0=0
[0148]
m2({b})=w2*β2({b})=0.46*0=0
[0149]
m2({c})=w2*β2({c})=0.46*0=0
[0150]
同理,m2({d})=0,m2({e})=0.0069,m2({f})=0.4531,m2({g})=0。
[0151]
将w1=0.54,w2=0.46代入公式14可以得到:
[0152][0153][0154]
将w1=0.54,w2=0.46和表2第一行数字代入公式15可以得到:
[0155][0156][0157]
将和代入公式16可以得到:
[0158][0159][0160]
步骤d2:利用证据理论er规则进行合成,求出离散型指标类型(简记为1)和连续型指标类型(简记为2)合成后证据的bpa值:
[0161]
代入公式17计算冲突系数k
[0162][0163]
(1)计算信用等级a,b,c,d,e,f,g组合后的bpa值
[0164]
代入公式18,可以得到
[0165][0166]
代入公式19,可以得到
[0167][0168]
代入公式20可以得到
[0169][0170]
(2)计算各个信用等级组合后的bpa值
[0171]
代入公式20可以得到信用等级a的组合后的bpa值
[0172][0173]
代入公式20可以得到信用等级b的组合后的bpa值
[0174][0175]
同理,m
12
({c})=0.3170,m
12
({d})=0.0710,m
12
({e})=0.0042,m
12
({f})=0.2773,m
12
({g})=0。
[0176]
步骤d3:组合后证据的bpa值转换成置信度,即借款人在smaa
‑
ds模型中的属于各个信用等级的概率
[0177]
代入公式21,可以得到
[0178][0179]
代入公式22,可以得到借款人在smaa
‑
ds模型中的属于信用等级a的概率
[0180][0181]
借款人在smaa
‑
ds模型中的属于信用等级b的概率
[0182][0183]
借款人在smaa
‑
ds模型中的属于信用等级c的概率
[0184][0185]
借款人在smaa
‑
ds模型中的属于信用等级d的概率
[0186][0187]
同理β
12
({e})=0.0063,β
12
({f})=0.4142,β
12
({g})=0。
[0188]
将此借款人在smaa
‑
ds模型中属于各个等级的概率放入表3中的第2行,选概率最大的等级作为借款人在smaa
‑
ds模型中的信用等级。第1个借款人属于等级c的概率最大,于是该借款人在smaa
‑
ds模型中的信用等级是c。同理可以计算第2
‑
16574个借款人在smaa
‑
ds模型中属于各信用等级的概率分布情况,放入表3第3
‑
16575行。当公式(13)中的比例w1从0到1遍历过程(w2=1
‑
w1)中,w1=0.54,w2=0.46时违约损失区分度f最大为0.0086,能够最大程度区分不同信用水平的借款人。于是w1=0.54,w2=0.46就是smaa
‑
ds模型中两种指标类型的最佳组合比例。
[0189]
表3借款人在smaa
‑
ds中属于各信用等级的概率分布情况
[0190][0191][0192]
并统计表3最后一列的数据可以得到smaa
‑
ds模型中每个等级的人数,将表3的最后一列数据带入公式(12)可以计算得到smaa
‑
ds模型的、违约损失率、各个等级的人数,并通过各个等级的人数确定各个等级的信用评分阈值点。
[0193]
步骤7:用户在用户登录模块登录,然后在用户数据管理模块填写和修改个人信息。对借款人在用户数据管理模块输入的数据输入到用户信用评级模块,用户点击用户信用评级模块,显示信用评级。
[0194]
本实施例中信用等级划分结果对比如表4所示,由图3可知,在smaa
‑
ds模型中w1=0.54,w2=0.46时使用证据理论er方法的信用等级划分结果最优。
[0195]
表4信用等级划分结果的对比
[0196][0197][0198]
图1对比4个模型信用等级划分结果
[0199]
同时smaa
‑
ds模型具有可解释性,能够指导实际银行等金融机构的贷款实践。smaa
‑
ds模型的优势表现在6个方面:
[0200]
1)smaa
‑
ds模型的违约损失区分度f最大,能最大程度地区分不同违约可能性的借款人。信用等级划分的本质是能最大程度区分不同违约可能性的借款人,而相邻等级之间的违约损失率的差f越大说明相邻等级借款人的信用水平差异越大,同一信用等级借款人的信用水平差异越小。smaa
‑
ds模型的违约损失区分度f=0.0086,lending club 43471个
样本和16574个样本、不区分指标类型、离散型指标和连续型指标对应的违约损失区分度f分别是0.0028、0.0022、0.0065、0.0067和0.0032。smaa
‑
ds模型的违约损失区分度f是不区分指标类型模型f的132.31%。显然,smaa
‑
ds模型中最能区分不同违约程度地借款人。
[0201]
2)smaa
‑
ds模型的高信用等级的违约损失率最低,能最大程度留住高信用等级的优质客户。在美国这样一个金融行业比较发达的市场,信用等级比较高的借款人往往拥有多个贷款来源,所以给高信用等级的客户划分的违约损失率最低,相应的贷款利率也最低,更能留住高信用等级的优质客户。smaa
‑
ds模型的a等级的违约损失率是0.68%,lending club 43471个样本和16574个样本、不区分指标类型、离散型指标和连续型指标对应的a等级违约损失率分别是3.41%、2.91%、1.25%、0.75%和0.62%。相对于不区分指标类型a等级的违约损失率,smaa
‑
ds模型的a等级的违约损失率降低了45.60%。显然,smaa
‑
ds模型中的高等级的违约损失率最小,最能留住优质客户。
[0202]
3)smaa
‑
ds模型的低等级的违约损失率最高,能最大程度降低平台预期的违约损失。对于信用等级比较低的借款人,p2p平台的主要目的是减少违约损失,所以将识别出最低等级借款人并给予较高的贷款定价,可以最大程度弥补p2p平台的违约损失。smaa
‑
ds模型的g等级的损失率是21.69%,lending club 43471个样本和16574个样本、不区分指标类型、离散型指标和连续型指标对应的g等级违约损失率分别是8.87%、7.27%、20.19%、20.53%和13.93%。相对于不区分指标类型g等级的违约损失率,smaa
‑
ds模型的g等级的违约损失率提高了7.43%。显然,smaa
‑
ds模型中的低等级的违约损失率最小,最能减少违约损失。
[0203]
4)smaa
‑
ds模型相邻等级之间的违约损失率最小间隔按照从大到小顺序排名第二,仅次于离散型指标。smaa
‑
ds模型的相邻等级之间的违约损失率最小间隔是2.41%,lending club 43471个样本和16574个样本、不区分指标类型、离散型指标和连续型指标对应的相邻等级之间的违约损失率最小间隔分别是0.81%、0.27%、1.97%、2.44%和1.50%。相对于不区分指标类型违约损失率的最小间隔,smaa
‑
ds模型提高了22.34%。显然,smaa
‑
ds模型中使得同一信用等级的借款人信用水平差距小,等级间借款人的信用水平差距大。
[0204]
5)smaa
‑
ds模型中a等级和g等级违约损失率差距最大,可以最大程度区分所有借款人的信用水平。smaa
‑
ds模型的a等级和g等级违约损失率差是21.01%,lending club 43471个样本和16574个样本、不区分指标类型、离散型指标和连续型指标对应的相邻等级之间的违约损失率最小间隔分别是5.46%、4.36%、18.94%、19.78%和13.31%。相对于不区分指标类型a等级和g等级违约损失率的差距,smaa
‑
ds模型提高了22.34%。显然,smaa
‑
ds模型中的a等级和g等级违约损失率差距最大。
[0205]
6)smaa
‑
ds模型服从信用等级越高违约损失率越低的信用等级划分的标准。从表11可以看出,smaa
‑
ds模型、不区分指标类型、离散型指标和连续型指标的信用等级划分结果服从信用等级越高违约损失率越低的信用等级划分标准;但是,lending club 43471个样本和16574个样本划分结果不服从上述标准。所以,smaa
‑
ds模型信用等级划分结果较好。
[0206]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同
替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求所限定的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。