1.本发明涉及互联网视频会议技术领域,具体涉及一种基于动作捕捉和三维重建的视频会议方法、终端及系统。
背景技术:
2.视频会议的核心技术是实时音视频数据流的数字压缩与解压缩,又称音视频编解码。现有的视频会议过程中,首先需要通过摄像头采集的原始视频信号,由于这个原始视频信号的数据量非常大(以常见的高清分辨率1080p@30fps为例,每秒钟的视频数据量约为744mbit),因此需要利用视频压缩技术压缩数据后,再通过网络传输。
3.然而,随着4k、8k等更高分辨率的视频信号普及,如今广泛使用的视频压缩技术(如h.261、h.263、h.264、h.265)已经不能够满足越来越高清的分辨率要求。
技术实现要素:
4.发明目的:为克服现有技术的缺陷,本发明从另一个角度出发,利用动作捕捉的数据量要远远低于完整视频画面数据量的特点,设计了一种基于动作捕捉和三维重建的视频远程会议方法及系统,可以在极低带宽下实现高品质的视频会议效果。
5.技术方案:为实现上述目的,本发明一方面提出一种基于动作捕捉和三维重建的视频会议终端,所述终端包括:编码模块、解码模块、动作捕捉模块、三维重建模块、网络传输模块;其中,
6.动作捕捉模块用于从本端获取的本地会议视频图像中分割出会议场地背景图像和人物图像,再从人物图像中提取骨骼关键节点,形成肢体网格点云,最后根据肢体网格点云将人物图像分割为局部肢体图像;
7.编码模块用于对本端待传输的会议场地背景图像、局部肢体图像和肢体网格点云进行压缩编码;
8.解码模块用于对接收到来自其他终端的压缩数据进行解码;
9.三维重建模块用于根据解码后的会议场地背景图像、局部肢体图像和肢体网格点云进行视频会议场景图像重建;
10.网络传输模块用于实现本终端与其他终端之间的数据传输。
11.针对所述视频会议终端,以下还提供了若干可选方式,但并不作为对上述总体方案的额外限定,仅仅是进一步的增补或优选,在没有技术或逻辑矛盾的前提下,各可选方式可单独针对上述总体方案进行组合,还可以是多个可选方式之间进行组合。
12.可选的,所述终端还包括摄像头,所述摄像头用于采集本地会议视频图像。
13.可选的,所述终端还包括显示模块,所述显示模块用于显示重建后的视频会议场景图像。
14.可选的,所述编码模块还用于对摄像头采集的原始视频流进行压缩编码。
15.另一方面,本发明提出一种基于动作捕捉和三维重建的视频会议系统,所述系统
包括至少两个所述的视频会议终端,即在所述系统中,包括作为发送端的视频会议终端和作为接收端的视频会议终端。
16.再一方面,本发明提出一种基于动作捕捉和三维重建的视频会议方法,所述方法基于所述的视频会议系统实现,包括以下步骤:
17.(1)发送端获取本地会议视频图像;
18.(2)发送端从本地会议视频图像中逐帧分割出会议场地背景图像和人物图像;
19.(3)发送端对人物图像进行骨骼关节点检测,得到人物的肢体网格点云;
20.(4)发送端根据肢体网格点云将人物图像分割为局部肢体图像;
21.(5)发送端将会议场地背景图像、肢体网格点云和局部肢体图像进行压缩编码后发送给接收端;
22.(6)接收端接收发送端发送来的压缩数据并进行解码;
23.(7)接收端在解码后的会议场地背景图像中,按照肢体网格点云中各关节点的位置关系将局部肢体图像进行贴图,逐帧重建视频会议场景图像。
24.针对所述视频会议方法,以下还提供了若干可选方式,但并不作为对上述总体方案的额外限定,仅仅是进一步的增补或优选,在没有技术或逻辑矛盾的前提下,各可选方式可单独针对上述总体方案进行组合,还可以是多个可选方式之间进行组合。
25.可选的,所述会议场地背景图像和所述局部肢体图像仅传输一次。
26.可选的,所述步骤(2)中,发送端通过预先训练好的基于神经网络的人物检测模型对每一帧本地会议视频图像进行会议场地背景图像和人物图像分割。
27.可选的,所述步骤(3)中,发送端采用cpn网络模型从人物图像中提取骨骼关节点。
28.可选的,所述视频会议方法还包括以下步骤:
29.在视频会议开始时,发送端先将获取的本地会议视频图像直接进行压缩编码后传输给接收端,同时执行所述步骤(2)至(5),待步骤(5)完成后,发送端停止对本地会议视频图像直接进行压缩编码后传输的步骤,返回步骤(1);
30.接收端初始时,对接收到的压缩后的本地会议视频图像进行解码并播放,当第一次接收到会议场地背景图像、肢体网格点云和局部肢体图像后,开始执行步骤(6)至(7)。
31.有益效果:与现有的视频会议中直接对采集到的原始视频流进行压缩后传输的方案相比,本发明具有以下优势:
32.本发明对原始视频流进行基于人工智能的图像数据分析处理,从原始视频流当中提取出会议场地背景图像、参会人物的局部肢体图像和肢体网格点云,由于会议过程中,会议场地背景图像和参会人物通常是不变的,所以会议场地背景图像、参会人物的局部肢体图像可以只传输一次,之后只要持续传输肢体网格点云,即可在接收端顺利实现逐帧重建视频会议场景图像。相较于直接传输原始视频流,本发明能够大大降低需要传输的数据量,进而可以在极低带宽下实现高品质的视频会议效果。
附图说明
33.图1为实施例涉及的视频会议终端的结构图;
34.图2为实施例涉及的关键点检测结果示意图;
35.图3为实施例涉及的cpn网络结构示意图;
36.图4为实施例涉及的视频会议方法的流程图。
具体实施方式
37.下面将结合附图和具体实施例对本发明作更进一步的说明。但应当理解的是,本发明可以以各种形式实施,以下在附图中出示并且在下文中描述的一些示例性和非限制性实施例,并不意图将本发明限制于所说明的具体实施例。
38.应当理解的是,在技术上可行的情况下,以下针对不同实施例所列举的技术特征可以相互组合,从而形成本发明范围内的另外的实施例。此外,本发明所述的特定示例和实施例是非限制性的,并且可以对以上所阐述的结构、步骤、顺序做出相应修改而不脱离本发明的保护范围。
39.实施例1:
40.本实施例提供了一种基于动作捕捉和三维重建的视频会议终端,用于远程视频会议。所述终端的结构如图1所示,所述终端包括摄像头、编码模块、解码模块、动作捕捉模块、三维重建模块、网络传输模块和显示屏;其中,摄像头、动作捕捉模块、编码模块和网络传输模块构成所述终端的发送通路,而网络传输模块、解码模块、三维重建模块和显示屏构成所述终端的接收通路。
41.在所述终端中,各模块的功能如下。
42.(一)摄像头
43.摄像头用于采集本地会议视频图像,包括单独的会议场地背景图像和带有人物的会议场景图像。
44.(二)动作捕捉模块用于对摄像头采集到的图像进行基于人工智能算法的分析处理,以完成对任务动作的捕捉。具体包括以下步骤:
45.s1、采用图像分割技术分割出图像中的人物,得到人物图像。
46.现有的图像分割技术很多,在本实施例中,我们仅示例性地给出一种实现方案,但现有的其他能够实现图像中人物分割的技术方案,同样适用于本发明。
47.本实施例中,我们搭建了基于神经网络的人物检测模型,采用3000张标注出人体轮廓并添加了人工标签的图片作为训练样本集合,采用梯度更新法在训练样本集合上训练所述人物检测模型,以使所述人物检测模型能够准确分割出人物图像。
48.s2、对人物图像进行骨骼关节点检测,得到肢体网格点云。
49.目前能够检测出骨骼关节点的智能算法非常多,例如alexander toshev和christian szegedy提出的deeppose算法、卡内基梅隆大学提出的convolutional pose machines、密西根大学提出的stacked hourglass networks算法等。
50.在本实施例中,我们仅示例性地给出一种实施方式,即采用cpn(cascaded pyramid network)网络模型,如图3所示。cpn网络模型由golbalnet和refinenet两个模块级联组成,其中,golbalnet用于对所有关键点进行检测,而refinenet则对检测结果中误差较大的部分进行修正。整个cpn网络模型,采用自上而下的检测策略,先检测出人体框,再在人体框中检测出关键点。
51.本实施例中,我们设置的关键点如图2所示,具体包括15个关节点:头、脊柱顶、脊柱底、左肩、右肩、左肘、右肘、左腕、右腕、左髋关节、右髋关节、左膝关节、右膝关节、左踝关
节、右踝关节,则得到的肢体网格点云就是由这15个关节点组成。
52.s3、根据肢体网格点云,将步骤s1提取出的人物图像进行局部肢体图像分割,例如:由左肩和左肘之间的连线可确定左上臂的轮廓,进而分割出左上臂,而由左肘和左腕之间的连线,则可以确定左下臂的轮廓。采用这样的方式,可以分割出头部、躯干和四肢部分的局部肢体图像。
53.s4、动作捕捉模块将会议场地背景图像、局部肢体图像、肢体网格点云传输给编码模块,由于会议过程中,场地背景和任人物通常是不会变化的,因此,会议场地背景图像和人物的局部肢体图像可以只传输一次,后续只需要持续传输肢体网格点云即可。至此,动作捕捉模块的工作流程完毕。
54.(三)编码模块
55.编码模块用于对动作捕捉模块传输过来的待传输图像进行压缩编码。由于动作捕捉需要一定的时间,所以一开始可以先按照传统视频会议方式,直接将摄像头采集到的原始视频流传输到编码模块进行压缩编码。同时,动作捕捉模块启动动作捕捉流程,待动作捕捉模块输出结果后,此时停止原本的视频流传输,而改为传输动作捕捉模块的输出结果,也就是上述的会议场地背景图像(可以只传输一次)、局部肢体图像(可以只传输一次)、肢体网格点云。
56.所述编码模块的编码方式包括h.264/avc或者h.265/hevc。
57.(四)解码模块
58.解码模块用于按照与编码模块相应的解码算法,对本终端接收到的编码后原始视频流或者编码后的图像数据进行解码。
59.(五)网络传输模块
60.网络传输模块用于实现本终端与其他终端之间的网络数据交互。
61.(六)三维重建模块
62.三维重建模块用于根据解码之后的会议场地背景图像、局部肢体图像、肢体网格点云重建视频会议场景图像。
63.具体来说,首先进行会议场地背景图像贴图,然后根据肢体网格点云中各关节点之间的关系,将局部肢体图像在会议场地背景图像上进行贴图,从而实现视频会议场景图像重建。
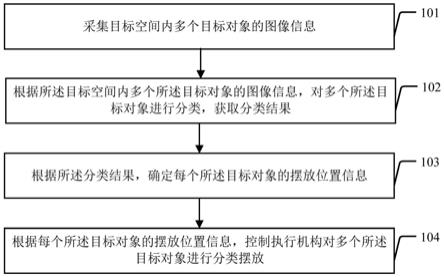
64.(七)显示屏
65.显示屏用于显示重建后的视频会议场景图像。
66.实施例2:
67.本实施例基于实施例1提出的视频会议终端,提出了一种视频会议系统,所述视频会议系统包括至少两个视频会议终端。
68.实施例3:
69.本实施例基于实施例2提出的视频会议系统,提出了基于动作捕捉和三维重建的远程视频会议方法,其流程如图4所示,具体包括以下步骤:
70.(1)发送端进行本地会议视频场景采集,并根据采集结果进行动作捕捉,具体为:从捕捉到的图像中分割出会议场地背景图像和人物图像;对人物图像进行骨骼关节点检测,得到人物的肢体网格点云,然后基于肢体网格点云将人物图像进行局部肢体图像分割;
71.(2)发送端将会议场地背景图像、局部肢体图像和肢体网格点云进行压缩编码后传输给接收端;其中,由于会议过程中,场地背景和人物通常是不会变化的,因此,会议场地背景图像和人物的局部肢体图像可以只传输一次,后续只需要持续传输肢体网格点云即可;
72.(3)接收端对接收到的压缩数据进行解码,根据得到的会议场地背景图像、局部肢体图像和肢体网格点云重建视频会议场景图像,并在显示屏上显示。
73.优选的,本实施中,发送端可以先采用传统的视频流传输手段,即先传输采集到的原始视频流,同时进行动作捕捉流程,即对采集到的图像进行会议场地背景图像、局部肢体图像、肢体网格点云的提取,待第一次动作捕捉完成后,则停止传输原始视频流,而是将会议场地背景图像、局部肢体图像、肢体网格点云进行压缩编码后传输给接收端。其中,会议场地背景图像、局部肢体图像可以只传输一次,之后只需要按照固定的帧率(比如30fps或60fps)持续传输肢体网格点云即可。
74.接收端开始时,按照传统的视频流传输手段接收并解码播放原始视频流,待接收到会议场地背景图像、局部肢体图像、肢体网格点云之后,则根据会议场地背景图像、局部肢体图像、肢体网格点云重建视频会议场景图像并显示。
75.以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。