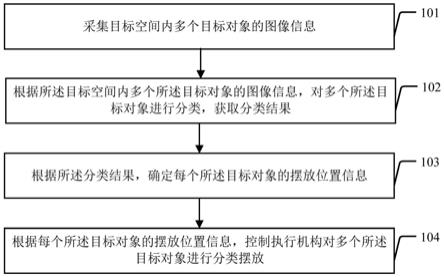
1.本发明涉及植物培育技术领域,更具体的说是涉及一种木本植物幼苗生物量预测方法。
背景技术:
2.幼苗的表型和生物量对苗木质量和造林成活率有重要影响,由此产生出许多评价指标,例如根尖数量用于评估植株生存能力;根系的总长度和表面积用于评估植物对养分和水分的获取能力;根系体积用于评估植株的生长速率、生物量分配和养分储备状况;总叶面积用于评估植株的光合作用和蒸腾作用,以及苗木质量;生物量用于评估水分、温度和光照对苗木的影响。此外,一些涵盖苗木表型和生物量分配的综合评价指标也在研究和生产中被广泛使用,例如反映苗木光合积累与根系总长度比重的比根长(specific root length;srl),反映苗木移栽后对新生境适应能力的根长比(root length ratio;rlr),以及苗木质量综合评价指标——壮苗指数(dickson quality index;dqi)。这些指标计算简洁,可解读性强,但均属于滞后性指标,不能对苗木培育过程进行动态实时地指导。
3.根系的形态和发育对植物生长至关重要,但由于非侵入性的根系研究方法尚未完全成熟,目前对根系的表型分析仍然受限,相关研究也没有像植株地上部分那样受到广泛关注。自然条件下根系形态的观测主要依靠电信号、电磁波、茎干液流、根窗及微根管等技术实现,存在操作复杂、测量成本高等问题。植株生物量是计算植物生产力、研究群落植被动态、估算植被碳储量、评估气候变化影响的关键指标,但常规的获取手段仍以烘干法为主,费时费力。现有研究表明,根系形态、植株生物量、总叶面积均与叶片叶绿素荧光参数存在密切关联,预示属于引领性指标的叶绿素荧光参数,具备对植株表型和生物量等滞后性指标进行预测的潜力。
4.因此,如何实现木本植物幼苗便捷测量,避免幼苗损伤,准确预测木本幼苗生物量是本领域技术人员亟需解决的问题。
技术实现要素:
5.有鉴于此,本发明提供了一种木本植物幼苗生物量预测方法,培育高质量苗木是造林成功的关键环节,研发高通量、高精度地表型与生物量指标测量方法,有助于提高育苗效率。本发明将株高、地径、叶绿素荧光、根系表型、生物量等指标作为数据集,并将前3类指标定义为预测指标,后2类指标定义为响应指标,应用随机森林回归算法,建立预测模型,实现能无损、实时预测植株表型和生物量。
6.为了实现上述目的,本发明采用如下技术方案:
7.一种木本植物幼苗生物量预测方法,包括以下步骤:
8.步骤1:提取木本植物幼苗参数作为小样本数据集,从木本植物幼苗参数中筛选初步输入指标以及输出指标;
9.步骤2:根据所述初步输入指标和所述输出指标,对小样本数据集采用随机森林算
法,结合穷举搜索,根据模型错误率,确定最优的初步二叉树变量个数和初步决策树数量,构建每项输出指标的初步预测模型,并提取各输出指标模型的inc node purity和inc mse参数;
10.步骤3:按照inc node purity或inc mse参数将各输出指标的初步预测模型的初步输入指标排序,对小样本数据集采用随机森林算法,结合十折交叉验证和穷举搜索,根据模型错误率,确定最优的终极二叉树变量个数、终极决策树数量和终极输入指标;
11.步骤4:利用筛选出的所述终极输入指标,终极二叉树变量个数和终极决策树数量,运行随机森林算法,构建各输出指标的终极预测模型;
12.步骤5:根据各输出指标的终极预测模型所需的终极输入指标,测量同批次的待测幼苗的相应指标,输入所述终极预测模型,获得待测量幼苗的各项输出指标。
13.优选的,所述步骤1中选定部分木本植物幼苗,测量株高、地径、叶片叶绿素相对含量、叶片叶绿素参数、单株生物量、根长比、总叶面积、茎生物量、根生物量、壮苗指数、叶生物量和比根长和单株生物量,将所述株高、所述地径、所述叶片叶绿素相对含量和所述叶片叶绿素参数作为初步输入指标,所述总叶面积、所述根长比、所述壮苗指数、所述比根长、所述根生物量、所述茎生物量、所述叶生物量和所述单株生物量作为输出指标。
14.优选的,所述步骤1中小样本数据集的数量大于60
‑
80株。
15.优选的,所述步骤1中的叶片叶绿素相对含量测量采用基于叶绿素被激发后发射的光强测量的叶绿素测定仪,测定部位为叶片叶肉部分。
16.优选的,所述步骤1中的叶片叶绿素荧光参数采用调制式叶绿素荧光仪获取叶片叶肉部分的快速叶绿素荧光指标和稳态叶绿素荧光指标。
17.优选的,所述步骤1中的生物量指将植物全株或部分烘干至恒重时的干质量。
18.优选的,所述步骤1中的比根长按照公式:比根长=根长/根生物量计算,根长比按照公式:根长比=根长/单株生物量计算,壮苗指数按照公式:壮苗指数=[单株生物量/((地径/株高) (根生物量/(茎生物量 叶生物量))]计算。
[0019]
优选的,所述步骤2的具体过程为:
[0020]
步骤21:采用穷举搜索法绘制所有二叉树变量个数的模型错误率与决策树数量的关系曲线,获得使模型错误率最低的二叉树变量个数和决策树数量;
[0021]
步骤22:依据二叉树变量个数的模型错误率与决策树数量的关系曲线,筛选使模型错误率最低的决策树数量,构建初步预测模型。
[0022]
优选的,所述步骤3的具体过程为:按照inc node purity或inc mse参数,对全部所述输入指标进行排序,进行十折交叉验证,初步确定能使模型错误率降至最低的输入指标数量,然后据此采用穷举搜索法获得使模型错误率低于给定范围的若干项最优输入指标、终极二叉树变量个数和终极决策树数量。
[0023]
优选的,进行十折交叉验证的预设次数取值范围为5至10次。
[0024]
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种木本植物幼苗生物量预测方法,将株高、地径、叶片叶绿素相对含量(spad)和叶绿素荧光参数作为输入指标,以木本植物幼苗的根干重、茎干重、叶干重和全株干重作为输出指标,采用随机森林算法,构建初步预测模型;之后采用十折交叉验证和穷举搜索,对输入指标进行筛选,构建终极预测模型,输出木本植物幼苗的根、茎、叶、全株干重。
附图说明
[0025]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
[0026]
图1附图为本发明提供的木本植物幼苗生物量预测方法流程图;
[0027]
图2附图为本发明提供的响应指标预测模型准确度示意图;
[0028]
图3附图为本发明提供的响应指标预测模型的训练集与预测集示意图。
具体实施方式
[0029]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0030]
本发明实施例公开了一种木本植物幼苗生物量预测方法,包括以下步骤:
[0031]
s1:选定部分木本植物幼苗,提取幼苗参数作为小样本数据集,测量株高、地径、叶片叶绿素相对含量、叶片叶绿素参数、单株生物量、根长比、总叶面积、茎生物量、根生物量、壮苗指数、叶生物量和比根长和单株生物量,将所述株高、所述地径、所述叶片叶绿素相对含量和所述叶片叶绿素参数作为初步输入指标,所述总叶面积、所述根长比、所述壮苗指数、所述比根长、所述根生物量、所述茎生物量、所述叶生物量和所述单株生物量作为输出指标;
[0032]
s2:根据初步输入指标和输出指标,对小样本数据集采用随机森林算法,结合穷举搜索,根据模型错误率,确定最优的初步二叉树变量个数和初步决策树数量,构建每项输出指标的初步预测模型,并提取各输出指标模型的inc node purity和inc mse参数;
[0033]
s21:绘制所有二叉树变量个数的模型错误率与决策树数量的关系曲线,并采用穷举搜索法获得模型错误率最低的二叉树变量个数;
[0034]
s22:依据二叉树变量个数的模型错误率与决策树数量的关系曲线,筛选使模型错误率最低的决策树数量,构建初步预测模型;
[0035]
具体的在s2中,运行随机森林的算法代码,需要以二叉树变量个数和决策树数量2个变量作为输入,然后算法给出这两个变量的对应模型错误率。通过穷举搜索,将所有可能的二叉树变量个数和决策树数量2个变量带入随机森林算法,并带入输入指标,从而获得计算后的输出指标,随机森林算法自动将其与实际的输出指标进行比较计算,从而给出不同的二叉树变量个数和决策树数量的模型错误率,然后选取能使对应模型错误率最低的二叉树变量个数和决策树数量。
[0036]
穷举搜索可以采用r语言代码自动检索,也可以根据每一个结果,人工检索。其中,r语言代码自动检索利用循环语句,将所有可能的二叉树变量个数和决策树数量带入随机森林算法,得到所有可能的对应模型错误率,然后再选取最低值,这就是穷举搜索的过程。整个过程通过代码实现。目前流行的随机森林算法并不具备穷举搜索功能,使得结果片面化。
[0037]
s3:采用十折交叉验证和穷举搜索法,根据模型错误率,确定最优的终极二叉树变量个数、终极决策树数量和终极输入指标;根据十折交叉验证能得到输入指标数量与模型错误率的关系曲线,能提供一个终极输入指标数量的理论最优值,还需要后续的穷举搜索,不断运行随机森林算法,寻找实际的终极输入指标数量。
[0038]
按照inc node purity或inc mse参数,对全部输入指标进行排序,进行5
‑
10次十折交叉验证,采用穷举搜索法获得使模型错误率进一步降低的若干项筛选指标,将筛选指标作为对模型准确度具有较高贡献的输入指标;进一步降低是相对于初步预测模型的模型错误率而言的,即终极预测模型的预测精度要高于初步预测模型的精度,通常能提高5%至21%。
[0039]
s4:利用筛选出的输入指标、终极二叉树变量个数和终极决策树数量,运行随机森林算法构建各输出指标的终极预测模型;初步模型是终极模型构建的基础,为其提供初始参数值和计算环境。
[0040]
s5:根据各输出指标的终极预测模型所需的终极输入指标,测量同批次的待测幼苗的相应指标,输入所述终极预测模型,获得待测量幼苗的各项输出指标。
[0041]
实施例
[0042]
(1)试验材料与处理
[0043]
试验用种子于2019年秋季采自山西省浮山县三交村(35
°
57
′
53.64
″
n,112
°4′
35.76
″
e,海拔1197m),以单株间距50m以上、实生起源、生长旺盛、中龄林中的辽东栎(quercus liaotungensis koidz)作为母树。试验在日光温室中进行,昼夜环境温度(28
±
2)℃/(22
±
2)℃,空气湿度(40
±
15)%。
[0044]
将辽东栎种子于25℃湿藏催芽后,选取露白、单粒重量(2.7
±
0.4)g、无虫害的种子,按照表1的设置播种,每个容器播种1粒,覆盖基质0.5cm。
[0045]
试验期间视基质湿度,在展叶前浇灌纯净水,在展叶后每次浇水冲施质量浓度0.1%的水溶肥溶液(m
n
:m
p
:m
k
=1:1:1)。待幼苗生长至表1中设置的培育时间,选取成熟、完整、未被遮光的叶片,在同1片叶片上,依次测定相对叶绿素含量(spad)、快速叶绿素荧光和稳态叶绿素荧光,然后测定该株幼苗的形态指标和生物量,每项测定每株测定1次,共计测量76株。
[0046]
表1试验处理设置
[0047][0048]
[0049]
表1中,容器规格表示方式为容器直径*容器高度;基质组成为体积百分比。
[0050]
(2)测定指标对应的方法
[0051]
1)叶绿素含量测定
[0052]
采用叶绿素测定仪测定叶片叶肉部分的spad。
[0053]
2)快速叶绿素荧光测定
[0054]
暗适应待测叶片15min后,采用mini调制式叶绿素荧光仪,设置测量脉冲光强度900μmol〃m
‑
2〃s
‑
1(持续30μs),饱和光强度2000μmol〃m
‑
2〃s
‑
1,光化光强度300μmol〃m
‑
2〃s
‑
1。按照仪器内置的ojip测量程序测定叶肉部分,获得叶绿素荧光诱导动力学曲线。
[0055]
3)稳态叶绿素荧光测定
[0056]
暗适应待测叶片15min后,采用调制式叶绿素荧光成像仪,设置饱和光强度2300μmol〃m
‑
2〃s
‑
1,光化光强度300μmol〃m
‑
2〃s
‑
1,按照fluorcam7软件自带的荧光淬灭程序(version1.2.5.18),获得叶绿素荧光成像。
[0057]
4)表型指标和生物量测定
[0058]
采用叶面积测量仪测定每株幼苗的总叶面积(la),随后将植株完整挖出并洗净根系附着的基质,采用根系和叶面积分析系统,测定株高(h)和地径(d)。将各单株的叶、茎和根分开,分别置于105℃杀青30min,然后于75℃烘干至恒质量,测定叶生物量(lb)、茎生物量(sb)、根生物量(rb)和单株生物量(wb)。
[0059]
(3)数据处理
[0060]
1)快速叶绿素荧光指标计算
[0061]
依据获得的叶绿素荧光诱导动力学曲线,计算暗适应后照光150μs和300μs时的相对荧光强度vl和vk、psii单位面积有活性反应中心的数量rc/cs0、单位反应中心吸收的能量abs/rc、单位反应中心以热能形式耗散的能量di0/rc、单位反应中心捕获的用于还原qa的能量tr0/rc、单位反应中心用于将电子从q
‑
a传递到质体醌(pq)的能量et0/rc、单位反应中心用于将电子从q
‑
a传递到光系统i(psi)的能量re0/rc、psii被光激发后产生的电子传递至psii次级电子受体qa的概率φpo、psii捕获的电子从q
‑
a传递到pq的概率ψeo、电子从pqh2传递到psi最终受体侧的概率δro、叶片性能指数piabs、叶片总性能指数pitotal等参数。
[0062]
2)稳态叶绿素荧光指标计算
[0063]
稳态叶绿素荧光参数采用fluorcam7软件自动给出的观测区域平均值,包括各光诱导阶段(4个光适应阶段,1个光稳态阶段,3个暗弛豫阶段)的初始荧光产量f0,最大荧光产量fm,瞬时荧光强度ft,荧光强度变化量fv,感生荧光衰变效应初始阶段的荧光峰值fp,最大荧光产量与瞬时荧光强度的差值fq,最大量子产额qy,psii量子产率fv/fm,基于玉米黄质梯度模型的非光化学猝灭系数npq,基于跨膜质子梯度的非光化学猝灭系数qn,基于沼泽模型的光化学猝灭系数qp,基于湖泊模型的光化学猝灭ql,荧光衰减指数rfd。
[0064]
3)表型综合指标计算
[0065]
按照公式“比根长=根长/根生物量”计算反应苗木关合积累与根系总长度比重的比根长(srl);按照公式“根长比=根长/单株生物量”计算反应苗木移栽后对新环境适应能力的根长比(rlr);按照公式“壮苗指数=[单株生物量/((地径/株高) (根生物量/(茎生物量 叶生物量))]”计算壮苗指数(dqi)。
[0066]
4)随机森林回归分析
[0067]
上述计算得到的指标和生物量构成数据集,将数据集的80%作为训练集,20%作为测试集,首先绘制所有二叉树变量个数(mtry)的模型错误率与决策树数量(ntree)的关系曲线,穷举搜索使模型错误率最低的二叉树变量个数,再依据关系曲线,筛选使模型错误率最低的决策树数量,初步构建预测模型。之后按照inc node purity或inc mse参数,对全部预测指标进行排序,进行5次十折交叉验证,穷举搜索使模型错误率进一步降低的若干项指标,作为对模型准确度具有较高贡献的预测指标。最后利用筛选出的预测指标,构建最终预测模型。
[0068]
(4)结果
[0069]
随机森林算法表明,单株生物量wb、根长比rlr、总叶面积la、茎生物量sb、根生物量rb、壮苗指数dqi、叶生物量lb、比根长srl的预测模型准确度分别达到91%、85.1%、88.6%、87.9%、87.7%、86.9%、85.4%、90.4%,统计图如图1所示,横坐标表示准确度,纵坐标表示各预测指标。对预测准确度超过85%的模型的训练集和预测集分析,获得如图2所示的各响应指标的预测值与实测值示意图,表明各响应指标的预测值与实测值差距较小,模型具备较高的稳定性,其中空心白点表示训练集数据,黑点表示预测集数据。
[0070]
本发明采用的快速叶绿素荧光诱导动力学和稳态荧光成像技术具备快捷、非损伤的特点,如果将该项技术实现机械自动化检测,可以大幅度提高检测效率。在预测算法方面,本发明采用属于机器学习类别的随机森林算法,辅之以十折交叉验证和穷举搜索,与常规的线性回归、线性混合模型、偏最小二乘回归等算法相比,模型的精确度和稳定性均较高。关于模型的预测准确度,对根生物量和单株生物量的预测准确度分别为87.7%和91.0%,预测精度较高。本发明也可与自动化叶绿素荧光成像表型分析系统联动,实现对幼苗表型指标与生物量的高通量预测;也可以与遥感技术联用,能将预测对象从单株扩展至群体。
[0071]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0072]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。