1.本发明涉及一种基于目标检测模型的超时劳动判别方法,属于计算机视觉技术领域。
背景技术:
2.在生产车间、特殊场所的视频监控场景下,面临图像方向多变、光照多变、目标物体遮挡、远近距离分布不确定等因素,使得该场景下的目标检测精度不太高,不能较好的满足工程实际需求。视频画面字幕识别是图像字符识别技术的推广应用,传统基于规则的固定区域的字符识别存在漏检率、误识别高等问题,且不能完全自动化实现业务需求。
3.近年来随着深度学习在计算机视觉领域的广泛应用,基于深度学习的目标检测识别模型极大提高了目标检测的精度和识别效果。为了有效提升视频监控场景下的小目标、多目标检测及图像字幕识别性能,基于深度学习,利用迁移学习的思想,训练视频目标检测模型、视频帧图像字幕识别模型并应用于生产车间、劳动场所等情形下的超时劳动识别,其精度和速度均满足基本业务需求。
技术实现要素:
4.为解决上述技术问题,本发明提供了一种基于目标检测模型的超时劳动判别方法,该基于目标检测模型的超时劳动判别方法主要使用基于深度学习的目标检测模型并结合规范制度综合判别超时劳动的异常行为。
5.本发明通过以下技术方案得以实现。
6.本发明提供的一种基于目标检测模型的超时劳动判别方法,包括以下步骤:
7.视频数据预处理:对输入的待识别视频数据进行采样并作图像增强、缩放;
8.视频目标检测与识别:利用迁移学习方法调整基于深度卷积神经网络的目标检测模型,用调整后的目标检测模型对预处理后视频数据中的人及人头目标进行快速检测,同时采用图像文本检测与识别算法训练用于识别视频帧画面中时间水印的图像ocr算法模型;
9.超时劳动判别及结果处理:基于视频帧画面中检测到的目标及时间水印,与设定的工作起止时间进行对比,判别是否超过规定工作结束时间的阈值,从而判断是否发生超时劳动的现象,如果是则截取对应时间段的视频片段并保存到异常视频库,否则返回视频预处理环节继续处理直到处理完毕。
10.视频数据预处理具体分为以下步骤:
11.①
输入视频及工作起止时间:输入待识别监控视频数据作为处理对象,同时传入规定的工作起止时间作为判别超时劳动的参照标准;
12.②
视频数据预处理:利用下采样的方式,按设定的间隔帧率采样视频帧,同时对采样视频帧进行图像增强、尺度变换的预处理操作。
13.视频目标检测与识别具体分为以下步骤:
14.③
采样视频帧目标检测:在大规模图像分类数据集上,基于yolo 系列算法进行预训练,获取目标检测模型,再使用人头数据集调整目标检测模型,使得目标检测模型能够同时检测视频帧画面中的人及人头目标;
15.④
识别采样视频帧时间水印:基于公开中英文数据集,通过east 文本检测算法和crnn文本识别算法共同实现对视频帧画面中时间水印的识别。
16.超时劳动判别及结果处理具体分为以下步骤:
17.⑤
判别是否超时劳动:统计视频帧画面中的人及人头目标数,根据画面时间与工作起止时间的对比结果并结合目标检测结果综合判别是否超时劳动;
18.⑥
判别结果处理:如果发生超时劳动,则截取该时刻起的视频至指定时间段或者视频结束,同时保存至异常视频库,否则返回步骤
②
继续处理视频直到处理完毕。
19.所述步骤
①
中,将输入待识别监控视频数据作为处理对象,同时工作起止时间为满足正常工作时间规定的预设值,记为[t
s
,t
f
],另记晚于t
f
时间的分钟数为t
c
,共同作为判别超时劳动的参照标准。
[0020]
所述步骤
②
中,视频数据预处理分为以下步骤:
[0021]
(2.1)视频帧降采样;
[0022]
(2.2)视频帧图像增强;
[0023]
(2.3)视频帧图像尺度变换。
[0024]
所述步骤
③
中,利用目标检测模型检测采样视频帧画面中的人及人头目标,具体步骤如下:
[0025]
(3.1)在coco图像数据集上,基于yolo系列算法进行训练,获取目标检测模型;
[0026]
(3.2)利用迁移学习思想,基于目标检测模型,在brainwash、nwpu
‑
crowd混合数据集上进行调整,获取人头检测模型;
[0027]
(3.3)输入采样视频帧图像,使用人头检测模型检测该视频帧画面中的人及人头目标,并将非空结果存入数组r。
[0028]
所述步骤
④
中,识别采样视频帧画面中的时间水印,具体步骤如下:
[0029]
(4.1)在公开中英文数据集上训练基于resnet50_vd骨干网络的 east文本检测算法,提取视频帧画面中的时间水印roi图;
[0030]
(4.2)同时,训练基于resnet34_vd骨干网络的crnn文本识别算法,识别步骤(4.1)中提取到的roi图中的字幕;
[0031]
(4.3)采用规则匹配的方式,从步骤(4.2)识别出的字幕中提取日期、时间,并转换为标准的日期时间格式,从而得到该视频帧画面中的时间水印,记为t
p
。
[0032]
所述步骤
⑤
中,判别是否超时劳动,分为以下步骤:
[0033]
(5.1)计算预先设定的工作起止时间的结束时间t
f
与当前识别到的画面时间t
p
的差,记为t0,其计算公式为t0=t
p
‑
t
f
;
[0034]
(5.2)当t0大于零但小于设定阈值t
c
时,或者t0小于零时,则忽略该视频帧,判别为否,置标志位rf为false;
[0035]
(5.3)反之,当t0大于零且大于设定阈值t
c
时,若步骤(3.3)的检测结果r非空,则将当前视频帧画面时间t
p
存入数组s,判别为是,置标志位rf为true,否则判别为否,置标志位rf为false。
[0036]
所述步骤
⑥
中,判别结果处理环节,分为以下步骤:
[0037]
(6.1)根据步骤
⑤
的判别结果,若rf为true,则保存当前视频帧,并进行下一视频帧处理,否则直接进行下一视频帧处理;
[0038]
(6.2)判断当前视频是否为最后一帧,若是,则表示处理完视频,保存所有结果并退出,否则继续处理视频数据直至处理完毕。
[0039]
本发明的有益效果在于:可以快速检测出监控视频场景下的小目标,并能实现对生产车间超过规定劳动时长的自动判别,从而为智慧车间等领域提供智能化的解决措施。
附图说明
[0040]
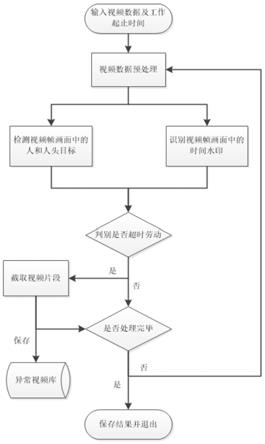
图1是本发明方法的流程图。
具体实施方式
[0041]
下面进一步描述本发明的技术方案,但要求保护的范围并不局限于所述。
[0042]
实施列1
[0043]
如图1所示的一种基于目标检测模型的超时劳动判别方法,包括如下主要过程:
[0044]
视频数据预处理:对输入的待识别视频数据进行采样并作图像增强、缩放等预处理;
[0045]
视频目标检测与识别:利用迁移学习方法微调基于深度卷积神经网络的目标检测模型实现对人及人头目标的快速检测,同时采用图像文本检测与识别算法训练图像ocr算法模型用于识别视频帧画面中的时间水印;
[0046]
超时劳动判别及结果处理:基于视频帧画面中检测到的目标及时间水印并与设定的工作起止时间进行对比,判别是否超过规定工作结束时间的阈值从而判断是否发生超时劳动的现象,如果是则截取对应时间段的视频片段并保存到异常视频库,否则返回视频预处理环节继续处理直到处理完毕。
[0047]
具体的,包括以下步骤:
[0048]
①
输入视频及工作起止时间:传入待识别监控视频数据作为处理对象,其格式应为mp4或avi等,同时传入规定的工作起止时间作为判别超时劳动的参照标准;
[0049]
②
视频数据预处理:传入的原始视频数据因格式、帧率等的不同会存在大量冗余视频帧,利用下采样的方式按设定的间隔帧率采样视频帧,以减少处理量,同时对采样视频帧进行图像增强、尺度变换等预处理操作;
[0050]
③
采样视频帧目标检测:利用迁移学习思想,在大规模图像分类数据集上基于yolo系列进行预训练得到目标检测模型,再使用人头数据集微调检测模型,使得目标检测模型能够同时检测视频帧画面中的人及人头目标;
[0051]
④
识别采样视频帧时间水印:基于公开中英文数据集,采用基于 resnet50_vd骨干网络的east文本检测算法,同时采用基于 resnet34_vd骨干网络的crnn文本识别算法共同实现对视频帧画面中时间水印的识别;
[0052]
⑤
判别是否超时劳动:统计视频帧画面中的人及人头目标数,根据画面时间与工作起止时间的对比结果并结合目标检测结果综合判别是否超时劳动;
[0053]
⑥
判别结果处理:如果发生超时劳动,则截取该时刻起的视频至指定时间段或者
视频结束,同时保存至异常视频库,否则返回步骤
②
继续处理视频直到处理完毕。
[0054]
其中,将输入监控视频数据作为本方法的处理对象,同时工作起止时间为满足正常工作时间规定的预设值,记为[t
s
,t
f
],另记晚于t
f
时间的分钟数为t
c
,共同作为判别超时劳动的参照标准。
[0055]
其中,视频数据预处理具体包括:
[0056]
(2.1)视频帧降采样,以减少处理量;
[0057]
(2.2)视频帧图像增强,以提升图像对比度;
[0058]
(2.3)视频帧图像尺度变换,以适配深度学习检测模型。
[0059]
其中,利用目标检测模型检测采样视频帧画面中的人及人头目标,具体步骤包括:
[0060]
(3.1)在coco图像数据集上基于yolo系列算法进行训练得到目标检测模型;
[0061]
(3.2)利用迁移学习思想,基于(3.1)的预训练模型,在 brainwash、nwpu
‑
crowd混合数据集上微调得到人头检测模型;
[0062]
(3.3)输入采样视频帧图像,使用上述检测模型进行推理,检测该视频帧画面中的人及人头目标,并将非空结果存入数组r。
[0063]
其中,识别采样视频帧画面中的时间水印,具体步骤包括:
[0064]
(4.1)在公开中英文数据集上训练基于resnet50_vd骨干网络的 east文本检测算法,提取视频帧画面中的时间水印roi图;
[0065]
(4.2)同时,训练基于resnet34_vd骨干网络的crnn文本识别算法,识别步骤(4.1)提取到的roi图中的字幕;
[0066]
(4.3)采用规则匹配的方式,从步骤(4.2)识别出的字幕中提取日期时间并转换为标准的日期时间格式,从而得到该视频帧画面中的时间水印,记为t
p
。
[0067]
其中,判别是否超时劳动,分为以下步骤:
[0068]
(5.1)计算预先设定的工作起止时间的结束时间t
f
与当前识别到的画面时间t
p
的差,记为t0,其计算公式为t0=t
p
‑
t
f
;
[0069]
(5.2)当t0大于零但小于设定阈值t
c
时,或者t0小于零时,则忽略该视频帧,判别为否,置标志位rf为false;
[0070]
(5.3)反之,当t0大于零且大于设定阈值t
c
时,若步骤(3.3)的检测结果r非空,则将当前视频帧画面时间t
p
存入数组s,判别为是,置标志位rf为true,否则判别为否,置标志位rf为false。
[0071]
其中,所述步骤
⑥
判别结果处理环节,分为以下步骤:
[0072]
(6.1)根据步骤
⑤
的判别结果,若rf为true,则保存当前视频帧,并进行下一视频帧处理;否则直接进行下一视频帧处理;
[0073]
(6.2)判断当前视频是否为最后一帧,若是,则表示处理完视频,保存所有结果并退出,否则继续处理视频数据直至处理完毕。
[0074]
实施例2
[0075]
如图1所示,一种基于目标检测模型的超时劳动判别方法,首先输入待识别的监控视频及工作起止时间,然后对视频进行间隔视频帧率的方式降采样并作图像增强、尺度变换等预处理操作,进而基于训练好的目标检测模型检测视频帧图像中的人及人头目标,同时识别该视频帧画面中的时间水印获得当前视频帧时间,最后结合是否超时劳动的判别规
则进行判别,最后对超时劳动情形进行视频截取并保存到异常视频库直至处理完视频。
[0076]
具体包括以下步骤:
[0077]
(1)输入视频及工作起止时间:
[0078]
输入监控视频数据作为本方法的处理对象,其格式应为.mp4 或.avi等;
[0079]
同时传入规定的工作起止时间记为[t
s
,t
f
],另记晚于t
f
时间的分钟数为t
c
,共同作为判别超时劳动的参照标准。
[0080]
(2)视频数据预处理:
[0081]
输入的原始视频数据存在数据冗余、光照、尺寸不统一等因素,需要先作如预处理操作:
[0082]
步骤2.1,视频帧降采样,以减少处理量;
[0083]
步骤2.2,视频帧图像增强,以提升图像对比度;
[0084]
步骤2.3,视频帧图像尺度变换,以更好训练深度学习检测模型。
[0085]
(3)采样视频帧目标检测:
[0086]
利用目标检测模型检测采样视频帧画面中的人及人头目标,具体步骤包括:
[0087]
步骤3.1,在coco图像数据集上基于yolo系列算法进行训练得到目标检测模型;
[0088]
步骤3.2,利用迁移学习思想,基于步骤3.1的预训练模型,在 brainwash、nwpu
‑
crowd混合数据集上微调得到人头检测模型;
[0089]
步骤3.3,输入采用视频帧图像,使用上述检测模型进行推理,检测该视频帧画面中的人及人头目标,并将非空结果存入数组r。
[0090]
(4)识别采样视频帧时间水印:
[0091]
识别视频帧画面中的时间水印,具体步骤包括:
[0092]
步骤4.1,在公开中英文数据集上训练基于resnet50_vd骨干网络的east文本检测算法,提取视频帧画面中的时间水印roi图;
[0093]
步骤4.2,同时,训练基于resnet34_vd骨干网络的crnn文本识别算法,识别步骤4.1提取到的roi图中的字幕;
[0094]
步骤4.3,采用规则匹配的方式,从步骤4.2识别出的字幕中提取日期时间并转换为标准的日期时间格式,从而得到该视频帧画面中的时间水印,记为t
p
。
[0095]
(5)判别是否超时劳动:
[0096]
判别是否超时劳动,分为以下步骤:
[0097]
步骤5.1,计算预先设定的工作起止时间的结束时间t
f
与当前识别到的画面时间t
p
的差,记为t0,其计算公式为t0=t
p
‑
t
f
;
[0098]
步骤5.2,当t0大于零但小于设定阈值t
c
时,或者t0小于零时,则忽略该视频帧,判别为否,置标志位rf为false;
[0099]
步骤5.3,反之,当t0大于零且大于设定阈值t
c
时,若步骤3.3的检测结果r非空,则将当前视频帧画面时间t
p
存入数组s,判别为是,置标志位rf为true,否则判别为否,置标志位rf为false。
[0100]
(6)判别结果处理:
[0101]
判别结果处理环节,分为以下步骤:
[0102]
步骤6.1,根据步骤5的判别结果,若rf为true,则保存当前视频帧,并进行下一视
频帧处理;否则直接进行下一视频帧处理;
[0103]
步骤6.2,判断当前视频是否为最后一帧,若是,则表示处理完视频,保存所有结果并退出,否则继续处理视频数据直至处理完毕。
[0104]
综上所述,本发明针对车间等特殊场所的小目标、遮挡等问题,基于迁移学习是思想,通过采用训练基于深度卷积神经网络的目标检测模型实现对上述场景下监控视频中的目标检测,从而得到基于目标检测模型的超时劳动判别方法。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。