技术特征:
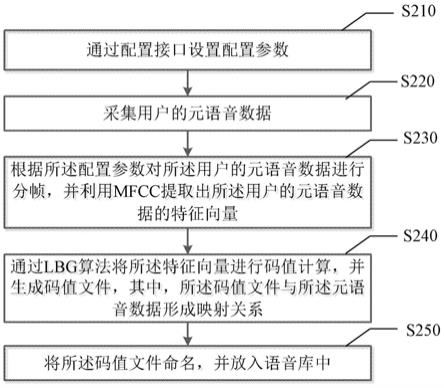
1.一种基于用户的语音库构建方法,其特征在于,包括以下步骤:通过配置接口设置配置参数;采集用户的元语音数据;根据所述配置参数对所述用户的元语音数据进行分帧,并利用mfcc提取出所述用户的元语音数据的特征向量;通过lbg算法将所述特征向量进行码值计算,并生成码值文件,其中,所述码值文件与所述元语音数据形成映射关系;以及将所述码值文件命名,并放入语音库中。2.根据权利要求1所述的语音库构建方法,其特征在于,所述配置参数包括:录音参数,所述录音参数用于在采集用户的元语音数据的过程中对采集的频率和采集的位数进行设置;解析参数,所述解析参数用于在采集用户的元语音数据的过程中对每帧长度和相邻两帧的间隔长度进行设置;以及分词参数,所述分词参数用于:根据用户的语速,设置用户的单位元语音的长度。3.根据权利要求1所述的语音库构建方法,其特征在于,在对所述用户的元语音数据进行分帧之前或之后,对所述用户的元语音数据进行端点检测。4.根据权利要求1所述的语音库构建方法,其特征在于,利用mfcc提取出所述用户的元语音数据的特征向量,包括对所述用户的元语音数据:加窗、预加重、fft变换和梅尔频率系数计算。5.根据权利要求1所述的语音库构建方法,其特征在于,在将所述码值文件放入语音库之前,校验所述码值文件的命名和格式,当校验成功时,将所述码值文件放入所述语音库;以及当校验失败时,重新设置所述码值文件的命名和格式。6.根据权利要求2所述的语音库构建方法,其特征在于,所述语音库中包括多个子语音库,多个所述子语音库根据字数或/和采样的位数进行划分,所述码值文件根据生成前的字数或/和采样的位数放入对应的子语音库中,其中,字数通过采集的位数和用户的单位元语音的长度获得。7.一种语音识别的方法,其特征在于,所述的方法基于权利要求1
‑
6中任意一项所述的语音库,所述识别方法包括以下步骤:通过配置接口设置配置参数;采集用户的元语音数据;结合所述配置参数,对所述用户的元语音数据进行分词处理,得到多段不同长度的子元语音数据;利用matlab对每段所述子元语音数据进行端点检测;根据端点检测结果,计算每段所述子元语音数据的码值;以及采用欧拉距离算法,将每段所述子元语音数据以及其对应的码值与所述语音库内的码值文件逐个进行匹配。8.根据权利要求7所述的方法,其特征在于,所述配置参数包括:录音参数,所述录音参数用于在采集用户的元语音数据的过程中对采集的频率和采集
的位数进行设置;解析参数,所述解析参数用于在采集用户的元语音数据的过程中对每帧长度和相邻两帧的间隔长度进行设置;分词参数,所述分词参数用于:根据用户的语速,设置用户的单位元语音的长度;以及匹配参数,所述匹配参数用于对每段所述子元语音数据的端点检测,其中,所述匹配参数包括:能量上限、能量下限、过零率上限、过零率下限、最长持续静默时间和最短语音长度。9.根据权利要求8所述的方法,其特征在于,利用matlab对每段所述子元语音数据进行端点检测,包括:利用matlab计算出每段所述子元语音数据的短时平均过零率和短时能量,将所述短时能量和所述短时平均过零率分别与所述匹配参数作比较,得到每段所述子元语音数据的端点。10.根据权利要求9所述的方法,其特征在于,得到每段所述子元语音数据的端点包括:从每段所述子元语音数据的起点向后搜索元语音信号;当满足所述短时能量大于能量上限且所述短时平均过零率也大于过零率上限时,所述端点为确信进入语音端;当满足所述短时能量大于能量上限或所述短时平均过零率大于过零率上限中的一个条件时,所述端点为可能进入语音端;从每段所述子元语音数据的终点向前搜索元语音信号;以及当满足所述短时能量小于能量下限且所述短时平均过零率也小于过零率下限时,所述端点为确信结束语音端;当满足所述短时能量小于能量下限或所述短时平均过零率小于过零率小限中的一个条件时,所述端点为可能结束语音端。11.根据权利要求10所述的方法,其特征在于,结合所述子元语音数据的确信进入语音端和确信结束语音端,当所述确信进入语音端到所述确信结束语音端的持续语音长度小于最短语音长度时,剔除所述子元语音数据。12.根据权利要求8所述的方法,其特征在于,采用欧拉距离算法,将每段所述子元语音数据以及其对应的码值与所述语音库内的码值文件逐个进行匹配,包括;根据用户的单位元语音的长度和子元语音数据,计算出每段所述子元语音数据的字数,根据字数匹配语音库内对应的子语音库,在所述对应的子语音库内,逐个匹配所述子元语音数据对应的码值。13.根据权利要求12所述的方法,其特征在于,在采用欧拉距离算法,将每段所述子元语音数据以及其对应的码值与所述语音库内的码值文件逐个进行匹配之前,设置欧拉距离的上临界值和下临界值。14.根据权利要求13所述的方法,其特征在于,在匹配过程中,当所述子元语音数据的码值与所述子语音库内的码值文件的码值做比较的结果大于上临界值时,匹配失败并将所述子元语音数据的码值与下一个码值文件做比较;当所述子元语音数据的码值与所述子语音库内的码值文件的码值做比较的结果小于下临界值时,匹配成功并输出结果;以及当所述子元语音数据的码值与所述子语音库内的码值文件的码值做比较的结果在上临界值与下临界值之间时,存入结果集合并将所述子元语音数据的码值与下一个码值文件
做比较。15.根据权利要求14所述的方法,其特征在于,当所述子元语音数据的码值与所述子语音库内的码值文件的码值做比较的结果大于上临界值时,匹配失败并将所述子元语音数据的码值与下一个码值文件做比较,包括:当所述子语音库内的码值文件均匹配失败时,扩展至与所述子语音库相邻的子语音库,并重新匹配。16.根据权利要求15所述的方法,其特征在于,当所述子语音库内的码值文件均匹配失败时,扩展至与所述子语音库相邻的子语音库,并重新匹配,包括:在所述子元语音数据的码值与所述语音库内的码值文件均匹配失败时,确认所述语音库内是否存在所述用户的元语音数据对应的所述码值文件,当存在时,执行第一操作,其中,所述第一操作包括:删除所述语音库内无误的所述码值文件;以及调整所述配置参数,并重新采集用户的元语音数据,输出新码值文件;当不存在时,执行第二操作,所述第二操作包括:采集用户的元语音数据并输出码值文件。17.根据权利要求14所述的方法,其特征在于,当所述子元语音数据的码值与所述子语音库内的码值文件的码值做比较的结果在上临界值与下临界值之间时,存入结果集合并将所述子元语音数据的码值与下一个码值文件做比较,包括:查看所述结果集合内的码值文件,取欧拉距离最小的值作为输出结果。18.根据权利要求16所述的方法,其特征在于,还包括:查看匹配结果,在匹配结果有误时,确认所述语音库内是否存在无误的所述用户的元语音数据对应的所述码值文件,当存在时,执行第一操作;当不存在时,执行第二操作。19.一种语音库的构建系统,包括ui层、分析层以及文件读写层,其特征在于,在所述ui层内,包括:参数配置模块,所述参数配置模块用于通过配置接口设置配置参数;录音模块,所述录音模块用于采集用户的元语音数据;在所述分析层内,包括:特征提取模块,所述特征提取模块用于:根据所述配置参数对所述用户的元语音数据进行分帧,并利用mfcc提取出所述用户的元语音数据的特征向量;码值计算模块,所述码值计算模块用于:通过lbg算法将所述特征向量进行码值计算,并生成码值文件,其中,所述码值文件与所述元语音数据形成映射关系;在所述文件读写层,包括:入库模块,所述入库模块用于将所述码值文件命名,并放入语音库中。20.根据权利要求19所述的构建系统,其特征在于,在分析层还包括:端点检测模块,所述端点检测模块用于:在对所述用户的元语音数据进行分帧之前或之后,对所述用户的元语音数据进行端点检测;在所述文件读写层还包括:校验模块,所述校验模块用于:在将所述码值文件放入语音
库之前,校验所述码值文件的命名和格式,当校验成功时,将所述码值文件放入所述语音库;以及当校验失败时,重新设置所述码值文件的命名和格式。21.一种语音识别系统,包括ui层、分析层以及文件读写层,其特征在于,在所述ui层内,包括:参数配置模块,所述参数配置模块用于通过配置接口设置配置参数;录音模块,所述录音模块用于采集用户的元语音数据;在所述分析层内,包括:分词模块,所述分词模块用于:结合所述配置参数,对所述用户的元语音数据进行分词处理,得到多段不同长度的子元语音数据;端点检测模块,所述端点检测模块用于:利用matlab对每段所述子元语音数据进行端点检测;码值计算模块,所述码值计算模块用于根据端点检测结果,计算每段所述子元语音数据的码值;在所述文件读写层,包括:检索模块,所述检索模块用于采用欧拉距离算法,将每段所述子元语音数据以及其对应的码值与所述语音库内的码值文件逐个进行匹配。22.根据权利要求21所述的系统,其特征在于,在文件读写层还包括读取模块,所述读取模块用于查看匹配结果。23.一种电子设备,包括:一个或多个处理器;存储装置,用于存储一个或多个程序,其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器执行根据权利要求1
‑
18中任一项所述的方法。24.一种计算机可读存储介质,其上存储有可执行指令,该指令被处理器执行时使处理器执行根据权利要求1
‑
18中任一项所述的方法。25.一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现根据权利要求1
‑
18中任一项所述的方法。
技术总结
本申请提供了一种基于用户的语音库构建方法,可以应用于人工智能技术领域。所述构建方法包括:通过配置接口设置配置参数;采集用户的元语音数据;根据所述配置参数对所述用户的元语音数据进行分帧,并利用MFCC提取出所述用户的元语音数据的特征向量;通过LBG算法将所述特征向量进行码值计算,并生成码值文件,其中,所述码值文件与所述元语音数据形成映射关系;以及将所述码值文件命名,并放入语音库中。根据本申请的语音库构建方法,针对个人的语音习惯、词语使用范围进行设计,可脱离网络使用,满足区域隔离网络内监控中心语音识别的需要,有效识别个人方言,在一定程度上克服了现有技术中对网络依赖、语音库过大、个人语言识别困难的问题。识别困难的问题。识别困难的问题。
技术研发人员:高天峰
受保护的技术使用者:中国工商银行股份有限公司
技术研发日:2021.08.06
技术公布日:2021/11/4
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。