1.本发明属于知识图谱技术领域,具体涉及一种基于深度学习的食品及健康知识图谱构建方法。
背景技术:
2.食品安全是一个非常重要,同时又非常复杂的领域。现有大量的面向食品安全方面的标准文件,但其数量庞大、覆盖面广、内容繁复,很难人工统一处理。所以引入知识图谱可以帮助人们更加精确化的分析食品安全问题,比如各种食品中的添加剂限量,限量超标会引发什么症状、疾病及其治疗信息等与食品安全息息相关的数据。
3.知识图谱(knowledge graph,kg)最早是作为语义网络(semantic web)研究内容之一出现的。国内外的知识库、知识图谱产品层出不穷,在许多领域都存在专有知识库并且构建了领域知识图谱,但是在农业与食品安全方面的专有知识库非常稀少,且国内尚无食品统一国家编码;2018年国外统一的食品本体库foodon发布,但由于本体在语言翻译过程中产生的不确定性,加上我国食品文化博大精深,具有浓厚的地理特色等原因,foodon很难直接作为国内基于食品安全的知识图谱构建的知识库;所以构建知识图谱的数据需要从大量标准文件以及网络数据中提取。由于缺少足够的标注数据,对于非关系型数据无法进行自动提取。在手动标注足够数据后,基于bilstm
‑
crf模型实现了实体识别,基于神经网络的transformer模型实现了关系抽取。在知识表示中使用了rdf三元组和表示学习两种知识表示方式。在表示学习使用了transe、transr、transd和transh四种模型进行嵌入。知识存储主要分为基于rdf三元组的存储和基于图数据库的存储。知识推理使用基于图数据库的路径查询和基于知识图谱嵌入推理两种方式。问答方面通过编写问题模板以及对应的查询语句实现。
4.由于食品领域的知识十分复杂,甚至对应食品还没有统一的编号系统,在知识融合过程中存在较大难点,即使使用表示学习来进行实体聚类,也可能因为同一物质的不同名称的实体没有收集全而效果不佳。
5.基于图数据库的知识存储方式接近实际业务需求,但其结构因人为设计完成,所以查询检索等效率会收到数据库建模影响。特别在领域知识图谱构建中,在模式层的搭建上最好是由该领域专家完成,使得模式层更加科学、高效。
技术实现要素:
6.本发明要解决的技术问题是:提供一种基于深度学习的食品及健康知识图谱构建方法,用于高效查询食品安全数据和科学分析食品安全问题。
7.本发明为解决上述技术问题所采取的技术方案为:一种基于深度学习的食品及健康知识图谱构建方法,包括以下步骤:s1:从国家标准文件和网络提取源数据;
8.s2:对源数据抽取信息,包括通过python脚本分别抽取结构化数据和半结构化数据,对非结构化数据采取字符级别的手动标注,且基于手动标注数据形成数据集,实现包括
基于bilstm
‑
crf模型进行的实体识别和基于transformer模型进行的关系抽取;
9.s3:分类整理提取的数据内容,设计知识图谱概念层,数据库建模,包括统一的实体、关系类别以及对应的字段名称,将多源异构数据融合在同一个知识图谱中;
10.s4:选取四种kge模型transe、transh、transr、transd对(头实体,关系,尾实体)类型的三元组数据进行嵌入embedding,应用于实体相似度计算以及关系预测;
11.s5:设计问题模板,搭建问答系统,查询整合结果。
12.按上述方案,所述的步骤s1中,数据源是未三元组化的知识,包括食品类、农产品类、国家标准类、食品营养值类、食品添加剂类、农药类、兽药类、污染物类、疾病与症状类;食品类的实体属性包括食品名称和食品分类;农产品类的实体属性包括农产品名称和农产品分类;国家标准类的实体属性包括标准名称和标准内容;食品营养值类的实体属性包括营养名称和营养值;食品添加剂类的实体属性包括添加剂名称和添加剂值;农药类的实体属性包括农药名称、农药分类、农药限量值;兽药类的实体属性包括兽药名称、兽药分类、兽药限量值;污染物类的实体属性包括污染物名称和污染物限量值;疾病与症状类的实体属性包括疾病名称、症状名称、疾病就诊科室、治疗药物。
13.按上述方案,所述的步骤s2中,具体步骤为:
14.s21:通过bilstm
‑
crf模型进行实体识别,结合经典模型条件随机场crf与双向长短期记忆网络bilstm,通过命名实体识别ner提取文本中的包括专有名词和量词的事实信息;
15.s22:通过transformer模型进行关系抽取re,从文本中抽取实体与实体之间或者实体与属性之间的语义关系;对输入的句子和实体计算既定的每种关系对于该实体在句子中的可能性,取最高的可能性作为目标关系;
16.s23:将所有数据转换成rdf三元组形式的知识并保存为.csv格式。
17.进一步的,所述的步骤s22中,transformer模型采用多层注意力机制,包括encoder内部和decoder内部的多头自注意力模块,以及encoder和decoder之间的多头注意力模块;encoder和decoder分别包括自注意力机制,decoder在自注意力机制的基础上加入encoder的反馈信息形成多头自注意力机制;transformer模型用于使输入的句子和实体经过嵌入层转换成对应向量,依次经过encoder、decoder、分类器得到实体关系。
18.按上述方案,所述的步骤s3中,具体步骤为:
19.s31:采用嵌入embedding后的相似的向量对应的实体判断相似实体,将不同名称映射到同一实体上,解决同物异名的问题;
20.s32:在图数据库中为同名实体设置分类标签,解决同名异物的问题。
21.按上述方案,所述的步骤s3后,还包括以下步骤:通过图数据库存储方法存储基于rdf三元组的数据内容用于信息检索和查询;存储的rdf三元组包括(农产品,包含,农产品)、(食品,包含,食品)、(农药,包含,杀虫剂、杀菌剂、增效剂等)、(食品,含有,营养值、农药、添加剂等)、(农产品,含有,营养值、农药、添加剂等)、(食品、农产品,参考标准,国家标准)、(国家标准,检测项目,食品、农产品)、(国家标准,引用,国家标准)、(食品,限量,农药、添加剂、污染物、兽药)、(农产品,限量,农药、添加剂、污染物、兽药)、(食品,营养值,营养物质)、(疾病,症状,症状)、(食品,原料,食品、农产品)、(农产品,原料,食品、农产品)、(农药、添加剂等,导致,症状)、(疾病,治疗药物,药物)、(疾病,治疗方式,治疗方法)、(疾病,所属
科室,科室)、(疾病,疾病检查项,医疗检查项目);包含关系的关系内容为父子类关系,含有关系的关系内容为各种含有量或参考限量,参考标准关系的关系内容为参考标准和参考内容,检测项目关系的关系内容为某国标的检测项目,引用关系的关系内容为某国标引用某国标,限量关系的关系内容为具体限量值,营养值关系的关系内容为具体营养值,症状关系的关系内容为某疾病的症状,原料关系的关系内容为某食品、农产品的原料,导致关系的关系内容为某物质超标引发的症状,治疗药物关系的关系内容为某疾病的治疗药物,治疗方式关系的关系内容为某疾病的治疗方式,所属科室关系的关系内容为某基本所属科室,疾病检查项关系的关系内容为某疾病的医疗检查项目。
22.按上述方案,所述的步骤s4中,具体步骤为:
23.s41:设知识图谱为g=(e,r,t),其中所有实体的集合为e={e1,e2,...e
|e|
},实体的个数为|e|;所有关系的集合为r={r1,r2,...r
|r|
},关系的个数为|r|;三元组集合triplet为t=e
×
r
×
e;单个三元组为(h,r,t),其中三元组的头实体head为h,尾实体tail为t,头实体和尾实体的关系为r;嵌入embedding后的头实体向量为v
h
、关系向量为v
r
、尾实体向量为v
t
;v
h
、设正样本数据集合为:
24.p={(h,r,t)},
25.负样本数据集合为:
26.n={(h
′
,r,t)|h
′
≠h∧(h,r,t)∈p}∪{(h,r,t
′
)|t
′
≠t∧(h,r,t)∈p};
27.transe模型将三元组(h,r,t)的r看作h到t的平移,通过transe模型得到关系:
28.v
h
v
r
≈v
t
,
29.设transe模型的损失函数为:
[0030][0031]
v
h
v
r
与v
t
的l1或l2距离表示头实体 关系到尾实体的距离,距离越近越好;
[0032]
向transe模型添加负样本数据后的得分函数为:
[0033][0034]
其中:
[0035][0036]
transh模型将v
h
和v
t
投影在关系v
r
的超平面上,使投影后的向量满足transe模型的假设:
[0037]
对于三元组(h,r,t),定义w
r
为关系r所在超平面的与v
r
正交的法向量,把v
h
和v
t
投影在r所在的超平面得到和则:
[0038]
[0039][0040]
transh的损失函数为:
[0041][0042]
transh的得分函数与transe一致,为:
[0043][0044]
transr模型分别给实体和关系创建不同的语义空间,将实体翻译到关系所在的语义空间再计算得分;
[0045]
对三元组(h,r,t)的每一个关系创建翻译矩阵通过翻译矩阵m
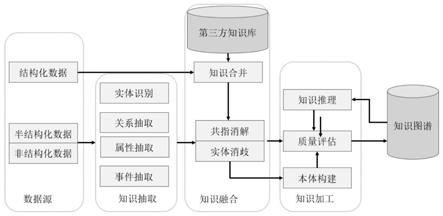
r
将v
h
和v
t
分别翻译在关系语义空间得到和
[0046][0047][0048]
transr模型的损失函数、得分函数均与transh模型一致;
[0049]
transd模型中设置翻译矩阵m
hr
和m
tr
分别用于将头实体h和尾实体t翻译至关系语义空间;设参数向量下标p表示该向量为参数向量;其中实体向量关系向量翻译矩阵则:
[0050][0051][0052]
将头实体和尾实体翻译后的向量记为和则:
[0053][0054][0055]
transd模型的损失函数和得分函数均与transr模型相同;
[0056]
s42:基于transr模型进行两两实体间的关系预测,在实验中采用预测关系的前两位作为结果计算准确度;
[0057]
s43:基于transr模型进行相似实体预测,使用嵌入embedding后的向量相似度预测实体相似度;采用被判断为相似的两个实体之间的公共路径条数作为判断相似实体预测结果的好坏指标。
[0058]
按上述方案,所述的步骤s5中,搭建问答系统的具体步骤为:
[0059]
s51:设变量x和cla为问题参数,根据收集到的数据类型设计问题模板包括:
[0060]
查询名叫x的食品含有哪些营养;
[0061]
查询名叫x的食品有什么食品添加剂;
[0062]
某查询名叫x的食品相关的国家标准;
[0063]
查询名叫x的国家标准中的抽检项目;
[0064]
查询name为x的节点;
[0065]
查询lable为x的节点;
[0066]
查询名叫x的食品、农产品中名叫cla的物质的最大残留量;
[0067]
查询名叫x节点的类别;
[0068]
查询名叫x的物质超量可能导致的症状和疾病;
[0069]
查询名叫x的疾病属于什么科室;
[0070]
查询名叫x的疾病的治疗药物;
[0071]
查询名叫x的疾病的治疗方法;
[0072]
查询名叫x的疾病的症状;
[0073]
查询名叫x的疾病的医疗检查项目;
[0074]
s52:采用jieba工具和自定义词典进行词性标注,提取问题参数;
[0075]
s53:对每个问题模板编写问题集,采用tfidf经典文本分类算法匹配问题模板;
[0076]
s54:通过py2neo工具封装cypher语句进行数据查询,通过python后台整合结果并返回。
[0077]
按上述方案,所述的步骤s5中,还包括搭建web端应用,具体步骤为:使用python flask框架搭建web系统,采用neovis实现图数据可视化部分,采用bootstrap美化前端框架;采用ajax完成前后端信息交互;实现包括实体识别、关系抽取、智能问答、固定类型查询、路径查询的功能。
[0078]
一种基于深度学习的食品及健康知识图谱,包括数据层和模式层;数据层采用rdf三元组和图数据存储数据源;模式层采用本体库对实体构造规则和约束。
[0079]
本发明的有益效果为:
[0080]
1.本发明的一种基于深度学习的食品及健康知识图谱构建方法,从信息抽取、知识表示、知识融合、知识存储、知识推理和知识图谱应用六个方面构建和应用面向食品安全领域的知识图谱,实现了高效查询食品安全数据和科学分析食品安全问题的功能。
[0081]
2.本发明在信息抽取阶段,基于手动标注数据集应用的深度学习方法有:基于bilstm
‑
crf模型实现了实体识别,基于transformer模型实现了关系抽取。
[0082]
3.本发明采用(实体,关系,实体)的三元组类型作为知识图谱表示学习的输入,通过表示学习将高维度的知识进行embedding,有效解决了数据稀疏性,提高了计算效率,可以应用到实体相似度计算以及关系预测。
附图说明
[0083]
图1是本发明实施例的领域知识图谱架构图。
[0084]
图2是本发明实施例的信息抽取流程图。
[0085]
图3是本发明实施例的实体识别的数据标注示例图。
[0086]
图4是本发明实施例的实体识别结果示例图。
[0087]
图5是本发明实施例的transformer模型架构图。
[0088]
图6是本发明实施例的关系抽取数据量图。
[0089]
图7是本发明实施例的关系抽取示例图。
[0090]
图8是本发明实施例的图数据库建模图。
[0091]
图9是本发明实施例的图数据库的可视化展示图。
[0092]
图10是本发明实施例的transe模型示例图。
[0093]
图11是本发明实施例的transh模型示例图。
[0094]
图12是本发明实施例的transr模型示例图。
[0095]
图13是本发明实施例的transd模式示例图。
[0096]
图14是本发明实施例的关系预测示例图。
[0097]
图15是本发明实施例的关系预测结果验证图。
[0098]
图16是本发明实施例的问答系统的流程图。
[0099]
图17是本发明实施例的问答演示示例图。
[0100]
图18是本发明实施例的web端菜单栏图。
[0101]
图19是本发明实施例的固定类型查询图。
[0102]
图20是本发明实施例的自然语言问题输入的问答系统示例图。
具体实施方式
[0103]
下面结合附图和具体实施方式对本发明作进一步详细的说明。
[0104]
本发明实施例的构建过程参见图1。
[0105]
1面向食品安全领域知识图谱的构建
[0106]
1.1领域知识图谱构建架构
[0107]
基于食品安全的知识图谱因其具有内容偏专业、数据要求严格且准确、更高的知识深度和更细的知识粒度等特点,属于领域知识图谱。
[0108]
在逻辑层面上,知识图谱分为数据层和模式层:数据层用来存储事实数据,通常是用rdf三元组方式和图数据进行存储;模式层用来对实体构造规则和约束,通常使用本体库来实现。
[0109]
领域知识图谱因对源数据(知识)在准确度上要求较高,需要花费大量人力检查处理知识,且也要求本体层相对完整,符合精确而深入的行业要求,所以在构建方法上采取自底向上和自顶向下相结合的方式进行构建。领域知识图谱的构建架构如图1所示。
[0110]
1.2源数据
[0111]
数据来源主要分为两部分:(1)国家标准文件中提取的数据。(2)网络上爬取的数据。收集来的数据中,大部分都为结构和半结构化数据,主要是具体限量值等数据;而物质超标引发症状这类数据多为非结构化数据。
[0112]
1.3信息抽取
[0113]
信息抽取按信息来源可以分为三类:对结构化数据进行抽取;对半结构化数据进行抽取;对非结构化数据进行抽取,如图2所示。
[0114]
结构化和半结构化数据通过编写python脚本提取;由于非结构化数据缺少训练集,无监督模型准确率太低,所以需要手动标注。最终所有数据都转换成三元组形式,存为.csv格式。
[0115]
经过整理、分类,现有数据9大类,如表1所示。
[0116]
表格1收集到的数据
[0117]
数据类别实体属性食品食品名称,分类等农产品农产品名称,分类等国家标准(gb)标准名称,标准内容等食品营养值营养名称,营养值食品添加剂添加剂名称,添加剂值农药农药名称,分类,限量值等兽药兽药名称,分类,限量值等污染物污染物名称,限量值等疾病与症状疾病名称,症状名称,疾病就诊科室,治疗药物等
[0118]
在手动标注数据后,基于全监督模型bilstm
‑
crf模型实现了实体识别,基于神经网络的全监督模型transformer实现了关系抽取。
[0119]
1.3.1基于bilstm
‑
crf模型的实体识别
[0120]
命名实体识别(named entity recognition,ner)目的是将文本中的专有名词、量词等事实信息提取出来,比如在句子“糖精钠是食品工业中常用的合成甜味剂”中提取出“糖精钠”和“甜味剂”两个实体。目前较为主流的命名实体识别采用的是基于深度学习的方法。基于bilstm
‑
crf的命名实体方法将中文命名实体识别看作序列标注问题,通过结合序列标注问题中的经典模型条件随机场(crf)与双向长短期记忆网络(bilstm)实现。
[0121]
在实际模型训练中,需要将非结构化数据进行字符级别的序列标注,如图3所示。
[0122]
如图4所示为实体识别结果的示例,bilstm
‑
crf模型的训练数据为:4000条句子作为训练集,1000条句子作为测试集,结果为:准确度(p):87.39%,召回率(r):87.69%,f1均值:0.8754。
[0123]
1.3.2基于transformer模型的关系抽取
[0124]
关系抽取(relation extraction,re)作为信息抽取的核心任务和重要环节,能够从文本中抽取实体与实体之间或者实体与属性之间的语义关系,比如句子“人在短期内若吸入大量氨气,会出现流泪等症状”通过关系抽取得到实体“氨气”与“流泪”含有“导致”这种关系。非结构化数据经过关系抽取后即可得到rdf三元组知识表示形式的知识。
[0125]
transformer模型架构图如图5所示,transformer模型与传统cnn模型不同的是其添加了多层注意力机制。多层注意力机制包含多头自注意力模块(encoder内部和decoder内部)及多头注意力模块(encoder和decoder之间)。具体来说,在encoder中含有自注意力机制,在decoder中在自注意力机制基础上加入encoder的反馈信息形成多头自注意力机制。整个流程先输入句子和实体,经过嵌入层转换成对应向量,最终由transformer网络加上分类器得到实体关系。transformer模型优点在于可以学习长距离的上下文特征,提高准确率;缺点在于训练参数过多,导致模型训练时间长。
[0126]
手动标注的数据中可作为关系抽取数据集的数据量如图6所示。
[0127]
在实际训练过程中,训练集有7006条,测试集有1785条,验证集有1605条,最终得到结果为正确率(acc):82.73%,精确率(p):79.09%,召回率(r):80.01%,f1均值:77.21%。
[0128]
如图7所示为关系抽取示例,输入句子和实体后能计算既定的每种关系对于该实体在句子中的可能性,取最高的即为目标关系。
[0129]
1.4知识表示
[0130]
本发明使用了基于rdf三元组和表示学习两种知识表示方式。基于rdf三元组的知识表示主要分为(头实体,关系,尾实体)和(实体,属性,属性值)两类。因本发明涉及的表示学习模型是基于头尾实体翻译假设的,所以只能对(头实体,关系,尾实体)这类数据进行表示学习。
[0131]
1.5知识融合
[0132]
知识融合是指将信息抽取过程中不同来源的异构数据进行融合,使得可以存在于同一个知识图谱中。
[0133]
本发明采取的知识融合方法是构建统一的概念层来进行知识融合。具体来说便是按提取的数据内容进行分类整理,最后设计统一的实体、关系类别以及对应的字段名称,系统方面对应的便是数据库设计,知识融合主要解决的有两个问题:共指消解和实体消歧。
[0134]
共指消解即是同物异名问题,这种问题在农产品、食品方面尤其显著,比如“红薯、白薯、番薯、山芋其实属于同一本体。番薯,山芋是这一本体东西的两种叫法。红薯,白薯是这一本体皮色不同的两个品种”。解决此问题的关键在于如何将不同名称映射到同一实体上,最简单的做法便是建立名称
‑
本体对应表,但在国内的农产品、食品领域甚至还未存在统一的编号,食品名称又附带地域特点,缺少标准且完整的数据支撑,很难建立完整的对应表。另一种办法便是利用表示学习,将embedding后的相似的向量所对应的实体来判断相似实体。
[0135]
实体消歧即同名异物问题,比如“苹果”是农产品,也是食品,甚至是一个公司名字,解决方法便是为同名实体打上分类标签,这在图数据库neo4j中可以较好实现。
[0136]
1.6知识存储
[0137]
本发明采取的存储方法主要是图数据库存储方法。基于rdf三元组的存储主要用于作为图数据库存储的前置数据以及表示学习的数据输入,图数据库存储方式主要用于信息检索、查询。
[0138]
依据信息抽取内容,关系设计如表2所示。
[0139]
表格2关系及其内容
[0140]
[0141][0142]
图数据库建模如图8所示。
[0143]
其中,图8中带“中间节点”的节点不是实体节点,设计中间节点是为了便于查询,可视化效果美观,同时防止图数据库中直接链接食品、农产品节点的节点过多,提高查询效率,也利于结果分类。
[0144]
所有数据全部导入neo4j,依据数据库统计显示,共有节点(实体节点加中间节点)52636个,关系239889条,属性532398个。知识在图数据库neo4j中存储的可视化展示如图9所示。
[0145]
2表示学习
[0146]
表示学习的价值在于能够量化语义信息,进而计算概念间和实体间的相似度,实现关系抽取、实体对齐和知识推理的效果。经freebase等知识库中的数据集验证,transe模型较之前的表示学习模型在性能上有着显著提升,并因其较少的参数和简洁的函数,在大规模知识图谱上的效率也十分可观。所以自transe之后的大量表示学习研究都是以transe为基础的翻译模型进行补充和改进的。
[0147]
本发明选取的kge模型为翻译模型中的transe、transh、transr和transd。
[0148]
在介绍模型之前,先定义几种后文需要用到的符号。知识图谱表示为g=(e,r,t),其中e={e1,e2,...e
|e|
}表示所有实体的集合,|e|是实体的个数;r={r1,r2,...r
|r|
}表示所有关系的集合,|r|是关系的个数;t=e
×
r
×
e代表三元组集合(triplet);单个三元组用(h,r,t)表示,其中h和t是三元组的头实体(head)和尾实体(tail),r表示头实体和尾实体的关系;embedding后的头实体向量、关系向量和尾实体向量分别记为v
h
、v
r
和v
t
,实体向量v
h
,关系向量定义p={(h,r,t)}为正样本数据集合,负样本数据集合定义为
[0149]
n={(h
′
,r,t)|h
′
≠h∧(h,r,t)∈p}∪{(h,r,t
′
)|t
′
≠t∧(h,r,t)∈p}
[0150]
即把正确三元组中的头尾实体进行替换即是负样本。
[0151]
2.1.1transe
[0152]
对于每个三元组(h,r,t)来说,bordes等人根据mikolov等人发现的语义平移现象,希望h和t在embedding后的低纬度空间中仍然保持与三元组(h,r,t)相同的语义关系。如图10所示,在transe中,对于三元组(h,r,t),transe将r看作是h到t的平移(或者叫翻译,translate embedding也由此命名)transe希望得到以下关系:
[0153]
v
h
v
r
≈v
t
[0154]
定义的损失函数如下:
[0155][0156]
即对于三元组(h,r,t)来说,v
h
v
r
与v
t
的l1或l2距离表示头实体 关系到尾实体的距离,距离越近越好。
[0157]
在实际的机器学习训练过程中,通常会添加负样本数据,对于transe来说,加入负样本的后的得分函数如下:
[0158][0159]
其中:
[0160][0161]
2.1.2transh
[0162]
为了解决transe模型在面对一对多、多对一、多对多关系时的问题,transh的解决方法是将v
h
和v
t
投影在关系v
r
的超平面上,使得投影之后的向量满足transe中的假设,如图11所示。具体内容如下:
[0163]
对于三元组(h,r,t),定义w
r
为关系r所在超平面的法向量,为了简单,一般选取与v
r
正交的法向量w
r
。把v
h
和v
t
投影在超平面后得到和通过w
r
很容易得到:
[0164][0165][0166]
transh的损失函数如下:
[0167][0168]
transh的得分函数与transe一致:
[0169][0170]
2.1.3transr
[0171]
transr认为,实体和关系使用同一语义空间是不合适的,理由如下:
[0172]
(1)从数据量上来说,在知识图谱中实体的数量|e|会远大于关系的数量|r|,而同一语义空间则意味着实体和关系使用了同一空间维度k。
[0173]
(2)从定义上来说,实体需要描述的是实体属性,而关系需要描述的是实体关系和关系属性。
[0174]
如图12所示,transr给实体和关系创建不同的语义空间,然后将实体翻译到关系所在的语义空间再计算得分。
[0175]
具体来说,对于三元组(h,r,t),先对每一个关系创建翻译矩阵利用翻译矩阵将v
h
和v
t
翻译在关系语义空间后得到和其中:
[0176][0177][0178]
transr的损失函数与得分函数均与transh一致。
[0179]
2.1.4transd
[0180]
为了解决以下问题:(1)翻译矩阵是由关系来确定的,和实体类型无关。(2)翻译矩阵大小为m
×
n,参数数量很大,学习过程中计算量很大。ji等人提出了一个transr的改进模型transd,如图13所示。
[0181]
具体来说,对于三元组(h,r,t),transd创建了两个翻译矩阵m
hr
和m
tr
分别用来将头实体h和尾实体t翻译至关系语义空间中。定义一些参数向量头实体h和尾实体t翻译至关系语义空间中。定义一些参数向量其中下标p代表该向量为参数向量,实体向量关系向量翻译矩阵其中:
[0182][0183][0184]
将头实体和尾实体翻译后的向量记为和则有:
[0185][0186][0187]
transd的损失函数和得分函数均与transr相同。
[0188]
因模型的定义是基于头尾实体平移(翻译)假设的,所以表示学习的输入三元组只能是(头实体,关系,尾实体)类型,而没有(实体,属性,属性值)这类三元组。所以在输入数据上需要整理出(头实体,关系,尾实体)这类三元组,经整理后,共有此类三元组约24万条,其中实体47915个,关系26种。
[0189]
2.2基于transr的关系预测
[0190]
关系预测也叫链接预测,是知识图谱补全的一部分。本发明基于transr嵌入模型实现了两两实体间的关系预测。如图14所示,在预测“油菜籽”与“甲基硫菌灵”的关系时,按照loss值排序后,前两个结果分别是“杀菌剂检测项目”与“农药检测项目”,如图15所示,在
图数据中验证后发现关系预测结果符合事实。
[0191]
在进行关系预测测试时,随机抽取了162个正三元组,然后通过以上方法进行验证,最终得到结果为:正确的关系出现在预测关系前两位中的概率为85.19%,其中选择在预测关系前两位中取结果原因是知识存在包含关系,比如在图15中,概率最大的两种预测关系分别是“杀菌剂检测项目”和“杀虫剂检测项目”,而杀菌剂是属于杀虫剂的,所以“油菜籽”和“甲基硫菌灵”的预测关系中“杀菌剂检测项目”和“杀虫剂检测项目”都是正确的。
[0192]
2.3基于transr的相似实体预测
[0193]
根据表示学习的特点,可以使用embedding后的向量相似度来预测实体相似度。因为表示学习输入的只有(实体,关系,实体),在图结果中即是节点与边,所以实际上是将知识图谱的图结构进行了表示学习。因此,对于相似实体判断结果,采用了被判断为相似的两个实体之间的公共路径条数来认定结果的好坏。作为测试,随机抽取了约1500个实体作为输入,通过基于transr模型的表示学习来计算与其相似的5个实体,然后在图数据库中通过cypher语句计算被判断相似的两个实体间的公共路径数量。
[0194]
经计算得出,结果中没有公共路径的比例为9.83%,即约9成结果是含有公共路径的,平均每个相似实体对含有公共路径1248条。
[0195]
3应用系统搭建
[0196]
3.1问答系统搭建
[0197]
本发明构建的知识图谱为领域知识图谱,覆盖面小但知识深度高,涉及的问题类型较少,但含有复杂问题,所以选用了基于问题模板的实现方法。
[0198]
问答系统的流程图如图16所示。
[0199]
问答系统主要需要设计问题模板,根据收集到的数据类型,编写了如下问题模板:
[0200]
(1)x含有哪些营养?(查询名叫x的食品含有哪些营养)。
[0201]
(2)x有什么食品添加剂?(查询名叫x的食品有什么食品添加剂)
[0202]
(3)x相关的国家标准?(某查询名叫x的食品相关的国家标准)
[0203]
(4)x中相关的抽检项目?(查询名叫x的国家标准中的抽检项目)
[0204]
(5)查询特定x的节点。(查询name为x的节点)
[0205]
(6)查询特定lable(类型)为x的节点(查询lable为x的节点)
[0206]
(7)x中某cla的最大残留量(最大值,规定值)是多少?(查询名叫x的食品、农产品中名叫cla的物质的最大残留量)
[0207]
(8)x属于某cla吗?x属于哪一cla?(查询名叫x节点的类别)
[0208]
(9)超量的x会导致什么症状,该症状可能是什么疾病?(查询名叫x的物质超量可能导致的症状和疾病)
[0209]
(10)x的治疗科室/看病科室是什么?(查询名叫x的疾病属于什么科室)
[0210]
(11)x的治疗药物是什么?(查询名叫x的疾病的治疗药物)
[0211]
(12)x的治疗方法有哪些?(查询名叫x的疾病的治疗方法)
[0212]
(13)x的症状有哪些?(查询名叫x的疾病的症状)
[0213]
(14)x的检查项目有哪些?(查询名叫x的疾病的医疗检查项目)
[0214]
其中x和cla等是变量,是问题参数,比如当x为“玉米”时,若匹配到第一个问题模板,则问题为“玉米含有哪些营养”,然后去数据库查询与玉米营养值有关的节点并整合内
容。
[0215]
提取问题参数过程使用了jieba工具外加自定义词典进行词性标注完成。
[0216]
匹配问题模板可以看成是文本分类问题,所以需要预先对每个问题模板编写尽可能多、全的问题集。由于人为编写问题集数量十分有限,所以没有采取复杂的文本分类算法,本发明选取的tfidf经典文本分类算法实现问题模板匹配。
[0217]
最后,通过python加上py2neo工具封装cypher语句外壳进行结果查询与整合。
[0218]
集成数据库查询的问答功能演示示例如图17所示。
[0219]
3.2web系统
[0220]
web系统使用python flask框架搭建,其中图数据可视化部分使用neo4j官方实验室产品neovis进行实现;前端使用bootstrap框架美化;前后端信息交互主要使用ajax完成。
[0221]
如图18所示,完成了实体识别、关系抽取、智能问答、固定类型查询和路径查询五类功能。
[0222]
图19所示为第8类问题的固定类型查询,查询的是“氯菊酯”超量可能引发的症状和疾病,在结果整合过程中,因为症状到疾病的路径过多,所以按照症状到路径链接的条数来对结果进行排序,并输出了数量最多的前10种疾病,表示最可能引发的疾病。
[0223]
图20为以自然语言问题输入的问答系统示例。
[0224]
以上实施例仅用于说明本发明的设计思想和特点,其目的在于使本领域内的技术人员能够了解本发明的内容并据以实施,本发明的保护范围不限于上述实施例。所以,凡依据本发明所揭示的原理、设计思路所作的等同变化或修饰,均在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。