1.本发明属于医学图像分割领域,更具体地,涉及一种无监督领域自适应图像分割方法及系统。
背景技术:
2.医学图像分割是将医学图像中医生感兴趣的区域从图像中提取出来,在临床的术前规划、术中导航和术后评估中都有很重要的应用价值。传统的分割方法比如基于阈值的分割、基于区域生长的分割和基于可变形模型的分割等方法在自动性、准确性和分割速度上都不能达到令人满意的效果。
3.近年来,随着深度学习在图像处理领域的长足发展,其在医学图像领域的突出表现也逐渐使其成为医学图像处理领域的主流。目前基于深度学习常用的分割方法为有监督的深度学习图像分割,其基于对大量的带有分割标签的医学图像数据进行训练形成分割模型。然而,由于医学图像的特殊性,很多医学图像并没有标签或者没有质量较高的标签,这就限制了有监督的深度学习图像分割的广泛应用。
技术实现要素:
4.针对现有技术的以上缺陷或改进需求,本发明提供了一种无监督领域自适应图像分割方法及系统,其目的在于结合带有分割标签的图像和不带分割标签的图像共同进行训练,由此解决带分割标签的图像数量不够而限制深度学习图像分割应用的技术问题。
5.为实现上述目的,按照本发明的一个方面,提供了一种无监督领域自适应图像分割方法,其包括:
6.确定源域数据和目标域数据,所述源域数据包括带分割标签的图像,所述目标域数据包括不带分割标签的图像;
7.根据源域数据训练分割模型和生成模型,所述分割模型用于预测无标签图像的分割标签,所述生成模型用于生成与输入图像相匹配的带分割标签的图像;
8.将目标域数据输入分割模型,得到对应的分割预测标签;
9.将目标域数据和对应的分割预测标签输入生成模型,得到匹配的参考图像和分割参考标签;
10.计算分割预测标签作和分割参考标签的重叠率,将重叠率符合预设值的分割预测标签作为准分割标签,
11.根据准分割标签和对应的目标域数据再次训练分割模型并重新确定准分割标签,直至分割模型的分割精度满足预设条件时结束训练,得到训练后的分割模型。
12.优选地,所述方法还包括:
13.利用训练后的分割模型对无标签图像进行分割。
14.优选地,所述分割模型为基于u
‑
net分割网络的分割模型。
15.优选地,所述生成模型为基于变分自编码器的生成模型。
16.优选地,所述将目标域数据和对应的分割预测标签输入生成模型,得到匹配的参考图像和分割参考标签,包括:
17.将目标域数据和对应的分割预测标签输入生成模型,在生成模型内匹配初始编码;
18.对初始编码进行解码,生成带分割标签的图案;
19.将生成的图像与输入的图案进行相似度比较,当相似度未达到预设程度时,优化初始编码得到新编码并进行解码,重新生成图案,直至生成的图像与输入的图案的相似度达到预设程度时,判定生成模型生成匹配的参考图像和分割参考标签。
20.优选地,判定生成的图像与输入的图案的相似度达到预设程度,包括:利用结构相似性损失函数来衡量生成图像与输入图像的相似度,当前后两次编码迭代得到的结构相似性损失函数的差值小于或等于预设收敛值,则判定生成的图像与输入的图案的相似度达到预设程度,所述结构相似性损失函数为
[0021][0022]
其中,x和y分别表示两幅图,μ
x
和μ
y
分别表示x和y的均值,σ
x
和σ
y
分别表示x和y的标准差,σ
xy
表示x和y的协方差。
[0023]
优选地,计算分割预测标签作和分割参考标签的重叠率,包括:
[0024]
根据dice损失函数和豪斯道夫距离函数分析分割预测标签作和分割参考标签的匹配度,其中,
[0025]
dice损失函数y
i
是分割参考标签,是分割预测标签,t
dice
为第一预设值;
[0026]
豪斯道夫距离函数h(a,b)=max
a∈a
{min
b∈b
{d(a,b)}}≤t
hd
,a、b分别是两副图像,a、b分别是a和b中的像素点,d(a,b)表示a、b两点的距离,t
hd
为第二预设值。
[0027]
优选地,判定分割模型的分割精度满足预设条件,包括,利用分割模型对目标域数据的多组无标签图像进行分割,得到对应的多组分割预测标签,计算多组分割预测标签与对应的分割参考标签的dice损失函数并求平均值,当平均值大于等于第三预设值时,判定为分割模型的分割精度满足预设条件,其中,
[0028]
dice损失函数y
i
是分割参考标签,是分割预测标签。
[0029]
优选地,所述根据源域数据训练分割模型和生成模型,还包括:
[0030]
在源域数据带分割标签的图像中提取感兴趣区域作为训练数据训练分割模型和生成模型。
[0031]
按照本发明的另一方面,提供了一种无监督领域自适应图像分割系统,包括:
[0032]
训练单元,用于根据源域数据训练分割模型和生成模型,所述源域数据包括带分割标签的图像,所述分割模型用于预测无标签图像的分割标签,所述生成模型用于生成与输入图像相匹配的带分割标签的图像;
[0033]
分割预测单元,用于将目标域数据输入分割模型,得到对应的分割预测标签,所述
目标域数据包括不带分割标签的图像;
[0034]
生成单元,用于将目标域数据和对应的分割预测标签输入生成模型,得到匹配的参考图像和分割参考标签;
[0035]
准标签确定单元,用于计算分割预测标签作和分割参考标签的重叠率,将重叠率符合预设值的分割预测标签作为准分割标签;
[0036]
迭代单元,用于根据准分割标签和对应的目标域数据再次训练分割模型并重新确定准分割标签,直至分割模型的分割精度满足预设条件时结束训练,得到训练后的分割模型。
[0037]
本发明是结合源域数据中带标签的图像和目标域数据中不带标签的图像共同训练分割模型。在训练分割模型时,首先利用源域数据中带分割标签的图像进行训练得到生成模型和初期的分割模型,然后将最新训练好的分割模型迁移至目标域不带分割标签的图像上,预测无标签图像上的分割标签,即获得目标域数据对应的分割预测标签,由于初期形成的分割模型的分割效果可能并不理想,部分预测的分割标签可能不准确,因此,本发明中还通过训练生成模型,通过生成模型获取用于评估分割预测标签准确度的参考标签,通过对比分割预测标签作和分割参考标签的匹配度,排除掉准确度不高的预测标签,将匹配程度符合预设值的分割预测标签作为准分割标签,将获得的准分割标签和对应的目标域的图像作为训练数据继续训练分割模型,以提高分割模型的分割精度。在本发明中,由于在训练分割模型时,通过预测目标域数据中不带标签的图像的分割标签,并将目标域数据作为部分训练数据继续训练分割模型,降低了训练分割模型时对源域数据的数量要求,即使是在无法获得大量带标签的图像的场景下也能应用,使得该无监督领域自适应图像分割方法能够广泛应用。同时,由于本发明中通过生成模型生成参考标签来判断分割标签的准确性,只有准确度高的预测标签和对应的图像才能用于对分割模型继续训练,因此,通过该无监督领域自适应方法最终训练出的分割模型,其分割精度较高。
附图说明
[0038]
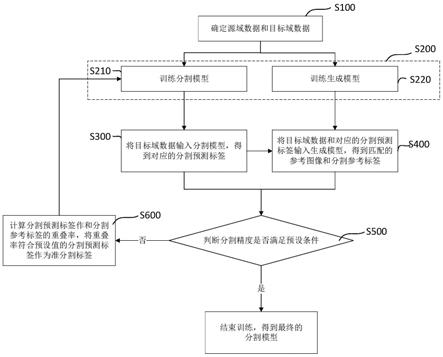
图1是本发明一实施例中无监督领域自适应图像分割方法的步骤流程图;
[0039]
图2中的(a)~(b)分别是本发明一实施例中盆骨的drr图像和x
‑
ray图像;
[0040]
图3是本发明一实施例中通过生成模型搜索最接近图像的流程图;
[0041]
图4是本发明一实施例中迭代训练的流程图;
[0042]
图5中的(a)~(g)分别是本发明一实施例中通过不同模型得到的盆骨分割标签;
[0043]
图6中的(a)~(g)分别是本发明一实施例中通过不同模型得到的右心室心内膜分割标签。
具体实施方式
[0044]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
[0045]
如图1所示为一实施例中无监督领域自适应图像分割方法的步骤流程图,该方法
包括
[0046]
步骤s100:确定源域数据和目标域数据。
[0047]
其中,所述源域数据包括带分割标签的图像,所述目标域数据包括不带分割标签的图像。
[0048]
在一实施例中,源域数据中的图像均带有分割标签,而目标域中的图像未带分割标签。
[0049]
在一具体的实施例中,先获取少量带分割标签的ct图像,然后利用光线投射法从多个角度对ct图像进行投影,获得大量带有分割标签的数字重建放射(digitally reconstructured radiograph,drr)投影图像,以drr图像作为源域数据。在本实施例中,在人体骨组织成像方式中,ct图像中骨组织成像要比其他影像方式,比如超声、核磁共振(mri)等的骨组织成像更加清晰,对比度更强,由于ct图像中的骨组织边界明显,在获取ct图像后,可使用传统的分割算法并手动微调即可得到较为准确的分割标签,由此获得带有分割标签的ct图像,然后利用光线投射法从多个角度对ct图像进行投影,获得大量带有分割标签的drr图像作为源域数据。
[0050]
在一具体的实施例中,可以获取无标签的x
‑
ray图像作为目标域数据。
[0051]
进一步的,源域数据和目标域数据中的图像均是针对同一区域骨组织的成像。例如,源域数据为利用光线投射法投影盆骨ct得到的drr图像,如图2中的(a)所示;目标域数据则可以为骨盆的x
‑
ray图像,如图2中的(b)所示。由图2中的(a)~(b)可以看出,drr投影图像与x
‑
ray图像有一些相似特征,比如图像灰度整体偏小,骨盆的大致形状类似等。
[0052]
步骤s200:根据源域数据训练分割模型和生成模型。
[0053]
在一实施例中,在步骤s200中,对模型进行训练之前,可以对源域数据进行预处理,先从源域数据图像中先提取出感兴趣(r0i)区域作为有效区域进行分析;同理,针对目标域数据,也可以提取感兴趣(r0i)区域作为有效区域进行后续操作。由于感兴趣区域在图像中面积较小导致类别不平衡,进而影响分割精度,因此我们在获得源域数据和目标域数据后需要提取roi以提升分割效果。
[0054]
如图1所示,步骤s200可拆分为两个步骤,分别为:
[0055]
步骤s210:训练分割模型。
[0056]
步骤s220:训练生成模型。
[0057]
需要说明的是,训练分割模型和训练生成模型是两个独立的过程,对其训练的先后顺序不做限定,两者可同时进行训练,也可先后训练,即步骤s210和步骤s220的先后顺序不做限定。
[0058]
在一实施例中,步骤s210训练分割模型,具体可以基于u
‑
net分割网络进行训练。u
‑
net神经网络是很多医学图像分割的主干网络,本发明使用u
‑
net模型作为分割模型,利用预处理后带有分割标签的源域数据训练u
‑
net分割模型。u
‑
net网络结构的编码路径可以有效提取图像中的特征信息,其解码路径可以生成像素/体素级的分割结果。在训练过程中,优化器使用的是adabelief优化器,两个动量超参数β_1=0.9,β_2=0.999,初始学习率为5e
‑
4,训练20个epoch。
[0059]
在一实施例中,步骤s220训练生成模型,具体可以基于变分自编码器(variational auto
‑
encoder,vae)训练,vae拥有和u
‑
net相似的编码
‑
解码结构,通过在脖
颈处选择不同的编码可以生成特定的图像。为了方便后续对数据的筛选,我们在这里利用源域数据训练生成模型vae。训练vae生成模型时,将源域图像及其分割标签按通道叠加后输入到vae生成模型中,模型的输出是重建的图像和分割标签,通过计算重建的图像和分割标签与输入的图像和分割标签的损失来监督vae模型,以使训练后的生成模型最终能生成与输入类似风格的图像和分割标签。损失函数使用均方根误差(mean square error,mse)损失l
mse
和二值交叉熵(binary cross entropy,bce)损失l
bce
,其中,
[0060][0061][0062]
其中,x
i
是输入图像,y
i
是输入分割标签,是vae生成的图像,是vae生成的分割标签。
[0063]
在训练过程中,使用adabelief优化器,两个动量超参数β_1=0.9,β_2=0.999,初始学习率为5e
‑
4,训练250个epoch。
[0064]
步骤s300:将目标域数据输入分割模型,得到对应的分割预测标签。
[0065]
在一实施例中,步骤s300是将最新训练出的分割模型迁移至目标域数据,利用分割模型预测目标域图像的分割标签,针对每一目标域图像形成对应的预测分割标签。
[0066]
步骤s400:将目标域数据和对应的分割预测标签输入生成模型,得到匹配的参考图像和分割参考标签。
[0067]
在一实施例中,步骤s400是将目标域数据和对应的分割预测标签输入生成模型,得到与输入图像最相近的参考图像和分割参考标签。
[0068]
具体地,步骤400可包括以下步骤:
[0069]
步骤s410:将目标域数据和对应的分割预测标签输入生成模型,在生成模型内匹配初始编码。
[0070]
具体地,将目标域数据输入生成模型的编码器中,得到一个初始的潜空间编码。
[0071]
步骤s420:对初始编码进行解码,生成带分割标签的参考图案。
[0072]
具体地,将潜空间编码输入到生成模型的解码器中,生成与该编码对应的带分割标签的参考图像。
[0073]
步骤s430:将生成的图像与输入的图案进行相似度比较,当相似度未达到预设程度时,优化初始编码得到新编码并进行解码,重新生成图案,直至生成的图像与输入的图案的相似度达到预设程度时,判定生成模型生成匹配的参考图像和分割参考标签。
[0074]
具体地,当将目标域数据输入生成模型,生成模型会判断其生成的图像是否为与输入图像最接近的图像,当输入图像与输出图像的相似度未达到预设程度时,需调整编码,具体以前次得到的编码为中心搜索周围的编码,并进行解码生成新的图像后继续判断新生成图像与输入图像的相似度,当相似度达到预设条件,则判定当前生成的图像为参考图像,当相似度未达到预设条件,重复上述过程,直至生成的图像与输入的图案的相似度达到预设程度。需要说明的是,生成模型进行解码生成的是带分割标签的图像,确定参考图像后,也同时确定了参考图像对应的分割参考标签。
[0075]
进一步地,判定生成的图像与输入的图案的相似度达到预设程度,包括:利用结构相似性(structual similarity,ssim)损失函数来衡量生成图像与输入图像的相似度,当前后两次编码迭代得到的结构相似性损失函数的差值小于或等于预设收敛值,则判定生成的图像与输入的图案的相似度达到预设程度,所述结构相似性损失函数为
[0076][0077]
其中,x和y分别表示两幅图,μ
x
和μ
y
分别表示x和y的均值,σ
x
和σ
y
分别表示x和y的标准差,σ
xy
表示x和y的协方差。具体地,预设收敛值可为5e
‑
3。即为提高搜索效率,使用了早停策略,当前后两次迭代的误差小于5e
‑
3时结束搜索。
[0078]
在搜索最相似图像的过程中,使用adabelief优化器,超参数β_1=0.9,β_2=0.999,学习率为5e
‑
3,迭代3000次。由于ssim通常是对两幅图像的全局求相似性,但医学图像中对图像细节更为关注,因此我们选择使用局部ssim,即对整幅图使用移动窗求ssim,窗宽为11。
[0079]
为了进一步理解步骤s400,结合图3所示,该过程为:
[0080]
将目标域图像和对应的分割预测标签输入生成模型中;
[0081]
生成模型通过编码器(encoder)在潜空间内搜索初始编码;
[0082]
通过解码器(decoder)对编码进行解码,生成参考图像和对应的分割参考标签;
[0083]
求生成的参考图像和输入的目标域图像的结构相似度(ssim)损失,当前后两次编码迭代得到的结构相似性损失函数的差值小于或等于预设收敛值,结束搜索,否则,重复在潜空间内优化编码直至搜索结果收敛。
[0084]
在一实施例中,通过步骤s400获得与分割预测标签对应的分割参考标签后,会执行
[0085]
步骤s500:判断当前分割模型的分割精度是否满足预设条件。
[0086]
在一实施例中,分割模型的分割精度满足预设条件,包括,利用分割模型对目标域数据的多组无标签图像进行分割,得到对应的多组分割预测标签,计算多组分割预测标签与对应的分割参考标签的dice损失函数并求平均值,当平均值大于等于第三预设值时,判定为分割模型的分割精度满足预设条件,其中,dice损失函数为
[0087][0088]
其中,y
i
是分割参考标签,是分割预测标签。
[0089]
具体地,第三预设值可以为0.95,即损失函数的平均值大于等于0.95时,判定当前分割模型的分割精度较好,不需继续训练。
[0090]
在迭代训练过程中,为进一步增强分割模型泛化能力,训练数据做了数据增强,包括伽马变换,水平翻转,垂直翻转,随机旋转(旋转角度在
‑
45
°
~45
°
之间),图像缩放,高斯模糊,图像平移(平移比例0~20%)等。我们选择adabelief优化器,两个超参数β_1=0.9,β_2=0.999,学习率为5e
‑
5,损失函数依然选择dice损失。当分割模型的精度不在上升时结束训练,得到最终在目标域图像上的分割模型。
[0091]
当当前分割模型的分割精度满足预设条件时,结束训练,得到最终的分割模型;当
当前分割模型的分割精度不满足预设条件时,则继续执行步骤s600和步骤s700。
[0092]
步骤s600:计算分割预测标签作和分割参考标签的重叠率,将重叠率符合预设值的分割预测标签作为准分割标签。
[0093]
由于不同图像域之间风格差异的影响,直接将预训练分割模型迁移至目标域上的分割效果可能并不理想;但会存在部分目标域图像的分割效果较好。因此,可以通过步骤s600筛选出这部分易分割的图像作为新的训练数据继续迭代训练分割模型。
[0094]
在一实施例中,计算分割预测标签作和分割参考标签的重叠率,包括:根据dice损失函数和豪斯道夫距离函数分析分割预测标签作和分割参考标签的匹配度,其中,
[0095]
dice损失函数y
i
是分割参考标签,是分割预测标签,t
dice
为第一预设值;
[0096]
豪斯道夫距离函数h(a,b)=max
a∈a
{min
b∈b
{d(a,b)}}≤t
hd
,a、b分别是两副图像,a、b分别是a和b中的像素点,d(a,b)表示a、b两点的距离,t
hd
为第二预设值。
[0097]
具体地,本发明中选择dice的t
dice
阈值0.9,hd的阈值t
hd
=15。
[0098]
当分割预测标签作和分割参考标签的重叠率满足上述预设值时,说明当前目标域图像的分割效果较好,可以该目标域图像和对应的分割预测标签作为准分割数据。
[0099]
步骤s700:根据准分割标签和对应的目标域数据再次训练分割模型并重新确定准分割标签,直至分割模型的分割精度满足预设条件时结束训练,得到训练后的分割模型。
[0100]
如图1所示,当确定准分割数据之后,再次跳转至步骤s210,以确定的准分割数据作为新的训练数据,继续训练分割模型,优化分割精度,重复步骤s210~步骤s700,直至分割模型的分割精度满足预设条件时结束训练,得到最终的分割模型。
[0101]
在一实施例中,在得到最终的分割模型后,可以分割模型应用于实际分割操作中,即,该方法还包括:
[0102]
步骤s800:利用训练后的分割模型对无标签图像进行分割。
[0103]
为了进一步理解步骤s600~步骤s800,结合图4所示,该过程为:
[0104]
求分割预测标签和分割参考标签的dice损失函数和豪斯道夫距离函数,确定准标签,利用准标签和对应的目标域图像对分割模型继续训练,直至分割模型的分割精度达到预设条件,然后利用最终形成的分割模型,对无标签的图像进行分割,得到最终分割标签。
[0105]
为了验证分割效果,利用训练好的分割模型预测了目标域测试数据,同时将预测结果和现有技术中取得较好结果的模型(cyclegan、advent、intrada)的预测结果做了对比。
[0106]
对于骨盆的测试结果如附图5所示,其中,(a)表示测试图像,(b)表示人工勾画的金标准,(c)表示仅源域训练分割模型的预测结果(d)表示cyclegan源域图像分割模型的预测结果,(e)表示advent模型的预测结果,(f)表示intrada模型的预测结果,(g)表示本发明分割模型的预测结果。从附图6可以看出,仅源域训练的分割模型直接预测目标域图像有较多的假阳性,其他其中方法则假阴性较多,我们的预测结果在整体形状和骨盆下方的闭孔细节上效果较好,且边界锐度更大,分割效果接近金标准。
[0107]
对于右心室心内膜的测试结果如附图6所示,其中,图6中的(a)~(g)的模型和图5中的(a)~(g)的模型分别一一对应。可以看出源域训练的分割模型和cyclegan模型的假阴
性更多,而advent和intrada模型有少量假阳性,本发明模型的预测效果在整体和细节上相比其他模型更准确。
[0108]
按照本发明的另一方面,提供了一种无监督领域自适应图像分割系统,包括:
[0109]
训练单元,用于根据源域数据训练分割模型和生成模型,所述源域数据包括带分割标签的图像,所述分割模型用于预测无标签图像的分割标签,所述生成模型用于生成与输入图像相匹配的带分割标签的图像;
[0110]
分割预测单元,用于将目标域数据输入分割模型,得到对应的分割预测标签,所述目标域数据包括不带分割标签的图像;
[0111]
生成单元,用于将目标域数据和对应的分割预测标签输入生成模型,得到匹配的参考图像和分割参考标签;
[0112]
准标签确定单元,用于计算分割预测标签作和分割参考标签的重叠率,将重叠率符合预设值的分割预测标签作为准分割标签;
[0113]
迭代单元,用于根据准分割标签和对应的目标域数据再次训练分割模型并重新确定准分割标签,直至分割模型的分割精度满足预设条件时结束训练,得到训练后的分割模型。
[0114]
本发明是结合源域数据中带标签的图像和目标域数据中不带标签的图像共同训练分割模型。在训练分割模型时,首先利用源域数据中带分割标签的图像进行训练得到生成模型和初期的分割模型,然后将最新训练好的分割模型迁移至目标域不带分割标签的图像上,预测无标签图像上的分割标签,即获得目标域数据对应的分割预测标签,由于初期形成的分割模型的分割效果可能并不理想,部分预测的分割标签可能不准确,因此,本发明中还通过训练生成模型,通过生成模型获取用于评估分割预测标签准确度的参考标签,通过对比分割预测标签作和分割参考标签的匹配度,排除掉准确度不高的预测标签,将匹配程度符合预设值的分割预测标签作为准分割标签,将获得的准分割标签和对应的目标域的图像作为训练数据继续训练分割模型,以提高分割模型的分割精度。在本发明中,由于在训练分割模型时,通过预测目标域数据中不带标签的图像的分割标签,并将目标域数据作为部分训练数据继续训练分割模型,降低了训练分割模型时对源域数据的数量要求,即使是在无法获得大量带标签的图像的场景下也能应用,使得该无监督领域自适应图像分割方法能够广泛应用。同时,由于本发明中通过生成模型生成参考标签来判断分割标签的准确性,只有准确度高的预测标签和对应的图像才能用于对分割模型继续训练,因此,通过该无监督领域自适应方法最终训练出的分割模型,其分割精度较高。
[0115]
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。