1.本发明涉及自然语言处理的技术领域,特别是涉及一种裁判文书摘要自动生成方法及装置。
背景技术:
2.随着信息时代的快速发展,互联网上的数据量呈指数级增长。文本摘要技术通过对文本信息概括、总结,提炼出文章的主旨,利用文摘代替原文章参与索引,可以有效缩短检索的时间,同时也能减少检索结果中的冗余信息,能让用户从大量数据中高效地获取所需信息。传统的人工提取文本摘要的方式需要耗费大量的时间,自动文本摘要技术顺势诞生。
3.2004年有学者提出textrank算法,通过词之间的相邻关系构建网络,然后用pagerank算法迭代计算每个节点的值,对该值进行排序即可获得关键词。pagerank原先是用来解决网页排名的问题,网页之间的链接关系即为图的边。textrank则模仿此方法,将某一个词与其前面n个词、以及后面n个词的关系以图表示,使其具有图相邻关系。具体实现:设置一个长度为n的滑动窗口,所有在这个窗口之内的词都视作当前词结点的相邻结点;因此textrank构建的图为无向图。同理可以将文本颗粒度由词层面上升到句子层面,构建句子级别的无向图,提取文章中的最关键句子。
4.2018年有学者提出lead3等方法。lead3算法即只取最开始的三个句子,是一个非常简单的方法并且在摘要数据集上能表现出很好的效果。这类方法属于经验类模型,在很多类型的文章中最能代表文章的通常就是文章的开头三句话。改进以后还可以通过正则表达式去匹配目标短语,去抽取相邻的三句话。
5.现有技术的缺点:
6.(1)基于统计学方法如lead3、textrank算法,生成的文本摘要逻辑性不强,主要是抽取原文中的关键句子进行拼接生成摘要。
7.(2)基于深度学习方法如bert,其模型的最大固定输入为512个token,而裁判文书大多为长文本且超过了该大小,导致对于长文本信息的利用不充分,而裁判文书大多为长文本。并且深度学习方法需要大量的人工标注去训练模型。
技术实现要素:
8.基于此,本发明的目的在于,提供一种裁判文书摘要自动生成方法及装置,增加了分类步骤,使得裁判文书的摘要更有一定的逻辑性和相关性。与现有的深度学习模型相比,本发明不需要人工进行标注,减少了人工标注训练集的成本。
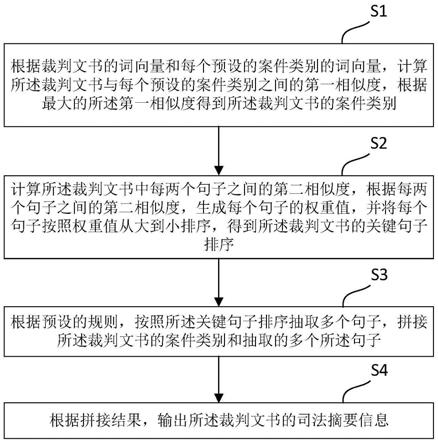
9.第一方面,本发明提供一种裁判文书摘要自动生成方法,包括以下步骤:
10.根据裁判文书的词向量和每个预设的案件类别的词向量,计算所述裁判文书与每个预设的案件类别之间的第一相似度,根据最大的所述第一相似度得到所述裁判文书的案件类别;
11.计算所述裁判文书中每两个句子之间的第二相似度,根据每两个句子之间的第二相似度,生成每个句子的权重值,并将每个句子按照权重值从大到小排序,得到所述裁判文书的关键句子排序;
12.根据预设的规则,按照所述关键句子排序抽取多个句子,拼接所述裁判文书的案件类别和抽取的多个所述句子;
13.根据拼接结果,输出所述裁判文书的司法摘要信息。
14.本发明所述的一种裁判文书摘要自动生成方法,增加了分类步骤,使得裁判文书的摘要更有一定的逻辑性和相关性。与现有的深度学习模型相比,本发明不需要人工进行标注,减少了人工标注训练集的成本。
15.进一步地,根据每两个句子之间的第二相似度,生成每个句子的权重值,包括:
16.根据所述第二相似度,构建所述裁判文书对应的节点连接图;其中,所述节点连接图包括点集和边集;所述点集包括所述裁判文书中的每个句子对应的节点,所述边集包括每两个相似度大于第二阈值的句子对应的节点之间形成的无向有权边;
17.根据所述节点连接图,利用如下公式计算每个节点的textrank值:
[0018][0019]
其中,s(v
i
)表示节点vi的textrank值,s(v
j
)表示节点v
j
的textrank值,out(v
j
)表示节点v
j
后继节点集合,即图结构中点v
j
所指向的点的集合,d为阻尼系数,w
ji
表示节点vi与节点v
j
之间边的相似度;w
jk
表示节点vk与节点v
j
之间边的相似度;通过套用该公式,迭代传播各个节点的权值,直至收敛后得到每个节点的textrank值;
[0020]
根据所述每个节点的textrank值确定所述每个句子的权重值。
[0021]
进一步地,利用如下公式,计算所述裁判文书中每两个句子之间的第二相似度:
[0022][0023]
其中,s
i
,s
j
分别表示两个句子,w
k
表示句子中的词。
[0024]
进一步地,所述根据裁判文书的词向量和每个预设的案件类别的词向量,计算所述裁判文书与每个预设的案件类别之间的第一相似度,包括:
[0025]
使用分词工具,将所述裁判文书与多个案件类别进行分词,列出所有的词取并集;
[0026]
使用给定形状和类型的矩阵存储向量,用0填充初始化,并分别对裁判文书与多个案件类别计算词频,得到所述裁判文书的向量表示和所述每个案件类别的向量表示;
[0027]
利用以下公式计算裁判文书和每个案件类别的余弦值:
[0028][0029]
其中,x1,x2,
…
,x
u
为所述裁判文书的向量表示,u为所述裁判文书中词的数量;y1,y2,
…
,y
v
为所述案件类别的向量表示,v为所述案件类别中词的数量;
[0030]
根据所述余弦值确定所述裁判文书与每个案件类别的第一相似度。
[0031]
进一步地,所述计算所述裁判文书中每两个句子之间的第二相似度之前,还包括:
[0032]
使用停用词词典过滤文档中高频无关词并去除多余符号;
[0033]
对所述裁判文书按照逗号与句号进行分割得到短句。
[0034]
第二方面,本发明提供一种裁判文书摘要自动生成装置,包括:
[0035]
案件分类模块,用于根据裁判文书的词向量和每个预设的案件类别的词向量,计算所述裁判文书与每个预设的案件类别之间的第一相似度,根据最大的所述第一相似度得到所述裁判文书的案件类别;
[0036]
句子排序模块,用于算所述裁判文书中每两个句子之间的第二相似度,根据每两个句子之间的第二相似度,生成每个句子的权重值,并将每个句子按照权重值从大到小排序,得到所述裁判文书的关键句子排序;
[0037]
句子拼接模块,用于根据预设的规则,按照所述关键句子排序抽取多个句子,拼接所述裁判文书的案件类别和抽取的多个所述句子;
[0038]
摘要生成模块,用于根据拼接结果,输出所述裁判文书的司法摘要信息。
[0039]
进一步地,所述句子排序模块包括:
[0040]
节点连接图构建单元,根据所述第二相似度,构建所述裁判文书对应的节点连接图;其中,所述节点连接图包括点集和边集;所述点集包括所述裁判文书中的每个句子对应的节点,所述边集包括每两个相似度大于第二阈值的句子对应的节点之间形成的无向有权边;
[0041]
textrank值计算单元,用于根据所述节点连接图,利用如下公式计算每个节点的textrank值:
[0042][0043]
其中,s(v
i
)表示节点vi的textrank值,s(v
j
)表示节点v
j
的textrank值,out(v
j
)表示节点vj后继节点集合,即图结构中点vj所指向的点的集合,d为阻尼系数,w
ji
表示节点vi与节点v
j
之间边的相似度;w
jk
表示节点vk与节点v
j
之间边的相似度;通过套用该公式,迭代传播各个节点的权值,直至收敛后得到每个节点的textrank值;
[0044]
根据所述每个节点的textrank值确定所述每个句子的权重值。
[0045]
进一步地,所述句子排序模还包括第二相似度计算单元,用于利用如下公式,计算所述裁判文书中每两个句子之间的第二相似度:
[0046][0047]
其中,s
i
,s
j
分别表示两个句子,w
k
表示句子中的词。
[0048]
进一步地,所述案件分类模块包括:
[0049]
分词单元,用于使用分词工具,将所述裁判文书与多个案件类别进行分词,列出所有的词取并集;
[0050]
词频计算单元,用于使用给定形状和类型的矩阵存储向量,用0填充初始化,并分别对裁判文书与多个案件类别计算词频,得到所述裁判文书的向量表示和所述每个案件类别的向量表示;
[0051]
余弦值计算单元,用于根据以下公式计算裁判文书和每个案件类别的余弦值:
[0052][0053]
其中,x1,x2,
…
,x
u
为所述裁判文书的向量表示,u为所述裁判文书中词的数量;y1,y2,
…
,y
v
为所述案件类别的向量表示,v为所述案件类别中词的数量;
[0054]
第一相似度确定单元,用于根据所述余弦值确定所述裁判文书与每个案件类别的第一相似度。
[0055]
进一步地,所述句子排序模块还包括:
[0056]
停用词单元,用于计算所述裁判文书中每两个句子之间的第二相似度之前,使用停用词词典过滤文档中高频无关词并去除多余符号;
[0057]
分割单元,用于对所述裁判文书按照逗号与句号进行分割得到短句。
[0058]
为了更好地理解和实施,下面结合附图详细说明本发明。
附图说明
[0059]
图1为本发明提供的一种裁判文书摘要自动生成方法的流程示意图;
[0060]
图2为本发明提供的一种裁判文书摘要自动生成方法所使用的节点连接图的示例图;
[0061]
图3为本发明提供的一种裁判文书摘要自动生成装置的结构示意图。
具体实施方式
[0062]
为使本技术的目的、技术方案和优点更加清楚,下面将结合附图对本技术实施例方式作进一步地详细描述。
[0063]
应当明确,所描述的实施例仅仅是本技术实施例一部分实施例,而不是全部的实施例。基于本技术实施例中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本技术实施例保护的范围。
[0064]
在本技术实施例使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本技术实施例。在本技术实施例和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本文中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
[0065]
下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本技术相一致的所有实施方式。相反,它们仅是如所附权利要求书中所详述的、本技术的一些方面相一致的装置和方法的例子。在本技术的描述中,需要理解的是,术语“第一”、“第二”、“第三”等仅用于区别类似的对象,而不必用于描述特定的顺序或先后次序,也不能理解为指示或暗示相对重要性。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本技术中的具体含义。
[0066]
此外,在本技术的描述中,除非另有说明,“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。
[0067]
第一方面,如图1所示,本发明提供的一种裁判文书摘要自动生成方法包括以下步
骤:
[0068]
s1:根据裁判文书的词向量和每个预设的案件类别的词向量,计算所述裁判文书与每个预设的案件类别之间的第一相似度,根据最大的所述第一相似度得到所述裁判文书的案件类别。
[0069]
其中,裁判文书是记载人民法院审理过程和结果的文件。它是诉讼活动结果的载体,也是人民法院确定和分配当事人实体权利义务的唯一凭证。一份结构完整、要素齐全、逻辑严谨的裁判文书,既是当事人享有权利和负担义务的凭证,也是上级人民法院监督下级人民法院民事审判活动的重要依据。
[0070]
在一个具体的实施例中,本发明针对民事案件的裁判文书进行摘要提取,将案件类别分为5种,分别为“原被告系借款合同纠纷”,“原被告系劳动合同纠纷”,“原被告系租赁合同纠纷”,“原被告系侵权责任纠纷”,“原被告继承纠纷”。若后续需要补充类别可以在类别数组中直接添加新的案件类别,或针对刑事案件、行政诉讼案件,可以在类别数组中替换为新的案件类别,具有可扩展性质。
[0071]
优选的,计算裁判文书与每个案件类别的第一相似度,包括如下子步骤:
[0072]
s11:使用分词工具,将所述裁判文书与多个案件类别进行分词,列出所有的词取并集。
[0073]
由于中文不像英文那样具有天然的分隔符,所以一般情况下,中文自然语言处理的第一步就是要对语料进行分词处理,将文本分割成单个的词语。
[0074]
在一个具体的实施例中,使用结巴中文分词工具包进行分词,列出所有的词取并集得到u个词。
[0075]
s12:使用给定形状和类型的矩阵存储向量,用0填充初始化,并分别对裁判文书与多个案件类别计算词频,得到所述裁判文书的向量表示和所述每个案件类别的向量表示。
[0076]
s13:利用以下公式计算裁判文书和每个案件类别的余弦值:
[0077][0078]
其中,x1,x2,
…
,x
u
为所述裁判文书的向量表示,u为所述裁判文书中词的数量;y1,y2,
…
,y
v
为所述案件类别的向量表示,v为所述案件类别中词的数量。
[0079]
s14:根据所述余弦值确定所述裁判文书与每个案件类别的第一相似度。
[0080]
在一个具体的实施例中,裁判文书与每个案件类别的第一相似度只用于排序其中的最大值,取相似度值最大的案件类别为裁判文书最终的案件类别结果,因此可直接令第一相似度等于余弦值。在其他例子中,如需对第一相似度进行其他处理和比对,也可以使用其他计算方式,利用余弦值确定第一相似度,比如取对数值、相对值或其他加权方式。
[0081]
s2:计算所述裁判文书中每两个句子之间的第二相似度,根据每两个句子之间的第二相似度,生成每个句子的权重值,并将每个句子按照权重值从大到小排序,得到所述裁判文书的关键句子排序。
[0082]
在一个优选的实施例中,针对裁判文书,先使用停用词词典(stop
‑
words)来过滤文档中高频无关词并去除多余符号,这样可以使得文本中存在的词更具有代表性。然后再将文本按照逗号与句号进行分割得到短句,即text=[s1,s2,
…
,s
m
]。
[0083]
优选的,利用如下公式,计算所述裁判文书中每两个句子之间的第二相似度:
[0084][0085]
其中,s
i
,s
j
分别表示两个句子,w
k
表示句子中的词。分子部分的意思是同时出现在两个句子中的单词的个数,分母是对句子中词的个数求对数之和。分母这样设计,可以防止较长的句子在相似度计算上的优势。
[0086]
在一个优选的实施例中,如图2所示,根据每两个句子之间的第二相似度,生成每个句子的权重值,具体包括以下子步骤:
[0087]
s21:根据所述第二相似度,构建所述裁判文书对应的节点连接图,
[0088]
其中,所述节点连接图包括点集和边集;所述点集包括所述裁判文书中的每个句子对应的节点,所述边集包括每两个相似度大于第二阈值的句子对应的节点之间形成的无向有权边。
[0089]
优选的,根据阈值去掉两个节点之间相似度较低的边连接。
[0090]
s22:根据所述节点连接图,利用如下公式计算每个节点的textrank值:
[0091][0092]
其中,s(v
i
)表示节点vi的textrank值,s(v
j
)表示节点v
j
的textrank值,out(v
j
)表示节点v
j
后继节点集合,即图结构中点v
j
所指向的点的集合,d为阻尼系数,w
ji
表示节点vi与节点v
j
之间边的相似度;w
jk
表示节点vk与节点v
j
之间边的相似度;通过套用该公式,迭代传播各个节点的权值,直至收敛后得到每个节点的textrank值。
[0093]
s23:根据所述每个节点的textrank值确定所述每个句子的权重值。
[0094]
在一个具体的实施例中,每个句子的权重值只用于按照从大到小的顺序给句子排序,因此可直接令每个句子的权重值等于该句子所对应的节点的textrank值。在其他例子中,如需对权重值进行其他处理和比对,也可以使用其他计算方式利用textrank值确定每个句子的权重值,比如取对数值、相对值或其他加权方式。
[0095]
s3:根据预设的规则,按照所述关键句子排序抽取多个句子,拼接所述裁判文书的案件类别和抽取的多个所述句子。
[0096]
在一个具体的实施例中,利用如下公式对裁判文书的案件类别和抽取的多个句子进行拼接:
[0097][0098]
其中,summary为拼接结果,topic为裁判文书的案件类别,s
i
为根据预设规则抽取的句子。
[0099]
本实施例中,预设规则为:当s1,s2,
…
,s
k 1
的句子长度之和大于300时,拼接s1,s2,
…
,s
k
。预设该规则的意义在于,限定最终拼接的结果不超过300字。如有其他字数需求,或其他条件要求,可根据不同的要求设置不同的抽取规则。
[0100]
s4:根据拼接结果,输出所述裁判文书的司法摘要信息。
[0101]
本发明提供的一种裁判文书摘要自动生成方法,最终输出的司法摘要的文字逻辑
归结如表1所示,由四个方面组成司法摘要。
[0102]
表1司法摘要文字逻辑样例
[0103][0104][0105]
本发明与现有的基于统计的模型相比,针对裁判文书文本增加了一个分类模型使得裁判文书的摘要更有一定的逻辑性和相关性。与现有的深度学习模型相比,本发明不需要人工进行标注,减少了人工标注训练集的成本。
[0106]
通过textrank算法并结合基于语义匹配的分类方法,使得裁判文书的摘要更具有一定的逻辑性和相关性。rouge
‑
1,rouge
‑
2,rouge
‑
l等评分方法上也相较于textrank方法有所提升约2%。
[0107]
第二方面,如图3所示,与前述方法相对应,本发明还提供一种裁判文书摘要自动生成装置,包括:
[0108]
案件分类模块,用于根据裁判文书的词向量和每个预设的案件类别的词向量,计算所述裁判文书与每个预设的案件类别之间的第一相似度,根据最大的所述第一相似度得到所述裁判文书的案件类别;
[0109]
句子排序模块,用于算所述裁判文书中每两个句子之间的第二相似度,根据每两个句子之间的第二相似度,生成每个句子的权重值,并将每个句子按照权重值从大到小排序,得到所述裁判文书的关键句子排序;
[0110]
句子拼接模块,用于根据预设的规则,按照所述关键句子排序抽取多个句子,拼接所述裁判文书的案件类别和抽取的多个所述句子;
[0111]
摘要生成模块,用于根据拼接结果,输出所述裁判文书的司法摘要信息。
[0112]
进一步地,所述句子排序模块包括:
[0113]
节点连接图构建单元,根据所述第二相似度,构建所述裁判文书对应的节点连接图;其中,所述节点连接图包括点集和边集;所述点集包括所述裁判文书中的每个句子对应的节点,所述边集包括每两个相似度大于第二阈值的句子对应的节点之间形成的无向有权边;
[0114]
textrank值计算单元,用于根据所述节点连接图,利用如下公式计算每个节点的textrank值:
[0115][0116]
其中,s(v
i
)表示节点vi的textrank值,s(v
j
)表示节点v
j
的textrank值,out(v
j
)表示节点v
j
后继节点集合,即图结构中点v
j
所指向的点的集合,d为阻尼系数,w
ji
表示节点vi与节点v
j
之间边的相似度;w
jk
表示节点vk与节点v
j
之间边的相似度;通过套用该公式,迭代传播各个节点的权值,直至收敛后得到每个节点的textrank值;
[0117]
根据所述每个节点的textrank值确定所述每个句子的权重值。
[0118]
进一步地,所述句子排序模还包括第二相似度计算单元,用于利用如下公式,计算所述裁判文书中每两个句子之间的第二相似度:
[0119][0120]
其中,s
i
,s
j
分别表示两个句子,w
k
表示句子中的词。
[0121]
进一步地,所述案件分类模块包括:
[0122]
分词单元,用于使用分词工具,将所述裁判文书与多个案件类别进行分词,列出所有的词取并集;
[0123]
词频计算单元,用于使用给定形状和类型的矩阵存储向量,用0填充初始化,并分别对裁判文书与多个案件类别计算词频,得到所述裁判文书的向量表示和所述每个案件类别的向量表示;
[0124]
余弦值计算单元,用于根据以下公式计算裁判文书和每个案件类别的余弦值:
[0125][0126]
其中,x1,x2,
…
,x
u
为所述裁判文书的向量表示,u为所述裁判文书中词的数量;y1,y2,
…
,y
v
为所述案件类别的向量表示,v为所述案件类别中词的数量;
[0127]
第一相似度确定单元,用于根据所述余弦值确定所述裁判文书与每个案件类别的
第一相似度。
[0128]
进一步地,所述句子排序模块还包括:
[0129]
停用词单元,用于计算所述裁判文书中每两个句子之间的第二相似度之前,使用停用词词典过滤文档中高频无关词并去除多余符号;
[0130]
分割单元,用于对所述裁判文书按照逗号与句号进行分割得到短句。
[0131]
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。