1.本发明属于神经网络单元架构设计技术领域,特别是涉及一种用于处理神经网络中的卷积运算的方法。
背景技术:
2.目前,卷积神经网络(英文全称:convolutional neural networks,缩写:cnn)广泛运用在图像类应用中。卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一。通常cnn模型是由输入层、卷积层、池化层、全连接层和分类层组合而构成的,在cnn中卷积层和不同的卷积核进行局部连接,从而产生输入数据的多个特征输出,将输出经过池化层降维后通过全连接层和分类层获取与输出目标的误差,再利用反向传播算法反复地更新cnn中相邻层神经元之间的连接权值,缩小与输出目标的误差,最终完成整个模型参数的训练。
3.在神经网络技术中,正在积极地进行在各种类型的电子系统中使用神经网络来分析输入数据并提取有效信息的研究。处理神经网络的装置需要针对复杂输入数据的大量运算。因此,需要用于高效处理神经网络的运算的技术,以便使用神经网络来实时分析大量输入数据并提取所需信息。当对神经网络进行训练时,通过仅使用少量的比特可以保持均匀的准确度或者可以提高准确度,并且在运算期间由处理神经网络的运算器使用的比特数可以进行各种改变。如果将这种神经网络的特性和在神经网络中执行的运算的并行性一起使用,则可以高效地处理神经网络中的各种运算。
技术实现要素:
4.本发明主要解决的技术问题是提供一种用于处理神经网络中的卷积运算的装置和方法,通过在神经网络单元内设置独立双寄存器配置结构,当神经网络单个子单元完成自身的运算后,自动切换为下一层的网络配置进行工作,从而实现了网络层运算的完全流水工作,提升了神经网络的工作效率。
5.为解决上述技术问题,本发明采用的一个技术方案是:一种用于处理神经网络中的卷积运算的方法,包括存储器、取数控制单元、卷积乘加运算单元、激活运算单元、计算单元和归一化单元,还包括两个通路选择单元,一个通路选择单元与第一单元连接,另一个通路选择单元与第二单元连接,第一单元和第二单元为取数控制单元、卷积乘加运算单元、激活运算单元、计算单元和归一化单元中任意的两个单元,每个通路选择单元都连接有两个配置寄存器;
6.配置寄存器用于存储运算指令,所述运算指令包括操作码和操作域,所述操作码用于指示所述运算指令对应的运算方式;所述操作域包括所述参与运算的数据的首地址和所述参与运算的数据中部分数据或者全部数据的索引的地址;
7.通路选择单元用于获取与之连接的单元工作完成的信号后,从当前选择的寄存器切换到另一个寄存器;
8.存储器用于存储参与运算的数据和卷积核数据;
9.取数控制单元用于根据寄存器信息对存储器进行数据读取操作,并把读取数据送往卷积乘加单元;
10.卷积乘加运算单元用于进行神经网络的卷积运算,并将运算结果送往激活运算单元;
11.激活运算单元用于进行神经网络的激活函数运算,并将运算结果送往计算单元;
12.计算单元用于进行神经网络的池化运算,并将池化运算结果送往归一化单元;
13.归一化单元用于将池化运算结果回写到存储器。
14.进一步地说,还包括处理器,所述处理器用于获取第一单元或者第二单元的完成信号,将下一层的神经网络配置信息写入通路选择单元当前选择的寄存器。
15.进一步地说,还包括配置存储器和配置读取单元,配置存储器用于存储神经网络每一层的神经网络配置信息,配置读取单元用于获取第一单元或者第二单元的完成信号,从寄存器上获取下一层的神经网络配置信息并写入通路选择单元当前选择的寄存器。
16.进一步地说,所述配置存储器还存储有神经网络各层配置信息地址索引表格。
17.进一步地说,还包括网络解析分层处理单元、配置产生单元和配置写入单元;
18.网络解析分层处理单元用于将工程文件解析分解为一层层独立的网络结构;
19.配置产生单元用于将单层的神经网络按照神经网络的结构产生对应的配置信息;
20.配置写入单元用于将每一层网络的配置信息写入配置存储器中。
21.一种用于处理神经网络中的卷积运算的方法,用于加快神经网络运算速度的装置中,包括存储器、取数控制单元、卷积乘加运算单元、激活运算单元、计算单元和归一化单元,还包括两个通路选择单元,一个通路选择单元与第一单元连接,另一个通路选择单元与第二单元连接,第一单元和第二单元为取数控制单元、卷积乘加运算单元、激活运算单元、计算单元和归一化单元中任意的两个单元,每个通路选择单元都连接有两个配置寄存器;配置寄存器用于存储运算指令,所述运算指令包括操作码和操作域,所述操作码用于指示所述运算指令对应的运算方式;所述操作域包括所述参与运算的数据的首地址和所述参与运算的数据中部分数据或者全部数据的索引的地址;存储器用于存储参与运算的数据和卷积核数据;
22.本方法包括如下步骤:
23.取数控制单元根据寄存器信息对存储器进行数据读取操作,并把读取数据送往卷积乘加单元;
24.卷积乘加运算单元用于进行神经网络的卷积运算,并将运算结果送往激活运算单元;
25.激活运算单元用于进行神经网络的激活函数运算,并将运算结果送往计算单元;
26.计算单元用于进行神经网络的池化运算,并将池化运算结果送往归一化单元;
27.归一化单元用于将池化运算结果回写到存储器;
28.通路选择单元获取与之连接的单元工作完成的信号后,从当前选择的寄存器切换到另一个寄存器。
29.进一步地说,所述装置还包括处理器,本方法还包括步骤:
30.所述处理器获取第一单元或者第二单元的完成信号,将下一层的神经网络配置信
息写入通路选择单元当前选择的寄存器。
31.进一步地说,所述装置还包括配置存储器和配置读取单元,配置存储器用于存储神经网络每一层的神经网络配置信息;所述方法还包括步骤:
32.配置读取单元获取第一单元或者第二单元的完成信号,从寄存器上获取下一层的神经网络配置信息并写入通路选择单元当前选择的寄存器。
33.进一步地说,所述配置存储器还存储有神经网络各层配置信息地址索引表格,所述配置读取单元从寄存器获取下一层的神经网络配置信息包括步骤:
34.所述配置读取单元从寄存器根据索引表格获取下一层的神经网络配置信息。
35.进一步地说,所述装置还包括网络解析分层处理单元、配置产生单元和配置写入单元;所述方法包括步骤:
36.网络解析分层处理单元将工程文件解析分解为一层层独立的网络结构;
37.配置产生单元将单层的神经网络按照神经网络的结构产生对应的配置信息;
38.配置写入单元将每一层网络的配置信息写入配置存储器中。
39.本发明的有益效果:通过在神经网络单元内设置独立双寄存器配置结构,当神经网络单个子单元完成自身的运算后,自动切换为下一层的网络配置进行工作,从而实现了网络层运算的完全流水工作,提升了神经网络的工作效率。
附图说明
40.图1是本发明装置的结构示意图;
41.图2是本发明方法的流程图。
具体实施方式
42.下面结合附图对本发明的较佳实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
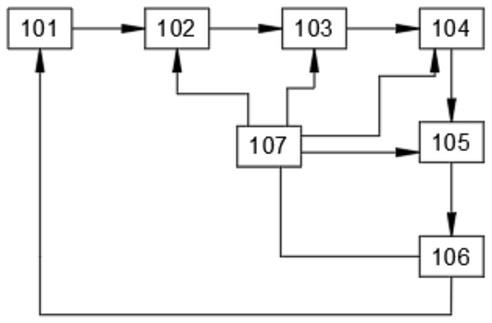
43.实施例:一种用于处理神经网络中的卷积运算的装置,如图1所示,包括存储器101、取数控制单元102、卷积乘加运算单元103、激活运算单元104、计算单元105和归一化单元106,还包括两个通路选择单元107,一个通路选择单元与第一单元连接,另一个通路选择单元与第二单元连接,第一单元和第二单元为取数控制单元、卷积乘加运算单元、激活运算单元、计算单元和归一化单元中任意的两个单元,每个通路选择单元都连接有两个配置寄存器;
44.配置寄存器用于存储运算指令,所述运算指令包括操作码和操作域,所述操作码用于指示所述运算指令对应的运算方式;所述操作域包括所述参与运算的数据的首地址和所述参与运算的数据中部分数据或者全部数据的索引的地址;
45.通路选择单元用于获取与之连接的单元工作完成的信号后,从当前选择的寄存器切换到另一个寄存器;
46.存储器用于存储参与运算的数据和卷积核数据;
47.取数控制单元用于根据寄存器信息对存储器进行数据读取操作,并把读取数据送往卷积乘加单元;
48.卷积乘加运算单元用于进行神经网络的卷积运算,并将运算结果送往激活运算单
元;
49.激活运算单元用于进行神经网络的激活函数运算,并将运算结果送往计算单元;
50.计算单元用于进行神经网络的池化运算,并将池化运算结果送往归一化单元;
51.归一化单元用于将池化运算结果回写到存储器。
52.还包括处理器,所述处理器用于获取第一单元或者第二单元的完成信号,将下一层的神经网络配置信息写入通路选择单元当前选择的寄存器。
53.还包括配置存储器和配置读取单元,配置存储器用于存储神经网络每一层的神经网络配置信息,配置读取单元用于获取第一单元或者第二单元的完成信号,从寄存器上获取下一层的神经网络配置信息并写入通路选择单元当前选择的寄存器。
54.所述配置存储器还存储有神经网络各层配置信息地址索引表格。
55.还包括网络解析分层处理单元、配置产生单元和配置写入单元;
56.网络解析分层处理单元用于将工程文件解析分解为一层层独立的网络结构;
57.配置产生单元用于将单层的神经网络按照神经网络的结构产生对应的配置信息;
58.配置写入单元用于将每一层网络的配置信息写入配置存储器中。
59.一种用于处理神经网络中的卷积运算的方法,如图2所示,用于加快神经网络运算速度的装置中,包括存储器、取数控制单元、卷积乘加运算单元、激活运算单元、计算单元和归一化单元,还包括两个通路选择单元,一个通路选择单元与第一单元连接,另一个通路选择单元与第二单元连接,第一单元和第二单元为取数控制单元、卷积乘加运算单元、激活运算单元、计算单元和归一化单元中任意的两个单元,每个通路选择单元都连接有两个配置寄存器;配置寄存器用于存储运算指令,所述运算指令包括操作码和操作域,所述操作码用于指示所述运算指令对应的运算方式;所述操作域包括所述参与运算的数据的首地址和所述参与运算的数据中部分数据或者全部数据的索引的地址;存储器用于存储参与运算的数据和卷积核数据;
60.本方法包括如下步骤:
61.取数控制单元根据寄存器信息对存储器进行数据读取操作,并把读取数据送往卷积乘加单元;
62.卷积乘加运算单元用于进行神经网络的卷积运算,并将运算结果送往激活运算单元;
63.激活运算单元用于进行神经网络的激活函数运算,并将运算结果送往计算单元;
64.计算单元用于进行神经网络的池化运算,并将池化运算结果送往归一化单元;
65.归一化单元用于将池化运算结果回写到存储器;
66.通路选择单元获取与之连接的单元工作完成的信号后,从当前选择的寄存器切换到另一个寄存器。
67.所述装置还包括处理器,本方法还包括步骤:
68.所述处理器获取第一单元或者第二单元的完成信号,将下一层的神经网络配置信息写入通路选择单元当前选择的寄存器。
69.所述装置还包括配置存储器和配置读取单元,配置存储器用于存储神经网络每一层的神经网络配置信息;所述方法还包括步骤:
70.配置读取单元获取第一单元或者第二单元的完成信号,从寄存器上获取下一层的
神经网络配置信息并写入通路选择单元当前选择的寄存器。
71.所述配置存储器还存储有神经网络各层配置信息地址索引表格,所述配置读取单元从寄存器获取下一层的神经网络配置信息包括步骤:
72.所述配置读取单元从寄存器根据索引表格获取下一层的神经网络配置信息。
73.所述装置还包括网络解析分层处理单元、配置产生单元和配置写入单元;所述方法包括步骤:
74.网络解析分层处理单元将工程文件解析分解为一层层独立的网络结构;
75.配置产生单元将单层的神经网络按照神经网络的结构产生对应的配置信息;
76.配置写入单元将每一层网络的配置信息写入配置存储器中。
77.本发明的工作原理如下:通过在神经网络单元内设置独立双寄存器配置结构,当神经网络单个子单元完成自身的运算后,自动切换为下一层的网络配置进行工作,从而实现了网络层运算的完全流水工作,提升了神经网络的工作效率。
78.以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。