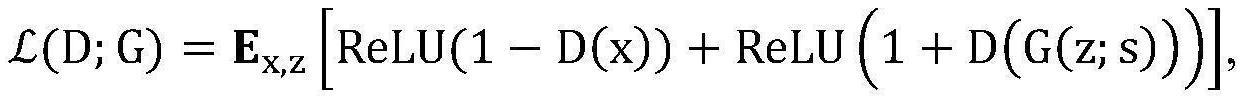
音频发生器及用于生成音频信号和训练音频发生器的方法
1.引言
2.在下文中,将描述不同的发明实施例和方面。另外,进一步的实施例将由所附权利要求书定义。应当注意,权利要求所定义的任何实施例都可以由本说明书中描述的任何细节(特征和功能)补充。
3.此外,本说明书中描述的实施例可以单独使用,也可以由本文的任何特征或权利要求中包括的任何特征补充。
4.另外,应当注意,本文所述的各个方面可以单独使用或组合使用。因此,可以向所述每个单独方面添加细节,而不向所述的另一个方面添加细节。
5.还应注意,本公开明确或隐含地描述了音频发生器和/或方法和/或计算机程序产品中可用的特征。因此,本文描述的任何特征可以在设备、方法和/或计算机程序产品的上下文中使用。
6.此外,本文公开的与方法相关的特征和功能也可用于设备(配置为执行此类功能)。此外,本文所公开的关于设备的任何特征和功能也可以在相应的方法中使用。换句话说,本文公开的方法可以由关于设备所描述的任何特征和功能补充。
7.此外,本文描述的任何特征和功能可以在硬件或软件中实现,或使用硬件和软件的组合实现,如“实现替代方案”一节所述。
8.实现替代方案
9.尽管在设备的上下文中描述了某些方面,但很明显,这些方面也代表了对相应方法的描述,其中特征对应于方法步骤或方法步骤的特征。类似地,在方法步骤的上下文中描述的方面也表示对相应设备的相应特征的描述。一些或所有的方法步骤可以由(或使用)硬件装置来执行,例如,微处理器、可编程计算机或电子电路。在一些实施例中,最重要的方法步骤中的一个或多个可以通过这样的装置来执行。
10.根据某些实施要求,本发明的实施例可以在硬件或软件中实现。该实现可以使用数字存储介质来执行,例如软盘、dvd、蓝光、cd、rom、prom、eprom、eeprom或闪存,这些介质具有存储在其上的电子可读控制信号,其与可编程计算机系统协作(或能够协作),从而执行相应的方法。因此,数字存储介质可以是计算机可读的。
11.根据本发明的一些实施例包括具有电子可读控制信号的数据载体,电子可读控制信号能够与可编程计算机系统协作,从而执行本文所述的方法之一。
12.通常,本发明的实施例可以实现为具有程序代码的计算机程序产品,当计算机程序产品在计算机上运行时,该程序代码可操作用于执行所述方法之一。程序代码可以例如存储在机器可读载体上。
13.其他实施例包括存储在机器可读载体上的用于执行本文所述方法之一的计算机程序。
14.换句话说,因此,本发明方法的实施例是,具有用于当计算机程序在计算机上运行时,执行本文所述方法之一的程序代码的计算机程序。
15.因此,本发明方法的进一步实施例是数据载体(或数字存储介质,或计算机可读介
质),包括记录在其上的用于执行本文所述方法之一的计算机程序。数据载体、数字存储介质或记录介质通常是有形的和/或非暂时性的。
16.因此,本发明方法的进一步实施例是表示用于执行本文所述方法之一的计算机程序的数据流或信号序列。数据流或信号序列可以例如被配置为经由数据通信连接传送,例如经由互联网。
17.进一步实施例包括处理装置,例如计算机或可编程逻辑器件,其被配置为或适于执行本文所述方法之一。
18.进一步实施例包括在其上安装有用于执行本文所述方法之一的计算机程序的计算机。
19.根据本发明的进一步实施例包括被配置为将用于执行本文所述方法之一的计算机程序(例如,电子地或光学地)传送到接收器的装置或系统。例如,接收器可以是计算机、移动设备、存储设备等。装置或系统可例如包括用于将计算机程序传送到接收器的文件服务器。
20.在一些实施例中,可编程逻辑器件(例如现场可编程门阵列)可用于执行本文所述方法的一些或全部功能。在一些实施例中,现场可编程门阵列可以与微处理器协作以执行本文所述的方法之一。通常,优选由任何硬件装置执行方法。
21.本文描述的设备可以使用硬件装置来实现,或者使用计算机来实现,或者使用硬件装置和计算机的组合来实现。
22.本文描述的设备,或本文描述的设备的任何组件,可以至少部分地在硬件和/或软件中实现。
23.本文描述的方法可以使用硬件装置,或使用计算机,或使用硬件装置和计算机的组合来执行。
24.本文描述的方法,或本文描述的方法的任何部分,可以至少部分地通过硬件和/或软件来执行。
25.上述所描述的实施例仅是对本发明的原理进行说明。应当理解,本文所述的布置和细节的修改和变化对于本领域技术人员将是显而易见的。因此,其意图仅受即将到来的专利权利要求的范围的限制,而不受通过本文的实施例的描述和解释方式所提供的具体细节的限制。
技术领域
26.本发明属于音频生成的技术领域。
27.本发明的实施例涉及音频发生器,其被配置为从输入信号和目标数据生成音频信号,目标数据表示音频信号。进一步的实施例涉及用于生成音频信号的方法,以及用于训练音频发生器的方法。进一步的实施例涉及计算机程序产品。
背景技术:
28.近年来,神经声码器在合成语音信号的自然度和感知质量方面已经超越了经典的语音合成方法。使用如wavenet和waveglow这样计算量大的神经声码器可以获得最好的结果,而基于生成式对抗网络的轻量级架构,例如melgan和parallel wavegan,在感知质量方
面仍然较差。
29.使用深度学习生成音频波形的生成模型,诸如wavenet、lpcnet和waveglow,在自然声音语音合成方面取得了重大进展。这些生成模型在文本到语音(tts)应用中被称为神经声码器,优于参数和拼接合成方法。它们可以使用目标语音的压缩表示(例如梅尔谱图)来调节,以再现给定的说话者和给定的话语。
30.先前的研究表明,在解码器侧使用这种生成模型可以实现非常低比特率的干净语音的语音编码。这可以通过使用经典低比特率语音编码器的参数来调节神经声码器来实现。
31.神经声码器也被用于语音增强任务,如语音降噪或去噪。
32.这些深度生成模型的主要问题通常是需要大量的参数,以及在训练和合成(推理)期间产生的复杂性。例如,wavenet被认为是合成语音质量方面的最先进技术,它一个接一个地顺序生成音频样本。此过程非常缓慢,计算要求很高,并且不能实时执行。
33.近年来,基于生成对抗网络(gan)的轻量级对抗声码器(诸如melgan和parallelwavegan)被提出用于快速波形生成。然而,使用这些模型生成的语音的报告的感知质量明显低于如wavenet和waveglow的神经声码器的基线。已经提出了一种用于文本到语音的gan(gan-tts)来弥补此质量差距,但仍然需要很高的计算成本。
34.神经声码器的种类繁多,但都有各自的缺点。自回归声码器,例如wavenet和lpcnet,可能具有非常高的质量,并且适合在cpu上进行推理的优化,但它们不适合在gpu上使用,因为它们的处理不能容易地并行化,并且它们不能在不影响质量的情况下提供非实时处理。
35.归一化流声码器,例如waveglow,也可能具有非常高的质量,并且适合在gpu上进行推理,但是它们包括非常复杂的模型,需要很长时间来训练和优化,并且也不适合嵌入式设备。
36.gan声码器,例如melgan和parallelwavegan可能适用于gpu上的推理并且是轻量级,但它们的质量低于自回归模型。
37.综上所述,目前还不存在提供高保真语音的低复杂度解决方案。gan是实现这一目标的研究最多的方法。本发明是解决此问题的有效方法。
38.本发明的目的是提供一种轻量级的神经声码器解决方案,该解决方案以非常高的质量生成语音并且可以用有限的计算资源进行训练,例如用于tts(文本到语音)。
附图说明
39.随后将参照附图描述根据本发明的实施例,其中:
40.图1示出了根据本发明的实施例的音频发生器架构,
41.图2示出了可用于训练根据本发明的音频发生器的鉴别器结构,
42.图3示出了根据本发明的实施例的音频发生器的部分的结构,
43.图4示出了根据本发明的实施例的音频发生器的部分的结构,以及
44.图5示出了不同模型的mushra专家听力测试的结果,
45.图6示出了根据本发明的实施例的音频发生器的架构,
46.图7示出了根据本发明对信号执行的操作。
47.图8示出了使用音频发生器的文本到语音应用中的操作。
48.图9a-9c示出了发生器的示例。
49.图10示出了块的输入和输出的几种可能性,块可以在本发明的发生器的内部或外部。
50.在图中,相似的附图标记表示相似的元件和特征。
技术实现要素:
51.根据一个方面,提供了音频发生器,被配置为从输入信号和目标数据生成音频信号,目标数据表示音频信号,音频发生器包括:
52.第一处理块,被配置为接收从输入信号得出的第一数据并输出第一输出数据,其中,第一输出数据包括多个通道,以及
53.第二处理块,被配置为作为第二数据接收第一输出数据或从第一输出数据得出的数据;
54.其中,对于第一输出数据的每个通道,第一处理块包括:
55.可学习层的条件集,被配置为处理目标数据以获得条件特征参数,目标数据从文本得出;以及
56.样式元件,被配置为将条件特征参数应用于第一数据或归一化的第一数据;以及
57.其中,第二处理块被配置为组合第二数据的多个通道以获得音频信号。
58.音频发生器可以使目标数据是频谱图。音频发生器可以使得目标数据是梅尔谱图。
59.音频发生器可以使得目标数据包括从文本获得的对数谱图或mfcc和梅尔谱图或另一类型的谱图中的至少一个声学特征。
60.音频发生器可以被配置为通过将文本或文本元素形式的输入转换为至少一个声学特征来获得目标数据。
61.音频发生器可以被配置为通过将至少一个语言学特征转换为至少一个声学特征来获得目标数据。
62.音频发生器可以包括从文本获得的音素、单词韵律、语调、短语中断和填充停顿中的至少一个语言学特征。
63.音频发生器可以被配置为通过将文本或文本元素形式的输入转换为至少一个语言学特征来获得目标数据。
64.音频发生器可使得目标数据包括从文本获得的字符和单词中的至少一个。
65.音频发生器可使得使用执行文本分析和/或使用声学模型的统计模型从文本得出目标数据。
66.音频发生器可使得使用执行文本分析和/或使用声学模型的可学习模型从文本得出目标数据。
67.音频发生器可使得使用执行文本分析和/或声学模型的基于规则的算法从文本得出目标数据。
68.音频发生器可以被配置为通过细化输入来获得目标数据。
69.音频发生器可以被配置为通过至少一个确定性层得出目标数据。
70.音频发生器可以被配置为通过至少一个可学习层得出目标数据。
71.音频发生器可以使得可学习层的条件集由一个或至少两个卷积层组成。
72.音频发生器可以使得第一卷积层被配置为使用第一激活函数对目标数据或上采样的目标数据进行卷积以获得第一卷积数据。
73.音频发生器可以使得可学习层的条件集和样式元件是包括一个或多个残差块的神经网络的残差块中的权重层的一部分。
74.方法可包括从文本获得的对数谱图或mfcc和梅尔谱图或另一类型的谱图中的至少一个声学特征。
75.方法可以通过将文本或文本元素形式的输入转换为至少一个声学特征来获得目标数据。
76.方法可以通过将至少一个语言学特征转换为至少一个声学特征来获得目标数据。
77.方法可以包括从文本中获得的音素、单词韵律、语调、短语中断和填充停顿中的至少一个语言学特征。
78.方法可以通过将文本或文本元素形式的输入转换为至少一个语言学特征来获得目标数据。
79.方法可包括从文本获得的字符和单词中的至少一个。
80.方法可以通过使用执行文本分析和/或使用声学模型的统计模型得出目标数据。
81.方法可以通过使用执行文本分析和/或使用声学模型的可学习模型得出目标数据。
82.方法可以通过使用执行文本分析和/或声学模型的基于规则的算法得出目标数据。
83.方法可通过至少一个确定性层得出目标数据。
84.方法可通过至少一个可学习层得出目标数据。
85.用于生成音频信号的方法可进一步包括从文本得出目标数据。
86.方法可以包括输入代表序列是文本。
87.方法可以包括输入代表序列是谱图。方法可包括谱图为梅尔谱图。
88.特别地,提出了一种音频发生器(例如,10),被配置为从输入信号(例如,14)和目标数据(例如,12)生成音频信号(例如,16),目标数据(例如,12)表示音频信号(例如,16),并且可从文本得出,音频发生器包括以下中的至少一个:
89.第一处理块(例如,40,50,50a-50h),被配置为接收从输入信号(例如,14)得出的第一数据(例如,15,59a)并输出第一输出数据(例如,69),其中第一输出数据(例如,69)包括多个通道(例如,47),以及
90.第二处理块(例如,45),被配置为作为第二数据接收第一输出数据(例如,69)或从第一输出数据(例如,69)得到的数据。
91.第一处理块(例如,50)对于第一输出数据的每个通道可以包括:
92.可学习层(例如,71,72,73)的条件集,被配置为处理目标数据(例如,12)以获得条件特征参数(例如,74,75);以及
93.样式元件(例如,77),被配置为将条件特征参数(例如,74,75)应用于第一数据(例如,15,59a)或归一化的第一数据(例如,59,76’)。
94.第二处理块(例如,45)可被配置为将第二数据(例如,69)的多个通道(例如,47)组合以获得音频信号(例如,16)。
95.还提出了一种方法,例如,用于由音频发生器(例如,10)从输入信号(例如,14)和目标数据(例如,从文本获得)生成音频信号(例如,16),目标数据(例如,12)表示音频信号(例如,16),方法包括:
96.通过第一处理块(例如,50,50a-50h)接收从输入信号(例如,14)得到的第一数据(例如,16559,59a,59b);
97.对于第一输出数据(例如,59b,69)的每个通道:
98.通过第一处理块(例如,50)的可学习层(例如,71、72、73)的条件集处理目标数据(例如,12),以获得条件特征参数(例如,74、75),目标数据可以从文本得出;以及通过第一处理块(例如,50)的样式元件(例如,77),将条件特征参数(例如,74、75)应用于第一数据(例如,15、59)或归一化的第一数据(例如,76’);
99.通过第一处理块(例如,50)输出包括多个通道(例如,47)的第一输出数据(例如,69);
100.通过第二处理块(例如,45)作为第二数据接收第一输出数据(例如,69)或从第一输出数据(例如,69)得出的数据;以及
101.通过第二处理块(例如,45),将第二数据的多个通道(例如,47)组合以获得音频信号(例如,16)。
102.还提出了一种训练用于音频生成的神经网络的方法,其中神经网络:
103.从表示要生成的音频数据(例如16)的输入序列(例如14)在给定时间步长输出音频样本;
104.被配置为对噪声向量(例如14)进行整形,以便使用输入代表序列(例如12)创建输出音频样本(例如16),以及
105.训练被设计为优化损失函数(例如140)。
106.还提出了一种生成音频信号(例如16)的方法,包括数学模型,其中数学模型被配置为从表示要生成的音频数据(例如16)的输入序列(例如12)以给定时间步长输出音频样本。数学模型可以对噪声向量(例如14)进行整形,以便使用输入代表序列(例如12)创建输出音频样本。
107.正是在此背景下,我们提出了stylemelgan(例如,音频发生器10),这是一种轻量级的神经声码器,允许以低计算复杂度合成高保真语音。stylemelgan是完全卷积的前馈模型,它使用时间自适应去归一化(tade)(例如图4中的60a和60b,以及图3中的60)经由目标语音波形的声学特征对低维噪声向量(例如128x1向量)进行样式化(例如在77处)。该架构允许高度并行的生成,在控制处理单元(cpu)和图形处理单元(gpu)上都比实时快几倍。为了高效和快速的训练,我们可以使用多尺度频谱重建损失和由多个鉴别器(例如,132a-132d)计算的对抗损失,并使用随机窗口化(例如,窗口105a,105b,105c,105d),多个鉴别器在多个频带中评估语音信号16。mushra和p.800听力测试示出,stylemelgan(例如,音频发生器10)在复制合成和tts场景中都优于已知的现有神经声码器。
108.特别地,本技术提出了一种用于生成高质量语音16的神经声码器,其可以基于生成对抗网络(gan)。这个解决方案,这里被称为stylemelgan(并且,例如,在音频发生器10中
实现),是轻量级的神经声码器,其允许以低计算复杂度合成高质量语音16。stylemelgan是一种前馈的全卷积模型,它使用时间自适应去归一化(tade)来使用例如目标语音波形的梅尔谱图(12)样式化(例如在块77)潜在噪声表示(例如69)。它允许高度并行的生成,在cpu和gpu上都比实时快几倍。对于训练,可以使用多尺度频谱重建损失,然后是对抗损失。这使得能够在单个gpu上进行不到2天的训练后获得能够合成高质量输出的模型。
109.本发明的潜在应用和益处如下:
110.本发明可应用于文本到语音,并且得到的质量,即用于tts和复制合成的生成的语音质量接近于wavenet和自然语音。它还提供了快速的训练,使得模型易于快速重新训练,具有个性化。它使用较少的内存,因为它是相对较小的神经网络模型。最后,提出的发明在复杂性方面提供了好处,即它具有非常好的质量/复杂性权衡。
111.本发明还可以应用于语音增强,为从噪声语音生成干净语音提供低复杂度和鲁棒性的解决方案。
112.本发明还可以应用于语音编码,其中它可以通过仅传输调节神经声码器所需的参数来显著降低比特率。此外,在此应用中,基于轻量级神经声码器的解决方案适用于嵌入式系统,尤其适用于配备gpu或神经处理单元(npu)的即将到来的(终端)用户设备(ue)。
113.本技术的实施例涉及音频发生器,被配置为从输入信号和目标数据生成音频信号,目标数据表示音频信号(例如,从文本得出),音频发生器包括第一处理块,被配置为接收从输入信号得到的第一数据并输出第一输出数据,其中第一输出数据包括多个通道,以及第二处理块,被配置为接收作为第二数据第一输出数据或从第一输出数据得到的数据,其中,第一处理块包括:用于第一输出数据的每个通道的可学习层的条件集,该可学习层的条件集被配置为处理目标数据以获得条件特征参数;以及样式元件,被配置为将条件特征参数应用于第一数据或归一化的第一数据;以及其中第二处理块被配置为组合第二数据的多个通道以获得音频信号。
114.根据一个实施例,可学习层的条件集由一个或两个卷积层组成。
115.根据一个实施例,第一卷积层被配置为使用第一激活函数对目标数据或上采样的目标数据进行卷积以获得第一卷积数据。
116.根据一个实施例,可学习层的条件集和样式元件是包括一个或多个残差块的神经网络的残差块中的权重层的一部分。
117.根据一个实施例,音频发生器进一步包括被配置为归一化第一数据的归一化元件。例如,归一化元件可以将第一数据归一化为零均值和单位方差的正态分布。
118.根据一个实施例,音频信号为语音音频信号。
119.根据一个实施例,优选地通过非线性插值,以2的因子或2的倍数或2的幂对目标数据进行上采样。在某些示例中,相反地,可以使用大于2的因子。
120.根据一个实施例,第一处理块进一步包括可学习层的另一集,被配置为使用第二激活函数处理从第一数据得出的数据,其中第二激活函数是门控激活函数。
121.根据一个实施例,可学习层的另一集由一个或两个(或甚至更多个)卷积层组成。
122.根据一个实施例,第二激活函数是softmax门控双曲正切tanh函数
123.根据一个实施例,第一激活函数是渗漏整流线性单元(渗漏relu)函数。
124.根据一个实施例,卷积操作以最大膨胀因子2运行。
125.根据一个实施例,音频发生器包括八个第一处理块和一个第二处理块。
126.根据一个实施例,第一数据具有比音频信号更低的维数。第一数据可具有低于音频信号的第一维度或至少一个维度。第一数据可以具有比音频信号低一个维度,但具有比音频信号多的多个通道。第一数据在所有维度上的样本总数可以低于音频信号。
127.根据一个实施例,目标数据是谱图,优选是梅尔谱图,或比特流。
128.目标数据可以从文本得到。音频发生器可以被配置为从文本得出目标数据。目标数据可以包括,例如,文本数据(字符,单词等),语言学特征,声学特征等中的至少一个。
129.在替换示例中,目标数据可以是音频数据的压缩表示,或者目标数据是降级的音频信号。
130.进一步的实施例涉及通过音频发生器从输入信号和目标数据生成音频信号的方法,目标数据表示音频信号(例如,从文本得出),方法包括通过第一处理块接收从输入信号得到的第一数据;对于第一输出数据的每个通道,通过第一处理块的可学习层的条件集处理目标数据,以获得条件特征参数;以及通过第一处理块的样式元件,将条件特征参数应用于第一数据或归一化的第一数据;通过第一处理块输出包括多个通道的第一输出数据;通过第二处理块作为第二数据接收第一输出数据或从第一输出数据得出的数据;以及通过第二处理块,将第二数据的多个通道组合以获得音频信号。在一些示例中,方法可以从文本得出目标数据。
131.归一化可以包括,例如,将第一数据归一化为零均值和单位方差的正态分布。
132.方法也可以被提供来自音频发生器的任何特征或特征组合。
133.进一步的实施例涉及用于训练如上所述的音频发生器的方法,其中训练包括重复如上所述的任一个方法中的步骤一次或多次。
134.根据一个实施例,用于训练的方法进一步包括由至少一个评估器评估所生成的音频信号,并根据评估的结果调整音频发生器的权重,评估器优选为神经网络。
135.根据一个实施例,用于训练的方法进一步包括根据评估的结果调整评估器的权重。
136.根据一个实施例,训练包括优化损失函数。
137.根据一个实施例,优化损失函数包括计算所生成的音频信号和参考音频信号之间的固定度量。
138.根据一个实施例,计算固定度量包括计算所生成的音频信号和参考信号之间的一个或多个频谱失真。
139.根据一个实施例,在所生成的音频信号和参考信号的频谱表示的幅度或对数幅度上,和/或在不同的时间或频率分辨率上,计算一个或多个频谱失真。
140.根据一个实施例,优化损失函数包括通过由一个或多个评估器随机提供和评估所生成的音频信号的表示或参考音频信号的表示来得到一个或多个对抗度量,其中评估包括将所提供的音频信号分类为指示音频信号的自然度的预训练分类水平的预定数量的类别。
141.根据一个实施例,优化损失函数包括通过一个或多个评估器计算固定度量和得出对抗度量。
142.根据一个实施例,首先使用固定度量来训练音频发生器。
143.根据一个实施例,四个评估器得出四个对抗度量。
144.根据一个实施例,评估器在通过滤波器组对生成的音频信号的表示或参考音频信号的表示进行分解后操作。
145.根据一个实施例,每个评估器接收生成的音频信号的表示或参考音频信号的表示的一个或几个部分作为输入。
146.根据一个实施例,通过使用随机窗口函数从输入信号采样随机窗口而生成信号部分。
147.根据一个实施例,随机窗口的采样对每个评估器重复多次。
148.根据一个实施例,为每个评估器采样随机窗口的次数与生成的音频信号的表示或参考音频信号的表示的长度成比例。
149.进一步的实施例涉及包括用于处理设备的程序的计算机程序产品,该程序包括当程序在处理设备上运行时用于执行本文所述方法的步骤的软件代码部分。
150.根据一个实施例,计算机程序产品包括软件代码部分存储在其上的计算机可读介质,其中程序可直接加载到处理设备的内部存储器中。
151.进一步的实施例涉及一种生成音频信号的方法,包括数学模型,其中数学模型被配置为从表示要生成的音频数据的输入序列(例如,从文本得出)以给定时间步长输出音频样本,其中数学模型被配置为对噪声向量进行整形以便使用输入代表序列创建输出音频样本。
152.根据一个实施例,使用音频数据训练数学模型。根据一个实施例,数学模型是神经网络。根据一个实施例,网络是前馈网络。根据一个实施例,网络是卷积网络。
153.根据一个实施例,噪声向量可以具有比要生成的音频信号更低的维数。第一数据可具有低于音频信号的第一维度或至少一个维度。第一数据可以具有低于音频信号的所有维度上的样本总数。第一数据可以具有比音频信号低一个维度,但具有比音频信号多的多个通道。
154.根据一个实施例,使用时间自适应去归一化(tade)技术用于调节使用输入代表序列的数学模型,并且因此用于对噪声向量进行整形。
155.根据一个实施例,修改的softmax门控tanh激活神经网络的每一层。
156.根据一个实施例,卷积操作以最大膨胀因子2运行。
157.根据一个实施例,对噪声向量以及输入代表序列进行上采样以获得目标采样率下的输出音频。
158.根据一个实施例,在数学模型的不同层中依次执行上采样。
159.根据一个实施例,每层的上采样因子为2或2的倍数,诸如2的幂。在一些示例中,上采样因子的值可以通常大于2。
160.所生成的音频信号通常可以用于文本到语音应用,其中输入代表序列从文本得到。
161.根据一个实施例,所生成的音频信号用于音频解码器,其中输入代表序列是要传输或存储的原始音频的压缩表示。
162.根据一个实施例,所生成的音频信号用于改善降级的音频信号的音频质量,其中输入代表序列从降级的信号得到。
163.进一步实施例涉及训练用于音频生成的神经网络,其中神经网络从表示要生成的
音频数据的输入序列以给定的时间步长输出音频样本,其中神经网络被配置为对噪声向量进行整形,以便使用输入代表序列创建输出音频样本,其中神经网络如上所述被设计,以及其中训练被设计为优化损失函数。
164.根据一个实施例,损失函数包括在生成的音频信号和参考音频信号之间计算的固定度量。
165.根据一个实施例,固定度量是在所生成的音频信号和参考信号之间计算的一个或多个频谱失真。
166.根据一个实施例,在所生成的音频信号和参考信号的频谱表示的幅度或对数幅度上计算一个或多个频谱失真。
167.根据一个实施例,在不同的时间或频率分辨率上计算形成固定度量的一个或多个频谱失真。
168.根据一个实施例,损失函数包括由附加判别神经网络得到的对抗度量,其中,判别神经网络接收生成的音频信号的表示或参考音频信号的表示作为输入,并且其中,判别神经网络被配置为评估生成的音频信号是否真实。
169.根据一个实施例,损失函数包括固定度量和由附加的判别神经网络得出的对抗度量。
170.根据一个实施例,首先仅使用固定度量来训练生成音频样本的神经网络。
171.根据一个实施例,对抗度量由4个判别神经网络得到。
172.根据一个实施例,判别神经网络在通过滤波器组对输入音频信号进行分解后操作。
173.根据一个实施例,每个判别神经网络接收输入音频信号的一个或多个随机窗口版本作为输入。
174.根据一个实施例,对每个判别神经网络重复多次随机窗口的采样。
175.根据一个实施例,对于每个判别神经网络,采样随机窗口的次数与输入音频样本的长度成比例。
具体实施方式
176.图8示出了音频发生器10的示例。音频发生器10可以将文本112转换为输出音频信号16。可以将文本112转换为目标数据12(见下文),目标数据12在一些示例中可以被理解为音频表示(例如,谱图,或更一般的谱图,mfcc,如对数谱图,或谱图,或mfcc或梅尔谱图,或其他声学特征)。目标数据12可用于为输入信号14(例如噪声)加条件,以便处理输入信号14使其成为不可听的语音。音频合成块(文本分析块)1110可以将文本112转换为音频表示(例如,谱图,或更一般的谱图,mfcc,如对数谱图,或谱图,或mfcc或梅尔谱图,或其他声学特征),例如在目标数据12设置的条件下。例如,音频合成块1110可负责处理语音的发音、相位、语调、持续时间等中的至少一个。音频合成块1110(文本分析块)可执行至少一项任务,诸如文本归一化、分词、韵律预测和字形到音素的转换。随后,可将生成的目标数据12输入到波形合成块1120(例如声码器)中,该波形合成块可基于从从文本112中获得的目标数据12获得的条件,例如从输入信号14生成波形16(输出音频信号)。
177.然而,需要注意的是,在一些示例中,块1110不是发生器10的一部分,但是块1110
可以位于发生器10的外部。在一些示例中,块1110可以被细分为多个子块(并且在一些特定情况下,子块中的至少一个可以是发生器10的一部分,并且子块中的至少一个可以位于发生器10的外部)。
178.一般来说,输入到块1110(或在某些示例中为发生器10)的输入可以是文本(或从文本得出的其他输入),其形式可以为下列中的至少一个:
179.·
文本112(例如,ascii码)
180.·
至少一个语言学特征(例如,音素、单词韵律、语调、短语停顿和填充停顿中至少一个,例如,从文本获得)
181.·
至少一个声学特征(例如,对数谱图,mfcc和梅尔谱图中的至少一个,例如,从文本获得)。
182.输入可以被处理(例如由块1110)以获得目标数据12。根据不同的实施例,块1110可以进行处理,以获得下述形式中的至少一种形式的目标数据12(从文本得出):
183.·
文本的字符或单词中的至少一个
184.·
至少一个语言学特征(例如,音素、单词韵律、语调、短语停顿和填充停顿中的至少一个,例如,从文本获得)
185.·
至少一个声学特征(例如,对数谱图,mfcc和梅尔谱图中的至少一个,例如,从文本获得)。
186.目标数据12(无论是以字符、语言学特征或声学特征的形式)将由发生器10(例如,由波形合成块、声码器1120)用于调节对输入信号14的处理,从而生成输出音频信号(声波)。
187.图10示出了实例化块1110的几种可能性的概要表:
188.a)在情况a中,输入到块1110的输入为纯文本112,并且块1110的输出(目标数据12)为文本的字符或单词(也是文本)中的至少一个。在情况a中,块1110对文本112的元素执行文本112的选择。随后,目标数据12(以文本112的元素的形式)将调节对输入信号14的处理,以获得输出信号16(声波)。
189.b)在情况b中,输入到块1110的输入为纯文本112,并且从块1110的输出(目标数据12)包括至少一个语言学特征,例如,从文本112获得的音素、单词韵律、语调、短语中断和填充停顿等中的语言学特征。在情况b中,块1110对文本112的元素进行语言分析,从而获得音素、单词韵律、语调、短语中断和填充停顿等中的至少一个语言学特征。随后,目标数据12(音素、单词韵律、语调、短语中断和填充停顿等中的至少一个的形式)将调节对输入信号14的处理,以获得输出信号16(声波)。
190.c)在情况c中,输入到块1110的输入为纯文本112,并且从块1110的输出(目标数据12)包括至少一个声学特征,例如,从文本获得的对数谱图或mfcc和梅尔谱图中的一个声学特征。在情况c中,块1110对文本112的元素执行声学分析,从而获得从文本112获得的对数谱图或mfcc和梅尔谱图中的至少一个声学特征。随后,目标数据12(例如,从文本获得的对数谱图、mfcc、梅尔谱图等中的至少一个声学特征的形式)将调节对输入信号14的处理,以获得输出信号16(声波)。
191.d)在情况d中,输入到块1110的输入是语言学特征(例如,音素、词韵律、语调、断句和填充停顿中的至少一个),并且输出也是经处理的语言学特征(例如,音素、词韵律、语调、
断句和填充停顿中的至少一个)。随后,目标数据12(音素、单词韵律、语调、短语中断和填充停顿等中的至少一个的形式)将调节对输入信号14的处理,以获得输出信号16(声波)。
192.e)在情况e中,输入到块1110的输入是语言学特征(例如,音素、单词韵律、语调、短语中断和填充停顿中的至少一个),并且来自块1110的输出(目标数据12)包括至少一个声学特征,例如,从文本获得的对数谱图或mfcc和梅尔谱图中的一个声学特征。在情况e中,块1110对文本112的元素执行声学分析,以获得对数谱图或mfcc和梅尔谱图中的至少一个声学特征。随后,目标数据12(例如,从文本中获得的对数谱图、mfcc、梅尔谱图等中的至少一个声学特征的形式)将调节对输入信号14的处理,以获得输出信号16(声波)。
193.f)在情况f中,输入到块1110的输入是声学特征的形式(例如从文本获得的对数谱图,mfcc,梅尔谱图等等中的至少一个声学特征的形式),和输出(目标数据12)是经处理的声学特征的形式(例如从文本获得的对数谱图,mfcc,梅尔谱图等等中的至少一个声学特征的形式)。随后,目标数据12(例如,以经处理的声学特征的形式,如从文本获得的对数谱图、mfcc、梅尔谱图等中的声学特征中的至少一个)将调节对输入信号14的处理,以获得输出信号16(声波)。
194.图9a示出了示例,其中块1110包括提供中间目标数据212的子块1112(文本分析块),以及其下游的生成以声学特征为形式的目标数据12的子块1114(例如,使用声学模型的音频合成)。因此,在图9a中,如果子区块1112和1114都是发生器10的一部分,我们处于情况c。如果子区块1112不是发生器10的一部分,但子区块1114是发生器10的一部分,我们处于情况e。
195.图9b示出示例,其中,块1110仅进行文本分析,并以语言学特征的形式提供目标数据12。因此,在图9b中,如果块1110是发生器10的一部分,则我们处于情况b。
196.图9c示出示例,其中不存在块1110,目标数据112为语言学特征的形式。
197.通常,在朝向比输入到块1110的输入更细化的目标数据的处理中,块1110(如果存在)操作以越来越多地细化文本(或从文本获得的其他输入)。块1110还可以使用原始文本中可能不存在的约束(例如,注意力函数、男人/女人的声音、口音、情感特征等)。这些约束通常可以由用户提供。
198.需要注意的是,在上面和下面的情况下,块1110(或者,如果存在,其任何子块,诸如块1112和1114中的任何一个)可以使用统计模型,例如执行文本分析和/或使用声学模型。另外或作为替代,块1110(或者,如果存在,其子块中的任何一个,诸如块1112和1114中的任何一个)可以使用可学习模型,例如执行文本分析和/或使用声学模型。可学习模型可以例如基于神经网络、马尔可夫链等。作为进一步补充或进一步替代,块1110(或者,如果存在,其子块中的任何一个,诸如块1112和1114中的任何一个)可以利用基于声学模型和/或执行文本分析的基于规则的算法。
199.在一些示例中,块1110(或者,如果存在,它的任何子块,诸如块1112和块1114中的任何一个)可以确定性地得出目标数据。因此,可能一些子块是可学习的,而其他子块是确定性的。
200.块1110也被称为“文本分析块”(例如,当将文本转换为至少一个语言学特征时)或“音频合成块”(例如,当将文本或至少一个语言学特征转换为至少一个声学特征,诸如谱图时)。无论如何,根据实施例,目标数据12可以是文本、语言学特征或声学特征的形式。
201.值得注意的是,图10示出了通常不提供转换的一些组合。这是因为从详细特征到简单特征的转换(例如,从语言特征到文本,或从声学特征到文本或语言特征)是不可想象的。
202.图6示出了音频发生器10的示例,其可以例如根据stylemelgan生成(例如,合成)音频信号(输出信号)16。在图6中,可以例如通过文本分析块1110处理文本112以获得目标数据12。随后,在波形合成块1120处,可使用目标数据12处理输入信号14(例如噪声)以获得可听音频信号16(声学波形)。获得的目标数据12可以从文本得出。
203.特别地,输出音频信号16可以基于输入信号14(也称为潜在信号,并且可以是噪声,例如白噪声)和目标数据12(也称为“输入序列”,并且在一些实例中,从文本得出)生成,并且目标数据12例如可在块1110从文本112获得。例如,目标数据12可以包括(例如是)谱图(例如,梅尔谱图),该梅尔谱图提供例如将时间样本序列映射到梅尔刻度上。另外或可替代地,目标数据12可以包括(例如是)比特流。例如,目标数据可以是或包括将在音频中再现的文本(例如,文本到语音)(或者更一般地,从文本得出)。通常要对目标数据12进行处理,以获得可被人类听者识别为自然的语音。输入信号14可以是噪声(其本身不携带有用信息),例如白噪声,但是,在发生器10中,从噪声中提取的噪声向量被样式化为具有由目标数据12调节的声学特征的噪声向量(例如在77处)。最后,输出音频信号16将被人类听众理解为语音。如图1所示,噪声向量14可以是128x1向量(一个单个样本,例如时域样本或频域样本,以及128个通道)。在其他示例中可使用其他长度的噪声向量14。
204.第一处理块50如图6所示。如图所示(例如,在图1中),第一处理块50可以由多个块(在图1中,块50a、50b、50c、50d、50e、50f、50g、50h)中的每一个实例化。块50a-50h可被理解为形成一个单个块40。将示出,在第一处理块40、50中,可学习层(例如71、72、73)的条件集可用于处理目标数据12和/或输入信号14。因此,可以在训练期间例如通过卷积获得条件特征参数74,75(在图3中也称为gammaγ和betaβ)。因此,可学习层71-73可以是学习网络的权重层的一部分,或者更一般地说,是另一个学习结构。第一处理块40、50可以包括至少一个样式元件77。至少一个样式元件77可以输出第一输出数据69。至少一个样式元件77可将条件特征参数74、75应用于输入信号14(潜在的)或从输入信号14获得的第一数据15。
205.每个块50处的第一输出数据69位于多个通道中。音频发生器10可以包括第二处理块45(在图1中示出为包括块42、44、46)。第二处理块45可以被配置为组合第一输出数据69(作为第二输入数据或第二数据被输入)的多个通道47,以在一个单个通道中但在采样序列中获得输出音频信号16。
[0206]“通道”不是在立体声的背景下理解的,而是在神经网络(例如卷积神经网络)的背景下理解的。例如,输入信号(例如潜在噪声)14可以在128个通道中(在时域的表示中),因为提供了通道序列。例如,当信号具有176个采样和64个通道时,可以将其理解为176列64行的矩阵,而当信号具有352个采样和64个通道时,可以将其理解为352列64行的矩阵(其他示意图也是可能的)。因此,所生成的音频信号16(在图1中生成1x22528行矩阵,其中22528可以被另一个其他数字取代)可以理解为单声道信号。如果要生成立体声信号,则只需对每个立体声通道重复公开的技术,以获得随后被混合的多个音频信号16。
[0207]
至少原始输入信号14和/或生成的语音16可以是向量。相反,每个块30和50a-50h,42,44的输出通常具有不同的维度。第一数据可具有低于音频信号的第一维度或至少一个
维度。第一数据可以具有低于音频信号的所有维度上的样本总数。第一数据可以具有比音频信号低一个维度,但具有比音频信号多的多个通道。在每个块30和50a-50h,可以对从噪声14向语音16演变的信号进行上采样。例如,在50a-50h块中第一块50a之前的上采样块30处,执行88次上采样。上采样的示例可以包括,例如,以下序列:1)相同值的重复,2)插入零,3)另一个重复或插入零 线性滤波,等等。
[0208]
生成的音频信号16通常可以是单通道信号(例如1x22528)。如果需要多个音频通道(例如,用于立体声播放),则所要求的程序原则上应多次迭代。
[0209]
类似地,目标数据12原则上也可以在一个单通道中(例如,如果它是文本,或者更一般地,如果它从文本得出,例如在情况a中,或者例如在图9c中)或在多个通道中(例如在谱图中,例如梅尔谱图,例如从文本得出,例如当在情况c、e、f中)。在任何情况下,可以对其进行上采样(例如,以2的因子、2的幂、2的倍数或大于2的值)以适应沿后续层(50a-50h,42)演变的信号的维度(59a,15,69),例如,以获得适应于信号维度的维度中的条件特征参数74,75。
[0210]
当第一处理块50在例如至少多个块50a-50h中实例化时,例如,对于多个块50a-50h,通道数量可以保持相同。第一数据可具有低于音频信号的第一维度或至少一个维度。第一数据可以具有低于音频信号的所有维度上的样本总数。第一数据可以具有比音频信号低的一个维度,但具有比音频信号多的多个通道。
[0211]
在随后的块处的信号可以具有彼此不同的维度。例如,样本可以被越来越多次地采样,例如,从88个样本到最后一个块50h处的22528个样本。类似地,目标数据12也在每个处理块50处被上采样。因此,条件特征参数74、75可适应待处理信号的样本数量。因此,目标数据12提供的语义信息在随后的层50a-50h中不丢失。
[0212]
要理解的是,可以根据生成对抗网络(gan)的范例执行示例。gan包括gan发生器11(图1)和gan鉴别器100(图2),也可以被理解为波形合成块1120的一部分。gan发生器11试图生成尽可能接近真实信号的音频信号16。gan鉴别器100应识别生成的音频信号是真实的(如图2中的真实音频信号104)还是假的(如生成的音频信号16)。gan发生器11和gan鉴别器100都可以被获得为神经网络。gan发生器11应使损耗最小化(例如,通过梯度方法或其他方法),并通过考虑gan鉴别器100的结果来更新条件特征参数74,75。gan鉴别器100应减少自身的鉴别损失(例如,通过梯度的方法或其他方法),并更新其自身的内部参数。因此,训练gan发生器11以提供越来越好的音频信号16,而训练gan鉴别器100从gan发生器11生成的假音频信号中识别真实信号16。一般而言,可以理解,gan发生器11可以包括发生器10的功能,而至少不包括gan鉴别器100的功能。因此,在上述大部分内容中,可以理解,除了鉴别器100的特征外,gan发生器11和音频发生器10可以具有或多或少相同的特征。音频发生器10可以包括作为内部组件的鉴别器100。因此,gan发生器11和gan鉴别器100可以共同构成音频发生器10。在不存在gan鉴别器100的示例中,音频发生器10可以由gan发生器11唯一地构成。
[0213]
正如“可学习层的条件集”所解释的那样,音频发生器10可以根据条件gan的范例获得,例如基于条件信息。例如,条件信息可以由目标数据(或其上采样版本)12构成,从中训练层71-73(权重层)的条件集并获得条件特征参数74,75。因此,样式元件77受可学习层71-73限制。
[0214]
这些示例可以基于卷积神经网络。例如,可以是3x3矩阵(或4x4矩阵等)的小矩阵
(例如,滤波器或核)沿着更大的矩阵进行卷积(褶积)(例如,通道x采样潜在或输入信号和/或谱图和/或谱图或上采样谱图或更一般的目标数据12),例如暗示滤波器(核)的元素和更大的矩阵(激活图,或激活信号)的元素之间的组合(例如,乘积的乘法和和;点积等)。在训练期间,获得(学习)滤波器(核)的元素,这些元素是使损失最小化的元素。在推理期间,使用在训练期间获得的滤波器(核)的元素。卷积的示例位于块71-73、61a、61b、62a、62b(见下文)。在块有条件(如图3中的块60)的情况下,则卷积不一定应用于从输入信号14经过中间信号59a(15)、69等向音频信号16演进的信号,而可以应用于目标信号14。在其他情况下(例如,在块61a、61b、62a、62b处),卷积可以不是有条件的,并且可以例如直接应用于从输入信号14向音频信号16演进的信号59a(15)、69等。从图3和图4可以看出,条件卷积和无条件卷积都可以被执行。
[0215]
在一些示例中,可以有卷积下游的激活函数(relu,tanh,softmax等),其可以根据预期效果而有所不同。relu可以映射0和卷积时得到的值之间的最大值(在实际中,如果是正的,保持相同的值,如果是负的,输出0)。渗漏relu可以在x》0时输出x,在x≤0时输出0.1*x,x是卷积得到的值(在一些示例中可以使用另一个值代替0.1,例如在0.1
±
0.05范围内的预定值)。tanh(可以在例如在块63a和/或63b处实现)可以提供卷积时获得的值的双曲正切,例如:
[0216]
tanh(x)=(e
x-e-x
)/(e
x
e-x
),
[0217]
其中x是卷积时获得的值(例如在块61a和/或61b处)。softmax(例如,在块64a和/或64b处应用)可以将指数应用于卷积的结果的元素中的每个元素(例如,在块62a和/或62b中获得的),并通过除以指数的和来对其进行归一化。softmax(例如在64a和/或64b处)可以为矩阵中由卷积(例如在62a和/或62b处)生成的条目提供概率分布。在应用激活函数之后,在一些示例中可以执行池化步骤(未在图中示出),但在其他示例中可以避免此步骤。
[0218]
图4示出了,也可以有softmax门控tanh函数,例如,将tanh函数的结果(例如,在63a和/或63b处获得)与softmax函数的结果(例如,在64a和/或64b处获得)相乘(例如,在65a和/或65b处获得)。
[0219]
多层卷积(例如可学习层的条件集)可以是一个接一个和/或彼此并行的,以提高效率。如果提供了激活函数和/或池化的应用,它们也可以在不同的层中重复(或者,例如,可以将不同的激活函数应用于不同的层)。
[0220]
输入信号14(例如噪声)在不同的步骤被处理,以成为生成的音频信号16(例如在由可学习层71-73的条件集设置的条件下,以及在由可学习层71-73的条件集学习的参数74、75上)。因此,输入信号应被理解为在处理方向上(图6中从14到16)朝着成为生成的音频信号16(例如语音)演进。将基本上基于目标信号12和训练来生成条件(以达到最优选的参数集74,75)。
[0221]
还需要注意的是,输入信号(或其任何演进)的多个通道可以被认为具有一组可学习层和与之相关的样式元件。例如,矩阵74和75的每一行与输入信号(或其演进之一)的特定通道相关联,并且因此从与特定通道相关联的特定可学习层获得。类似地,可以认为样式元件77由多个样式元件组成(每个元件用于输入信号x、c、12、76、76
′
、59、59a、59b等的每一行)。
[0222]
图1示出了音频发生器10的示例(其可以体现图6的音频发生器10),并且其还可以
和加法器65c处的加法可以被理解为实例化这样的事实,即每个块50(50a-50h)处理对残差信号的操作,然后将其添加到信号的主要部分。因此,块50a-50h中的每个可以被认为是残差块。
[0232]
值得注意的是,加法器65c处的加法不一定需要在残差块50(50a-50h)内执行。可以执行多个残差信号65b’(每个信号由每个残差块50a-50h输出)的单个相加(例如,在第二处理块45中的加法器块处)。因此,不同的残差块50a-50h可以彼此并行操作。
[0233]
在图4的示例中,每个块50可以重复其卷积层两次(例如,首先在副本600处,包括块60a、61a、62a、63a、64a、65a中的至少一个,并获得信号59b;然后,在副本601处,包括60b、61b、62b、63b、64b、65b块中的至少一个,并获取信号65b',信号65b'可以添加到主分量59a'中)。
[0234]
对于每个副本(600,601),将可学习层71-73的条件集和样式元件77应用于从输入信号16演进到音频输出信号16的信号(例如,每个块50两次)。在tade块60a处对第一副本600处的第一数据59a执行第一时间自适应去归一化(tade)。在目标数据12设定的条件下,tade块60a对第一数据59a(输入信号或,例如,经处理的噪声)进行调制。在第一tade块60a中,可以在上采样块70处执行目标数据12的上采样,以获得目标数据12的上采样版本12’。上采样可以通过非线性插值获得,例如,使用因子2、2的幂、2的倍数或大于2的其他值。因此,在一些示例中,可以使谱图12'具有与要以谱图为条件的信号(76,76',x,c,59,59a,59b等)相同的维度(例如符合)。对经处理的噪声(第一数据)(76、76
′
、x、c、59、59a、59b等)应用样式信息可以在块77(样式元件)处执行。在随后的副本601中,可以将另一个tade块60b应用于第一副本600的输出59b。图3提供了tade模块60(60a,60b)的示例(另见下文)。在调制第一数据59a之后,进行卷积61a和62a。随后,还执行激活函数tanh和softmax(例如构成softmax门控tanh函数)(63a,64a)。激活函数63a和64a的输出在乘法器块65a处相乘(例如,以实例化门控),以获得结果59b。如果使用两个不同的副本600和601(或使用两个以上副本),则60a,61a,62a,63a,64a,65a的通路被重复。
[0235]
在示例中,分别位于tade块60a和60b的下游的61b和62b处的第一和第二卷积可以以核中相同数量的元素执行(例如,9,例如,3x3)。然而,第二卷积61b和62b可以有2的膨胀因子。在示例中,卷积的最大膨胀因子可以是2。
[0236]
图3示出了tade块60(60a,60b)的示例。可以看出,目标数据12可以被上采样,例如,以符合输入信号(或由此演进而来的信号,如59、59a、76’,也称为潜在信号或激活信号)。在这里,可以执行卷积71,72,73(目标数据12的中间值用71'指示),以获得参数γ(gamma,74)和β(beta,75)。在71,72,73的任何处的卷积也可能需要整流线性单元relu,或渗漏整流线性单元(渗漏relu)。参数γ和β可以具有与激活信号相同的维度(被处理以从输入信号14演变为生成的音频信号16的信号,在归一化形式下在这里表示为x,59或76')。因此,当激活信号(x,59,76
′
)具有两个维度时,γ和β(74和75)也具有两个维度,并且它们中的每个与激活信号可重叠(γ和β的长度和宽度可以与激活信号的长度和宽度相同)。在样式元件77处,将条件特征参数74和75应用于激活信号(第一数据59a或由乘法器65a输出的59b)。然而,应当注意,激活信号76’可以是第一数据59,59a,59b(15)的归一化版本(在实例归一化块76处为10)。还需要注意的是,样式元件77中示出的公式(γx β)可以是逐元素乘积,而不是卷积乘积或点积(事实上,γx β也被指示为x
⊙
γ β,其中
⊙
指示元素乘法)。
[0237]
在样式元件77之后,输出信号。卷积72和73的下游不一定有激活函数。还应注意,参数γ(74)可被理解为方差,以及β(75)可被理解为偏差。此外,图1中的块42可以实例化为图3中的块50。然后,例如,卷积层44将通道数量减少到1,然后,执行tanh 56以获得语音16。
[0238]
图7示出了块50a-50h中的一个的副本600和601中的一个中演进的示例。
[0239]
目标数据14(例如梅尔谱图);以及
[0240]
潜在噪声c(12),也用59a指示,或者作为从输入信号12向生成的音频信号16演变的信号。
[0241]
值得注意的是,61a、61b、62a、62b可以是被配置为使用激活函数(例如63a、64a、63b、64b)(其是门控激活函数(第二激活函数))处理从第一数据(例如因此从输入信号14)得出的数据的可学习层的集合(或其一部分)。此可学习层的集合可以由一个或两个或甚至更多个卷积层组成。第二激活函数可以是门控激活函数(例如tanh和softmax)。此特征可以与以下事实相结合:第一激活函数(用于获得第一卷积数据71')是relu或渗漏relu。
[0242]
可以执行以下程序(或其步骤中的至少一个):
[0243]
·
从输入,诸如文本112(例如,美国信息交换标准代码ascii代码或另一类型的代码),生成目标数据12(例如,文本特征、语言学特征或声学特征,诸如梅尔谱图)(可以使用不同类型的目标数据)。
[0244]
·
目标数据(例如谱图)12经过以下步骤中的至少一个:
[0245]
·
在上采样块70处被采样,以得到上采样谱图12
′
;
[0246]
·
在卷积层71-73(权重层的一部分)处,执行卷积(例如,沿着上采样谱图12'卷积核12a);
[0247]
·
获得(学习得到)γ(74)和β(75);
[0248]
·
将γ(74)和β(75)应用(例如通过卷积)到从输入信号14和生成的音频信号16演进而来的潜在信号59a(15)。
[0249]
tts
[0250]
文本到语音(tts)(例如,使用块1110执行)旨在合成给定文本112的可理解和自然发声的语音16。它可能在工业上有广泛的应用,特别是在机器对人通信方面。
[0251]
本发明的音频发生器10在最后阶段包括不同的组件,其中包括声码器1120,并且主要包括用于转换音频波形16中的文本特征、语言学特征或声学特征的块。
[0252]
特别地,在块1110处,可以分析文本112(输入)并且可以从文本112提取语言学特征,例如通过文本分析模块(子块)1112,如图9a所示。文本分析可以包括,例如,多个任务,如文本归一化、分词、韵律预测和字形到音素(另见图8)。然后,通过声学模型(例如,通过子块1114),将这些语言学特征(可以充当中间目标数据212)转换为声学特征,例如mfcc、基频、梅尔谱图,或这些特征的组合,这些特征可以构成图1和图3-8的目标数据12。
[0253]
值得注意的是,此流水线可以被端到端处理取代,例如通过引入dnn。例如,可以直接从语言学特征调节神经声码器1120(例如,在图10的情况b和d中),或者声学模型可以直接处理字符,绕过测试分析阶段(不使用图9a中的子块1114)。例如,在块1110中可以使用一些端到端模型,如tacotron1和2,以简化文本分析模块,并且直接将字符/音素序列作为输入序列,例如以梅尔谱图的形式作为声学特征(目标数据12)输出。
[0254]
当前的解决方案可以用作tts系统(即包括块1110和1120),其中,在一些示例中,
目标数据12可以包括从文本112得出的信息流或语音表示。例如,表示可以是从文本112得出的字符或音素,这意味着文本分析块1110的通常输入。在这种情况下,预调节(预条件)可学习层可以用于块1110,例如用于提取适用于神经声码器(例如块1120)的声学特征或条件特征(目标数据12)。此预调节层1110可以使用深度神经网络(dnn),如编码器-注意-解码器架构,将字符或音素直接映射到声学特征。可替代地,表示(目标数据)12可以是或包括语言学特征,即与韵律、语调、停顿等信息相关的音素。在这种情况下,预条件可学习层1110可以是基于隐马尔可夫模型(hmm)、深度神经网络(dnn)或递归神经网络(rnn)等统计模型将语言学特征映射到声学特征的声学模型。最后,目标数据12可以直接包括从文本112得出的声学特征,其可以用作条件特征,例如,在可学习或确定性预调节层1110之后。在极端情况下(例如图10中的情况f),目标数据12中的声学特征可以直接用作条件特征,并且任何预调节层可以被绕过。
[0255]
由此,音频合成块1110(文本分析块)在一些示例中可以是确定性的,但在其他情况中可以通过至少一个可学习层获得。
[0256]
在示例中,目标数据12可以包括声学特征,如从文本112获得的对数谱图、或谱图、或mfcc或梅尔谱图。
[0257]
在替代例中,目标数据12可以包括从文本获得的音素、单词韵律、语调、短语中断或填充停顿等语言学特征。
[0258]
目标数据可以使用统计模型、可学习模型或基于规则的算法中的至少一种从文本得出,统计模型、可学习模型或基于规则的算法可包括文本分析和/或声学模型。
[0259]
因此,一般而言,从诸如文本112的输入(例如文本)输出目标数据12(以便从文本112得出目标数据12)的音频合成块1110可以是确定性块或可学习块。
[0260]
一般来说,目标数据12可以具有多个通道,而文本112(目标数据12从中得出)可以具有单个通道。
[0261]
图9a示出了发生器10a的示例(其可以是发生器10的示例),其中目标数据12包括从文本112获得的声学特征,如对数谱图、或谱图、或mfcc或梅尔谱图中的至少一种。在这里,块1110包括文本分析块1112,文本分析块1112提供中间目标数据212,中间目标数据212可包括从文本112获得的诸如音素、单词韵律、声调、短语中断或填充停顿等语言学特征中的至少一种。随后,音频合成块1114(例如,使用声学模型)可以将目标数据12生成为声学特征中的至少一种,如从文本112获得的对数谱,或谱图,或mfcc或梅尔谱图。
[0262]
之后,波形合成块1120(可以是上述波形合成块中的任何一个)可用于生成输出音频信号16。
[0263]
图9b示出了发生器10b的示例(其可以是发生器10的示例),其中目标数据12包括从文本112获得的如音素、单词韵律、语调、短语中断或填充停顿的语言学特征中的至少一种。波形合成器(例如声码器1120)可用于输出音频信号16。波形合成块1120可以是上面讨论的图1-8中描述的任何波形合成块。在这种情况下,例如,目标数据可以直接被摄取到可学习层71-73的条件集,以获得γ和β(74和75)。
[0264]
在图9c中,示出了将文本112直接用作目标数据的发生器10c的示例(其可以是图1-8中任何发生器10的示例)。因此,目标数据12包括从文本112获得的字符或单词中的至少一个。波形合成块1120可以是上面讨论的任何示例。
[0265]
一般而言,上述任何音频发生器(特别是任何文本分析块1110(例如图8或图9a-9c中的任何一个)可以使用由文本分析和/或声学模型组成的统计模型、可学习模型或基于规则的算法中的至少一种从文本得出目标数据。
[0266]
在一些示例中,目标数据12可以由块1120确定性地获得。在其他示例中,目标数据12可以非确定性地获得,并且块1110可以是一个可学习层或多个可学习层。
[0267]
gan鉴别器
[0268]
在训练期间,可以使用图2中的gan鉴别器100,以获得例如应用于输入信号12(或其处理和/或归一化版本)的参数74和75。训练可以在推理之前执行,并且参数74和75可以,例如,存储在非暂时性存储器中并随后使用(然而,在一些示例中,参数74或75也落在线计算)。
[0269]
gan鉴别器100具有学习如何从真实输入信号(例如,真实语音)104中识别生成的音频信号(例如,如上所述合成的音频信号16)的作用。因此,gan鉴别器100的作用主要在训练期间发挥(例如,用于学习参数72和73),并且在gan发生器11(可以看作是没有gan鉴别器100的音频发生器10)的作用的对抗位置被看到。
[0270]
一般来说,gan鉴别器100可以被输入由gan发生器10合成的音频信号16和例如通过麦克风获得的真实音频信号(例如,真实语音)104,并处理这些信号以获得要最小化的度量(例如,损耗)。实际音频信号104也可以被认为是参考音频信号。在训练期间,可以重复如上所述的用于合成语音16的操作,例如多次,以获得例如参数74和75。
[0271]
在示例中,可以不分析整个参考音频信号104和/或整个生成的音频信号16,而只分析其中的一部分(例如,一部分、切片、窗口等)。获得从生成的音频信号16和从参考音频信号104采样的随机窗口(105a-105d)中生成的信号部分。例如,可以使用随机窗口函数,使得不会先验地预定义将使用哪个窗口105a,105b,105c,105d。此外,窗口的数量不一定是四个,可以有所不同。
[0272]
在窗口(105a-105d)内,可以应用pqmf(正交镜像滤波器组(pqmf))110。因此,获得子带120。因此,获得生成的音频信号(16)的表示或参考音频信号(104)的表示的分解(110)。
[0273]
可使用评估块130来执行评估。可以使用多个评估器132a、132b、132c、132d(以132复合指示)(可以使用不同的数量)。通常,每个窗口105a、105b、105c、105d可以被输入到相应的评估器132a、132b、132c、132d。随机窗口(105a-105d)的采样可以对每个评估器(132a-132d)重复多次。在示例中,针对每个评估器(132a-132d)采样随机窗口(105a-105d)的次数可以与生成的音频信号的表示或参考音频信号(104)的表示的长度成比例。因此,每个评估器(132a-132d)可以作为输入接收生成的音频信号(16)的表示或参考音频信号(104)的表示的一个或多个部分(105a-105d)。
[0274]
每个评估器132a-132d本身可以是神经网络。特别是,每个评估器132a-132d可以遵循卷积神经网络的范例。每个评估器132a-132d可以是残差评估器。每个评估器132a-132d可以具有在训练期间调整的参数(例如权重)(例如,以类似于上面解释的那些之一的方式)。
[0275]
如图2所示,每个评估器132a-132d也执行下采样(例如,按4或按另一个下采样比)。对于每个评估器132a-132d,通道数量增加(例如,增加4,或者在某些示例中增加与下
采样比相同的数字)。
[0276]
在评估器的上游和/或下游,可以提供卷积层131和/或134。上游卷积层131可以具有,例如,维度为15的核(例如,5x3或3x5)。下游卷积层134可以有,例如,维度为3的核(例如,3x3)。
[0277]
在训练期间,损失函数(对抗损失)140可以被优化。损失函数140可以包括在生成的音频信号(16)和参考音频信号(104)之间的固定度量(例如在预训练步骤期间获得)。固定度量可以通过计算生成的音频信号(16)和参考音频信号(104)之间的一个或多个频谱失真来获得。这种失真可以通过考虑以下因素来测量:
[0278]-生成的音频信号(16)和参考音频信号(104)的频谱表示的幅度或对数幅度,和/或
[0279]-不同的时间或频率分辨率。
[0280]
在示例中,对抗性损失可以通过由一个或多个评估器(132)随机提供和评估生成的音频信号(16)的表示或参考音频信号(104)的表示来获得。评估可包括将所提供的音频信号(16,132)分类为预定数量的类,所述预定数量的类指示音频信号(14,16)的自然度的预训练分类水平。例如,预定数量的类可以是“真实”vs“假的”。
[0281]
损失的示例可以如下获得:
[0282][0283]
其中:
[0284]
x是真实的语音104,
[0285]
z为潜在噪声14(或更一般地,输入信号或第一数据或潜在),
[0286]
s是x的梅尔谱图(或更一般地,目标信号12)。
[0287]
d(
…
)是评估器在概率分布方面的输出(d(
…
)=0表示“肯定是假的”,d(
…
)=1表示“肯定是真的”)。
[0288]
谱重建损失仍然用于正则化,以防止出现对抗性伪影。最后的损失可以是,例如:
[0289][0290]
其中每个i是每个评估器132a-132d处的贡献(例如,每个评估器(132a-132d)提供不同的di)和是预训练的(固定的)损失。
[0291]
在训练期间,对的最小值有搜索,例如可以表示为如下
[0292][0293]
可以执行其他类型的最小化。
[0294]
一般来说,最小对抗性损失140与待应用于样式元件77的最佳参数(例如,74、75)相关联。
[0295]
讨论
[0296]
使用附带的描述详细地描述本公开的实例。特别地,在下面的描述中,为了对本公开的实施例提供更彻底的解释,将描述许多细节。然而,对于本领域技术人员来说,可以在
没有这些具体细节的情况下实施其他实施例是显而易见的。描述的不同实施例的特征可以彼此组合,除非相应组合的特征是互斥的或明确排除这种组合。
[0297]
应当指出的是,相同或相似的元件或具有相同功能的元件可以具有相同或相似的附图标记,或者被相同地指定,对具有相同或相似附图标记的元件进行重复描述,或者通常省略相同或相似附图比较的元件。具有相同或相似附图标记或被标记为相同的元件的描述是可互换的。
[0298]
神经声码器在诸如文本到语音、语音编码和语音增强等许多应用中,已经证明在自然高质量语音的合成方面优于经典方法。第一个开创性的合成高质量语音的生成神经网络是wavenet,此后不久,许多其他方法被开发出来。这些模型提供了先进的质量,但通常以非常高的计算成本和非常缓慢的合成。近年来出现了大量计算成本较低的语音生成模型。其中一些是现有模型的优化版本,而另一些则利用了与经典方法的集成。此外,还引入了许多全新的方法,通常依赖于gan。大多数gan声码器在gpu上提供非常快的生成,但代价是牺牲了合成的语音的质量。
[0299]
这项工作的主要目标之一是提出一种gan架构,我们称之为stylemelgan(可以在音频发生器10中实现),它可以以低计算成本和快速训练合成非常高质量的语音16。stylemelgan的发生器网络可能包含3.86m个可训练参数,并以22.05khz的频率合成语音,比cpu上的实时速度快2.6倍,并且比在gpu上快超过54倍。例如,模型可以由8个上采样块组成,这些上采样块逐渐将低维噪声向量(例如图1中的30)变换为原始语音波形(例如16)。合成可以以目标语音的梅尔谱图为条件(或更一般地以目标数据12为条件),其可以经由时间自适应去归一化(tade)层(60,60a,60b)插入每个发生器块(50a-50h)中。此插入条件特征的方法非常有效,并且据我们所知,这是音频领域的新方法。通过四个鉴别器132a-132d的集合来计算对抗损失(例如,通过图2的结构,在gan鉴别器100中)(但在某些示例中可能有不同数量的鉴别器),每个鉴别器在可区分的伪正交镜像滤波器组(pqmf)110之后操作。这允许在训练期间分析语音信号(104或16)的不同频带。为了使训练更加鲁棒性和有利于推广,鉴别器(例如四个鉴别器132a-132d)不以发生器10使用的输入声学特征为条件,并且使用随机窗口(例如105a-105d)对语音信号(104或16)进行采样。
[0300]
总之,提出了stylemelgan,这是一种低复杂度的gan,用于经由tade层(例如60,60a,60b)以梅尔谱图(例如12)为条件的高质量语音合成。发生器10可以高度并行化。发生器10可以是完全卷积的。上述发生器10可以使用pqmf多采样随机窗口鉴别器(例如132a-132d)的集合进行对抗训练,该pqmf多采样随机窗口鉴别器的集合可以通过多尺度频谱重建损失进行正则化。生成的语音的质量可以用客观的(例如,fr
é
chet分数)和/或主观的评估来评估。进行了两次听力测试,复制合成场景的mushra测试和tts场景的p.800acr测试,都证实了stylemelgan达到了最先进的语音质量。
[0301]
现有的神经声码器通常通过对最终波形的幅度进行建模,直接在时域中合成语音信号。这些模型大多是生成神经网络,即它们对自然语音信号中观察到的语音样本的概率分布进行建模。它们可以分为自回归和非自回归或并行,前者将分布明确地分解为条件分布的乘积,以及后者直接对联合分布进行建模。wavenet、samplernn和wavernn等自回归模型已经被报道用于合成高感知质量的语音信号。一大类非自回归模型是归一化流之一,例如waveglow。混合方法是使用逆自回归流,其使用噪声潜在表示和目标语音分布之间的因
式变换。以上的示例主要是指自回归神经网络。
[0302]
gan在音频方面的早期应用包括用于无条件语音生成的wavegan和用于音乐生成的gan-synth。melgan学习语音片段的梅尔谱图与其相应的时域波形之间的映射。它确保了比实时生成更快,并利用了由频谱重建损失正则化的多尺度鉴别器的对抗性训练。gan-tts是第一个使用独特的对抗性训练用于基于声学特征的语音生成的gan声码器。它的对抗损失是由条件和无条件随机窗口鉴别器的集合计算的。并行wavegan使用发生器,在结构上与wavenet类似,发生器使用由多尺度谱重建损失正则化的无条件鉴别器进行训练。在multiband-melgan中使用了类似的思想,它分别生成目标语音的每个子带,从而节省了计算能力,然后使用合成pqmf得到最终波形。它的多尺度鉴别器评估全频带语音波形,并使用多频带尺度频谱重建损失进行正则化。该领域的研究非常活跃,我们可以引用最近的gan声码器,诸如vocgan和hooligan。
[0303]
图1示出了在音频发生器10中实现的stylemelgan的发生器架构。发生器模型通过以梅尔谱图(或更一般地,目标数据)为条件12的渐进上采样(例如在50a-50h块),将噪声向量(在图1中用30表示)映射到语音波形16(例如在22050hz)中。它使用时间自适应去归一化,tade(参见块60,60a,60b),这可能是基于归一化激活图的线性调制的特征调节(图3中的76')。调制参数γ(gamma,图3中的74)和β(beta,图3中的75)是自适应地从条件特征中学习的,并且在一个示例中具有与潜在信号相同的维数。这为发生器模型的所有层提供了条件特征,从而在所有上采样阶段保持信号结构。在公式从而在所有上采样阶段保持信号结构。在公式中,128是潜在噪声的通道的数量(在不同的示例中可以选择不同的数量)。因此,可以生成维度128的随机噪声,其均值为0,并且其自相关矩阵(128
×
128的平方)等于单位i。因此,在示例中,可以认为生成的噪声在通道之间是完全去相关的,并且方差为1(能量)。可以在每22528个生成的样本处实现(或者可以为不同的示例选择其他数字);因此,维度在时间轴上可以是1,以及在通道轴上可以是128。(可以提供与128不同的其他数量)
[0304]
图3示出了音频发生器10的一部分的结构,并示出了tade块60(60a,60b)的结构。经由c
⊙
γ β对输入激活c(76')进行自适应调制,其中
⊙
表示元素乘法(值得注意的是,γ和β具有激活图的相同维度;还注意到,c是图3中x的归一化版本,因此c
⊙
γ β是xγ β的归一化版本,也可以用x
⊙
γ β表示)。在块77的调制之前,使用实例归一化层76。层76(归一化元件)可以将第一数据归一化为零均值和单位方差的正态分布。可以使用softmax门控tanh激活函数(例如,图4中由块63a-64a-65a实例化的第一个,以及由块63b-64b-65b实例化的第二个),据报道,其性能优于整流线性单元relu函数。softmax门控(例如,通过乘法65a和65b获得)允许在音频波形生成中产生较少的伪影。
[0305]
图4示出了音频发生器10的一部分的结构,并示出了taderesblock50(可以是块50a-50h中的任何一个),它是发生器模型的基本构建块。完整的架构如图1所示。它包括8个上采样阶段50a-50h(在其他示例中,其他数字是可能的),包括,例如,taderesblock和以因子2对信号79b进行上采样的层601,加上一个最终激活模块46(如图1所示)。最终激活包括一个taderesblock42,然后是通道变化卷积层44,例如具有tanh非线性46。例如,这种设计允许使用64的通道深度进行卷积操作,从而节省复杂性。此外,这种上采样过程允许保持膨胀因子低于2。
[0306]
图2示出了滤波器组随机窗口鉴别器(fb-rwd)的结构。stylemelgan可以使用多个(例如四个)鉴别器132a-132d进行它的对抗训练,其中在示例中,鉴别器132a-132d的架构没有平均池化下采样。此外,每个鉴别器(132a-132d)可以在从输入语音波形(104或16)切片的随机窗口(105a-105d)上操作。最后,每个鉴别器(132a-132d)可以分析通过分析pqmf(例如110)获得的输入语音信号(104或16)的子带120。更精确地说,在示例中,我们可以使用分别从从1秒的波形中提取的分别为512、1024、2048和4096个样本的选择随机段计算的1、2、4和8个子带。这使得能够在时域和频域两者中对语音信号(104或16)进行多分辨率对抗性评估。
[0307]
众所周知,训练gan是具有挑战性的。使用权重(例如74和75)的随机初始化,对抗性损失(例如140)可能导致严重的音频伪像和不稳定的训练。为了避免此问题,可以首先只使用由频谱收敛的误差估计和从不同stft分析计算的对数幅度组成的频谱重建损失对发生器10进行预训练。以这种方式获得的发生器可以生成非常调性的信号,尽管在高频中具有显著的拖尾。尽管如此,这仍然是对抗性训练的一个很好的起点,与直接从完整的随机噪声信号开始相比,对抗性训练可以受益于更好的谐波结构。然后对抗性训练通过去除音调效果和锐化拖尾的频带来驱动生成自然度。铰链损失140用于评估对抗度量,如下面的公式1所示。
[0308][0309]
其中x为真实语音104,z为潜在噪声14(或更一般地为输入信号),以及s为x(或更一般地为目标信号12)的梅尔谱图。值得注意的是,频谱重建损失(140)仍然用于正则化,以防止出现对抗性伪影。最终损失(140)根据公式2,如下所示。
[0310][0311]
权重归一化可以应用于g(或更准确地说是gan发生器11)和d(或更准确地说是鉴别器100)中的所有卷积操作。在实验中,stylemelgan使用一个nvidia tesla v100 gpu在ljspeech语料库上以22050hz的频率进行训练。对数幅度梅尔谱图是为80个梅尔波段计算的,并被归一化为具有零平均值和单位方差。当然,这只是一种可能;其他值也同样可能。使用adam优化器对发生器进行100000步的预训练,学习率(lrg)为10-4
,β1=0.5,β2=0.9。在开始对抗训练时,将g的学习率(lrg)被设置为5*10-5
,并使用具有adam优化器的fb-rwd,鉴别器学习率(lrd)为2*10-4
,且β相同。fb-rwd在每个训练步骤重复随机窗口化1s/window_length(即每个窗口长度1秒)次,以支持具有足够梯度更新的模型。对于批中每个样本使用32的批次大小和长度为1s(即1秒)的片段。训练持续大约150万步,即1.500.000步。
[0312]
实验中使用的模型如下:
[0313]
·
wavenet用于复制合成和文本到语音的目标实验
[0314]
·
pwgan用于复制合成和文本到语音的目标实验
[0315]
·
melgan用于复制合成的目标实验,具有客观评估
[0316]
·
waveglow用于复制合成的目标实验
[0317]
·
变换器.v3,用于文本到语音的目标实验
[0318]
已经针对上述预训练的基线声码器模型对stylemelgan进行了客观和主观评估。音频tts输出的主观质量经由听众在受控环境中执行的p.800听力测试进行评估。该测试集
包含同一说话者记录的未见过的话语,这些话语是从librivox在线语料库中随机选择的。因此,该模型是鲁棒的并且不主要依赖于训练数据。这些话语测试了模型的泛化能力,因为它们是在略有不同的条件下记录的,并且呈现不同的韵律。使用griffinlim算法重新合成原始话语,并使用这些话语代替通常的锚定条件。这有利于使用整体评分量表。
[0319]
传统的客观测量方法诸如pesq和polqa对由神经声码器生成的语音波形评估不可靠。相反,使用了有条件的fr
é
chet深度语音距离(cfdsd)。以下不同神经声码器的cfdsd分数示出,stylemelgan显著优于其他模型。
[0320]
·
melgan训练cfdsd0.235测试cfdsd0.227
[0321]
·
pwgan训练cfdsd0.122测试cfdsd0.101
[0322]
·
waveglow训练cfdsd0.099测试cfdsd0.078
[0323]
·
wavenet训练cfdsd0.176测试cfdsd0.140
[0324]
·
stylemelgan训练cfdsd0.044测试cfdsd0.068
[0325]
可以看出,stylemelgan优于其他对抗性和非对抗性声码器。
[0326]
由15名专家听众组成的小组进行了mushra听力测试。之所以选择这种类型的测试,是因为它可以更精确地评估生成的语音的质量。锚是使用griffin-lim算法的py-torch实现生成的,具有32次迭代。图5示出了mushra测试的结果。可以看出,stylemelgan显著优于其他声码器约15个mushra点。结果还示出,waveglow生成的输出质量与wavenet相当,同时与parallelwavegan不相上下。
[0327]
音频tts输出的主观质量可以经由由31名听众在受控环境中执行的p.800acr听力测试来评估。espnet的变换器.v3模型可用于生成测试集的转录的梅尔谱图。同样的griffin-lim锚也可以被添加,因为这有利于使用整体评级量表。
[0328]
以下不同tts系统的p800平均意见分数(mos)示出了类似的发现,stylemelgan明显优于其他模型:
[0329]
·
griffinlimp800mos:1.33 /-0.04
[0330]
·
变换器 parallelwaveganp800mos:3.19 /-0.07
[0331]
·
变换器 wavenetp800mos:3.82 /-0.07
[0332]
·
变换器 stylemelganp800mos:4.00 /-0.07
[0333]
·
记录p800mos:4.29 /-0.06
[0334]
下面示出了不同并行声码器模型的以实时因子(rtf)的生成速度和参数数量。stylemelgan在生成质量和推理速度之间提供了明确的折衷。
[0335]
这里给出了对于所研究的各种模型,在cpu(例如intelcorei7-67003.40ghz)和gpu(例如nvidiageforcegtx1060)上生成的参数的数量和实时因子。
[0336]
·
parallelwavegan参数:1.44mcpu:0.8xgpu:17x
[0337]
·
melgan参数:4.26mcpu:7xgpu:110x
[0338]
·
stylemelgan参数:3.86mcpu:2.6xgpu:54x
[0339]
·
waveglow参数:80m-gpu:5x
[0340]
最后,图5示出了mushra专家听力测试的结果。可以看出,stylemelgan优于现有技术的模型。
[0341]
结论
[0342]
此工作提出了stylemelgan,一种用于高保真语音合成的轻量级和高效的对抗性声码器。该模型使用时间自适应归一化(tade)向所有生成层提供充分和准确的条件,而不是仅向第一层提供调节。对于对抗性训练,发生器与滤波器组随机窗口鉴别器竞争,后者在时域和频域两者中提供语音信号的多尺度表示。stylemelgan在cpu和gpu上的操作速度比实时速度快一个数量级。客观和主观实验结果表明,stylemelgan显著优于先前的对抗式声码器以及自回归、基于流和基于扩散的声码器,为神经波形生成提供了新的最先进的基线。
[0343]
综上所述,本文所述的实施例可以任选地由本文所述的任何要点或方面补充。然而,需要注意的是,本文描述的要点和方面可以单独使用或组合使用,并且可以单独和组合地引入到本文描述的任何实施例中。
[0344]
虽然在装置的上下文中描述了一些方面,但很明显,这些方面也代表了对相应方法的描述,其中设备或其部分对应于方法步骤或方法步骤的特征。类似地,在方法步骤上下文中描述的方面也表示对相应装置或装置的一部分或相应装置的项目或特征的描述。一些或所有的方法步骤可以由(或使用)硬件装置来执行,例如,微处理器、可编程计算机或电子电路。在一些实施例中,最重要的方法步骤中的一个或多个可以通过这样的装置来执行。
[0345]
根据某些实施要求,本发明的实施例可以在硬件或软件中实现。该实现可以使用数字存储介质来执行,例如软盘、dvd、蓝光、cd、rom、prom、eprom、eeprom或闪存,这些介质具有存储在其上的电子可读控制信号,其与可编程计算机系统协作(或能够协作),从而执行相应的方法。因此,数字存储介质可以是计算机可读的。
[0346]
根据本发明的一些实施例包括具有电子可读控制信号的数据载体,其能够与可编程计算机系统协作,从而执行本文所述的方法之一。
[0347]
通常,本发明的实施例可以实现为具有程序代码的计算机程序产品,当计算机程序产品在计算机上运行时,该程序代码可用于执行所述方法之一。程序代码可以例如存储在机器可读载体上。
[0348]
其他实施例包括存储在机器可读载体上的用于执行本文所述方法之一的计算机程序。
[0349]
换句话说,因此,本发明方法的实施例是,具有当计算机程序在计算机上运行时,用于执行本文所述方法之一的程序代码的计算机程序。
[0350]
因此,本发明方法的进一步实施例是数据载体(或数字存储介质,或计算机可读介质),包括记录在其上的用于执行本文所述方法之一的计算机程序。数据载体、数字存储介质或记录介质通常是有形的和/或非暂时的。
[0351]
因此,本发明方法的进一步实施例是表示用于执行本文所述方法之一的计算机程序的数据流或信号序列。数据流或信号序列可以例如被配置为经由数据通信连接传送,例如经由互联网传送。
[0352]
进一步的实施例包括处理装置,例如计算机或可编程逻辑器件,其被配置为或适应于执行本文所述的方法之一。
[0353]
进一步实施例包括在其上安装有用于执行本文所述方法之一的计算机程序的计算机。
[0354]
根据本发明的进一步实施例包括被配置为将用于执行本文所述方法之一的计算机程序(例如,电子地或光学地)传送到接收器的装置或系统。例如,接收器可以是计算机、
移动设备、存储器设备等。装置或系统可例如包括用于将计算机程序传送到接收器的文件服务器。
[0355]
在一些实施例中,可编程逻辑器件(例如现场可编程门阵列)可用于执行本文所述方法的一些或全部功能。在一些实施例中,现场可编程门阵列可以与微处理器协作以执行本文所述的方法之一。通常,方法优选由任何硬件装置执行。
[0356]
本文所述的装置可以使用硬件装置来实现,或者使用计算机来实现,或者使用硬件装置和计算机的组合来实现。本文描述的装置,或本文描述的装置的任何组件,可以至少部分地在硬件和/或软件中实现。本文所述的方法可以使用硬件装置,或使用计算机,或使用硬件装置和计算机的组合来执行。本文描述的方法,或本文描述的方法的任何部分,可以至少部分地通过硬件和/或软件来执行。
[0357]
上述所描述的实施例仅是对本发明的原理进行说明。应当理解,本文所述的布置和细节的修改和变化对于本领域技术人员将是显而易见的。因此,其意图仅受即将到来的专利权利要求的范围的限制,而不受通过本文的实施例的描述和解释方式所提供的具体细节的限制。
[0358]
参考文献
[0359]
a.van den oord,s.dieleman,h.zen,k.simonyan,et al.,“wavenet:a generative model for raw audio,”arxiv:1609.03499,2016.
[0360]
r.prenger,r.valle,and b.catanzaro,“waveglow:a flow-based generative network for speech synthesis,”in ieee international conference on acoustics,speech and signal processing(icassp),2019,pp.3617
–
3621.
[0361]
s.mehri,k.kumar,i.gulrajani,r.kumar,et al.,“samplernn:an unconditional end-to-end neural audio generation model,”arxiv:1612.07837,2016.
[0362]
n.kalchbrenner,e.elsen,k.simonyan,s.noury,
[0363]
et al.,“efficient neural audio synthesis,”[0364]
arxiv:1802.08435,2018.
[0365]
a.van den oord,y.li,i.babuschkin,k.simonyan,et al.,“parallel wavenet:fast high-fidelity speech synthesis,”in proceedings of the 35th icml,2018,pp.3918
–
3926.
[0366]
j.valin and j.skoglund,“lpcnet:improving neural speech synthesis through linear prediction,”in ieee international conference on acoustics,speech and signal processing(icassp),2019,pp.5891
–
5895.
[0367]
k.kumar,r.kumar,de t.boissiere,l.gestin,et al.,“melgan:generative adversarial networks for con-ditional waveform synthesis,”in advances in neurips 32,pp.14910
–
14921.2019.
[0368]
r.yamamoto,e.song,and j.kim,“parallel wavegan:a fast waveform generation model based on genera-tive adversarial networks with multi-resolution spec-trogram,”in ieee international conference on acous-tics,speech and signal processing(icassp),2020,pp.6199
–
6203.
spectral energy distance for parallel speech synthesis,”arxiv:2008.01160,2020.
[0384]“p.800:methods for subjective determination of trans-mission quality,”standard,international telecommuni-cation union,1996.
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。