labeling.journal of advances in neural information processing systems,2021,34:18408-18419.提出课程伪标签的方法,在固定匹配方法的基础上,考虑不同类别的数据学习难度不同的问题,研究不同类别的置信度阈值,实验验证提出的方法进一步提升了模型的性能。6.基于图卷积网络的多说话人会议数据半监督学习方法:2022年tong f,zheng s,zhang m,et al.graph convolutional network based semi-supervised learning on multi-speaker meeting data[c]//icassp 2022-2022ieee international conference on acoustics,speech and signal processing(icassp).ieee,2022:6622-6626.提出一种基于图卷积网络的半监督学习方法,在给定一个预先训练的嵌入提取器的基础上,对标记数据训练图卷积网络,并用“伪标记”对未标记数据进行聚类,在此基础上,提出一种自校正训练机制,该机制在伪标签上迭代运行聚类训练校正过程。实验结果表明,该方法有效地利用了未标记数据,提高了说话人识别的准确率。
技术实现要素:
[0003]
本发明的目的是提供一种对无标签数据选取具备高准确率和高利用率两种特性的基于自适应扩充策略的三阶段半监督声纹识别方法。
[0004]
为实现上述目的,本发明提供了如下方案:
[0005]
(1)提出构建三阶段框架(three-stage framework,tsf)的半监督学习方法;
[0006]
(1.1)将对比学习、监督学习以及半监督学习统一在三阶段的半监督学习框架中;
[0007]
(1.2)利用模型自身的分类能力在第二阶段结束后预测初始置信度阈值,进行第三阶段的半监督学习;
[0008]
(2)提出基于自适应扩充策略的三阶段(three-stage framework with adaptive expansion strategy,tsf-aes)半监督声纹识别方法;
[0009]
(2.1)利用未被置信度阈值选取的无标签数据预测底线阈值;
[0010]
(2.2)在基于所述tsf的半监督学习方法基础上,利用自适应扩充策略(adaptive expansion strategy,aes),根据模型的性能自适应地结合底线阈值调整置信度阈值,以合理扩充无标签数据的选取量,进一步提升模型的声纹识别性能;
[0011]
(3)完成对所述基于自适应扩充策略的三阶段半监督声纹识别方法的训练和测试;
[0012]
(3.1)利用所述基于tsf-aes半监督声纹识别方法训练半监督声纹识别模型;
[0013]
(3.2)完成训练后模型的性能测试。
[0014]
所述的步骤(1.1)具体包括:
[0015]
对有标签数据和无标签数据进行数据强增强和数据弱增强,其中数据强增强是在原始音频中加入音乐、人声、噪音或混响脉冲响应,并在特征提取后进行时域-频域增强,数据弱增强是只在特征提取后进行时域-频域增强,时域增强表示为其中,x(t)表示时间t下的信号,t1和t2表示数据增强的起止时域,频域增强表示为其中,x(f)表示频段f下的信号,f1和f2表
示数据增强的起止频域。
[0016]
所述的步骤(1.1)具体包括:
[0017]
利用无标签声纹数据进行第一阶段对比学习,采用强化对抗训练的对比学习方法构建正负样本对,利用对比学习使模型学习到数据间的相似性,对比学习结束后,获取编码器的参数用于第二阶段。
[0018]
所述的步骤(1.1)具体包括:
[0019]
利用有标签数据在第一阶段对比学习的基础上,进行第二阶段监督学习提升模型的分类能力,当模型的性能趋近稳定时,结束第二阶段监督学习,获取编码器的参数用于第三阶段。
[0020]
所述的步骤(1.1)具体包括:
[0021]
在第二阶段监督学习的基础上进行第三阶段半监督学习,将弱增强的无标签数据经过编码器获取概率向量分布,将概率最大值大于置信度阈值的样本所预测出的标签作为伪标签,并对强增强数据计算损失其中,表示无标签数据集,xu表示无标签数据,f
θ
(
·
)表示编码器,f
θ
(a(xu))表示弱增强的无标签数据经过编码器获取的概率向量分布,as(xu)表示强增强的无标签数据,τ表示置信度阈值,h(
·
)表示附加角度边界的归一化指数函数(additive angular margin softmax,aam-softmax)损失,有标签数据与其真实标签计算损失进行监督学习其中,表示有标签数据集,x
l
表示有标签数据,y表示数据的真实标签,利用总损失进行半监督学习。
[0022]
所述的步骤(1.2)具体包括:
[0023]
在第二阶段监督学习基础上,利用有标签数据,通过模型自身的分类能力预测初始阈值作为第三阶段的置信度阈值,将有标签数据概率向量分布最大值对应的类与真实标签进行比对,将相同数据对应的概率最大值求平均作为第三阶段初始置信度阈值,该置信度阈值可以根据当前模型对数据的分类能力对无标签数据进行置信度筛选。
[0024]
所述的步骤(2.1)具体包括:
[0025]
根据置信度阈值将无标签数据分为被选择和未被选择,对于未被选择的无标签数据进行数据弱增强,并经过编码器获取概率向量分布,将概率向量分布中的最大值求平均作为底线阈值,其中,κi表示第i个epoch的底线阈值,u表示未被选择的无标签数据量,n表示无标签数据的总量,τi表示第i个epoch的置信度阈值。
[0026]
所述的步骤(2.2)具体包括:
[0027]
第三阶段利用提出的自适应扩充策略,根据模型的性能自适应地结合底线阈值调整置信度阈值,以增加无标签数据的选取量,当模型的性能趋于稳定时,根据初始阈值、底线阈值、当前的训练轮数和总训练轮数自适应调整置信度阈值,使模型在保证高质量的无
标签数据前提下逐渐增加无标签数据的选取量,进一步提高无标签数据的利用率。
[0028]
所述的步骤(3.1)具体包括:
[0029]
将所述基于tsf-aes半监督声纹识别方法和声纹识别模型(emphasized channel attention,propagation and aggregation in tdnn,ecapa-tdnn)相结合,利用声纹数据集对所述基于tsf-aes半监督声纹识别方法训练半监督声纹识别模型。
[0030]
所述的步骤(3.2)具体包括:
[0031]
利用声纹数据集对训练后的模型进行性能测试,通过等错误率,以及所选取的无标签数据对应的伪标签质量和数量等性能指标验证声纹识别结果,完成基于自适应扩充策略的三阶段半监督声纹识别任务。
[0032]
本发明的有益效果为:
[0033]
(1)由于传统的半监督学习方法都产生于图像识别领域,如fixmatch、flexmatch等方法,且目前对于半监督声纹识别方法的研究多数都是基于图的方法,其在建立图的过程中需要消耗大量的计算资源和时间。本发明将适用于图像识别领域的半监督学习思想与对比学习和监督学习相结合,将其应用于声纹识别领域中,提出一种基于自适应扩充策略的三阶段半监督声纹识别方法。(2)本发明提出构建tsf的半监督学习方法,将对比学习、监督学习以及半监督学习统一在三阶段的学习框架中。在对比学习阶段,模型学习到数据间的相似性,在监督学习阶段,模型通过有标签数据提升模型的分类能力,监督学习结束后,通过模型自身的分类能力预测初始阈值以在第三阶段半监督学习中筛选出高质量的无标签数据,在半监督学习阶段,模型使用初始阈值作为置信度阈值进行半监督学习。(3)本发明提出基于tsf-aes半监督声纹识别方法,在tsf的基础上,引入自适应扩充策略,通过未被置信度阈值选择的无标签数据预测出底线阈值,再根据模型自身的性能自适应结合初始阈值和底线阈值动态降低置信度阈值,使模型在保证高质量的无标签数据前提下逐渐增加无标签数据的选取量,进一步提升模型的性能。
附图说明
[0034]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
[0035]
图1是本发明方法的流程图;
[0036]
图2是本发明提出构建的tsf的半监督学习方法结构图;
[0037]
图3是本发明提出的基于tsf-aes半监督声纹识别方法结构图;
[0038]
图4是有标签数据占比2.2%时,基于fixmatch、flexmatch、tsf以及tsf-aes的半监督学习方法在ecapa-tdnn模型上通过置信度阈值选取的伪标签质量和数量对比图,图4(a)是所选取的伪标签数量对比图,图4(b)是所选取的伪标签质量对比图;
[0039]
图5是有标签数据占比5.5%时,基于fixmatch、flexmatch、tsf以及tsf-aes的半监督学习方法在ecapa-tdnn模型上通过置信度阈值选取的伪标签质量和数量对比图,图5(a)是所选取的伪标签数量对比图,图5(b)是所选取的伪标签质量对比图;
[0040]
图6是有标签数据占比11%时,基于fixmatch、flexmatch、tsf以及tsf-aes的半监
督学习方法在ecapa-tdnn模型上通过置信度阈值选取的伪标签质量和数量对比图,图6(a)是所选取的伪标签数量对比图,图6(b)是所选取的伪标签质量对比图;
[0041]
图7是有标签数据占比22%时,基于fixmatch、flexmatch、tsf以及tsf-aes的半监督学习方法在ecapa-tdnn模型上通过置信度阈值选取的伪标签的质量和数量对比图,图7(a)是所选取的伪标签数量对比图,图7(b)是所选取的伪标签质量对比图;
[0042]
图8是有标签数据占比33%时,基于fixmatch、flexmatch、tsf以及tsf-aes的半监督学习方法在ecapa-tdnn模型上通过置信度阈值选取的伪标签质量和数量对比图,图8(a)是所选取的伪标签数量对比图,图8(b)是所选取的伪标签质量对比图;
[0043]
图9是第一阶段对比学习有无情况下,模型在第二阶段监督学习和第三阶段半监督学习中的等错误率对比图,图9(a)是第二阶段监督学习模型等错误率对比图,图9(b)是第三阶段半监督学习模型等错误率对比图。
具体实施方式
[0044]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0045]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
[0046]
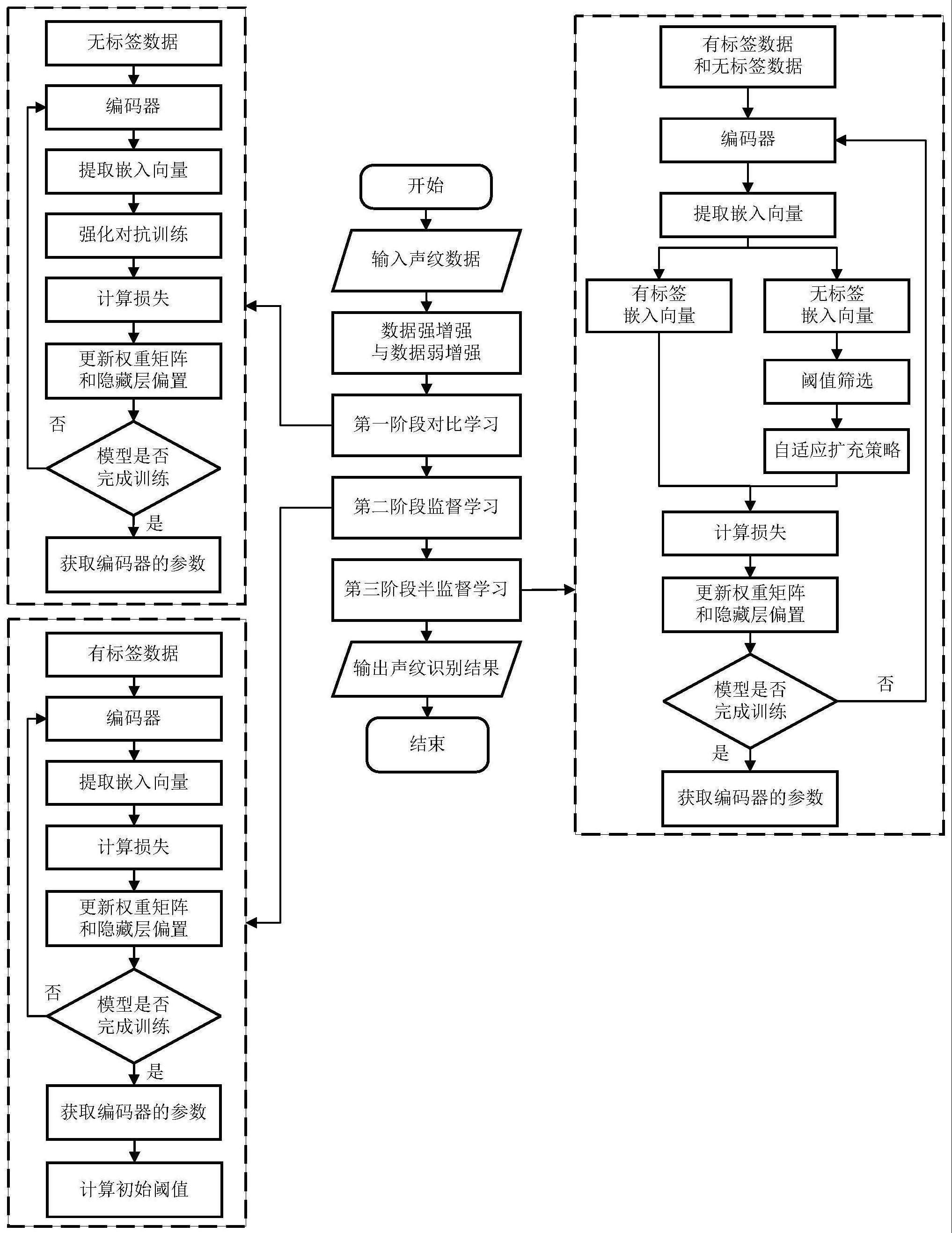
结合图1,本发明的具体步骤如下:
[0047]
(1)提出构建tsf的半监督学习方法
[0048]
将对比学习、监督学习以及半监督学习统一在三阶段的训练框架中,第一阶段对比学习采用强化对抗训练的方法使用无标签数据进行训练,使模型学习到数据间的相似性;第二阶段监督学习使用有标签数据进行监督学习,使模型提升对数据的分类能力;在第二阶段监督学习结束后,模型通过有标签数据预测出适合数据集的初始阈值作为置信度阈值,在第三阶段进行半监督学习,通过第二阶段监督学习获取的置信度阈值对弱增强的无标签数据进行筛选,并将选择到的无标签数据预测的伪标签与其强增强样本计算损失,对于有标签数据则进行监督学习。图2是本发明提出构建的tsf的半监督学习方法结构图。
[0049]
(1.1)对原始音频数据进行预处理和数据增强
[0050]
本发明使用大型公开声纹数据集voxceleb2中的训练集进行训练,其中包含5994位说话人提供的1092009条声纹数据。首先对训练集中的数据进行划分,对于每类分别选取4条、10条、20条以及40条数据作为有标签数据,另外再对每类选取33%的数据作为有标签数据,将全部的声纹数据作为无标签数据。为了统一度量,采用有标签数据占比表示不同有标签数据量,分别为2.2%、5.5%、11%、22%以及33%。
[0051]
对有标签数据和无标签数据进行数据强增强和数据弱增强,其中数据强增强是在原始音频中加入音乐、人声、噪音或混响脉冲响应,并在特征提取后进行时域-频域增强,数据弱增强是只在特征提取后进行时域-频域增强,在特征提取前不做处理。
[0052]
从声纹信号中提取fbank特征,进行预加重、分帧、加窗、快速傅立叶变换,而后经过梅尔滤波器组,利用对数滤波器组进行运算,得到声信号的fbank特征。
[0053]
为了进一步提升模型的学习难度,提升鲁棒性,在所有数据的fbank特征上进行时域-频域增强,采用矩形窗口在fbank特征上进行连续步长的时域和频域掩盖,具体操作是将掩盖内的采样点设置为0。特征提取后的fbank特征矩阵为x(f,t),其中f表示频率,t表示时间,通过在特征矩阵时间范围[t1,t2]和频率范围[f1,f2]内随机选取矩形窗口进行掩盖,其增强策略的具体表示为:
[0054][0055]
(1.2)tsf的半监督学习方法
[0056]
采用三阶段框架的半监督学习方法对处理后数据进行学习,使用ecapa-tdnn作为声纹识别模型,首先将无标签数据使用强化对抗训练的方法进行对比学习,对于每条音频随机划分出两个不重叠的片段,将同一条音频的两个片段形成正对,将不同音频的任意两个片段形成负对,同时对同一段音频进行不同的数据增强以鼓励模型对声纹信息具有判别性,对所应用的增强具有不变性。e
i,j,
k表示第i条音频数据的第j个片段添加第k种增强后,编码器所获得的嵌入向量。其原型损失l
spk
具体表示为:
[0057][0058]
s(e
i,1,1
,e
i,2,2
)=w
×
sim(e
i,1,1
,e
i,2,2
) b
[0059][0060]
式中,n表示无标签数据数目,sin(
·
)表示e
i,1,1
和e
i,2,2
的余弦相似度,w和b是可学习的权重和偏置量。
[0061]
强化对抗性训练的假设是来自同一条音频数据的两个片段,其在相同类型的数据增强下具有相同的信道特性,在不同类型的数据增强下具有不同的信道特性,该方法利用二元交叉熵损失训练模型来分类两个输入是否属于同一信道,为了削弱正确预测两段音频数据是否具有相同信道特性的能力,强化对抗性训练还在嵌入提取器和分类器间加入梯度反转层。其损失函数l
aat
表示为:
[0062][0063]
式中,σ(
·
)是sigmoid函数,g(
·
)是模型的分类器。
[0064]
强化对抗训练的总损失函数具体表示为:
[0065]
l=l
spk
l
aat
[0066]
通过第一阶段对比学习模型学习到了数据间的相似性,但模型并没有学习到足够的分类能力,这导致模型无法通过置信度阈值选择高质量的伪标签。第二阶段监督学习需要模型在学习到足够分类能力的同时得到一个适合声纹数据集的相对高置信度阈值。本发明以有标签数据为切入点,模型通过对有标签数据的学习提升分类能力,并在模型拥有足够分类能力时预测出初始阈值。使用有标签数据在第一阶段对比学习的基础上进行第二阶段监督学习,当模型的等错误率近4个时间步不下降时,将弱增强后的有标签数据的概率向
量分布最大值求平均作为初始阈值。由于第二阶段需要获得一个足够高的初始阈值使筛选出的无标签数据的伪标签是高质量的,所以在计算初始阈值时,将有标签数据预测的伪标签与真实标签不同的数据去除掉,这些错误的概率信息会使初始阈值变低。初始阈值τ0计算的数学表达如下:
[0067][0068]
式中,k表示伪标签与真实标签相同的数据量,m表示全部的有标签数据量,f
θ
(aw(xi))表示弱增强后的有标签数据经过编码器后的概率向量分布,为指示函数,条件成立为1,否则为0,y为数据的真实标签。
[0069]
第三阶段进行半监督学习,弱增强后的无标签数据通过编码器获取概率向量分布,对其最大值大于初始阈值的数据预测伪标签,并与其对应的强增强结果计算损失,无标签数据的损失函数数学表达如下:
[0070][0071]
式中,表示无标签数据集,xu表示无标签数据,f
θ
(
·
)表示编码器,f
θ
(aw(xu))表示弱增强的无标签数据经过编码器获取的概率向量分布,as(xu)表示强增强的无标签数据,h(
·
)表示附加角度边界的归一化指数函数(additive angular margin softmax,aam-softmax)损失。
[0072]
有标签数据根据其真实标签进行监督学习,损失函数具体表示为:
[0073][0074]
式中,表示有标签数据集,x
l
表示有标签数据。
[0075]
第三阶段利用总损失进行半监督学习。
[0076]
(2)提出基于tsf-aes半监督声纹识别方法
[0077]
基于tsf的半监督学习方法通过第二阶段监督学习预测出初始阈值,并将其作为第三阶段半监督学习的置信度阈值。固定的置信度阈值虽然可以选择到足够高质量的无标签数据,但是对于无标签数据的利用率不足,为了进一步提高模型对无标签数据的利用率,提出aes,根据模型的性能自适应地结合底线阈值调整置信度阈值,以合理扩充无标签数据的选取量,进一步提升模型的声纹识别性能。图3是本发明提出的基于tsf-aes半监督声纹识别方法结构图。
[0078]
(2.1)底线阈值的获取
[0079]
本发明在基于tsf的半监督学习方法基础上,采用自适应扩充策略对无标签数据进行扩充。对未被置信度阈值选择的无标签数据进行数据弱增强,并经过编码器获取概率向量分布,将概率向量分布中的最大值求平均作为底线阈值κ,其计算公式如下:
[0080][0081]
式中,κi表示第i个epoch的底线阈值,u代表未被选择到的无标签数据量,τi为第i个epoch的置信度阈值。
[0082]
(2.2)自适应扩充策略
[0083]
将当前的置信度阈值在模型的等错误率近4个时间步不再下降的情况下向底线阈值靠近,其显然比当前的置信度阈值低,并且是随着模型训练动态变化的,aes采用类似线性下降的方法加以缓冲,以尽量保证选取的无标签数量缓慢增长。本发明在模型对无标签数据选取量增多,准确率略有下降的变化中达到最好的识别性能,以实现对无标签数据选取具备高准确率和高利用率,aes具体表示为:
[0084][0085]
式中,随着训练的轮次由0到1线性增加,κ
i-1
表示第i-1个epoch预测的底线阈值。
[0086]
(3)完成对基于tsf-aes半监督声纹识别方法的训练和测试
[0087]
本发明使用voxceleb1中的测试集进行测试,其中包括40位说话人提供的4874条音频数据,以及由这4874条音频随机组合形成的37611条测试项,以验证模型的识别性能。本发明将基于mean teacher、pseudo label、fixmatch、flexmatch、simclrv2的半监督学习方法以及使用全部数据进行监督学习的方法与声纹识别模型ecapa-tdnn相结合,将这些方法与本发明提出的方法进行对比实验,利用等错误率(equal error rate,eer)作为评价指标。在半监督学习中,由于置信度阈值所选取的伪标签质量和数量同样是重要的观测指标,所以将选取的伪标签质量和数量加入到评价指标中。
[0088]
实验对每一条测试项进行测试,每项测试项是从测试集中选择的两条音频,并标注了这两条音频是否属于同一位说话人,属于为1,否则为0。测试数据经过编码器生成嵌入向量,通过计算两个嵌入向量的余弦相似度作为分数score,假设这两个嵌入向量分别为a和b,score的计算公式如下:
[0089][0090]
模型根据score的大小判断这两条音频是否属于同一说话人,表1为预测结果与实际结果统计情况:
[0091]
表1
[0092][0093]
等错误率(eer)建立在错误接受率和错误拒绝率之上,错误接受率(far)表示本不该接受但是实际预测属于同一说话人的概率,其具体表达如下:
[0094]
far=fp/(tn fp)
[0095]
错误拒绝率(frr)表示本不应该拒绝的样本但是实际预测不属于同一说话人,其具体表达为:
[0096]
frr=fn/(fn tp)
[0097]
等错误率表示错误接受率和错误拒绝率相等时刻的值,该值越小越好,其具体表达如下:
[0098]
eer=far=frr
[0099]
伪标签的质量表示置信度阈值选择到的无标签数据所预测的伪标签与实际标签一致的比例,其具体表达如下:
[0100][0101]
式中,表示被置信度阈值选取的无标签数据,p表示被置信度阈值选取的无标签数据量。
[0102]
伪标签的数量表示置信度阈值选取的无标签数据量与总数据量的比值,其具体表达为:
[0103][0104]
表2为有标签数据占比2.2%、5.5%、11%、22%以及33%时,基于mean teacher、pseudo label、fixmatch、flexmatch、simclrv2的半监督学习方法以及使用全部数据进行监督学习的方法与本发明提出的基于tsf和tsf-aes的半监督声纹识别方法在ecapa-tdnn模型上的等错误率对比结果(%)。在不同有标签数据量下,本发明提出的基于tsf-aes半监督声纹识别方法相比于上述其他半监督声纹识别方法均取得了最佳的性能,并且与使用全部数据进行监督学习的声纹识别方法性能相近。当有标签占比2.2%时,基于tsf-aes的方法较tsf方法等错误率从2.19%降至1.95%,性能提升11%,提出的基于tsf和tsf-aes的方法较上述其他半监督学习方法性能至少提升45.4%;当有标签占比5.5%时,基于tsf-aes的方法较tsf方法等错误率从2.17%降至1.66%,性能提升23.5%,提出的基于tsf和tsf-aes的方法较上述其他半监督学习方法性能至少提升26.9%;当有标签占比11%时,基于tsf-aes的方法较tsf方法等错误率从1.82%降至1.59%,性能提升12.6%,提出的基于tsf和tsf-aes的方法较上述其他半监督学习方法性能至少提升31.6%;当有标签占比22%时,基于tsf-aes的方法较tsf方法等错误率从1.45%降至1.32%,性能提升9.0%,提出的基于tsf和tsf-aes的方法较上述其他半监督学习方法性能至少提升44.0%;当有标签占比33%时,基于tsf-aes的方法较tsf方法等错误率从1.48%降至1.22%,性能提升17.6%,虽然提出的tsf方法等错误率较flexmatch方法略高,但是本发明提出的基于tsf-aes的半监督学习方法等错误率低于flexmatch,降低0.02%。
[0105]
表2
[0106][0107]
为了证明本发明提出的基于tsf-aes半监督声纹识别方法可以通过置信度阈值选择质量和数量更优的无标签数据,针对不同的有标签数据占比,对基于tsf-aes、tsf、fixmatch以及flexmatch的半监督声纹识别方法分析通过置信度阈值选择到的伪标签的质量和数量,其中fixmatch和flexmatch方法使用0.000351作为置信度阈值。图4是有标签占比2.2%时,基于fixmatch、flexmatch、tsf以及tsf-aes的半监督学习方法在ecapa-tdnn模型上通过置信度阈值选取的伪标签质量和数量对比图,图4(a)是所选取的伪标签数量对比图,图4(b)是所选取的伪标签质量对比图。图5是有标签占比5.5%时,基于fixmatch、flexmatch、tsf以及tsf-aes的半监督学习方法在ecapa-tdnn模型上通过置信度阈值选取的伪标签质量和数量对比图,图5(a)是所选取的伪标签数量对比图,图5(b)是所选取的伪标签质量对比图。图6是有标签占比11%时,基于fixmatch、flexmatch、tsf以及tsf-aes的半监督学习方法在ecapa-tdnn模型上通过置信度阈值选取的伪标签质量和数量对比图,图6(a)是所选取的伪标签数量对比图,图6(b)是所选取的伪标签质量对比图。图7是有标签占比22%时,基于fixmatch、flexmatch、tsf以及tsf-aes的半监督学习方法在ecapa-tdnn模型上通过置信度阈值选取的伪标签质量和数量对比图,图7(a)是所选取的伪标签数量对比图,图7(b)是所选取的伪标签质量对比图。图8是有标签占比33%时,基于fixmatch、flexmatch、tsf以及tsf-aes的半监督学习方法在ecapa-tdnn模型上通过置信度阈值选取的伪标签质量和数量对比图,图8(a)是所选取的伪标签数量对比图,图8(b)是所选取的伪标签质量对比图。对于伪标签的数量,fixmatch方法和flexmatch方法呈现两个极端,在不同有标签数据量下,fixmatch方法通过置信度阈值选取的伪标签数量均较少,最多的情况下也不足全部数据的10%。flexmatch方法通过课程伪标签算法几乎每次都选取了全部的无标签数据。本发明构建的基于tsf的半监督学习方法所选取伪标签的数量适中且缓慢上升,本发明提出的基于tsf-aes半监督声纹识别方法选取伪标签的数量呈阶段性上升,每一次大幅上升表明改变了一次置信度阈值,最终选取的伪标签数量均达到了85%以上,相比tsf方法提升明显。对于伪标签的质量,fixmatch方法通过高置信度阈值选取的伪标签质量在模型训练初期呈现震荡趋势,多数情况下在模型训练后期逐渐趋于平稳并接近100%,但是当有标签占比33%时,其选取的伪标签质量最终只能达到70%,说明fixmatch方法无法
让模型学习到足够的分类能力,从而无法通过置信度阈值选取足够高质量的伪标签。flexmatch方法由于在模型训练初期就选取了几乎全部的无标签数据,其伪标签的质量多数情况下接近0,当有标签数据占比33%时,模型由于有较多的有标签数据进行学习,所选取的伪标签质量从0开始逐渐上升,最后达到95%,说明flexmatch方法无法保证所选取的伪标签的质量。本发明构建的tsf的半监督学习方法根据模型自身性能预测出适合数据集的置信度阈值,并且可以在第三阶段半监督学习中选择到准确率接近100%的伪标签,本发明提出的基于tsf-aes半监督声纹识别方法通过自适应扩充策略,阶段性地降低置信度阈值从而扩充无标签数据的选取量,其所选取的伪标签质量随着自适应扩充略有下降,但是准确率仍然接近100%,说明本发明提出的基于tsf-aes半监督声纹识别方法所选取的伪标签数量不断增多的同时,质量并没有受到影响,进而验证了本发明对无标签数据的选取兼顾了高准确率和高利用率两种特性,从而达到了最佳的性能。
[0108]
为进一步验证第一阶段对比学习对于本发明的必要性,在有标签占比2.2%、5.5%以及11%时进行消融实验,分别验证第一阶段对比学习有无情况下,模型在第二阶段监督学习和第三阶段半监督学习中的性能以及在第二阶段监督学习中模型训练的速度。图9是第一阶段对比学习有无情况下,模型在第二阶段监督学习和第三阶段半监督学习中的等错误率对比图,图9(a)是第二阶段监督学习模型等错误率对比图,图9(b)是第三阶段半监督学习模型等错误率对比图。在没有第一阶段对比学习情况下,第二阶段和第三阶段模型的等错误率都要高于加入对比学习后的情况。当有标签数据占比2.2%时,在没有第一阶段对比学习的情况下,模型在第三阶段半监督学习过程中性能将无法进一步提升。表3为有标签数据占比2.2%、5.5%以及11%时,第一阶段对比学习有无情况下模型第二阶段监督学习训练的轮数(epochs),在没有第一阶段对比学习情况下,第二阶段监督学习的速度均慢于或等于有对比学习阶段的情况,且模型的等错误率也均高于有对比学习阶段的情况,当有标签数据较少时,没有对比学习阶段会导致模型第二阶段监督学习无法学习到足够的分类能力,导致第三阶段半监督学习无法继续提升性能,所以第一阶段对比学习对于本发明所提出的方法是必要的。
[0109]
表3
[0110][0111]
综上所述,本发明提出的一种基于自适应扩充策略的三阶段半监督声纹识别方法仅使用少量的有标签数据和大量的无标签数据就可以达到较优的性能,能够有效地完成声纹识别任务。
[0112]
以上所述的实施例仅是对本发明优选方式进行的描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。