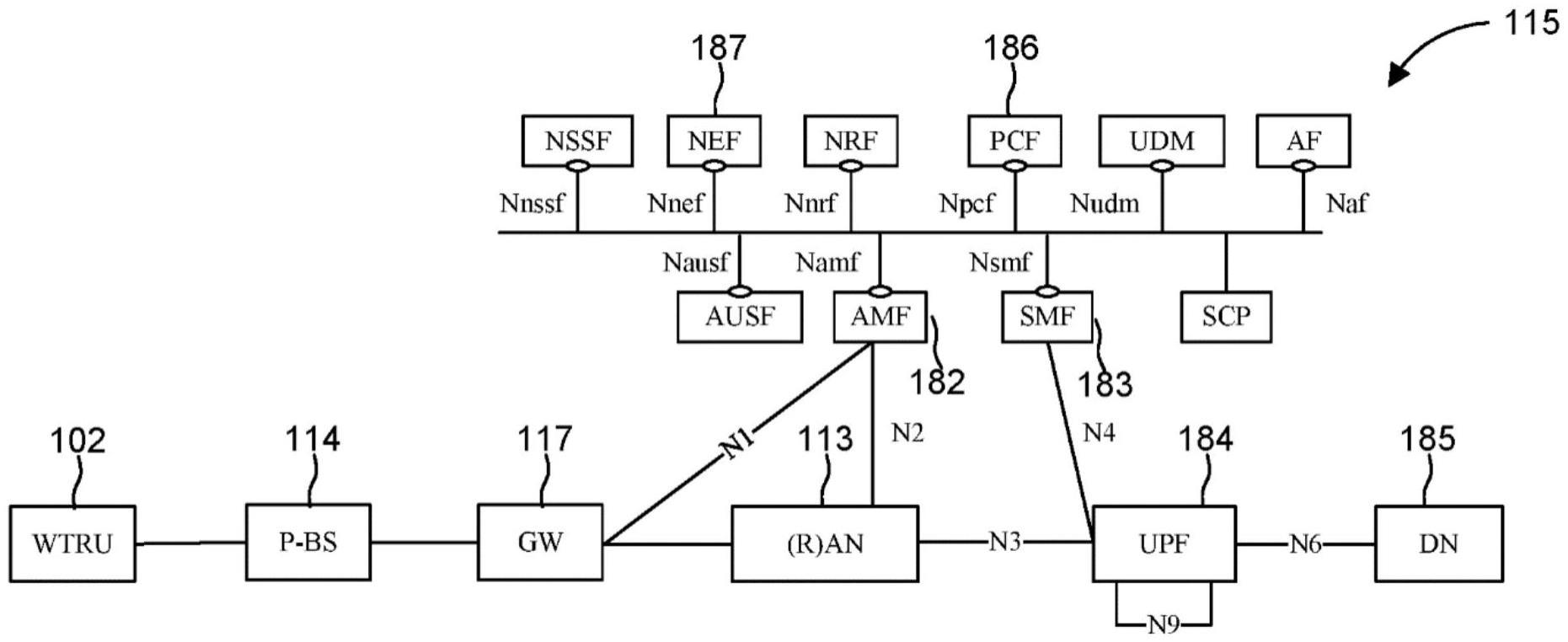
1.本发明涉及音频信号(例如,音频对象)的编码和编码音频信号(例如,编码音频对象)的解码。
背景技术:
2.引言
3.本文档描述了一种使用定向音频编码(dirac)以低比特率对基于对象的音频内容进行编码和解码的参数化方法。所呈现的实施例用作3gpp沉浸式语音和音频服务(ivas)编解码器的一部分,并且其中提供了对低比特率的具有元数据的独立流(ism)模式(一种离散编码方法)的有利替代。
4.现有技术
5.对象的离散编码
6.对基于对象的音频内容进行编码的最直接方法是单独地编码并将对象和对应的元数据一起发送。该方法的主要缺点是:随着对象数量的增加,对对象进行编码所需的比特消耗过高。该问题的简单解决方案是采用“参数化方法”,其中,一些相关参数是根据输入信号计算的,与组合若干个对象波形的合适下混信号一起进行量化和发送。
7.空间音频对象编码(saoc)
8.空间音频对象编码[saoc_std、saoc_aes]是一种参数化方法,其中,编码器基于某个下混矩阵d和参数集来计算下混信号,并将这两者发送给解码器。这些参数表示所有各个对象的心理声学相关属性和关系。在解码器处,使用渲染矩阵r将下混渲染到特定扬声器布局。
[0009]
saoc的主要参数是大小为n*n的对象协方差矩阵e,其中,n是指对象的数量。将该参数作为对象级别差异(old)和可选的对象间协方差(ioc)传输给解码器。
[0010]
矩阵e的各个元素e
i,j
由下式给出:
[0011][0012]
对象级别差异(old)被定义为
[0013][0014]
其中,和绝对对象能量(nrg)被描述为
[0015][0016]
以及
[0017][0018]
其中,i和j分别是对象xi和xj的对象索引,n指示时间索引,以及k指示频率索引。l指示时间索引集,并且m指示频率索引集。ε是避免被零除的附加常数,例如ε=10。
[0019]
输入对象(ioc)的相似度测量值可以例如由互相关给出:
[0020][0021]
大小为n_dmx*n的下混矩阵d由元素d
i,j
来定义,其中,i是指下混信号的通道索引,并且j是指对象索引。对于立体声下混(n_dmx=2),d
i,j
根据参数dmg和dcld被计算为
[0022][0023][0024]
其中,dmgi和dcldi由下式给出:
[0025][0026][0027]
对于单声道下混(n_dmx=1)情况,d
i,j
仅根据dmg参数被计算为
[0028][0029]
其中,
[0030][0031]
空间音频对象编码-3d(saoc-3d)
[0032]
空间音频对象编码3d音频再现(saoc-3d)[mpegh_aes、mpegh_ieee、mpegh_std、saoc_3d_pat]是上述mpeg saoc技术的扩展,mpeg saoc技术以比特率非常高效的方式对通
道和对象信号进行压缩和渲染。
[0033]
与saoc的主要差异是:
[0034]
·
虽然原始saoc仅支持多达两个下混通道,但saoc-3d可以将多对象输入映射到任意数量的下混通道(和关联的辅助信息)。
[0035]
·
与已经使用mpeg环绕声作为多通道输出处理器的经典saoc相比,直接渲染到多通道输出。
[0036]
·
丢弃了一些工具,例如残差编码工具。
[0037]
尽管存在这些差异,但从参数角度来看,saoc-3d与saoc相同。saoc-3d解码器——类似于saoc解码器——接收多通道下混x、协方差矩阵e、渲染矩阵r和下混矩阵d。
[0038]
渲染矩阵r由输入通道和输入对象来定义,并且分别从格式转换器(通道)和对象渲染器(对象)接收。
[0039]
下混矩阵d由元素d
i,j
来定义,其中,i是指下混信号的通道索引,并且j是指对象索引并根据下混增益(dmg)进行计算:
[0040][0041]
其中,
[0042][0043]
大小为n_out*n_out的输出协方差矩阵c被定义为:
[0044]
c=rer
*
[0045]
相关方案
[0046]
存在与saoc本质上相似但存在以下细微差异的若干个其他方案:
[0047]
·
针对对象的双耳提示编码(bcc)已经在例如[bcc2001]中进行了描述,并且是saoc技术的前身。
[0048]
·
联合对象编码(joc)和高级联合对象编码(a-joc)执行与saoc类似的功能,同时在解码器侧提供大致分离的对象,而不将它们渲染到特定输出扬声器布局[joc_aes,ac4_aes]。该技术将上混矩阵的元素从下混发送给分离对象作为参数(而不是old)。
[0049]
定向音频编码(dirac)
[0050]
另一种参数化方法是定向音频编码。dirac[pulkki2009]是空间声音的感知驱动再现。假设:在一个时间实例并针对一个临界频带,人类听觉系统的空间分辨率仅限于对一个方向线索和另一耳间相干性线索进行解码。
[0051]
基于这些假设,dirac通过淡入淡出两个流来表示一个频带中的空间声音:非定向扩散流和定向非扩散流。dirac处理分两个阶段执行:分析和合成,如图12a和图12b所示。
[0052]
在dirac分析阶段,将b格式的一阶重合麦克风视为输入,并在频域中分析声音的扩散度和到达方向。
[0053]
在dirac合成级中,声音被划分为两个流,即非扩散流和扩散流。使用幅度平移(panning)将非扩散流再现为点源,这可以通过使用向量基幅度平移(vbap)[pulkki 1997]来进行。扩散流负责产生包围感,并且是通过向扬声器传送相互解相关信号来产生的。
[0054]
图12a中的分析级包括带滤波器1000、能量估计器1001、强度估计器1002、时间平
均元件999a和999b、扩散度计算器1003和方向计算器1004。所计算的空间参数是每个时间/频率区的介于0和1之间的扩散度值和由块1004生成的每个时间/频率区的到达方向参数。在图12a中,方向参数包括方位角和仰角,该方位角和仰角指示声音相对于参考或收听位置并且具体地相对于麦克风所在位置的到达方向,从该位置收集输入到带滤波器1000的四个分量信号。在图12a中,这些分量信号是一阶环绕声分量,该一阶环绕声分量包括全向分量w、方向分量x、另一方向分量y和又一方向分量z。
[0055]
图12b所示的dirac合成级包括用于生成b格式麦克风信号w、x、y、z的时间/频率表示的带通滤波器1005。将各个时间/频率区的对应信号输入到虚拟麦克风级1006,该虚拟麦克风级1006针对每个通道生成虚拟麦克风信号。具体地,为了生成例如中央通道的虚拟麦克风信号,将虚拟麦克风指向中央通道的方向,并且所得信号是中央通道的对应分量信号。然后经由直接信号分支1015和扩散信号分支1014处理该信号。两个分支都包括对应的增益调节器或放大器,这些增益调节器或放大器在块1007、1008中由从原始扩散度参数导出的扩散度值控制,并且在块1009、1010中被进一步处理以获得一定麦克风补偿。
[0056]
还使用从由方位角和仰角组成的方向参数导出的增益参数对直接信号分支1015中的分量信号进行增益调整。具体地,将这些角度输入到vbap(向量基幅度平移)增益表1011中。对于每个通道,将结果输入到扬声器增益平均级1012和另一归一化器1013,然后将所得增益参数转发给直接信号分支1015中的放大器或增益调节器。在组合器1017中,对在解相关器1016的输出处生成的扩散信号和直接信号或非扩散流进行组合,然后,在另一组合器1018中将其他子带相加,该另一组合器1018例如可以是合成滤波器组。因此,生成用于某个扬声器的扬声器信号,并且针对某个扬声器设置中的其他扬声器1019的其他通道执行相同的过程。
[0057]
dirac合成的高质量版本如图12b所示,其中,合成器接收所有b格式信号,根据这些b格式信号,针对每个扬声器方向计算虚拟麦克风信号。所使用的方向图通常是偶极子。然后,取决于关于分支1016和1015所讨论的元数据,以非线性方式修改虚拟麦克风信号。图12b中未示出dirac的低比特率版本。然而,在该低比特率版本中,经发送单个音频通道。处理上的不同之处在于:所有虚拟麦克风信号都将被所接收到的单个音频通道代替。虚拟麦克风信号被划分为两个流,即被分别处理的扩散流和非扩散流。通过使用向量基幅度平移(vbap)将非扩散声音再现为点源。在平移时,在单声道声音信号与扬声器特定增益因子相乘之后,将单声道声音信号应用于扬声器子集。使用扬声器设置的信息和指定的平移方向来计算增益因子。在低比特率版本中,将输入信号简单地平移到由元数据暗示的方向。在高质量版本中,每个虚拟麦克风信号与对应的增益因子相乘,这产生与平移相同的效果,但是它不太容易出现任何非线性伪音。
[0058]
扩散声音合成的目的是创建围绕听者的声音感知。在低比特率版本中,通过对输入信号进行解相关并从每个扬声器中再现它来再现扩散流。在高质量版本中,扩散流的虚拟麦克风信号在某种程度上已经不相干,并且仅需要轻微地对它们进行解相关处理。
[0059]
dirac参数(也被称为空间元数据)由扩散度和方向的元组组成,该方向在球坐标中由两个角度(即,方位角和仰角)来表示。如果分析级和合成级两者都在解码器侧运行,则dirac参数的时间-频率分辨率可以被选择为与用于dirac分析和合成的滤波器组相同,即,用于音频信号的滤波器组表示的每个时隙和频率区间的不同参数集。
[0060]
已经进行了一些工作来减少元数据的大小,以使dirac范例能够用于空间音频编码和电话会议场景[hirvonen2009]。
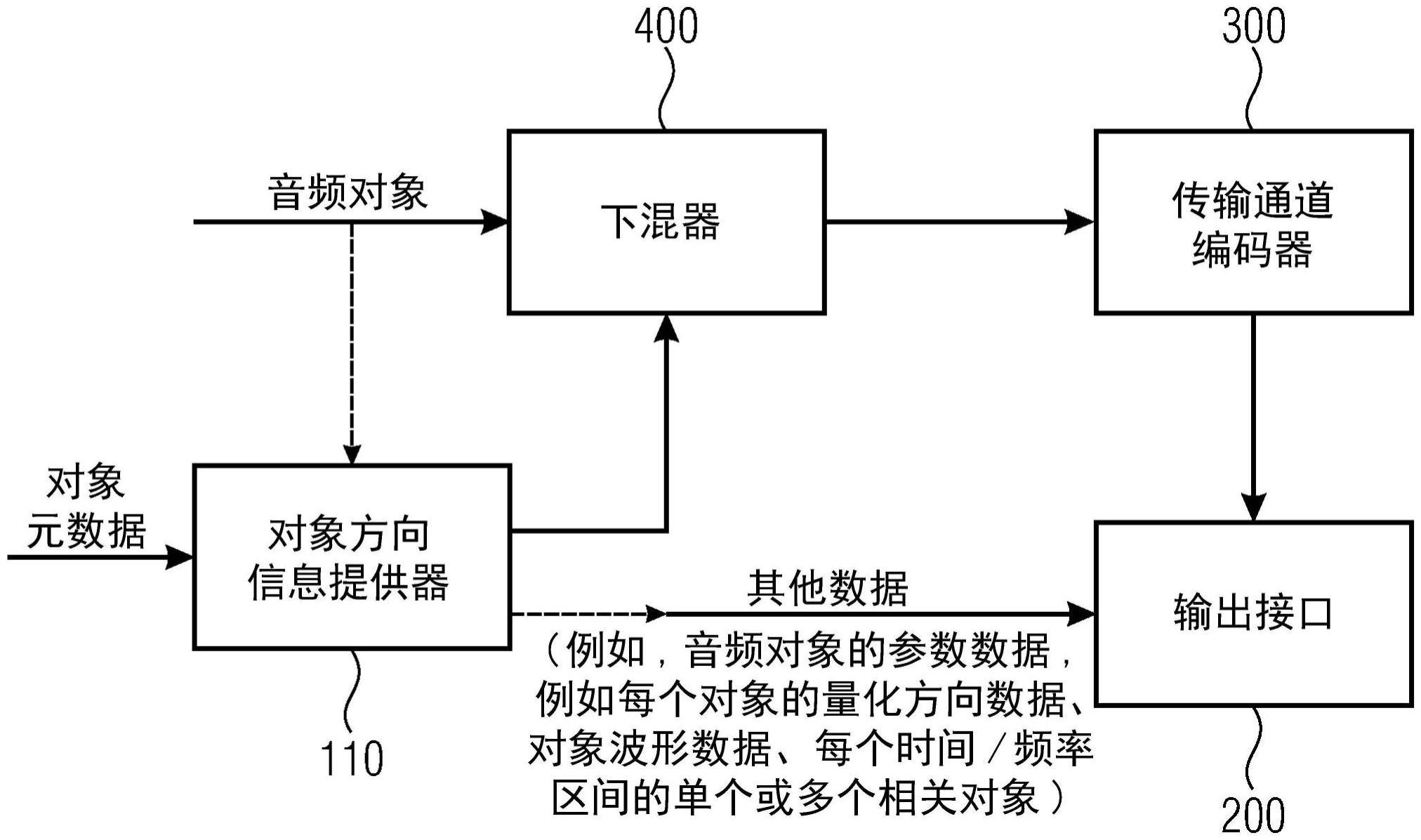
[0061]
在[wo2019068638]中,介绍了一种基于dirac的通用空间音频编码系统。与针对b格式(一阶环绕声格式)输入设计的经典dirac相比,该系统可以接受一阶或更高阶环绕声、多通道或基于对象的音频输入,并且还允许混合类型输入信号。所有信号类型以单独或组合的方式进行高效编码和发送。前者组合了渲染器(解码器侧)处的不同表示,而后者在dirac域中使用不同音频表示的编码器侧组合。
[0062]
与dirac框架的兼容性
[0063]
本实施例建立在如[wo2019068638]中所提出的任意输入类型的统一框架之上,并且——与[wo2020249815]对多通道内容所做的类似——旨在消除无法将dirac参数(方向和扩散度)高效地应用于对象输入的问题。事实上,根本不需要扩散度参数,但发现每个时间/频率单元的单个方向提示不足以再现高质量的对象内容。因此,该实施例建议每个时间/频率单元采用多个方向提示,并相应地引入适配的参数集,该适配的参数集在对象输入的情况下代替经典dirac参数。
[0064]
低比特率的灵活系统
[0065]
与从听者的角度使用基于场景的表示的dirac相比,saoc和saoc-3d是针对基于通道和基于对象的内容而设计的,其中参数描述了通道/对象之间的关系。为了将基于场景的表示用于对象输入并因此与dirac渲染器兼容,同时确保高效表示和高质量再现,需要适配的参数集以便也允许用信号发送多个方向提示。
[0066]
该实施例的重要目标是找到一种以低比特率对对象输入进行高效编码并且对于越来越多的对象具有良好可扩展性的方法。对每个对象信号进行离散编码无法提供这种可扩展性:每个附加对象都会导致整体比特率显著上升。如果数量增加的对象超过了所允许的比特率,这将直接导致输出信号非常明显的劣化;这种劣化是支持该实施例的另一论据。
[0067]
本发明的目的是提供对多个音频对象进行编码或对编码音频信号进行解码的改进构思。
[0068]
该目的是通过根据权利要求1所述的用于编码的装置、根据权利要求18所述的解码器、根据权利要求28所述的编码方法、根据权利要求29所述的解码方法、根据权利要求30所述的计算机程序或根据权利要求31所述的编码音频信号来实现的。
[0069]
在本发明的一方面中,本发明基于以下发现:对于多个频率区间中的一个或多个频率区间,定义了至少两个相关音频对象,并且与这至少两个相关对象相关的参数数据被包括在编码器侧,并用于解码器侧,以获得高质量且高效的音频编码/解码构思。
[0070]
根据本发明的另一方面,本发明基于以下发现:执行适合于与每个对象相关联的方向信息的特定下混,使得具有对整个对象(即,对于时间帧中的所有频率区间)有效的关联方向信息的每个对象被用于将该对象下混到多个传输通道中。方向信息的使用例如等同于生成传输通道作为具有某些可调整特性的虚拟麦克风信号。
[0071]
在解码器侧,执行依赖于协方差合成的特定合成,该协方差合成在特定实施例中特别适合于不受解相关器引入的伪音影响的高质量协方差合成。在其他实施例中,使用依赖于与标准协方差合成相关的特定改进的高级协方差合成,以便提高音频质量和/或减少计算在协方差合成内使用的混合矩阵所需的计算量。
[0072]
然而,即使在通过基于所发送的选择信息显式地确定时间/频率区间内的各个贡献来进行音频渲染的更经典合成中,音频质量相对于现有技术对象编码方法或通道下混方法而言是优越的。在这种情况下,每个时间/频率区间具有对象标识信息,并且当执行音频渲染时,即当考虑每个对象的方向贡献时,使用该对象标识来查找与该对象信息相关联的方向,以便确定每个时间/频率区间的各个输出通道的增益值。因此,当时间/频率区间中仅存在单个相关对象时,则基于对象id和关联对象的方向信息的“码本”,针对每个时间/频率区间仅确定该单个对象的增益值。
[0073]
然而,当时间/频率区间中存在多于1个相关对象时,则计算每个相关对象的增益值,以便将传输通道的对应时间/频率区间分配到由用户提供的输出格式(例如,某个通道格式是立体声格式、5.1格式等)控制的对应输出通道中。无论增益值是否用于协方差合成的目的(即,用于应用混合矩阵将传输通道混合到输出通道中的目的)、或者增益值是否用于通过将增益值乘以一个或多个传输通道的对应时间/频率区间然后对对应时间/频率区间中的每个输出通道的贡献进行求和来显式地确定时间/频率区间中的每个对象的单独贡献(可能通过添加扩散信号分量得到增强),输出音频质量由于通过确定每个频率区间的一个或多个相关对象所提供的灵活性而仍然得到增强。
[0074]
这种确定可能是非常高效的,因为时间/频率区间的仅一个或多个对象id必须被编码,并与每个对象的方向信息一起发送给解码器,然而,这也可能是非常高效的。这是因为:对于帧,所有频率区间仅存在单个方向信息。
[0075]
因此,无论合成是使用优选增强的协方差合成还是使用每个对象的显式传输通道贡献的组合进行的,都获得了高效和高质量的对象下混,该对象下混优选地通过使用特定对象方向相关下混来增强,该特定对象方向相关下混依赖于反映了生成传输通道作为虚拟麦克风信号的下混权重。
[0076]
与每个时间/频率区间的两个或更多个相关对象相关的方面可以优选地与执行对象到传输通道的特定方向相关下混的方面相结合。然而,这两个方面也可以彼此独立地应用。此外,尽管在某些实施例中执行每个时间/频率区间的两个或更多个相关对象的协方差合成,但高级协方差合成和高级传输通道到输出通道上混也可以通过仅发送每个时间/频率区间的单个对象标识来执行。
[0077]
此外,无论每个时间/频率区间是否存在单个或若干个相关对象,上混也可以通过计算标准或增强协方差合成中的混合矩阵来执行,或者上混可以通过单独确定时间/频率区间的贡献(其基于用于从方向“码本”中获取特定方向信息的对象标识)以确定对应贡献的增益值来执行。然后对这些进行求和,以便在每个时间/频率区间存在两个或更多个相关对象的情况下获得每个时间/频率区间的完整贡献。然后,该求和步骤的输出等同于混合矩阵应用的输出,并且执行最终的滤波器组处理以便生成对应输出格式的时域输出通道信号。
附图说明
[0078]
随后参考附图描述本发明的优选实施例,在附图中:
[0079]
图1a是根据每个时间/频率区间具有至少两个相关对象的第一方面的音频编码器的实现;
[0080]
图1b是根据具有方向相关对象下混的第二方面的编码器的实现;
[0081]
图2是根据第二方面的编码器的优选实现;
[0082]
图3是根据第一方面的编码器的优选实现;
[0083]
图4是根据第一方面和第二方面的解码器的优选实现;
[0084]
图5是图4的协方差合成处理的优选实现;
[0085]
图6a是根据第一方面的解码器的实现;
[0086]
图6b是根据第二方面的解码器;
[0087]
图7a是用于示出根据第一方面确定参数信息的流程图;
[0088]
图7b是进一步确定参数化数据的优选实现;
[0089]
图8a示出了高分辨率滤波器组时间/频率表示;
[0090]
图8b示出了根据第一方面和第二方面的优选实现的针对帧j的相关辅助信息的传输;
[0091]
图8c示出了包括在编码音频信号中的“方向码本”;
[0092]
图9a示出了根据第二方面的优选编码方式;
[0093]
图9b示出了根据第二方面的静态下混的实现;
[0094]
图9c示出了根据第二方面的动态下混的实现;
[0095]
图9d示出了第二方面的另一实施例;
[0096]
图10a示出了第一方面的解码器侧的优选实现的流程图;
[0097]
图10b示出了根据对每个输出通道的贡献进行求和的实施例的图10a的输出通道计算的优选实现;
[0098]
图10c示出了根据第一方面的针对多个相关对象确定功率值的优选方式;
[0099]
图10d示出了使用依赖于对混合矩阵的计算和应用的协方差合成来计算图10a的输出通道的实施例;
[0100]
图11示出了用于对时间/频率区间的混合矩阵的高级计算的若干个实施例;
[0101]
图12a示出了现有技术的dirac编码器;以及
[0102]
图12b示出了现有技术的dirac解码器。
具体实施方式
[0103]
图1a示出了用于对多个音频对象进行编码的装置,该装置在输入处接收原样的音频对象和/或音频对象的元数据。编码器包括对象参数计算器100,其针对时间/频率区间提供至少两个相关音频对象的参数数据,并且将该数据转发给输出接口200。具体地,对象参数计算器针对与时间帧相关的多个频率区间中的一个或多个频率区间计算至少两个相关音频对象的参数数据,其中,具体地,至少两个相关音频对象的数量低于多个音频对象的总数。因此,对象参数计算器100实际上执行选择,而不仅指示所有对象是相关的。在优选实施例中,该选择是通过相关性来进行的,并且相关性是通过幅度相关测量值(例如,幅度、功率、响度、或通过将幅度提高到不同于1并且优选地大于1的功率而获得的另一种测量值)来确定的。然后,如果一定数量的相关对象可用于时间/频率区间,则选择具有最相关特性的对象(即,在所有对象中具有最高功率的对象),并且将关于这些所选对象的数据包括在参数数据中。
[0104]
输出接口200被配置为输出编码音频信号,该编码音频信号包括关于一个或多个频率区间的至少两个相关音频对象的参数数据的信息。取决于实现,输出接口可以接收其他数据(例如,对象下混、或表示对象下混的一个或多个传输通道、或附加参数、或若干个对象被下混的混合表示形式的对象波形数据、或单独表示形式的其他对象)并将其输入到编码音频信号中。在这种情况下,将对象直接引入或“复制”到对应的传输通道中。
[0105]
图1b示出了根据第二方面的用于对多个音频对象进行编码的装置的优选实现,其中接收到音频对象和相关对象元数据,该相关对象元数据指示关于多个音频对象的方向信息,即,每个对象或一组对象(如果该组对象具有与其相关联的相同方向信息)的一个方向信息。将音频对象输入到下混器400中,以便对多个音频对象进行下混以获得一个或多个传输通道。此外,提供了传输通道编码器300,该传输通道编码器300对一个或多个传输通道进行编码以获得一个或多个编码传输通道,该一个或多个编码传输通道然后被输入到输出接口200中。具体地,下混器400连接到对象方向信息提供器110,该对象方向信息提供器110在输入处接收可以导出对象元数据的任何数据,并输出由下混器400实际使用的方向信息。从对象方向信息提供器110转发给下混400的方向信息优选地是去量化方向信息,即,然后在解码器侧可用的相同方向信息。为此,对象方向信息提供器110被配置为导出或提取或获取非量化对象元数据,然后对对象元数据进行量化以导出表示图1b所示的“其他数据”中的量化索引的量化对象元数据,该量化索引在优选实施例中被提供给输出接口200。此外,对象方向信息提供器110被配置为对量化对象方向信息进行去量化以获得从块110转发给下混器400的实际方向信息。
[0106]
优选地,输出接口200被配置为附加地接收音频对象的参数数据、对象波形数据、每个时间/频率区间的单个或多个相关对象的一个或若干个标识、以及如之前所讨论的量化方向数据。
[0107]
随后,示出了其他实施例。提出了一种用于对音频对象信号进行编码的参数化方法,该参数化方法允许低比特率的高效传输以及消费者侧的高质量再现。基于考虑每个关键频带和时间实例(时间/频率区)的一个方向提示的dirac原理,针对输入信号的时间/频率表示的每个这样的时间/频率区确定最主要的对象。由于这证明了对于对象输入来说是不够的,因此每个时间/频率区确定附加的、第二最主要的对象,并且基于这两个对象,计算功率比以确定两个对象中的每个对象对所考虑的时间/频率区的影响。注意:针对每个时间/频率单位考虑多于两个的最主要对象也是可想象的,特别是对于越来越多的输入对象。为了简单起见,以下描述主要基于每个时间/频率单元的两个主要对象。
[0108]
因此,发送给解码器的参数化辅助信息包括:
[0109]
·
针对每个时间/频率区(或参数带)的相关(主要)对象子集计算的功率比。
[0110]
·
表示每个时间/频率区(或参数带)的相关对象子集的对象索引。
[0111]
·
与对象索引相关联并针对每个帧提供的方向信息(其中每个时域帧包括多个参数带,并且每个参数带包括多个时间/频率区)。
[0112]
方向信息可经由与音频对象信号相关联的输入元数据文件获得。例如,可以基于帧来指定元数据。除了辅助信息之外,组合输入对象信号的下混信号也被发送给解码器。
[0113]
在渲染阶段期间,所发送的方向信息(经由对象索引导出)用于将所发送的下混信号(或更一般地:传输通道)平移到适当方向。基于所发送的功率比将下混信号分配到两个
相关的对象方向,该功率比用作加权因子。该处理是针对解码下混信号的时间/频率表示的每个时间/频率区进行的。
[0114]
本节对编码器侧处理进行了总结,然后详细描述了参数和下混计算。音频编码器接收一个或多个音频对象信号。对于每个音频对象信号,描述对象属性的元数据文件是相关联的。在该实施例中,关联元数据文件中所描述的对象属性对应于基于帧提供的方向信息,其中,一个帧对应于20毫秒。每个帧由帧号来标识,也被包含在元数据文件中。方向信息以方位角和仰角信息的形式给出,其中,方位角从(-180,180]度中取值,而仰角从[-90,90]度中取值。元数据中提供的其他属性可以包括例如距离、传播、增益;在该实施例中未考虑这些属性。
[0115]
元数据文件中提供的信息与实际音频对象文件一起用于创建参数集,该参数集被发送给解码器并用于对最终音频输出文件进行渲染。更具体地,编码器估计每个给定时间/频率区的主要对象子集的参数,即功率比。主要对象子集由对象索引来表示,该对象索引也用于标识对象方向。这些参数与传输通道和方向元数据一起被发送给解码器。
[0116]
图2给出了编码器的概览,其中传输通道包括根据输入对象文件计算的下混信号和在输入元数据中提供的方向信息。传输通道的数量总是小于输入目标文件的数量。在实施例的编码器中,编码音频信号由编码传输通道来表示,并且编码参数化辅助信息由编码对象索引、编码功率比和编码方向信息指示。编码传输通道和编码参数化辅助信息两者一起形成由多路复用器220输出的比特流。具体地,编码器包括接收输入对象音频文件的滤波器组102。此外,对象元数据文件被提供给提取器方向信息块110a。块110a的输出被输入到量化方向信息块110b中,该量化方向信息块110b将方向信息输出到执行下混计算的下混器400。此外,经量化的方向信息(即,量化索引)从块110b转发给编码方向信息202块,该编码方向信息202块优选地执行某种熵编码以便进一步降低所需的比特率。
[0117]
此外,滤波器组102的输出被输入到信号功率计算块104,并且信号功率计算块104的输出被输入到对象选择块106并且附加地被输入到功率比计算块108。功率比计算块108还连接到对象选择块106,以便计算功率比(即,仅用于所选对象的组合值)。在块210中,对所计算的功率比或组合值进行量化和编码。如稍后将概述的,功率比是优选的,以便保存一个功率数据项的传输。然而,在不需要这种保存的其他实施例中,不是功率比,而是实际信号功率或从由块104确定的信号功率中导出的其他值可以在对象选择器106的选择下被输入到量化器和编码器中。然后,不需要功率比计算108,并且对象选择106确保仅将相关参数化数据(即,相关对象的功率相关数据)输入到块210中以用于量化和编码的目的。
[0118]
将图1a与图2进行比较,块102、104、110a、110b、106、108优选地被包括在图1a的对象参数计算器100中,并且块202、210、220优选地被包括在图1a的输出接口块200中。
[0119]
此外,图2中的核心编码器300对应于图1b的传输通道编码器300,下混计算块400对应于图1b的下混器400,以及图1b的对象方向信息提供器110对应于图2的块110a、110b。此外,图1b的输出接口200优选地以与图1a的输出接口200相同的方式实现并且包括图2的块202、210、220。
[0120]
图3示出了编码器变体,其中,下混计算是可选的并且不依赖于输入元数据。在该变体中,输入音频文件可以直接馈送到核心编码器中,该核心编码器从它们创建传输通道,因此传输通道的数量对应于输入对象文件的数量;如果输入对象的数量是1或2,这将特别
有趣。对于大量对象,下混信号仍将用于减少要发送的数据量。
[0121]
在图3中,相似的附图标记指代图2的相似功能。这不仅针对图2和图3有效,而且对本说明书中描述的所有其他图也有效。与图2不同,图3在没有任何方向信息的情况下执行下混计算400。因此,下混计算可以是例如使用预先已知的下混矩阵的静态下混,或者可以是不依赖于与包括在输入对象音频文件中的对象相关联的任何方向信息的能量相关下混。然而,方向信息在块110a中被提取并且在块110b中被量化,并且经量化的值被转发给方向信息编码器202以便在形成比特流的编码音频信号(例如,二进制编码音频信号)中具有编码方向信息。
[0122]
在具有不太多数量的输入音频对象文件的情况下或者在具有足够的可用传输带宽的情况下,下混计算块400也可以被省去,使得输入音频对象文件直接表示由核心编码器编码的传输通道。在这种实现中,也不需要块104、104、106、108、210。然而,优选的实现导致混合实现,其中,一些对象被直接引入到传输通道中,而其他对象被下混到一个或多个传输通道中。在这种情况下,则图3所示的所有块将是必需的,以便直接生成如下比特流,该比特流在编码传输通道内具有一个或多个对象以及由图2或图3的下混器400生成的一个或多个传输通道。
[0123]
参数计算
[0124]
使用滤波器组将包括所有输入对象信号的时域音频信号转换到时域/频域中。例如:cldfb(复杂低延迟滤波器组)分析滤波器将20毫秒的帧(对应于48khz的采样率下的960个样本)转换为大小为16x60的时间/频率区,其中具有16个时隙和60个频带。对于每个时间/频率单元,瞬时信号功率被计算为:
[0125]
pi(k,n)=|xi(k,n)|2,
[0126]
其中,k表示频带索引,n表示时隙索引,以及i表示对象索引。由于每个时间/频率区的发送参数在最终比特率方面的成本非常高,因此采用分组以便计算针对减少数量的时间/频率区的参数。例如:16个时隙可以一起被组合为单个时隙,并且60个频带可以基于心理声学尺度被组合为11个频带。这将16x60的初始尺寸减小到与11个所谓的参数带相对应的1x11。基于分组对瞬时信号功率值进行求和,以获得减小维度的信号功率:
[0127][0128]
其中,t对应于该示例中的15,并且bs和be定义参数带边界。
[0129]
为了确定针对其计算参数的最主要对象的子集,所有n个输入音频对象的瞬时信号功率值按降序进行排序。在该实施例中,我们确定两个最主要对象,并且范围从0至n-1的对应对象索引被存储为要发送的参数的一部分。此外,计算了将两个主要对象信号彼此相关的功率比:
[0130]
[0131][0132]
或者用不限于两个对象的更一般的表达方式:
[0133][0134]
其中,在该上下文中,s表示要考虑的主要对象的数量,并且:
[0135][0136]
在两个主要对象的情况下,对于两个对象中的每个对象,0.5的功率比意味着两个对象同样存在于对应的参数带内,而1和0的功率比表示两个对象之一不存在。这些功率比被存储为要发送的参数的第二部分。由于功率比总和为1,因此发送s-1个而不是s个值就足够了。
[0137]
除了每个参数带的对象索引和功率比值之外,还必须发送从输入元数据文件中提取的每个对象的方向信息。由于信息最初是基于帧来提供的,因此这是针对每个帧进行的(其中,每个帧在所描述的示例中包括11个参数带或总共16x60个时间/频率区)。因此,对象索引间接地表示对象方向。注意:由于功率比总和为1,因此每个参数带要发送的功率比的数量可以减少1;例如:在考虑2个相关对象的情况下,发送1个功率比值就足够了。
[0138]
对方向信息和功率比值两者进行量化并与对象索引进行组合以形成参数化辅助信息。然后,该参数化辅助信息被编码,并与编码传输通道/下混信号一起被混合到最终比特流表示中。例如,通过使用每个值3个比特来量化功率比,实现输出质量和扩展比特率之间的良好折衷。方向信息可以被提供有5度的角分辨率,并随后以每个方位角值7个比特和每个仰角值6个比特进行量化,以给出实际示例。
[0139]
下混计算
[0140]
所有输入音频对象信号被组合为下混信号,该下混信号包括一个或多个传输通道,其中,传输通道的数量小于输入对象信号的数量。注意:在该实施例中,如果仅存在一个输入对象,则仅出现单个传输通道,这因此意味着下混计算被跳过。
[0141]
如果下混包括两个传输通道,则该立体声下混例如可以被计算为虚拟心形麦克风信号。虚拟心形麦克风信号是通过在元数据文件中应用针对每个帧提供的方向信息来确定的(这里,假设所有仰角值为零):
[0142]wl
=0.5 0.5*cos(方位角-pi/2)
[0143]
wr=0.5 0.5*cos(方位角 pi/2)
[0144]
在这里,虚拟心形位于90
°
和-90
°
处。因此确定两个传输通道(左和右)中每个传输通道的单独权重,并将这些单独权重应用于对应的音频对象信号:
[0145][0146][0147]
在该上下文中,n是大于或等于2的输入对象数量。如果针对每个帧更新了虚拟心形权重,则采用适合于方向信息的动态下混。另一种可能性是采用固定下混,其中假设每个对象位于静态位置处。该静态位置例如可以对应于对象的初始方向,这然后导致对于所有帧都相同的静态虚拟心形权重。
[0148]
如果目标比特率允许,则可以设想多于两个传输通道。在三个传输通道的情况下,则心形可以均匀地布置在例如0
°
、120
°
和-120
°
处。如果使用四个传输通道,则第四心形可以面朝上或者四个心形可以再次以均匀的方式水平地布置。如果对象位置例如仅是一个半球的一部分,则该布置也可以针对对象位置定制。所得下混信号由核心编码器进行处理,并与编码参数化辅助信息一起被转化为比特流表示。
[0149]
备选地,可以将输入对象信号馈送到核心编码器中而不被组合为下混信号。在这种情况下,所得传输通道的数量对应于输入对象信号的数量。通常,给出与总比特率相关的传输通道的最大数量。然后,仅当输入对象信号的数量超过传输通道的该最大数量时才采用下混信号。
[0150]
图6a示出了用于对编码音频信号(例如,由图1a或图2或图3输出的信号)进行解码的解码器,该编码音频信号包括多个音频对象的方向信息和一个或多个传输通道。此外,对于时间帧的一个或多个频率区间,编码音频信号包括至少两个相关音频对象的参数数据,其中,至少两个相关对象的数量低于多个音频对象的总数。具体地,解码器包括用于提供频谱表示形式的一个或多个传输通道的输入接口,该频谱表示在时间帧中具有多个频率区间。这表示从输入接口块600转发给音频渲染器块700的信号。具体地,音频渲染器700被配置用于使用包括在编码音频信号中的方向信息将一个或多个传输通道渲染为多个音频通道,音频通道的数量对于立体声输出格式优选地是两个通道,或者对于较多数量的输出格式(例如,3通道、5通道、5.1通道等)优选地是多于两个通道。具体地,音频渲染器700被配置为:针对一个或多个频率区间中的每一频率区间,根据与至少两个相关音频对象中的第一相关音频对象相关联的第一方向信息以及根据与至少两个相关音频对象中的第二相关音频对象相关联的第二方向信息来计算一个或多个传输通道的贡献。具体地,多个音频对象的方向信息包括与第一对象相关联的第一方向信息、以及与第二对象相关联的第二方向信息。
[0151]
图8b示出了帧的参数数据,在一个优选实施例中,该参数数据包括多个音频对象的方向信息810,此外还包括在812处示出的一定数量的参数带中的每个参数带的功率比,以及在块814处指示的每个参数带的一个(优选地是两个或甚至更多个)对象索引。具体地,图8c中更详细地示出了多个音频对象810的方向信息。图8c示出了具有从1至n的某个对象id的第一列的表,其中n是多个音频对象的数量。此外,提供了第二列,其具有每个对象的方向信息,该方向信息优选地作为方位角值和仰角值,或者在二维情况的情况下,仅作为方位
角值。这在818处被示出。因此,图8c示出了输入到图6a的输入接口600中的被包括在编码音频信号中的“方向码本”。来自列818的方向信息与来自列816的某个对象id唯一地相关联,并且对帧中的“整个”对象(即,对帧中的所有频带)有效。因此,无论频率区间的数量是高分辨率表示中的时间/频率区还是较低分辨率表示中的时间/参数带,仅单个方向信息被发送并被输入接口用于每个对象标识。
[0152]
在该上下文中,图8a示出了当图2或图3的滤波器组102被实现为之前讨论的cldfb(复杂低延迟滤波器组)时由该滤波器组生成的时间/频率表示。对于如之前关于图8b和图8c讨论给出方向信息的帧,滤波器组生成图8a中的范围从0至15的16个时隙和范围从0至59的60个频带。因此,一个时隙和一个频带代表时间/频率区802或804。然而,为了降低辅助信息的比特率,优选地将高分辨率表示转换为低分辨率表示,如图8b所示,其中仅存在单个时间区间,并且其中60个频带被转换为如图8b中的812处所示的11个参数带。因此,如图10c所示,高分辨率表示由时隙索引n和频带索引k来指示,并且低分辨率表示由分组时隙索引m和参数带索引l给出。然而,在本说明书的上下文中,时间/频率区间可以包括图8a的高分辨率时间/频率区802、804或由图10c中的块731c的输入处的分组时隙索引和参数带索引标识的低分辨率时间/频率单元。
[0153]
在图6a的实施例中,音频渲染器700被配置为:针对一个或多个频率区间中的每一频率区间,根据与至少两个相关音频对象中的第一相关音频对象相关联的第一方向信息以及根据与至少两个相关音频对象中的第二相关音频对象相关联的第二方向信息来计算一个或多个传输通道的贡献。在图8b所示的实施例中,块814具有参数带中每个相关对象的对象索引,即具有两个或更多个对象索引,使得每个时间频率区间存在两个贡献。
[0154]
如稍后将关于图10a概述的,对贡献的计算可以经由混合矩阵间接地进行,其中每个相关对象的增益值被确定并用于计算混合矩阵。备选地,如图10b所示,可以使用增益值再次显式地计算贡献,然后针对某个时间/频率区间中的每个输出通道,对经显式计算的贡献进行求和。因此,无论贡献是被显式计算的还是被隐式计算的,音频渲染器仍然使用方向信息将一个或多个传输通道渲染到多个音频通道中,使得对于一个或多个频率区间中的每一频率区间,根据与至少两个相关音频对象中的第一相关音频对象相关联的第一方向信息以及根据与至少两个相关音频对象中的第二相关音频对象相关联的第二方向信息,将一个或多个传输通道的贡献包括在多个音频通道中。
[0155]
图6b示出了根据第二方面的用于对编码音频信号进行解码的解码器,该编码音频信号包括:多个音频对象的方向信息和一个或多个传输通道;以及对于时间帧的一个或多个频率区间而言的音频对象的参数数据。同样,解码器包括接收编码音频信号的输入接口600,并且解码器包括用于使用方向信息将一个或多个传输通道渲染为多个音频通道的音频渲染器700。具体地,音频渲染器被配置为根据多个频率区间中的每个频率区间的一个或多个音频对象以及与频率区间中的一个或多个相关音频对象相关联的方向信息,计算直接响应信息。该直接响应信息优选地包括用于协方差合成或高级协方差合成或用于显式计算一个或多个传输通道的贡献的增益值。
[0156]
优选地,音频渲染器被配置为使用时间/频带中的一个或多个相关音频对象的直接响应信息并使用关于多个音频通道的信息来计算协方差合成信息。此外,将协方差合成信息(其优选地是混合矩阵)应用于一个或多个传输通道以获得多个音频通道。在另一实现
中,直接响应信息是一个或多个音频对象中的每个音频对象的直接响应向量,并且协方差合成信息是协方差合成矩阵,并且音频渲染器被配置为在应用协方差合成信息时针对每个频率区间执行矩阵运算。
[0157]
此外,音频渲染器700被配置为:在计算直接响应信息时,导出一个或多个音频对象的直接响应向量,并且针对一个或多个音频对象,根据每个直接响应向量来计算协方差矩阵。此外,在计算协方差合成信息时,计算目标协方差矩阵。然而,可以使用目标协方差矩阵的相关信息(即,一个或多个最主要对象的直接响应矩阵或向量,以及通过应用功率比而确定的被指示为e的直接功率的对角矩阵)而不是目标协方差矩阵。
[0158]
因此,目标协方差信息不一定必须是显式目标协方差矩阵,而是从一个音频对象的协方差矩阵或时间/频率区间中更多音频对象的协方差矩阵中、从关于时间/频率区间中的相应一个或多个音频对象的功率信息以及从用于一个或多个时间/频率区间的一个或多个传输通道导出的功率信息中导出的。
[0159]
比特流表示由解码器读取,并且编码传输通道和包含在其中的编码参数化辅助信息可用于进一步处理。参数化辅助信息包括:
[0160]
·
作为量化方位角和仰角值的方向信息(对于每个帧)
[0161]
·
表示相关对象子集的对象索引(对于每个参数带)
[0162]
·
将相关对象彼此相关的量化功率比(对于每个参数带)
[0163]
所有处理都是以逐帧方式进行的,其中每个帧包含一个或多个子帧。例如,帧可以由四个子帧组成,在这种情况下,一个子帧将具有5毫秒的持续时间。图4示出了解码器的简化概览。
[0164]
图4示出了实现第一方面和第二方面的音频解码器。图6a和图6b所示的输入接口600包括解复用器602、核心解码器604、用于对对象索引进行解码的解码器608、用于对功率比进行解码和去量化的解码器612、以及用于对612处指示的方向信息进行解码和去量化的解码器。此外,输入接口包括用于提供时间/频率表示形式的传输通道的滤波器组606。
[0165]
音频渲染器700包括:直接响应计算器704;原型矩阵提供器702,由例如用户接口接收到的输出配置所控制;协方差合成块706;以及合成滤波器组708,以便最终提供包括通道输出格式的音频通道数量的输出音频文件。
[0166]
因此,项目602、604、606、608、610、612优选地被包括在图6a和图6b的输入接口中,并且图4的项目702、704、706、708是图6a或图6b的以附图标记700指示的音频渲染器的部分。
[0167]
对编码参数化辅助信息进行解码,并重新获得量化功率比值、量化方位角值和量化仰角值(方向信息)、以及对象索引。未发送的一个功率比值是通过利用所有功率比值总和为1的事实来获得的。它们的分辨率(l,m)对应于编码器侧采用的时间/频率区的分组。在使用更精细的时间/频率分辨率(k,n)的进一步处理步骤期间,参数带的参数对该参数带中包含的所有时间/频率区有效,对应于使得(l,m)
→
(k,n)的扩展。
[0168]
编码传输通道由核心解码器进行解码。使用滤波器组(与编码器中使用的滤波器组相匹配),将如此解码的音频信号的每个帧转换为时间/频率表示,该时间/频率表示的分辨率通常优于(但至少等于)用于参数化辅助信息的分辨率。
[0169]
输出信号渲染/合成
[0170]
以下描述适用于音频信号的一个帧;t表示转置运算符:
[0171]
使用解码传输通道x=x(k,n)=[x1(k,n),x2(k,n)]
t
,即时间-频率表示形式的音频信号(在这种情况下包括两个传输通道)和参数化辅助信息,导出每个子帧(或用于降低计算复杂度的帧)的混合矩阵m以合成包括多个输出通道(例如,5.1、7.1、7.1 4等)的时间-频率输出信号y=y(k,n)=[y1(k,n),y2(k,n),y3(k,n),...]
t
:
[0172]
对于所有(输入)对象,使用所发送的对象方向,确定所谓的直接响应值,该直接响应值描述要用于输出通道的平移增益。这些直接响应值特定于目标布局,即扬声器的数量和位置(作为输出配置的一部分提供)。平移方法的示例包括向量基幅度平移(vbap)[pulkki1997]和边缘衰落幅度平移(efap)[borβ2014]。每个对象具有与之相关联的直接响应值的向量dri(包含与扬声器一样多的元素)。这些向量每帧被计算一次。注意:如果对象位置对应于扬声器位置,则该向量包含针对该扬声器的值1;所有其他值为0。如果对象位于两个(或三个)扬声器之间,则非零向量元素的对应数量为两个(或三个)。
[0173]
实际合成步骤(在该实施例中,协方差合成[vilkamo2013])包括以下子步骤(参见图5的可视化):
[0174]
ο对于每个参数带,描述分组到该参数带中的时间/频率区内的输入对象中的主要对象子集的对象索引用于提取进一步处理所需的向量子集dri。由于仅考虑例如2个相关对象,因此需要与这2个相关对象相关联的2个向量dri。
[0175]
ο根据直接响应值dri,然后针对每个相关对象计算尺寸为输出通道*输出通道的协方差矩阵ci:
[0176]ci
=dri*dr
it
[0177]
ο对于每个时间/频率区(在参数带内),确定音频信号功率p(k,n)。在两个传输通道的情况下,将第一通道的信号功率与第二通道的信号功率相加。将这些功率比值中的每一个与该信号功率相乘,从而针对每个相关/主要对象i产生一个直接功率值:
[0178]
dpi(k,n)=pri(k,n)*p(k,n)
[0179]
ο对于每个频带k,大小为输出通道*输出通道的最终目标协方差矩阵cy是通过对(子)帧内的所有时隙n进行求和以及对所有相关对象进行求和来得到的:
[0180][0181]
图5示出了在图4的块706中执行的协方差合成步骤的详细概览。具体地,图5实施例包括信号功率计算块721、直接功率计算块722、协方差矩阵计算块73、目标协方差矩阵计算块724、输入协方差矩阵计算块726、混合矩阵计算块725和渲染块727,该渲染块727对于图5附加地包括图4的滤波器组块708,使得块727的输出信号优选地对应于时域输出信号。然而,当块708不被包括在图5的渲染块中时,则结果是对应音频通道的频谱域表示。
[0182]
(以下步骤是最先进的[vilkamo2013]的一部分,并且是为了清楚起见而添加。)
[0183]
ο对于每个(子)帧和每个频带,根据解码音频信号来计算大小为传输通道*传输通道的输入协方差矩阵cy=xx
t
。可选地,可以仅使用主对角线的条目,在这种情况下,其他非零条目被设置为零。
[0184]
ο定义了大小为输出通道*传输通道的原型矩阵,该原型矩阵描述了传输通道到输
出通道的映射(作为输出配置的一部分提供),其数量由目标输出格式(例如,目标扬声器布局)给出。该原型矩阵可以是静态的,也可以逐帧变化。示例:如果仅发送了单个传输通道,则该传输通道被映射到每个输出通道。如果发送了两个传输通道,则左(第一)通道被映射到位于( 0
°
, 180
°
)内位置处的所有输出通道,即“左”通道。右(第二)通道相应地映射到位于(-0
°
,-180
°
)内位置处的所有输出通道,即“右”通道。(注释:0
°
描述听者前方的位置,正角描述听者左侧的位置,以及负角描述听者右侧的位置。如果采用了不同约定,则需要相应地调整角度的符号。)
[0185]
ο使用输入协方差矩阵c
x
、目标协方差矩阵cy和原型矩阵,针对每个(子)帧和每个频带计算混合矩阵[vilkamo2013],导致每个(子)帧例如60个混合矩阵。
[0186]
ο混合矩阵在(子)帧之间进行(例如,线性)内插,对应于时间平滑。
[0187]
ο最后,通过将最后混合矩阵m集乘以尺寸输出通道*传输通道中的每一个,输出通道y被逐频带地合成到解码传输通道x的时间/频率表示的对应频带:
[0188]
y=mx
[0189]
注意,我们没有使用如[vilkamo2013]中所描述的残差信号r。
[0190]
·
使用滤波器组将输出信号y转换回时域表示y(t)。
[0191]
经优化的协方差合成
[0192]
由于针对本实施例如何计算输入协方差矩阵cy和目标协方差矩阵cy,因此可以实现使用来自[vilkamo2013]的协方差合成对最佳混合矩阵计算的某些优化,从而导致显著降低了混合矩阵计算的计算复杂度。请注意,在本节中,hadamard运算符表示对矩阵的逐元素运算,即不是遵循例如矩阵乘法的规则,而是逐个元素地进行相应的运算。该运算符意味着:不对整个矩阵进行对应的运算,而是分别对每个元素进行运算。矩阵a和b的乘法将例如不对应于矩阵乘法ab=c,而是对应于逐元素运算a_ij*b_ij=c_ij。
[0193]
svd(.)表示奇异值分解。来自[vilkamo2013]的被呈现为matlab函数(列表1)的算法如下(现有技术):
[0194]
输入:大小为m
×
m的矩阵c
x
,包含输入信号的协方差
[0195]
输入:大小为n
×
n的矩阵cy,包含输出信号的目标协方差
[0196]
输入:大小为n
×
m的矩阵q,原型矩阵
[0197]
输入:标量α,针对s
x
的正则化因子([vilkamo2013]建议α=0.2)
[0198]
输入:标量β,针对的正则化因子([vilkamo2013]建议β=0.001)
[0199]
输入:布尔值a,表示是否应执行能量补偿而不是计算残差协方差cr[0200]
输出:大小为n
×
m的矩阵m,最佳混合矩阵
[0201]
输出:大小为n
×
n的矩阵cr,包含残差协方差
[0202]
[0203][0204]
如前一节所述,仅可选地使用c
x
的主对角线元素,并且所有其他条目都被设置为零。在这种情况下,c
x
是对角矩阵,并且满足[vilkamo2013]的等式(3)的有效分解是
[0205][0206]
并且不再需要来自现有技术算法的行3的svd。
[0207]
考虑用于从直接响应dri和前一节中的直接功率(或直接能量)生成目标协方差的公式
[0208]ci
=dri*dr
it
[0209]
dpi(k,n)=pri(k,n)*p(k,n)
[0210][0211]
最后一个公式可以被重新布置并写成
[0212][0213]
如果我们现在定义
[0214][0215]
从而获得
[0216][0217]
可以容易看出,如果我们布置k个最主要对象的直接响应矩阵r=[dr1…
drk]中的直接响应,并创建直接功率的对角矩阵作为e,其中e
i,i
=ei,cy也可以表示为
[0218]cy
=rerh[0219]
并且满足[vilkamo2013]的等式(3)的cy的有效分解由以下公式给出:
[0220]
[0221]
因此,不再需要来自现有技术算法的行1的svd。
[0222]
这导致本实施例内用于协方差合成的优化算法,该优化算法还考虑到我们始终使用能量补偿选项并因此不需要残差目标协方差c
x
:
[0223]
输入:大小为m
×
m的对角矩阵c
x
,包含具有m个通道的输入信号的协方差
[0224]
输入:大小为n
×
k的矩阵r,包含对k个主要对象的直接响应
[0225]
输入:对角矩阵e,包含主要对象的目标功率
[0226]
输入:大小为n
×
m的矩阵q,原型矩阵
[0227]
输入:标量α,s
x
(的正则化因子[vilkamo2013]建议α=0.2)
[0228]
输入:标量β,(的正则化因子[vilkamo2013]建议β=0.001)
[0229]
输出:大小为n
×
m的矩阵m,最佳混合矩阵
[0230]
[0231][0232]
仔细比较现有算法和所提出的算法表明:前者需要大小分别为m
×
m、n
×
n和m
×
n的矩阵的三个svd,其中,m是下混通道的数量,并且n是对象所渲染到的输出通道的数量。
[0233]
所提出的算法仅需要大小为m
×
k的矩阵的一个svd,其中,k是主要对象的数量。此外,由于k通常比n小得多,因此该矩阵小于来自现有技术算法的对应矩阵。
[0234]
对于m
×
n矩阵[golub2013],标准svd实现的复杂度大致为o(c1m2n c2n3),其中,c1和c2是取决于所使用算法的常数。因此,与现有技术算法相比,所提出算法的计算复杂度显著降低。
[0235]
随后,关于图7a、图7b讨论了与第一方面的编码器侧相关的优选实施例。此外,关于图9a至图9d讨论了第二方面的编码器侧实现的优选实现。
[0236]
图7a示出了图1a的对象参数计算器100的优选实现。在块120中,将音频对象转换为频谱表示。这是由图2或图3的滤波器组102实现的。然后,在块122中,选择信息的计算例
如如图2或图3的块104所示。为此,可以使用幅度相关测量值,例如幅度本身、功率、能量或通过将幅度提高到不同于1的功率而获得的任何其他幅度相关测量值。块122的结果是对应时间/频率区间中的每个对象的选择信息集。然后,在块124中,导出每个时间/频率区间的对象id。在第一方面中,导出每个时间/频率区间的两个或更多个对象id。根据第二方面,每个时间/频率区间的对象id的数量甚至可以仅为单个对象id,使得在块124中识别由块122提供的信息中最重要或最强或最相关的对象。块124输出关于参数数据的信息,并且包括最相关的一个或多个对象的单个或多个索引。
[0237]
在每个时间/频率区间具有两个或更多个相关对象的情况下,块126的功能对于计算表征时间/频率区间中的对象的幅度相关测量值是有用的。该幅度相关测量值可以与已经在块122中针对选择信息计算的幅度相关测量值相同,或者优选地,组合值是使用由块102已经计算的信息来计算的,如块122和块126之间的虚线所示,然后幅度相关测量值或一个或多个组合值在块126中被计算并转发给量化器和编码器块212,以便在辅助信息中具有编码幅度相关值或编码组合值,作为附加参数化辅助信息。在图2或图3的实施例中,这些值是与“编码对象索引”一起被包括在比特流中的“编码功率比”。在每个频率区间仅具有单个对象id的情况下,功率比计算和量化编码不是必需的,并且时间频率区间中的最相关对象的索引足以执行解码器侧渲染。
[0238]
图7b示出了图7b的对选择信息102的计算的优选实现。如块123所示,针对每个对象和每个时间/频率区间计算信号功率作为选择信息。然后,在示出图7a的块124的优选实现的块125中,提取并输出具有最高功率的单个或优选地两个或更多个对象的对象id。此外,在两个或更多个相关对象的情况下,功率比的计算如作为块126的优选实现的块127所示,其中,功率比是针对提取对象id计算的,该提取对象id与具有由块125找到的对应对象id的所有提取对象的功率相关。该过程是有利的,因为仅必须发送数量比时间/频率区间的对象数量少1的组合值,因为在该实施例中存在解码器已知的规则,该规则规定所有对象的功率比必须总和为1。优选地,图7a的块120、122、124、126和/或图7b的123、125、127的功能由图1a的对象参数计算器100来实现,并且图7a的块212的功能由图1a的输出接口200来实现。
[0239]
随后,关于若干个实施例更详细地说明了图1b所示的根据第二方面的用于编码的装置。在步骤110a中,方向信息或者从输入信号中提取,例如如图12a所示,或者通过读取或解析包括在元数据部分或元数据文件中的元数据信息来提取。在步骤110b中,对每帧和音频对象的方向信息进行量化,并且将每帧每对象的量化索引转发给编码器或输出接口,例如图1b的输出接口200。在步骤110c中,对方向量化索引进行去量化以便具有在某些实现中也可以由块110b直接输出的去量化值。然后,基于去量化方向索引,块422基于某个虚拟麦克风设置来计算每个传输通道和每个对象的权重。该虚拟麦克风设置可以包括布置在相同位置处并具有不同取向的两个虚拟麦克风信号,或者可以是如下设置:其中,存在相对于参考位置或取向(例如,虚拟听者位置或取向)的两个不同位置。具有两个虚拟麦克风信号的设置将导致每个对象的两个传输通道的权重。
[0240]
在生成三个传输通道的情况下,虚拟麦克风设置可以被认为包括来自在相同位置处且具有不同取向、或在相对于参考位置或取向的三个不同位置处布置的麦克风的三个虚拟麦克风信号,其中,该参考位置或取向可以是虚拟听者位置或取向。
[0241]
备选地,可以基于虚拟麦克风设置来生成四个传输通道,该虚拟麦克风设置从布置在相同位置处且具有不同取向的麦克风生成四个虚拟麦克风信号,或者从布置在相对于参考位置或参考取向的四个不同位置处的麦克风生成四个虚拟麦克风信号,其中参考位置或取向可以是虚拟听者位置或虚拟听者取向。
[0242]
此外,为了计算每个对象和每个传输通道(以两个通道为例)的权重w
l
和wr,虚拟麦克风信号是从虚拟一阶麦克风或虚拟心形麦克风或虚拟8字形麦克风或偶极子麦克风或双向麦克风导出的信号,或者是从虚拟定向麦克风或从虚拟亚心形麦克风或从虚拟单向麦克风或从虚拟超心形麦克风或从虚拟全向麦克风导出的信号。
[0243]
在该上下文中,应当注意,为了计算权重,不需要实际麦克风的任何放置。相反,用于计算权重的规则取决于虚拟麦克风设置(即,虚拟麦克风的放置和虚拟麦克风的特性)而变化。
[0244]
在图9a的块404中,将权重应用于对象,使得对于每个对象,在权重不同于0的情况下获得对象对特定传输通道的贡献。因此,块404接收对象信号作为输入。然后,在块406中,对每个传输通道的贡献求和,使得例如对象对第一传输通道的贡献被加在一起并且对象对第二传输通道的贡献被加在一起,等等。如块406所示,然后,块406的输出在例如时域中是传输通道。
[0245]
优选地,输入到块404中的对象信号是具有全带信息的时域对象信号,并且块404中的应用和块406中的求和是在时域中执行的。然而,在其他实施例中,这些步骤也可以在谱域中执行。
[0246]
图9b示出了实现静态下混的另一实施例。为此,在块130中提取第一帧的方向信息,并且取决于第一帧来计算权重,如块403a所示。然后,对于块408中所指示的其他帧,权重保持原样以实现静态下混。
[0247]
图9c示出了计算动态下混的另一种实现。为此,块132提取每个帧的方向信息,并且针对每个帧更新权重,如块403b所示。然后,在块405中,将经更新的权重应用于帧,以实现从帧到帧变化的动态下混。图9b和图9c的那些极端情况之间的其他实现也是有用的,其中,例如,仅针对每第二、三或每第n帧更新权重,和/或执行随时间的权重平滑,使得出于根据方向信息进行下混的目的,天线特性不会时不时地改变太多。图9d示出了由图1b的对象方向信息提供器110控制的下混器400的另一实现。在块410中,下混器被配置为分析帧中所有对象的方向信息,并且在块112中,出于计算立体声示例的权重w
l
和wr的目的,麦克风被放置为与分析结果一致,其中麦克风的放置是指麦克风位置和/或麦克风方向。在块414中,类似于关于图9b的块408所讨论的静态下混,将麦克风留给其他帧,或者根据关于图9c的块405所讨论的内容来更新麦克风,以便获得图9d的块414的功能。关于块412的功能,麦克风可以被放置为使得获得良好的分离,从而使得第一虚拟麦克风“看”向第一组对象并且第二虚拟麦克风“看”向第二组对象,第二组对象与第一组对象不同,并且优选地,不同之处在于,一个组中的任何对象尽可能地不被包括在另一组中。备选地,块410的分析可以通过其他参数来增强,并且放置也可以通过其他参数来控制。
[0248]
随后,根据第一方面或第二方面并关于例如图6a和图6b所讨论的解码器的优选实现由下图10a、图10b、图10c、图10d和图11给出。
[0249]
在块613中,输入接口600被配置为获取与对象id相关联的单独对象方向信息。该
过程对应于图4或图5的块612的功能,并且导致如关于图8b并且特别是8c所示出和讨论的“帧的码本”。
[0250]
此外,在块609中,获取每个时间/频率区间的一个或多个对象id,而不管这些数据对于低分辨率参数带或高分辨率频率区是否可用。对应于图4中的块608的过程的块609的结果是在时间/频率区间中的一个或多个相关对象的特定id。然后,在块611中,从“帧的码本”(即,从图8c所示的示例性表)中获取每个时间/频率区间的特定一个或多个id的特定对象方向信息。然后,在块704中,针对每个时间/频率区间,计算由输出格式控制的各个输出通道的一个或多个相关对象的增益值。然后,在块730或706、708中,计算输出通道。对输出通道的计算的功能可以如图10b所示在对一个或多个传输通道的贡献的显式计算中进行,或者可以如图10d或图11所示通过对传输通道贡献的间接计算和使用来进行。图10b示出了在与图4的功能相对应的块610中获取功率值或功率比的功能。然后,将这些功率值应用于每个相关对象的各个传输通道,如块733和735所示。此外,除了由块704确定的增益值之外,这些功率值还被应用于各个传输通道,使得块733、735产生传输通道(例如,传输通道ch1、ch2
……
)的对象特定贡献。然后,在块737中,针对每个时间/频率区间的每个输出通道将这些显式计算的通道传输贡献加在一起。
[0251]
然后,取决于实现,可以提供扩散信号计算器741,该扩散信号计算器741在对应时间/频率区间中生成针对每个输出通道ch1、ch2
……
的扩散信号,并且扩散信号和块737的贡献结果的组合被组合,使得获得每个时间/频率区间中的完整通道贡献。当协方差合成附加地依赖于扩散信号时,该信号对应于图4的滤波器组708的输入。然而,当协方差合成706不依赖于扩散信号而仅依赖于没有任何解相关器的处理时,则至少每个时间/频率区间的输出信号的能量对应于在图10b的块739的输出处的通道贡献的能量。此外,在不使用扩散信号计算器741的情况下,则块739的结果对应于块706的结果,即具有每个时间/频率区间的可以针对每个输出通道ch1、ch2单独转换的完整通道贡献,以便最终获得具有时域输出通道的输出音频文件,该输出音频文件可以被存储或转发给扬声器或任何类型的渲染设备。
[0252]
图10c示出了图10b或图4的块610的功能的优选实现。在步骤610a中,针对某个时间/频率区间获取组合(功率)值或若干个值。在块610b中,基于所有组合值必须总和为1的计算规则,计算时间/频率区间中的其他相关对象的对应其他值。
[0253]
然后,结果将优选地是低分辨率表示,其中,针对每个分组时隙索引和每个参数带索引,低分辨率表示具有两个功率比。这些功率比表示低时间/频率分辨率。在块610c中,时间/频率分辨率可以扩展到高时间/频率分辨率,使得其具有高分辨率时隙索引n和高分辨率频带索引k的时间/频率区的功率值。该扩展可以包括对分组时隙内的对应时隙和参数带内的对应频带直接使用一个且相同的低分辨率索引。
[0254]
图10d示出了用于计算图4的块706中的协方差合成信息的功能的优选实现,由用于将两个或更多个输入传输通道混合成两个或更多个输出信号的混合矩阵725来表示。因此,当具有例如两个传输通道和六个输出通道时,每个单独的时间/频率区间的混合矩阵的大小将是六行和两列。在与图5中的块723的功能相对应的块723中,接收每个时间/频率区间中每个对象的增益值或直接响应值,并且计算协方差矩阵。在块722中,接收功率值或功率比,并计算时间/频率区间中每个对象的直接功率值,并且图10d中的块722对应于图5的
块722。
[0255]
将块721和722两者的结果都输入到目标协方差矩阵计算器724中。附加地或备选地,目标协方差矩阵cy的显式计算不是必需的。相反,将包括在目标协方差矩阵中的相关信息(即,针对两个或更多个相关对象,在矩阵r中指示的直接响应值信息和在矩阵e中指示的直接功率值)输入到用于计算每个时间/频率区间的混合矩阵的块725a中。此外,混合矩阵725a接收关于从与图5的块726相对应的块726中所示的两个或更多个传输通道导出的输入协方差矩阵c
x
以及原型矩阵q的信息。可以对每个时间/频率区间和帧的混合矩阵进行时间平滑,如块725b所示,并且在与图5的渲染块的至少一部分相对应的块727中,将混合矩阵以非平滑或平滑形式应用于对应时间/频率区间中的传输通道,以获得时间/频率区间中的完整通道贡献,基本类似于之前关于图10b在块739的输出处所讨论的对应完整贡献。因此,图10b示出了传输通道贡献的显式计算的实现,而图10d示出了经由目标协方差矩阵cy或经由块723和722的直接引入到混合矩阵计算块725a中的相关信息r和e来隐式地计算每个时间/频率区间和每个时间频率区间中的每个相关对象的传输通道贡献的过程。
[0256]
随后,关于图11示出了用于协方差合成的优选优化算法。需要概述的是,图11所示的所有步骤都是在图4的协方差合成706内或在图5的混合矩阵计算块725或图10d中的725a内计算的。在步骤751中,计算第一分解结果ky。由于如下事实:如图10d所示,直接使用包括在矩阵r中的增益值信息和来自两个或更多个相关对象的信息,具体地包括在矩阵er中的直接功率信息,而无需显式计算协方差矩阵,因此可以容易地计算该分解结果。因此,可以直接计算块751中的第一分解结果并且无需太多工作量,因为不再需要特定奇异值分解。
[0257]
在步骤752中,将第二分解结果计算为k
x
。由于输入协方差矩阵被视为忽略了非对角线元素的对角矩阵,因此也可以在没有显式奇异值分解的情况下计算该分解结果。
[0258]
然后,在步骤753中,计算基于第一正则化参数α的第一正则化结果,并且在步骤754中,基于第二正则化参数β来计算第二正则化结果。由于k
x
在优选实现中是对角矩阵,因此相对于现有技术简化了对第一正则化结果753的计算,因为s
x
的计算仅是参数变化,而不是如现有技术中的分解。
[0259]
此外,对于块754中的对第二正则化结果的计算,第一步骤附加地仅是参数重命名而不是现有技术中与矩阵u
xhs
的相乘。
[0260]
此外,在步骤755中,计算归一化矩阵gy,并且基于步骤755,在步骤756中基于k
x
和原型矩阵q以及由块751获得的ky的信息来计算酉矩阵p。由于这里不需要任何矩阵λ,因此相对于可用的现有技术简化了对酉矩阵p的计算。
[0261]
然后,在步骤757中,计算没有能量补偿的混合矩阵,即mo
pt
,并且为此,使用酉矩阵p、块754的结果和块751的结果。然后,在块758中,使用补偿矩阵g来执行能量补偿。执行能量补偿使得不需要从解相关器导出的任何残差信号。然而,代替执行能量补偿,在该实现中将添加具有足够大的能量以填充由混合矩阵mo
pt
留下的能隙而没有能量信息的残差信号。然而,出于本发明的目的,不依赖解相关信号以避免由解相关器引入的任何伪音。但是,如步骤758所示的能量补偿是优选的。
[0262]
因此,用于协方差合成的优化算法在步骤751、752、753、754中以及在步骤756内针对酉矩阵p的计算提供了优点。需要强调的是,优化算法甚至提供了优于现有技术的优点,其中仅步骤755、752、753、754、756之一或仅这些步骤的子组被实现,如图所示,但对应的其
他步骤与现有技术一样被实现。原因是这些改进并不彼此依赖,而是可以彼此独立应用。然而,就实现的复杂度而言,实现的改进越多,该过程将越好。因此,图11实施例的完整实现是优选的,因为它提供了最大程度的复杂度降低,但即使根据优化算法仅实现步骤751、752、753、754、756之一并且其他步骤如现有技术一样实现,也获得了复杂度降低而没有任何质量劣化。
[0263]
本发明的实施例也可以被视为如下过程:通过混合三个高斯(gaussian)噪声源(每个通道一个高斯噪声源)和用于创建相关背景噪声的第三公共噪声源来为立体声信号生成舒适噪声,或者附加地或单独地,利用与sid帧一起发送的相干值控制对噪声源的混合。
[0264]
这里要提到的是,之前和之后讨论的所有备选方案或方面以及由所附权利要求中的权利要求限定的所有方面可以单独地使用,即,没有与所设想的备选方案、目标或独立权利要求不同的任何其他备选方案或目标。然而,在其他实施例中,两个或更多个备选方案或方面或独立权利要求可以彼此组合,并且在其他实施例中,所有方面或备选方案和所有独立权利要求可以彼此组合。
[0265]
本发明的编码信号可以存储在数字存储介质或非暂时性存储介质上,或者可以在诸如无线传输介质或诸如互联网的有线传输介质的传输介质上传输。
[0266]
尽管已经在装置的上下文中描述了一些方面,但将清楚的是,这些方面还表示对应方法的描述,其中,块或装置对应于方法步骤或方法步骤的特征。类似地,在方法步骤上下文中描述的方面也指示对相应块或项或者相应装置的特征的描述。
[0267]
取决于某些实现要求,可以在硬件中或在软件中实现本发明的实施例。实现可以使用其上存储有电子可读控制信号的数字存储介质(例如,软盘、dvd、cd、rom、prom、eprom、eeprom或闪存)来执行,与可编程计算机系统协作(或能够协作),使得执行相应方法。
[0268]
根据本发明的一些实施例包括具有电子可读控制信号的数据载体,能够与可编程计算机系统协作,使得执行本文所述的方法之一。
[0269]
通常,本发明的实施例可以实现为具有程序代码的计算机程序产品,程序代码可操作以在计算机程序产品在计算机上运行时执行方法之一。该程序代码可以例如存储在机器可读载体上。
[0270]
其他实施例包括存储在机器可读载体或非暂时性存储介质上的用于执行本文描述的方法之一的计算机程序。
[0271]
换言之,本发明的方法的实施例因此是具有程序代码的计算机程序,该程序代码用于在计算机程序在计算机上运行时执行本文所述的方法之一。
[0272]
因此,本发明的方法的其他实施例是其上记录有计算机程序的数据载体或数字存储介质或计算机可读介质,该计算机程序用于执行本文所述的方法之一。
[0273]
因此,本发明的方法的其他实施例是表示计算机程序的数据流或信号序列,所述计算机程序用于执行本文描述的方法之一。数据流或信号序列可以例如被配置为经由数据通信连接(例如,经由互联网)传送。
[0274]
另一实施例包括处理装置,例如,计算机或可编程逻辑器件,所述处理装置被配置为或适于执行本文所述的方法之一。
[0275]
另一实施例包括其上安装有计算机程序的计算机,该计算机程序用于执行本文所
述的方法之一。
[0276]
在一些实施例中,可编程逻辑器件(例如,现场可编程门阵列)可以用于执行本文所述的方法的功能中的一些或全部。在一些实施例中,现场可编程门阵列可以与微处理器协作以执行本文所述的方法之一。通常,方法优选地由任意硬件装置来执行。
[0277]
上述实施例对于本发明的原理仅是说明性的。应当理解,本文描述的布置和细节的修改和变形对于本领域其他技术人员将是显而易见的。因此,旨在仅由所附专利权利要求的范围来限制而不是由借助对本文的实施例的描述和解释所给出的具体细节来限制。
[0278]
方面(彼此独立使用、或与所有其他方面或仅其他方面的子组一起使用)
[0279]
装置、方法或计算机程序包括下面所提到的特征中的一个或多个:
[0280]
关于新颖方面的发明示例:
[0281]
·
多波思想与对象编码相结合(每个t/f区使用多于一个方向提示)
[0282]
·
对象编码方法,其尽可能地接近dirac范式,以允许ivas中的任何种类的输入类型(目前未涵盖的对象内容)
[0283]
关于参数化(编码器)的发明示例:
[0284]
·
对于每个t/f区:该t/f区中的n个最相关对象的选择信息加上这n个最相关对象贡献之间的功率比
[0285]
·
对于每个帧,对于每个对象:一个方向
[0286]
关于渲染(解码器)的发明示例:
[0287]
·
从所发送的对象索引和方向信息以及目标输出布局中获取每个相关对象的直接响应值
[0288]
·
从直接响应中获取协方差矩阵
[0289]
·
根据每个相关对象的下混信号功率和发送功率比计算直接功率
[0290]
·
从直接功率和协方差矩阵中获取最终目标协方差矩阵
[0291]
·
仅使用输入协方差矩阵的对角线元素
[0292]
优化的协方差合成
[0293]
关于与saoc差异的一些旁注:
[0294]
·
考虑n个主要对象而不是所有对象
[0295]
→
功率比因此与old相关,但计算方式不同
[0296]
·
saoc在编码器处不使用方向-》方向信息仅在解码器(渲染矩阵)处被引入
[0297]
→
saoc-3d解码器接收用于渲染矩阵的对象元数据
[0298]
·
saoc采用下混矩阵并发送下混增益
[0299]
·
本发明实施例不考虑扩散度
[0300]
随后,总结了本发明的其他示例。
[0301]
1.一种用于对多个音频对象进行编码的装置,包括:
[0302]
对象参数计算器(100),被配置为:针对与时间帧相关的多个频率区间中的一个或多个频率区间,计算至少两个相关音频对象的参数数据,其中,所述至少两个相关音频对象的数量低于所述多个音频对象的总数,以及
[0303]
输出接口(200),被配置为输出编码音频信号,所述编码音频信号包括关于所述一个或多个频率区间的所述至少两个相关音频对象的参数数据的信息。
[0304]
2.根据示例1所述的装置,其中,所述对象参数计算器(100)被配置为:
[0305]
将所述多个音频对象中的每个音频对象转换(120)为具有多个频率区间的频谱表示,
[0306]
计算(122)所述一个或多个频率区间的每个音频对象的选择信息,以及
[0307]
基于所述选择信息,导出(124)对象标识作为指示所述至少两个相关音频对象的参数数据,以及
[0308]
其中,所述输出接口(200)被配置为将关于所述对象标识的信息引入到所述编码音频信号中。
[0309]
3.根据示例1或2所述的装置,其中,所述对象参数计算器(100)被配置为:对所述一个或多个频率区间中的相关音频对象的一个或多个幅度相关测量值或从幅度相关测量值导出的一个或多个组合值进行量化和编码(212),作为所述参数数据,以及
[0310]
其中,所述输出接口(200)被配置为将经量化的一个或多个幅度相关测量值或经量化的一个或多个组合值引入到所述编码音频信号中。
[0311]
4.根据示例2或3所述的装置,
[0312]
其中,所述选择信息是所述音频对象的诸如幅度值、功率值或响度值、或提高到不同于1的功率的幅度之类的幅度相关测量值,以及
[0313]
其中,所述对象参数计算器(100)被配置为计算(127)组合值,例如相关音频对象的幅度相关测量值与相关音频对象的两个或更多个幅度相关测量值之和的比率,以及
[0314]
其中,所述输出接口(200)被配置为:将关于所述组合值的信息引入到所述编码音频信号中,其中,所述编码音频信号中关于所述组合值的信息项的数量至少等于1且小于所述一个或多个频率区间的相关音频对象的数量。
[0315]
5.根据示例2至4之一所述的装置,
[0316]
其中,所述对象参数计算器(100)被配置为基于所述一个或多个频率区间中的所述多个音频对象的选择信息的顺序来选择所述对象标识。
[0317]
6.根据示例2至5之一所述的装置,其中,所述对象参数计算器(100)被配置为:
[0318]
计算(122)信号功率作为所述选择信息,
[0319]
针对每个频率区间分别导出(124)对应一个或多个频率区间中的具有最大信号功率值的两个或更多个音频对象的对象标识,
[0320]
计算(126)具有所述最大信号功率值的两个或更多个音频对象的信号功率之和与具有所导出的对象标识的音频对象中的每个音频对象的信号功率之间的功率比作为所述参数数据,以及
[0321]
对所述功率比进行量化和编码(212),以及
[0322]
其中,所述输出接口(200)被配置为将经量化和编码的功率比引入到所述编码音频信号中。
[0323]
7.根据示例1至6之一所述的装置,其中,所述输出接口(200)被配置为将以下内容引入到所述编码音频信号中:
[0324]
一个或多个编码传输通道,
[0325]
作为所述参数数据的、所述时间帧中的多个频率区间中的一个或多个频率区间中的每个频率区间的相关音频对象的两个或更多个编码对象标识,以及一个或多个编码组合
值或编码幅度相关测量值,以及
[0326]
所述时间帧中的每个音频对象的经量化和编码的方向数据,所述方向数据对于所述一个或多个频率区间中的所有频率区间是恒定的。
[0327]
8.根据示例1至7之一所述的装置,其中,所述对象参数计算器(100)被配置为:计算所述一个或多个频率区间中的至少最主要对象和第二最主要对象的参数数据,或
[0328]
其中,所述多个音频对象中的音频对象的数量是三个或更多个,所述多个音频对象包括第一音频对象、第二音频对象和第三音频对象,以及
[0329]
其中,所述对象参数计算器(100)被配置为:针对所述一个或多个频率区间中的第一频率区间,仅计算诸如所述第一音频对象和所述第二音频对象的第一组音频对象作为所述相关音频对象;以及针对所述一个或多个频率区间中的第二频率区间,仅计算诸如所述第二音频对象和所述第三音频对象或所述第一音频对象和所述第三音频对象的第二组音频对象作为所述相关音频对象,其中,所述第一组音频对象至少在一个组成员方面不同于所述第二组音频对象。
[0330]
9.根据示例1至8之一所述的装置,其中,所述对象参数计算器(100)被配置为:
[0331]
计算具有第一时间或频率分辨率的原始参数化数据,并将所述原始参数化数据组合为具有比所述第一时间或频率分辨率低的第二时间或频率分辨率的组合参数化数据,并且相对于具有所述第二时间或频率分辨率的组合参数化数据计算所述至少两个相关音频对象的参数数据,或
[0332]
确定具有与所述多个音频对象的时间或频率分解中使用的第一时间或频率分辨率不同的第二时间或频率分辨率的参数带,并且针对具有所述第二时间或频率分辨率的参数带计算所述至少两个相关音频对象的参数数据。
[0333]
10.根据前述示例之一所述的装置,其中,所述多个音频对象包括指示关于所述多个音频对象的方向信息(810)的相关元数据,以及
[0334]
其中,所述装置还包括:
[0335]
下混器(400),用于对所述多个音频对象进行下混以获得一个或多个传输通道,其中,所述下混器(400)被配置为:响应于关于所述多个音频对象的方向信息而对所述多个音频对象进行下混;以及
[0336]
传输通道编码器(300),用于对一个或多个传输通道进行编码以获得一个或多个编码传输通道;以及
[0337]
其中,所述输出接口(200)被配置为:将所述一个或多个传输通道引入到所述编码音频信号中。
[0338]
11.根据示例10所述的装置,其中,所述下混器(400)被配置为:
[0339]
生成两个传输通道作为两个虚拟麦克风信号,所述两个虚拟麦克风信号布置在相同位置处并具有不同取向、或布置在相对于诸如虚拟听者位置或取向的参考位置或取向的两个不同位置处,或
[0340]
生成三个传输通道作为三个虚拟麦克风信号,所述三个虚拟麦克风信号布置在相同位置处并具有不同取向、或布置在相对于诸如虚拟听者位置或取向的参考位置或取向的三个不同位置处,或
[0341]
生成四个传输通道作为四个虚拟麦克风信号,所述四个虚拟麦克风信号布置在相
同位置处并具有不同取向、或布置在相对于诸如虚拟听者位置或取向之类的参考位置或取向的四个不同位置处,或
[0342]
其中,所述虚拟麦克风信号是虚拟一阶麦克风信号、或虚拟心形麦克风信号、或虚拟8字形或偶极或双向麦克风信号、或虚拟定向麦克风信号、或虚拟亚心形麦克风信号、或虚拟单向麦克风信号、或虚拟超心形麦克风信号、或虚拟全向麦克风信号。
[0343]
12.根据示例10或11所述的装置,其中,所述下混器(400)被配置为:
[0344]
针对所述多个音频对象中的每个音频对象,使用对应音频对象的方向信息来导出(402)针对每个传输通道的加权信息;
[0345]
使用针对特定传输通道的音频对象的加权信息对所述对应音频对象进行加权(404),以获得针对所述特定传输通道的对象贡献,以及
[0346]
组合(406)所述多个音频对象对所述特定传输通道的对象贡献,以获得所述特定传输通道。
[0347]
13.根据示例10至12之一所述的装置,
[0348]
其中,所述下混器(400)被配置为:计算所述一个或多个传输通道作为一个或多个虚拟麦克风信号,所述一个或多个虚拟麦克风信号布置在相同位置处并且具有不同取向、或布置在相对于诸如虚拟听者位置或取向之类的参考位置或取向的不同位置处,所述方向信息与所述参考位置或取向相关,
[0349]
其中,所述不同位置或取向在中心线上或所述中心线的左侧和中心线上或中心线的右侧,或者其中,所述不同位置或取向均匀或不均匀地分布到水平位置或取向,例如相对于所述中心线 90度或-90度,或相对于所述中心线-120度、0度和 120度,或者其中,所述不同位置或取向包括相对于虚拟听者所在的水平面向上或向下指向的至少一个位置或取向,其中,关于所述多个音频对象的方向信息与所述虚拟听者位置或参考位置或取向相关。
[0350]
14.根据示例10至13之一所述的装置,还包括:
[0351]
参数处理器(110),用于对指示关于所述多个音频对象的方向信息的元数据进行量化,以获得针对所述多个音频对象的量化方向项,
[0352]
其中,所述下混器(400)被配置为:响应于作为所述方向信息的量化方向项进行操作,以及
[0353]
其中,所述输出接口(200)被配置为:将关于所述量化方向项的信息引入到所述编码音频信号中。
[0354]
15.根据示例10至14之一所述的装置,
[0355]
其中,所述下混器(400)被配置为:对关于所述多个音频对象的方向信息执行(410)分析,并根据所述分析的结果放置(412)一个或多个虚拟麦克风以生成传输通道。
[0356]
16.根据示例10至15之一所述的装置,
[0357]
其中,所述下混器(400)被配置为:使用在多个时间帧上是静态的下混规则进行下混(408),或
[0358]
其中,所述方向信息在多个时间帧上是可变的,并且其中,所述下混器(400)被配置为:使用在所述多个时间帧上是可变的下混规则进行下混(405)。
[0359]
17.根据示例10至16之一所述的装置,所述下混器(400)被配置为:使用所述多个音频对象的样本的逐个样本加权和组合在时域中进行下混。
[0360]
18.一种用于对编码音频信号进行解码的解码器,所述编码音频信号包括:多个音频对象的一个或多个传输通道和方向信息,以及针对时间帧的一个或多个频率区间的至少两个相关音频对象的参数数据,其中,所述至少两个相关音频对象的数量低于所述多个音频对象的总数,所述解码器包括:
[0361]
输入接口(600),用于提供频谱表示形式的所述一个或多个传输通道,所述频谱表示在所述时间帧中具有多个频率区间;以及
[0362]
音频渲染器(700),用于使用所述方向信息将所述一个或多个传输通道渲染为多个音频通道,使得根据与所述至少两个相关音频对象中的第一相关音频对象相关联的第一方向信息以及根据与所述至少两个相关音频对象中的第二相关音频对象相关联的第二方向信息,考虑来自所述一个或多个传输通道的贡献,或
[0363]
其中,所述音频渲染器(700)被配置为:针对所述一个或多个频率区间中的每一频率区间,根据与所述至少两个相关音频对象中的第一相关音频对象相关联的第一方向信息以及根据与所述至少两个相关音频对象中的第二相关音频对象相关联的第二方向信息,计算来自所述一个或多个传输通道的贡献。
[0364]
19.根据示例18所述的解码器,
[0365]
其中,所述音频渲染器(700)被配置为:针对所述一个或多个频率区间,忽略与所述至少两个相关音频对象不同的音频对象的方向信息。
[0366]
20.根据示例18或19所述的解码器,
[0367]
其中,所述编码音频信号包括所述参数数据中的每个相关音频对象的幅度相关测量值(812)或与至少两个相关音频对象相关的组合值(812),以及
[0368]
其中,所述音频渲染器(700)被配置为:根据所述幅度相关测量值或所述组合值来确定(704)所述一个或多个传输通道的定量贡献。
[0369]
21.根据示例20所述的解码器,其中,编码信号包括所述参数数据中的所述组合值,以及
[0370]
其中,所述音频渲染器(700)被配置为:使用相关音频对象之一的组合值和该一个相关音频对象的方向信息来确定(704、733)所述一个或多个传输通道的贡献,以及
[0371]
其中,所述音频渲染器(700)被配置为:使用从所述一个或多个频率区间中的相关音频对象中的另一相关音频对象的组合值以及所述另一相关音频对象的方向信息导出的值,确定(704、735)所述一个或多个传输通道的贡献。
[0372]
22.根据示例18至21之一所述的解码器,其中,所述音频渲染器(700)被配置为:
[0373]
根据所述多个频率区间中的每个频率区间的相关音频对象以及与所述频率区间中的相关音频对象相关联的方向信息,计算(704)直接响应信息。
[0374]
23.根据示例22所述的解码器,
[0375]
其中,所述音频渲染器(700)被配置为:使用所述元数据中包括的诸如扩散度参数之类的扩散度信息或解相关规则来确定(741)针对所述多个频率区间中的每个频率区间的扩散信号,并且组合由所述直接响应信息确定的直接响应和所述扩散信号,以获得所述多个通道中的通道的谱域渲染信号,或
[0376]
使用所述直接响应信息(704)和关于所述多个音频通道的信息(702)来计算(706)合成信息,并且将协方差合成信息应用(727)于所述一个或多个传输通道,以获得所述多个
音频通道,或
[0377]
其中,所述直接响应信息(704)是每个相关音频对象的直接响应向量,并且其中,所述协方差合成信息是协方差合成矩阵,并且其中,所述音频渲染器(700)被配置为:在应用(727)所述协方差合成信息时针对每个频率区间执行矩阵运算。
[0378]
24.根据示例22或23所述的解码器,其中,所述音频渲染器(700)被配置为:
[0379]
在计算所述直接响应信息(704)时,导出每个相关音频对象的直接响应向量;以及针对每个相关音频对象,根据每个直接响应向量来计算协方差矩阵,
[0380]
在计算所述协方差合成信息时,从以下内容导出(724)目标协方差信息:来自所述相关音频对象中的每个相关音频对象的协方差矩阵,关于相应相关音频对象的功率信息,以及从所述一个或多个传输通道导出的功率信息。
[0381]
25.根据示例24所述的解码器,其中,所述音频渲染器(700)被配置为:
[0382]
在计算所述直接响应信息(704)时,导出每个相关音频对象的直接响应向量;以及针对每个相关音频对象,根据每个直接响应向量来计算(723)协方差矩阵,
[0383]
从所述传输通道导出(726)输入协方差信息,以及
[0384]
从所述目标协方差信息、所述输入协方差信息和关于所述多个通道的信息导出(725a,725b)混合信息,以及
[0385]
将所述混合信息应用(727)于所述时间帧中的每个频率区间的传输通道。
[0386]
26.根据示例25所述的解码器,其中,将针对所述时间帧中的每个频率区间应用所述混合信息的结果转换(708)到时域中以获得时域中的多个音频通道。
[0387]
27.根据示例22至26之一所述的解码器,其中,所述音频渲染器(700)被配置为:
[0388]
在分解(752)从所述传输通道导出的输入协方差矩阵时,仅使用所述输入协方差矩阵的主对角线元素,或
[0389]
使用直接响应矩阵以及所述对象或传输通道的功率矩阵来执行对目标协方差矩阵的分解(751),或
[0390]
通过取所述输入协方差矩阵的每个主对角线元素的根来执行(752)对所述输入协方差矩阵的分解,或
[0391]
计算(753)经分解的输入协方差矩阵的正则化逆矩阵,或
[0392]
在计算要用于能量补偿的最佳矩阵时执行(756)奇异值分解,而无需扩展单位矩阵。
[0393]
28.一种对多个音频对象和指示关于所述多个音频对象的方向信息的相关元数据进行编码的方法,包括:
[0394]
对所述多个音频对象进行下混以获得一个或多个传输通道;
[0395]
对所述一个或多个传输通道进行编码以获得一个或多个编码传输通道;以及
[0396]
输出包括所述一个或多个编码传输通道的编码音频信号,
[0397]
其中,所述下混包括响应于关于所述多个音频对象的方向信息而对所述多个音频对象进行下混。
[0398]
29.一种对编码音频信号进行解码的方法,所述编码音频信号包括:多个音频对象的一个或多个传输通道和方向信息,以及针对时间帧的一个或多个频率区间的至少两个相关音频对象的参数数据,其中,所述至少两个相关音频对象的数量低于所述多个音频对象
audio—the new standard for coding of immersive spatial audio“,ieee journal of selected topics in signal processing,vol.9,no.5,august 2015
[0414]
[mpegh_std]text of iso/mpeg23008
–
3/dis 3d audio,sapporo,iso/iec jtc1/sc29/wg11 n14747,jul.2014.
[0415]
[saoc_3d_pat]apparatus and method for enhanced spatal audio object coding,wo 2015/011024 a1
[0416]
[pulkki1997]v.pulkki,“virtual sound source positioning using vector base ampl itude panning,”j.audio eng.soc.,vol.45,no.6,pp.456
–
466,jun.1997.
[0417]
[delaunay]c.b.barber,d.p.dobkin,and h.huhdanpaa,“the quickhull algorithm for convex hulls,”in proc.acm trans.math.software(toms),new york,ny,usa,dec.1996,vol.22,pp.469
–
483.
[0418]
[hirvonen2009]t.hirvonen,j.ahonen,and v.pulkki,“perceptual compression methods for metadata in directional audio coding applied to audiovisual teleconference”,aes 126
th
convention 2009,may 7
–
10,munich,germany.
[0419]
[borβ2014]c.borβ,“a polygon-based panning method for 3d loudspeaker setups”,aes 137
th convention 2014,october 9
ꢀ‑
12,los angeles,usa.
[0420]
[wo2019068638]apparatus,method and computer program for encoding,decoding,scene processing and other procedures related to dirac based spatial audio coding,2018
[0421]
[wo2020249815]parameter encoding and decoding for multichannel audio using dirac,2019
[0422]
[bcc2001]c.faller,f.baumgarte:“efficient representation of spatial audio using perceptual parametrization”,proceedings of the 2001 ieee workshop on the applications of signal processing to audio and acoustics(cat.no.01th8575).
[0423]
[joc_aes]heiko purnhagen;toni hirvonen;lars villemoes;jonas samuelsson;janusz klejsa:“immersive audio delivery using joint object coding”,140
th aes convention,paper number:9587,paris,may 2016.
[0424]
[ac4_aes]k.j.m.wolters,j.riedmiller,a.biswas,p.ekstrand,a.p.hedelin,t.hirvonen,h.j.klejsa,j.koppens,k.krauss,h-m.lehtonen,k.linzmeier,h.muesch,h.mundt,s.norcross,j.popp,h.purnhagen,j.samuelsson,m.schug,l.r.thesing,l.villemoes,and m.vinton:“ac-4
–
the next generation audio codec”,140
th aes convention,paper number:9491,paris,may2016.
[0425]
[vilkamo2013]j.vilkamo,t.a.kuntz,“optimized covariance domain framework for time-frequency processing of spatial audio”,journal of the audio engineering society,2013.
[0426]
[golub2013]gene h.golub and charles f.van loan,“matrix computations”,
johns hopkins university press,4th edition,2013。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。