技术特征:
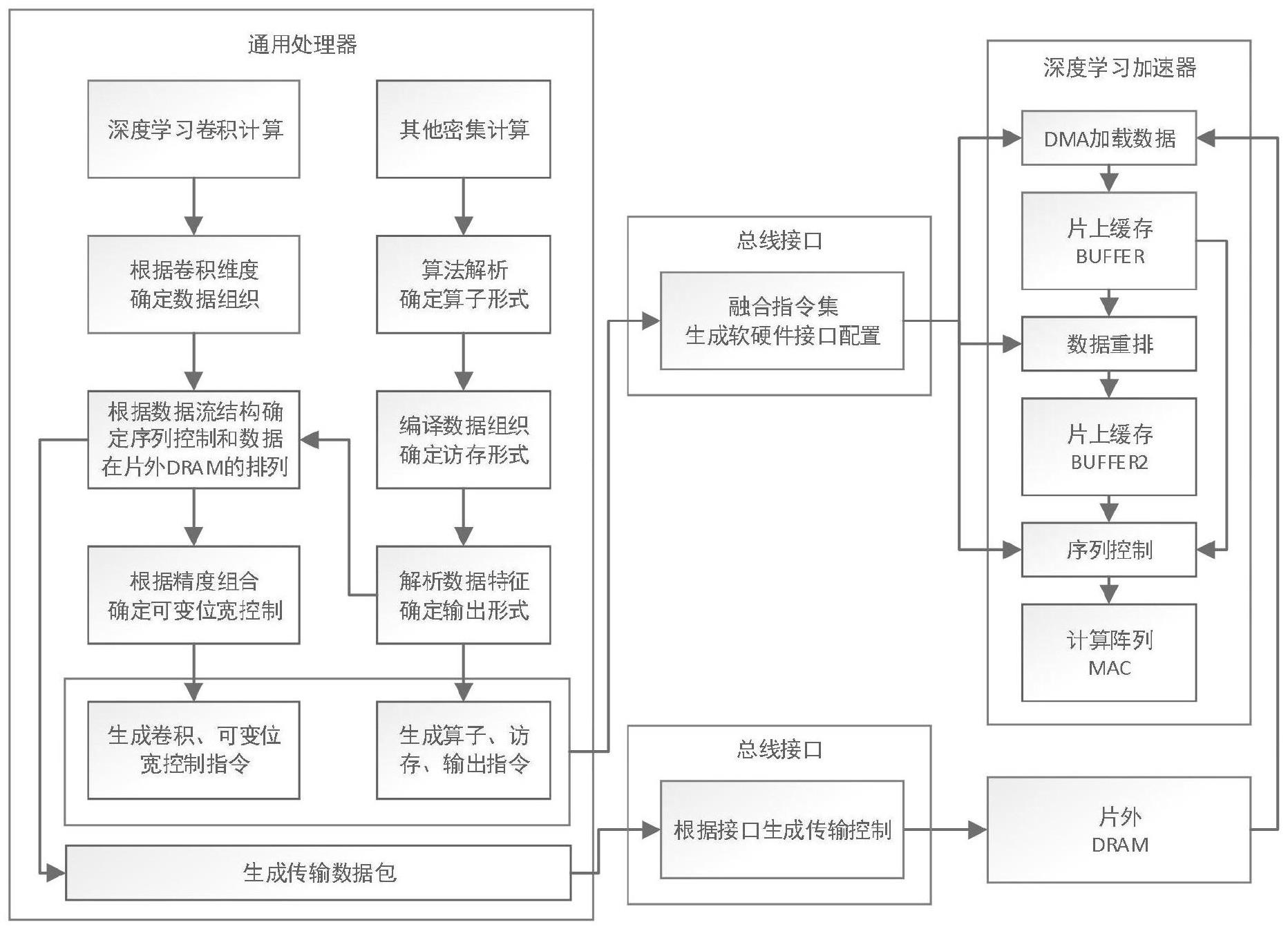
1.一种深度学习处理器的泛化架构设计方法,其特征在于:所述方法具体过程为:步骤1:系统分为软件部分和硬件部分;软件部分即通用处理器,通用处理器负责对硬件编程;硬件部分即深度学习加速器,深度学习加速器负责硬件计算;通用处理器包括深度学习卷积计算任务和密集型计算任务;通用处理器读取数据,解析数据在片外存储器的组织形式;当进行密集型计算任务时,进入步骤2;当进行深度学习卷积计算任务时,进入步骤3;步骤2:解析密集型计算任务,得到最优的算子计算形式,将步骤1数据在片外存储器的组织形式加载到片上缓存buffer,基于最优的算子计算形式将片上缓存buffer的数据重排,将重排后数据加载到片上缓存buffer2中;缓存buffer2中数据传输到mac阵列中,mac阵列输出结果传给片外存储器;步骤3:将步骤1数据在片外存储器的组织形式加载到片上缓存buffer,缓存buffer中数据传输到mac阵列中,mac阵列输出结果传给片外存储器。2.根据权利要求1所述的一种深度学习处理器的泛化架构设计方法,其特征在于:所述步骤2:解析密集型计算任务,得到最优的算子计算形式,将步骤1数据在片外存储器的组织形式加载到片上缓存buffer,基于最优的算子计算形式将片上缓存buffer的数据重排,将重排后数据加载到片上缓存buffer2中;缓存buffer2中数据传输到mac阵列中,mac阵列输出结果传给片外存储器;具体过程为:密集型计算任务的算子包括向量向量乘,矩阵向量乘,矩阵矩阵乘和向量向量扩充乘;向量向量乘a1×
b1完成向量和向量的乘积计算,向量a1或者b1的维数可编程控制,所述向量a1或者b1的维数指向量a1或者向量b1中数据的数量;矩阵向量乘完成矩阵和向量的乘积计算,矩阵的向量数可编程控制,向量的维数可编程控制,所述向量的维数指向量中数据的数量;矩阵矩阵乘完成矩阵和矩阵的乘积计算,矩阵的向量数以及矩阵中向量的维数可编程控制;向量向量扩充乘完成矩阵矩阵乘的计算结果的对角线相加,矩阵的向量数以及矩阵中向量的维数可编程控制;若一组向量向量乘a1×
b1,a2×
b2,
…
,a
n
×
b
n
中向量a1,a2,a
n
不相同且向量b1,b2,b
n
不相同,向量向量乘a1×
b1,a2×
b2,
…
,a
n
×
b
n
还是向量向量乘a1×
b1,a2×
b2,
…
,a
n
×
b
n
;若一组向量向量乘a1×
b1,a2×
b2,
…
,a
n
×
b
n
中向量a1,a2,a
n
相同或向量b1,b2,b
n
相同,则将相同的向量提取出来,另一组不相同的向量拼接转换成矩阵,向量向量乘变成矩阵向量乘;若一组向量向量乘a1×
b1,a2×
b2,
…
,a
n
×
b
n
中向量a1,a2,a
n
相同且向量b1,b2,b
n
相同,则将一组相同的向量提取出来,另一组相同的向量拼接转换成矩阵,向量向量乘变成矩阵向量乘;若一组矩阵向量乘a1×
b1,a2×
b2,
…
,a
n
×
b
n
中矩阵a1、a2、a
n
相同,矩阵a1、a2、a
n
提取出来,将向量b1、b2、b
n
拼接转换成矩阵,矩阵向量乘变成矩阵矩阵乘;
a1、a2、a
n
表示矩阵,b1、b2、b
n
表示向量;若一个矩阵矩阵乘a
×
b的计算结果的对角线相加,得到向量向量扩充乘;b1、b2、b
n
表示矩阵;即得到最优的算子计算形式;将步骤1数据在片外存储器的组织形式加载到片上缓存buffer,基于最优的算子计算形式将片上缓存buffer的数据重排,将重排后数据加载到片上缓存buffer2中;缓存buffer2中数据传输到mac阵列中,mac阵列输出结果传给片外存储器。3.根据权利要求2所述的一种深度学习处理器的泛化架构设计方法,其特征在于:所述基于最优的算子计算形式将片上缓存buffer的数据重排,将重排后数据加载到片上缓存buffer2中,具体过程为:基于密集计算对应的密集公式将片上缓存buffer的数据拆成最优的算子计算形式;将拆成的最优的算子计算形式加载到片上缓存buffer2中。4.根据权利要求3所述的一种深度学习处理器的泛化架构设计方法,其特征在于:所述步骤3:将步骤1数据在片外存储器的组织形式加载到片上缓存buffer,缓存buffer中数据传输到mac阵列中,mac阵列输出结果传给片外存储器;具体过程为:步骤31、将密集型计算任务的算子转换成深度学习卷积计算任务中的序列控制形式;步骤32、序列控制模块将缓存buffer中数据按照深度学习卷积计算任务中的序列控制形式加载出来然后传输到mac阵列中。5.根据权利要求4所述的一种深度学习处理器的泛化架构设计方法,其特征在于:所述步骤31、将密集型计算任务的算子转换成深度学习卷积计算任务中的序列控制形式;具体过程为:密集型计算任务的算子包括向量向量乘,矩阵向量乘,矩阵矩阵乘和向量向量扩充乘;通用的深度学习加速器包含一个mac阵列,一个周期一个mac单元加载一个数据的一个卷积核,将mac阵列转换成向量向量乘;通用的深度学习加速器包含一个mac阵列,一个周期多个mac单元中每个mac阵列加载同一个数据的不同卷积核,将mac阵列转换成矩阵向量乘;通用的深度学习加速器包含一个mac阵列,多个周期多个mac单元加载不同数据的不同卷积核,将mac阵列转换成矩阵矩阵乘;通用的深度学习加速器包含一个mac阵列,多个周期多个mac单元加载不同数据的不同卷积核,一组矩阵矩阵乘的计算结果的对角线相加,将mac阵列转换成向量向量扩充乘。6.根据权利要求5所述的一种深度学习处理器的泛化架构设计方法,其特征在于:所述深度学习卷积计算任务中包括可变位宽的控制指令;所述密集型计算任务中包括可变位宽的控制指令。7.根据权利要求6所述的一种深度学习处理器的泛化架构设计方法,其特征在于:所述mac为乘法累加运算;mac阵列为多个乘法累加运算单元组成的阵列;mac阵列是4bit的mac阵列,对于不同的位宽组合是通过4bit拼接得到的。
技术总结
一种深度学习处理器的泛化架构设计方法,本发明涉及深度学习处理器的泛化架构设计方法。本发明的目的是为了解决现有深度学习处理器在智能IoT场景中不能兼容深度学习以外的其他计算密集的任务,导致芯片面积的增加、成本的增加、利用率的偏差、计算能效低的问题。过程为:架构包含任务解析的通用处理器与加速计算的深度学习加速器。当进行深度学习卷积计算任务时,通用处理器解析数据在片外的组织形式,将数据加载至片上缓存Buffer,由序列控制器按卷积顺序将数据加载至MAC阵列进行计算。当进行密集计算任务时,增加重排模块,基于最优的算子计算形式将Buffer数据重排至片上缓存Buffer2中,并将Buffer2数据传输至MAC阵列中进行计算。本发明用于深度学习处理器领域。本发明用于深度学习处理器领域。本发明用于深度学习处理器领域。
技术研发人员:杨兵 朱智彧 刘成 张文宇 李潇 罗小琴
受保护的技术使用者:哈尔滨理工大学
技术研发日:2023.04.23
技术公布日:2023/8/3
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。