1.本发明涉及数据处理技术领域,具体涉及基于大数据的互联网广告智能监测系统。
背景技术:
2.广告相似的恶意竞争是指竞争对手在广告中使用与其他公司类似的商标、标志、品牌名称、产品名称或广告语,以混淆消费者并获取不当竞争优势的行为。这种行为违反了商标法和不正当竞争法。现有技术是通过对比广告文本的dice相似度来判断广告是否存在抄袭,模仿等不正当竞争关系。dice相似度是一种用于衡量两个集合相似程度的度量方法,它是通过计算两个集合中共同元素的数量来衡量它们的相似度。但是dice相似度只能通过相同字符占比确定文本相似度,无法通过结构,位置等信息确定文本相似度,且无法处理相同的重复字符,对文本相似性判断不够准确。
技术实现要素:
3.本发明提供基于大数据的互联网广告智能监测系统,以解决现有的问题。
4.本发明的基于大数据的互联网广告智能监测系统采用如下技术方案:本发明一个实施例提供了基于大数据的互联网广告智能监测系统,该系统包括以下模块:文本采集模块,用于采集数据文本和对比文本;数据分组模块,用于利用相似度对数据文本和对比文本进行分组得到对应分组;参数计算模块,用于计算每个对应分组的字符频率差异程度参数、交集字符位置分布权重影响参数和数据位置相似程度权重参数;权重拟合模块,用于将每个对应分组的字符频率差异程度参数、交集字符位置分布权重影响参数和数据位置相似程度权重参数得到相似度权数,并利用相似度权数得到dice相似度权重;相似判定模块,用于利用dice相似度权重得到整个数据文本和对比文本的相似度并判断互联网广告是否涉嫌抄袭。
5.优选的,所述数据文本和对比文本的获取方法为:在所有互联网广告文本中,按照文本的出现时间进行采集,在所有采集到的文本中选择两个文本,将两个文本中出现时间较为靠前的文本记为对比文本,两个文本中出现时间较为靠后的文本记为数据文本。
6.优选的,所述利用相似度对数据文本和对比文本进行分组得到对应分组,包括的具体步骤如下:对每个数据文本和每个对比文本进行dice相似度计算得到每个数据文本和每个对比文本的相似度,将每个数据文本和与其相似度最高的对比文本进行关联,得到对应字符,最后把所有的对应字符放入一个集合中,将该集合记为对应分组。
7.优选的,所述字符频率差异程度参数的具体计算公式如下:其中,为第i个对应分组下的字符频率差异程度参数,i表示所有的i个对应分组中第i个对应分组且有,为第i个对应分组下第q个交集字符在数据文本中出现的次数,为第i个对应分组下第q个交集字符在对比文本中出现的次数,q为每个分组中数据文本和对比文本字符集合的交集中的第q个字符,共q个且有。
8.优选的,所述交集字符位置分布权重影响参数的具体获取步骤如下:在每个对应分组中,将每个交集字符在数据文本和对比文本中的位置分别记为和,并计算如下公式:其中,为第i个对应分组下的交集字符位置分布权重影响参数,表示第q个交集字符在第i个对应分组内数据文本中的位置,表示第q个交集字符在第i个对应分组内对比文本中的位置,和分别为第i个对应分组内数据文本和对比文本的交集字符分别在数据文本和对比文本中的位置的平均值,为第i个对应分组内交集字符在数据文本中占用的位置的数量,为第i个对应分组内交集字符在对比文本中占用的位置的数量,为第i个对应分组下第q个交集字符在数据文本中出现的次数,为第i个对应分组下第q个交集字符在对比文本中出现的次数,q为每个分组中数据文本和对比文本字符集合的交集中的第q个字符,共q个且有。
9.优选的,所述数据位置相似程度权重参数的具体获取步骤如下:获取每个对应分组中的每种字符在数据文本和对比文本中的位置,计算所有对应分组中的所有字符在数据文本和对比文本中的平均位置,并计算每个对应分组中的每种字符在数据文本和对比文本中的位置与所有字符的平均位置的差异值,并将差异值进行归一化,得到每个对应分组的数据位置相似程度权重参数。
10.优选的,所述将每个对应分组的字符频率差异程度参数、交集字符位置分布权重影响参数和数据位置相似程度权重参数得到相似度权数,并利用相似度权数得到dice相似度权重,包括的具体步骤如下:首先,将每个对应分组的字符频率差异程度参数、交集字符位置分布权重影响参数和数据位置相似程度权重参数分别加一,将加一后的结果相乘,得到每个对应分组下数据文本和对比文本的相似度权数;最后,再将每个对应分组下数据文本和对比文本的相似度权数进行归一化操作,得到每个对应分组的dice相似度权重。
11.优选的,所述利用dice相似度权重得到整个数据文本和对比文本的相似度,包括
的具体步骤如下:计算每个对应分组内数据文本和对比文本的dice相似度,将每个对应分组内数据文本和对比文本的dice相似度与每个对应分组的dice相似度权重相乘,得到每个对应分组的相似因子,计算所有对应分组的相似因子的算数均值,将算术均值作为整个数据文本和对比文本的相似度。
12.本发明的技术方案的有益效果是:根据文本数据特征,计算dice交集数据的频率,位置分布,和结构的相似性结合dice算法综合判断文本与对比文本的相似性,解决了dice相似度无法通过结构,位置等信息确定文本相似度,且无法处理相同的重复字符的问题,可以更准确的判断两个广告文本的相似性。
附图说明
13.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
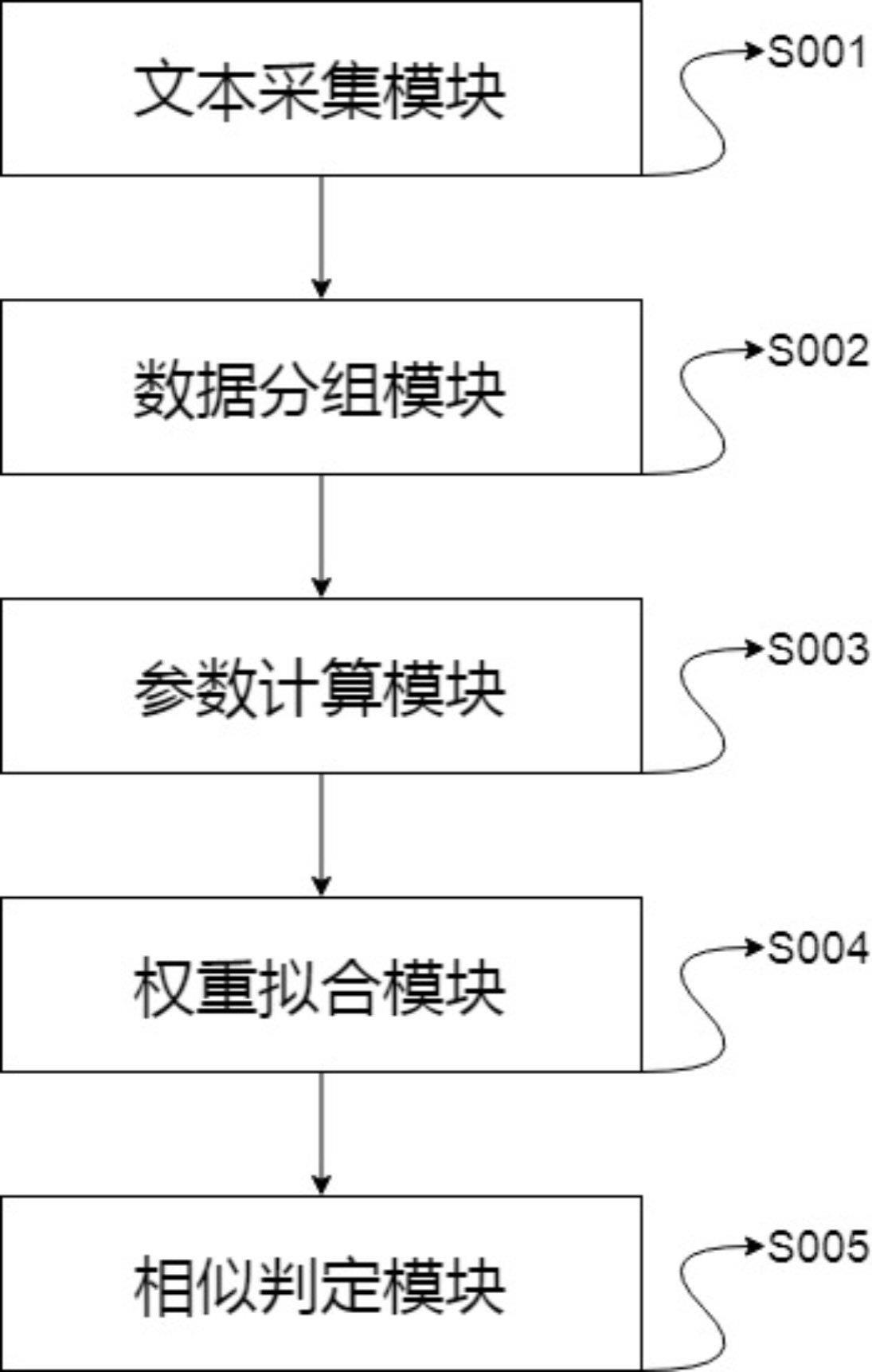
14.图1为本发明基于大数据的互联网广告智能监测系统的系统结构图。
具体实施方式
15.为了更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明提出的基于大数据的互联网广告智能监测系统,其具体实施方式、结构、特征及其功效,详细说明如下。在下述说明中,不同的“一个实施例”或“另一个实施例”指的不一定是同一实施例。此外,一或多个实施例中的特定特征、结构或特点可由任何合适形式组合。
16.除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。
17.下面结合附图具体的说明本发明所提供的基于大数据的互联网广告智能监测系统的具体方案。
18.请参阅图1,其示出了本发明一个实施例提供的基于大数据的互联网广告智能监测系统的步骤流程图,该系统包括以下模块:文本采集模块s001,用于采集数据文本和对比文本。
19.在所有互联网广告文本中,按照文本的出现时间进行采集,在所有采集到的文本中选择两个文本,将两个文本中出现时间较为靠前的文本记为对比文本,两个文本中出现时间较为靠后的文本记为数据文本。需要说明的是,本实施例中的对比文本和数据文本是一个相对概念而不是绝对的,两者不能独立出现。对采集到的所有文本进行无关信息(如标点符号、语助词等)进行去除,得到了数据文本和对比文本。
20.数据分组模块s002,用于利用相似度对数据文本和对比文本进行分组得到对应分组。
21.由于dice相似算法对于长文本的处理效果并不理想,而根据断句对文本数据分组可以利用标点符号将长文本分割成数个短文本,提高了算法的准确性,且根据断句对文本
数据进行分组,尽可能地使文本的结构信息保留在同一个分组之内,有助于后续分析结构信息。故本实施例在利用原标点符号位置进行断句的基础上,对每个数据文本和每个对比文本进行dice相似度计算,将每个数据文本和与其对应的相似度最高的对比文本进行关联,得到对应字符,将所有的对应字符放入一个集合中,则该集合就是对应分组,见如下表示:其中,表示第i个对应分组,其中表示第i个数据文本,表示与第i个数据文本最相似的对比文本。i表示对应分组的总个数且有。
22.参数计算模块s003,用于计算每个对应分组的字符频率差异程度参数、交集字符位置分布权重影响参数和数据位置相似程度权重参数。
23.由于dice相似度算法只考虑了文本中字符的相似度,对于字符出现的频率和位置及结构信息并未考虑,从而导致对广告文本相似性判断并不准确,所以需要添加对应分组内字符的字符频率差异程度参数、交集字符位置分布权重影响参数和数据位置相似程度权重参数。
24.首先,当数据文本与对比文本中交集字符在文本中出现频率越接近,则数据文本与对比文本的相似度越高。记某分组下数据文本和对比文本字符集合分别为,且,为每个分组中数据文本和对比文本字符集合的交集中的第q个字符,简记为第i个分组的第q个交集字符,共q个则有,同时把每个交集字符在第i个对应分组内数据文本和对比文本中出现的次数分别记为和,其中表示交集中的第q个字符在第i个对应分组内数据文本中出现的次数,表示交集中的第q个字符在第i个对应分组内对比文本中出现的次数;累加每个交集字符在数据文本中出现次数和对比文本中出现次数之差,可以得到交集字符在数据文本和对比文本中出现次数的差异,但由于两组对比文本的长度可能不同,所以计算两组数据文本交集字符出现的次数与其组内数据总量的比值之差,即计算两组数据文本交集字符出现的频率之差得到每个对应分组下字符频率差异程度参数的公式如下:其中,为第i个对应分组的字符频率差异程度参数,为第i个对应分组下第q个交集字符在数据文本中出现的次数,为第i个对应分组下第q个交集字符在对比文本中出现的次数。差值的绝对值越小,则说明第i个对应分组下第q个交集字符出现频率越接近,数据文本和对比文本的相似性越高,并通过累加所有交集字符在数据文本和对比文本中出现频率的差值的绝对值,和越小,则说明第i个对应分组下其所有交集字符出现频率的差异性越小,数据相似性越高。
25.本实施例首先得到了每个对应分组的字符频率差异程度参数。
26.其次,相似度高的文本在字符的位置分布上会比较接近,而相似度低的文本在字符的位置分布上差异较大,故同一对应分组下数据文本与对比文本的交集字符在各自数据文本和对比文本中的位置的离散程度反映了数据文本和对比文本的相似性。如果两个文本相似度高,则它们的交集字符位置分布会比较接近,因为它们在内容和语言结构上有很多相似之处,相反,如果两个文本相似度较低,则它们的交集字符位置分布差异会比较大,因为它们在内容和语言上的相似之处很少。在第i个对应分组中,每个交集字符在数据文本和对比文本中的位置分别为和(由于数据文本和对比文本的长度可能不一致,故交集字符在数据文本和对比文本中的位置的区间也可能不一致,故e与r在数值上相等但是表示的位置不相等,例如表示的是某对应分组下第3个交集字符在数据文本中的位置,这个位置在数据文本中的位置等于4,而表示的是某对应分组下第3个交集字符在对比文本中的位置,这个位置在对比文本中的位置等于9。另外在本实施例中当一个交集字符在数据文本或者对比文本中存在多个位置时,取这多个位置的均值作为其在数据文本或者对比文本中的位置),则有以下公式:其中,为第i个对应分组的交集字符位置分布权重影响参数,表示第q个交集字符在第i个对应分组内数据文本中的位置,表示第q个交集字符在第i个对应分组内对比文本中的位置,和分别为第i个对应分组内数据文本和对比文本的交集字符分别在数据文本和对比文本中的位置的平均值,为第i个对应分组内交集字符在数据文本中占用的位置的数量,为第i个对应分组内交集字符在对比文本中占用的位置的数量,和则分别表示了第i个对应分组内数据文本和对比文本中交集字符出现次数的总数。离散程度可以作为一种指标来衡量数据的相似性,数据文本和对比文本中数据分布情况越接近则其数据位置的离散程度越接近,而数据文本中数据分布差异越大则其数据位置的离散程度差异越大,数据分布相似性越高,数据文本和对比文本离散程度差的绝对值越小,数据分布相似性越低,数据文本和对比文本离散程度差的绝对值越大。
27.本实施例其次得到了每个对应分组的交集字符位置分布权重影响参数。
28.最后,虽然交集字符位置分布的离散程度可以一定程度上判断数据的相似性,但交集字符种类很多,可能存在交集数据分布情况相同但字符位置不同的情况,且交集数据种类较多,同一对应分组下的两个文本中相同的交集字符的数量可能不同,导致无法对相同的每个字符位置一一进行对比,所以计算每个字符在其分组内平均位置再进行差异分析可以得到该字符在分组内存在的大致位置分布,如果数据文本和对比文本的字符交集位置分布相似程度很高,那么它们可能具有相似的数据结构和内容。反之,如果原文本和对比文本的字符交集位置分布相似程度很低,那么它们可能不具有相似的数据结构和内容。在第i
个对应分组中,获取对比文本和数据文本的所有字符,其中第f中字符在数据文本中存在的数量和位置分别记为和,第f中字符在对比文本中存在的数量和位置分别记为和,并得到每个对应分组中的每种字符分布情况的差异程度具体公式如下:其中,为第i个对应分组中的第f种字符分布情况的差异程度,为第f种字符在第i个对应分组下的数据文本中存在的数量,为第f种字符在第i个对应分组下的对比文本中存在的数量;为第f种字符在第i个对应分组下的数据文本中的位置,为第f种字符在第i个对应分组下的对比文本中的位置;为第i个对应分组下数据文本中的字符总数量,为第i个对应分组下对比文本中的字符总数量。公式计算了第i个对应分组中的第f种字符在数据文本和对比文本中的平均位置,并对位置信息进行归一化,方便对比数据文本和对比文本该字符的位置信息,的值越小,则说明第i个对应分组中的第f种字符在数据文本和对比文本中的位置越接近。
29.通过上述公式可以计算分组交集内每种字符的平均位置,其中n为交集字符种类数量,即上述步骤中去重后的数据交集数量,所以分组内数据位置相似程度权重用以下公式表示:其中,为第i个对应分组的数据位置相似程度权重参数,f为第i个对应分组中字符种类的总数,且有,为第i个对应分组中的第f种字符分布情况的差异程度。累加每个分组中所有种类字符在数据文本和对比文本中的位置差异程度可以得到这组数据总的位置差异程度,位置差异程度越小,数据文本和对比文本的相似性越高。
30.本实施例最后得到了每个对应分组的数据位置相似程度权重参数。
31.至此,本实施例获得了每个对应分组的字符频率差异程度参数、交集字符位置分布权重影响参数和数据位置相似程度权重参数。
32.权重拟合模块s004,用于将每个对应分组的字符频率差异程度参数、交集字符位置分布权重影响参数和数据位置相似程度权重参数得到相似度权数,并利用相似度权数得到dice相似度权重。
33.根据模块s003得到的三个参数得到每个对应分组下数据文本和对比文本的相似度权数的计算公式如下所示:其中,为第i个对应分组下数据文本和对比文本的相似度权数,、和分别为第i个对应分组的字符频率差异程度参数、交集字符位置分布权重影响参数和数据位置相似程度权重参数。三个参数的参数值越大,数据的相似程度越低,即权重越小参数大小和
相似程度为负相关关系,即参数大小与dice相似度权重为负相关关系,所以在计算权数时需要取倒数,且避免参数为0时公式不成立,所以需要给分母加1。而对于加权运算中,权重需要满足归一化条件,故可以用以下公式对进行归一化:其中,是第i个对应分组的dice相似度权重,是第i个对应分组下数据文本和对比文本的相似度权数。
34.至此,得到了每个对应分组的dice相似度权重。
35.相似判定模块s005,用于利用dice相似度权重得到整个数据文本和对比文本的相似度并判断互联网广告是否涉嫌抄袭。
36.利用dice相似度判定并结合所有对应分组dice相似度判定的权重,可以得到整个数据文本和对比文本的相似度:其中,dic为整个数据文本和对比文本的相似度,i为对应分组的总个数且有,为第i个对应分组的原始dice相似度,具体计算为现有公知技术,为与之对应的权重。对所有对应分组的原始dice相似度进行加权平均,可以得到数据文本和对比文本的相似度,再除以总的对应分组的数目,就得到了归一化的数据文本和对比文本的dice相似度。
37.至此,得到了归一化的数据文本和对比文本的dice相似度,在实际判断互联网广告是否涉嫌抄袭的过程中,可以人为设定抄袭阈值,当某数据文本和对比文本的相似度超过抄袭阈值时,则认为该数据文本相较于对比文本存在抄袭现象,将判断结果传输给相应工作人员进行解决处理。
38.以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。