1.本发明涉及工业物理系统的建模技术领域,具体涉及一种面向功能需求分类标记的模型库构建方法及系统。
背景技术:
2.目前,很多工业技术需要用到modelica语言来实现物理系统的建模,而一个完整工业项目包含的模型中的机理组件是多种多样的。现有的机理模型库的构建方法需要构建模型字典id和模型特性字典id来确定机理模型及机理模型特性,这种方法需要花费大量的人力物力,存在手动分类,效率较低的问题。因此,需要一个较好的模型库构建方法来实现将多样的机理组件以及组件之间的基础对应关系进行分类,分类为带有标注属性的不同功能需求的modelica模型机理库,这样有助于为后期组件之间的关系分析提供数据。
技术实现要素:
3.本发明要解决的技术问题:针对现有技术的上述问题,提供一种面向功能需求分类标记的模型库构建方法及系统,本发明能够实现将多样的机理组件以及组件之间的基础对应关系进行分类,分类为带有标注属性的不同功能需求的modelica模型机理库,这样有助于为后期组件之间的关系分析提供数据。
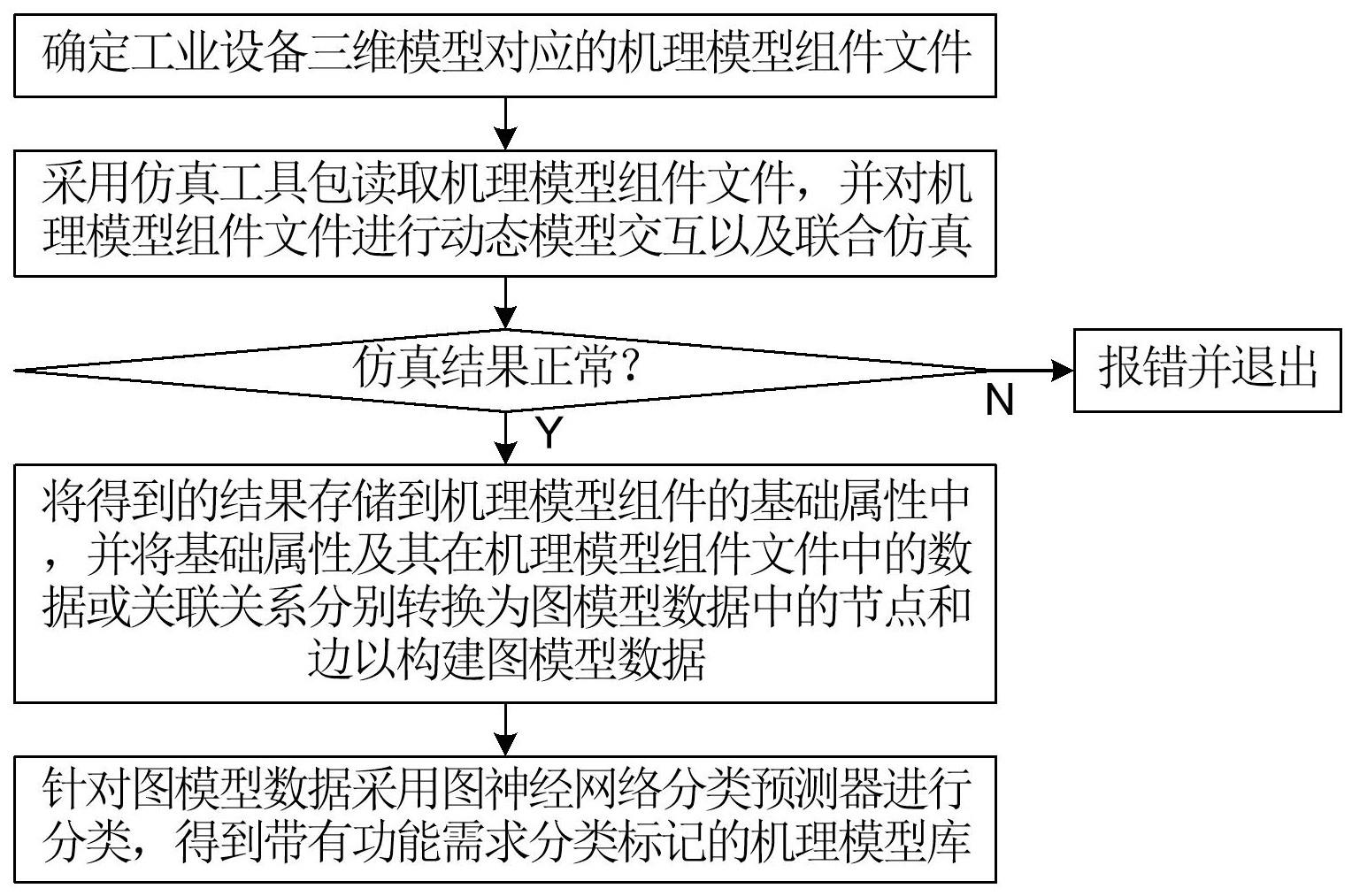
4.为了解决上述技术问题,本发明采用的技术方案为:一种面向功能需求分类标记的模型库构建方法,包括:s101,确定工业设备三维模型对应的机理模型组件文件;s102,采用仿真工具包读取机理模型组件文件,并对机理模型组件文件进行动态模型交互以及联合仿真,若仿真结果正常,则跳转下一步;s103,将进行动态模型交互以及联合仿真得到的结果存储到机理模型组件的基础属性中,并将基础属性及其在机理模型组件文件中的数据或关联关系分别转换为图模型数据中的节点和边以构建图模型数据,其中所述节点为工业设备三维模型各个组件的基础属性,所述边为连接两个组件的数据或关联关系;s104,针对图模型数据采用训练好的图神经网络分类预测器进行分类,从而得到带有功能需求分类标记的机理模型库。
5.可选地,所述机理模型组件文件是指modelica机理模型组件文件。
6.可选地,步骤s102中采用的仿真工具包为pyfmi仿真工具包。
7.可选地,步骤s102中还包括在仿真结果不正常时,报错并退出。
8.可选地,步骤s104中的图神经网络分类预测器为改进的图卷积神经网络gcn,所述改进的图卷积神经网络gcn包括由级联连接的n个一次层和一个二次层构成,且其中:所述一次层的函数表达式为:,上式中,表示任意第k个一次层的输出向量,为激活函数,为第k-1个一次
层的输出向量,为从邻接矩阵中导出的系数矩阵,为第k个一次层的权重矩阵;所述二次层的函数表达式为:,上式中,表示二次层的输出向量,和是不同的权重矩阵,,上标t表示矩阵的转置操作,为的第i个元素,表示将所有的元素组合,表示第n个一次层的输出向量。
9.可选地,步骤s104之前还包括训练图神经网络分类预测器:s201,构建图模型数据的训练样本集;s202,通过凸聚类使用数据驱动的混合函数来增强图模型数据的训练样本集;s203,采用增强后的图模型数据的训练样本集训练图神经网络分类预测器。
10.可选地,步骤s202包括:s301,针对训练样本集中的原始图模型数据,通过贝叶斯随机块模型sbm将原始图模型数据转换为欧几里得描述符;s302,针对欧几里得描述符进行凸聚类,并使用凸聚类计算簇路径;s303,通过簇路径得到数据驱动混合函数,并使用数据驱动混合函数获得扩展的簇路径;s304,将扩展的簇路径叠加到原始的簇路径上,得到扩展簇路径;s305,使用扩展簇路径对新的图模型数据及其标签进行采样得到增强后的新图模型数据,并将增强后的新图模型数据加入训练样本集中。
11.可选地,步骤s203中采用增强后的图模型数据的训练样本集训练图神经网络分类预测器时,包括采用二进制交叉熵损失函数作为训练图神经网络分类预测器时采用的损失函数。
12.此外,本发明还提供一种面向功能需求分类标记的模型库构建系统,包括相互连接的微处理器和存储器,所述微处理器被编程或配置以执行所述面向功能需求分类标记的模型库构建方法。
13.此外,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序用于被微处理器编程或配置以执行所述面向功能需求分类标记的模型库构建方法。
14.和现有技术相比,本发明主要具有下述优点:本发明方法包括采用仿真工具包读取工业设备三维模型对应的机理模型组件文件,进行动态模型交互以及联合仿真,若仿真结果正常则将结果存储到机理模型组件的基础属性中,并将基础属性及其在机理模型组件文件中的数据或关联关系分别转换为图模型数据中的节点和边以构建图模型数据,针对图模型数据采用训练好的图神经网络分类预测器进行分类得到带有功能需求分类标记的机理模型库。本发明能够实现将多样的机理组件以及组件之间的基础对应关系进行分类,分类为带有标注属性的不同功能需求的modelica模型机理库,这样有助于为后期组件之间的关系分析提供数据。
附图说明
15.图1为本发明实施例方法的基本流程示意图。
16.图2为本发明实施例方法的完整流程示意图。
17.图3为本发明实施例中将原始图模型数据转换为欧几里得描述符的原理示意图。
18.图4为本发明实施例中采样得到增强后的新图模型数据的原理示意图。
具体实施方式
19.如图1所示,本实施例提供一种面向功能需求分类标记的模型库构建方法,包括:s101,确定工业设备三维模型对应的机理模型组件文件;s102,采用仿真工具包读取机理模型组件文件,并对机理模型组件文件进行动态模型交互以及联合仿真,若仿真结果正常,则跳转下一步;s103,将进行动态模型交互以及联合仿真得到的结果存储到机理模型组件的基础属性中,并将基础属性及其在机理模型组件文件中的数据或关联关系分别转换为图模型数据中的节点和边以构建图模型数据,其中所述节点为工业设备三维模型各个组件的基础属性,所述边为连接两个组件的数据或关联关系;s104,针对图模型数据采用训练好的图神经网络分类预测器进行分类,从而得到带有功能需求分类标记的机理模型库。
20.参见图2,本实施例中的机理模型组件文件是指modelica机理模型组件文件。工业装备可以看作是由不同的子系统组合构成。其中子系统中有包括非常多的机理组件,例如,异步交流电机中的转矩、电机额定转速、转子转速、定子旋转磁场的同步转速等。将系统中的机理组件用节点表示,节点标签可以用于限制节点所属系统,同一系统下机理组件之间的数据公式以及关联用节点之间的边表示,边的方向与组件数据传输方向一致,表示了组件之间的数据关系或者关联关系,这些节点和边共同组成了modelica机理模型组件文件图模型的基础属性。作为构建模型机理库的关键,图模型的节点包含了组件的主要结构信息,节点的属性只包含主要工作状态下的属性信息。图模型的边则用来表示节点之间相关性。
21.本实施例中,步骤s102中采用的仿真工具包为pyfmi仿真工具包。fmi(功能打样接口)是一个工具独立的标准,通过xml文件与编译的c代码的融合来支持动态模型的交互和联合调试,fmu是一个压缩文件,包含了xml格式接口数据描述和功能,fmu就是采用fmi接口而开发的软件组织。pyfmi是一个python的第三方仿真工具包,使用pyfmi对之前modelica组件文件进行读取,进行动态模型的交互以及联合仿真,解决模型相互操作的问题,也就是将组件运行一遍,查看组件是否正常,如果可以正常相互运行、相互操作,则将仿真结果的组件存储到模型库的基础属性中,基础属性也就是主要工作状态下的属性信息,如能量数据,物理参数,时间信息等属性。将之前收集的正式modelica机车组件文件放入相应组件库的不同功能部门下,使用pyfmi第三方库将组件库中的组件进行模拟仿真。
22.参见图1,本实施例中步骤s102中还包括在仿真结果不正常时,报错并退出。
23.利用图神经网络来进行图节点分类,并按不同功能需求来标注属性包括收集工业项目所提供的图神经网络节点分类的数据集,根据其标签,将工业组件用图节点的形式存储表示,将组件之间的数据关系和关联关系用边表示,使用图节点分类方法如半监督分类的gcn模型、基于注意力的gat模型以及它们的改进版本,对图进行训练,最后在测试集上检
n. liu, and x. hu,
ꢀ“
g-mixup: graph data augmentation for graph classification,
”ꢀ
arxiv preprint arxiv:2202.07179, 2022。
27.本实施例中应用凸聚类来表征图形空间中图形数据的空间关系,通过凸聚类使用数据驱动的混合函数来增强图模型数据的训练样本集是一种数据增强方法,采用图数据扩充的新型数据驱动非线性混合机制可为样本及其标签提供不同的混合函数,可通过在数据样本对及其标签之间进行线性插值来创建新的训练数据。凸聚类公式如下:,上式中,为簇中心,是可调融合参数,为所有簇,为路径数,是指定之间融合强度的权重,函数和分别是量化数据保真度和样本融合,为簇中第i个样本,为簇中第j个样本,为第i个观察点,为簇中第i个样本与所观察点的量化数据保真度函数,为簇中第i个样本与簇中第j个样本的融合函数。进行凸聚类计算的簇路径,再通过簇路径得到数据驱动混合函数,采用图混合的方法,利用数据样本的位置来通知在何处以及如何在类之间进行插值,通过簇路径刻画空间中图的空间关系。作为一种优选的实施方式,本实施例中将凸聚类公式改进为以下公式:,上式中,为第i个簇,为0时,的取值。
28.步骤s303中通过簇路径得到数据驱动混合函数,并使用数据驱动混合函数获得扩展的簇路径为现有方法,具体可参见文献:e. c. chi and s. steinerberger,
ꢀ“
recovering trees with convex clustering,
”ꢀ
siam journal on mathematics of data science,vol. 1, no. 3, pp. 383
–
407, 2019。
29.步骤s305中使用扩展簇路径对新的图模型数据及其标签进行采样时,扩展簇路径公式如下,其中为第k个索引集表示簇赋值,为路径数,通过基于上述公式的t个路径的子集的簇分配来组合t个路径,以计算k个分支的簇路径:,上式中,为第k个分支中的簇中心,为第k个索引集表示簇赋值,为1到t中某个路径的簇中心。使用扩展簇路径对新的图模型数据及其标签进行采样得到增强后的新图模型数据如图4所示,首先选择分支和混合参数,将作为得到的图形的质心,根据参数选择的不同可以为每个和得到任意数量的新图即是采样过程,可采用函数表达式表示为:,上式中,即为增强后的新图模型数据。
30.本实施例中,步骤s203中采用增强后的图模型数据的训练样本集训练图神经网络分类预测器时,包括采用二进制交叉熵损失函数作为训练图神经网络分类预测器时采用的损失函数。
31.综上所述,本实施例方法将进行动态模型交互以及联合仿真得到的结果存储到整个模型库的基础属性中,使用图数据库的方式将基础属性及其对应的关联关系和数据关系化为节点和边,节点即是各个组件的基础属性同时包括特性,连接节点的边即是连接两个组件的数据关系或关联关系,例如组件之间的数据公式,利用之前得到的关于数据集的最优的图神经网络分类预测器,将之前整理好的正式的机理组件的图模型分类为带有标注属性的按分类标记的不同功能需求的modelica模型机理库,可为未来的数据关系分析提供数据基础。本实施例方法中利用图模型来表示工业子系统中的机理组件,不局限于单一工业项目,并通过图神经网络的方式对组件文件进行分类的预测,有助于构建工业项目中面向功能需求分类标记的基础模型库,以备为后期工业项目中的组件关系分析提供数据。
32.此外,本实施例还提供一种面向功能需求分类标记的模型库构建系统,包括相互连接的微处理器和存储器,微处理器被编程或配置以执行所述面向功能需求分类标记的模型库构建方法。此外,本实施例还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,计算机程序用于被微处理器编程或配置以执行所述面向功能需求分类标记的模型库构建方法。
33.本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可读存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
34.以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。