在用于以对象为中心的视觉推理的对象嵌入上实现注意力的神经网络
1.相关申请的交叉引用
2.本技术要求于2020年10月2日提交的美国临时申请no.63/087,041的优先权。在先申请的公开内容被认为是本技术的公开内容的一部分,并且通过引用并入本技术的公开内容中。
技术领域
3.本说明书涉及处理视频帧序列以生成对查询的响应的系统。
背景技术:
4.神经网络是采用一层或多层非线性单元的机器学习模型来预测接收到的输入的输出。一些神经网络除了输出层之外还包括一个或多个隐藏层。每个隐藏层的输出被用作网络中的下一层(即,下一隐藏层或输出层)的输入。网络的每个层根据相应参数集的当前值从所接收的输入生成输出。
技术实现要素:
5.本说明书描述了一种视频处理神经网络系统,该视频处理神经网络系统在一个或多个位置中的一个或多个计算机上被实现为一个或多个计算机程序,该一个或多个计算机程序能够推理视频帧序列中的对象。更具体地,该系统被配置为处理视频帧以响应与对象有关的查询。如本文所使用的,“视频帧”包括来自lidar和其他类似雷达的技术的视频帧。
6.本说明书中描述的主题能够在特定实施例中实现,以便实现以下优点中的一个或多个。
7.本说明书中描述的以对象为中心的处理的实施方式能够回答需要高级时空推理的查询。系统还能够提供对需要理解交互对象的动态的查询的正确响应。该系统的实施方式通常能够回答需要预测性推理(“what will happen next(接下来将发生什么)”)、反事实推理(“what would happen in a different circumstance(在不同情况下将发生什么)”)、解释性推理(“why did something happen(为什么发生某事)”)和因果推理的查询。该系统的实施方式还能够展示对对象永久性的理解,例如,当跟踪暂时被遮挡的目标时,并且可以推理视觉数据的因果动态结构。
8.所描述的以对象为中心的技术能够在先前的方法失败的情况下或者在先前需要更多手动设计的神经符号方法的情况下成功。
9.系统的实施方式部分地依赖于无监督学习,特别是对于对象分割子系统。通常,与一些其他方法相比,系统能够更快地并且以相对较少量的标记的训练数据来学习,从而减少训练时间以及计算和存储器要求。
10.在附图和以下描述中阐述了本说明书的主题的一个或多个实施例的细节。主题的其他特征、方面和优点根据说明书、附图和权利要求书将变得显而易见。
附图说明
11.图1示出了示例视频处理系统。
12.图2示出了视频处理系统的示例架构。
13.图3是使用图1的视频处理系统处理视频的示例过程的流程图。
14.图4是用于训练图1的视频处理系统的示例过程的流程图。
15.各个附图中相同的附图标记和名称指示相同的元件。
具体实施方式
16.本说明书描述了一种视频处理系统,其被配置为分析视频帧序列以检测视频帧中的对象并响应于查询提供与检测到的对象有关的信息。查询可以包括例如对与对象中的一个或多个有关的未来事件或状态的预测的请求(例如,“will objects x and y collide?(对象x和y将碰撞吗?)”),或者对与对象中的一个或多个有关的条件或反事实信息的请求(例如,“what event would[not]happen if object x is modified,moved or absent?(如果对象x被修改、移动或不存在,什么事件将[不]发生吗?)”),或者对视频帧的分析以确定对象中的一个或多个的属性或特性的请求(例如,“how many objects of type z are moving?(多少类型z的对象正在移动?)”)。
[0017]
对查询的响应可以例如是/否回答的形式,或者可以定义可能回答的集合上的概率分布;或者响应可以定义对象的位置。系统的实施方式在能够被定义的查询类型方面是灵活的,并且系统的单个实施方式能够处置多种不同类型的查询。仅作为示例,该系统能够被用来预测两个对象是否将碰撞,或者如何避免碰撞。对查询的响应可以由人类或计算机系统以许多方式使用。例如,分析本身可能是有用的,或者它可以被用来提供警告和/或控制一个或多个对象的运动。
[0018]
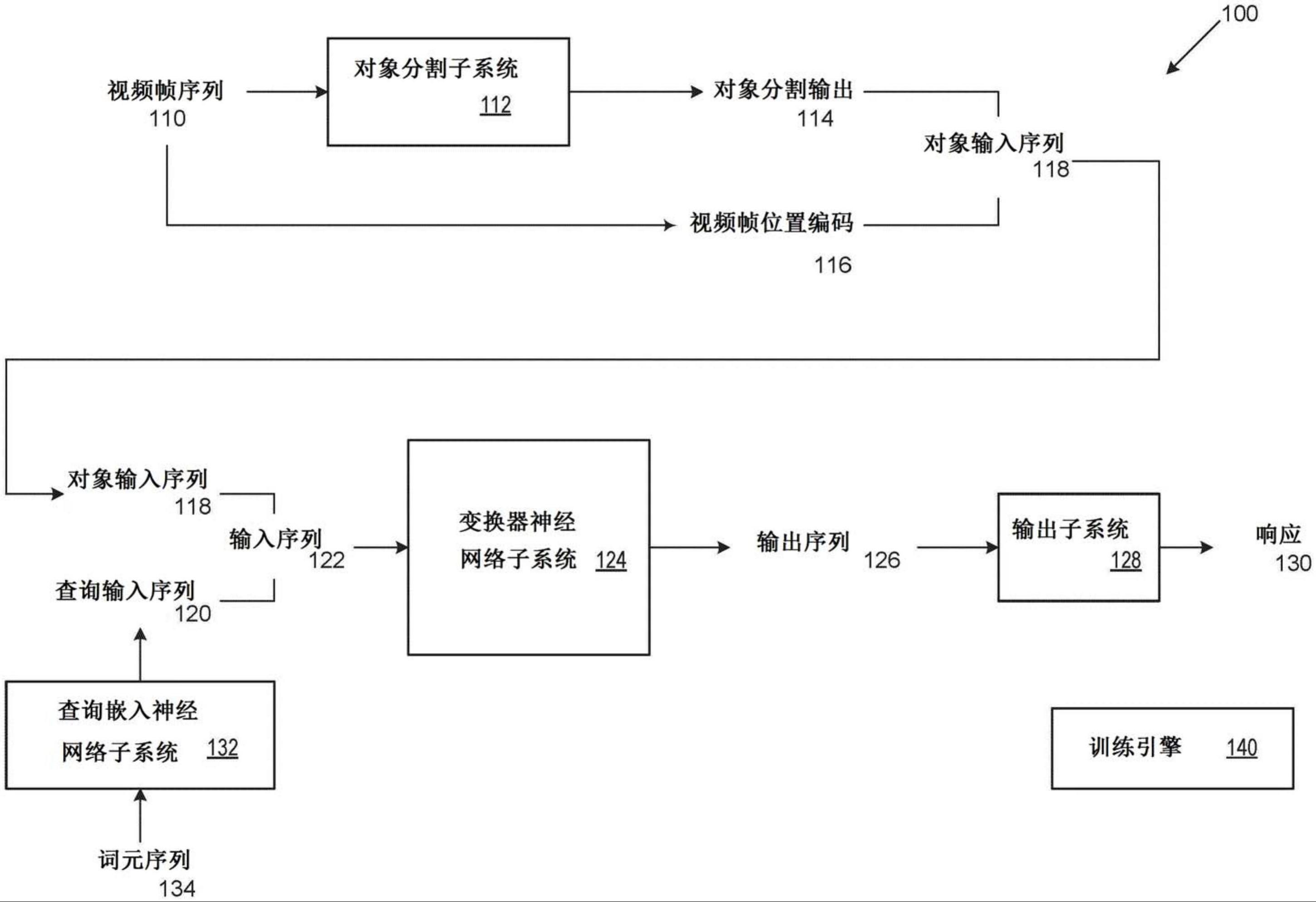
图1示出了示例视频处理系统100。视频处理系统100是包括一个或多个计算机和存储指令的一个或多个存储设备的系统的示例,指令在由一个或多个计算机执行时使得一个或多个计算机实现下面描述的系统、组件和技术。
[0019]
视频处理系统100包括对象分割子系统112,对象分割子系统112被配置为接收包括视频帧序列110的输入,并且处理视频帧序列的每个视频帧的像素以生成对象分割输出114。对于每个视频帧,对象分割输出114包括视频帧中的多个对象中的每个对象的表示。
[0020]
例如,对象分割子系统112可以接收每个视频帧作为用于该帧的像素值集合,并且可以处理像素值以生成d维向量集合,每个d维向量包括对象之一的表示。
[0021]
每个对象的表示可以是解耦表示(disentangled representation)。如本文所使用的,解耦表示可以是每个对象由单独的参数集合描述的表示,即对象中的一个的参数基本上不受对象中的另一个的影响。在系统的实施方式中,解耦表示不需要完全解耦。
[0022]
还从视频帧序列110生成视频帧位置编码116。这对序列中的每个视频帧的相对位置——即时间或顺序——进行编码。可以使用任何合适的编码。在一些实施方式中,位置编码还可以取决于序列的不同视频帧之间的时间距离——例如,时间位置t可以被编码为d维向量,其中,每个维度的值i是对于偶数i,为sin(ωt),以及对于奇数i,为cos(ωt),其中,ω=n-2i/d
,其中,n是大数,例如10000。
[0023]
在实施方式中,每个视频帧的对象分割输出114与视频帧位置编码116组合以生成
对象输入序列118。例如,视频帧中的每个对象的表示可以与帧的位置编码级联;或者可以将视频帧中的每个对象的表示添加到帧的位置编码(其中,这些是相同维度的向量)。因此,对象输入序列118包括元素序列,每个元素包括位置编码。
[0024]
在一些实施方式中,变换器神经网络子系统124还接收表示要应用于视频帧序列的查询的查询输入序列120,特别是与视频帧中表示的对象有关的查询,如下面进一步描述的。这提供了一种灵活的系统,其可以用于以多于一种方式询问视频。在一些其他实施方式中,可以训练变换器神经网络子系统124以实现特定的预定查询(诸如预测对象的位置),并且不需要显式查询输入。
[0025]
因此,变换器神经网络子系统124接收输入序列122,输入序列122包括对象输入序列118,并且还可以包括查询输入序列120。在存在的情况下,查询输入序列120可以被附加到对象输入序列118。变换器神经网络子系统124被配置为将一系列注意力神经网络层应用于输入序列122,以生成输出序列126,该输出序列126包括针对输入序列122的每个元素的经变换的输入元素。
[0026]
变换器神经网络子系统124是特征在于具有一系列注意力神经网络层——在实施方式中,自注意力神经网络层——的神经网络子系统。注意力神经网络层具有用于输入序列的每个元素的注意力层输入,并且被配置为在注意力层输入上应用注意力机制以生成用于输入序列的每个元素的注意力层输出。注意力层输入和注意力层输出包括相同维度的向量,并且注意力神经网络层可以具有残差连接。
[0027]
在实施方式中,该系列注意力神经网络层包括变换器神经网络子系统的不同连续层,每个层应用不同的(学习的)注意力函数。然而,可以连续应用相同的注意力神经网络层,即,可以多次——可选地可变次数——应用相同的(学习的)注意力函数。通常,在本说明书中,术语“学习的”是指在系统训练期间已经调整的函数或值。在实施方式中,每个注意力神经网络层可以接收位置编码。
[0028]
在一些实施方式中,变换器神经网络子系统124的注意力神经网络层将输入序列122的n个元素映射到输出序列126的n个元素。输入序列由注意力神经网络层并行地接收和处理以生成输出序列。例如,第一注意力神经网络层之后的每个注意力神经网络层可以具有包括隐藏状态的注意力层输入,并且可以生成包括用于下一注意力神经网络层的隐藏状态的激活的注意力层输出。最后一个注意力神经网络层的注意力层输出可以用于生成输出序列的元素。
[0029]
在一些实施方式中,变换器神经网络子系统124将输入序列122的n个元素映射到中间序列的n个元素,并且然后由自回归解码器一次一个地处理中间序列的元素以生成输出序列126。通常,可以在视频处理系统100中使用变换器神经网络的任何变体。
[0030]
视频处理系统100包括被配置为接收输出序列128的一个或多个元素的输出子系统128。输出子系统128使用一个或多个输出神经网络层来处理一个或多个元素,以生成作为对查询的响应130的视频处理系统输出。在一些实施方式中,输出子系统128仅接收输出序列128的最后一个元素。
[0031]
在实施方式中,视频处理系统输出,即,响应130,定义了对查询的可能响应集合——例如,对由查询提出的问题的可能回答集合——上的概率分布。例如,响应可以包括可能的输出词元(token)上的分类概率分布,或者特定响应为真(或假)的概率。视频处理系
统输出可以包括诸如对数或概率的分数集合,每个分数用于响应集合中的每个可能响应,或者可以以其他方式参数化概率分布。在这种情况下,查询输入序列120可以包括可能响应的编码。
[0032]
在一些实施方式中,视频处理系统输出,即,响应130,定义作为对象的可能位置的可能响应集合上的概率分布,例如,在1维、2维或3维中的位置网格上的分类分布。对象可以但不必由查询指定。
[0033]
输出子系统128可以具有多个头端以允许例如取决于查询的多个不同类型的响应。
[0034]
在实施方式中,输入序列122,例如查询输入序列120,包括概要词元元素,即,将用于确定输入序列的概要的占位符元素。然后,输出序列126包括概要词元元素的经变换的版本,并且输出子系统可以仅接收并处理经变换的概要词元元素以生成响应130。在实施方式中,概要词元元素被包括在输入序列122的末尾。
[0035]
概要词元元素的经变换的版本表示输入序列的概要,即,由于在训练期间的这种布置,其学习表示输入序列的概要。概要词元元素可以是学习的(即,可训练的)向量,例如,概要词元的经学习的嵌入。概要词元元素的经变换的版本可以包括表示输入序列的概要的单个向量。
[0036]
如前所述,对象输入序列的每个元素可以包括与帧的位置编码组合的视频帧中的对象的(解耦)表示。一个或多个注意力神经网络层(例如,至少第一层)的注意力层输入可以包括用于每个视频帧的每个对象表示。这提供了全局注意力机制,其中,一个或多个注意力神经网络层能够关注每个视频帧中的每个对象。这能够帮助系统了解对象动态和因果关系。在输入序列122包括查询输入序列120的情况下,注意力层输入还可以包括查询输入序列的每个元素,使得全局注意力机制可以同时关注完整查询。
[0037]
在另一方法(未示出)中,第一变换器神经网络子系统处理每个帧内的对象的表示,并且在层次上在第一变换器神经网络子系统上方的第二变换器神经网络子系统执行帧间处理。例如,第一变换器神经网络子系统的输入可以是由视频帧中的每个对象的表示形成的序列,并且输出序列的元素可以被级联成单个特征向量。第二变换器神经网络子系统的输入可以是从用于每个帧的特征向量形成的序列,并且输出序列126可以是第二变换器神经网络子系统的输出。用于帧的位置编码可以被包括在第一或第二变换器神经网络子系统或两者的输入中。
[0038]
不需要使用任何特定类型的对象分割子系统112。然而,通常,对象分割子系统应该确定帧中的每个对象的表示,即每个对象的对象特征向量。对象分割子系统不必需从一帧到下一帧以一致的顺序确定每个对象的表示,因为变换器神经网络子系统124能够跨帧跟踪对象身份。
[0039]
在一些实施方式中,对象分割子系统112为每个对象确定参数化表示对象的潜在变量向量的多变量分布的参数集。潜在变量向量的分量可以被解耦并且表示形状的位置和/或特性,诸如对象的形状、尺寸和/或颜色。对象分割输出114可以包括用于每个对象的分布的平均值向量,即多变量分布的平均值的向量,其可以被用作对象的解耦表示。
[0040]
在使用生成对象分割掩模而不是用于每个对象的特征向量的对象检测器的情况下,可以通过将掩模应用于图像帧并将结果映射到对象特征向量潜在空间来生成对象特征
向量。例如,对于时间t处的对象i,可以使用用于w
×
h像素图像的对象分割掩膜a
ti
∈[0,1]w×h来构造对象特征向量v
ti
=f(a
ti
·
image),其中,f是针对每个对象应用一次的神经网络,例如resnet。
[0041]
如上所述,输入序列122可以是对象输入序列118和查询输入序列120的组合。查询输入序列120可以包括表示查询的向量序列,通常是关于对象的当前或未来事件或状态的问题。
[0042]
查询输入序列120可以由查询嵌入神经网络子系统132生成,查询嵌入神经网络子系统132被配置为接收和处理表示查询的词元134的序列。查询嵌入神经网络子系统132生成每个词元的相应嵌入,以提供表示查询的向量序列的对应向量。查询嵌入神经网络子系统132可以包括例如一个或多个前馈神经网络层、递归神经网络层或注意力神经网络层或这些的组合。在对查询的响应将是从可能的响应或回答的集合中的选择的情况下,查询输入序列120可以包括可能的响应或回答,例如,作为由查询嵌入神经网络子系统132生成的嵌入。
[0043]
与对象输入序列188类似,查询输入序列120的每个元素可以与元素在序列中的位置的编码组合,以表示元素的顺序,并因此表示词元的顺序。同样,可以使用任何合适的编码,例如,如前所述。
[0044]
在实施方式中,变换器神经网络子系统124在对象输入序列118和查询输入序列120之间共享,这促进表示查询的词元和对象的表示之间的信息流。在一些实施方式中,但不一定,输入序列122的每个元素可以包括用于指示元素是属于对象输入序列118还是属于查询输入序列120的标签。例如,标签可以是识别元素的模态(对象或查询)的独热向量。
[0045]
表示查询的词元序列134中的词元可以包括自然语言的词或词条(wordpiece),或者形式语言的词元。在实施方式中,查询可以但不需要包括当由查询嵌入神经网络子系统132处理时将成为概要词元元素的概要词元,例如伪词。
[0046]
视频处理系统100可以包括训练引擎140以训练系统,如稍后描述的。
[0047]
由注意力神经网络层应用的注意力机制可以是任何种类的注意力机制。通常,注意力机制将查询和键-值对集合映射到输出,其中查询、键和值都是向量。输出被计算为值的加权和,其中,分配给每个值的权重通过查询与对应键的兼容性函数——例如,点积或缩放点积——来计算。
[0048]
在实施方式中,注意力机制被配置为在注意力层输入上应用自注意力机制;这之后可以是一个或多个前馈神经网络层以生成注意力层输出。通常,注意力机制确定两个序列之间的关系;自注意力机制被配置为将相同序列中的不同位置相关联,以确定序列的经变换的版本作为输出。例如,注意力层输入可以包括用于输入序列的每个元素的向量。这些向量向自注意力机制提供输入,并且由自注意力机制使用以确定用于注意力层输出的相同序列的新表示,其类似地包括用于输入序列的每个元素的向量。自注意力机制的输出可以被用作注意力层输出,或者可以由一个或多个前馈层处理以提供注意力层输出。
[0049]
在一些实施方式中,注意力机制被配置为将例如由矩阵wq定义的查询变换、例如由矩阵wk定义的键变换和例如由矩阵wv定义的值变换中的每一个应用于输入序列x的每个元素的注意力层输入,以导出相应的查询向量q=xwq、键向量k=xwk和值向量v=xwv,其用于确定用于输出的关注序列。例如,注意力机制可以是通过将每个查询向量应用于每个键
向量以确定用于每个值向量的相应权重,然后使用相应权重组合值向量以确定用于输入序列的每个元素的注意力层输出而应用的点积注意力机制。可以通过缩放因子,例如,通过查询和键的维度的平方根,来缩放注意力层输出,以实现缩放的点积注意力。因此,例如,注意力机制的输出可以被确定为其中,d是键(和值)向量的维度。在另一实施方式中,注意力机制可以包括“附加注意力”机制,其使用具有隐藏层的前馈网络来计算兼容性函数。如前所述,注意力机制的输出可以由一个或多个全连接的前馈神经网络层进一步处理。
[0050]
注意力机制可以实现多头注意力,即它可以并行地应用多个不同的注意力机制。然后,如果需要,可以将这些的输出与应用于减少到原始维度的学习线性变换进行组合,例如,级联。
[0051]
变换器神经网络子系统的合适架构的示例在ashish vaswani等人的“attention is all you need”,advances in neural information processing systems,第5998-6008页,2017;arxiv:1810.04805devlin等(bert);和arxiv:1901.02860dai等(transformer-xi)中进行了描述。
[0052]
图2示出了视频处理系统100的示例架构;该示例还图示了系统的训练。
[0053]
在该示例中,视频帧序列110描绘了移动对象,并且对象分割子系统112包括如arxiv:1901.11390中所述的“monet”对象分割子系统。在一些其他示例实施方式中,对象分割子系统包括如arxiv:1903.00450中所述的“iodine”对象分割系统;如arxiv:1703.06870中所述的掩模r-cnn对象分割系统;如arxiv:1506.01497中所述的更快的r-cnn对象分割系统;或如arxiv:2005.12872中所述的检测变换器(detr)对象分割系统。这些中的一些具有以下优点:它们能够在无监督的情况下被训练,即没有对象标签。
[0054]
作为示例,“monet”对象分割子系统的输出是对象注意力掩膜集合,每个对象注意力掩膜针对每个图像像素定义像素属于对应对象的概率。掩模的像素被编码成具有d维均值μ
ti
的潜在变量,其中,i索引对象并且t索引经处理的视频帧。更具体地,monet生成潜在变量z
t
,q(z
t
|f
t
,a
ti
)的后验分布,其中,a
ti
是如前所述的对象分割掩膜,并且f
t
是w
×
h像素图像帧。后验分布q(
·
)是对角高斯分布,并且均值μ
ti
的d维向量提供第t个图像帧中的第i个对象的表示(嵌入),并且因此提供对象输入序列118的元素。在使用多头注意力的情况下,潜在变量的维度可以被线性地投影到可被头部数量整除的维度。
[0055]
变换器神经网络子系统124对对象输入序列118和概要词元元素202——在实施方式中为可训练向量——进行操作。在存在表示查询的词元序列的情况下,变换器神经网络子系统124还操作查询输入序列120,例如词嵌入序列,可选地包括针对对查询的可能响应集合中的每一个的一个或多个词元的嵌入。
[0056]
变换器神经网络子系统124生成输出序列126,输出序列126包括经变换的概要词元元素204,即概要词元元素202的经变换的版本。这通过输出子系统128,例如具有一个隐藏层的mlp(多层感知器),以生成响应130。响应130可以定义例如“是”、“否”和“未确定”的可能响应上的分类分布,或者更复杂的描述性响应上的分类分布;或者可以定义对象和/或对象的位置。
[0057]
在训练期间,可以利用预测神经网络206来增强视频处理系统100。预测神经网络
206允许系统通过预测从变换器神经网络子系统124的输入掩蔽的对象——更具体地,对象表示,即对象嵌入——来实现自监督学习。在实施方式中,预测神经网络206包括一个或多个线性层。
[0058]
预测神经网络206可以被配置为针对每个视频帧接收和处理来自变换器神经网络子系统124的输出序列126的元素。更具体地,对于视频帧中的多个对象中的每个对象,预测神经网络可以接收并处理与对象的(解耦)表示对应的输入序列的元素的变换版本,并生成对应的预测(解耦)表示208。然而,一些对象的对象表示被掩蔽,因此需要变换器神经网络子系统124学习预测所表示的对象的动态。下面进一步描述使用预测神经网络206训练视频处理系统100。
[0059]
在一个特定的示例实施方式中,每帧表示8个对象,每个对象作为具有16维度的向量,并且使用具有10个头和28个注意力神经网络层的变换器神经网络子系统124。然而,最佳超参数值通常将取决于应用。
[0060]
图3示出了使用视频处理系统100处理视频以生成对查询的响应的示例过程的流程图。
[0061]
该过程获得视频帧序列(300),并使用对象分割子系统112对其进行处理以生成对象分割输出114(302)。对象分割输出与帧位置编码组合以生成对象输入序列118(304)。
[0062]
该过程还获得概要词元,并且可选地前置表示查询的词元序列(306)。该过程使用查询嵌入神经网络子系统132生成词元序列的嵌入,并且在序列具有多于一个词元的情况下,添加词元的位置编码(308),以生成查询输入序列120。在变型中,在不使用查询嵌入神经网络子系统132的情况下获得查询输入序列120的概要词元元素。
[0063]
对象输入序列118和查询输入序列120被组合以获得输入序列122,并且这由变换器神经网络子系统124处理以获得包括经变换的概要词元元素204的输出序列126(310)。然后,由输出子系统128处理经变换的概要词元元素204,以生成对查询的可能响应集合的概率分布(312),并且根据概率分布确定对查询的响应(314)。例如,可以将对查询的响应确定为具有最大概率的响应;或者可以从概率分布采样响应。
[0064]
图4示出了用于训练视频处理系统100的示例过程的流程图。训练过程可以由训练引擎140实现。
[0065]
该过程使用训练示例,每个训练示例包括视频帧序列,可选地查询,其中,查询由输入到系统的词元序列134定义,以及对查询的正确响应。对于每个训练示例,如上所述处理视频帧序列和可选查询(400)以生成响应130。
[0066]
通常,使用常规的监督机器学习技术例如,基于反向传播来训练系统,特别是变换器神经网络子系统,以优化目标函数,该目标函数取决于视频处理系统输出与对训练示例的查询的正确响应之间的差异,即取决于视频处理系统输出是否正确。在实施方式中,预训练对象分割子系统。
[0067]
在实施方式中,根据通过处理来自训练示例的视频帧序列而生成的响应130与正确响应之间的差异来确定(402)分类损失。分类损失可以是例如平方(l2)损失或交叉熵损失。该过程通过反向传播分类损失的梯度来训练输出子系统128、变换器神经网络子系统124和(利用查询输入)查询嵌入神经网络子系统132(408)。梯度传播可以在对象分割子系统112处停止。训练可以使用lamb优化器(arxiv:1904.00962)。
[0068]
训练方法的一些实施方式还使用预测神经网络206确定辅助填充损失(404)。然后,训练方法可以包括例如通过掩蔽一个或多个对象表示来抑制对象分割输出中的一个或多个视频帧的一个或多个对象的表示。然后,该方法根据抑制的表示和预测的表示之间的差异的度量来确定填充损失,反向传播填充损失的梯度以调整变换器神经网络子系统124的参数,例如权重。这实现了可以使用不包括正确响应的训练示例来执行的进一步的自监督训练。在实施方式中,在利用填充损失的训练期间,梯度通过预测神经网络206和变换器神经网络子系统124传播,并且这些被训练,但是查询嵌入神经网络子系统不被训练。
[0069]
在特定示例中,第i个图像帧中的第i个对象由均值向量μ
ti
表示。应用掩模m
ti
∈{0,1}以获得由变换器神经网络子系统124变换为μ
′
ti
的视频帧m
ti
μ
ti
中的对象的掩蔽表示。然后训练变换器神经网络子系统124,使得可以使用根据下式确定的辅助填充损失,由μ
′
ti
预测掩蔽的对象表示:
[0070][0071]
其中,l(
·
)是损失函数,f(
·
)是由预测神经网络206应用的(学习的)线性映射,并且τ
ti
∈{0,1}是识别预测目标的独热指标变量,例如τ
ti
=1-m
ti
(尽管不一定仅识别被掩蔽的条目,因为预测目标可以是这些的子集)。损失函数l(
·
)可以是例如l2损失(f(μ
′
ti
)-μ
ti
)2或对比损失的形式,例如或其变体,其中,s在视频帧上运行。
[0072]
可以使用各种掩蔽方案,例如,在t和i上随机均匀设置m
ti
=1;约束这种掩蔽,使得每帧恰好掩蔽一个对象表示;在m
ti
=1的上下文与τ
ti
=1的填充目标之间添加一个或多个帧的缓冲器,其中,在缓冲区中,m
ti
=0和τ
ti
=0。总损失可以是由参数λ加权的辅助填充损失和分类损失的组合。在相同的训练过程期间,即在没有预训练步骤的情况下,可以最小化两个损失。
[0073]
在响应定义对象的位置的情况下,训练方法可以包括根据对查询的响应与对查询的正确响应之间的距离的度量——例如,根据对象的预测位置与实际位置之间的距离——来确定附加辅助损失(406)。总损失可以包括来自附加辅助损失的加权贡献。
[0074]
距离可以是物理距离或相似性的度量。例如,附加辅助损失可以是预测的网格位置或“单元”与实际网格位置或单元之间的l1距离。然后,训练方法可以包括反向传播附加辅助损失的梯度以调整变换器神经网络子系统124的参数。这能够在捕获视频帧的相机正在移动的情况下辅助对象跟踪。
[0075]
本说明书结合系统和计算机程序组件使用术语“被配置”。对于要被配置为执行特定操作或动作的一个或多个计算机的系统,是指系统已经在其上安装了软件、固件、硬件或它们的组合,这些软件、固件、硬件或它们的组合在操作中使系统执行操作或动作。对于要被配置为执行特定操作或动作的一个或多个计算机程序,是指一个或多个程序包括当由数据处理装置执行时使装置执行操作或动作的指令。
[0076]
本说明书中描述的主题和功能操作的实施例能够在数字电子电路中、在有形体现的计算机软件或固件中、在计算机硬件中实现,包括本说明书中公开的结构及其结构等价物,或者它们中的一个或多个的组合。本说明书中描述的主题的实施例能够被实现为一个或多个计算机程序,即,在有形非暂时性存储介质上编码的计算机程序指令的一个或多个
模块,以用于由数据处理装置执行或控制数据处理装置的操作。计算机存储介质能够是机器可读存储设备、机器可读存储基板、随机或串行存取存储器设备或它们中的一个或多个的组合。替代地或另外,程序指令能够被编码在人工生成的传播信号上,例如,机器生成的电、光或电磁信号,其被生成以对信息进行编码以传输到合适的接收器装置以供数据处理装置执行。
[0077]
术语“数据处理装置”是指数据处理硬件,并且涵盖用于处理数据的所有类型的装置、设备和机器,包括例如可编程处理器、计算机或多个处理器或计算机。该装置还能够是或进一步包括专用逻辑电路,例如,fpga(现场可编程门阵列)或asic(专用集成电路)。除了硬件之外,该装置还能够可选地包括为计算机程序创建执行环境的代码,例如,构成处理器固件、协议栈、数据库管理系统、操作系统或它们中的一个或多个的组合的代码。
[0078]
计算机程序,其也可以被称为或描述为程序、软件、软件应用、app、模块、软件模块、脚本或代码,能够用任何形式的编程语言编写,包括编译或解释语言,或者声明或过程语言;并且它能够以任何形式部署,包括作为独立程序或作为模块、组件、子例程或适合在计算环境中使用的其他单元。程序可以但不必对应于文件系统中的文件。程序能够被存储在保存其他程序或数据——例如,存储在标记语言文档中的一个或多个脚本——的文件的一部分中、存储在专用于所讨论的程序的单个文件中,或者存储在多个协调文件——例如,存储一个或多个模块、子程序或代码部分的文件——中。计算机程序能够被部署为在一个计算机上或在位于一个站点处或分布在多个站点上并通过数据通信网络互连的多个计算机上执行。
[0079]
在本说明书中,术语“数据库”广泛地用于指代任何数据集合:数据不需要以任何特定方式被结构化,或者根本不需要被结构化,并且它能够被存储在一个或多个位置中的存储设备上。因此,例如,索引数据库能够包括多个数据集合,每个数据集合可以被不同地组织和访问。
[0080]
类似地,在本说明书中,术语“引擎”广泛地指代被编程为执行一个或多个特定功能的基于软件的系统、子系统或过程。通常,引擎将被实现为安装在一个或多个位置中的一个或多个计算机上的一个或多个软件模块或组件。在一些情况下,一个或多个计算机将专用于特定引擎;在其他情况下,能够在相同的一个或多个计算机上安装和运行多个引擎。
[0081]
本说明书中描述的过程和逻辑流程能够由执行一个或多个计算机程序的一个或多个可编程计算机执行,以通过对输入数据进行操作并生成输出来执行功能。过程和逻辑流程也能够由专用逻辑电路——例如fpga或asic——执行,或由专用逻辑电路和一个或多个编程计算机的组合执行。
[0082]
适合于执行计算机程序的计算机能够基于通用或专用微处理器或两者,或者任何其他类型的中央处理单元。通常,中央处理单元将从只读存储器或随机存取存储器或两者接收指令和数据。计算机的元件是用于执行或运行指令的中央处理单元和用于存储指令和数据的一个或多个存储器设备。中央处理单元和存储器能够由专用逻辑电路补充或并入专用逻辑电路中。通常,计算机还将包括用于存储数据的一个或多个大容量存储设备——例如,磁盘、磁光盘或光盘,或者可操作地耦合以从该一个或多个大容量设备接收数据或将数据传送到该一个或多个大容量设备或两者。然而,计算机不必须具有这样的设备。此外,计算机能够被嵌入在另一设备——例如,移动电话、个人数字助理(pda)、移动音频或视频播
放器、游戏控制台、全球定位系统(gps)接收器或便携式存储设备,例如,通用串行总线(usb)闪存驱动器,仅举几例——中。
[0083]
适合于存储计算机程序指令和数据的计算机可读介质包括所有形式的非易失性存储器、介质和存储器设备,包括例如半导体存储器设备,例如,eprom、eeprom和闪存设备;磁盘,例如,内部硬盘或可移动磁盘;磁光盘;以及cd rom和dvd-rom盘。
[0084]
为了提供与用户的交互,能够在计算机上实现本说明书中描述的主题的实施例,该计算机具有用于向用户显示信息的显示设备,例如,crt(阴极射线管)或lcd(液晶显示器)监视器,以及用户能够用来向该计算机提供输入的键盘和定点设备,例如,鼠标或轨迹球。其它种类的设备也能够被用于提供与用户的交互;例如,提供给用户的反馈能够是任何形式的感觉反馈,例如,视觉反馈、听觉反馈或触觉反馈;并且能够以包括声、语音或触觉输入的任何形式接收来自用户的输入。另外,计算机能够通过向由用户使用的设备发送文档并从由用户使用的设备接收文档——例如,通过响应于从web浏览器接收到请求而向用户的设备上的web浏览器发送网页——来与用户交互。此外,计算机能够通过向个人设备——例如,正在运行消息传送应用的智能电话——发送文本消息或其他形式的消息并且继而从用户接收响应消息来与用户交互。
[0085]
用于实现机器学习模型的数据处理装置还能够包括,例如,专用硬件加速器单元,其用于处理机器学习训练或生产的公用和计算密集型部分,即推断、工作负载。
[0086]
能够使用机器学习框架,例如,tensorflow框架来实现和部署机器学习模型。
[0087]
本说明书中描述的主题的实施例能够在计算系统中实现,该计算系统包括后端组件,例如,作为数据服务器;或者包括中间件组件,例如,应用服务器;或者包括前端组件,例如,具有用户能够通过其与本说明书中描述的主题的实施方式交互的图形用户界面、web浏览器或app的客户端计算机;或者包括一个或多个这样的后端、中间件或前端组件的任何组合。系统的组件能够通过任何形式或介质的数字数据通信——例如通信网络——互连。通信网络的示例包括局域网(“lan”)和广域网(“wan”),例如,互联网。
[0088]
计算系统能够包括客户端和服务器。客户端和服务器通常彼此远离并通常通过通信网络交互。客户端和服务器的关系借助于在相应的计算机上运行并且彼此具有客户端-服务器关系的计算机程序而产生。在一些实施例中,服务器将数据(例如,html页面)传输到用户设备,例如,用于向与充当客户端的设备交互的用户显示数据和从其接收用户输入的目的。能够在服务器处从设备接收在用户设备处生成的数据,例如,用户交互的结果。
[0089]
虽然本说明书包含许多具体实施方式细节,但是这些不应当被解释为对任何发明的范围或可以要求保护的范围的限制,而是应当解释为可以特定于特定发明的具体实施例的特征的描述。在本说明书中在分开实施例的上下文中描述的某些特征也可以在单个实施例中组合实现。相反,在单个实施例的上下文中描述的各种特征也可以分开地或以任何合适的子组合在多个实施例中实现。此外,尽管特征在上文可以被描述为以某些组合起作用并且甚至最初如此要求保护,但是来自所要求保护的组合的一个或多个特征在一些情况下能够从组合中删除,并且所要求保护的组合可以涉及子组合或子组合的变型。
[0090]
类似地,虽然以特定顺序在附图中描绘了并且在权利要求中记载了操作,但是这不应当被理解为要求以所示的特定顺序或依次顺序执行这些操作,或者执行所有示出的操作,以实现期望的结果。在某些情况下,多任务和并行处理可能是有利的。此外,上述实施例
中的各种系统模块和组件的分开不应当被理解为在所有实施例中都需要这种分开,并且应当理解到,所描述的程序组件和系统通常能够被一起集成在单个软件产品中或封装到多个软件产品中。
[0091]
已经描述了主题的特定实施例。其它实施例在以下权利要求书的范围内。例如,权利要求中记载的动作能够以不同的顺序执行,并且仍然实现期望的结果。作为一个示例,附图中描绘的过程不必然需要所示的特定顺序或依次顺序来实现期望的结果。在一些情况下,多任务和并行处理可能是有利的。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。