基于车联网实车数据和svm的驾驶风格辨识模型建模与统计方法
技术领域
1.本发明属于智能网联汽车数据分析技术领域,特别涉及一种基于车联网实车数据和svm的驾驶风格辨识模型建模与统计方法。
背景技术:
2.随着国内各大车企对智能网联汽车技术不断发展,企业车联网数据也正在爆发式增长,如何利用用户车联网信息来挖掘出有价值的信息,对于提高企业车辆产品更新换代、用户安全出行行为以及用户对于车辆的驾驶体验有重要的意义。
3.驾驶风格是指驾驶员操纵车辆时所表现出的相对稳定的行为特性,是一种驾驶行为方面表现出的相对稳定状态,在驾驶人群之间存在差异,并且反映了驾驶人有意识的选择。经统计分析表明激进型驾驶风格驾驶员驾驶车辆的速度标准差最大,车速波动较明显,并且其减速度、加速度的最大值最高,加速度、减速度数值变动较保守型和普通型相比较为明显,存在急加速、急减速的情况。若驾驶员长时间以激进型驾驶风格在道路行驶,其道路交通事故发生概率相较于普通型和保守型较大。车企与车队管理者能够定期的分析驾驶员所处于的驾驶风格,对各个汽车厂家在使用空中下载技术(ota)进行产品功能升级或内测名单筛选时可以作为驾驶员参考因素,同时通过研究驾驶员驾驶风格,有利于设计车辆个性化控制策略,制定不同驾驶风格所对应的控制策略实现驾驶员功能要求,实现由“人适应车”向“车适应人”转变,例如在电动助力转向、线控制动、车道保持辅助(lka)、自适应巡航(acc)、自动换道、自动紧急制动控制、混合动力汽车能量管理、电池soc预估等方面,以满足不同类型驾驶人的驾驶体验和感受,提升驾驶舒适性。
4.因此,在汽车远程监控管理系统的功能开发和车辆控制器控制策略设计过程中,对驾驶员行车数据中进行风格类型判别与类型统计,将驾驶员驾驶风格这一信息引入到监控管理系统和车辆控制策略中,来提高车辆行驶安全性和制定个性化车辆控制系统是一个亟待解决的问题。为此,提出一种基于svm的驾驶员驾驶风格识别方法,显得尤为重要。
5.公开于该背景技术部分的信息仅仅旨在增加对本发明的总体背景的理解,而不应当被视为承认或以任何形式暗示该信息构成已为本领域一般技术人员所公知的现有技术。
技术实现要素:
6.本发明的目的在于提供一种基于车联网实车数据和svm的驾驶风格辨识模型建模与统计方法,从而克服上述现有技术中的缺陷。
7.为实现上述目的,本发明提供了一种基于车联网实车数据和svm的驾驶风格辨识模型建模与统计方法,方法具体包括如下步骤:
8.s1从企业车联网服务云平台数据库中获取车辆具体某一天24小时有效行车历史数据,所述行车历史数据为现有车辆网车载的硬件设备能够采集到的数据信息,包括数据采集时间、车速、累计里程、经度、纬度、大气压力、发动机信息、电机信息、电池信息,必须采
集的主要所需为数据采集时间、车辆行驶车速这两种;
9.s2对所述历史行驶数据进行处理,形成适用svm分类算法模型的车辆行驶数据样本;
10.s3支持向量机(svm)分类识别模型训练数据集准备,使用依维柯现有车型采集某一地区道路的循环工况数据,经处理形成适用于无监督学习算法初始数据集;
11.s4初始数据集经无监督学习算法学习后,分析确定出初始数据集中各样本数据驾驶风格类型标签,形成分类识别模型训练数据集;
12.s5利用带有驾驶风格类别标签的数据集训练svm分类识别模型,对模型的超参数进行调整,调整后的模型预测准确率达到最优;
13.s6利用训练好的支持向量机svm驾驶风格识别模型对车辆行驶数据样本进行识别,并对当天的驾驶风格类型进行统计。
14.优选地,上述技术方案中,步骤s2历史行驶数据进行处理步骤包括:
15.s2.1将步骤(1)获取的数据表示为data=[t veh_v],其中车辆数据采集时间t=[t
1 t2ꢀ…ꢀ
tn],采集频率为1hz采集一次车辆状态信息;车辆运行状态信息:行驶车速veh_v=[v
1 v2ꢀ…ꢀ
vn];
[0016]
s2.2待识别行驶数据data分块处理,将行驶数据data从第一个速度不为0的时间点开始以固定行驶时间t进行窗口化划分,得到行驶数据工况块;
[0017]
s2.3对每一个工况块的速度信息差值求取加速度信息;
[0018]
s2.4计算各工况块的特征参数信息,所述特征参数信息为9种,包括速度标准差、平均加速度、最大加速度、平均减速度、最大减速度、加速度标准差、减速度标准差、加速时间比例、减速时间比例,均是围绕着速度、加速度衍生出来的特征变量;
[0019]
s2.5所述的特征参数信息计算公式:
[0020]
速度标准差:
[0021]
平均加速度:
[0022]
最大加速度:a
max
=max(a1,a2,a3,a4,...,an);
[0023]
平均减速度:
[0024]
最大减速度:d
max
=max(d1,d2,d3,d4,...,dn);
[0025]
加速度标准差:
[0026]
减速度标准差:
[0027]
加速时间比例:
[0028]
减速时间比例:
[0029]
s2.6所有的工况块对(2.5)中9种特征参数进行计算,然后表示为:
[0030]
pre_data=[v
m a
av a
max d
av d
max a
m d
m a
p d
p
]。
[0031]
优选地,上述技术方案中,步骤s3中svm分类模型训练数据准备步骤包括:
[0032]
s3.1采集某一区域道路工况数据作为初始模型训练数据,车辆设备采集频率为1hz;
[0033]
s3.2所述的某一区域道路为具有某一地形趋势的区域,以及车辆实际生产过程中长期行驶的区域,经采集得到数据;
[0034]
s3.3将模型训练数据进行步骤(2)窗口化处理,并进一步进行复合划分,增加数据集样本数目,以及降低训练数据的事件偶然性、随机性,得到训练数据data
training
;
[0035]
s3.4无监督学习,获取训练样本的真实标签,对训练样本进行归一化处理,计算公式为:
[0036]
s3.5经步骤(3.4)归一化处理后的数据进行数据降维,选用合适的将为方法对数据进行数据将为,降低模型的研究复杂度,在这里选用主成分分析方法进行数据降维,获取降维数据data
dimensionality reduction
;
[0037]
s3.6降维数据进行聚类分析,找出数据中的类别标签,结合日常驾驶经验和习惯,将驾驶风格划分为三类,即激进型、普通型、保守型三种驾驶风格,综合考虑数据样本以及分类任务,采用k-means 聚类算法进行聚类分析,初始聚类类别为三种,得到每个数据样本的真实标签,将数据标签返回到步骤s3.3训练数据data
training
中,至此训练数据中每条样本对应一条驾驶风格标签。
[0038]
优选地,上述技术方案中,步骤s4分析训练数据集中驾驶风格类型标签步骤包括:
[0039]
s4.1经步骤s3.6聚类分析后标签返回到训练数据data
training
中,以返回数据标签进行分类,对每一类数据中9种特征参数分别求取平均值,作为最终每一类的聚类中心;
[0040]
s4.2对三个聚类中心数据进行分析比较,通过分析比较对各数据标签赋予相对应的类型。
[0041]
优选地,上述技术方案中,步骤s5中svm分类识别模型训练包括:
[0042]
s5.1对data
training
数据集进行划分,其中数据集中的80%数据样本作为训练集,20%数据样本的作为验证集;
[0043]
s5.2利用训练集对svm机器学习模型进行训练学习,使用python3语言调用sklearn库,使用sklearn.svm模块进行模型训练,由于存在三种驾驶风格涉及多分类,需要采用一对多模式(one ve rest),即decisionfunctionshape='ovr',采用三个svm机器学习模型进行识别,最终识别结果根据每一个svm机器学习模型结果进行决策,评价方法以mse均方误差作为标准;
[0044]
s5.3进一步采用网格搜索和三折交叉验证等方法对svm超参数调整,所需要调整的参数有目标函数的惩罚系数c,核函数kernel,核函数的系数gamma;
[0045]
s5.4经参数调整后,最优模型参数为:{'c':1.793,'kernel':'linear'},模型训练准确率为97.1%,验证集验证准确率为98.2%,验证准确率高于训练训练准确率,可以认为具有较强的泛化能力,因此具有较高准确率,泛化能力强。
[0046]
优选地,上述技术方案中,步骤s6中,svm驾驶风格识别模型应用步骤包括:
[0047]
s6.1获取步骤s2中pre_data数据,利用所训练好的svm驾驶风格识别模型进行识别,返回数据标签;
[0048]
s6.2返回的数据标签映射为相对应的驾驶风格类型,对驾驶风格类型进行统计分析,获取各类型占比数据,通过类型占比可以看出驾驶员在一段时间倾向于某一种驾驶风格类型。
[0049]
与现有技术相比,本发明具有如下有益效果:
[0050]
本发明通过对车辆用户的行车数据进行分析,定期的识别与统计用户驾驶风格,为实现对用户驾驶行为安全性分析、车辆功能升级与内测、个性化控制策略提供数据作为参考,充分利用现有车载设备t-box、车联网云平台和数据库、车载控制器等条件,通过一套识别及统计方法,即可实现对接入到企业车联网云平台内的所有车辆的驾驶员驾驶风格识别与统计,该方法简单高效,易实施,所训练的模型具有较强的泛化能力,可在多种平台下进行部署应用,利于实际生产应用。
附图说明
[0051]
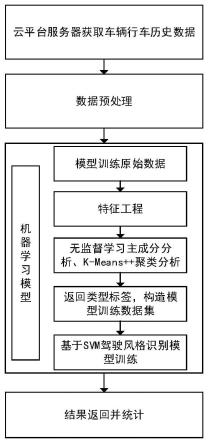
图1是本发明所叙述基于svm的驾驶员驾驶风格识别与统计方法流程图;
[0052]
图2是本发明所叙述历史行驶数据进行处理流程图;
[0053]
图3是本发明所叙述训练数据集工况块复合划分原理图;
[0054]
图4是本发明所叙述训练数据集驾驶风格类型标签分析流程图;
[0055]
图5是本发明所叙述pca主成分分析贡献率以及累积贡献率图;
[0056]
图6是本发明所叙述sse随聚类类别k变化曲线图;
[0057]
图7是本发明所叙述k=3时轮廓系数阴影面积与平均轮廓系数图;
[0058]
图8是本发明所叙述聚类中心数值分析结果图;
[0059]
图9是本发明所叙述svm分类模型训练流程图;
[0060]
图10是本发明所叙述驾驶风格识别记录及统计流程图;
[0061]
图11是本发明所叙述示例样本驾驶风格识别结果;
[0062]
图12是本发明所叙述示例样本各类型驾驶风格占比。
具体实施方式
[0063]
下面对本发明的具体实施方式进行详细描述,但应当理解本发明的保护范围并不受具体实施方式的限制。
[0064]
除非另有其它明确表示,否则在整个说明书和权利要求书中,术语“包括”或其变换如“包含”或“包括有”等等将被理解为包括所陈述的元件或组成部分,而并未排除其它元件或其它组成部分。
[0065]
如图1所示,基于svm的驾驶员驾驶风格识别与统计方法,所述方法具体包括如下步骤:
[0066]
(1)从企业车联网服务云平台数据库中获取车辆具体某一天24小时有效行车历史数据,所述的行车历史数据包括数据采集时间、车辆行驶车速、经纬度位置信息;
[0067]
(2)对所述历史行驶数据进行处理,形成适用svm分类算法模型的车辆行驶数据样本;
[0068]
(3)支持向量机(svm)分类识别模型训练数据集准备,通过采集某一地区道路或者采用车辆标准行驶循环工况数据,经处理形成适用于无监督学习算法初始数据集;
[0069]
(4)初始数据集无监督学习算法学习后,分析确定出初始数据集中各样本数据驾驶风格类型标签,形成分类识别模型训练数据集;
[0070]
(5)利用带有驾驶风格类别标签的数据集训练svm分类识别模型,经超参数调整后,准确率达到最优;
[0071]
(6)利用训练好的支持向量机(svm)驾驶风格识别模型对车辆行驶数据样本进行识别,并对当天的驾驶风格类型进行统计。
[0072]
如图2所示,所述步骤(2)历史行驶数据进行处理步骤包括:
[0073]
(2.1)将步骤(1)获取的数据表示为data=[t veh_v],其中车辆数据采集时间t=[t
1 t2ꢀ…ꢀ
tn],间隔时间1s采集一次车辆状态信息;
[0074]
车辆运行状态信息:行驶车速veh_v=[v
1 v2ꢀ…ꢀ
vn];
[0075]
(2.2)待识别行驶数据data分块处理,将行驶数据data从第一个速度不为0的时间点开始以固定行驶时间t进行窗口化划分,得到行驶数据工况块;
[0076]
(2.3)对每一个工况块的速度信息差值求取加速度信息;
[0077]
(2.4)计算各工况块的特征参数信息,包括速度标准差、平均加速度、最大加速度、平均减速度、最大减速度、加速度标准差、减速度标准差、加速时间比例、减速时间比例;
[0078]
(2.5)所述的特征参数信息计算公式:
[0079]
速度标准差:
[0080]
平均加速度:
[0081]
最大加速度:a
max
=max(a1,a2,a3,a4,...,an);
[0082]
平均减速度:
[0083]
最大减速度:d
max
=max(d1,d2,d3,d4,...,dn);
[0084]
加速度标准差:
[0085]
减速度标准差:
[0086]
加速时间比例:
[0087]
减速时间比例:
[0088]
(2.6)所有的工况块对(2.5)中9种特征参数进行计算,然后表示为:
[0089]
pre_data=[v
m a
av a
max d
av d
max a
m d
m a
p d
p
]。
[0090]
如图4所示,所述步骤(3)svm分类模型训练数据准备步骤包括:
[0091]
(3.1)采集某一区域道路工况数据作为初始模型训练数据,车辆设备采集频率为1hz;
[0092]
(3.2)所述的某一区域道路为具有某一地形趋势的区域,以及车辆实际生产过程中长期行驶的区域,经采集得到数据;
[0093]
(3.3)将模型训练数据进行步骤(2)窗口化处理,如图3所示,进行复合划分,增加数据集样本数目,以及降低训练数据的事件偶然性、随机性,得到训练数据data
training
;
[0094]
(3.4)无监督学习,获取训练样本的真实标签,对训练样本进行归一化处理,计算公式为:
[0095][0096]
(3.5)经步骤(3.4)归一化处理后的数据进行数据降维,选用合适的将为方法对数据进行数据将为,降低模型的研究复杂度,在这里选用主成分分析(pca)方法进行数据降维,如图5所示,一般可以认为累积贡献率大于85%前n个主成分即可表达出初始数据集所代表信息,为此,在这里选取累积贡献率大于85%的前四个主成分代表初始训练数据,得到降维数据data
dimensionality reduction
;
[0097]
(3.6)降维数据进行聚类分析,找出数据中的类别标签,如图6和7所示,根据sse和聚类轮廓系数曲线,可以看出当聚类类别k=3时,sse曲线出现拐点,利用肘部法则,k=3为最佳聚类类别数,并且针对每一类别的轮廓系数面积阴影均超过样本平均轮廓系数虚线,故聚类个数合理的,结合日常驾驶经验和习惯,将驾驶风格划分为三类,即激进型、普通型、保守型三种驾驶风格,综合考虑数据样本以及分类任务,采用k-means 聚类算法进行聚类分析,初始聚类类别为三种,得到每个数据样本的真实标签,将数据标签返回到步骤(3.3)训练数据data
training
中,至此训练数据中每条样本对应一条驾驶风格标签。
[0098]
如图4所示,所述步骤(4)分析训练数据集中驾驶风格类型标签步骤包括:
[0099]
(4.1)经步骤(3.7)聚类分析后标签返回到训练数据data
training
中,以返回数据标签进行分类,对每一类数据中9种特征参数求取平均值,作为最终聚类中心,如图8所示,所得到的聚类中心对各特征参数数值分析后,映射相应的驾驶风格类型标签,对于激进型驾驶员器速度标准差为18.883是其余两种类型中最大的,并且其最大加速度、最大减速度、平均加速度、平均减速度、最大减速度等参数相较于其余两种均为最大,保守型与之相反,普通型介于两者之间;
[0100]
(4.2)对三个聚类中心数据进行分析比较,通过分析比较对各数据标签赋予相对应的类型。
[0101]
如图9所示,所述步骤(5)svm分类识别模型训练包括:
[0102]
(5.1)对data
training
数据集进行划分,其中数据集中的80%数据样本作为训练集,20%数据样本的作为验证集;
[0103]
(5.2)利用训练集对svm机器学习模型进行训练学习,使用python3语言调用sklearn库,使用sklearn.svm模块进行模型训练,由于存在三种驾驶风格涉及多分类,需要采用一对多模式(one ve rest),即decisionfunctionshape='ovr',采用三个svm机器学习模型进行识别,最终识别结果根据每一个svm机器学习模型结果进行决策,评价方法以mse均方误差作为标准;
[0104]
(5.3)进一步采用网格搜索和三折交叉验证等方法对svm超参数调整,所需要调整的参数有目标函数的惩罚系数c,核函数kernel,核函数的系数gamma。
[0105]
(5.4)经参数调整后,最优模型参数为:{'c':1.793,'kernel':'linear'},模型训练准确率为97.1%,预测准确率为98.2%,具有较高准确率,泛化能力强。
[0106]
如图10所示,svm驾驶风格识别模型应用步骤包括:
[0107]
(6.1)获取步骤(2)中pre_data数据,利用所训练好的svm驾驶风格识别模型进行识别,返回数据标签,如图11所示标签返回结果示例;
[0108]
(6.2)返回的数据标签映射为相对应的驾驶风格类型,对驾驶风格类型进行统计分析,获取各类型占比数据,如图12所示各类型占比示例,通过类型占比可以看出驾驶员在一段时间倾向于某一种驾驶风格类型。
[0109]
在具体生产部署应用时,本发明可以运行在用户终端或云平台服务器中,应用部署较为灵活,可应用于多种服务框架种作为一种简单高效的分析识别方法工具,通过调用企业内部车联网服务云平台数据库或车辆终端实时进行实时分析识别,并将识别结果传递给车联网远程监控服务云平台或车辆控制器,实现对驾驶员驾驶风格分析与追踪,保障驾驶员行车安全性,或作为关键信息执行个性化控制策略,来提升驾驶员驾驶体验感。
[0110]
总体来说,本发明提供了一种简单高效泛化能力强并且易实施的算法识别模型,利用企业大量实际车辆行驶数据进行数据分析,从大量用户行车数据中获取驾驶员在驾驶车辆时的状态信息,探寻驾驶员在驾驶车辆过程中表现出的行为规律,以便后续结合数据挖掘、机器学习、深度学习等技术对驾驶员驾驶行为综合评价系统开发,对于识别出的不良风格和具有不驾驶行为的驾驶员可针对性制定安全教育推荐项目、匹配相对应的ubi车险方案等风险管理措施,同时根据不同驾驶风格需求对车辆功能进行个性化控制系统开发,来满足不同驾驶员需求,优化车辆驾驶体验感。
[0111]
上述具体实施方式用来解释本发明,而不是对本发明进行限制,在本发明精神和权力范围内,对本发明做出的任何修改和改变,都在本发明的保护范围之内。
[0112]
前述对本发明的具体示例性实施方案的描述是为了说明和例证的目的。这些描述并非想将本发明限定为所公开的精确形式,并且很显然,根据上述教导,可以进行很多改变和变化。对示例性实施例进行选择和描述的目的在于解释本发明的特定原理及其实际应用,从而使得本领域的技术人员能够实现并利用本发明的各种不同的示例性实施方案以及各种不同的选择和改变。本发明的范围意在由权利要求书及其等同形式所限定。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。