1.本发明涉及用于控制扬声器的数字信号处理,并且更具体地,涉及一种用于控制稀疏扬声器阵列以递送空间化声音的信号处理方法。
背景技术:
2.出于各种目的,每个参考文献、专利、专利申请或其他具体识别的信息都通过引用明确地整体并入本文。
3.空间化声音对于一系列应用(包含虚拟现实、增强现实和修改现实)是有用的。此类系统通常由音频和视频装置组成,它们提供三维感知虚拟音频和视觉对象。创建此类系统的一个挑战是如何为不稳定的收听者更新音频信号处理方案,以便收听者感知预期的声音图像,尤其是使用稀疏换能器阵列。
4.试图给收听者空间感的声音再现系统试图使收听者感觉到声音来自可能不存在真实声源的位置。例如,当收听者坐在一个良好的双通道立体声系统前的“最佳位置”时,就有可能在两个扬声器之间呈现一个虚拟的声场。如果将两个相同的信号传递到面向收听者的两个扬声器,收听者应感觉到声音来自他或她正前方的位置。如果增加其中一个扬声器的输入,虚拟声源将偏向扬声器。此原理被称为幅度立体声,自从双通道立体声格式首次推出以来,它一直是用于混合双通道素材最常用的技术。
5.然而,幅度立体声本身不能在两个扬声器所跨越的角度之外创建准确的虚拟图像。事实上,即使在两个扬声器之间,幅度立体声也仅在扬声器所跨越的角度为60度或更小时才能正常工作。
6.虚拟源成像系统的工作原理是优化收听者耳朵处的声波(幅度、相位、延迟)。真实的声源在收听者的耳朵上生成一定的耳间时间差和电平差,收听觉系统利用这些时间差和电平差来定位声源。例如,收听者左侧的声源在左耳比在右耳更响,并且到达得更早。虚拟源成像系统被设计成准确地再现这些线索。在实践中,扬声器被用来在收听者的耳朵周围的区域中再现一组期望的信号。扬声器的输入由期望信号的特征确定,并且期望信号必须由虚拟声源发射的声音的特征确定。因此,声音定位的典型方法是确定表示收听者的双耳感知的头部相关传递函数(hrtf),以及收听者头部的影响,并且将hrtf和声音处理和传递链反演到头部,以产生优化的“期望信号”。将双耳感知限定为空间化声音,可以优化声发射以产生声音。例如,然后hrtf模拟耳朵的耳廓。barreto、armando、和navarun gupta.“用于音频空间化的耳廓动态建模”。wseas声学与音乐汇刊1,第1号(2004):77-82。
7.典型地,单组换能器仅最佳地为单个头部递送声音,并且寻求为多个收听者进行优化需要非常高阶的消除,使得打算给一个收听者的声音在另一个收听者处被有效地消除。在消声室之外,准确的多用户空间化是困难的,除非采用耳机。
8.双耳技术通常用于虚拟声音图像的再现。双耳技术基于这种原理:如果声音再现系统能够在收听者的耳膜处生成与真实声源产生的声压相同的声压,那么收听者将不能辨别虚拟图像和真实声源之间的差异。
9.例如,典型的离散环绕声系统假设特定的扬声器设置来生成最佳听音点,其中听觉成像是稳定和强健的。然而,并且不是所有的区域都能适应此类系统的适当规格,这进一步最小化了已经小的最佳点。为了在扬声器上实现双耳技术,有必要消除串扰,串扰会阻止用于一只耳朵的信号被另一只耳朵听到。然而,此类通常由时不变滤波器实现的串扰消除仅适用于特定的收听位置,并且声场只能被控制在最佳位置。
10.数字声音投影仪是换能器或扬声器阵列,其被控制使得音频输入信号以受控的方式在阵列前方的空间内发射。通常,声音以波束的形式发射,导向阵列前方半空间内的任意方向。通过使用精心选择的来自房间特点的反射路径,收听者将会感觉到由阵列发射的声音波束,就好像源自其最后一次反射的位置。如果最后的反射发生在后方的角落,收听者会感觉到声音好像是从他或她身后的声源发射的。然而,人类的感知也涉及回声处理,使得二次和更高的反射应与收听者习惯的环境有物理对应,否则收听者可能感觉到失真。
11.因此,如果一个人在一个长方形的房间里寻找声音来自于收听者的左前方的感觉,收听者将会期望来自后面的稍微延迟的回声,以及来自另一个面墙的进一步的二阶反射,每一个都被反射表面的特性在声学上着色。
12.数字声音投影仪的一个应用是取代常规的分立环绕声系统,常规的离散环绕声系统通常采用放置在收听者位置周围不同位置的若干分离的扬声器。数字声音投影仪通过为环绕声音频信号的每个通道生成波束,并且将声音波束导向适当的方向,在收听者的位置创建真正的环绕声,而不需要其他的扬声器或另外的布线。hooley等人的美国专利公开第2009/0161880号中描述了一种此类系统,其公开内容通过引用并入本文。
13.串扰消除在某种意义上是最终的声音再现问题,因为高效的串扰消除器在多个“目标”位置给出了对声场的完全控制。串扰消除器的目的是在单个目标位置再现期望的信号,同时在所有其余的目标位置完美地消除声音。仅使用两个扬声器和两个目标位置来消除串扰的基本原理已经为人所知30多年了。atal和schroeder的u.s.3,236,949(1966)使用物理推理来确定串扰消除器如何工作,串扰消除器包括对称地放置在单个收听者前方的仅两个扬声器。为了仅在左耳再现短脉冲,左扬声器首先发射正脉冲。此脉冲必须在右耳被右扬声器发射的稍弱的负脉冲抵消。然后,此负脉冲必须在左耳被由左扬声器发射的另一个更弱的正脉冲抵消,以此类推。atal和schroeder的模型假设自由场条件。收听者的躯干、头部和外耳对传入声波的影响被忽略。
14.为了控制双耳信号或“目标”信号的递送,有必要知道收听者的躯干、头部和耳廓(外耳)如何根据声源的位置来修改传入的声波。可以通过对“仿真头”或人类对象进行测量来获得此信息。此类测量的结果被称为“头部相关传递函数”,或hrtf。
15.收听者之间的hrtf差异显著,尤其是在高频时。收听者之间hrtf的大统计变化是耳机上虚拟源成像的主要问题中的一个。耳机可以很好地控制再现的声音。没有“串扰”(声音不会环绕头部到达对侧耳朵),声学环境不会修改再现的声音(房间反射不会干扰直接声音)。然而,不幸的是,当耳机被用于再现时,虚拟图像通常被感觉太靠近头部,有时甚至在头部内部。当试图将虚拟图像直接放在收听者面前时,此现象尤其难以避免。似乎不仅需要补偿收听者自己的hrtf,还需要补偿用于再现的耳机的响应。此外,整个声场会随着收听者的头部移动(除非使用头部跟踪和声场重新合成,并且这需要大量的另外的处理能力)。另一个方面,使用线性换能器阵列的空间化扬声器再现提供自然的收听条件,但是需要补偿
串扰,并且还需要考虑来自声学环境的反射。
16.comhear mybeam
tm
线性阵列在线性阵列中的相同、等距、独立供电且相位完全对准的扬声器元件上采用数字信号处理(dsp),以产生相长和相消干涉。见,u.s.9,578,440。扬声器意图被放置在平行于收听者的耳间轴线的线性阵列中,在收听者的前方。
17.波束成形或空间滤波是传感器阵列中用于定向信号发射或接收的信号处理技术。这是通过组合天线阵列中的元件来实现的,以此类方式,特定角度的信号经历相长干涉,而其他信号经历相消干涉。为了实现空间选择性,可以在发射端和接收端两者都使用波束成形。与全向接收/发射相比的改善被称为阵列的方向性。自适应波束成形用于借助于最佳(例如,最小平方)空间滤波和干扰抑制来检测和估计传感器阵列输出端的感兴趣信号。
18.mybeam扬声器是有源的——它含有自己的放大器和i/o,可以被配置为包含环境监测以自动调整音量,并且可以根据收听者的距离调整其波束成形焦点,并且以几种不同的模式操作,包含双耳(跨耳)、针对语音和隐私优化的单波束成形、近场覆盖、远场覆盖、多个收听者等。在近场或远场覆盖的双耳模式下,mybeam可渲染出异常清晰的普通pcm立体声音乐或视频信号(压缩或未压缩的信号源)、非常宽广和细致的声场、出色的动态范围,并且传达出强烈的环绕感(扬声器的图像音乐性部分源于扬声器阵列的采样准确相位校准)。扬声器以高达96k的采样率和24位精度运行,以卓越的保真度再现高分辨率和高清音频。当再现双耳处理内容的pcm立体声信号时,高分辨率的3d音频成像很容易被感知。高度信息以及正面180度图像都得到了很好的渲染,并且对于一些源实现了后方成像。参考形式因子包含12个扬声器、10个扬声器和8个扬声器版本,宽度约为8至22英寸。
19.u.s.5,862,227公开了一种空间化声音再现系统。此系统采用z域滤波器,并且优化滤波器h1(z)和h2(z)的系数,以便最小化给出为的成本函数其中e[
·
]是期望算子,em(n)表示期望信号和磁头附近位置的再现信号之间的误差。成本函数还可以具有惩罚滤波器h1(z)和h2(z)中使用的滤波器系数的平方幅度之和的项,以便改善反演问题的条件。
[0020]
在u.s.6,307,941中公开了另一个空间化声音再现系统。示例性实施例可以使用(i)fir和/或iir滤波器(数字的或模拟的)和(ii)空间移位信号(例如,系数)的任意组合,空间移位信号是使用以下方法中的任意一种生成的:原始脉冲响应采集;平衡模型降阶;汉克尔范数建模;最小二乘建模;修改或未修改的prony方法;最小相位重构;迭代预滤波;或临界带平滑。
[0021]
u.s.9,215,544涉及用于在两个扬声器上对双耳再现进行多通道编码的声音空间化。来自多个通道的求和过程用于限定左和右扬声器信号。
[0022]
u.s.7,164,768提供一种定向通道音频信号处理器。
[0023]
u.s.8,050,433提供了一种在立体声生成系统中消除双通道扬声器和收听者的双耳之间串扰的设备和方法。
[0024]
u.s.9,197,977和9,154,896涉及一种用于处理音频信号以创建“4d”空间化声音的方法和设备,其使用两个或更多个扬声器,具有多次反射建模。
[0025]
iso/iecfcd23003-2:200x,空间音频对象编码(saoc),移动图像和音频的编码,iso/iecjtc1/sc29/wg11n10843,2009年7月,英国伦敦,讨论了来自mpeg音频格式的音频流的立体声下混转码。代码转换分两步完成:在一步中,根据渲染矩阵的信息,来自saoc比特
流的对象参数(old、nrg、ioc、dmg、dcld)被代码转换成mpeg环绕比特流的空间参数(cld、icc、cpc、adg)。在第二步中,根据从对象参数和渲染矩阵导出的参数来修改对象下混,以形成新的下混信号。
[0026]
信号和参数的计算是按每个处理带m和参数时隙l进行的。代码转换器的输入信号是立体声下混,表示为
[0027]
代码转换器中可用的数据是协方差矩阵e、渲染矩阵m
ren
和下混矩阵d。协方差矩阵e是原始信号矩阵乘以其复共轭转置的近似值,ss
*
≈e,其中s=s
n,k
。矩阵的元素e是从对象old和ioc获得的,其中和渲染矩阵m
ren
的大小6
×
n通过矩阵乘法y=y
n,k
=m
ren
s确定音频对象s的目标渲染。下混权重矩阵d的大小2
×
n通过矩阵乘法x=ds以具有两行的矩阵的形式确定下混信号。
[0028]
矩阵的元素d
ij
(i=1,2;j=0...n-1)从去量化的dcld和dmg参数中获得,
[0029]
其中dmgj=d
dmg
(j,l)和dcldj=d
dcld
(j,l)。
[0030]
代码转换器根据渲染矩阵m
ren
所描述的目标渲染来确定mpeg环绕解码器的参数。六通道目标协方差用表示f并且由给出。代码转换过程在概念上可以分为两个部分。在一个部分中,对左、右和中心通道进行三通道渲染。在此阶段,获得用于下混修改的参数以及用于mps解码器的ttt盒的预测参数。在另一个部分中,确定用于前通道和环绕通道之间渲染的cld和icc参数(ott参数,左前-左环绕,右前-右环绕)。确定空间参数来控制对由前和环绕信号组成的左通道和右通道的渲染。这些参数描述了用于mps解码c
ttt
的ttt盒的预测矩阵(用于mps解码器的cpc参数)和下混转换器矩阵g。c
ttt
是从修改的下混获得目标渲染的预测矩阵a3是大小3
×
n减小的渲染矩阵,相应地描述左通道、右通道和中心通道的渲染。它是a3=d
36mren
用由限定的6至3部分下混矩阵d
36
获得的。
[0031]
调整部分下混权重w
p
,p=1,2,3是使得w
p
(y
2p-1
y
2p
)的能量等于达到限制因子的能量||y
2p-1
||2 ||y
2p
||2之和。
[0032]
w3=0.5,其中f
i,j
表示f的元素。为了估计期望的预测矩阵c
ttt
和下混预处理矩阵g,我们限定导致目标渲染c3x≈a3s的大小3
×
2的预测矩阵c3。此类矩阵是通过考虑正规方程c3(ded
*
)≈a3ed
*
而导出的。
[0033]
在给定目标协方差模型的情况下,正规方程的解产生目标输出的最佳可能波形匹配。g和c
ttt
现在通过解方程组c
ttt
g=c3得到。为避免计算术语j=(ded
*
)-1
时出现数值问题,
对j进行了修改。首先计算j的特征值λ
1,2
,求解det(j-λ
1,2
i)=0。按照降序(λ1≥λ2)对特征值进行排序,并且根据上面的等式计算对应于较大特征值的特征向量。它肯定位于正x平面(第一元素必须是正的)。第二特征向量是从第一特征向量通过
–
90度旋转获得的:
[0034]
根据下混矩阵d和预测矩阵c3计算加权矩阵w=(d
·
diag(c3))。因为c
ttt
是mpeg环绕声预测参数c1和c2(如iso/iec23003-1:2007中所限定)的函数,所以c
ttt
g=c3按以下方式重写,以找到函数的驻点或点,用γ=(d
ttt c3)w(d
ttt c3)
*
和b=gwc3v,其中和v=(1 1
ꢀ‑
1)。如果γ不能提供唯一的解决方案(det(γ)<10-3
),则选择最接近产生ttt通过的点的点。作为第一步,选择γ=[γ
i,1
γ
i,2
]元素含有最多能量γ的行i,因此γ
i,12
γ
i,22
≥γ
j,12
γ
j,22
,j=1,2。然后确定一个解决方案,使得其中
[0035]
如果获得的和的解超出了限定为(如iso/iec23003-1:2007中所限定)的预测系数的允许范围,则如下计算。首先限定点集,x
p
为:
[0036][0037]
和距离函数,
[0038]
然后根据下式限定预测参数:预测参数根据以下条件进行约束:其中λ、γ1和γ2限定为
[0039][0040]
[0041]
对于mps解码器,cpc以d
cpc_1
=c1(l,m)和d
cpc_2
=c2(l,m)形式提供。确定前通道和环绕通道之间的渲染的参数可以直接从目标协方差矩阵f估计
[0042]
其中(a,b)=(1,2)和(3,4)。
[0043]
对于每个ott盒h,mps参数在形式和中提供。
[0044]
立体声下混x被处理成修改后的下混信号立体声下混x被处理成修改后的下混信号其中g=d
ttt
c3=d
tttmren
ed
*
j。来自saoc代码转换器的最终立体声输出是通过x与去相关的信号分量混合来产生的,根据:其中去相关的信号xd是按照本文所述以及根据下面的混合矩阵g
mod
和p2来计算的。
[0045]
首先,将渲染上混误差矩阵限定为其中a
diff
=d
ttta3-gd并且此外,将预测信号的协方差矩阵限定为
[0046]
增益向量g
vec
随后可计算为:
[0047][0048]
并且混合矩阵g
mod
将给出为
[0049]
类似地,混合矩阵p2给出为:
[0050]
要导出vr和wd,r需要求解的特征方程:det(r-λ
1,2
i)=0,给出特征值,λ1和λ2。r的对应的特征向量v
r1
和v
r2
可以通过解方程组来计算:(r-λ
1,2
i)v
r1,r2
=0。按照降序(λ1≥λ2)对特征值进行排序,并且根据上面的等式计算对应于较大特征值的特征向量。它肯定位于正x平面(第一元素必须是正的)。第二特征向量是从第一特征向量通过-90度旋转获得的:合并p1=(1 1)g,rd可根据:计算,其给出了
[0051]
并且最后是混合矩阵,
[0052]
去相关信号xd由iso/iec23003-1:2007中描述的去相关器创建。因此,decorrfunc
()表示去相关过程:
[0053]
saoc代码转换器可以让混合矩阵p1、p2和预测矩阵c3根据较高频率范围的替代方案来计算。此替代方案对于下混信号特别有用,其中上频率范围由非波形保持编码算法编码,例如高效aac中的sbr。对于由bstttbandslow≤pb<numbands、p1、p2和c3限定的上限参数带,应根据下述替代方案进行计算:
[0054]
相应地限定能量下混和能量目标向量:
[0055]
和帮助矩阵
[0056]
然后计算增益向量
[0057]
这最终给出了新的预测矩阵
[0058]
对于saoc系统的解码器模式,下混预处理单元的输出信号(在混合qmf域中表示)被馈入对应的合成滤波器组,如iso/iec23003-1:2007中所述,产生最终的输出pcm信号。下混预处理包括单声道、立体声以及后续的双耳处理(如果需要)。
[0059]
输出信号由单声道下混信号x和去相关的单声道下混信号xd计算为去相关的单声道下混信号xd计算为xd=decorrfunc(x)。在双耳输出的情况下,从saoc数据导出的上混合参数g和p2、渲染信息和头部相关传递函数(hrtf)参数被应用于下混信号x(和xd),产生双耳输出目标双耳渲染矩阵a
l,m
的大小2
×
n由元素组成。每个元素都是从hrtf参数和具有元素元素的渲染矩阵导出的。目标双耳渲染矩阵a
l,m
表示所有音频输入对象y和期望的双耳输出之间的关系。
[0060][0061]
用于每个处理带m的hrtf参数由和给出。hrtf参数可用的空间位置由
索引i来表征。这些参数用iso/iec23003-1:2007来描述。
[0062]
上混参数g
l,m
和被计算为和
[0063]
左输出通道和右输出通道的增益和分别为和具有元素的期望协方差矩阵f
l,m
的大小2
×
2被给出为f
l,m
=a
l,mel,m
(a
l,m
)
*
。标量v
l,m
计算为v
l,m
=d
lel,m
(d
l
)
*
ε。具有元素的下混矩阵d
l
的大小1
×
n可以被发现为
[0064]
具有元素的矩阵e
l,m
从下面的关系导出。通道间相位差给出为
[0065]
通道间相干性计算为旋转角度α
l,m
和β
l,m
给出为
[0066][0067][0068]
在立体声输出的情况下,可以在不使用hrtf信息的情况下应用“x-1-b”处理模式。这可以通过导出渲染矩阵a的所有元素来完成,产生:在单声道输出的情况下,“x-1-2”处理模式可以应用于以下条目:
[0069]
在立体声到双耳“x-2-b”处理模式中,上混参数g
l,m
和计算为
[0070][0071][0072]
左右输出通道的对应的增益和分别为分别为
[0073]
具有元素的期望协方差矩阵f
l,m,x
的大小2
×
2被给出为f
l,m,x
=a
l,mel,m,x
(a
l,m
)
*
。具有干双耳信号的元素的协方差矩阵c
l,m
的大小2
×
2被估计为其中
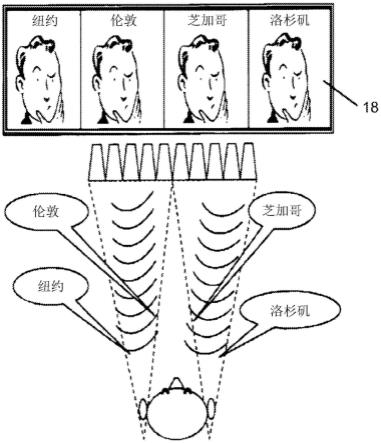
[0074][0075]
对应的标量v
l,m,x
和v
l,m
计算为v
l,m,x
=d
l,xel,m
(d
l,x
)
*
ε,v
l,m
=(d
l,1
d
l,2
)e
l,m
(d
l,1
d
l,2
)
*
ε。
[0076]
具有元素的下混矩阵d
l,x
的大小1
×
n可以被发现为n可以被发现为
[0077]
具有元素的立体声下混矩阵d
l
的大小2
×
n可以被发现为
[0078]
具有元素的矩阵e
l,m,x
从以下关系中导出
[0079]
具有元素的矩阵e
l,m
给出为通道间相位差给出为
[0080]
icc和的计算方式为旋转角度α
l,m
和β
l,m
给出为
[0081]
在立体声输出的情况下,如上描述的直接应用立体声预处理。在单声道输出的情况下,mpeg saoc系统用单个活动渲染矩阵条目来应用立体声预处理
[0082]
为每个时隙n和每个混合子带k限定音频信号。为每个参数时隙l和处理带m限定对应的saoc参数。iso/iec 23003-1:2007的表a.31规定了混合域和参数域之间的后续映射。因此,所有计算都是相对于特定的时间/带指数进行的,并且对于每个引入的变量都隐含对应的维度。otn/ttn上混合过程由预测模式或m
energy
能量模式的矩阵m表示。在第一种情况下,m是利用下混信息和每个eao通道的cpc的两个矩阵的乘积。它在“参数域”中由表示,其中是扩展下混矩阵的逆矩阵,和c暗示cpc。扩展下混矩阵的系数mj和nj将右下混通道和左下混通道的每个eaoj的下混值表示为mj=d
1,eao(j)
、nj=d
2,eao(j)
。在立体声的情况下,扩展的下混矩阵是
[0083][0084]
对于单声道来说,它变为了
[0085][0086]
对于立体声下混,每个eaoj持有两个cpcc
j,0
和c
j,1
产出矩阵c
[0087]
[0088]
cpc是从传输的saoc参数中导出的,即old、ioc、dmg和dcld。对于一个特定的eao通道,j=0...n
eao-1cpc可以通过下式来估计
[0089][0090]
在以下对能量值p
lo
、p
ro
、p
loro
、p
loco,j
和p
roco,j
中描述的。中描述的。中描述的。
[0091]
参数old
l
、oldr和ioc
lr
对应于常规对象,并且可以使用下混信息来导出:
[0092][0093]
cpc受后续限制函数的约束:
[0094][0095]
用加权因子
[0096]
受约束的cpc变为
[0097]
ttn元素的输出产生
[0098][0099]
其中x表示saoc解码器/代码转换器的输入信号。
[0100]
在立体声的情况下,扩展的下混矩阵矩阵是
[0101][0102]
并且对于单声道来说,它变为
[0103]
对于单声道下混,仅通过一个系数cj产生来预测一个eaoj
[0104][0105]
根据上面提供的关系,从saoc参数中获得所有矩阵元素cj。对于单声道下混情况,otn元件的输出信号y产生在立体声的情况下,矩阵m
energy
根据以下等式从对应的old获得
[0106][0107]
ttn元素的输出产生
[0108][0109]
单声道信号的等式的修改导致
[0110][0111]
ttn元素的输出产生
[0112]
立体声情况下的对应otn矩阵m
energy
可以导出为
[0113][0114]
因此,otn元件的输出信号y产生y=m
energy
d0。
[0115]
对于单声道情况,otn矩阵m
energy
简化为
[0116][0117]
juliuso.smithiii,虚拟乐器和音频效果的物理音频信号处理,音乐和声学计算机研究中心(ccrma),斯坦福大学音乐系,斯坦福,加利福尼亚94305美国,2008年12月版(测试版),考虑了声学模拟音乐厅或其他收听音空间的要求。假设我们只需要空间中一个或多
个离散收听音点(“耳朵”)的响应,这是由于一个或多个离散点声源的声能。可以使用与衰减缩放或低通滤波器串联的单个延迟线来模拟从声源传播到收听者耳朵的直接信号。经由一次或多次反射到达收听点的每条声线都可以使用延迟线和一些比例因子(或滤波器)来模拟。两条光线创建前馈梳状滤波器。更通常地,抽头延迟线fir滤波器可以模拟许多反射。每个抽头以适当的延迟和增益产生一个回声,每个抽头可以独立滤波以模拟空气吸收和有损反射。原则上,因为混响实际上是由从每个声源到每个收听音点的许多声传播路径组成的,所以抽头延迟线可以准确地模拟任何混响环境。相对于其他技术,抽头延迟线在计算上是昂贵的,并且仅处理一个“点对点”传递函数,即从一个点源到一只耳朵,并且依赖于物理环境。通常,滤波器还应包含通过耳朵的耳廓进行滤波,使得每个回声可以被感知为来自3d空间中正确的到达角度;换句话说,至少一些混响反射应被空间化,以便它们看起来来自它们在3d空间中的自然方向。同样,如果收听音空间中有任何变化,包含源或收听者的位置,滤波器也会变化。基本架构提供一组信号,s1(n),s2(n),s3(n),
…
馈送到一组滤波器(h
11
,h
12
,h
13
),(h
21
,h
22
,h
23
),
…
然后相加形成复合信号y1(n),y2(n),表示双耳的信号。每个滤波器h
ij
都可以实现为抽头延迟线fir滤波器。在频域中,用传递函数矩阵表示输入输出关系很方便:
[0118][0119]
由h
ij
(n)表示从源j到耳朵i的滤波器的脉冲响应,两个输出信号由六个卷积计算:
[0120][0121]
其中m
ij
表示fir滤波器h
ij
的阶数。由于许多滤波器系数h
ij
(n)为零(至少对于小的n),使得将它们实现为抽头延迟线会更高效,使得使内部和变得稀疏。为了更准确,每个抽头可以包含模拟空气吸收和/或球面扩散损失的低通滤波器。对于大型n,脉冲响应并且不稀疏,必须采用非常昂贵的fir滤波器,或使用较便宜的iir滤波器来逼近脉冲响应的尾部。
[0122]
对于音乐,典型的混响时间约为一秒。假设我们恰好选择一秒作为混响时间。在50khz的音频采样率下,每个滤波器每个样本需要50,000次乘法和加法运算,即每秒25亿次乘加运算。处理三个源和两个收听点(耳朵),我们达到了混响器每秒300亿次操作。尽管使用fft卷积而不是直接卷积可以改善这些数字(代价是引入吞吐量延迟,这对于实时系统可能是个问题),但是在混响空间中所有相关的点对点传递函数的精确实现在计算上仍然非常昂贵。
[0123]
尽管抽头延迟线fir滤波器可以为混响环境中的任何点对点传递函数提供准确的模型,但由于计算费用极高,它在实践中很少用于此目的。尽管有专门的商业产品经由输入信号与脉冲响应的直接卷积来实现混响,但是绝大多数人工混响系统使用其他方法来更经济地合成后期混响。
[0124]
点对点传递函数模型的一个缺点是,当任何东西移动时,一些或所有滤波器必须改变。相反,如果计算模型是整个声学空间的,那么声源和收听者可以根据需要移动,而不会影响下面的房间模拟。此外,我们可以使用“虚拟仿真头”作为收听者,配有耳廓滤波器,
这样混响的所有3d方向都可以在两个提取的耳朵信号捕获。因此,有令人信服的理由来考虑期望声学收听空间的完整3d模型。让我们简单估计一下房间的“强力”声学模拟的计算要求。普遍认为音频信号需要20khz的带宽。由于声音的传播速度约为每毫秒一英尺,因此20khz正弦波的具有的波长约为1/20英尺,即半英寸。由于根据基本采样理论,我们必须以高于信号中最高频率两倍的速度进行采样,因此在我们的模拟中,我们需要“网格点”间隔不超过四分之一英寸。在此网格密度下,模拟一个普通的12'
×
12'
×
8'的家庭房间需要超过1亿个网格点。使用有限差分或波导网格技术,平均网格点可以实现为无乘法计算;然而,由于它具有在六个空间方向上来来去去的波,所以每个样本需要约10次加法。因此,以50khz的音频采样率运行此类房间模拟器需要每秒500亿次加法,这与三个源、两个耳朵的模拟相当。
[0125]
基于感知的限制,混响室的脉冲响应可以分为两个部分。第一段称为早期反射,由脉冲响应中相对稀疏的第一回声组成。其余的称为后期混响,回声非常密集,最好以某种方式在统计上来表征响应。类似地,混响室的频率响应可以分为两个部分。低频区间由相对稀疏的谐振模式分布组成,而在较高频率下,这些模式非常密集,以至于它们在统计上被最好地表征为具有某些(规则)统计特性的随机频率响应。早期反射是空间化滤波器的特定目标,使得回声来自3d空间中的正确方向。众所周知,早期反射对空间感,即收听者对收听空间形状的感知具有强的影响。
[0126]
无损原型混响器的所有极点都在z平面的单位圆上,并且其混响时间为无穷大。要将混响时间设置为期望值,我们需要在单位圆内稍微移动极点。此外,我们希望高频极点比低频极点阻尼更大。此类型的变换可以使用替换z-1
←
g(z)z-1
来获得,其中g(z)表示传播介质中每个样本的滤波(在所有频率上增益不超过1的低通滤波器)。因此,要在反馈延迟网络(fdn)中设置混响时间,我们需要找到将极点移动到期望位置的g(z),然后设计低通滤波器放置在每个延迟线的输出(或输入)端。混响器中的所有极点半径应随频率平滑变化。
[0127]
设t
60
(ω)表示弧度频率ω下期望的混响时间,并且设hi(z)表示与延迟线i串联放置的低通滤波器的传递函数。我们现在考虑的问题是如何设计这些滤波器来产生期望的混响时间。我们将hi(z)基于每个频率下的期望混响时间来指定的理想幅度响应,然后使用常规的滤波器设计方法来获得这一理想规格的低阶近似值。由于替换会引入损耗z-1
←
g(z)z-1
,我们需要找出它对无损原型极点半径的影响。让表示第i极。(回想一下无损原型的所有极点都在单位圆上)。如果每样本损耗滤波器g(z)是零相位,那么替换z-1
←
g(z)z-1
将只影响极点的半径,并且不影响它们的角度。如果g(z)的e幅度响应沿着单位圆接近于1,则我们得到第i极点从移动到的近似值,其中
[0128]
换句话说,当z-1
替换为g(z)z-1
时,其中g(z)是零相位,并且|g(e
jω
)|接近(但小于)1,频率ωi为的单位圆上的一个极点约沿着复平面中的径向线移动到半径为的点。我们所期望的极点在某一频率ωi上的半径就是给出我们所期望的t
60
(ωi):因此,理想的单样本滤波器g(z)满足
[0129]
因此,与长度mi延迟线串联的低通滤波器应近似这意味着
取20log
10
双方给
[0130]
既然我们已经指定了理想的延迟线滤波器hi(e
jωt
),那么可以使用任何数量的滤波器设计方法来找到提供良好近似的低阶hi(z)。示例包含matlab中的函数invfreqz和stmcb。由于混响时间的变化通常相对于ω非常平滑,因此滤波器hi(z)可以是非常低阶的。
[0131]
早期反射应通过在早期反射延迟线的每个抽头上包含头部相关传递函数(hrtf)而被空间化。后期混响也可能需要某种空间化。真正的漫射场由在3d空间中向所有方向传播的平面波的总和组成。空间化也可以应用于后期反射,尽管由于这些是以统计方式处理的,所以实现方式是不同的。
[0132]
另见,u.s.10,499,153;9,361,896;9,173,032;9,042,565;8,880,413;7,792,674;7,532,734;7,379,961;7,167,566;6,961,439;6,694,033;6,668,061;6,442,277;6,185,152;6,009,396;5,943,427;5,987,142;5,841,879;5,661,812;5,465,302;5,459,790;5,272,757;20010031051;20020150254;20020196947;20030059070;20040141622;20040223620;20050114121;20050135643;20050271212;20060045275;20060056639;20070109977;20070286427;20070294061;20080004866;20080025534;20080137870;20080144794;20080304670;20080306720;20090046864;20090060236;20090067636;20090116652;20090232317;20090292544;20100183159;20100198601;20100241439;20100296678;20100305952;20110009771;20110268281;20110299707;20120093348;20120121113;20120162362;20120213375;20120314878;20130046790;20130163766;20140016793;20140064526;20150036827;20150131824;20160014540;20160050508;20170070835;20170215018;20170318407;20180091921;20180217804;20180288554;20180288554;20190045317;20190116448;20190132674;20190166426;20190268711;20190289417;20190320282;wo00/19415;wo 99/49574;以及wo 97/30566。
[0133]
naef、martin、oliver staadt和markus gross。“沉浸式虚拟环境的空间化音频渲染”。在acm虚拟现实软件和技术研讨会的会议录中,第65-72页。acm,2002公开了来自图形处理器单元的反馈,以进行空间化的音频信号处理。lauterbach、christian、anish chandak和dinesh manocha。“采用平截头体跟踪的复杂和动态场景中的交互式声音渲染”。ieee可视化和计算机图形汇刊13,第6期(2007):1672-1679也将图形风格分析用于音频处理。murphy、david和flaithr
í
neff.“电脑游戏和虚拟现实的空间声音”。游戏声音技术和玩家互动:概念和发展,第287-312页。igi global,2011年讨论了计算机游戏和vr环境中的空间化音频。begault、durand r.和leonard j.trejo。“虚拟现实和多媒体的3-d声音”。(2000),nasa/tm-2000-209606讨论了空间化音频系统的各种实现。另见begault、durand、elizabethm.wenzel、martinegodfroy、joeld.miller和markr.anderson。“将空间音频应用于人机接口:nasa25年的经验”。音频工程学会会议:第40届国际会议:空间音频:感知空间的声音。音频工程学会,2010年。
[0134]
herder、jens。“通过聚类优化声音空间化资源管理”。在三维图像杂志中,3d论坛协会,第13卷,第3期,第59-65页.1999年涉及用于简化空间音频处理的算法。
[0135]
verron、charles、mitsuko aramaki、richard kronland-martinet和gr
é
gory pallone。“用于环境声音的3-d沉浸式合成器”。ieee音频、语音和语言处理汇刊18,第6期
(2009):1550-1561涉及空间化声音合成。
[0136]
malham、david g、和anthony myatt.“使用双声道立体声技术的3-d声音空间化”。计算机音乐杂志19,第4期(1995):58-70讨论了环绕声技术的使用(3d声场的使用)。另见,hollerweger、florian.多用户虚拟环境中的环绕声音空间化。电子音乐与声学研究所(iem),电子艺术技术研究中心(create)博士论文2006年。
[0137]
mcgee、ryan和matthew wright.“声音元素空间化器”。在icmc.2011z.;以及mcgee,ryan,“声音元素空间化器”(m.s.thesis,u.california santa barbara 2010),介绍了声音元素空间化器(ses),用于渲染和控制空间音频的新型系统。ses提供多种3d声音渲染技术,并且允许利用任意数量的移动声源进行任意扬声器配置。
[0138]
跨耳音频处理在以下内容中进行了讨论:
[0139]
baskind、alexis、thibaut carpentier、markus noisternig、olivier warusfel和jean-marc lyzwa。“多通道5.1制作中的双耳和跨耳空间化技术”。(双耳和跨听觉播放技术在5.1音乐制作中的应用)。第27届tonmeistertagung-vdt国际会议,2012年11月
[0140]
bosun、xie、liu lulu、和chengyun zhang.使用四个实际扬声器的空间环绕声的跨耳再现。在国际噪音和噪音大会和会议记录中,第259卷,第9期,第61-69页。噪声控制工程研究所,2019年。
[0141]
casey、michael a.、william g.gardner和sumit basu。“人工生命交互式视频环境(alive)的视觉控制波束成形和跨听觉渲染”。音频工程学会大会99。音频工程学会,1995年。
[0142]
cooper、duane h.,和jerald l.bauck.跨耳录音的前景。音频工程学会杂志37,第1/2期(1989):3-19。
[0143]
fazi、filippo maria、和eric hamdan.“跨耳音频中的阶段压缩”。音频工程协会第144号公约。音频工程学会,2018年。
[0144]
gardner、william grant。跨耳3-d音频。麻省理工学院媒体实验室感知计算部,1995年。
[0145]
glasal,ralph,《双声道立体声,取代立体声实现音乐厅现实主义》,第2版(2015年)。
[0146]
greff,“参数阵列在跨耳应用中的使用”。在第20届国际声学大会论文集中,第1-5页。2010年。
[0147]
guastavino、catherine、v
é
ronique larcher、guillaume catusseau和patrick boussard。“空间音频质量评估:比较跨耳、环绕立体声和立体声”。佐治亚理工学院,2007年。
[0148]
guldenschuh、markus、和alois sontacchi.“跨耳聚焦声音再现的应用”。在2009年第6届欧控ino研讨会上。2009年。
[0149]
guldenschuh、markus、和alois sontacchi.“波束成形方法中的跨耳立体声”。in proc.dafx,第9卷,第1-6页。2009年。
[0150]
guldenschuh、markus、chris shaw和alois sontacchi。“跨耳波束成形器的评估”。国际航空科学理事会第27届大会(icas 2010)。nizza,frankreich,pp.2010-10.2010年。
[0151]
guldenschuh、markus。“跨耳波束成形”。博士diss.,硕士论文,格拉茨理工大学,奥地利格拉茨,2009。
[0152]
hartmann、william m.、brad rakerd、zane d.crawford和peter xinya zhang。“用于低频音调定位的跨耳实验和修正的双工理论”。美国声学学会会刊139,第2期(2016):968-985。
[0153]
ito、yu、和yoichi haneda.“使用圆形扬声器阵列进行波束成形的跨耳系统的研究”。proc.23rd int.cong。声学(2019年)。
[0154]
johannes、reuben、和woon-seng gan.“具有跨耳音频束投影的3d音效”。第10届西太平洋声学会议,中国北京,论文,第244卷,第8期,第21-23页。2009年。
[0155]
jost、adrian、和jean-marc jot。“具有用户控制校准的跨耳3d音频”。cost-g6数字音频效果会议论文集,dafx2000,维罗纳,意大利。2000年。
[0156]
kaiser、fabio。“跨耳音频-通过扬声器再现双耳信号”。博士diss.,格拉茨音乐与艺术大学/音乐与艺术学院/ircam,毕业论文,2011年3月,2011年。
[0157]
liu、lulu、和bosun xie.“两个前置扬声器静态跨耳再现的限制”。(2019)
[0158]mé
aux、eric、和sylvain marchand.“合成跨耳音频渲染(star):声音空间化的感知方法”。2019年。
[0159]
samejima、toshiya、yosasaki、izumi taniguchi和hiroyuki kitajima。“基于反馈控制的强健跨耳声音再现系统”。声学科学与技术31,第4期(2010):251-259。
[0160]
simon galvez、marcos f.和filippo maria fazi。“用于跨耳再现的扬声器阵列”。(2015年)。
[0161]
simon g
á
lvez、marcos felipe、miguel blanco galindo和filippo maria fazi。“低通道数跨耳系统反射和混响效应的研究”。在国际噪音和噪音大会和会议记录中,第259卷,第3期,第6111-6122页。噪声控制工程研究所,2019年。
[0162]
villegas、juli
á
n、和takaya ninagawa.“具有范围控制的基于纯数据的跨耳滤波器”。(2016年)
[0163]
en.wikipedia.org/wiki/perceptual-based_3d_sound_localization
[0164]
duraiswami、grant、mesgarani、shamma、同时多语者环境中的增强可理解性。2003年,听觉显示国际会议论文集(icad'03)。
[0165]
shohei nagai、shunichi kasahara、junre kimot,“在人-远程呈现中使用空间声音的定向交流”第6届增强人类国际会议论文集,新加坡2015,美国纽约acm,isbn:978-1-4503-3349-8。
[0166]
siu-lantan、annabel j.cohen、scottd.lipscomb、rogera.kendall,“多媒体音乐心理学”,牛津大学出版社,2013年。
技术实现要素:
[0167]
在本发明的一个方面,提供一种用于三维(3-d)音频技术的系统和方法,以使用声学换能器的稀疏线性(或曲线)阵列来创建使收听者沉浸的复杂沉浸式收听觉场景。稀疏阵列是相对于理想化的通道模型具有不连续间隔的阵列,(例如四个或更少的声波发射器),其中从换能器发射的声音在更高维度被内部建模,然后被减少或叠加。在一些情况下,声波
发射器的数量为四个或更多个,从通道模型的更大数量的通道导出,例如大于八个。
[0168]
三维声场是根据数学和物理约束来建模的。所述系统和方法提供多个扬声器,即向包含目标收听者的双耳的空间发射的自由场声传输换能器。这些系统由复杂的多通道算法实时控制。
[0169]
所述系统可以假定稀疏扬声器阵列和收听者的耳朵之间的固定关系,或可以采用反馈系统来跟踪收听者的耳朵或头部的移动和位置。
[0170]
所采用的算法通过扬声器阵列提供高度本地化的音频,从而提供环绕声成像和声场控制。典型地,稀疏阵列中的扬声器寻求在发射的广角散射模式下操作,而不是更传统的“波束模式”,在所述模式中,每个换能器向收听者发射窄角声场。也就是说,换能器发射模式足够宽以避免声音空间停顿。
[0171]
在一些情况下,所述系统支持在环境内有多个收听者,尽管在这种情况下,要么采用增强立体声操作模式,要么采用头部跟踪。例如,当两个收听者在环境中时,名义上相同的信号被提供给每个收听者的左耳和右耳,而不管他们在房间中的取向。在一个重要的实现中,这需要多个换能器合作来消除每个收听者右耳处的左耳发射,并且消除每个收听者左耳处的右耳发射。然而,可以采用试探法来减少每个收听者对最少一对换能器的需求。
[0172]
典型地,空间音频不仅针对跨耳音频幅度控制进行归一化,而且还针对群延迟进行归一化,以便在正确的时间感知到正确的声音出现在每只耳朵处。因此,在一些情况下,信号可能表示精细幅度和延迟控制的折衷。
[0173]
因此,源内容可以被虚拟地转向各种角度,使得可以根据不同收听者的位置为他们生成不同的动态变化的声场。
[0174]
提供一种信号处理方法,用于使用去卷积滤波器以各种方式递送空间化声音,以从扬声器阵列递送离散的左/右耳音频信号。所述方法可以用于在公共空间中提供私人收听区域,用离散声源对多个收听者进行寻址,为单个收听者提供源材料的空间化(虚拟环绕声),以及使用空间线索增强嘈杂环境中的对话的可理解性,仅举几个应用为例。
[0175]
在一些情况下,传声器或传声器阵列可以用于提供空间中体素处(诸如在收听者的耳朵处或附近)的声音条件的反馈。尽管最初看起来相当于头戴式耳机,人们可以简单地对每只耳朵使用单个换能器,但是本技术并且不强迫收听者佩戴头戴式耳机,并且结果更加自然。此外,(一个或多个)传声器可以用于最初了解房间条件,然后不再需要,或可以选择性地仅用于一部分环境。最后,传声器可以用于提供交互式语音通信。
[0176]
在双耳模式下,扬声器阵列产生两个发射信号,通常瞄准主要收听者的耳朵,每只耳朵一个离散的波束。这些波束的形状是使用卷积或逆滤波方法设计的,使得一只耳朵的波束在收听者的另一只耳朵几乎不贡献能量。这经由双耳源信号提供令人信服的虚拟环绕声。在此模式下,双耳源可以在没有耳机的情况下准确渲染。无需物理离散环绕扬声器即可递送虚拟环绕声体验。注意,在真实环境中,墙壁和表面的回声会给声音着色并且产生延迟,并且自然的声音发射将提供这些与环境相关的线索。由于耳朵和头部的形状,人耳有一定的能力区分来自前方或后方的声音,但大多数源材料的关键特征是时间和声音着色。因此,可以通过处理中的延迟滤波器来模拟环境的活跃度,从相同的阵列发射延迟的声音,所述相同的阵列具有与主声信号大体上相同的波束模式。
[0177]
在一个方面,提供一种用于从扬声器阵列产生双耳声音所述的方法,其中从多个
源接收多个音频信号,并且基于收听者相对于发射器阵列的位置和取向,通过头部相关传递函数(hrtf)对每个音频信号进行滤波。经滤波的音频信号被合并且以形成双耳信号。在稀疏换能器阵列中,可能期望在相应的双耳通道之间提供交叉信号,尽管在阵列的方向性足以提供收听者耳朵的物理隔离,并且收听者的位置相对于阵列被很好地限定和约束的情况下,可能不需要交叉。典型地,音频信号被处理以提供串扰消除。
[0178]
当源信号是预先录制的音乐或其他经处理的音频时,初始处理可以可选地移除试图隔离原始对象及其相应的声音发射的处理效果,使得空间化对于声场是准确的。在一些情况下,在源中推断的空间位置是人为的,即,对象位置被限定为生产过程的一部分,并且不表示实际位置。在此类情况下,空间化可能会延伸回原始源,并且寻求(重新)优化所述过程,因为原始产品可能不会通过空间化系统进行优化以进行再现。
[0179]
在稀疏线性扬声器阵列中,针对多个虚拟通道的滤波/处理信号被分别处理,然后针对每个相应的虚拟扬声器被组合(例如求和)成单个扬声器信号,然后所述扬声器信号被馈送到扬声器阵列中的相应的扬声器,并且通过相应的扬声器传输到收听者。
[0180]
求和过程可以校正相应的信号的时间对准。也就是说,原始完整阵列信号对于每个耳朵的相应的信号具有时间延迟。当在没有补偿的情况下求和时,为了产生复合信号,所述信号将包含在不同时间到达耳朵的多个增量时间延迟表示,表示相同的时间点。因此,空间的压缩导致时间的扩展。然而,由于时间延迟是按照算法编程的,因此可以通过算法压缩来恢复时间对准。
[0181]
结果是,空间化声音具有到达每个耳朵的准确时间、相位对准和空间化声音复杂性。
[0182]
在另一个方面,提供一种方法,用于通过接收至少一个音频信号,通过一组空间化滤波器对每个音频信号进行滤波(通过不同组的空间化滤波器对每个输入音频信号进行滤波,所述不同组的空间化滤波器可以是交互式的或最终是组合的),其中为扬声器阵列中的每一个扬声器提供单独的空间化滤波器路径段,使得通过不同的空间化滤波器段对每个输入音频信号进行滤波,将每个相应的扬声器的滤波后的音频信号求和为扬声器信号,将每个扬声器信号传输到扬声器阵列中的相应的扬声器,并且将信号递送到空间的一个或多个区域(通常相应地由一个或多个收听者占据)。
[0183]
这样,声信号处理路径的复杂性被简化为利用组合器表示阵列位置的一组并行级。一种用于提供双扬声器空间化音频的替代方法提供一种基于对象的处理算法,其波束跟踪相应的源之间的音频路径,离开散射对象,到达收听者的耳朵。后一种方法提供更任意的算法复杂性,并且每个处理路径的一致性更低。
[0184]
在一些情况下,滤波器可以被实现为递归神经网络或深度神经网络,其通常模拟相同的空间化过程,但是没有明确的离散数学函数,并且寻求最佳的整体效果,而不是串行或并行地优化每个效果。所述网络可以是接收声音输入并且产生声音输出的整体网络,或是通道化系统,其中每个通道可以表示空间、带、延迟、源对象等,使用不同的网络进行处理,并且组合网络输出。此外,神经网络或其他统计优化网络可以为通用信号处理链提供系数,诸如数字滤波器,其可以是有限脉冲响应(fir)特征和/或无限脉冲响应(iir)特征、到其他通道的泄漏路径、专用时间和延迟均衡器(其中通过fir或iir滤波器的直接实现是不期望的或不方便的)。
[0185]
更典型地,基于物理(或虚拟)参数,采用离散数字信号处理算法来处理音频数据。在一些情况下,基于自动或手动反馈,算法可以是自适应的。例如,传声器可能会检测到由于共振或其他影响而产生的失真,而这些失真在基本算法中并且没有得到内在补偿。类似地,可以采用通用hrtf,其基于收听者头部的实际参数进行调整。
[0186]
在另一个方面,一种用于产生局部声音的扬声器阵列系统包括:输入端,从至少一个源接收多个音频信号;具有处理器和存储器的计算机,其确定多个音频信号是否应由音频信号处理系统处理;包括多个扬声器的扬声器阵列;其中音频信号处理系统包括:至少一个头部相关传递函数(hrtf),其感测或估计收听者与扬声器阵列的空间关系;以及组合器,其被配置为组合多个处理通道以形成扬声器驱动信号。音频信号处理系统实现空间化滤波器;其中扬声器阵列通过多个扬声器将相应的扬声器信号(或波束成形扬声器信号)递送到一个或多个收听者。
[0187]
通过波束成形,意味着换能器的发射不是全向的或心形的,而是具有发射轴线,左耳和右耳之间的间隔大于3db,优选大于6db,更优选大于10db,并且利用换能器之间的主动抵消,可以实现更高的间隔。
[0188]
在通过多个扬声器递送到一个或多个收听者之前,多个音频信号可以由包含双耳化的数字信号处理系统处理。
[0189]
可以提供收听者头部跟踪单元,所述收听者头部跟踪单元基于一个或多个收听者的位置变化来调整双耳处理系统和声学处理系统。
[0190]
双耳处理系统还可以包括双耳处理器,所述双耳处理器实时计算左hrtf和右hrtf,或合成hrtf。
[0191]
本发明的方法采用了允许其通过采用去卷积或逆滤波器以及物理或虚拟波束成形来递送波束的算法,所述波束被配置为产生双耳声音——针对每只耳朵的声音——而不采用耳机。这样,虚拟环绕声体验可以被递送到系统的收听者。所述系统避免了使用经典的双通道“串扰消除”来提供基于扬声器的卓越双耳声音成像。
[0192]
双耳3d声音再现是一种通过耳机实现的声音预制作。另一个方面,跨耳3d声音再现是由扬声器实现的一种声音预制作。见,kaiser,fabio。“跨耳音频-通过扬声器再现双耳信号”。博士diss.,格拉茨音乐与艺术大学/音乐与艺术学院/ircam,毕业论文,2011年3月,2011年。kaiser、fabio。“跨耳音频-通过扬声器再现双耳信号”。博士diss.,格拉茨音乐与艺术大学/音乐与艺术学院/ircam,毕业论文,2011年3月,2011年。kaiser、fabio。“跨耳音频-通过扬声器再现双耳信号”。博士diss.,格拉茨音乐与艺术大学/音乐与艺术学院/ircam,毕业论文,2011年3月,2011年。跨耳音频是三维声音空间化技术,能够通过扬声器再现双耳信号。它是基于消除扬声器和收听者耳朵之间的声音路径。
[0193]
心理声学研究表明,记录良好的立体声信号和双耳录音含有有助于创建强健、详细的3d听觉图像的线索。经由将左通道和右通道信号聚焦在适当的耳朵上,3d空间化音频的一种实现,称为“mybeam”(加利福尼亚州圣地亚哥的comhear公司),保持了关键的心理声学线索,同时经由精确的波束成形方向性避免了串扰。
[0194]
总之,这些线索被称为头部相关传递函数(hrtf)。简而言之,hrtf分量线索是耳间时间差(itd,两个位置之间的声音到达时间差)、耳间强度差(iid,两个位置之间的声音强度差,有时称为ild)和耳间相位差(ipd,到达每个耳朵的波的相位差,依赖于声波的频率和
itd)。一旦收听者的大脑分析了ipd、itd和ild,就可以相对准确地确定声源的位置。
[0195]
本发明提供一种用于优化波束成形和控制小型线性扬声器阵列以产生空间化的、局部化的、和双耳的或跨听觉的虚拟环绕或3d声音的方法。信号处理方法允许小型扬声器阵列使用高度优化的逆滤波器以各种方式递送声音,向收听者递送狭窄的声音波束,同时产生可忽略的伪影。与早期的紧凑波束成形音频技术不同,本方法不依赖于超声波或高功率放大。所述技术可以使用低功率技术实现,在一米处产生98db spl,同时利用约20瓦的峰值功率。在扬声器应用的情况下,主要用例允许来自小型(10英寸-20英寸)线性扬声器阵列的声音以窄波束聚焦:
[0196]
·
在需要和有效的地方以高度可理解的方式引导声音;
[0197]
·
在不想要或可能造成干扰的地方限制声音
[0198]
·
提供基于非耳机的、高清晰度、可操控的音频成像,其中立体声或双耳信号被引导至收听者的耳朵,以产生生动的3d收听觉。
[0199]
在传声器应用的情况下,基本用例允许来自传声器阵列(从几个小振膜到数十个1维、2维或3维布置)的声音以窄波束形式捕获声音。这些波束可以被动态地操纵,并且可以覆盖其覆盖模式内的许多说话者和声源,放大期望的源并且提供对不期望的源的消除或抑制。
[0200]
在多点电话会议或视频会议应用中,所述技术允许会议中每个参与者的不同空间化和定位,提供对现有技术的显著改善,在现有技术中,每个扬声器的声音在空间上重叠。此类重叠使得很难在不同的参与者之间进行区分,而不需要每个参与者在他或她每次发言时都表明自己的身份,这有损于自然的面对面对话的感觉。此外,本发明可以扩展为使用视频分析或移动传感器来提供对收听者位置的实时波束控制和跟踪,因此当收听者在房间内或扬声器阵列前移动时,连续优化双耳或空间化音频的递送。
[0201]
所述系统可能比大多数(如果不是全部的话)类似的扬声器系统更小、更便携。因此,所述系统不仅可用于固定的结构安装,诸如在房间或虚拟现实洞穴中,还可以用于私人交通工具,诸如汽车、公共交通工具,如公共汽车、火车和飞机,以及开放区域,诸如办公室隔间和无墙教室。
[0202]
所述技术相对于mybeam
tm
有所改善,因为它提供类似的应用和优势,同时需要更少的扬声器和放大器。例如,所述方法将12通道波束成形阵列虚拟为两个通道。通常,所述算法将每对6个通道(设计成驱动一组6个等间距排列的扬声器)下混为安装在这6个扬声器中间的扬声器的单个扬声器信号。典型地,虚拟线阵列是12个扬声器,其中2个真实扬声器位于元件3-4和9-10之间。
[0203]
真实扬声器直接安装在每组6个虚拟扬声器的中心。如果(s)是扬声器之间的中心到中心的距离,那么从阵列中心到每个真实扬声器中心的距离是:a=3*s
[0204]
左扬声器从中心偏移-a,并且右扬声器偏移a。
[0205]
主要算法是简单地对6个虚拟通道进行下混,应用限制器和/或压缩器来防止饱和或削波。例如,左通道是:
[0206]
l
输出
=限制(l1 l2 l3 l4 l5 l6)
[0207]
然而,由于音频源位置的变化,需要考虑扬声器之间的延迟,如下所述。在一些情况下,可以改变一些驱动器的相位来限制峰化,同时避免削波或限制失真。
[0208]
由于六个扬声器在不同的位置被组合成一个,传播距离的变化,即对于收听者的延迟,可能是显著的,特别是在较高的频率下。可以基于虚拟扬声器和真实扬声器之间的行进距离的变化来计算延迟。
[0209]
在本次讨论中,我们将只关注数组的左侧。右侧类似,但倒置。
[0210]
为了计算从收听者到每个虚拟扬声器的距离,假设扬声器n被编号为1至6,其中1是最靠近中心的扬声器,并且6是最左边的。从阵列中心到扬声器的距离为:d=((n-1) 0.5)*s
[0211]
使用勾股定理,从扬声器到收听者的距离可以计算为:
[0212]
从真实的扬声器到收听者的距离是
[0213]
每个扬声器的样本延迟可以通过两个收听者之间的距离差来计算。这可以将它们转换为样本(假设声速为343m/s,采样率为48khz。
[0214]
这可能导致收听者距离之间的显著延迟。例如,如果扬声器到扬声器的距离为38mm,而收听者距离阵列500mm,则从虚拟最左侧扬声器(n=6)到真实扬声器的延迟为:
[0215][0216][0217]
尽管延迟看起来小,但延迟量显著,尤其是在较高频率下,整个周期可能仅3或4个样本。
[0218]
表1
[0219][0220][0221]
因此,当将用于虚拟扬声器的信号组合成物理扬声器信号时,优选地基于虚拟扬声器相对于物理扬声器的位移来补偿时间偏移。这可以在信号处理链的不同位置完成。
[0222]
因此,本技术提供空间化音频虚拟通道的下混,以维持虚拟通道的延迟编码,同时最小化所需的物理驱动器和放大器的数量。
[0223]
在类似的声音输出下,每个扬声器的功率当然会随着下混而更高,这导致峰值功率处理限制。假设每个虚拟通道的幅度、相位和延迟是重要的信息,那么控制峰化的能力是有限的。然而,考虑到削波或限制特别不协调,控制其他变量有助于实现高额定功率。可以通过对延迟进行操作来便于控制,例如在具有30hz较低范围的扬声器系统中,可以施加125ms的延迟,以准许计算所有显著的回声和削峰缓解策略。在还呈现视频内容的情况下,
可以减少此类延迟。然而,不要求延迟。
[0224]
在一些情况下,收听者相对于物理扬声器换能器不在中心,或多个收听者分散在环境内。此外,由建议的下混导致的物理换能器的峰值功率可能超过限制。在此类情况下以及其他情况下,下混算法可以是自适应的或灵活的,并且提供虚拟换能器到物理扬声器换能器的不同映射。
[0225]
例如,由于收听者位置或峰值水平,虚拟阵列中的虚拟换能器到物理扬声器换能器下混的分配可能是不平衡的,诸如,在12个虚拟换能器的阵列中,7个虚拟换能器下混用于左物理换能器,并且5个虚拟换能器用于右物理换能器。这具有移动声音轴线的效果,并且还将自适应分配的换能器的另外的效果移动到另一个通道。如果换能器相对于其他换能器异相,则峰值将被消减,而如果同相,将产生相长干涉。
[0226]
重新分配可以是在组之间的边界处的虚拟换能器,或可以是不连续的虚拟换能器。类似地,自适应分配可以是一个以上的虚拟换能器。
[0227]
此外,物理换能器的数量可以是大于2的偶数或奇数,并且通常小于虚拟换能器的数量。在通常位于标称左侧、中间和右侧的三个物理换能器的情况下,虚拟换能器和物理换能器之间的分配可以基于收听者(或多个收听者)的位置、空间化效果、峰值幅度消减问题和收听者偏好,在组大小、组过渡、组的连续性和组的可能重叠(即,相同虚拟换能器信号的部分在多个物理通道中表示)方面是自适应的。
[0228]
所述系统可以采用各种技术来实现最佳hrtf。在最简单的情况下,使用最佳原型hrtf,而不管收听者和环境。在其他情况下,(一个或多个)收听者的特征由登录、直接输入、相机、生物测定测量或其他手段以及为(一个或多个)特定收听者选择或计算的定制或选择的hrtf来确定。这通常在滤波过程中实现,独立于下混过程,但是在一些情况下,定制可以作为空间化滤波的后处理或部分后处理来实现。也就是说,除了下混之外,可以实现主空间化滤波和虚拟换能器信号创建之后的过程,以根据(一个或多个)收听者、环境或其他因素来适应或修改信号,与下混和定时调整分离。
[0229]
如上所述,限制峰值幅度潜在地是重要的,因为一组虚拟换能器信号(例如6个),被时间对准并且求和,导致峰值幅度潜在地比任一个虚拟换能器信号的峰值高六倍。解决此问题的一种方法是简单地限制组合信号或使用压扩器(非线性幅度滤波器)。但是,这些会产生失真,并且会干扰空间化效果。其他选项包含一些虚拟传感器信号的相移,但是这也可能导致听觉伪影,并且需要施加延迟。所提供的另一个选项是基于相位和幅度将虚拟换能器(尤其是那些组之间的过渡附近的换能器)分配给下混组。尽管这也可以用延迟来实现,但是也有可能几乎瞬时地移动组分配,这可能导致位置伪影,而不是谐波失真伪影。也可以组合这些技术,通过在各种峰值消减选项之间扩展效果来最小化感知失真。
[0230]
因此,目的是提供一种用于产生跨耳空间化声音的方法,其包括:接收表示空间音频对象的音频信号;通过空间化滤波器对每个音频信号进行滤波,以生成表示空间化音频的虚拟音频换能器阵列的虚拟音频换能器信号阵列;将虚拟音频换能器信号阵列分离成子集,每个子集包括多个虚拟音频换能器信号,每个子集用于驱动位于相应的子集的物理位置范围内的物理音频换能器;基于来自相应的虚拟音频换能器的标称位置和物理音频换能器相对于收听者的目标耳朵的物理位置的声音的到达时间差,对相应的子集的相应的虚拟音频换能器信号进行时间偏移;以及将相应的子集的时间偏移的相应的虚拟扬声器信号组
合为物理音频换能器驱动信号。
[0231]
另一个目的是提供一种用于产生跨耳空间化声音所述的系统,其包括:输入端,其被配置为接收表示空间音频对象的音频信号;空间化音频数据滤波器,其被配置为处理每个音频信号以生成表示空间化音频的虚拟音频换能器阵列的虚拟音频换能器信号阵列,虚拟音频换能器信号阵列被分成子集,每个子集包括多个虚拟音频换能器信号,每个子集用于驱动位于相应的子集的物理位置范围内的物理音频换能器;时间延迟处理器,其被配置为基于来自相应的虚拟音频换能器的标称位置和对应的物理音频换能器相对于收听者的目标耳朵的物理位置的声音的到达时间差,对相应的子集的相应的虚拟音频换能器信号进行时间偏移;以及组合器,其被配置为将相应的子集的时间偏移的相应的虚拟扬声器信号组合为物理音频换能器驱动信号。
[0232]
另一个目的是提供一种用于产生空间化声音所述的系统,其包括:输入端,其被配置为接收表示空间音频对象的音频信号;至少一个自动化处理器,其被配置为:通过空间化滤波器处理每个音频信号,以生成表示空间化音频的虚拟音频换能器阵列的虚拟音频换能器信号阵列,虚拟音频换能器信号阵列被分成子集,每个子集包括多个虚拟音频换能器信号,每个子集用于驱动位于相应的子集的物理位置范围内的物理音频换能器;基于来自相应的虚拟音频换能器的标称位置和对应的物理音频换能器相对于收听者的目标耳朵的物理位置的声音的到达时间差,对相应的子集的相应的虚拟音频换能器信号进行时间偏移;并且将相应的子集的时间偏移的相应的虚拟扬声器信号组合为物理音频换能器驱动信号;以及至少一个输出端口,其被配置为呈现相应的子集的物理音频换能器驱动信号。
[0233]
所述方法还可以包括消减组合的时间偏移的相应的虚拟音频换能器信号的峰值幅度以减少物理音频换能器的饱和失真。
[0234]
滤波可以包括用数字信号处理器来处理至少两个音频通道。滤波可以包括利用被配置为充当音频信号处理器的图形处理单元来处理至少两个音频通道。
[0235]
虚拟音频换能器信号阵列可以是12个虚拟音频换能器的线性阵列。虚拟音频换能器阵列可以是具有至少3倍数量的虚拟音频换能器信号作为物理音频换能器驱动信号的线性阵列。虚拟音频换能器阵列可以是具有至少6倍数量的虚拟音频换能器信号作为物理音频换能器驱动信号的线性阵列。
[0236]
每个子集可以是虚拟音频换能器信号的非重叠相邻组。每个子集可以是至少6个虚拟音频换能器信号的非重叠相邻组。每个子集可以具有虚拟音频换能器,其位置与虚拟音频换能器信号的另一个子集的表示位置范围重叠。所述重叠可以是一个虚拟音频换能器信号。
[0237]
虚拟音频换能器信号阵列可以是具有12个虚拟音频换能器信号的线性阵列,被分成两个非重叠组,每个组有6个相邻的虚拟音频换能器信号,它们相应地被组合以形成2个物理音频换能器驱动信号。每组对应的物理音频换能器可以位于6个虚拟音频换能器信号的相邻组的第3虚拟音频换能器和第4虚拟音频换能器之间。
[0238]
物理音频换能器可以具有非定向发射模式。虚拟音频换能器阵列可以针对方向性进行建模。虚拟音频换能器阵列可以是音频换能器的相控阵列。
[0239]
滤波可以包括串扰消除。可以使用可重入数据滤波器来进行滤波。
[0240]
所述方法还可以包括接收表示收听者的耳朵位置的信号。所述方法还可以包括跟
踪收听者的移动,并且根据所跟踪的移动来调整滤波。
[0241]
所述方法还可以包括自适应地将虚拟音频换能器信号分配给相应的子集。
[0242]
所述方法还可以包括自适应地确定收听者的头部相关传递函数,并且根据自适应地确定的头部相关传递函数进行滤波。
[0243]
所述方法还可以包括感测收听者的头部的特征,并且根据所述特征来调整头部相关传递函数。
[0244]
滤波可以包括时域滤波或频域滤波。
[0245]
物理音频换能器驱动信号可以相对于表示空间音频对象的所接收到的音频信号延迟至少25ms。
[0246]
所述系统还可以包括峰值幅度消减滤波器、限制器或压扩器,所述峰值幅度消减滤波器、限制器或压扩器被配置为减少组合的时间偏移的相应的虚拟音频换能器信号的物理音频换能器的饱和失真。
[0247]
所述系统还可以包括相位旋转器,所述相位旋转器被配置为旋转至少一个虚拟音频换能器信号的相对相位。
[0248]
空间化音频数据滤波器可以包括被配置为处理至少两个音频通道的数字信号处理器。空间化音频数据滤波器可以包括图形处理单元,所述图形处理单元被配置为处理至少两个音频通道。
[0249]
空间化音频数据滤波器可以被配置为进行串扰消除。空间化音频数据滤波器可以包括可重入数据滤波器。
[0250]
所述系统还可以包括输入端口,所述输入端口被配置为接收表示收听者的耳朵位置的信号。
[0251]
所述系统还可以包括输入端,所述输入端被配置为接收跟踪收听者的移动的信号,其中所述空间化音频数据滤波器是自适应地依赖于所跟踪的移动的。
[0252]
虚拟音频换能器信号可以被自适应地分配给相应的子集。
[0253]
空间化音频数据滤波器可以依赖于收听者的自适应地确定的头部相关传递函数。
[0254]
所述系统还可以包括输入端口,所述输入端口被配置为接收包括收听者的头部的感测到的特征的信号,其中头部相关传递函数根据所述特征进行调整。
[0255]
空间化音频数据滤波器可以包括时域滤波器和/或频域滤波器。
附图说明
[0256]
图1a是示出用于私人收听的波场合成(wfs)模式操作的图。
[0257]
图1b是示出将wfs模式用于多用户、多位置音频应用的图。
[0258]
图2是示出wfs信号处理链的框图。
[0259]
图3是用于wfs模式操作的控制点的示例性布置的图。
[0260]
图4是用于wfs模式操作的信号处理方案的第一实施例的图。
[0261]
图5是用于wfs模式操作的信号处理方案的第二实施例的图。
[0262]
图6a至图6e是一组极坐标图,相应地示出了在10000hz、5000hz、2500hz、1000hz和600hz的频率下波束被转向0度的原型扬声器阵列的测量性能。
[0263]
图7a是示出双耳模式操作的基本原理的图。
[0264]
图7b是示出如用于空间化声音呈现的双耳模式操作的图。
[0265]
图8是示出示例性双耳模式处理链的框图。
[0266]
图9是用于双耳模态的信号处理方案的第一实施例的图。
[0267]
图10是用于双耳模式操作的控制点的示例性布置的图。
[0268]
图11是用于双耳模式的信号处理链的第二实施例的框图。
[0269]
图12a和图12b相应地示出了在左耳测量和右耳测量的双耳模式下示例性扬声器阵列的预测性能的模拟频域和时域表示。
[0270]
图13示出了虚拟扬声器阵列和物理扬声器之间的关系。
具体实施方式
[0271]
在双耳模式下,扬声器阵列提供两个声音输出,对准主要收听者的耳朵。逆滤波器设计方法来自数学模拟,其中创建了近似真实世界的扬声器阵列模型,并且在整个目标声场中放置了虚拟传声器。创建或请求跨这些虚拟传声器的目标函数。使用正则化解决逆问题,为阵列中的每一个扬声器元件创建稳定且可实现的逆滤波器。对于每个阵列元素,源信号与这些逆滤波器进行卷积。
[0272]
在第二波束成形或波场合成(wfs)模式中,变换处理器阵列将表示多个离散源的声音信号提供给同一大致区域中的分离的物理位置。掩蔽信号也可以在幅度和时间上动态调整,以提供最佳的掩蔽和收听者感兴趣的信号的可理解性缺乏。
[0273]
wfs模式也使用逆滤波器。此模式不是将两个波束对准收听者的耳朵,而是将多个波束对准或导向阵列周围的不同位置。
[0274]
所述技术涉及一种数字信号处理(dsp)策略,允许双耳渲染和wfs/声音波束成形两者,可以单独使用,也可以同时使用。如上所述,然后针对少量物理换能器,例如2个或4个,组合虚拟空间化。
[0275]
对于双耳和wfs模式,通过一组数字滤波器对要再现的信号进行滤波处理。这些滤波器可以通过数值求解电声逆问题来生成。下面描述要解决的特定逆问题的特定参数。然而,通常,数字滤波器设计基于最小二乘意义上的最小化原则,即j=e βv类型的成本函数
[0276]
成本函数是两项之和:性能误差e,它衡量目标点处期望信号的再现效果;以及努力代价βv,它是一个与输入到所有扬声器的总功率成比例的量。正实数β是正则化参数,它确定分配给努力项的权重。注意,根据本实现方式,可以在求和之后,并且可选地在执行限制器/峰值消减函数之后,应用成本函数。
[0277]
通过将β从零变到无穷大,解决方案逐渐从仅最小化性能误差变为仅最小化努力成本。在实践中,此正则化是通过将扬声器的功率输出限制在反演问题病态的频率上来实现的。这是在不影响系统在反演问题条件良好的频率下的性能的情况下实现的。这样,可以防止再现声音的频谱中出现尖峰。如果需要,可以使用频率相关的正则化参数来选择性地衰减峰值。
[0278]
波场合成/波束成形模式
[0279]
wfs声音信号是为虚拟扬声器的线性阵列生成的,它限定若干分离的声音波束。在wfs模式操作中,可以通过使用窄波束将来自扬声器阵列的不同源内容导向不同的角度,以最大限度地减少收听期间对相邻区域的泄漏。如图1a中所示,使用由扬声器阵列72递送的
音乐和/或噪声的相邻波束,私人收听成为可能。直接声音波束74被目标收听者76收听到,而掩蔽噪声音波束78(可以是音乐、白噪声或不同于主声音波束74的一些其他信号)被引导到目标收听者周围,以防止周围区域内的其他人无意中偷收听。掩蔽信号也可以在幅度和时间上动态调整,以提供最佳的掩蔽和收听者感兴趣的信号的可理解性,如后面包含drcedsp块的图中所示。
[0280]
当虚拟扬声器信号被组合时,空间声音消除能力的重要部分丢失;然而,对于直接(即,非反射)声音路径,至少在理论上有可能优化在收听者中的每一个耳朵处的声音。
[0281]
在wfs模式下,阵列提供多个离散源信号。例如,三个人可以围绕阵列收听三个不同的源,彼此的信号几乎没有干扰。图1b示出了用于多用户/多位置应用的wfs模式的示例性配置。仅两个扬声器换能器,对每个收听者的完全控制是不可能的,尽管通过优化,可接受的(相对于立体声音频的改善)是可用的。如图中示出的,阵列72为收听者76a和76b中的每一者限定离散的声音波束73、75和77,声音波束中的每一个具有不同的声音内容。尽管两个收听者被示为接收相同的内容(三个波束中的每一个),但是不同的内容可以在不同的时间被递送到收听者中的一个或另一个。当阵列信号被求和时,一些方向性丢失,并且在一些情况下,被反演。例如,在将一组12个扬声器阵列信号相加为4个扬声器信号的情况下,定向消除信号在大多数位置可能无法消除。然而,优选地,对于最佳定位的收听者来说,适当的抵消是优选可用的。
[0282]
wfs模式信号通过dsp链生成,如图2中所示。离散源信号801、802和803各自与扬声器阵列信号中的每一个的逆滤波器卷积。逆滤波器是允许根据用于生成滤波器的数学模型中的规范,针对特定位置对局部化的音频波束进行优化的机制。可以实时进行计算,以提供即时优化的波束控制能力,这将允许用音频跟踪阵列的用户。在所示的示例中,扬声器阵列812具有十二个元件,因此对于每个源有十二个滤波器804。对应于相同的第n个扬声器信号的结果滤波信号在组合器806处相加,所述组合器的结果信号被馈送到多通道声卡808,所述多通道声卡具有对应于阵列中十二个扬声器中的每一个的dac。然后将十二个信号分成通道,即2个或4个,然后针对对应的阵列信号的物理位置和相应的物理换能器之间的位置差对每个子集的成员进行时间调整,并且求和,然后进行限制算法。然后使用d类放大器810放大限制信号,并且通过两个或四个扬声器阵列812递送到(一个或多个)收听者。
[0283]
图3示出了如何生成空间化滤波器。首先,假设给定了n个阵列单元的相对布置。限定一组m个虚拟控制点92,其中每个控制点对应于一个虚拟传声器。控制点布置在围绕n个扬声器阵列98的半圆上并且以扬声器阵列的中心为中心。弧96的半径可以随着阵列的大小而缩放。控制点92(虚拟传声器)均匀地布置在弧上,相邻点之间的角度距离恒定。
[0284]
计算m
×
n矩阵h(f),它表示阵列中每个扬声器和每个控制点之间的电声传递函数,作为频率f的函数,其中h
p
,l对应于(n个扬声器中的)第1个扬声器和第p个控制点92之间的传递函数。这些传递函数可以从扬声器的声辐射模型测量或分析限定。模型的一个示例是由声学单极子给出的,由下面的等式给出:
[0285]
其中c是声音传播的速度,f是频率,并且r
p,l
是第1个扬声器和第p个控制点之间的距离。
[0286]
代替在阵列信号被完全限定之后校正时间延迟,还可以在生成信号时使用正确的扬声器位置,以避免重新限定信号。
[0287]
如本领域已知的,通过多极展开可以获得每个扬声器的更高级的分析辐射模型。(参见,例如,v.rokhlin,“三维亥姆霍兹方程的平移算子的对角形式”,应用和计算调和分析,1:82-93,1993)。
[0288]
用m个元素限定向量p(f),表示由控制点92识别的位置处的目标声场,并且作为频率f的函数。目标字段有多种选择。一种可能性是将值1分配给识别(一个或多个)期望声音波束的(一个或多个)方向的(一个或多个)控制点,而将值零分配给所有其他控制点。
[0289]
数字滤波器系数在频率(f)域或数字采样(z)域中限定,是滤波器计算算法的输出的向量a(f)或a(z)的n个元素。滤波器可能有不同的拓扑结构,诸如fir、iir或其他类型。对于每个频率f或样本参数z,通过求解最小化例如以下成本函数j(f)=||h(f)a(f)-p(f)||2 β||a(f)||2的线性优化问题来计算向量a。符号||...||表示向量的l2范数,并且β是正则化参数,其值可以由设计者限定。标准优化算法可以用于数值求解上述问题。
[0290]
现在参考图4,系统的输入是任意一组音频信号(从a到z),称为声源102。系统输出是驱动扬声器阵列108的n个单元的一组音频信号(从1到n)。这n个信号被称为“扬声器信号”。
[0291]
对于每个声源102,输入信号通过一组n个数字滤波器104进行滤波,阵列的每个扬声器有一个数字滤波器104。这些数字滤波器104被称为“空间化滤波器”,其由上面公开的算法生成,并且作为(一个或多个)收听者的位置和/或要生成的声音波束的预期方向的函数而变化。
[0292]
数字滤波器可以实现为有限脉冲响应(fir)滤波器;然而,采用其他滤波器拓扑结构可以实现更高的效率和更好的响应建模,诸如采用反馈或可重入的无限脉冲响应(iir)滤波器。滤波器可以在传统的dsp架构中实现,或在图形处理单元(gpu,developer.nvidia.com/vrworks-audio-sdk-depth)或音频处理单元(apu,www.nvidia.com/en-us/drivers/apu/)中实现。有利地,声学处理算法被呈现为射线追踪、透明度和散射模型。
[0293]
对于每个声源102,通过第n个数字滤波器104滤波的音频信号(即,对应于第n个扬声器)在组合器106处与对应于不同的音频源102但是对应于相同的第n个扬声器的音频信号相加。求和的信号然后被输出到扬声器阵列108。
[0294]
图5示出了图4的双耳模式信号处理链的替代实施例,其包含使用可选部件,包含心理声学带宽扩展处理器(pbep)和动态范围压缩器和扩展器(drce),所述心理声学带宽扩展处理器(pbep)和动态范围压缩器和扩展器(drce)提供更复杂的动态范围和掩蔽控制、针对特定环境的滤波算法定制、房间均衡和基于距离的衰减控制。
[0295]
pbep 112通过生成较高频率的声音材料,允许收听者感知包含在音频频谱的较低部分中的声音信息,使用较高频率的声音提供较低频率的感知)。由于pbe处理是非线性的,所以它出现在空间化滤波器104之前是很重要的。如果在空间滤波器之后插入非线性pbep块112,其效果会严重降低声音波束的产生。
[0296]
重要的是要强调,使用pbep 112是为了补偿(心理声学上)扬声器阵列在较低频率的不良方向性,而不是补偿单个扬声器本身的不良低音响应,如现有技术应用中通常所做
的那样。
[0297]
dsp链中的drce114提供源信号的响度匹配,使得保持阵列108的输出信号的足够的相对掩蔽。在双耳渲染模式中,使用的drce是2通道块,其对两个传入通道进行相同的响度校正。
[0298]
如同pbep块112一样,因为drce114处理是非线性的,所以它出现在空间化滤波器104之前是重要的。如果要在空间滤波器104之后插入非线性drce块114,其效果会严重降低声音波束的产生。然而,如果没有此dsp块,dsp链和阵列的心理声学性能也会降低。
[0299]
另一个可选部件是收听者跟踪设备(ltd)116,其允许所述设备接收关于(一个或多个)收听者的位置的信息并且实时动态地调整空间化滤波器。ltd 116可以是检测收听者头部移动的视频跟踪系统,或可以是本领域中已知的另一个类型的移动感测系统。ltd 116生成收听者跟踪信号,所述信号被输入到滤波器计算算法118中。可以通过实时重新计算数字滤波器或通过从预先计算的数据库加载不同的滤波器组来实现自适应。替代用户定位包含雷达(例如心跳)或激光雷达跟踪rfid/nfc跟踪、呼吸声等。
[0300]
图6a至图6e是原型阵列的辐射方向图的极坐标能量辐射图,所述原型阵列由在wfs模式下操作的dsp方案在10,000hz、5,000hz、2,500hz、1,000hz和600hz五个不同频率下驱动,并且用波束转向0度的传声器阵列测量。
[0301]
双耳模式:用于双耳模式的dsp包括将要再现的音频信号与表示头部相关传递函数(hrtf)的一组数字滤波器的卷积。
[0302]
图7a示出了在双耳模式操作中使用的基本方法,其中扬声器位置10的阵列被限定为产生特殊形成的音频束12和14,所述音频束和可以被分别递送到收听者的耳朵16l和16r。使用此模式,波束本身就能消除串扰。然而,在通过较少数量的扬声器进行总结和演示之后,这是不可用的。
[0303]
图7b示出了在多个位置与多方进行的假想视频会议呼叫。当位于纽约的一方正在说话时,声音好像来自与拼接显示器18中扬声器的视频图像相协调的方向被递送。当洛杉矶的参与者说话时,声音可以与所述扬声器的图像在视频显示中的位置相协调地递送。即时双耳编码也可以用于递送令人信服的空间音频耳机,避免现有技术耳机设置中经常出现的声音明显错位。
[0304]
如图8中示出的,双耳模式信号处理链由多个离散的源组成,在中示出的示例中,有三个源:源201、202和203,它们然后与双耳头部相关传输函数(hrtf)编码滤波器211、212和213卷积,所述滤波器对应于从标称扬声器位置到收听者的期望虚拟传输角度。每个声源有两个hrtf滤波器,一个用于左耳,一个用于右耳。所得到的左耳的hrtf滤波信号被全部加在一起,以生成对应于将被收听者左耳收听到的声音的输入信号。类似地,收听者右耳的hrtf滤波信号被加在一起。然后,得到的左耳和右耳信号相应地与逆滤波器组221和222卷积,其中虚拟扬声器阵列中的每一个虚拟扬声器元件一个滤波器。然后,经由进一步的时空变换、组合和限制/峰值消减,将虚拟扬声器组合成真实扬声器信号,并且经由多通道声卡230和d类放大器240(每个物理扬声器一个)将所得的组合信号发送到对应的扬声器元件,用于经由扬声器阵列250向收听者进行音频传输。在双耳模式中,本发明生成馈送虚拟线性阵列的声音信号。虚拟线性阵列信号被组合成扬声器驱动信号。扬声器向主要收听者的耳朵提供两个声音波束-一个声音波束用于左耳,并且一个声音波束用于右耳。
[0305]
图9示出了具有声源a到z的双耳模态的双耳模式信号处理方案。如参考图8所述,系统的输入是一组声源信号32(a到z),系统的输出相应地是一组扬声器信号38(1到n)。对于每个声源32,输入信号通过表示左右头部相关传递函数的两个数字滤波器34(hrtf-l和hrtf-r)滤波,所述传递函数是针对给定声源32打算渲染给收听者的角度计算的。例如,说话者的声音可以被渲染为从收听者右侧30度到达的平面波。hrtf滤波器34可以从数据库中获取,或可以使用双耳处理器实时计算。在hrtf滤波之后,对应于不同声源但对应于同一个耳朵(左耳或右耳)的经处理的信号在组合器35处被合并且在一起。这生成两个信号,以下相应地称为“总双耳信号-左”或“tbs-l”和“总双耳信号-右”或“tbs-r”。
[0306]
两个总双耳信号tbs-l和tbs-r中的每一者都通过一组n个数字滤波器36进行滤波,每个数字滤波器用于一个扬声器,使用下面公开的算法进行计算。这些滤波器被称为“空间化滤波器”。为了清楚起见,强调用于右总双耳信号的空间化滤波器组不同于用于左总双耳信号的空间化滤波器组。
[0307]
对应于相同的第n个虚拟扬声器但是针对两个不同耳朵(左耳和右耳)的滤波后的信号在组合器37处被相加在一起。这些是虚拟扬声器信号,其馈送到组合器系统,组合器系统又馈送到物理扬声器阵列38。
[0308]
用于双耳模态的空间化滤波器36的计算算法类似于用于上述wfs模态的算法。与wfs情况的主要区别在于,在双耳模式中仅使用了两个控制点。这些控制点对应于收听者耳朵的位置,并且如图10中所示布置。表示收听者耳朵的两个点42之间的距离在0.1m和0.3m的范围内,而每个控制点和扬声器阵列48的中心46之间的距离可以随着使用的阵列的大小而缩放,但是通常在0.1m和3m之间的范围内。
[0309]
使用每个扬声器和每个控制点之间的电声传递函数的元素来计算2
×
n矩阵h(f),作为频率f的函数。如上所述,这些传递函数既可以测量或可以分析计算。限定一个2元素向量p。此向量可以是[1,0]或[0,1],这取决于空间化滤波器是相应地为左耳还是右耳计算的。给定频率f的滤波器系数是通过最小化以下成本函数j(f)=||h(f)a(f)-p(f)||2 β||a(f)||2计算的向量a(f)的n个元素。如果多个解是可能的,则选择对应于a(f)的l2范数的最小值的解。
[0310]
图11示出了图9的双耳模式信号处理链的可选实施例,其包含使用可选部件,包含心理声学带宽扩展处理器(pbep)和动态范围压缩器和扩展器(drce)。pbep 52通过生成较高频率的声音材料,允许收听者感知包含在音频频谱的较低部分中的声音信息,使用较高频率的声音提供较低频率的感知)。因为pbep处理是非线性的,所以它出现在空间化滤波器36之前是很重要的。如果在空间滤波器之后插入非线性pbep块52,其效果会严重降低声音波束的产生。
[0311]
重要的是要强调,使用pbep 52是为了补偿(心理声学上)扬声器阵列在较低频率的不良方向性,而不是补偿单个扬声器本身的不良低音响应。
[0312]
dsp链中的drce 54提供源信号的响度匹配,使得保持阵列38的输出信号的足够的相对掩蔽。在双耳渲染模式中,使用的drce是2通道块,其对两个传入通道进行相同的响度校正。
[0313]
如同pbep块52一样,因为drce 54处理是非线性的,所以它出现在空间化滤波器36之前是重要的。如果要在空间滤波器36之后插入非线性drce块54,其效果会严重降低声音
波束的产生。然而,如果没有此dsp块,dsp链和阵列的心理声学性能也会降低。
[0314]
另一个可选部件是收听者跟踪设备(ltd)56,其允许所述设备接收关于(一个或多个)收听者的位置的信息并且实时动态地调整空间化滤波器。ltd 56可以是检测收听者头部移动的视频跟踪系统,或可以是本领域中已知的另一个类型的移动感测系统。ltd 56生成收听者跟踪信号,所述收听者跟踪信号被输入到滤波器计算算法58中。可以通过实时重新计算数字滤波器或通过从预先计算的数据库加载不同的滤波器组来实现自适应。
[0315]
图12a和图12b示出了用于双耳模式的算法的模拟性能。图12a示出了左耳和右耳的目标位置处的模拟频域信号,而图12b示出了时域信号。两个图都清楚地示出了以一只耳朵为目标的能力,在此情况下,以左耳为目标,具有期望的信号,同时最小化在收听者的右耳检测到的信号。
[0316]
wfs和双耳模式处理可以结合到单个装置中,以产生总声场控制。此类方法将结合将选择的声音波束导向目标收听者的优点,例如为了隐私或增强的可理解性,以及单独控制递送到收听者耳朵的声音混合以产生环绕声。所述装置可以替代地或组合地使用双耳模式或wfs模式来处理音频。尽管本文没有具体示出,wfs和双耳模式两者的使用将由图5和图11的框图表示,它们相应的输出在信号求和步骤由组合器37和106组合。wfs和双耳模式两者的使用也可以通过结合图2和图8中的框图来示出,它们相应的输出在多通道声卡230之前的最后一个求和块处被加在一起。
[0317]
示例
[0318]
根据u.s.9,578,440实现了12通道空间化虚拟音频阵列。此虚拟阵列提供信号,用于驱动位于收听者面前的线性或曲线等间距阵列,例如12个扬声器。虚拟阵列分为两个或四个。在两个的情况下,“左”例如6个信号被导向左物理扬声器,并且“右”例如6个信号被导向右物理扬声器。用至少两个中间处理步骤将虚拟信号相加。
[0319]
第一中间处理步骤补偿虚拟扬声器的标称位置和扬声器换能器的物理位置之间的时间差。例如,最靠近收听者的虚拟扬声器被分配参考延迟,而更远的虚拟扬声器被分配增加的延迟。在典型情况下,虚拟阵列的位置使得相邻虚拟扬声器的时间差递增变化,尽管可以实现更严格的分析。在48khz采样率下,最近和最远虚拟扬声器之间的差异可以是例如4个周期。
[0320]
第二中间处理步骤限制了信号的峰值,以避免过度驱动物理扬声器或导致显著失真。此限制可以是频率选择性的,因此仅一个带受到此过程的影响。此步骤应在延迟补偿之后进行。例如,可以采用压扩器。替代地,假设仅罕见的峰值,可以采用简单的限制。在其他情况下,可以采用更复杂的峰值消减技术,诸如一个或多个通道的相移,典型地基于信号的预测峰值,所述预测峰值从其实时呈现稍微延迟。注意,此相移改变了第一中间处理步骤的时间延迟;然而,当达到系统的物理限制时,折衷是必要的。对于12个扬声器和2个物理扬声器的虚拟线阵列,物理扬声器位置在元件3-4和9-10之间。如果(s)是扬声器之间的中心到中心的距离,那么从阵列中心到每个真实扬声器中心的距离是:a=3s。左扬声器从中心偏移-a,并且右扬声器偏移a。
[0321]
第二中间处理步骤主要是利用限制器和/或压缩器或其他处理来提供峰值消减的六个虚拟通道的下混,应用所述处理来防止饱和或削波。例如,左通道是:l
输出
=限制(l1 l2 l3 l4 l5 l6)
[0322]
并且正确的通道是r
输出
=限制(r1 r2 r3 r4 r5 r6)
[0323]
在下混之前,需要考虑与物理扬声器换能器和收听者耳朵相比,虚拟扬声器和收听者耳朵之间的延迟差异。由于虚拟扬声器阵列的长度与声音波长的比率增加,此延迟在较高频率下尤其显著。为了计算从收听者到每个虚拟扬声器的距离,假设扬声器n被编号为1至6,其中1是离中心最近的扬声器,并且6是离中心最远的。从阵列中心到扬声器的距离是:d=((n-1) 0.5)*s。使用勾股定理,从扬声器到收听者的距离可以计算为:1) 0.5)*s。使用勾股定理,从扬声器到收听者的距离可以计算为:
[0324]
从真实的扬声器到收听者的距离是
[0325]
每个扬声器的样本延迟可以通过两个收听者之间的距离差来计算。这可以将它们转换为样本(假设声速为343m/s,采样率为48khz。
[0326]
这可能导致收听者距离之间的显著延迟。例如,如果虚拟阵列扬声器间距离为38mm,并且收听者距离阵列500mm,则从虚拟最左侧扬声器(n=6)到真实扬声器的延迟为:38mm,并且收听者距离阵列500mm,则从虚拟最左侧扬声器(n=6)到真实扬声器的延迟为:
[0327][0328]
在更高的音频频率下,即12khz,完整的波周期是4个样本,差值等于360
°
相移。见表1。
[0329]
因此,当将用于虚拟扬声器的信号组合成物理扬声器信号时,优选地基于虚拟扬声器相对于物理扬声器的位移来补偿时间偏移。时间偏移也可以在空间化算法中完成,而不是作为后处理。
[0330]
本发明可以用软件、硬件或硬件和软件的组合来实现。本发明也可以体现为计算机可读介质上的计算机可读代码。计算机可读介质可以是能够存储数据的任何数据存储装置,所述数据随后可以被计算装置读取。计算机可读介质的示例包含只读存储器、随机存取存储器、cd-rom、磁带、光学数据存储装置和载波。计算机可读介质也可以分布在网络联接的计算机系统上,使得以分布式方式存储和执行计算机可读代码。
[0331]
根据书面描述,本发明的许多特征和优点是显而易见的,因此,所附权利要求意图覆盖本发明的所有这些特征和优点。此外,由于本领域技术人员将容易想到许多修改和变化,所以不期望将本发明限制于所示出和描述的确切配置和操作。因此,所有合适的修改和等效物都可以被视为落入本发明的范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。