1.本公开属于自然语言语音识别领域,并且更具体地,属于使用被配置为接收用户骨骼的振动来识别用户说出的词语的加速度计的领域。
背景技术:
2.当前使用各种方法和系统来识别用户说出的词语。当今可用的大多数设备均使用声学麦克风,声学麦克风可以使用音频气流检测器来拾取用户说出的词语。声学麦克风被用于检测与用户在户外说出的,来自用户喉头的用户言语相对应的声频信号。附加地,现有技术中的一些设备使用结合有加速度计的一个或多个麦克风来检测用户的言语振动,加速度计位于用户的耳塞中,其中耳塞为有线或无线扬声器并且位于用户耳朵中的麦克风设备。然而,与声学麦克风结合使用的这些加速度计被用作语音活动检测器,而不是被用于识别或标识已说出的词语。现有技术的这些设备中的每一个设备在其中用户不能清楚地对词语进行发音以供声学麦克风识别的情况下词语有效识别用户说出的词语方面具有许多缺点。在用户具有生理缺陷导致他们不能清晰地言语的情况下,由麦克风拾取的声学信号不足以执行词语甚至语音识别。
技术实现要素:
3.根据本公开,语音命令识别和自然语言识别使用加速度计来执行,加速度计感测来自用户的一个或多个骨骼的振动的信号。由于词语识别仅使用来自加速度计的信号就可以进行,因此不需要声学麦克风,并且因此声学麦克风不用于收集用于词语识别的数据。骨传导是声音通过颅骨的骨骼传导到内耳的传导。
4.根据一个实施例,壳体包含加速度计和处理器,两者均在同一壳体内。加速度计优选地是mems加速度计,其能够感测正在说出词语的用户的骨骼中存在的振动。处理器位于与mems加速度计相同的壳体内并与加速度计电耦合。处理器被配置为处理在从加速度计的信号中接收到的感测振动并输出指示用户说出的词语的标识的信号。
5.在一个实施例中,壳体被定位为环绕用户的颈部并且在壳体的一个位置处包含mems加速度计以及用于接收来自mems加速度计的信号的处理器。当壳体被定位在用户的颈部靠近喉部(也称为喉头)时,来自舌骨的振动被感测。根据另一实施例,壳体被定位为邻近用户的下巴骨来感测从用户的下巴骨传导的振动,而在另一实施例中,加速度计被定位为邻近用户的腭骨,以感测用户上颚的振动。
6.训练和识别用户说出的词语的方法包括创建和感测与已说出的已知词语相对应的音频振动的参考集。用户说出已知词语,则使用加速度计来感测来自用户骨骼的振动。基于所感测的参考振动,将与所说出的词语相对应的参考信号或样本信号从加速度计输出到处理器。参考信号被存储来训练函数并在训练函数之后在推断步骤或使用时标识所说出的词语的匹配项。输入是从另一源接收的,另一源提供已知与参考信号匹配的词语的标识。例如,在参考数据被收集时,显示器可以提示用户说出已知词语。备选地,已知词语可以来自
键盘输入、鼠标输入或来自计算机的其他选择,计算机标识说出的词语导致参考信号的生成。然后参考信号被存储为已提供的词语的匹配项。该过程被重复多次来获得相同词语的附加参考信号,以训练可以是神经网络的分类模型。它还针对不同的词语重复多次,使得大量的参考词语被训练。分类模型被训练为使用用于训练函数的参考来将不同的信号分类为不同的词语。
7.在稍后的时间点,使用加速度计来感测来自用户的骨传导的音频振动样本集。样本信号基于样本感测振动,从加速度计输出。分类模型接收样本信号并输出标签值。执行阈值确定以确定标签值是否在所存储词语的阈值内。如果标签值在参考词语的阈值内,则样本信号被确定为与存储词语匹配。一旦匹配被确定,所存储的词语作为与加速度计感测的音频振动样本集相对应的所说出的词语而被输出。
8.具有或没有言语或发音挑战的个体用户可以在训练阶段或步骤中与该自然语言识别系统进行交互。在高声学噪声环境中,当麦克风受到噪声影响且传统言语识别例程失败时,加速度计音频可能是有利的。该系统可以具有诸如通过在计算机或膝上型计算机的监视器上或在诸如手机或平板计算机的手持电子设备上显示词语来提示用户说出选定词语集的训练步骤程序。系统可以显示第一词语(诸如球),并诸如以显示器上提示的节奏提示用户一次或多次说出词语。位于用户身上(诸如靠近用户颈部)的检测设备被部分搁置在斜角肌或斜方肌以及用户颈部后部。检测设备是受损言语辅助设备。该检测设备可以是用户头部中的植入单元或者可以与用户分离,但靠近用户头部而定位。
9.当用户发音或说出所提示的词语时,检测设备将收集指示由该用户发音的所提示的词语的振动信息。系统可以在训练步骤或预训练步骤期间收集每个词语的一个样本或一系列样本。每个样本均作为来自加速度计并且与由于词语发音引起的骨振动相对应的信号来传输。该样本信号作为输入传输到计算机或远程服务器上存储的函数、算法或神经模型。该函数的输出是n(诸如n=11)个标签的集合,其中每个标签可以表示词语。该函数是通过收集用户发音的一组词语而生成的神经模型。函数在从用户收集一些信号之后在训练步骤中进行开发。构建函数的训练步骤可以与收集样本异步发生。一旦针对特定用户构建了函数,函数就可以被存储在设备中或由用户实时访问以从模型中受益,即,用户可以利用检测设备来帮助用户与他人更有效地沟通。模型的使用可以被称为推断步骤。
10.作为函数的神经模型可以由权重矩阵表示。模型的生成使用或学习待被识别的词语集合或来自加速度计并表示当词语被发音时的振动的信号集合。因此,例如,神经模型可以通过处理11个词语来创建,其中针对每个词语收集3-4个信号,即,系统收集并存储同一词语的3-4次不同重复的加速度计信号。系统可以从同一词语的3-4次不同重复中创建频谱图和更多特征,以生成100个或更多生成的样本。
11.1100个信号的数据集被创建(100个生成的样本信号
×
11词语=1100个信号)。该数据集可以被用于训练神经模型。在该训练过程结束时,神经模型被创建。神经模型可以被认为是接收输入信号、输出11个标签中的一个标签的函数。一旦模型被创建,模型将保持不变并且被用于接收言语并提供言语解释。为了使用新模型,例如,能够识别更多标签,有必要使用包含新词语的增强数据集来重新训练神经网络。数据的收集和神经网络的训练是“离线”或异步的过程。系统在使用时对词语的识别来自于通过函数或神经模型运行信号来标识词语。
12.该技术对于不能清楚地说出词语的用户特别有用。各种用户可能具有不允许用户将声波清晰地输出到空气中的生理缺陷。根据本公开,仍然可以基于在用户的颈部、耳朵、上颚、下巴或颅骨中感测到的振动来正确识别所说出的词语。附加地,一些用户可能具有各种言语障碍,诸如颈部受伤、喉头、上颚、嘴巴、牙齿的生物学缺陷或其他残疾,这些言语障碍会妨碍清晰地说出可以被声学麦克风识别的词语。即使与该词语相对应的声学声音不能被识别,使用感测来自用户骨骼的振动的加速度计的本技术也允许清楚地识别用户说出的词语。此外,该技术在存在高水平环境噪声并且麦克风通过空气的声音接收性能下降的情况下很有用。该系统可以被用于麦克风收集的环境噪声水平较高的区域,以使用户的语音可以仅通过骨振动来收集。
附图说明
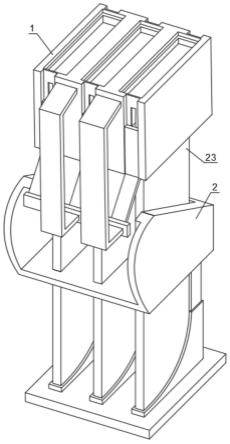
13.图1是放置在用户颈部周围的壳体的透视图,壳体用于基于由加速度计感测的颈部中骨骼的传导来识别词语。
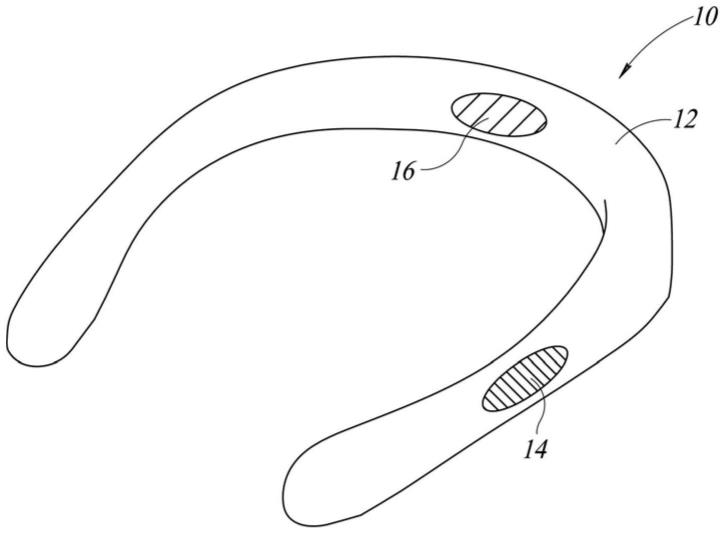
14.图2是用户穿戴图1的颈部壳体的示意图。
15.图3是关于感测来自用户骨骼的声学信号的传导并识别所说出的词语的框图。
16.图4a表示由加速度计感测的第一个说出的词语的xy加速度信号。
17.图4b是图4a中感测的加速度的频谱图。
18.图4c是针对用户说出的不同词语的基于骨传导的xy加速度信号。
19.图4d是图4c的信号的频谱图。
20.图5是根据本公开的原理的用于识别所说出的词语的系统的框图。
21.图6是基于骨传导来识别所说出的词语的另一实施例。
22.图7是围绕颈部定位的壳体的等距视图,壳体还包括扬声器。
23.图8是包含用于定位在用户耳朵中的加速度计的壳体。
24.图9是用于邻近用户的腭骨(邻近上颚)而定位的壳体的视图。
25.图10a和图10b图示了用户在具有位于下巴和前额上的壳体中的加速度计的情况下说话的情形。
26.图11图示了仅位于用户下巴上的壳体。
27.图12是图示了针对使用多个运动-言语传感器的语音识别的一个实施例的框图。
28.图13图示了数据被收集来训练分类模型的一个方法。
29.图14图示了根据本文所述的系统的言语识别方法。
30.图15是基于他们说出的不同短语的骨传导感测而收集的数据。
31.图16a是从没有语言障碍的三个不同个体收集的相同短语的数据。
32.图16b是基于从具有严重语言障碍的三个不同个体的相同短语的骨传导而收集的数据。
33.图17a是使用第一种类型的递归(recurrent)训练来语音识别没有语言障碍地说出清楚、可听的词语的个体的模型损失度(loss)的曲线图。
34.图17b是使用第一类型的递归训练来语音识别没有语言障碍地说出清楚、可听的词语的个体的模型的准确度的曲线图。
35.图17c是使用第一类型的递归训练来语音识别具有严重声音和音频语言障碍的个
体的模型损失度的曲线图。
36.图17d是使用第一类型的递归训练来语音识别具有严重声音和音频语言障碍的个体的模型的准确度的曲线图。
37.图18a是使用第二类型的递归训练来识别没有语言障碍地说出清楚、可听的词语的个体的模型损失度的曲线图。
38.图18b是使用第二类型的递归训练来识别没有语言障碍地说出清楚、可听的词语的个体的模型的准确度的曲线图。
39.图18c是使用第二类型的递归训练来识别具有严重声音和音频语言障碍的个体的模型损失度的曲线图。
40.图18d是使用第二类型的递归训练来识别具有严重声音和音频语言障碍的个体的模型的准确度的曲线图。
41.图19a和图19b示出了使用用于骨传导感测的加速度计的句子结构构建。
42.图20a和图20b示出了使用用于骨传导感测的加速度计的附加句子结构构建。
43.图21是示出使用骨传导感测的词语识别算法的流程图。
具体实施方式
44.图1示出了用于使用一个或多个加速度计来识别言语的系统10,加速度计基于骨传导和用户身体内的其他振动来感测来自用户身体的振动,而不是使用麦克风来识别言语。根据系统10的一个实施例,它包括用于围绕用户颈部而定位的壳体12。壳体12包括加速度计14以及与加速度计电耦合的微处理器16。
45.系统10被配置为不论用户的言语能力如何而收集和处理来自高噪声环境的加速度计音频信号。加速度计音频不受噪声环境的影响。在这些高噪声环境下,麦克风言语识别可能会失败,而加速度计振动检测仍然可以准确有效地识别用户的言语。在一些实施例中,麦克风将不包括在壳体12中。
46.壳体12在第一臂和第二臂从其延伸的中央部分中具有弯曲形状。第一臂和第二臂朝向用户颈部的前部弯曲,并且被配置为邻近地定位速度计14,并且在一定距离内检测用户的舌骨、颌骨或颅骨的其他骨骼中的骨振动。加速度计14被定位在第一臂上。在备选实施例中,第二加速度计可以被定位在第二臂中。壳体12将包括与处理器和加速度计耦合的电源,诸如电池。壳体可以包括无线充电设备或者可以包括与电源耦合来对电池充电的端口。壳体可以包括无线收发器,无线收发器传输从加速度计收集的信号,或者当被耦合到单独的计算机或平板计算机时可以传输数据。
47.壳体12可以由柔性材料制成,诸如在用户皮肤上令人舒适的硅树脂。壳体12可以包括内部柔性骨架,该骨架可以弯曲到一个位置并保持该位置来允许用户舒适并有效地定位用于言语检测的第一臂和第二臂。
48.在备选实施例中,能够实现真正的无线立体声的耳塞对将在该耳塞对中包括至少一个加速度计。例如,左耳塞可以包括扬声器、麦克风、加速度计、处理器和电池。处理器被配置为发射和接收信号,诸如扬声器待播放的声音信号、麦克风收集的任何音频信号、以及加速度计收集的振动或加速度信号。右耳塞可以包括扬声器、麦克风、处理器和电池。
49.在不同的配置中,左右耳塞两者将各自包括扬声器、麦克风、加速度计、处理器和
电池。在又一备选方案中,左耳塞和右耳塞可以省略麦克风。
50.图2图示了用于围绕用户的颈部定位的壳体12的优选实施例的操作。具体地,用户18使得壳体12围绕其颈部20定位。壳体12包括加速度计14,加速度计14被定位为接收源自用户18的颈部20的振动22。振动22包括骨传导振动、喉咙振动运动以及用户说话时发生的其他加速度。当用户说出词语时,产生所说出的词语的声学振动24。然而,系统10不会感测或拾取声学振动24。相反,系统10没有输入来接收基于用户说话时说出的词语或空气的运动的声学振动。识别言语的唯一输入是与用户身体相邻或耦合的加速度计。
51.如图2所示,当用户说话时,源自用户颈部20的振动22被加速度计14拾取并且与振动相对应的信号被发送到处理器。振动将至少部分地基于当用户说出特定词语时振动的骨传导。对于与颈部耦合的壳体,这可能是颈骨或舌骨。当词语被说出时,与振动相对应的信号从加速度计14发送并由处理器16接收。如本文别处更详细解释的,处理器16执行振动分析并识别已说出的词语。
52.图3图示了根据本公开的原理的用于执行所说出的词语的识别的系统的框图。如图3所示,加速度计14接收基于骨传导和身体移动(诸如用户说出词语时头部的位置)的振动22。加速度计在x、y和z轴上感测振动。加速度计14接收信号并将它们作为运动信号传输到处理器16。处理器16包含从加速度计14接收运动信号的运动信号接收电路或模块28。在运动信号在运动信号接收模块28中被接收之后,它们被输出到滤波和分割电路30,滤波和分割电路还可以包括语音激活检测电路。根据一个实施例,滤波和分割和/或语音活动检测电路30检测到正在说出的词语并激活根据本公开的识别算法。备选地,框30不是必需的,并且在一些实施例中不使用。相反,来自运动信号接收模块28的输出被直接输入到频谱图和特征提取模块32。处理器16内的频谱图和特征提取模块32执行从运动创建频谱图并且还从已感测的运动信号中提取各种特征。所创建的频谱图和特征提取被输入到定制的语音识别电路34,语音识别电路根据本文其他地方公开的原理来执行语音识别。在一个实施例中,定制的语音识别电路模块34可以在处理器16中,而在其他实施例中,它可以在单独的处理器中,例如,在台式计算机、膝上型计算机上,或者云中处理器上,其在执行定制的语音识别训练和功能。在一个实施例中,定制的语音识别模块34可以在稍后的时间批量处理频谱图和特征提取,而不是对每个振动22做出响应。
53.定制的语音识别模块34内为人工智能训练模块36。如本文其他地方所述,人工智能训练模块36执行机器学习,以将分类模型训练为识别各种动作并将它们分类为已由特定用户说出的选定词语中的一个选定词语。人工智能训练如图13所示进行,使得用户所说出的词语可以被具体识别。
54.在一个实施例中,用户开始训练程序,程序将提示用户多次说出词语或一系列词语(短语)。训练程序将收集与每个提示词语或一系列词语相关联的加速度计输出,并将其存储在壳体中的存储器中,诸如存储在处理器或独立存储器中。存储器可以存储频谱图和从提取模块32提取的特征。该提取模块32可以被存储在处理器中。一旦测试或训练数据集被收集,神经模型就被训练以创建函数,该函数被配置为对所接收的用户语音模式进行分类并针对所提示的词语或短语标识标签。一旦函数被创建,函数可以被存储在壳体中,以在无需连接到无线网络(例如蜂窝网络或wi-fi)的情况下,进行实时言语识别。该函数由语音命令识别模块38表示。
55.训练在训练模块36中执行,训练模块36可以被容纳在远程系统中,远程系统以无线方式或通过有线连接来接收训练数据。神经模型生成针对每个单独的用户来创建定制的语音识别的函数。系统可以被配置为为了语音命令目的,而训练预定数量的特定词语和短语。备选地,系统可以被配置为训练自然语言言语识别。不同之处在于收集和训练神经模型的词语和短语的时间和数量。
56.在识别词语的特定序列的训练在定制的语音识别电路模块34中被执行之后,分类模型或函数被存储在处理器16内的存储器中,或者被存储在可以与个人计算机或者云相关联的另一远程文件中,并且然后进行保存以供将来在语音识别中使用。对于具有特定的、有限的词语或短语的集合的实施例,诸如对于语音命令,函数将具有在被加载或编程到处理器16中之前训练的n个标签。标签可以包括与标签相关联的指令,一旦指令被函数标识,将触发处理器或单独的支持物联网的设备的动作(诸如在框42中)。例如,用户可以说“锁定前门”,并且与该短语相关联的标签将激活单独的程序,该单独的程序与安装在用户前门处的无线锁定系统耦合。
57.在稍后的时间点,在分类模型被创建之后,如图2所示的用户说出词语,并且来自所说出的词语的振动22被加速度计14拾取并且被输入到运动信号电路28。针对运动信号电路28,它们被输入到频谱图和特征提取模块32。在电路的语音识别操作期间,频谱图和特征提取信号被直接发送到语音命令识别模块38,语音命令识别模块38预先接收并在其中存储由语音识别电路34提供的分类模型。在所说出的词语被识别之后,可以采取附加动作,例如,所识别的词语可以被发送到文本至言语模块40,文本至言语模块将所说出的词语转换为文本并将所说出的词语转换为言语并从扬声器输出所说出的词语,使得所说出的词语可以被清楚地听到。备选地或附加地,所识别的词语可以被发送到功能激活电路42来激活某些功能,例如,打开灯、开门、打开计算机、移动轮椅或采取其他动作。
58.现在将更详细地描述可以使用本公开的特定语音识别设备的上下文,以更好地理解其中提供的益处。
59.通常,人们有许多会影响他们说出清晰词语的能力的因素。一个人可能有残疾、疾病或其他状况,使他们难以或不可能清楚地说出可以通过正常声学过程听到的词语。例如,人可能中风,可能变老并且无法通过嘴大声说话,并且可能进行过牙科治疗,可能在他们的口腔、喉咙、颈部、上颚或他们身体的其他部位受伤。
60.当一个人具有语音限制条件时,他们仍然能够移动他们的颈部、身体、上颚或其他身体部位来说出词语,但是,该词语使用标准的声学过程并不能清楚地被听到。例如,用户可能正试图说“早上好”,但可能发出的唯一的声音会在听觉上被听到为短促的咕噜声,诸如“grr”或“grrrn”。因此,尽管用户已尝试说词语“早上好”词语,但实际上用户附近的人所说和听到的声学词语根本不会听到所识别的词语。然而,用户总是期望与他们周围的听众交流词语,使得他们可以参与正常的社交互动或执行某些命令。本公开的系统使得这成为可能。
61.图4a示出了信号48,信号48的振幅52被示出为当第一个词语被说出时,加速度计随时间在水平轴50上感测的x和y加速度信号的总和。
62.图4b是图4a中感测的加速度的频谱图54。众所周知,频谱图处于随着时间感测的频域中。
63.图4c示出了信号56,信号56的振幅被示出为当第二个不同的词语被说出时,加速度计随时间在水平轴50上感测的x和y加速度信号的总和。
64.图4d是图4c中感测的加速度的频谱图58。
65.图5是用于执行说话来识别所说出的词语,然后输出言语的备选实施例的框图。根据图5的实施例,骨传导在用户说出词语时发生。当词语被说出时,在运动信号传感器电路22中的加速度计14中感测到运动。然后来自加速度计14的信号被发送到处理器,以在步骤44中进行处理器分析。如果适当的训练没有被完成,则在初始训练计划期间,信号将被发送到训练模块34,在训练模块34中基于加速度计或传感器的特定位置以及如本文别处描述的所说出的词语进行训练。由于加速度计可以被定位在相对于用户身体的不同位置处,因此可以针对每个单独的加速度计14进行一些训练,这将基于该加速度计相对于用户的位置而创建自定义数据集。分类模型被创建在训练模块34中,并且然后可供其他处理器使用。在图5的实施例中,云服务46执行自然语言处理,以便对已说出的词语进行自然语言识别。在图5的具体实施例中,函数可以被存储在云中,并且使用云资源进行标识已说出的特定词语的处理。这被与图3中其中所有资源均被包含在同一壳体10内的实施例进行比较。具体地,在图3的实施例中,包括所有训练软件和所有数据库或存储器位置的处理器均被存储在相同的壳体10并且处理器16与加速度计14相邻。对于图5的实施例,训练模块34以及识别模块46在远程处理器中被执行,诸如在距远程服务器一定距离,在云服务或经由互联网连接访问的其他远程位置中执行。在所说出的词语已被识别之后,词语的标识从模块46输出到文本至言语引擎48。文本至言语引擎48可以在云中,或者备选地,如图3中所解释的,它可以位于与用户设备10在同一壳体中的本地处理器处。优选地,在图5的实施例中,文本至言语分析在诸如云远程服务器中被远程执行,并且然后用于创建所说出的语音的信号经由适当的连接(无论是互联网、无线还是其他可接受的技术)发送回本地用户。在图5的实施例中,本地壳体10几乎没有本地处理资源。在图5的实施例中,所有本地资源均可以在单个半导体芯片上执行,单个半导体芯片包括加速度计以及分析信号并将其发送到壳体10中不存在的附加处理器执行分析和词语识别的远程位置所需的任何处理。因此,在一个实施例中,处理器模块44位于远程服务器中,并且用于执行识别的处理器16与加速度计14不在同一壳体中。
66.图6示出了其中大量云资源被使用来将用户说出的短语转换为由与用户相邻的本地扬声器输出的词语的实施例。在图6的实施例中,当用户说话时,由加速度计14感测的骨传导振动22被创建并且运动信号在模块28中被创建。然后在模块28中创建的运动信号被输出到可以在任何可接受的位置处的词语识别模块50。模块50可以是用户本地的,并且在与耦合到用户的设备相同的壳体10中,或者,它可以在远程位置处,并且使用用户不具备的处理能力来执行。在图6的实施例中,词语识别模块50包含存储在其中的分类模型以及与该特定用户的经识别的已说出的词语的链接,并且因此完整的词语识别发生在模块50内。在词语被识别之后,词语的标识被输出到商业上可用的转录服务,在该实施例中是亚马逊转录服务52。亚马逊转录服务执行适当的处理,其可以包括自然语言处理,以便识别已说出的短语的特性、上下文、语句结构和含义。然后所说出的短语可以被输出到文本至言语引擎54,文本至言语引擎54在所示示例中是由亚马逊(amazon)和amazon polly出售的可商用的文本至言语模块54。amazon polly 54将创建语音,并且然后将已说出的语音输出到适当的扬声器,使得聆听者可以听到该人所说出的内容。
67.如果用户正在与远程的人交谈,图5和图6的实施例特别有用。这样的对话可能发生在互联网电话会议、电话呼叫或可能通过远程通信链路发生的其他对话中。这些实施例允许不能识别言语的人经由手机、互联网连接或其他可用链路与远方的其他人进行有价值的对话。因此,患有喉咙损伤、中风或一些其他状况而使他们无法像声学信号那样正确说出词语的人,可以使用本文所公开的系统和设备将系统训练为通过他们试图说出已被他们标识的词语的特定动作而识别所说出的词语。系统将识别来自用户的运动22,将其与期望词语匹配,并且然后诸如在手机通话期间,创建可以输出到任何位置的所说出的词语。
68.虽然根据优选实施例,加速度计14拾取运动作为用户想要说出特定词语的尝试,但振动22不需要起源于声带,或者用户尝试说出尽可能接近所呈现的词语。例如,词语可以被呈现给用户来训练系统,并且即使声带没有正确操作或者它们中的一些或全部操作缺失,加速度计14可以基于来自颈部或喉部的振动来感测说出词语的尝试。因此,加速度计可以被定位为感测用户身体的运动并使用训练模块34,将该特定运动与选定词语匹配并将其存储在训练中,使得即使喉头功能不全,也可以识别用户执行该特定运动的任何时间。
69.图7图示了被封装在单个壳体中的言语系统10的识别一个实施例。在图7的实施例中,壳体12被配置为邻近用户的颈部而定位。在该实施例中,壳体12包含将用户说出的词语转换为本地的人可以听到的声学输出所需的所有模块、处理器、扬声器和硬件。在该实施例中,加速度计14与人的颈部相邻并且与处理器16和扬声器15一起被包含在壳体12内。然后,如本文关于其他图(例如图3)所描述的,用户说出一个词语,该词语在加速度计14中被识别为运动信号,并被发送到处理器16,在处理器16中,词语的标识被匹配为标签,然后被发送到扬声器15,使得词语可以作为声学信号输出,以供用户面前的人听到。因此,通过这种方式,穿戴壳体12的人可以以正常的语音、以正常的速度说话,并且当他们说话时,所说出的词语从扬声器15输出,就好像它们来自说话者的嘴巴一样。在大量的词语(在一些情况下是几十个词语,而在其他情况下是几百个词语)已被训练之后,用户18将能够在他或她面前的人进行一些正常的对话。当他们说出正常语句时,运动信号22由加速度计14发送,所说出的词语的标识由处理器16确定,并且然后经由扬声器15进行言语输出。
70.图8图示了其中系统10完全包含在被定位在用户的耳朵20内的听筒的壳体62内的情形。在该特定实施例中,加速度计14被定位为邻近人耳中的骨骼。当人说话时,耳朵中骨骼的振动创建与已说出的词语相对应的运动模式22。人耳中的加速度计14感测到耳骨中的振动并输出与其感测到的振动相对应的信号。然后系统将所感测的振动转换为经识别的词语并提供该词语的标识。图3、图5或图6中阐述的步骤可以如前所述在图8的实施例中执行。如将理解的,针对所说出的相同词语,发生在用户耳骨中的运动22将显著不同于发生在用户颈部处的运动。因此,训练模块34将执行针对位于人耳处的加速度计14的训练。系统将在其中存储使用定位在用户耳骨处的加速度计14进行训练的指示,并且因此当信号被接收时,拾取信号的位置的标识与数据一起被提供。数据信号在运动被感测时标识加速度计的位置并且其被提供给处理器16。处理器16因此将使用针对该特定位置的分类模型来执行所说出的词语的识别。如将理解的,在处理器16与听筒在同一壳体62中的实施例中,将认识到信号源自用户的耳骨。对于在远程位置处进行识别的那些实施例,如图5和图6所示,运动信号将携带指示运动起源和运动被感测时加速度计位置的数据。
71.图9示出了其中系统10被安装在用户的上颚中的实施例。具体地,壳体12被成形和
配置为附接至腭骨64。当用户说话时,来自腭骨64的振动由加速度计14发送,并且然后振动在适当的运动信号拾取器28中被转换为运动信号,并将它们输出到如关于本文前面的图所描述的处理器16。对于一些用户,使得加速度计14与腭骨64相邻将是执行已说出的词语的识别的最有效方法。
72.图10a图示了壳体12可以定位在用户身上的不同位置处的情形的附加位置。在图10a的实施例中,两个壳体12被定位在用户身上,第一壳体12a在下巴骨上,并且第二壳体12b在颅骨上,在该实施例中,在前额上。相应的壳体12a和12b可以在用户身上的其他位置处,例如,一个可以靠近颈部,另一个可以在头顶,而另一个可以在头骨上的不同位置处,靠近耳朵、下巴或下巴前部。图10a的实施例图示了壳体12可以定位的不同位置以及多个壳体可以被连接到用户的身体来增加所收集的数据并识别如现在将关于图10b进行描述的,用户的不同类型的运动。
73.图10b图示了执行作为测试言语模式如何根据人说话时身体的移动而变化的测试的言语识别的情形。在图10b中,用户18具有与下巴耦合的第一壳体12a以及与前额耦合的第二壳体12b。传感器中的每一个传感器可以基于所说出的词语来检测通过骨骼的振动,并且它们还可以检测身体的振动或移动,例如,移动手臂或手、移动头部或用户在说话时位置的其他变化。
74.图10b的曲线图70示出了由定位在用户前额上的壳体12b内的加速度计14检测的运动和振动。曲线图72示出了由定位在用户下巴上的壳体12a内的加速度计14检测的运动和振动。当用户说出词语时,在相应加速度计14处接收的信号的振幅在曲线图中示出为振幅随着时间而变化的信号70、72。如图10b中曲线图下方的文本所示,随着时间的推移,用户首先说出三个buongiorno(意大利语表示早上好),然后说三个buonasera(意大利语表示晚上好)。如曲线图70和72所示,在相应传感器12b和12a处的振幅的振动响应中可以看出人说了三次早上好和晚上好。接下来,讲话者将buongiorno和buonasera这两个词语各说了三次,但同时以各种动作移动他们的头部。从曲线图中可以看出,当头部移动时,加速度计感测到头部的移动并同时记录所感测的头部运动的变化,以感测当用户说出词语时发生的振动。因此,接下来的六个信号表示人说出早上好和晚上好,同时在他们说话时移动他们的头部的情形。在此之后,用户说出了许多不同的字母,例如,字母a、e、i、o、u,同时保持他们的头部静止,然后不断移动他们的头部,同时说出相同的字母a、e、i、o、u。在此之后,如以下的符号和加速度计感测的相应位置的运动振幅所示,用户没有说话并移动了他们的头部。如下所示,在说出词语之后,用户将他们的头部向左移动,然后向右移动,然后向下移动,然后向上移动,然后快速左右移动,然后他们旋转他们的头部,然后,对于最后两个测试模式,他们一边旋转并从右向左移动头部,一边用他们的嘴大声哼着恒定的声音,并重复了两次。他们的嘴巴张开的嗡嗡声用字母arl表示,意味着他们发出“aww”的声音是嗡嗡声,并且在张开他们的嘴巴的同时头部从右向左转动。
75.该研究的结果表明,系统能够轻松地区分言语模式和身体运动。具体地,这优选地使用高通滤波器来执行。与从所说出的词语中感测的振动和运动相比,身体的移动相对较慢并且由较慢的频率信号表示。因此,阻挡或消除低频运动的滤波器被应用于信号,这对于消除身体运动是有效的。它还可以有效地消除其他身体部位的运动,诸如身体的手臂、或手、腿或、四肢。因此,在优选实施例中,信号条件由加速度计14输出的信号执行,并且因此
在运动感测信号发生之后,执行滤波以去除不在所说出的语音的频率范围内的信号。附加地,滤波器也被应用于滤除和阻挡远高于人类语音范围的较高频率。因此,可能来自外部源的频率(无论是光、计算机还是其他频率)或者如果用户手持频率远高于人语音的设备(诸如振动产品、计算机或其他产品),这通过滤除高频而被去除。
76.测试被执行并且图10b图示了可以使用仅具有单个加速度计的当前系统。不必将加速度计定位为感测人体(诸如头部或其他身体部位)的移动。相反,根据优选实施例,仅单个加速度计14被使用并且从单个加速度计14接收的信号被过滤和调节,以便于基于用户尝试说出词语而接收通过用户的骨骼传导的所有振动和运动并阻挡来自其他源的与用户尝试说出词语不相关的运动。
77.图11图示了其中单个传感器壳体12a被定位在用户的下巴上的实施例。在该实施例中,传感器12a包含加速度计14,并且在一个实施例中,与其他系统无线通信来远程执行处理和信号创建。在图11的实施例中,壳体12a可以非常小,可能是针头的大小,或者甚至可能更小。在该实施例中,加速度计14被充分定位为基于言语模式或用户说话,特别是基于来自下巴骨、下巴或面部其他位置的振动来适当地接收和感测运动。壳体12a仅包含非常小的mems加速度计14,然后是发射器,以将信号无线传输到执行如本文别处所述的附加处理的另一位置。
78.因此,图11的实施例具有拾取器的优点,即,非常小并且根据其位置,可以基本上隐藏并且不能被其他人看到。例如,小点、针头尺寸或更小可以被放置在颌骨后部,靠近人的耳骨,或用户颈部或头骨上的其他位置。用户将创建一系列样本来训练神经网络并通过在期望位置使用传感器12a的壳体说出本文所述的多个词语来生成函数,并且然后可以在壳体12位于期望位置的情况下继续他们的正常一天,并且然后可以使得另一设备(诸如ipad、计算机(诸如笔记本计算机)、收音机或将接收信号的其他设备)执行信号处理,以将词语与在所收集的样本上训练的分类模型匹配、识别词语并且然后向在场的人清楚地说出词语。因此,用户现在能够在友好的基础上与他或她在场的许多不同的人进行社交互动,并能够与他们进行清晰的交流,即使基于他们能够产生声音的某些身体障碍能够识别他们正在说出的词语,也立即从与该人相关联的扬声器说出,扬声器可能在口袋里、随身携带或与他们相邻的其他扬声器。
79.如可以理解的,壳体12a在图11中被放大并且在大多数实施例中将非常小。图11的实施例还允许用户将加速度计14作为首饰配件佩戴。例如,用户很可能希望在他们的颚骨上戴耳钉、穿过他们耳朵的耳环、位于他们舌头上的耳钉或者对用户或用户在场的人来说将被视为珠宝的一些其他壳体。本公开提供包括加速度计14和必要的发射天线的这样的珠宝,以允许用户说出的词语被识别,并且然后从用户随身携带的扬声器(诸如手机、ipad、或其他本地携带的便携式设备)输出。
80.图12图示了在使用图10a、图11或在一些实施例中图7的系统说话时执行来自各种传感器的输入的过程。如图12所示,多个加速度计14可以被定位在用户的身体上的不同位置处。当用户说出词语时,运动振动22被相应的加速度计14感测。它们可以被感测为x、y和z方向的移动,或者可以不同的感测移动和附加传感器可以被添加,如图12所示,两个传感器被图示,但可以理解,可以提供三个、四个或更多个传感器。从相应滤波器14输出的信号被馈送到预处理块74。块74执行包括滤波、分割的各种功能,并且根据需要进行调节,然后进
行计算。块74执行如前所述的滤波来提供低通滤波器、高通滤波器或适当的滤波,以去除与用户试图说出词语不相关的信号并隔离、分割和呈现与用户说出词语相关联的所有运动。在块74中执行的过程可以由微处理器16执行,并且表示如本文中关于图3、图5和图6所解释的过程。具体地,在处理块74内,功能被执行来执行完整的语音识别,使得每个所说出的词语被标识并且清楚地提供输出作为来自模块74的标识词语。因此,模块74可以包括一个处理器、在云上操作的互联网或如本文其他地方描述的其他处理能力。在词语被标识之后,它被输出到合成器76,合成器76将信号转换为所说出的词语,如前所述,所说出的词语在与用户相关联的扬声器上提供。
81.图13图示了一种方法,分类模型或函数可以通过该方法,通过从用户收集言语信息并训练神经模型来创建。根据图13的流程图,在第一步骤100中,词语被提供给用户来提示他们说出特定词语。该提示可以是在用户正在查看的屏幕上呈现词语的形式,或者是从计算机的扬声器上输出的词语,诸如作为从手机、ipad或其他训练设备输出的所说出的声学词语来提供。特定词语因此被提供给被提示说话的用户。该词语然后在步骤102中由用户说出。当词语被说出时,加速度计在步骤104中感测骨振动和身体运动或位置。
82.在步骤106中,用户的骨振动和其他移动作为参考数据被存储为对应于所选定或提示的词语。因此,将所提示的工作与从加速度计收集的信号链接的匹配或关系被存储。系统已标识的词语可能在声学上与未受损的说话者完全不同,使得这种关系将言语模式与提供给神经模型的提示词语联系起来。例如,被提示说出的词语可能是“早上好”,并且用户的声学输出可能是类似于“grr”的声音,或者类似于“gmmm”的声音,或者用户能够基于他们当前的身体能力发出的其他声音。数据针对所选定或提示的参考被存储,并且如果所提示的词语的更多样本有利于训练,则用户将被再次提示,参见步骤108。借助步骤100-108,用户被提示重复说出词语来基于特定相同词语,收集用户骨振动的多个样本。
83.应当认识到,每次用户说出他们被提示说出的选定词语时,他们发出的声音可能有些不同。可以根据需要继续说出相同的提示词语,以确认已针对该特定词语构建了足够的数据库或数据集来训练模型,从而生成函数。这可能意味着根据用户及其每次说出选定词语时创建精确振动模式的能力,词语被说出三次、五次或几十次。由于数据未被实时处理,因此系统会收集大量样本进行处理来训练函数,使得函数能够唯一地标识选定参考词语。一旦单个词语或短语的样本集完成,系统可以在框109中呈现另一词语并开始新的样本收集序列,样本收集序列被用于创建不同的标签。具体地,系统前进到框109来向用户提供新的参考词语,然后重复步骤100-108的序列。与自然语言言语识别(大量词语和短语)相比,该训练序列根据最终用途,会持续用户希望呈现给他们的尽可能多的词语,即,语音命令(有限数量的词语和短语)。因此,在框110中,询问是否存在待被训练的任何其他词语。如果存在待被训练的词语,则序列重复框109并且如果没有待被训练的更多词语。不同的词语样本可以被实时存储或在样本收集阶段之后提供给神经模型。样本收集阶段可以在各种不同的时间段内进行,例如几天或几周,这对于用户来说是可以接受的。
84.在步骤112中,所存储的数据被用于训练分类模型,分类模型将输入声学信号分类为不同的标签。每个标签表示用户在步骤100中选择并在步骤102中说出的词语。在一个实施例中,分类模型是神经网络。人工智能被应用来定位对于试图说出同一词语的所有尝试共同的模式,并将一个所说出的词语与不同的词语进行区分。
85.如果用户期望在不同时间在身体上的不同位置处使用不同的壳体,则用户将利用壳体12在不同的位置处重复如图13所所示的序列。例如,用户可以在步骤102中使用被配置为与颈部相邻的壳体12来收集所说出的数据,然后在将加速度计被定位在下巴上、上颚中、与耳骨相邻或其他位置中的情况下再次执行该序列。每次数据收集被执行时,加速度计都会提供信号,该信号指示进行收集时加速度计的位置。因此,所收集的信息在信号被收集时标识加速度计的位置。然后分类模型使用这些位置数据以及所说出的词语和骨振动而被训练。稍后,当言语识别被执行时,加速度计输出的信号将包括标识在词语被说出时,加速度计在用户身体上的位置的信息。这允许分类模型正确地分类源自用户身体上的不同位置的加速度计在词语被说出时的骨振动信号。
86.图14图示了根据本文所述的系统的言语识别方法。如图14所示,在步骤114中,使用定位为邻近人体的加速度计14来感测骨振动。由加速度计感测的振动作为样本信号从加速度计14发送到处理器16。样本信号是用户说出他们希望系统识别的词语的输入。在步骤118中,样本信号作为输入被馈送到分类模型。这在处理器16中、或在远程服务器、或在云或如本文先前描述的其他位置上被执行。在步骤120中,确定样本信号的分类是否与所存储的词语匹配。如前所述,来自加速度计14的信号将向处理器指示加速度计在振动被感测时的位置。因此,样本信号将由在数据库或所收集的样本数据集上训练的分类模型来处理,分类模型对应于通过在相同位置处使用加速度计创建的参考信号或样本信号。
87.在一些实施例中,分类模型将被直接提供给壳体,使得语音识别或言语检测都不会从壳体远程处理。在其他实施例中,分类模型可以被存储并从壳体远程访问,诸如实时传送所收集的语音或振动数据。
88.一旦分类模型被训练,用户就可以开始说出命令或在壳体中进行语音识别通信。分类模型将标识与所说出的振动相对应的相关标签。这可以与步骤120相关联。然后经匹配的存储词语在步骤122中输出。该输出可以是来自分类模型的多个标签,标签在118和120中被评估,其中关于多个输出标签中最相关的标签做出判定。一旦最相关的标签(诸如具有最高百分比的标签)被标识并且该词语的标识被提供给系统,使得它可以作为122中的输出被提供。一旦词语的标识被输出,系统可以将其作为文本(可听的,诸如来自扬声器所说出的词语,或用户可能需要的其他输出(例如触觉反馈)在显示器上提供。
89.在备选实施例中,如果多于一个参考信号在样本信号的阈值内,则两个词语被提供并且用户可以诸如通过从文本选项中选择一个词语、听到它被说出来而具有选择他们希望呈现的词语的选项,或者在一个实施例中,两个词语均可以从扬声器中说出,使得用户可以听到这两个词语,并基于上下文来确定要说出哪个词语。
90.本文描述的是系统和方法,通过系统和方法,原本会使他们无法对他人说出可理解的词语的残疾人现在能够说出随后将提供给在他们面前的人的词语,并且它们可以很容易地理解和执行正常的对话。因此,患有广泛残疾的人,无论是喉部、声带、颌骨受伤,还是经常发生的牙齿缺失而无法与在场的人进行清晰的交流的老年人,现在都可以根据本文中教导的系统很容易做到。
91.如果用户变得特别精通为词语或短语创建样本,则用户将有可能只使用每个词语的一个输入来创建数据库、数据集或训练数据,并且还可以拥有相当大的已标识的词语数据库。例如,有经验的用户可以被提示阅读整个段落,或者可能是其中具有大量词语的文本
或小书。当用户说出词语时,所说出的词语的标识可以由用户从键盘或其他源输入,告诉系统他们刚刚说出或即将说出的词语。使用该技术的用户可以在短时间内阅读大量的词语,从而建立非常大的数据库。备选地,可以在计算机上向用户呈现待阅读的段落,并且每个词语按顺序突出显示,并且用户说出突出显示的词语,然后移动到下一个突出显示的词语,然后移动到所呈现的消息中的任何突出显示的词语。因此,在许多情况下,用户将能够从计算机读取文本,诸如显示监视器上呈现的几个页面,并且当他们阅读每个突出显示的词语时,系统会将正在说出的词语与在显示文本中突出显示的词语匹配,并且用户将能够建立其中包含与用户可能想要说出的词语相对应的许多词语的非常大的数据库。在进一步的备选实施例中,用户可以将样本文本键入到键盘中,其中包含他们希望识别的词语。用户因此可以键入字母、段落或从另一源获得与用户希望识别并存储在系统中的词语相对应的词语的大样本。在用户将待被识别的词语输入系统之后,用户然后可以提示系统以特定序列呈现这些词语,并在呈现给用户时说出这些词语,使得他们建立与他们希望识别的词语相对应的、拥有自己词语的数据库选择。
92.加速度计信号由神经模型处理(推断过程);这个过程的输出是输入信号在一个可能的输出类/标签中的分类。每个标签表示属于在先前单独的时间用于训练神经网络的数据集的词语。输出标签的选择可以以不同的方式完成。最简单的选择是选择具有较高值的标签。例如,其他技术可以基于对连续推断输出的观察。滤波器可以在这些基础上构建,以用于观察例如时间窗口中类标签的出现。
93.根据本文所公开的技术,即使他们可能对正常言语有严重的残疾,人也因此能够在社交环境中更正常地发挥,从而为以前不能享受口头对话的那些人提供了显著的优势。
94.图15提供了使用一个或多个骨传导加速器感测在具有正常言语障碍的人说出短语“早上好”、“晚上好”、“谢谢你”和“不客气”时骨骼中的振动而收集的数据的四个不同图表。应注意,创建图15的这些图表的所说出的语言是意大利语,然而,如果以任何语言说出词语,则将获得对应的频率图表,并且在此呈现的相同原理适用于任何语言。为了便于参考而在本公开中将短语翻译成英语呈现。第一图表140示出了短语“早上好”随时间的频率响应,其中以灰度级示出了在说出短语时信号的强度。类似地,图表142随时间示出了短语“晚上好”,曲线144随时间示出了短语“谢谢你”,曲线146随时间示出了短语“不客气”。这些相应频率图表中的每一个图表将具有基于正在说出词语的个体的特定特征。不幸的是,因为由特定说出的词语产生的骨传导在人与人之间非常不同,尤其是对于难以用可听的词语说话的人,频率图表在人与人之间将不一致。该不一致性将足够大,使得不可能建立将会普遍应用的对具有严重语音障碍的所有人起作用的可靠的模型。现在将对此进行解释。
95.图16a是从没有语言障碍的三个不同个体收集的相同短语“早上好”的数据,而图16b是基于从具有严重语言障碍的三个不同个体的相同短语的骨传导而收集的数据。查看图16a中的频谱图频率图表150、152和154,示出了它们彼此非常相似,即使三个不同的个体说出了该短语。一般的言语识别引擎应该能够识别由这三个不同的个体说出的短语“早上好”。无需对数据库和识别系统进行特殊培训。另一方面,图16b示出了由没有能力说出可听的词语,并且因此无法收集音频信号的三个不同个体说出的非常相同的短语“早上好”。然而,从三个不同个体的加速度计收集到的骨传导信号在输出频率方面彼此之间完全不同。
96.可以看出,频谱图图表160中的第一讲话者在1.2秒到2.2秒的时间段期间具有显
著的信号数据,而在说出该短语的期间在任何其它时间数据很少甚至没有数据。另一方面,由讲话者162产生的频谱图图表在时间以及从骨传导拾取的各种信号的振幅和频率方面均具有非常不同的频率响应。产生频谱图图表164的讲话者针对他们的频率曲线还具有不同的输出特定特征,这与曲线160或162不是非常相似。因此,存在这样的问题:是否可能在使用骨传导收集频率信号时,使用传统软件、自然语言处理或机器学习来创建将正确地识别由具有言语障碍的用户说出的短语的数据库。
97.在图17a和图17b中示出了使用标准lstm神经网络来执行对没有语言障碍地说出清楚、可听的词语的人的语音识别。更具体地,图17a是使用第一种类型的递归训练来语音识别没有语言障碍地说出清楚、可听的词语的个体的模型损失度的曲线图。图17b是使用第一类型的递归训练来语音识别没有语言障碍地说出清楚、可听的词语的个体的模型的准确度的曲线图。
98.如图16a所示,由可以没有语言障碍地清楚地说出可听的词语的不同个体说出的短语早上好是提供给标准lstm神经网络以执行如图17a和图17b中的曲线图所示的语音识别的数据类型。如图165所示,模型损失度具有如线166所示的多个训练样本。如可以从曲线图165可见,在50个样本之后,损失度从0.08迅速降低大约0.005。这表明模型损失度低,并且机器学习能够被训练。此后,如测试线167所示,收集了多个测试数据样本。在测试期间,在40个样本之后,损失度还从约0.08减小到约0.01,并且在50个样本周期之后,损失度继续减小到约0.005。这指示用于机器学习的软件有效地以低损失度识别说出的词语。此外,训练数据集和测试数据集朝零收敛,进一步指示软件能够执行所要求的功能。
99.图17b中的曲线图168示出了相同数据集上的准确度模型,收集了可听地清楚地说出的词语的样本。在训练期间,如所收集的样本,准确度在从最初几个样本的20%以下之后提高到接近100%,即在40个样本之后为1.0,并且在60个样本之后接近100%,如线169所示。然后如线171所示地对测试样本进行了测试,并且当测试更多样本时,在50或60个样本之后,准确度也从40%以下提高到接近100%。这两条线收敛,并靠近100%,因此证明对于正常的说出的可听的词语,当前可用的神经网络和软件程序对于图16a所示的类型的清晰地说出的词语执行语音识别是可接受的。
100.如图17c和图17d所示地进行了首次尝试,使用图17a和图17b中用于没有语言障碍的人说出的标准音频言语的相同机器学习工具来执行在说出可听的语言词语方面具有严重障碍的人的词语识别。将图17a和图17b中使用的用于识别没有语言障碍地说出清楚、可听的词语的人的识别的标准lstm神经网络应用于尝试具有严重说话和可听的语言障碍的人的识别。为了训练模型来理解和正确识别具有言语障碍的用户说出的词语,收集并分析了各种样本。在使用机器学习的第一次尝试中,使用了标准的递归神经网络,其在架构中利用人工递归神经网络的长短期记忆(lstm),以便执行图16b中提供的数据的深度学习。lstm神经网络在本领域中是公知的,并且因此这里将不详细描述关于它们在用于语音识别的人工递归神经网络中的使用。当将这种类型的机器学习应用到图16b的类型的数据时,即,应用到来自图16a的类型的数据时,产生图17c和图17d的图表,其分别提供这种类型的机器学习网络的损失度和准确度的测量,以正确地表征和识别词语。
101.图17c是使用标准lstm网络的模型损失度的曲线图170,其中,在训练序列期间,系统对重复说出的短语的识别如线172所示,开始于在5个时期之后,即,在已经采取5个样本
之后的约0.08,然后进步到在35个样本之后损失度小于0.04,即,线172已经发生了35个时期。一旦系统被认为被充分训练以便以低损失度正确地操作,则进行测试以确定识别说出的所训练词语的准确度,如线174所示。从曲线图170中可以看出,五个样本之后的损失度与线174所示的测试序列的训练模型的值大致相同。然而,随着继续进行多次测试,测试样本没有改善模型损失度。相反,即使在35个时期之后,模型损失度仍保持在0.07以上。这证明使用标准lstm人工智能技术的机器学习系统的能力不能正确地创建将识别说出的词语的数据库。该模型的故障在图17d中的曲线图176中进一步示出,曲线图176是准确度模型。可以看出,在图17d的模型准确度曲线图176中,如线178所示,训练准确度从三个或四个样本周期之后的约0.2上升到35个样本周期之后的约0.7。因此,训练显示出适当的进展。然而,在测试阶段期间,训练没有执行到实际的识别。在测试过程中,如线180所示,词语识别的准确度在5个样本周期之后约为0.2,并且在35个样本之后缓慢上升到约0.4,并且在样本25之后没有显示出任何改善。因此,准确度模型还证实了尽管机器学习的神经网络看起来是可训练的,但基于训练集,它不将学习带到短语测试集,并且尽管进行了重复训练,但实际上没有创建将正确识别短语的数据库。
102.以上对由普通讲话者可听地说出的短语的机器学习在40个样本之后具有低于0.01的模型损失度,其在60个样本之后进一步降低到低于0.005。类似地,模型准确度从10个样本之后的约0.6上升到40个样本之后的约100%。此外,训练模型和测试模型收敛具有来自系统的相同响应。没有为了便于参考而示出这些曲线图,因为它们证明了由普通讲话者说出的音频词语。
103.因此,将新的机器学习技术应用于基于不能以正常方式说话的用户的骨传导而获得的信号。根据本公开的原理,应用基于卷积神经网络的新的机器学习序列。在卷积神经网络中,在该网络中没有环路,只有前馈。数据在网络的核心内被卷积。卷积神经网络(cnn或convnet)在本领域中普遍被认为通常用于分析图像的类型的人工神经网络。本公开中提出的特定算法对数据执行多个操作以执行词语识别。此外,在作为卷积神经网络的一部分的特定序列中采取多个特定步骤。
104.参考图21示出并描述了本公开中所呈现的算法,稍后在本文中描述。因此,对用于语音识别的算法进行测试,以判定其在图16a所示类型的具有良好可听特征的用户的标准言语识别中的有用性。图18a是使用机器学习的新公开的言语识别软件算法的损失度模型的曲线图,而图18b是相同公开算法的准确度模型曲线图。
105.如从图18a可见,曲线图180示出了训练部分期间损失度从约0.082快速下降到20个样本之后的小于0.005,并且在40个样本之后,损失度约为零,并且如从线183可见,这对于所有将来的样本持续。类似地,当对测试数据进行测试时,测试期间的模型损失度在20个样本周期内从0.072快速降低到约0.005,并且在40个样本周期之后接近零,与训练样本收敛在一起。这表明特定软件算法在机器学习中经历了较低的损失度,并且对于可以说出清楚可听的词语的人的语音识别来说,它将表现良好。类似地,曲线图185中所示的准确度模型也证明了图21中公开的算法的模型准确度可以被训练成具有高准确度。当训练开始时,准确度迅速上升而朝向10个样本之后的90%,并且在20个样本之后接近1.0,即100%,准确度从30个样本到之后的100个样本保持在约100%。然后,当对测试数据进行测试时,测试结果与训练结果收敛,并且在10个样本后接近0.9,并且在20个样本之后开始接近1.0的准确
度,即100%。从40个样本以后,测试模型的准确度保持在约100%。这进一步证明图21的软件算法对于说出清楚可听的词语的人的标准语音识别是高度准确的。实际上,将图18a和图18b的曲线图与图17a和图17b的曲线图相比较,可以看出图21所公开的算法相比标准机器学习技术具有更低的损失度并且更快地接近零损失度,并且还比利用ltsm神经网络的标准机器学习技术具有更高的准确度并且明显更快地接近100%准确度。
106.已经证明图21所公开的算法在用于标准音频语音识别时是优异的,现在将检查数据结果以确定针对具有严重语言和可听的说话障碍的个体说出的短语的可接受性。图18c是根据本公开的使用所创建的机器学习序列作为递归训练和测试来识别具有严重口语障碍的个体的模型损失度的图。图18d是如在本公开中介绍和教导的使用递归训练来识别具有严重语言障碍的个体的模型的准确度的图。在图21中示出了训练和测试的具体顺序,这将在后面描述。
107.现在转到如本文教导的所公开的机器学习技术的结果,图18c示出了模型损失度图表190,其中训练集从约0.08的2-3个训练样本之后的损失度开始,然后在约40个样本后进步到约0.005的损失度,并且在80个样本周期后进步到约0.0001的损失度。这是在如曲线图190中的线192所示的训练阶段期间。现在检查如线194所示的测试阶段,对用户说出短语的样本约100个执行数据库的测试,其中,信号是由加速度计通过骨传导拾取的。在样本开始处,模型损失度约为0.08,然后其也在20个样本后迅速降低到约0.02,在40个样本后降低到约0.015,然后在100个样本后进一步降低到约0.005。因此,即使在多次测试之后,如线194所示的测试样本朝零损失度收敛。这证明了在序列中的不同步骤处使用卷积神经网络的机器学习能够被训练和执行基于感测不能以正常方式说出音频词语的人的骨传导信号的说出的词语的正确识别。
108.回到图18d,在曲线图196中示出了所公开的神经网络和机器学习的准确度。模型准确度从零样本处的约为零开始,然后在训练期间快速上升到约0.8,如线198所示。即,在训练阶段期间,准确度变为大约80%。然后如线200所示地进行测试阶段。在测试阶段,测试模型的准确度与5个样本到10个样本周期后的训练模型大致相同。然后,在15个样本和25个样本之间,测试模型的准确度从大约40%上升到60%以上,然而,测试模型的上升并不像相同样本周期期间的训练模型的上升一样迅速。然后,在大约40个样本之后,测试模型继续改进并且达到约80%,并且在60个样本到70个样本之后等于训练模型。因此,训练模型和测试模型的准确度在约40个样本周期之后收敛。这证明了如本文教导的所公开的机器学习技术对于执行图16b中所示的使用如本文公开的加速度计的骨传导感测类型的信号识别是有效的。
109.图21是示出用于使用骨传导感测进行词语识别的算法的流程图,该算法用于创建图18c和图18d的图表190和192。现在将对此进行详细描述。在步骤302中,输入骨传导数据,如果用户已经能够说话,则骨传导数据可以被认为对应于音频数据。然而,特定用户难以产生可听言语,并且因此如本文别处所公开的,将加速度计放置在用户的骨骼附近。在将骨传导数据输入到系统之后,对骨传导信号执行卷积,如304所示。使用与用于音频卷积相同类型的技术来执行该卷积。即,在该卷积步骤304中,通过将信号的两个源(输入信号和脉冲响应)的频谱相乘的方式执行处理。通过这样做,两个源之间共享的频率被放大和增强,而两个源之间不共享的频率被减弱。这将使输入信号具有对应于脉冲响应的音质。此外,来自脉
冲响应的与输入信号共有的特征频率将被放大。卷积技术在公开的文献中有描述。可以说,如关于音频信号的频谱图所教导的卷积技术被应用于骨传导信号,结果是输入信号能够呈现音质并且因此能够执行更精确的分析。
110.在步骤304中执行卷积之后,根据卷积的结果和信号执行非线性函数。非线性函数在机器学习中的一般用途是,神经网络将逼近不遵循线性的函数,以成功地预测函数的类别。因此,在步骤306中,非线性函数提供输入和响应变量之间的映射,其目的是将到卷积神经网络的节点的输入信号转换为修改后的信号,然后该修改后的信号被输出到下一层,在该层中,该修改后的信号变为到序列中的下一步骤的输入,如步骤308所示。在一般概念中存在许多关于非线性函数和机器学习的学术文献,并且在步骤306期间将这样的函数应用于步骤304的骨信号卷积的输出,然后并且将该信号推进到步骤308,在步骤308中执行比例偏置和归一化。在如步骤308中执行的比例偏置顺序中,对数据内的不同情况给予不同的加权。该模型被测试以查看如果改变一个数据点或者使用不同的数据样本来训练或测试该模型,则性能是否保持相同。不同的加权被应用于卷积信号的不同部分,以便更准确地识别在骨传导期间感测到的短语的不同部分。在训练顺序期间提供频谱的每个方面并进行加权偏置。在信号上应用比例偏置,以便在不同的训练样本期间测试训练的准确度。当准确地知道正在说出哪个词语时,在训练期间执行比例偏置,以便确定要提供给频谱的不同部分的适当加权。因此可以确定比例偏置并将其用于测试样本。此外,在步骤308中,执行归一化。该机器学习序列的归一化是将数据转换成对于所有信号具有相同比例的范围的过程。即,在算法内使用标准化距离,例如,将数据变换成单位球面或一些其它归一化技术。这也用于执行加权和归一化频谱的不同部分的加权,如通过比例偏置所执行。然后,在步骤310中,在应用比例偏置和归一化之后,对信号执行池化。在机器学习中,池化层用于从通过在图像上卷积滤波器而产生的映射中累积特征。即,执行池化,其中从在步骤304中产生的骨骼卷积信号中提取广义特征,这有助于神经网络独立于它们在频谱中的位置来识别特征,并且该信号是一个整体。虽然卷积层是卷积神经网络的基本构建块,但是在步骤310中的这一阶段,池化层的使用提供应用于卷积信号的映射,然后在系统中呈现的滤波器,并且池化滤波器基于该滤波器计算作为特征映射的一部分的输出。
111.然后,在步骤312中,对来自310中的池化步骤的输出信号进行另一次卷积。这是类似于对音频卷积执行的类型的骨骼信号卷积。如前所述,卷积是组合两个信号以形成输出信号,并且如前面关于步骤304所述地在步骤312中执行相同类型的卷积。然而,该步骤在池化函数之后执行,并因此提供信号的进一步细化。在312中的第二卷积步骤之后,在步骤314中对来自312中的卷积步骤的信号的输出再次重复非线性化步骤。步骤314的非线性函数以与先前关于步骤306所描述的方式类似的方式进行。此后,在步骤316处,对信号再次进行比例偏置和归一化函数,之后如步骤318所示地对信号进行池化。
112.然后对来自步骤318的输出信号进行用于机器学习中的音频信号的稠密函数。该稠密函数实现输出的操作等于输入核的激活加上加权偏置。具体地,稠密函数实现以下操作:输出=激活(点(输入,核) 偏置)(output=activation(dot(input,kernel) bias))。在该等式中,“激活”是作为激活参数传递的逐元素激活函数,“核”是由该层创建的权重矢量,“偏置”是由该层创建的偏置向量(仅当用户_偏置(use_bias)为真时适用)。这些是步骤320的稠密函数的基本属性。该稠密函数是使用线性操作的深度神经网络中的一种类型的
层,其中输入通过权重连接到每个输出。如神经网络中稠密层的使用,机器学习中稠密函数的一般概念通常是已知的。稠密函数的具体概念在步骤318的池化之后的步骤320中执行,从而提供更完整的信号,以用于执行通过具有严重言语障碍的人的骨传导感测到的所讲词语的识别。在稠密函数步骤320之后,在步骤322中执行先前描述的非线性化过程,之后在步骤324中执行信号的整形(reshaping)。执行数字音频信号的整形以增加322中的非线性化步骤的信号输出的表观信噪比。它可以仅作为整形函数或作为抖动函数的一部分来执行。可以动态地进行音频信号的频谱整形,以提供频谱内容的平滑并避免信号内容中的突然变化。已知用于执行音频信号的频谱整形的各种技术,在美国专利号10,230,411中描述了其中的一种技术。
113.在步骤324中执行整形之后,在步骤326中再次执行稠密函数,并且然后将非线性函数应用于信号328,此后在步骤330中提供输出,在该输出上通过将信号与数据库中的信号进行比较来执行识别,以确定数据库中是否存在匹配的词语或短语。
114.因此,图21提供了根据本公开的步骤顺序,通过该步骤顺序,从骨传导数据收集的信号通过机器学习算法的不同层被修改,并且步骤330中输出的结果数据已经被适当地调节,在该结果数据上可以执行口语短语的识别。有利地,包括图21的算法的整个网络在单个处理器上运行。该模型可以完全加载到标准微处理器中,其一个示例是st 32微处理器系列。一个具体的示例是stm 32f746g。该特定处理器具有足够的板载flash和ram以执行本文公开的算法。重要的是,适当的分类和识别可以直接由本地处理器在系统的edge上执行,而无需访问云或具有数千个处理器的其它大型服务器场。该模型可以包含适当的权重度量,即在机器学习网络中使用加权压缩和加权量化。
115.图19a和图19b示出了句子结构的构建,其使用了图21中阐述的步骤的使用加速计的骨骼传导感测和针对图18a和图18b描述的卷积神经网络。如图19a和图19b所示,难以形成可听的声音的人创建了句子结构,其中由本文描述的传感器执行识别,所述传感器定位为感测来自用户的骨传导。在会话的第一部分,用户说出问候语,诸如曲线图402的早上好,或曲线图404的晚上好。此后,用户组建句子,在给出的示例中,说出曲线图406的短语“我想要”,随后是讲话者想要的可能的不同物品。这可以是用户所指向的物品,随后是“这个”408、如频谱410所示的短语“那个”、如频谱412所示的“水”或如频谱414所示的“面包”。
116.如图20a和20b所示,然后讲话者可以响应于不同的人说出的词语,并且在响应之后可以指示频谱416的“是”或频谱418的“否”。在图20a所示的例子中,用户已经指示了他们希望的物品(在频谱410中示出),此后会话中的其他人确认想要的具体物品。然后,如图20a所示,用户可以用是或否作出响应。在这之后,会话可以推进到图20b的说出频谱420的感谢你或频谱422的不客气的不同选项。
117.使用感测骨传导的加速度计感测已经说出的词语的方法可以在如本文先前描述的图5和图6中所示的系统上执行。具体地,已经描述的算法可以是图5的处理器34中的ai训练的一部分,或者是图6的系统中的处理器50的词语识别系统的一部分。如图5和图6所示,当加速度计接收到由于用户说出词语而产生的信号时,系统在感测到用户骨骼中的运动后开始操作。
118.本公开执行基于骨传导的言语识别,其具有对声学环境噪声的抗扰性。具体地,在依赖于用户的音频陈述的系统中,如果存在大声的邻近噪声,无论是来自道路、机器、风扇
还是其它大声的音频噪声,说出的词语的识别可能非常困难,并且在某些情况下是不可能的。然而,加速度计紧靠讲话者的骨骼,所以对声学环境噪声具有抗扰性。本地的噪声不会进入讲话者的骨骼,并且信号的唯一来源是基于用户说出词语时骨骼的振动。因此,几乎没有来自本地环境的噪声。可以在使用如本文描述的,特别是关于图21所描述的机器学习来对信号进行处理之后,自然语言识别可以基于骨传导信号而执行,并且语音指令可以被识别。具有受损的言语、运动技能问题和其它问题的个体可以使用本文当前所公开的系统来完全识别其词语和短语。
119.上述各种实施例可以被组合来提供进一步的实施例。如果需要,实施例的各方面可以被修改来采用各种专利、申请和出版物的概念,从而提供更进一步的实施例。
120.可以根据以上详细描述对实施例进行这些和其他改变。一般而言,在所附权利要求中,所使用的术语不应被解释为将权利要求限制为在说明书和权利要求中公开的特定实施例,而应被解释为包括这样的权利要求所要求保护的所有可能的实施例及其等同物的全部范围。因此,权利要求不受本公开内容的限制。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。