基于swin-transformer和cnn并行网络的自监督单目深度估计方法
技术领域
1.本发明属于计算机视觉领域,涉及一种基于swin-transformer和cnn并行网络的自监督深度估计方法。
背景技术:
2.深度估计一直是计算机视觉领域的重要问题之一,最近几年,自动驾驶、人机交互、虚拟现实、机器人等领域发展极为迅速,尤其是视觉方案在自动驾驶中取得惊艳的效果,在这些应用场景中,如何获取场景中的深度信息是非常关键的。
3.同时,从深度图中获得场景深度信息容易分辨出物体的边界,应用到计算机视觉的其他任务,比如3d目标检测和分割、场景理解等,可以简化原本的算法。
4.相比于有监督的方式,自监督单目深度估计可以实现不依赖真实深度标签进行单目深度估计,大大节约了采集真实深度值的成本。
5.transformer结构在建立长程相关性上有很大的优势,应用在视觉众多子任务领域都取得了不错的效果,但是transformer建模会丢失图像原有的结构信息,对于深度估计任务,图像的结构信息会对深度估计的精度有一定的影响。而卷积神经网络(cnn)虽然建立长程相关性的能力不足,但能很好地保存图像的结构信息。在transformer众多进化结构中,swin-transformer能够提供多尺度的特征信息,本发明提出将swin-transformer和cnn以并行结合的方式用于深度估计任务中的特征提取部分,实现二者的优势互补,同时使用swin-transformer和cnn提供多尺度的分层特征并进行融合,增强网络的特征提取能力,来获得更高精度的深度预测。
技术实现要素:
6.本发明的目的在于提出一种基于swin-transformer和cnn并行网络的自监督单目深度估计方法,该方法可以针对无标签的单目视频序列进行自监督训练。构建了swin-transformer和cnn并行分支组成的编码器来分别提取特征,通过swin-transformer和cnn信息融合(scfuse)模块将提取的特征进行融合。并且设计一种逐尺度自蒸馏损失,与单尺度图像重建损失和边缘平滑损失结合,共同构成网络的整体损失。
7.本发明的目的是这样实现的:步骤如下:
8.步骤一:使用单目像机进行拍摄并进行处理后得到一系列分辨率为h*w,长度为n的图像序列;
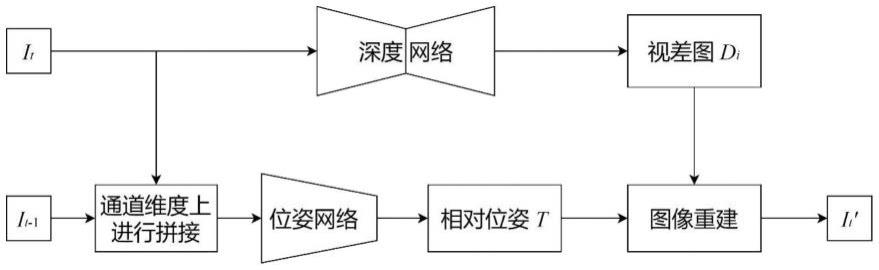
9.步骤二:在步骤一的图像序列中选取一帧图像i
t
作为swin-transformer和卷积神经网络(cnn)并行结构的深度网络的输入,输出为不同尺度的深度图di,将i
t
和相邻帧图像i
t-1
在通道维度上进行拼接后作为纯卷积神经网络结构的位姿网络的输入,输出两帧图像的相对位姿t
t
→
t-1
;
10.步骤三:基于步骤二中深度网络最终输出的深度图d0和位姿网络输出的相对位姿
t
t
→
t-1
进行输入图像i
t
的视图重建得到重建图像i
t
′
,计算单尺度图像重建损失l
rc
;基于步骤二中深度网络输出的不同分辨率的深度图di计算逐尺度自蒸馏损失l
esd
和边缘平滑损失ls;
11.步骤四:基于单尺度图像重建损失l
rc
、逐尺度自蒸馏损失l
esd
和边缘平滑损失ls构造深度网络和位姿网络的整体损失函数l
total
,使用单目视频进行网络的自监督训练,直至整体损失函数l
total
收敛;得到训练好的深度网络;
12.步骤五:将单张图像输入到训练好的深度网络中,网络输出与输入图像分辨率大小相同的深度图d0,将深度图d0作为输入图像的单目深度估计结果。
13.本发明还包括这样一些结构特征:
14.1.所述步骤二构建的深度网络由编码器和解码器组成,编码器和解码器之间进行跨层跳跃连接。其中编码器由swin-transformer分支和cnn分支并行组成,利用swin-transformer分支和cnn分支分别提取图像特征得到不同尺度的特征图。swin-transformer分支中包含有n个swin-transformer模块,输入图像经过swin-transformer分支总共得到n种不同尺度的特征图xi。cnn分支由cnn模块组成,输入图像经过cnn分支总共得到n种不同尺度的特征图yi,其中,n的大小可以根据输入图像的分辨率大小进行选择,以达到适应不同分辨率输入的目的。
15.2.步骤二中构建的深度网络的解码器由swin-transformer模块组成,其能输出n 1种不同分辨率的深度图d0、d1、d2、
…
、dn,分辨率依次减小,其中d0和输入图像i
t
分辨率大小相同。
16.3.步骤二中深度网络的编码器部分通过swin-transformer和cnn信息融合(scfuse)模块将编码器swin-transformer分支和cnn分支输出的不同尺度的特征图xi和yi进行融合,获得n个不同尺度的融合后的特征图zi。scfuse模块的操作如式(1)所示:
[0017][0018]
其中,xi和yi分别表示两个输入的特征图,zi为第i个scfuse模块的输出,表示将两个特征图在通道维度上进行拼接,conv1×1表示步长为1,卷积核大小为1*1的卷积步骤。
[0019]
4.步骤三提出一种逐尺度自蒸馏损失用于网络的自监督训练。逐尺度自蒸馏损失l
esd
的定义如公式(2)所示:
[0020][0021]
其中,di表示深度网络解码器部分输出的第i个深度图,upsample(
·
)表示上采样操作,||
·
||2表示图像相似性函数,其定义如公式(3)所示:
[0022][0023]
其中,和表示两张图像的像素值,n表示图像的像素点总数。
[0024]
5.步骤四基于单尺度图像重建损失l
rc
、逐尺度自蒸馏损失l
esd
和边缘平滑损失ls构造深度网络和位姿网络的整体损失函数l
total
。单尺度图像重建损失l
rc
的定义如公式(4)所示:
[0025]
l
rc
=α(1-ssim(i
t
,i
t
′
)) β||i
t-i
′
t
||1(4)
[0026]
其中,i
t
和i
′
t
分别表示输入图像和重建后的图像,ssim表示结构相似性函数,α和β
表示约束平衡因子。
[0027]
边缘平滑损失ls的定义如公式(5)所示:
[0028][0029]
其中,和分别表示输入图像i
t
横向和纵向的梯度,p
t
表示输入图像i
t
某点的像素坐标,素坐标,表示平均深度值。
[0030]
网络的整体损失如公式(6)所示:
[0031]
l
total
=λ1l
rc
λ2ls λ3l
esd
(6)
[0032]
其中,l
total
表示网络整体损失函数,λ1、λ2和λ3是约束平衡因子。
[0033]
与现有技术相比,本发明的有益效果是:本发明提出一种swin-transformer与cnn并行结合的方法用于深度估计任务中,通过分别提取多尺度特征再融合的方式将transformer所具有的具有长程相关性的优点和cnn能有效保持图像空间结构信息的优点结合起来,并以自监督的方式训练整个网络。本发明提出的逐尺度自蒸馏损失,能够减少网络从图像重建损失引起的重复弱监督信号中学习,并且能让网络学习到更好的中间特征表示来提升深度估计的精度。
附图说明
[0034]
图1为本发明模型结构示意图;
[0035]
图2为本发明的深度网络结构图;
[0036]
图3为本发明的swin-transformer模块结构图;
[0037]
图4位本发明的合并操作示意图;
[0038]
图5位本发明的扩展操作示意图;
[0039]
图6为本发明的cnn模块1结构图;
[0040]
图7为本发明的cnn模块2结构图;
[0041]
图8为本发明的scfuse模块结构图。
具体实施方式
[0042]
下面结合附图与具体实施方式对本发明作进一步详细描述。
[0043]
本发明的一种基于swin-transformer和卷积神经网络(cnn)并行网络的自监督单目深度估计方法,其模型如附图1所示,由深度网络和位姿网络两部分组成。深度网络输出不同尺度的单通道深度图di,其中与输入图像分辨率大小相同的深度图d0作为深度估计结果,深度图d0的每个像素值表示深度值大小,位姿网络输出两帧图像之间的相对位姿。该方法具体步骤描述如下:
[0044]
步骤一:利用相机内参已知的单目相机拍摄一段视频,经过处理后得到一系列分辨率大小为h*w、长度n为2的图像序列。
[0045]
步骤二:构建swin-transformer和卷积神经网络(cnn)并行结构的深度网络,将图像序列的一帧图像i
t
作为深度网络输入,输出对应的不同分辨率的深度图d0、d1、d2、
…
、dn,分辨率依次减小,其中d0和输入图像i
t
分辨率大小相同。构建纯卷积网络结构的位姿网络,
将图像i
t
和相邻帧图像i
t-1
在通道维度上拼接后作为位姿网络输入,输出为两帧图像的相对位姿t
t
→
t-1
。
[0046]
步骤二(1)深度网络主要由编码器和解码器两部分组成。
[0047]
编码器的具体构建步骤为:
[0048]
如附图2所示,首先构建swin-transformer分支网络。swin-transformer分支网络由分块操作、线性映射以及swin-transformer模块和合并操作的重复堆叠n次构成。通道数为c,大小为h
×
w输入图像i
t
先通过分块操作和线性映射得到通道数为c,大小为h/4
×
w/4的特征图。其中,分块操作实现方式为每相邻4*4大小的为一块,在通道维度上进行展平,得到通道数为16*c,大小为h/4
×
w/4的特征图,线性映射通过1*1卷积将通道维度从4*c降为c,特征图大小不变。之后每经过一次swin-transformer模块和合并操作,通道数会加倍,特征图的大小会减半。最终swin-transformer分支输出的特征图的通道数为n*c,大小为h/2
n 1
×
w/2
n 1
。输入图像i
t
经过swin-transformer分支总共会得到n个尺度不同的特征图xi。合并操作具体操作如附图4所示,先将输入特征图按块提取相同位置的信息并在通道维度上进行拼接,再通过层归一化操作和线性映射操作,实现输入特征图的下采样操作。
[0049]
然后构建cnn分支网络。cnn分支网络由cnn模块1和重复堆叠n次的cnn模块2构成。cnn模块1具体结构如附图6所示,cnn模块1由两层卷积和一层最大池化组成,其中两层卷积的卷积核大小都为3*3,步长都为1,每层卷积之后都紧接着relu层,最大池化层的池化窗口大小为2*2,步长为2。输入图像i
t
通过cnn模块1输出通道数为c/2,大小为h/2
×
w/2的特征图。cnn模块2具体结构如图7所示,cnn模块2同样由两层卷积和一层最大池化组成,其中两层卷积的卷积核大小都为3*3,步长都为1,每层卷积之后都紧接着relu层,最大池化层的池化窗口大小为2*2,步长为2。与cnn结构1不同,cnn结构2会将输入的特征图通道数加倍,大小减半。最终cnn分支输出的特征图的通道数为n*c,大小为h/2
n 1
×
w/2
n 1
。输入图像i
t
经过cnn分支总共会得到n个尺度不同的特征图yi。
[0050]
最后构建scfuse模块,用于融合编码器中swin-transformer分支和cnn分支输出的不同尺度特征图。如附图8所示,scfuse模块可以将两个相同尺度的特征图进行深度融合,并输出与输入同样尺寸的融合后的特征图,具体操作如式(1)所示:
[0051][0052]
其中,xi和yi分别表示两个输入的特征图,zi为第i个scfuse模块的输出,表示将两个特征图在通道维度上进行拼接,conv1×1表示步长为1,卷积核大小为1*1的卷积步骤,通过该卷积步骤,能让网络自己学习到分配给来自swin-transformer分支和cnn分支特征信息的权重,从而实现更灵活的特征融合。通过n个scfuse模块输出n个不同分辨的融合后的特征图zi。
[0053]
深度网络的解码器具体构建方式为:
[0054]
如附图2所示,解码器部分由扩展操作和swin-transformer模块的重复堆叠组成。扩展操作的作用是对输入特征图进行上采样,具体步骤如附图5所示,先经过一个线性层将通道维度增加到原来的两倍,然后通过与合并操作中相反的重新排列操作将输入特征图的大小扩大到原来的两倍,从而实现输入特征图的上采样操作。解码器的输入来自于编码器的swin-transformer分支的输出再经过一个swin-transformer模块,解码器输出的特征图
经过线性变换得到n 1个不同分辨率的深度图d0、d1、d2、
…
、d
n 1
。
[0055]
深度网络的编码器部分和解码器部分通过一个swin-transformer结构连接。编码器的swin-transformer分支输出和cnn分支经过scfuse模块融合后输出的n个不同分辨的融合后的特征图zi,通过跳跃连接输入到编码器各层,具体方式为与深度网络的解码器每个扩展操作输出进行逐像素相加再输入到解码器各swin-transformer模块中,从而将底层信息融合到深层网络中,使深层网络获得底层关键信息。
[0056]
深度网络中所有的swin-transformer模块内部结构是一样的,具体结构如附图3所示。深度网络的编码器中的swin-transformer模块除了第一个其余的输入都来自于上一步合并操作的输出,并且输出给下一步合并操作以及对应的scfuse模块用于特征融合。深度网络的解码器部分每个swin-transformer模块输入来自于上一步扩展操作输出和解码器scfuse模块输出融合后的特征图,并且输出给下一步扩展操作。
[0057]
步骤二(2)位姿网络为纯卷积结构组成。
[0058]
位姿网络主要包含七层卷积层,每层卷积核的个数分别为16、32、64、128、256、256、256,步长都为2,第一层卷积核大小为7*7,第二层为5*5,其余层都为3*3,每一层卷积后用relu激活层激活,最后经过1*1卷积输出两帧之间的相对位姿,其包含三个欧拉角和三个平移量,描述了拍摄两帧时相机的相对运动。将相邻两帧图像i
t
和i
t-1
在通道维度上拼接后作为位姿网络的输入,输出为两帧图像i
t
和i
t-1
的相对位姿t
t
→
t-1
。
[0059]
步骤三:基于步骤二中深度网络输出的最大分辨率的深度图d0和位姿网络输出的相对位姿t
t
→
t-1
进行输入图像i
t
的视图重建得到重建图像i
t
′
。重建步骤具体为,设p
t
为输入图像i
t
某像素点,使用重投影公式(2)可获得p
t
在相邻帧图像i
t-1
上的投影点ps。
[0060]
ps=kt
t
→
t-1
d0(p
t
)k-1
p
t
(2)
[0061]
然后通过对相邻帧图像i
t-1
中ps最邻近的四个像素点进行双线性采样得到p
t
的像素值,由p
t
组成重建图像i
′
t
。使用重建图像和输入图像构建单尺度图像重建损失,单尺度图像重建损失l
rc
如公式(3)所示。
[0062]
l
rc
=α(1-ssim(i
t
,i
t
′
)) β||i
t-i
′
t
||1(3)
[0063]
其中,ssim表示结构相似性函数,α和β表示约束平衡因子。理论上,如果重建的图像i
t
′
与输入图像i
t
完全一样,则单尺度重建损失为零。
[0064]
基于步骤二中深度网络的解码器部分输出的不同尺度的深度图di计算逐尺度自蒸馏损失,逐尺度自蒸馏损失l
esd
如公式(4)所示:
[0065][0066]
其中,di表示解码器输出的第i个深度图,upsample(
·
)表示上采样步骤,其表示将较小分辨率的深度图d
i 1
采样到di同样大小,||
·
||2表示图像相似性函数,其定义如公式(5)所示:
[0067][0068]
其中,ia和ib表示两幅大小相同的图像,和表示两张图像的像素值,n表示图像的像素点总数。
[0069]
对于深度网络解码器最终输出的深度图d0,构造边缘平滑损失ls如公式(6)所示:
[0070][0071]
其中,和分别表示输入图像i
t
横向和纵向的梯度,p
t
表示输入图像i
t
某点的像素坐标,素坐标,表示平均深度值,边缘平滑损失ls使得物体边缘的深度变化更加锐利,非物体边缘区域的深度变化更加平滑。
[0072]
步骤四:基于单尺度图像重建损失l
rc
、逐尺度自蒸馏损失l
esd
和边缘平滑损失ls构造深度网络和位姿网络的整体损失函数l
total
,网络的整体损失函数l
total
定义如公式(7)所示:
[0073]
l
total
=λ1l
rc
λ2ls λ3l
esd
(7)
[0074]
其中,λ1、λ2和λ3是约束平衡因子。
[0075]
使用单目视频进行网络的自监督训练,直至整体损失函数l
total
收敛。得到训练好的深度网络。
[0076]
步骤五:将单张图像输入到训练好的深度网络中,网络输出与输入图像分辨率大小相同的深度图d0,将深度图d0作为输入图像的单目深度估计结果。
[0077]
综上,本发明的目的在于提出一种基于swin-transformer和卷积神经网络(cnn)并行网络的自监督单目深度估计方法。本发明将swin-transformer和cnn同时用于特征提取,并将提取的特征进行融合,可以使网络在建立长程相关性和保留空间结构信息之间进行平衡,强化网络学习特征的能力,并且结合本发明提出的逐尺度自蒸馏损失,进行网络的自监督训练,进而提升自监督单目深度估计精度。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
