1.本发明涉及网格聚类技术领域,特别涉及一种基于虚拟密度和竞争算法的网格聚类方法。
背景技术:
2.网格聚类算法和任何其它类型的聚类算法一样,网格聚类需要选择适当的超参数来适应不同的分布,且网格聚类算法受到网格划分和密度阈值等因素影响明显,且存在以下技术问题:(1)网格划分对聚类结果有较大影响,如果网格划分稀疏,每个网格单元就比较大,可能忽略小的簇和导致聚类结果受到单元格的矩形影响而失真,且有可能把不应属于当前簇的节点并入,将会降低聚类分析的质量。但单元格太小也会产生很多问题,出现过度划分,将本来应当属于一个簇划分为多个等,还可能出现单元格密度普遍较低的情况,导致选择任何聚类的阈值只能选取1,出现聚类过度,因此任何阈值都不能适应需求。(2)由于常用的网格为矩形,容易产生形状失真,如sting算法产生的平直边缘不符合分布的实际情况。(3)有些分布本身比较稀疏,划分网格后大部分单元格没有或仅有一个点,如果采用1作为高密度阈值则显然把所有的点都纳入分类,不能剔除噪声,如果采用更大的值作为阈值又忽略了大部分成员,不符合算法的目的。
3.现有技术中,有研究人员采用小波变换进行处理,小波变换虽然进行了密度的平滑但也不能很好地处理分布密集度差别很大的带来的问题,对于簇与簇之间没有明显边缘的情况效果略差,另外小波函数具有多样性使得选取比较有难度。也有采用clique、sci等方法,但同样不能灵活的选取有效的阈值,高密度网格的确定也存在着类似的问题,导致不能适应特定的分布。还有采用可变网格划分的方法又,但这种方法相对复杂,且也容易产生矩形聚类,使聚类结果不符合实际分布。此外,网格聚类的另一个主要问题是可能被网格限制,遗漏较多元素,产生过多的离群点,这种问题在clique表现较为明显。
技术实现要素:
4.本发明的目的在于,提供一种基于虚拟密度和竞争算法的网格聚类方法。本发明可以对不同的分布特点的数据集有较好的适应能力,避免了网格聚类大量遗漏元素的情况,体现了网格算法的高效率且保证了效果。
5.本发明的技术方案:一种基于虚拟密度和竞争算法的网格聚类方法,包括如下步骤:
6.步骤1、根据数据空间分布和需求确定单元格虚拟密度邻域,虚拟密度邻域中,当前单元格一侧的单元格行或列数记为ev;
7.步骤2、计算数据空间各维的坐标区间,基于坐标区间和ev划分网格;
8.步骤3、统计落在每个网格中数据点的数量,得到单元格密度;
9.步骤4、计算每个单元格的虚拟密度;
10.步骤5、确定聚类阈值;
11.步骤6、高密度网格群形成簇;
12.步骤7、去除含有成员极少的簇;
13.步骤8、采用竞争算法将没有划归到现有簇中的单元格按照竞争规则分配到合适的簇中,完成聚类。
14.上述的基于虚拟密度和竞争算法的网格聚类方法,对于数据空间,a={a1,a2,...,ar}是包含n个数据点的r维空间数据集v={v1,v2,...,vn}中数据对象的r个属性的有界定义域,w=a1×
a2×
...
×ar
是r维空间,其中任一数据元素vi={v
i1
,v
i2
,...,v
in
}(i∈1,2,...n)的第j个分量v
ij
∈a
ij
;
15.网格划分时将w的每一维m等分,将w分割成mr个网格的单元,称为w的m
×
m划分;
16.基于上述划分,第i维上的单元格边长为:
17.li=(max(v
1i
,v
2i
,...,v
ni
)-min(v
1i
,v
2i
,...,v
ni
))/m(i=1,2,...,r);
ꢀꢀꢀ
(1)
18.第1维序号为k1,第2维序号为k2,...第r序号为kr个单元格记为cell(k1,k2,...kr),任意数据点v
p
={v
p1
,v
p2
,...,v
pn
}i∈(1,2,...r)如果符合:v
pi
∈[li(k
i-1) min(v
1i
,v
2i
,...,v
ni
),l
iki
min(v
1i
,v
2i
,...,v
ni
))(i=1,2,...n)则认为v
p
落入cell(k1,k1,...kr);
[0019]
把落入cell(k1,k1,...kr)的数据点的数量成为cell(k1,k2,...kr)的密度,记为d(cell(k1,k1,...kr));
[0020]
其中单元格c1=cell(a1,a2,...ar),c2=cell(b1,b2,...br)为任意两个单元格;将直接相邻单元格,即有r-1共同边的两个单元格的距离定义为1,基于欧式距离算法,c1与c2的距离为:
[0021][0022]
以单元格p=cell(k1,k2,...kr)为圆心,ε为半径的空间区域作为单元格c的ε-邻域,记作δ
ε
(p);所有满足ri∈(k
i-ε,ki ε)(i=1,2,...,r)的单元格的集合称为单元格p的ε-邻域;
[0023]
单元格p的虚拟密度是其邻域内各单元格的实际密度加权和:
[0024][0025]
式中,r为权值函数,r(x)∈(0,1),其值随着pi与p的距离增大而减小;
[0026]
为计算虚拟密度设置的邻域为虚拟密度邻域,记作δ
ev
,其当前单元格一侧的单元格行或列数用ev表示。
[0027]
前述的基于虚拟密度和竞争算法的网格聚类方法,所述ev值取2-10。
[0028]
前述的基于虚拟密度和竞争算法的网格聚类方法,所述单元格p的虚拟密度采用如下的权值函数来调整邻域内单元格的贡献率:
[0029]
r(d(pi,pj))=r/(d 1);
[0030]
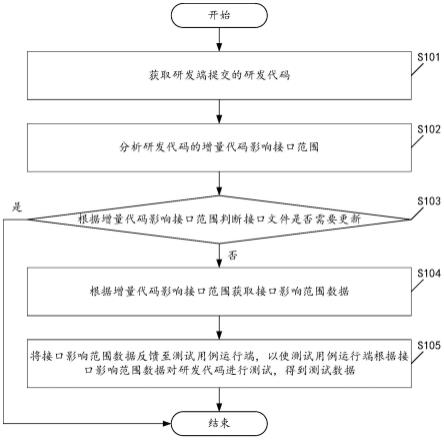
式中,r(d(pi,pi))=1,即当前单元格密度的贡献率为1,r是权值调整系数。
[0031]
前述的基于虚拟密度和竞争算法的网格聚类方法,步骤6中,簇的形成按如下公式进行:
[0032][0033]
其中,当vd(p)<tc并且其直接邻居均不属于任何格簇,则认为当前单元格p不属于任何格簇,其簇号仍然为0;当vd(p)>tc并且其直接邻居均属于簇号为k的格簇,则将单元格p归入该簇号为k的格簇;当vd(p)>tc并且其直接邻居均属于多个格簇,则合并这些集群,并任取其一作为簇号,令其为c
merge
;当vd(p)>tc并且其直接邻居不属于任何格簇,则新建一个格簇,簇号为c
max
1,c
max
是现有格簇的最大簇号。
[0034]
前述的基于虚拟密度和竞争算法的网格聚类方法,步骤7中,设置簇评定阈值clmt,去除单元格少于阈值clmt的高密度单元格群,将高密度单元格数量高于阈值clmt的密度单元格群形成单独的簇。
[0035]
前述的基于虚拟密度和竞争算法的网格聚类方法,步骤8中,所述竞争算法是对于有两个或以上格簇临近的单元格,通过判断该单元格更靠近哪一个格簇来确定其归属;其中为竞争算法设置邻域称为竞争邻域,记作δ
ec
,其当前单元格一侧的单元格行或列数用ec表示。
[0036]
与现有技术相比,本发明根据数据空间分布和需求确定单元格虚拟密度邻域,在进行网格的划分,然后在单元格密度的基础通过计算每个单元格的邻域密度的加权和得到其虚拟密度。根据分布特点和算法目标选取适当密度阈值,将高于密度阈值的连续单元格标记为新的单元格组成的簇,去除零散单元格形成的格簇后引入竞争算法,在确定的邻域内对于每一个不属于任何一个格簇的单元格对比其与临近格簇的相近程度,将其划入更加接近的格簇中。最后将各元素分配到其所在的格簇对应的簇中,完成聚类。本发明引入虚拟密度符合聚类分析的目标,可以更好地反应分布的宏观情况,且单元格的密度得到平滑,突出了高密度区域,模糊了成员分布不均匀性,使高密度区域更加完整清晰。另外可以更好地进行量化密度,虚拟密度不再是一个整数值,可以灵活改变判定高密度的阈值,改变了一些网格聚类中因为只能选取整数导致的无法找到合适的阈值的问题。此外,阈值选择一直比较困难的问题,本发明降低阈值选择的敏感性,格簇竞争的算法可在一定程度上弥补了参数选择可能的不足,使聚类结果更加理想。本发明对不同的分布特点的数据集有较好的适应能力,避免了网格聚类大量遗漏元素的情况,体现了网格算法的高效率且保证了效果。
附图说明
[0037]
图1是单元格的ε-邻域示意图;
[0038]
图2展示了使用三维图展示了虚拟密度,高度为虚拟密度;其中图2中的(1)为d31(d31是数据集)真实密度示意图,(2)是d31虚拟密度示意图,(3)是compound真实密度,(4)是compound虚拟密度;
[0039]
图3展示了ev值对虚拟密度影响,其中图3中的(1)图表示了ev等于3的虚拟密度示意图;图3中的(2)图表示了ev等于10的虚拟密度示意图;
[0040]
图4显示了r值对虚拟密度的影响,其中图4中的(1)图表示了r等于0.1的虚拟密度
示意图;图4中的(2)图表示了r等于0.8的虚拟密度示意图;
[0041]
图5离群点控制效果示意图;其中图5中的(1)图表示了ec等于0的离群点控制效果示意图;图5中的(2)图表示了ec等于1的离群点控制效果示意图;
[0042]
图6为vdgc算法的聚类结果;
[0043]
图7是dpc算法的聚类结果;
[0044]
图8是clique算法的聚类结果;
[0045]
图9是dbscan算法的聚类结果;
[0046]
图10为数据点数与运行时间的比较示意图;
[0047]
图11展示了vdgc算法划分与运行时间关系示意图。
具体实施方式
[0048]
下面结合实施例对本发明作进一步的说明,但并不作为对本发明限制的依据。
[0049]
实施例:一种基于虚拟密度和竞争算法的网格聚类方法,包括如下步骤:
[0050]
步骤1、根据数据空间分布和需求确定单元格虚拟密度邻域,虚拟密度邻域中,当前单元格一侧的单元格行或列数记为ev;
[0051]
对于数据空间,a={a1,a2,...,ar}是包含n个数据点的r维空间数据集v={v1,v2,...,vn}中数据对象的r个属性的有界定义域,w=a1×
a2×
...
×ar
是r维空间,其中任一数据元素vi={v
i1
,v
i2
,...,v
in
}(i∈1,2,...n)的第j个分量v
ij
∈a
ij
;
[0052]
网格划分时将w的每一维m等分,将w分割成mr个网格的单元,称为w的m
×
m划分;
[0053]
基于上述划分,第i维上的单元格边长为:
[0054]
li=(max(v
1i
,v
2i
,...,v
ni
)-min(v
1i
,v
2i
,...,v
ni
))/m(i=1,2,...,r);
ꢀꢀꢀ
(1)
[0055]
第1维序号为k1,第2维序号为k2,...第r序号为kr个单元格记为cell(k1,k2,...kr),任意数据点v
p
={v
p1
,v
p2
,...,v
pn
}i∈(1,2,...r)如果符合:v
pi
∈[li(k
i-1) min(v
1i
,v
2i
,...,v
ni
),l
iki
min(v
1i
,v
2i
,...,v
ni
))(i=1,2,...n)则认为v
p
落入cell(k1,k1,...kr);
[0056]
把落入cell(k1,k1,...kr)的数据点的数量成为cell(k1,k2,...kr)的密度,记为d(cell(k1,k1,...kr));
[0057]
其中单元格c1=cell(a1,a2,...ar),c2=cell(b1,b2,...br)为任意两个单元格;将直接相邻单元格,即有r-1共同边的两个单元格的距离定义为1,基于欧式距离算法,c1与c2的距离为:
[0058][0059]
在二维空间中两个有共同边的单元格距离为1,仅有一个共同点的单元格距离为
[0060]
以单元格p=cell(k1,k2,...kr)为圆心,ε为半径的空间区域作为单元格c的ε-邻域,记作δ
ε
(p);所有满足ri∈(k
i-ε,ki ε)(i=1,2,...,r)的单元格的集合称为单元格p的ε-邻域;
[0061]
在二维空间中为左下角序号分别为k
1-ε,k
2-ε到为右上角序号k1 ε,k2 ε形成的正
方形区域为p的ε-邻域,如图1所示。
[0062]
单元格p的虚拟密度是其邻域内各单元格的实际密度加权和:
[0063][0064]
式中,r为权值函数,r(x)∈(0,1),其值随着pi与p的距离增大而减小;
[0065]
为计算虚拟密度设置的邻域为虚拟密度邻域,记作δ
ev
,其当前单元格一侧的单元格行或列数用ev表示。
[0066]
步骤2、计算数据空间各维的坐标区间,基于坐标区间和ev划分网格;以二维分布为例,统计所有元素,计算坐标x和y的最大值xmax、ymax和最小值xmin、ymin,并以为[xmin-ev,xmax ev]、[ymin-ev,ymax ev]边界划分网格;
[0067]
步骤3、统计落在每个网格中数据点的数量,得到单元格密度d(p);即把落入cell(k1,k1,...kr)的数据点的数量成为cell(k1,k2,...kr)的密度,记为d(cell(k1,k1,...kr));
[0068]
步骤4、计算每个单元格的虚拟密度;单元格p的虚拟密度是其邻域内各单元格的实际密度加权和:
[0069][0070]
式中,r为权值函数,r(x)∈(0,1),其值随着pi与p的距离增大而减小;
[0071]
为计算虚拟密度设置的邻域为虚拟密度邻域,记作δ
ev
,其当前单元格一侧的单元格行或列数用ev表示,所述ev值取2-10。实施例中为3。
[0072]
所述单元格p的虚拟密度采用如下的权值函数来调整邻域内单元格的贡献率:
[0073]
r(d(pi,pj))=r/(d 1);
[0074]
式中,r(d(pi,pi))=1,即当前单元格密度的贡献率为1,r是权值调整系数。
[0075]
步骤5、确定聚类阈值,阈值可以根据实际需要设置;
[0076]
步骤6、高密度网格群形成簇;簇的形成按如下公式进行:
[0077][0078]
其中,当vd(p)<tc并且其直接邻居均不属于任何格簇,则认为当前单元格p不属于任何格簇,其簇号仍然为0;当vd(p)>tc并且其直接邻居均属于簇号为k的格簇,则将单元格p归入该簇号为k的格簇;当vd(p)>tc并且其直接邻居均属于多个格簇,则合并这些集群,并任取其一作为簇号,令其为c
merge
;当vd(p)>tc并且其直接邻居不属于任何格簇,则新建一个格簇,簇号为c
max
1,c
max
是现有格簇的最大簇号。
[0079]
步骤7、去除含有成员极少的簇;设置簇评定阈值clmt,去除单元格少于阈值clmt的高密度单元格群,将高密度单元格数量高于阈值clmt的密度单元格群形成单独的簇。
[0080]
步骤8、采用竞争算法将没有划归到现有簇中的单元格按照竞争规则分配到合适的簇中,完成聚类。所述竞争算法是对于有两个或以上格簇临近的单元格,通过判断该单元
格更靠近哪一个格簇来确定其归属;其中为竞争算法设置邻域称为竞争邻域,记作δ
ec
,其当前单元格一侧的单元格行或列数用ec表示。
[0081]
为了进一步的阐述本发明的效果,图2使用三维图展示了虚拟密度,高度为虚拟密度。其中图2中的(1)为d31(d31是数据集)真实密度示意图,(2)是d31虚拟密度示意图,(3)是compound真实密度,(4)是compound虚拟密度。从中可以看出虚拟密度可以模糊分布中密度的变化,很好地反映了宏观密度的变化,实际应用中可以通过调整虚拟密度算法使vdgc(本发明的方法,称之为virtual density grid competing clustering algorithm,即vdgc算法)适应不同的应用场景。真实密度则可能出现分离的峰值,在各点间距稍大时特别明显,在图2-(3)compound真实密度可以看出网格密度存在的问题。实际使用中应选择合适的参数时虚拟密度突出各簇特征而又不至于忽略的分布的总体情况。
[0082]
本发明的设置ev的目的是为了计算虚拟密度,ev规定了影响当前单元格的单元格范围。可以通过调整ev适应不同的分布,对于密度较低的分布扩大范围,使分散的分布容易形成簇,反之则考虑缩小之,使集中的分布得到区分,形成不同的簇。图3展示了ev值对虚拟密度影响,其中图3中的(1)图表示了ev等于3的虚拟密度示意图;图3中的(2)图表示了ev等于10的虚拟密度示意图。可见增加ev范围,可能使距离近的簇聚集为更大的高密度区,容易形成更大的簇。反之则容易形成更多更小的簇。选择邻域范围和网格划分有一定关系,网格划分细密则应当增大ev值,反之则应减小ev,这样才能使虚拟密度更好地反应宏观特征,更符合聚类的目标。ev对于算法的计算量有较大影响。本实施例各算例多数采用80*80的网格划分,ev值取3,邻域均为49格范围,对于大部分分布是可用的。
[0083]
本发明通过权值函数来调整邻域内单元格的贡献率。图4显示了r值对虚拟密度的影响,其中图4中的(1)图表示了r等于0.1的虚拟密度示意图;图4中的(2)图表示了r等于0.8的虚拟密度示意图,图4的(1)图中r值为0.1,显然得到的虚拟密度接近实际密度,图4的(2)图中r值为0.8,虚拟密度明显更加平滑而峰值更加突出,更接近聚类目标,可见ev不变增大r则可以增大领域内各单元格对密度的贡献率,使虚拟密度相对平缓,使各簇边界变模糊,易于形成较大的簇,降低了聚类的分辨率,反之则提升聚类的分辨率。
[0084]
可见,通过把区分小规模簇的能力称为分辨能力,网格聚类的网格划分如果偏大则明显降低对小而密集的簇的分辨能力,如果网格划分细密则分辨能力更高,可能使完整的潜在簇分离,形成多个簇,对于很多分布来说这是矛盾的,因为簇内成员距离较大,而簇间距离较小,难以实现很好的效果。虚拟密度则一定程度上改变了这些情形,可以通过调整ev和r值控制分辨率,使聚类算法更加可控。
[0085]
进一步地,本发明通过调整ec对离群点进行一定程度的控制,ec增加则离群点减少,反之则增加。图5中的(1)图表示了ec等于0的离群点控制效果示意图;图5中的(2)图表示了ec等于1的离群点控制效果示意图。经过统计,图5中的(1)图离群点有847个,图5中的(2)图有514个离群点。
[0086]
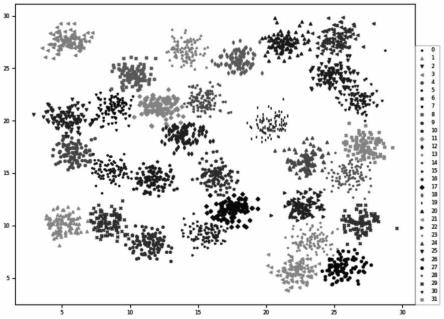
再进一步地,申请人将本发明的方法与dpc算法、clique算法和dbscan算法比较,数据集为d31,均选用适应分布的超参数,图6为vdgc算法的聚类结果,图7是dpc算法的聚类结果;图8是clique算法的聚类结果,图9是dbscan算法的聚类结果。表1是各算法的比较结果(均采用d31数据集)。
[0087]
算法差错数差错率算法耗时
vdgc652%0.14580dpc1103.5%2.49598clique>1000>32%0.14156dbscan47915.45%7.61195
[0088]
表1
[0089]
通过比较可以发现,dpc算法有110个点划入错误簇中,而vdgc则有65个点,clique算法则产生了35个簇,有681个点认作离群点,且出现了簇的分裂和合并。需要说明的是这些错误并非事实上错误,原数据集的划分也有较多模棱两可的情况。
[0090]
与dpc算法不同,vdgc算法无需指明簇数量。算法效率方面在同样软硬件环境下vdgc耗时0.14580秒,而dpc耗时2.49598秒,显然计算各点之间的距离有更高的算法复杂度。
[0091]
从上述结果看出vdgc聚类的质量明显好于其它各算法,其速度也明显比多数算法更快,这反应了vdgc算法效率优势。
[0092]
如果对空间w做m
×
m的网格划分,vdgc算法复杂度为o(m2),几乎与数据点数量无关,图10为数据点数与运行时间的比较示意图,可见在数据较多的情况vdgc算法效率优势更加明显。图11展示了vdgc算法划分与运行时间关系,可见其明显的相关性。
[0093]
综上所述,本发明所提出的虚拟密度方法使得网格聚类可以从更加宏观的角度处理聚类问题,vdgc算法有较多可以调节的参数,带来一定复杂性的同时也使算法更具灵活性和可控性,使其更具有适应能力。此外本发明还具有效率优势,本发明为网格聚类提供有价值的思路。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。