一种基于无监督神经网络lbri的动作识别方法及系统
技术领域:
:1.本发明涉及计算机
技术领域:
:,尤其涉及一种基于无监督神经网络lbri的动作识别方法及系统。
背景技术:
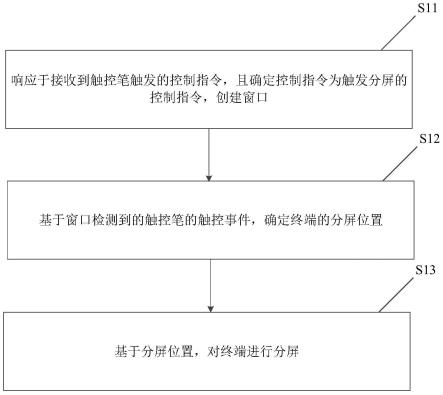
::2.计算机动作识别领域,常常会采用循环神经网络和长短期记忆网络等进行动作识别,其中,循环神经网络(recurrentneuralnetwork,rnn)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络(recursiveneuralnetwork)。3.长短期记忆网络(lstm,longshort-termmemory)是一种时间循环神经网络,是为了解决一般的rnn(循环神经网络)存在的长期依赖问题而专门设计出来的,所有的rnn都具有一种重复神经网络模块的链式形式。在标准rnn中,这个重复的结构模块只有一个非常简单的结构,例如一个tanh层。4.但是现有技术当中并没有一种可仿生,并且可高效进行动作识别的方法。技术实现要素:5.本发明的目的是提供一种基于无监督神经网络lbri的动作识别方法及系统,以解决如何提高动作识别效率的技术问题。6.本发明的目的是采用以下技术方案实现的:一种基于无监督神经网络lbri的动作识别方法,包括如下步骤:7.s1:获取动作信息,并提取特征值;8.s2:将特征值通过特征总线fb传输至lbri模型,所述特征值为随时间输入的特征值序列tsq,将特征值序列tsq归类为排列类atar;9.s3:lbri模型记忆新的排列类atar,识别旧的排列类atar,解决动作识别的问题。10.进一步的,所述lbri模型会记住若干排列类atar,当向lbri模型输入已经记住的排列类atar时,lbri模型将其识别;当向lbri模型输入新的的排列类atar时,lbri模型将其进行记忆。11.进一步的,通过感受器-大脑模型rb中的感受器receptor从外界接收刺激,并将其提取出特征值。12.进一步的,所述感受器receptor包括去除全连接层的cnn。13.进一步的,所述lbri模型包括长短期记忆网络框架lstmf模块、生物本能神经网络训练模块、循环联想神经网络rann模块和可解释序列脉冲神经网络isnn模块。14.进一步的,所述长短期记忆网络框架lstmf模块包括短期记忆子模块、长期记忆子模块和生物本能子模块,其中,所述短期记忆子模块用以对传入的特征值按照时间顺序进行处理及无条件记录;所述长期记忆子模块用以对传入的特征值进行推理;所述生物本能子模块用以识别重复出现的、规律性的特征值序列,并生成新的长期记忆。15.进一步的,所述生物本能神经网络训练模块包括rdtc生物本能子模块和lgen生物本能子模块,所述rdtc生物本能子模块用以定期对短期记忆进行检索并判断其中的序列是否是有重复出现的规律性片段,将其进行分类并指出;所述lgen生物本能子模块用以生成长期记忆,若rdtc检测到有重复出现的规律性片段则根据此些片段生成新的长期记忆。16.进一步的,所述循环联想神经网络rann模块包括微分循环神经网络drnn子模块、对象记忆子模块和序列记忆子模块,所述微分循环神经网络drnn子模块用以求出特征值变化的趋势;所述对象记忆子模块用以对特征值的记忆以类划分;所述序列记忆子模块用以模拟生物短期记忆记住最新的,忘记最旧的的特性。17.进一步的,所述可解释序列脉冲神经网络isnn模块包括推理igear子模块和非脉冲神经元filter子模块,所述推理igear子模块用以模拟排列类atar;所述非脉冲神经元filter子模块用以接收特征值总线fbr的输入,并输出至推理igear子模块。18.一种基于无监督神经网络lbri的动作识别系统,包括lbri模型,所述lbri模型用以解决动作识别的问题。19.本发明的有益效果在于:本发明相较于现有技术,在动作识别方面,更仿生、更节约存储空间,并且识别效率更高。附图说明20.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图示出的结构获得其他的附图。21.图1为本发明流程图;22.图2为3dcnn输入输出流程图;23.图3为采用lbri模型的输入输出流程图;24.图4为循环联想神经网络rann模块原理框图;25.图5为对象记忆子模块积累同一类原理图;26.图6为一个同一类在对象记忆子模块的结构;27.图7为smc结构原理图;28.图8为个sum为6的smc队列图例图;29.图9为图8循环队列展开后的原理图;30.图10为序列实例;31.图11为图10抽象图;32.图12为序列原理图;33.图13为图12抽象图;34.图14为igear子模块原理图;35.图15为igear抽象图;36.图16为非脉冲神经元filter子模块原理图;37.图17为第m与第m 1个成员的igear结构示意图;38.图18为数据制作流程图;39.图19通过数据集制作长期记忆的流程图;40.图20为lbri模型总的示意图。具体实施方式41.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。42.应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。43.下面结合附图,对本发明的一些实施方式作详细说明。在不冲突的情况下,下述的实施例及实施例中的特征可以相互组合。44.实施例1:45.参阅图1,一种基于无监督神经网络lbri的动作识别方法,包括如下步骤:46.s1:获取动作信息,并提取特征值;47.s2:将特征值通过特征总线fb传输至lbri模型,所述特征值为随时间输入的特征值序列tsq,将特征值序列tsq归类为排列类atar;48.s3:lbri模型记忆新的排列类atar,识别旧的排列类atar,解决动作识别的问题。49.lbri模型的数学基础、能处理的问题以及其输入输出:50.输入基础:序列,序列同常规数学定义相同,是指元素进行有规律排列。对于任意序列a,a中的第n(n∈n*)成员是指按顺序从头计数排在第n个的元素,记为a(n)num(使用num上标作为标记),称a(n)num与a(n 1)num相邻,称n为成员序号。表示序列时不同成员用符号“,”相隔。序列a中从a(n)num开始至a(n k)num成员结束(序列本身不会少于n k个成员,n∈n*,k∈n)的部分称为序列a的子序列,记作a'ssn,n k(a’ssubsequence,起始序号作为下标)。排列,任意序列b的一个排列是指序列b中相邻或不相邻的若干成员按在序列b中的次序形成的组合。b的排列也是一个序列,如在序列b1,6,7,8,3,4中第2、3、5个成员6,7,3就形成一个排列。排列中成员出现的顺序必须与其序列中元素出现的顺序相同,如3,7,6便不是一个排列。b的排列记作b'ara(b’sarrange),其中a是排列包括成员的序号按升序形成的序列,上述的6,7,3记作b'ar2,3,5。排列b'ara囊括的子序列是指序列b中从排列的第1个成员开始至排列的最后1个成员结束的子序列,函数cs(b'ara)(calculatesubsequence)是用于求得b'ara囊括子序列的函数。如b'ar2,3,5囊括的子序列为cs(b'ar2,3,5)=b'ss2,5。序列、子序列、排列的长度都等于其包含了成员的数量。设c是序列b的一个排列或子序列,且b(n)num是c的第m成员,则称b(n)num是c(n)num的父映射成员,c(n)num是b(n)num的子映射成员。如b'ar2,3,5(3)num的父映射成员是b(5)num。51.lbri模型能处理的问题:lbri的输入同脉冲神经网络(snn)一样。随着时间推移,特征值不断地通过特征总线(featurebus:fb)向lbri输入,lbri会像生物一般对输入持续进行反应。输入的特征值是随时间输入的特征值序列tsq(timesequence:时间序列)。tsq比普通序列多一种属性,便是相邻成员的时间差。tsq可以用《s,t》的二元组表示,s为任意序列,长度为n,t为对应s的时间差向量,有n-1维。其中t的任意第m位(m《n)代表着s(m)num与s(m 1)num的在fb上的传入时间差。对于任意的tsq序列s中的成员s(a)num、s(b)num(a《b),定义二者之间在fb上的传入时间差为s(a)num,s(b)num)t。定义接受一个序列成员的一维函数pred与posn,pred为求输入和其前一个成员(如果有的话)的传入时间差,posn为求输入和其后一个成员(如果有的话)的传入时间差,即52.pred(s(b)num)=(s(b-1)num,s(b)num)t,posn((b)num)=(s(b)num,s(b 1)num)t53.tsq中部分成员是无用的噪音,而部分成员则组成若干类有规律的、需要识别的序列。称这种排列类为atar(attentionarrange)。一个atar代表一类tsq,如跑步代表着一类动作序列。lbri模型会记住若干类atar。当其遇见已经记住的atar时,将其识别;遇见新的atar时判断出tsq中存在着一个新的atar并将它进行记忆。lbri的解决的问题是记忆新的atar,识别旧的atar。此问题为attentionarrangerecognizequestion(可被注意序列的识别问题),其的一个典型下属问题便是动作识别。54.lbri模型的输入输出:涉及一种模型receptor-brainmode(感受器-大脑模型,简称rb)。在rb中receptor从外界接收刺激(比如传入图像)并将其提取出特征值,之后receptor再将特征值通过featurebus(特征值总线,简称fb)传递给brain,brain对特征值进行处理并产生结果。lbri在此模型中担任brain的角色,而receptor已有很多模型,如去除全连接层的cnn(若干的卷积层和池化层)。55.以下将使用cnn作为例子,阐述lbri模型与传统深度学习输入与输出的不同。传统cnn的brain为全连接层,在此例中lbri取代了全连接层作为brain,而之前的卷积、池化层作为receptor则类似生物的眼睛——为brain提供以神经脉冲为形式的特征值。在处理动作识别时,一种传统cnn将多张图片作为输入、执行一次推理并产生输出(被称为3dcnn,其输入输出可参阅图2),而使用了lbri模型替换全连接层的cnn将图片按照拍摄时间依次传入(流程图可参阅图3),lbri模型将不断作出反应并产生输出(类似snn)。以上比较只是一个例子,lbri模型不止可以嵌入cnn,只要receptor改变,其就可以处理其他来源的特征值(不只是图片,如声音)。lbri的输入输出同snn非常像,这是由于循环联想神经网络rann和可解释序列脉冲神经网络isnn的结构导致的,这将在后文提及。56.lbri模型包括长短期记忆网络框架lstmf模块、生物本能神经网络训练模块、循环联想神经网络rann模块和可解释序列脉冲神经网络isnn模块。57.长短期记忆网络框架lstmf(longshort-termmemoryframe:lstmf)模块,是lbri模型的框架,分为三个子模块,短期记忆子模块、长期记忆子模块和生物本能子模块。58.短期记忆子模块,此部分负责对传入的特征值按照时间顺序进行处理及无条件记录(即只要有传入就将其处理并记忆)。短期记忆有存储上限,当达到存储上限后若有新的特征值传入便会遗忘时间最早的记忆(最早到来的特征值),腾出容量给最新传入的特征值。59.长期记忆子模块,此部分负责对传入的特征值进行推理。长期记忆模块中有着大量长期记忆,每一条长期记忆对应着一类atar。其功能是:如果一类atar已存在于长期记忆模块中(被学习),那么若属于此atar的tsq完整传入时,长期记忆部分便能识别出此tsq并产生特定的信号:recall。此过程称为推理。功能如何实现将在后文解释。60.生物本能子模块,是lbri模型中对神经网络的一套训练方法。其有两部分功能:1)识别重复出现的、规律性的特征值序列的功能rdtc(repetitiondetect:重复序列勘察),2)生成新的长期记忆(生成新的神经网络)的功能lgen(long-termmemorygenerator:长期记忆生成器)。需要强调的是rdtc,rdtc功能定期扫描短期记忆,如若疑似出现新的atar,其将产生特定的信号:detected。61.lstmf的大体逻辑是:短期记忆子模块与长期记忆子模块并行运行,当特征值传入时,短期记忆将其处理并存储,而长期记忆直接接收进行推理。rdtc定期扫描短期记忆,若期间未产生detected,则认为最近传入的序列都是无规律的、不值得学习的,或已经学习过,lbri模型将不产生额外行为;但若有detected出现,那么lbri模型将认为最近传入的特征值可能存在新的atar。之后lbri将调用生物本能的lgen功能,根据rdtc,制造出若干新的长期记忆加入长期记忆子模块中。需要指出的是:一开始长期记忆子模块中并没有任何长期记忆,在不断的特征值输入过程中lbri模型将不断积累长期记忆,而后这些长期记忆便可用于推理。因此lbri模型是一种无监督学习的模型。62.生物本能神经网络训练(biologicalinstincttrainingmethod)模块,biologicalinstinct是一种学说与仿生的训练方法,现将描述它的来源及其原理。生物有一经诞生便拥有的、类似函数映射的能力,如看到某种食物后下意识判定能不能吃。现称这种能力为“biologicalinstinct”(生物本能)。生物本能是一种映射,给予输入并产生输出,是一种象征着直觉的函数。可以使用达到函数映射功能的结构模拟生物本能。在lbri模型中,被模拟的生物本能有两个:rdtc生物本能子模块和lgen生物本能子模块。63.rdtc(repetitiondetect):rdtc拟合的生物本能:将一组序列作为输入,人能够判断其是否具有重复的片段,将其进行分类并指出。rdtc会定期对短期记忆进行检索并判断其中的序列是否是有重复出现的片段。rdtc部分以短期记忆为输入,并产生特定格式的输出。输出具体格式将在后文提及。64.lgen(long-termmemorygenerator):lgen拟合的生物本能:在学习到新的事物后人脑中的神经元之间结构会发生不同程度及方面的变化。这种变化同输入有一定的函数关系。长期记忆是由一种类似snn的网络,新的长期记忆生成的过程对应着神经元之间产生新的变化。新网络中神经元的参数数、连接的权重,将由lgen对应的生物本能求得。lgen的输入是rdtc的输出,而lgen的输出则是新的长期记忆。rdtc与lgen的细节将在后文描述,二者都是映射功能的函数结构。65.循环联想神经网络rann(recurrentassociateneuralnetwork:rann)模块。现提出“记忆对象与记忆序列分离”假说,当人记住一组序列a时,如看到一段动作,人们并未将a的每个成员都进行记忆,而是将成员归类到已经存在于记忆中的若干类中,并将a转化为不同类的序列。每一种类被单独记忆,存储具体的细节,而有关时间序列的记忆则只记住这些对象出现的先后顺序,而并不去记忆具体的细节。以上的观点称为对象序列分离说。循环联想神经网络rann模块包括微分循环神经网络drnn(differentialrnn)子模块、对象记忆(objectmemory)子模块和序列记忆(sequencememory)子模块。后两部分应用了记忆对象与记忆序列分离假说。循环联想神经网络rann模块原理框图可参见图4。66.微分循环神经网络drnn子模块,是一种rnn,其加工fb传来的特征值并输出到lbri内部通用的特征值总线fbr(featurebusafterrnn)。fbr传递的特征值的维度为fbrd,fbr每隔fbrt传入新的特征值,此值与fb保持一致。drnn的目的是求出特征值变化的趋势,其认为当下特征值代表着的状态不止取决于自己,也取决于之前传入的特征值。如小球进行直线或曲线运动,截取某一时刻的图像并不能判断是直线还是曲线运动,需要结合之前的图像。drnn相当于对一串序列进行微分,求得当前序列处于何种状态。67.可以作为drnn的rnn有两个条件:较差的记忆力和抗噪音。1.较差的记忆力,rnn只应记住近期传入的特征值序列。无论之前输入过何种序列的特征值,只要近期输入的特征值序列相似,rnn就应拥有相近的隐状态及输出。2.抗噪音,若近期输入的特征值序列近似,即使有噪音使他们不完全相同,rnn也应拥有相近的隐状态及输出。特征值序列近似的标准应由使用者决定。应使用特制的训练集来训练rnn以达到上述目的。drnn部分也可由lstm模型等与rnn功能近似的结构实现。68.对象记忆子模块,objectmemory实现了对象序列分离假说中的对象部分。其从fbr上接收特征值,其采用了聚类思想。objectmemory对特征值的记忆以类划分。如若两个特征值向量距离相近则视为同一类(cluster)。一开始objectmemory中并没有cluster,在特征值不断传入的过程中objectmemory会积累大量cluster(参见图5)。一个同一类在对象记忆子模块的结构可参阅图6,centroid为cluster的质心,是一个向量,其维度为fbrd。当特征值与centroid距离小于某使用者给定的阈值tolerance时则该特征值被归类为此cluster;weight为cluster的权重,是一个数,其值域为(0,wmax),wmax是使用者给定的正常量,代表最近一段时间传入特征值属于此cluster的频率,初值为一个属于(0,wmax)的常数,如何确定见下文。average为归属于cluster的特征值与centroid距离的均值的象征,是一个数,均值越大average越大,初值为0;variance为归属于cluster的特征值与centroid距离的方差的象征,是一个数,方差越大variance越大,初值为0;当新特征值a从fbr传来时,objectmemory会同记忆中所有cluster进行比较。若a与一个cluster的centroid距离大于tolerance时则判定a不属于此cluster。69.现分3种情况讨论:1.objectmemory中还没有cluster;2.objectmemory中有cluster但a不属于任何的cluster;3.objectmemory中有cluster且a属于若干个cluster。70.情况1:创建一个新的cluster,将a作为其centroid,并为weight、average、variance赋予初值。71.情况2:创建一个新的cluster,将a作为其centroid,并为weight、average、variance赋予初值。weight的初值有两种选择,第一是所有cluster的初值都采取使用者给定的常数,第二是制作一个函数结构,利用centroid初值决定weight初值。此函数结构可以用ann之类的实现,目的是为了对于部分特征值有所侧重,使lbri投入更多注意力到某类特殊的特征值上。这个函数结构需要使用者按需训练。72.情况3:选择centroid与a距离最近的cluster作为a的所属类。若有多个cluster的centroid与a的距离都很接近则选择weight最大的cluster作为a的所属类。之后将a所属cluster的centroid、average、variance值重新计算,同时提高weight值。73.现说明上述步骤中cluster各参数的具体变化方式:每个cluster的centroid、average、variance值只有在情况3的时候才进行更新,在其他时间保持不变。情况3中centroid、average、variance计算方式:74.centroid′=centroid (centroid-a)×f(weight)×μ75.average′=average×(1-fraca(weight)) dis(centroid,a)×fraca(weight)76.variance′=variance×(1-fracv(weight)) |dis(centroid,a)-average′|×fracv(weight)77.其中centroid、average、variance为计算前的旧值,centroid’、average’、variance’为计算后的新值,μ是学习步长,是人为给定的正常量,选择何值应在具体应用场景下进行大量实验来确定。f(x)是满足以下条件的函数:78.1)定义域为(0,wmax)、值域为(0,e),其中e是人为给定的正常量;79.2)在定义域上连续且单调递减;80.dis(x,y)是求得向量x、y之间距离的函数。81.fraca(x)、fracv(x)是满足以下条件的函数:82.1)定义域为(0,wmax)、值域为(0,1);83.2)在定义域上连续且单调递减。84.在两种状况下cluster的weight会改变:1.时间流逝,2.发生情况3。85.1.时间流逝,weight每隔dt秒会下降dw大小的值,其中86.dw=g(weight)dt87.其中g(x)可以是满足以下条件的任意函数:88.1)定义域为[0,wmax][0089]2)g(0)=0,g(wmax)=0,g(x)<0。[0090]3)有视情况而定的、位于(0,wmax)中的常数b,g(b)为函数g(x)的最小值。[0091]4)函数在定义域上连续,且在(0,b]上单调递减,在[b,wmax)上单调递增[0092]上述参数及函数由使用者依情况给定。[0093]2.发生情况3,发生情况3后weight应上升一个常数是处于(0,wmax)之间的、视情况而定的常数,称为上升步长,一般远小于wmax。[0094]如果后大于wmax,强制令weight=wmax-α,其中α是视情况而定的大于0的常数,且α<<wmax。[0095]以上便是centroid与weight的具体变化方式。值得注意的是,虽说f(x)、g(x)、fraca(x)、fracv(x)可选择任意满足条件的函数,但不同函数的选择将会对lbri带来巨大影响,选择何种函数应在具体应用场景下进行大量实验确定。当一个cluster的weight值小于fgt即其太久未出现时,lbri会将其删除。这个过程称为遗忘,其中fgt》0且fgt<<wmax。可以看出,只要fbr传入特征值,那么其经过objectmemory后必定会归属于某个cluster。上述参数及函数由使用者依情况给定。[0096]序列记忆子模块,sequencememory部分实现的是对象序列分离说中的序列部分,其不记忆fbr传来的特征值,而是记忆特征值属于的cluster。[0097]sequencememory是长度有限的、以cluster为元素的tsq。sequencememory采用了类似循环队列的记忆方式以模拟生物短期记忆记住最新的,忘记最旧的的特性。其由大量的序列记忆细胞(sequencememorycell:smc)构成。[0098]首先说smc的结构。一个smc拥有两个指针,一个指向下一个smc,称为nextpointer(nptr:指向下一个的指针);另一个指向一个cluster,称为associatepointer(aptr:注意力指针)。现分两部分讨论sequencememory的结构。[0099]1.smc之间的结构,smc之间组成循环队列,所有smc使用nptr指向下一个。一个smc只能被一个smc所指向,它们首尾相连。同时,还有一个头指针header指向某一个smc(可参阅图7)。smc的数量是固定的,数量越多短期记忆所能记住的越多,在最开始时header指向任意的smc。每一个smc对应一个fbr传入的特征值,但smc不记录具体特征值。其中header指向对应最新传入特征值的smc,此smc称为hsmc。当新的特征值传入时,将由当下hsmc的下一个smc与其对应,header将指向hsmc的下一个smc。此过程称为hsmc迭代。如若smc0指向smc1smc1指向smc2,开始时smc0为hsmc,现有特征值a、b依次传入,当a传入时,a将对应smc1,header将指向smc1,smc1成为当下的hsmc;当b传入时,b将对应smc2,header将指向smc2,smc2成为当下的hsmc。当整个smc循环队列填满时,即整个队列的smc都成为过一次hsmc后,若新的特征值传来,hsmc迭代依旧会发生。此时代表最旧记忆的smc将对应最新的特征值。通俗来讲,最旧记忆会腾出空间给最新记忆。[0100]2.smc指向cluster的结构,一个smc对应一个特征值的特性是由aptr实现的。当特征值a从fbr传入时,objectmemory将输出其归属的cluster,同时sequencememory中的hsmc迭代同步发生,生成新的hsmc,并将hsmc的aptr指向a归属的cluster。若smc未成为过hsmc则令其aptr置空,若smc所指向的cluster因weight太小被删除则同样令其aptr置空。[0101]综上所述,objectmemory使用其cluster结构记录特征值的细节,sequencememory使用smc循环队列记录cluster序列。通过smc寻找指向的cluster的过程称为联想(associate)。[0102]rann的结构及行为已阐述结束,下面阐述与rann有关的biologicalinstinct功能:repetitiondetect。[0103]dtc功能的目的是为检索存短期记忆对应的tsq无重复atar。将smc循环队列展开为一个长度为sum的序列,hsmc的下一个smc是第1成员,hsmc是第sum成员,被指向的smc位于指向其的smc之后。之后将smc联想的cluster按此顺序排成tsq并称其为cw(currentwindow:当下窗口),代表着短期记忆内记忆的特征值序列。cw的长度为sum,其元素都是cluster,且相邻成员的时间差为fbrt。一个sum为6的smc队列图例如图8所示,其循环队列展开之后参见图9,则cw序列按顺序为:cluster2,cluster3,cluster3,cluster2,cluster1,cluster1;其时间差向量为[fbrt,fbrt,fbrt,fbrt,fbrt]。[0104]现提出同位置特征近似假说(samepositionresemblance)。在人类认为近似的两个排列中,决定排列近似度的因素不止是排列的长度之类的排列的基础属性,而更取决于人们对排列中每个成员留下的印象。如图10所示,虽然序列a与b长度不同、b与c长度相同,但受试者仍认为a与b的相似度高于b与c,如图11所示。虽然图a与b长度不同,也不是相似图形(即等比例放大缩小图形),且b与c的图形比例相对于a与b来说更为接近,受试者仍认为a与b较b与c更为相似。同位置特征近似理论认为人会对物体提取一个大致结构的特征值,且人认为具有相近结构的物体更相似。而在具有相似结构的事物中,有些元素则被称为地位近似的,如图12和图13所示,受试者认为在上述ab中,被虚线相连的元素在相似结构中具有相似地位。同位置特征近似假说:人的大脑会对其认定相似的结构中的、具有相似地位的元素产生近似的特征值。该特征值称为地位特征值,有如下特点:仅在相似的结构中具有相似地位的元素才能产生相近的特征值,在其他情况下任意两元素产生的特征值应该距离很远。(即使相似结构不同地位的特征值也离得很远)若a、b是来自两个相同或不同序列的成员且它们的地位特征值相近,则称a等价b。在第一例中a的第3个成员与b的第三个成员等价,a的第6、7个成员及b的第6个成员互相等价。结构相似的评价标准由使用者给出,使lbri模型拥有同等的标准必须制作特殊训练集对rdtc进行训练。[0105]在cw序列中,weight高的cluster将更加被注意。若cw中一些高weight的cluster组成的具有近似结构的排列反复出现,称此类排列同属一类atar。现对于cw上任意一类atar:b,对于任意的cw'ara,若其属于b,则称为b的衍生排列,称b的衍生排列囊括的子序列为b的衍生子序列,一个衍生序列内必有至少一个衍生子排列。若子序列a为b的衍生子序列,称a属于b。cw上必须有多个互不重合的、成员weight权重较高的、结构相似的子排列才可视为cw上出现了一类atar,atar的结构是这一类相似的结构。即使b的某个衍生子序列中混入一些低weight的cluster,该子序列仍属于b的衍生子序列,低权重的cluster将被视为噪音。b的衍生子排列中有效成员(高weight)称为valid,噪音成员(低weight)称为noise。b的衍生子排列或衍生子序列的长度或成员都不一定相同,判定一个cw的子序列是否属于b的充要条件是其valid组成的排列是否与b的结构相似。注意,cw成员的特征值与地位特征值概念不同,特征值指cw成员cluster的centroid记录的特征值,地位特征值只成员根据前后结构生成的特征值。[0106]使用者训练rdtc的目标是使其能从cw中识别出对于自己的标准来说结构相似的、同属一类的子序列们,这需要按需求制作定制的训练集。但给定的结构相似标准必须遵循以下限制:[0107]1.等价类齐全[0108]等价类是指一类相互等价的所有成员(无论是否来自同一tsq),不同等价类之间的成员不等价。一类atar中有若干等价类,设任意的b类atar有n个等价类,b的任意衍生子排列b必满足此条件:对于n个等价类,b的每一个成员都必须被归为其中一类,且对于这n个中任意一个等价类,b都至少有一个成员属于它。b的衍生子序列由于混入噪音所以不一定满足此条件。对于包含若干b类atar的衍生子排列的任意集合ba及ba中任意一个排列的任意一个成员c,定义二元函数eql(ba,c)可以求得ba所有序列中和c同属一个等价类的所有成员的集合。eql的输入为一个tsq集合和属于此集合中任意序列的任意成员。[0109]2.相邻等价类时间差近似[0110]属于不同等价类的成员在一类atar的衍生子排列中的出现是有次序的。一类atar等价类可以按次序形成等价类序列。设在b类atar中有相邻的第n与n 1个等价类,b有任意的衍生子排列b的两个成员b1与b2分别属于第n与n 1个等价类,则(b1,b2)t必须处于一个范围之内。此范围称为相邻类范围。通俗解释,若人记住过一组动作a,当a中某一个动作的下一个动作太早或太迟出现时人们都会认为所看到的不是动作a了。[0111]rdtc通过将cw序列分割成不同的、属于不同类的子序列并标记来实现功能。同一个cw序列上可能存在着不止一类atar。使用者应为自己需求训练rdtc,但rdtc必须满足排异限制。[0112]排异限制,cw中较长的子序列最多只能被划分到一类atar的一个子序列中。即在rdtc划分后的cw上,任意两个衍生子序列之间不可大规模重合,无论是否属于一类。两个子序列大规模重合指同时存在于双方的成员数量与任意一方长度之比大于某个上限阈值a,a的具体值由使用者根据需求而定。图例是当时违反排异限制的划分方式。子序列b公有成员数量与长度之比达到超过a,所以a、b大规模重合。rdtc在大多数情况下不应做出违反排异限制的划分,这需要使用者制作特殊训练集训练。[0113]rdtc的输入规格,rdtc接受的输入共有sum个维度相同的向量,称为输入子向量。每一个cw的成员对应一个输入子向量,按照cw序列的顺序将sum个输入子向量拼接为输入矩阵对rdtc进行输入。对于任意的n《sum,cw(n)num的输入子向量对应输入矩阵第n列的向量。输入子向量有fbrd 1个维度,由cw成员cluster的centroid向量与weight拼接而成。其中前fbrd维为centroid,最后一位为weight。综上所述rdtc的输入是一个(fbrd 1)×sum的矩阵(输入矩阵)。其中,若有smc的aptr置空,则令其的输入子向量为零向量。[0114]rdtc的输出同样是一个矩阵,由对应着每个cw成员的、sum个输出子向量按cw中的顺序拼接而成。输出子向量由三部分组成:judge、head、position。judge与head是两个数,位于输出子向量的前两位,而position是posd维的向量,posd由使用者结合具体情况给定,位于输出子向量的后posd位。所以输出子向量共有posd 2维,rdtc的输出则为一个(posd 2)×sum的矩阵(输出矩阵)。其中,judge与head位的值域应为(0,1)。rdtc凭借judge与head位划分cw序列,其中的position特征值是生成的cw成员的地位特征值。设cw中划分出了两个子序列a与b,若a与b同属一类atar,则其地位相近的成员对应输出矩阵中的position向量也应距离相近。rdtc应满足以下输出限制:[0115]将整个cw序列化为输入矩阵输入rdtc并得到输出矩阵,若存在至少一类atar,应有:[0116]1.输出矩阵中,valid对应的输出子向量的judge位应尽可能接近1,noise对应的输出子向量的judge位尽可能接近0;[0117]2.输出矩阵中,cw划分得到的任何一个衍生子序列中首个成员对应的输出子向量head位应尽可能为1,最后一个成员对应的输出子向量head位应尽可能为0,其它情况下此位应处于0与1之间,不接近它们中的任何一个。rdtc功能建议使用传统dnn或使用自注意力机制的transformers实现,因为这是一个非线性的函数。[0118]可解释序列脉冲神经网络isnn(interpretablesnn-analogousneuralnetwork)模块,isnn类似于snn,但改变了一部分结构,isnn的结构与功能:[0119]1.isnn中的脉冲神经元使用简化后的lif(leakyintegrate-and-fire)模型。为简化计算及提升可解释性,取消了神经脉冲的传播时延及持续放电的行为。神经元的动作由在电位达到阈值后短时期内放电简化为在电位达到阈值后只放电一瞬间,同时接受神经脉冲的后续神经元的电位不再是持续上升,而是立即上升一个数。2.isnn中部分神经元可以被封锁,以此特性替换生物神经元的不应期。被封锁时,输入突触的电位脉冲将不会对神经元的电位产生影响。isnn神经元的行为是:[0120][0121]u(t dt)=u(t) du(t) cuj·∑j、wj·cj(t)ꢀꢀ式2[0122]s(t)=1,u(t)=ur2ifu(t)≥uth[0123]s(t)=0ifu(t)<uth[0124]式中,t代表时间变量,u(t)为膜电位函数,s(t)为输出的脉冲电位函数;dt代表时间步长,du(t)代表膜电位在一个时间步长内自发改变的值;τ是常数,ur1为静息电位,ur2为重置电位;uth是膜电位阈值;wj为第j个输入突触的权重,cj(t)是第j个输入突触的脉冲电位函数;cuj是第j个输入突触的控制条件,是布尔函数,当电位脉冲传入时,根据具体情况决定cuj取0还是1。cuj将若干个自己或其它神经元的电位是否处于某个范围当作判断条件;其中cj(t)只在离散的点上值为1,t取其余值时为0。这意味着cj(t)的定义域上不存在任何一处连续的部分使cj(t)取值为1。上述参数在每个神经元中都不同。公式表明正常情况下每过dt时间神经元膜电位便会改变du(t),式1给出二者的比例;而当电位脉冲从输入突触传来时,则根据突触是否被封锁来判断决定膜电位受的影响。如果受影响则膜电位立即根据输入突触的权重上升一个常数,否则无变化。当膜电位高于uth时立即释放一次电位脉冲,之后膜电位降为ur2。[0125]构成isnn的基本组件包括推理igear子模块和非脉冲神经元filter子模块。igear(inferencegear:推理组件)子模块,一个igear由四个神经元组成,名称分别为:trigger、upperlimit、lowerlimit、and(触发器、上限、下限、与运算)。其中trigger的输出只连接到upperlimit和lowerlimit,upperlimit和lowerlimit的电位是and的控制条件,upperlimit的电位是trigger的控制条件(此关系用虚线表示)。igear子模块原理图可见图14。[0126]igear的输入包括igearinput1与igearinput2。igearinput1是来自其它igear的输出且其·只作为trigger的输入,而igearinput2则是来自于后文讲述的filter(过滤器)部分的输出,且其只作为and的输入。后文提到将igear1连接到igear2是指将igear1的输出作为igear2的trigger的输入,将filter连接到igear2是指将filter的输出作为igear2的and的输入。igear可抽象成如图15所示的组件。filter是isnn的非脉冲神经元部件,其接受fbr的输入。每个filter监视着一个cluster,现有监视cluster1的filter名为filter1。定义函数ftr(filter1)可求出filter1监视的cluster1的范围。此范围由cluster1的centroid、average、variance计算得到。具体计算方式由使用者给定。落在此范围内的特征值将会被判断为与centroid相近,认定其属于此cluster。若fbr传来的特征值落在ftr(filter1)时filter1便立刻产生一次瞬时的脉冲。[0127]filter输出都与igear相连。filter的实现很简单,少量层数的ann或者其它简易的函数结构即可实现。非脉冲神经元filter子模块原理图可见图16。[0128]isnn由igear与filter构成。一条长期记忆由一个isnn网络构成,其模拟了一类atar。若isnn网络s1模拟了b,那么当b的某个衍生子序列从fbr沿时间依次传入时,s1将会在其传入完毕后产生一个瞬间的脉冲,告诉lbri它识别出了此类atar。现将讲述一个isnn如何进行模拟。[0129]首先讲述相连的igear组成的结构igear链如何模拟a类atar的衍生子排列a。a为cw的一个排列,a各个成员的地位特征值已求出。[0130]任意的tsq可增广为“tsq三元组”。tsq三元组结构为《s,t,p》。其中s为序列本身,t为其时间差向量,p为地位矩阵。对于任意的tsqa,as,at,ap表示a三元组的三个属性。令a的长度为n,则p为posd×n的矩阵。[0131]对于任意的j≤n,p的第j个向量为a的第j成员的地位特征值。利用函数triplize(三元组化)生成tsq的三元组,其中tsq的地位特征值需要提前給出,则a的三元组为triplize(a,ap)。[0132]现利用triplize(a,ap)构建一条属于a的igear链。a为cw的子序列或排列。为as的每一个成员生成一个igear,且对于as中的任意第m位成员,称其igear为第migear。若第m 1与m-1igear存在,将第migear连接到第m 1igear,第m-1连接到第migear。第migear的and神经元还需要连接上与as第m成员cluster的filter。一个filter可以连接多个as成员的igear,只要这些成员同为一个cluster。如此形成按顺序相连的igear链ac,并标记其最后一个igear为输出位。ac可以抽象成一个以igear为元素的tsq。[0133]ac将拥有下述行为。当一个与a结构相似的tsqa’传入时,ac中的igear将按连接顺序依次发出脉冲,最终在a’中与a最后一个成员等价的成员到达后,ac末尾的igear发出ac的输出脉冲。其中,对于任意的m(m》1,m≤n),以等价于a(m)num的a’成员的到达时刻为0时刻,只有在某一时间范围内等价于a(m 1)num的a’成员到达,ac的第m 1igear才会发出脉冲。此时间范围称为容许范围,求法后文给出。构造第m与第m 1个成员的igear结构,如图17所示。[0134]假设第m以及第m 1个成员的容许范围为[start,end],其分别接受filterm与filterm 1的输入。在m的等价成员到达后igearm发出脉冲,igearm 1的trigger将在瞬间接受到脉冲并也立刻发出电位脉冲。(以下提到的igear内部神经元都是igearm 1内部的结构)正常情况下and神经元用于接收filterm 1的输入突触处于封锁状态,即其控制单元函数值为0。在收到了电位脉冲后其在接下来的一段时间范围内由于upperlimit及lowerlimit的电位改变filterm 1的输入突触将处于开放状态,即其控制单元函数值为1(具体实现将后文讲述)。此时间范围即为容许范围[start,open]。这意味着只有在收到igearm传来的脉冲后igearm 1才能从filterm 1处接收脉冲。[0135]upperlimit及lowerlimit的具体实现,令trigger对于upperlimit的输入权重是wu,对于lowerlimit的输入权重是wl。其中wu≥0,wl≤0。在trigger发出脉冲后,受wu及wl取值影响,upperlimit的电位将上升一个常数并随后开始下降,而lowerlimit的电位将下降一个常数并随后开始上升。[0136]对于upperlimit,wu的取值需要满足此条件:[0137]对于lowerlimit,wl的取值需要满足此条件:[0138]其中,τu是upperlimit中的τ参数,τl是lowerlimit中的τ参数,a≈b表明a与b数值极为相近但不一定必须相等,至于a与b之间的差值允许范围由使用者决定。upperlimit和lowerlimit的控制条件无论何时都是1。[0139]and的控制条件cua为:[0140][0141]else,cua=0[0142]trigger的控制条件cut为:[0143][0144][0145]其中uu、ul为upperlimit及lowerlimit的电位,为阈值,应为两个常数,且参数τu、uu、ul、由容许范围[start,end]决定,只要满足上述条件的取值都可以。在获得容许范围后可通过方程求得。[0146]以trigger发出脉冲的瞬间为0时刻,根据上式,upperlimit只有在[0,end]范围的时刻左右内电位才会大于而lowerlimit只有在[start,-∞]范围的时刻左右内电位才会大于这意味着只有在容许范围[start,end]内filterm 1发出的脉冲and神经元才会接收到,且在[0,end]范围内trigger不会接受其它igear发出的脉冲。filterm 1监视ac(m 1)num,所以只有属于ac(m 1)num的特征值从fbr传入时filterm 1才会产生脉冲。[0147]综上所述,在trigger发出脉冲后,只有在范围大约为[start,end]的时刻有属于ac(m 1)num的特征值近从fbr传入时,igearm 1才会产生脉冲。对于a的第一个成员,没有igear与之对应,直接使用filter1连接到igear2的trigger。因为任何一个属于第1成员cluster的特征值都可能被视为近似序列的开始。[0148]现给出容许范围[start,end]的计算方式,定义一个atar数据集为一类或若干类atar衍生子排列的若干tsq三元组的集合。b、c类atar数据集data是指data中所有的tsq都属于b类或c类atar。其它命名以此类推。求得容许范围不止需要triplize(a),还需要a类atar数据集。设现有a类数据集adata,triplize(a,ap)∈adata。设集合md为:所有adata的三元组的序列中,与ac(m 1)num等价(地位特征值近似)的成员的集合。对于md中的任意元素c,计算pred(c)并将其放入时间差集timeset。统计timeset中时间差值的分布,应用统计学方法给出时间差分布最集中的区域。此区域即为求得的容许范围[start,end]。称将一个tsq三元组及其所属的数据集按上述步骤映射到一个igear链的函数为chainize,即:[0149]chainize(triplize(a,ap),adata)=ac[0150]上述igear链可在一定程度上模拟一类atar但只能识别与其结构很相似的序列。其识别范围狭窄,容错率小,无法很好的识别一类atar。isnn网络是一种对igear链的强化学习,极大程度地提升了识别能力,可以更大范围地识别atar。以下是制作isnn的流程。[0151]双次映射生成isnn:现制作isnn网络s1以模拟名为b的一类atar,且现拥有一个b类atar的数据集d。[0152]1.构造集合dtuples。对于d中的任意一个tsq三元组triplize(b,bp),进行如下操作:利用函数chainize构造igear链bc=chainize(triplize(b,bp),d)。利用bc及bp为b构造一个元组《bc,bp》(这种元组命名为单链元组)。令dtuples是d中所有元素生成的单链元组的集合。定义将一个atar数据集映射到单链元组集合的函数为tuplize,即tuplize(d)=dtuples。[0153]2.将dtuples集合使用connect函数映射到一个isnn网络上,connect函数实现如下:1)connect接受单链元组的集合为输入并输出为一个isnn网络。2)设connect函数接受集合tuples,令chains为tuples中所有元组的igear链的集合,tuples中任意的元组a中的igear链和矩阵名为ac、qp。对于a,定义集合eqlna,n=eql(chains,ac(n 1)num)(与ac(n 1)num同属一个等价类的任意igear链上的所有成员)。将ac中任意的第n成员的输出连接到eqlna,n中所有igear的输入上。即对于eqlna,n中任意元素m,都有ac的第n个igear的输出作为m的输入。3)chains中所有链的igear都进行了2)的操作后会相互连接形成isnn网络output,将output作为输出,即connect(tuples)=output。将igear链b0中的b0(n)num连接到所有同b0(n 1)num等价的igear。则connect(dtuples)=s1。如此之后在s1中,每一个子排列的igear不止连接属于自己序列的igear,还连接处于其它子排列的、与自己下一个成员等价的成员的igear。这样的策略会引起igear回路,回路出现是正常的,不应该避免。isnn网络中单个igear的trigger将会连接多个其它的igear,此时trigger的情况就不是收到其中一个igear的脉冲后立刻发出脉冲了。其它igear到trigger的权重是要进行计算的。对于一个trigger,其行为应该是在短时间内有一定数量比例的输入发出脉冲其才输出脉冲。遵循这一原则后按使用场景对所有的igear输出权重进行赋值。[0154]isnn的结构及行为已阐述结束,下面将阐述与isnn有关的biologicalinstinct功能lgen:long-termmemorygenerator。当我们确认cw序列中存在某种未被学习过的atar时,会运行rdtc功能对cw序列进行特征值提取,产生若干类atar以及对于每一类atar的若干个衍生子排列。lgen的功能是把rdtc提取结果转化成isnn网络。lgen只需要给出cw提取结果的isnn网络结构以及里面的参数即可。现给出过程。1.制作atar数据集singles,抽取输出序列中judge位为1的成员并形成排列(称其为regular序列)。对regular序列进行划分,对于regular中任意的head位接近1的第m位成员,搜索在其之后的、离其最近的、head位接近0的第m'位成员,并提取regular的子序列regular'ssm,m',若第m位成员之后并无head位接近0的成员,则不予处理。将所有通过上述方式提取出的子序列集合称为arranges。对于arranges中的任意tsqs,从输出矩阵中提取其地位特征值并按序重新拼接为矩阵sp,使用triplize求出s的三元组triplize(s,sp)。称由arranges得到的所有的三元组的集合为singles,singles即为需要的atar数据集。数据集制作流程如图18所示。2.对singles进行双次映射得到isnn网络union,对singles进行双次映射,即union=connect(tuplize(singles))。3.将union划分为numerous集合:定义separate为将一个isnn映射到一个isnn集合的函数。对于任意isnn,将其抽象为一张图g,igear为g的节点,igear之间只要有连接就将此连接抽象成一条无向边。现将任意输入in映射到输出out,即separate(in)=out,将out中的元素和in抽象成图后,separate函数将求出in中的所有极大联通子图,并将它们对应的isnn子网络形成集合out进行输出。第三步对union进行划分得到isnn集合numerous,numerous中的每一个网络象征着一类atar,numerous=separate(union),设s为numerous中的任意网络。4.设s为numerous中的任意网络,找出里面所有的输出位igear,并将其连接到一个只属于s的输出神经元上。只有在短时间内一定比例的输出igear发出脉冲s的神经元才发出脉冲。根据此限制确定相关参数。5.将numerous中的各个网络加入长期记忆,并整合数据集中的等价类,加入等价类数据池eqlpool中。eqlpool数据池记载着多种等价类,每一类由质心地位特征值及范围等参数表示。利用d中的地位特征值矩阵进行地位特征值聚类,并将新得到的类加入eqlpool。如果新得到的类x和eqlpool中已有的类y大规模重合则将x合并到y并对y进行质心及范围的调整。具体做法参考聚类算法。通过数据集制作长期记忆的流程如图19所示。[0155]长期记忆中输出神经元的输出便是lbri的输出,通过输出所属的不同长期记忆对应的isnn网络来判定传入的特征值中触发了哪一部分回忆。rdtc的detected信号,detected信号是为了发现新的、未被加入长期记忆的atar而设立的。其策略是,定期使用rdtc功能扫描cw序列,收集judge位为1的成员的地位特征值。判断这些特征值在不在eqlpool中的等价类之中。若某一次执行完rdtc后发现大于一定比例的地位特征值不在eqlpool中,那么判定此出现结构迥异的新atar,发出detected信号。[0156]lbri模型总的示意图见图20。[0157]为了更清楚的说明本发明的构思,以人类动作识别为实例做进一步说明:[0158]采用receptor-brainmode,其中由类似于cnn的结构作为receptor,lbri作为brain。receptor以固定周期h不断通过固定的摄像头截取照片并提取特征值,之后将特征值通过fb传给lbri。每过h的时间lbri便会收到一个特征值。每个人不同的姿态应被提取不同的特征值,相近的姿态对应相近的特征值。如举起右手与抬起右脚对应不同的特征值,而举右手到相近高度的两个姿态应对应相近的特征值。摄像头不断拍照,receptor不断处理图片。当某一个人进入视野范围时receptor应注意到他并提取其在每一张照片上姿态的特征值,当视野有很多人时receptor应具有注意力,只连续提取其中一个人的姿态。receptor不属于本发明实现的范畴,在此只提及实现动作识别对receptor的要求作为举例。[0159]brain:lbri模型。每当有特征值从fb传入时,其都会经过rann中drnn的处理,并传入到lbri内部的特征值总线fbr上。经drnn处理后每个特征值将不止代表人当前的姿态,还代表正在进行的动作。如一段将手以速度v举过头顶的动作被拍摄到,这一段动作最后被传入的姿态为手垂直悬于头顶,fb传入的特征值为a1;而在将手以2v的速度举过头顶的动作中,最后被传入的姿态仍是手垂直悬于头顶,fb传入的特征值为a2。因为最后的姿态几乎一样,所以a1与a2极其相近。但drnn处理时不仅考虑此时刻的姿态,因其具有的很短的记忆其还能考虑之前时刻的姿态。所以因为之前传入的特征值不一样,所以a1、a2经加工后得到的特征值b1、b2就不相近了。drnn处理后的特征值代表着一种运动趋势,b1虽与b2对应的姿态相近,但速度不同,运动趋势不同,故二者不相近。同样手做直线运动举过头顶及做曲线运动举过头顶,手位于头顶的姿态虽相同,但drnn结合之前的可以分辨出其运动趋势不同,故给出不同的特征值。其中运动趋势是指人肢体运动的状态,包括但不限于运动速度、直线或曲线运动、运动方向等信息。若人位于不同姿态时drnn提取的特征值一定不相近,人即使处于同一姿态drnn也会因运动趋势的原因得出不同的特征值。只有同一姿态同一运动趋势时drnn才会求出相近的特征值。综上所述,fbr中的特征值是包含了人的姿态和运动趋势信息的特征值,称其象征着“运动姿态”。称fbr中相近的特征值为相同运动姿态,不相近的为不同运动姿态。[0160]当fbr特征值传入时,其会被objectmemory聚类为各种cluster。每一个cluster都代表着不同的运动姿态,之后负责记忆顺序的sequencememory将记住运动姿态出现的顺序。短期记忆如此形成,若一种运动姿态太长时间未出现就会被忘掉。[0161]一开始eqlpool中没有任何地位特征值类。rdtc定期扫描短期记忆,产生地位特征值。若短期记忆中有一段动作反复出现,则在某一次扫描中rdtc将分辨出其属于一类atar。收集此atar的地位特征值后,若发现存在大比例的不属于eqlpool中的地位特征值,则产生detected信号。其它情况下不产生detected信号。detected信号发出说明rdtc发现了新的重复出现的动作。[0162]若detected信号发出则lgen立刻运作,利用让rdtc产生detected的短期记忆制作数据集,并按照专利中给出的方法利用数据集制作isnn网络,形成象征着全新动作的新的长期记忆。[0163]一开始长期记忆模块中没有isnn,lgen在其后的时间里不断产生isnn并放入长期记忆。一条长期记忆对应一个isnn网络,也对应着一种被记忆的、曾经重复出现的动作。当特征值自fbr传来时,若某一个被记住的动作再现,则在其输入完后长期记忆中对应此动作的isnn便将其识别并给出输出。[0164]综上所述,在动作识别中,未见过的动作只要多次出现lbri模型便会将其记住,已记住的动作只要在次出现lbri模型便会将其识别。因此,lbri模型是一种无监督的动作识别方法。[0165]基于同一发明构思,本发明还提供了一种基于无监督神经网络lbri的动作识别系统,用以实现所述基于无监督神经网络lbri的动作识别方法,包括lbri模型,所述lbri模型用以解决动作识别的问题。[0166]需要说明的是,对于前述的实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本技术并不受所描述的动作顺序的限制,因为依据本技术,某一些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例属于优选实施例,所涉及的动作并不一定是本技术所必须的。[0167]上述实施例中,描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。当前第1页12当前第1页12
技术领域:
:1.本发明涉及计算机
技术领域:
:,尤其涉及一种基于无监督神经网络lbri的动作识别方法及系统。
背景技术:
::2.计算机动作识别领域,常常会采用循环神经网络和长短期记忆网络等进行动作识别,其中,循环神经网络(recurrentneuralnetwork,rnn)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络(recursiveneuralnetwork)。3.长短期记忆网络(lstm,longshort-termmemory)是一种时间循环神经网络,是为了解决一般的rnn(循环神经网络)存在的长期依赖问题而专门设计出来的,所有的rnn都具有一种重复神经网络模块的链式形式。在标准rnn中,这个重复的结构模块只有一个非常简单的结构,例如一个tanh层。4.但是现有技术当中并没有一种可仿生,并且可高效进行动作识别的方法。技术实现要素:5.本发明的目的是提供一种基于无监督神经网络lbri的动作识别方法及系统,以解决如何提高动作识别效率的技术问题。6.本发明的目的是采用以下技术方案实现的:一种基于无监督神经网络lbri的动作识别方法,包括如下步骤:7.s1:获取动作信息,并提取特征值;8.s2:将特征值通过特征总线fb传输至lbri模型,所述特征值为随时间输入的特征值序列tsq,将特征值序列tsq归类为排列类atar;9.s3:lbri模型记忆新的排列类atar,识别旧的排列类atar,解决动作识别的问题。10.进一步的,所述lbri模型会记住若干排列类atar,当向lbri模型输入已经记住的排列类atar时,lbri模型将其识别;当向lbri模型输入新的的排列类atar时,lbri模型将其进行记忆。11.进一步的,通过感受器-大脑模型rb中的感受器receptor从外界接收刺激,并将其提取出特征值。12.进一步的,所述感受器receptor包括去除全连接层的cnn。13.进一步的,所述lbri模型包括长短期记忆网络框架lstmf模块、生物本能神经网络训练模块、循环联想神经网络rann模块和可解释序列脉冲神经网络isnn模块。14.进一步的,所述长短期记忆网络框架lstmf模块包括短期记忆子模块、长期记忆子模块和生物本能子模块,其中,所述短期记忆子模块用以对传入的特征值按照时间顺序进行处理及无条件记录;所述长期记忆子模块用以对传入的特征值进行推理;所述生物本能子模块用以识别重复出现的、规律性的特征值序列,并生成新的长期记忆。15.进一步的,所述生物本能神经网络训练模块包括rdtc生物本能子模块和lgen生物本能子模块,所述rdtc生物本能子模块用以定期对短期记忆进行检索并判断其中的序列是否是有重复出现的规律性片段,将其进行分类并指出;所述lgen生物本能子模块用以生成长期记忆,若rdtc检测到有重复出现的规律性片段则根据此些片段生成新的长期记忆。16.进一步的,所述循环联想神经网络rann模块包括微分循环神经网络drnn子模块、对象记忆子模块和序列记忆子模块,所述微分循环神经网络drnn子模块用以求出特征值变化的趋势;所述对象记忆子模块用以对特征值的记忆以类划分;所述序列记忆子模块用以模拟生物短期记忆记住最新的,忘记最旧的的特性。17.进一步的,所述可解释序列脉冲神经网络isnn模块包括推理igear子模块和非脉冲神经元filter子模块,所述推理igear子模块用以模拟排列类atar;所述非脉冲神经元filter子模块用以接收特征值总线fbr的输入,并输出至推理igear子模块。18.一种基于无监督神经网络lbri的动作识别系统,包括lbri模型,所述lbri模型用以解决动作识别的问题。19.本发明的有益效果在于:本发明相较于现有技术,在动作识别方面,更仿生、更节约存储空间,并且识别效率更高。附图说明20.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图示出的结构获得其他的附图。21.图1为本发明流程图;22.图2为3dcnn输入输出流程图;23.图3为采用lbri模型的输入输出流程图;24.图4为循环联想神经网络rann模块原理框图;25.图5为对象记忆子模块积累同一类原理图;26.图6为一个同一类在对象记忆子模块的结构;27.图7为smc结构原理图;28.图8为个sum为6的smc队列图例图;29.图9为图8循环队列展开后的原理图;30.图10为序列实例;31.图11为图10抽象图;32.图12为序列原理图;33.图13为图12抽象图;34.图14为igear子模块原理图;35.图15为igear抽象图;36.图16为非脉冲神经元filter子模块原理图;37.图17为第m与第m 1个成员的igear结构示意图;38.图18为数据制作流程图;39.图19通过数据集制作长期记忆的流程图;40.图20为lbri模型总的示意图。具体实施方式41.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。42.应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。43.下面结合附图,对本发明的一些实施方式作详细说明。在不冲突的情况下,下述的实施例及实施例中的特征可以相互组合。44.实施例1:45.参阅图1,一种基于无监督神经网络lbri的动作识别方法,包括如下步骤:46.s1:获取动作信息,并提取特征值;47.s2:将特征值通过特征总线fb传输至lbri模型,所述特征值为随时间输入的特征值序列tsq,将特征值序列tsq归类为排列类atar;48.s3:lbri模型记忆新的排列类atar,识别旧的排列类atar,解决动作识别的问题。49.lbri模型的数学基础、能处理的问题以及其输入输出:50.输入基础:序列,序列同常规数学定义相同,是指元素进行有规律排列。对于任意序列a,a中的第n(n∈n*)成员是指按顺序从头计数排在第n个的元素,记为a(n)num(使用num上标作为标记),称a(n)num与a(n 1)num相邻,称n为成员序号。表示序列时不同成员用符号“,”相隔。序列a中从a(n)num开始至a(n k)num成员结束(序列本身不会少于n k个成员,n∈n*,k∈n)的部分称为序列a的子序列,记作a'ssn,n k(a’ssubsequence,起始序号作为下标)。排列,任意序列b的一个排列是指序列b中相邻或不相邻的若干成员按在序列b中的次序形成的组合。b的排列也是一个序列,如在序列b1,6,7,8,3,4中第2、3、5个成员6,7,3就形成一个排列。排列中成员出现的顺序必须与其序列中元素出现的顺序相同,如3,7,6便不是一个排列。b的排列记作b'ara(b’sarrange),其中a是排列包括成员的序号按升序形成的序列,上述的6,7,3记作b'ar2,3,5。排列b'ara囊括的子序列是指序列b中从排列的第1个成员开始至排列的最后1个成员结束的子序列,函数cs(b'ara)(calculatesubsequence)是用于求得b'ara囊括子序列的函数。如b'ar2,3,5囊括的子序列为cs(b'ar2,3,5)=b'ss2,5。序列、子序列、排列的长度都等于其包含了成员的数量。设c是序列b的一个排列或子序列,且b(n)num是c的第m成员,则称b(n)num是c(n)num的父映射成员,c(n)num是b(n)num的子映射成员。如b'ar2,3,5(3)num的父映射成员是b(5)num。51.lbri模型能处理的问题:lbri的输入同脉冲神经网络(snn)一样。随着时间推移,特征值不断地通过特征总线(featurebus:fb)向lbri输入,lbri会像生物一般对输入持续进行反应。输入的特征值是随时间输入的特征值序列tsq(timesequence:时间序列)。tsq比普通序列多一种属性,便是相邻成员的时间差。tsq可以用《s,t》的二元组表示,s为任意序列,长度为n,t为对应s的时间差向量,有n-1维。其中t的任意第m位(m《n)代表着s(m)num与s(m 1)num的在fb上的传入时间差。对于任意的tsq序列s中的成员s(a)num、s(b)num(a《b),定义二者之间在fb上的传入时间差为s(a)num,s(b)num)t。定义接受一个序列成员的一维函数pred与posn,pred为求输入和其前一个成员(如果有的话)的传入时间差,posn为求输入和其后一个成员(如果有的话)的传入时间差,即52.pred(s(b)num)=(s(b-1)num,s(b)num)t,posn((b)num)=(s(b)num,s(b 1)num)t53.tsq中部分成员是无用的噪音,而部分成员则组成若干类有规律的、需要识别的序列。称这种排列类为atar(attentionarrange)。一个atar代表一类tsq,如跑步代表着一类动作序列。lbri模型会记住若干类atar。当其遇见已经记住的atar时,将其识别;遇见新的atar时判断出tsq中存在着一个新的atar并将它进行记忆。lbri的解决的问题是记忆新的atar,识别旧的atar。此问题为attentionarrangerecognizequestion(可被注意序列的识别问题),其的一个典型下属问题便是动作识别。54.lbri模型的输入输出:涉及一种模型receptor-brainmode(感受器-大脑模型,简称rb)。在rb中receptor从外界接收刺激(比如传入图像)并将其提取出特征值,之后receptor再将特征值通过featurebus(特征值总线,简称fb)传递给brain,brain对特征值进行处理并产生结果。lbri在此模型中担任brain的角色,而receptor已有很多模型,如去除全连接层的cnn(若干的卷积层和池化层)。55.以下将使用cnn作为例子,阐述lbri模型与传统深度学习输入与输出的不同。传统cnn的brain为全连接层,在此例中lbri取代了全连接层作为brain,而之前的卷积、池化层作为receptor则类似生物的眼睛——为brain提供以神经脉冲为形式的特征值。在处理动作识别时,一种传统cnn将多张图片作为输入、执行一次推理并产生输出(被称为3dcnn,其输入输出可参阅图2),而使用了lbri模型替换全连接层的cnn将图片按照拍摄时间依次传入(流程图可参阅图3),lbri模型将不断作出反应并产生输出(类似snn)。以上比较只是一个例子,lbri模型不止可以嵌入cnn,只要receptor改变,其就可以处理其他来源的特征值(不只是图片,如声音)。lbri的输入输出同snn非常像,这是由于循环联想神经网络rann和可解释序列脉冲神经网络isnn的结构导致的,这将在后文提及。56.lbri模型包括长短期记忆网络框架lstmf模块、生物本能神经网络训练模块、循环联想神经网络rann模块和可解释序列脉冲神经网络isnn模块。57.长短期记忆网络框架lstmf(longshort-termmemoryframe:lstmf)模块,是lbri模型的框架,分为三个子模块,短期记忆子模块、长期记忆子模块和生物本能子模块。58.短期记忆子模块,此部分负责对传入的特征值按照时间顺序进行处理及无条件记录(即只要有传入就将其处理并记忆)。短期记忆有存储上限,当达到存储上限后若有新的特征值传入便会遗忘时间最早的记忆(最早到来的特征值),腾出容量给最新传入的特征值。59.长期记忆子模块,此部分负责对传入的特征值进行推理。长期记忆模块中有着大量长期记忆,每一条长期记忆对应着一类atar。其功能是:如果一类atar已存在于长期记忆模块中(被学习),那么若属于此atar的tsq完整传入时,长期记忆部分便能识别出此tsq并产生特定的信号:recall。此过程称为推理。功能如何实现将在后文解释。60.生物本能子模块,是lbri模型中对神经网络的一套训练方法。其有两部分功能:1)识别重复出现的、规律性的特征值序列的功能rdtc(repetitiondetect:重复序列勘察),2)生成新的长期记忆(生成新的神经网络)的功能lgen(long-termmemorygenerator:长期记忆生成器)。需要强调的是rdtc,rdtc功能定期扫描短期记忆,如若疑似出现新的atar,其将产生特定的信号:detected。61.lstmf的大体逻辑是:短期记忆子模块与长期记忆子模块并行运行,当特征值传入时,短期记忆将其处理并存储,而长期记忆直接接收进行推理。rdtc定期扫描短期记忆,若期间未产生detected,则认为最近传入的序列都是无规律的、不值得学习的,或已经学习过,lbri模型将不产生额外行为;但若有detected出现,那么lbri模型将认为最近传入的特征值可能存在新的atar。之后lbri将调用生物本能的lgen功能,根据rdtc,制造出若干新的长期记忆加入长期记忆子模块中。需要指出的是:一开始长期记忆子模块中并没有任何长期记忆,在不断的特征值输入过程中lbri模型将不断积累长期记忆,而后这些长期记忆便可用于推理。因此lbri模型是一种无监督学习的模型。62.生物本能神经网络训练(biologicalinstincttrainingmethod)模块,biologicalinstinct是一种学说与仿生的训练方法,现将描述它的来源及其原理。生物有一经诞生便拥有的、类似函数映射的能力,如看到某种食物后下意识判定能不能吃。现称这种能力为“biologicalinstinct”(生物本能)。生物本能是一种映射,给予输入并产生输出,是一种象征着直觉的函数。可以使用达到函数映射功能的结构模拟生物本能。在lbri模型中,被模拟的生物本能有两个:rdtc生物本能子模块和lgen生物本能子模块。63.rdtc(repetitiondetect):rdtc拟合的生物本能:将一组序列作为输入,人能够判断其是否具有重复的片段,将其进行分类并指出。rdtc会定期对短期记忆进行检索并判断其中的序列是否是有重复出现的片段。rdtc部分以短期记忆为输入,并产生特定格式的输出。输出具体格式将在后文提及。64.lgen(long-termmemorygenerator):lgen拟合的生物本能:在学习到新的事物后人脑中的神经元之间结构会发生不同程度及方面的变化。这种变化同输入有一定的函数关系。长期记忆是由一种类似snn的网络,新的长期记忆生成的过程对应着神经元之间产生新的变化。新网络中神经元的参数数、连接的权重,将由lgen对应的生物本能求得。lgen的输入是rdtc的输出,而lgen的输出则是新的长期记忆。rdtc与lgen的细节将在后文描述,二者都是映射功能的函数结构。65.循环联想神经网络rann(recurrentassociateneuralnetwork:rann)模块。现提出“记忆对象与记忆序列分离”假说,当人记住一组序列a时,如看到一段动作,人们并未将a的每个成员都进行记忆,而是将成员归类到已经存在于记忆中的若干类中,并将a转化为不同类的序列。每一种类被单独记忆,存储具体的细节,而有关时间序列的记忆则只记住这些对象出现的先后顺序,而并不去记忆具体的细节。以上的观点称为对象序列分离说。循环联想神经网络rann模块包括微分循环神经网络drnn(differentialrnn)子模块、对象记忆(objectmemory)子模块和序列记忆(sequencememory)子模块。后两部分应用了记忆对象与记忆序列分离假说。循环联想神经网络rann模块原理框图可参见图4。66.微分循环神经网络drnn子模块,是一种rnn,其加工fb传来的特征值并输出到lbri内部通用的特征值总线fbr(featurebusafterrnn)。fbr传递的特征值的维度为fbrd,fbr每隔fbrt传入新的特征值,此值与fb保持一致。drnn的目的是求出特征值变化的趋势,其认为当下特征值代表着的状态不止取决于自己,也取决于之前传入的特征值。如小球进行直线或曲线运动,截取某一时刻的图像并不能判断是直线还是曲线运动,需要结合之前的图像。drnn相当于对一串序列进行微分,求得当前序列处于何种状态。67.可以作为drnn的rnn有两个条件:较差的记忆力和抗噪音。1.较差的记忆力,rnn只应记住近期传入的特征值序列。无论之前输入过何种序列的特征值,只要近期输入的特征值序列相似,rnn就应拥有相近的隐状态及输出。2.抗噪音,若近期输入的特征值序列近似,即使有噪音使他们不完全相同,rnn也应拥有相近的隐状态及输出。特征值序列近似的标准应由使用者决定。应使用特制的训练集来训练rnn以达到上述目的。drnn部分也可由lstm模型等与rnn功能近似的结构实现。68.对象记忆子模块,objectmemory实现了对象序列分离假说中的对象部分。其从fbr上接收特征值,其采用了聚类思想。objectmemory对特征值的记忆以类划分。如若两个特征值向量距离相近则视为同一类(cluster)。一开始objectmemory中并没有cluster,在特征值不断传入的过程中objectmemory会积累大量cluster(参见图5)。一个同一类在对象记忆子模块的结构可参阅图6,centroid为cluster的质心,是一个向量,其维度为fbrd。当特征值与centroid距离小于某使用者给定的阈值tolerance时则该特征值被归类为此cluster;weight为cluster的权重,是一个数,其值域为(0,wmax),wmax是使用者给定的正常量,代表最近一段时间传入特征值属于此cluster的频率,初值为一个属于(0,wmax)的常数,如何确定见下文。average为归属于cluster的特征值与centroid距离的均值的象征,是一个数,均值越大average越大,初值为0;variance为归属于cluster的特征值与centroid距离的方差的象征,是一个数,方差越大variance越大,初值为0;当新特征值a从fbr传来时,objectmemory会同记忆中所有cluster进行比较。若a与一个cluster的centroid距离大于tolerance时则判定a不属于此cluster。69.现分3种情况讨论:1.objectmemory中还没有cluster;2.objectmemory中有cluster但a不属于任何的cluster;3.objectmemory中有cluster且a属于若干个cluster。70.情况1:创建一个新的cluster,将a作为其centroid,并为weight、average、variance赋予初值。71.情况2:创建一个新的cluster,将a作为其centroid,并为weight、average、variance赋予初值。weight的初值有两种选择,第一是所有cluster的初值都采取使用者给定的常数,第二是制作一个函数结构,利用centroid初值决定weight初值。此函数结构可以用ann之类的实现,目的是为了对于部分特征值有所侧重,使lbri投入更多注意力到某类特殊的特征值上。这个函数结构需要使用者按需训练。72.情况3:选择centroid与a距离最近的cluster作为a的所属类。若有多个cluster的centroid与a的距离都很接近则选择weight最大的cluster作为a的所属类。之后将a所属cluster的centroid、average、variance值重新计算,同时提高weight值。73.现说明上述步骤中cluster各参数的具体变化方式:每个cluster的centroid、average、variance值只有在情况3的时候才进行更新,在其他时间保持不变。情况3中centroid、average、variance计算方式:74.centroid′=centroid (centroid-a)×f(weight)×μ75.average′=average×(1-fraca(weight)) dis(centroid,a)×fraca(weight)76.variance′=variance×(1-fracv(weight)) |dis(centroid,a)-average′|×fracv(weight)77.其中centroid、average、variance为计算前的旧值,centroid’、average’、variance’为计算后的新值,μ是学习步长,是人为给定的正常量,选择何值应在具体应用场景下进行大量实验来确定。f(x)是满足以下条件的函数:78.1)定义域为(0,wmax)、值域为(0,e),其中e是人为给定的正常量;79.2)在定义域上连续且单调递减;80.dis(x,y)是求得向量x、y之间距离的函数。81.fraca(x)、fracv(x)是满足以下条件的函数:82.1)定义域为(0,wmax)、值域为(0,1);83.2)在定义域上连续且单调递减。84.在两种状况下cluster的weight会改变:1.时间流逝,2.发生情况3。85.1.时间流逝,weight每隔dt秒会下降dw大小的值,其中86.dw=g(weight)dt87.其中g(x)可以是满足以下条件的任意函数:88.1)定义域为[0,wmax][0089]2)g(0)=0,g(wmax)=0,g(x)<0。[0090]3)有视情况而定的、位于(0,wmax)中的常数b,g(b)为函数g(x)的最小值。[0091]4)函数在定义域上连续,且在(0,b]上单调递减,在[b,wmax)上单调递增[0092]上述参数及函数由使用者依情况给定。[0093]2.发生情况3,发生情况3后weight应上升一个常数是处于(0,wmax)之间的、视情况而定的常数,称为上升步长,一般远小于wmax。[0094]如果后大于wmax,强制令weight=wmax-α,其中α是视情况而定的大于0的常数,且α<<wmax。[0095]以上便是centroid与weight的具体变化方式。值得注意的是,虽说f(x)、g(x)、fraca(x)、fracv(x)可选择任意满足条件的函数,但不同函数的选择将会对lbri带来巨大影响,选择何种函数应在具体应用场景下进行大量实验确定。当一个cluster的weight值小于fgt即其太久未出现时,lbri会将其删除。这个过程称为遗忘,其中fgt》0且fgt<<wmax。可以看出,只要fbr传入特征值,那么其经过objectmemory后必定会归属于某个cluster。上述参数及函数由使用者依情况给定。[0096]序列记忆子模块,sequencememory部分实现的是对象序列分离说中的序列部分,其不记忆fbr传来的特征值,而是记忆特征值属于的cluster。[0097]sequencememory是长度有限的、以cluster为元素的tsq。sequencememory采用了类似循环队列的记忆方式以模拟生物短期记忆记住最新的,忘记最旧的的特性。其由大量的序列记忆细胞(sequencememorycell:smc)构成。[0098]首先说smc的结构。一个smc拥有两个指针,一个指向下一个smc,称为nextpointer(nptr:指向下一个的指针);另一个指向一个cluster,称为associatepointer(aptr:注意力指针)。现分两部分讨论sequencememory的结构。[0099]1.smc之间的结构,smc之间组成循环队列,所有smc使用nptr指向下一个。一个smc只能被一个smc所指向,它们首尾相连。同时,还有一个头指针header指向某一个smc(可参阅图7)。smc的数量是固定的,数量越多短期记忆所能记住的越多,在最开始时header指向任意的smc。每一个smc对应一个fbr传入的特征值,但smc不记录具体特征值。其中header指向对应最新传入特征值的smc,此smc称为hsmc。当新的特征值传入时,将由当下hsmc的下一个smc与其对应,header将指向hsmc的下一个smc。此过程称为hsmc迭代。如若smc0指向smc1smc1指向smc2,开始时smc0为hsmc,现有特征值a、b依次传入,当a传入时,a将对应smc1,header将指向smc1,smc1成为当下的hsmc;当b传入时,b将对应smc2,header将指向smc2,smc2成为当下的hsmc。当整个smc循环队列填满时,即整个队列的smc都成为过一次hsmc后,若新的特征值传来,hsmc迭代依旧会发生。此时代表最旧记忆的smc将对应最新的特征值。通俗来讲,最旧记忆会腾出空间给最新记忆。[0100]2.smc指向cluster的结构,一个smc对应一个特征值的特性是由aptr实现的。当特征值a从fbr传入时,objectmemory将输出其归属的cluster,同时sequencememory中的hsmc迭代同步发生,生成新的hsmc,并将hsmc的aptr指向a归属的cluster。若smc未成为过hsmc则令其aptr置空,若smc所指向的cluster因weight太小被删除则同样令其aptr置空。[0101]综上所述,objectmemory使用其cluster结构记录特征值的细节,sequencememory使用smc循环队列记录cluster序列。通过smc寻找指向的cluster的过程称为联想(associate)。[0102]rann的结构及行为已阐述结束,下面阐述与rann有关的biologicalinstinct功能:repetitiondetect。[0103]dtc功能的目的是为检索存短期记忆对应的tsq无重复atar。将smc循环队列展开为一个长度为sum的序列,hsmc的下一个smc是第1成员,hsmc是第sum成员,被指向的smc位于指向其的smc之后。之后将smc联想的cluster按此顺序排成tsq并称其为cw(currentwindow:当下窗口),代表着短期记忆内记忆的特征值序列。cw的长度为sum,其元素都是cluster,且相邻成员的时间差为fbrt。一个sum为6的smc队列图例如图8所示,其循环队列展开之后参见图9,则cw序列按顺序为:cluster2,cluster3,cluster3,cluster2,cluster1,cluster1;其时间差向量为[fbrt,fbrt,fbrt,fbrt,fbrt]。[0104]现提出同位置特征近似假说(samepositionresemblance)。在人类认为近似的两个排列中,决定排列近似度的因素不止是排列的长度之类的排列的基础属性,而更取决于人们对排列中每个成员留下的印象。如图10所示,虽然序列a与b长度不同、b与c长度相同,但受试者仍认为a与b的相似度高于b与c,如图11所示。虽然图a与b长度不同,也不是相似图形(即等比例放大缩小图形),且b与c的图形比例相对于a与b来说更为接近,受试者仍认为a与b较b与c更为相似。同位置特征近似理论认为人会对物体提取一个大致结构的特征值,且人认为具有相近结构的物体更相似。而在具有相似结构的事物中,有些元素则被称为地位近似的,如图12和图13所示,受试者认为在上述ab中,被虚线相连的元素在相似结构中具有相似地位。同位置特征近似假说:人的大脑会对其认定相似的结构中的、具有相似地位的元素产生近似的特征值。该特征值称为地位特征值,有如下特点:仅在相似的结构中具有相似地位的元素才能产生相近的特征值,在其他情况下任意两元素产生的特征值应该距离很远。(即使相似结构不同地位的特征值也离得很远)若a、b是来自两个相同或不同序列的成员且它们的地位特征值相近,则称a等价b。在第一例中a的第3个成员与b的第三个成员等价,a的第6、7个成员及b的第6个成员互相等价。结构相似的评价标准由使用者给出,使lbri模型拥有同等的标准必须制作特殊训练集对rdtc进行训练。[0105]在cw序列中,weight高的cluster将更加被注意。若cw中一些高weight的cluster组成的具有近似结构的排列反复出现,称此类排列同属一类atar。现对于cw上任意一类atar:b,对于任意的cw'ara,若其属于b,则称为b的衍生排列,称b的衍生排列囊括的子序列为b的衍生子序列,一个衍生序列内必有至少一个衍生子排列。若子序列a为b的衍生子序列,称a属于b。cw上必须有多个互不重合的、成员weight权重较高的、结构相似的子排列才可视为cw上出现了一类atar,atar的结构是这一类相似的结构。即使b的某个衍生子序列中混入一些低weight的cluster,该子序列仍属于b的衍生子序列,低权重的cluster将被视为噪音。b的衍生子排列中有效成员(高weight)称为valid,噪音成员(低weight)称为noise。b的衍生子排列或衍生子序列的长度或成员都不一定相同,判定一个cw的子序列是否属于b的充要条件是其valid组成的排列是否与b的结构相似。注意,cw成员的特征值与地位特征值概念不同,特征值指cw成员cluster的centroid记录的特征值,地位特征值只成员根据前后结构生成的特征值。[0106]使用者训练rdtc的目标是使其能从cw中识别出对于自己的标准来说结构相似的、同属一类的子序列们,这需要按需求制作定制的训练集。但给定的结构相似标准必须遵循以下限制:[0107]1.等价类齐全[0108]等价类是指一类相互等价的所有成员(无论是否来自同一tsq),不同等价类之间的成员不等价。一类atar中有若干等价类,设任意的b类atar有n个等价类,b的任意衍生子排列b必满足此条件:对于n个等价类,b的每一个成员都必须被归为其中一类,且对于这n个中任意一个等价类,b都至少有一个成员属于它。b的衍生子序列由于混入噪音所以不一定满足此条件。对于包含若干b类atar的衍生子排列的任意集合ba及ba中任意一个排列的任意一个成员c,定义二元函数eql(ba,c)可以求得ba所有序列中和c同属一个等价类的所有成员的集合。eql的输入为一个tsq集合和属于此集合中任意序列的任意成员。[0109]2.相邻等价类时间差近似[0110]属于不同等价类的成员在一类atar的衍生子排列中的出现是有次序的。一类atar等价类可以按次序形成等价类序列。设在b类atar中有相邻的第n与n 1个等价类,b有任意的衍生子排列b的两个成员b1与b2分别属于第n与n 1个等价类,则(b1,b2)t必须处于一个范围之内。此范围称为相邻类范围。通俗解释,若人记住过一组动作a,当a中某一个动作的下一个动作太早或太迟出现时人们都会认为所看到的不是动作a了。[0111]rdtc通过将cw序列分割成不同的、属于不同类的子序列并标记来实现功能。同一个cw序列上可能存在着不止一类atar。使用者应为自己需求训练rdtc,但rdtc必须满足排异限制。[0112]排异限制,cw中较长的子序列最多只能被划分到一类atar的一个子序列中。即在rdtc划分后的cw上,任意两个衍生子序列之间不可大规模重合,无论是否属于一类。两个子序列大规模重合指同时存在于双方的成员数量与任意一方长度之比大于某个上限阈值a,a的具体值由使用者根据需求而定。图例是当时违反排异限制的划分方式。子序列b公有成员数量与长度之比达到超过a,所以a、b大规模重合。rdtc在大多数情况下不应做出违反排异限制的划分,这需要使用者制作特殊训练集训练。[0113]rdtc的输入规格,rdtc接受的输入共有sum个维度相同的向量,称为输入子向量。每一个cw的成员对应一个输入子向量,按照cw序列的顺序将sum个输入子向量拼接为输入矩阵对rdtc进行输入。对于任意的n《sum,cw(n)num的输入子向量对应输入矩阵第n列的向量。输入子向量有fbrd 1个维度,由cw成员cluster的centroid向量与weight拼接而成。其中前fbrd维为centroid,最后一位为weight。综上所述rdtc的输入是一个(fbrd 1)×sum的矩阵(输入矩阵)。其中,若有smc的aptr置空,则令其的输入子向量为零向量。[0114]rdtc的输出同样是一个矩阵,由对应着每个cw成员的、sum个输出子向量按cw中的顺序拼接而成。输出子向量由三部分组成:judge、head、position。judge与head是两个数,位于输出子向量的前两位,而position是posd维的向量,posd由使用者结合具体情况给定,位于输出子向量的后posd位。所以输出子向量共有posd 2维,rdtc的输出则为一个(posd 2)×sum的矩阵(输出矩阵)。其中,judge与head位的值域应为(0,1)。rdtc凭借judge与head位划分cw序列,其中的position特征值是生成的cw成员的地位特征值。设cw中划分出了两个子序列a与b,若a与b同属一类atar,则其地位相近的成员对应输出矩阵中的position向量也应距离相近。rdtc应满足以下输出限制:[0115]将整个cw序列化为输入矩阵输入rdtc并得到输出矩阵,若存在至少一类atar,应有:[0116]1.输出矩阵中,valid对应的输出子向量的judge位应尽可能接近1,noise对应的输出子向量的judge位尽可能接近0;[0117]2.输出矩阵中,cw划分得到的任何一个衍生子序列中首个成员对应的输出子向量head位应尽可能为1,最后一个成员对应的输出子向量head位应尽可能为0,其它情况下此位应处于0与1之间,不接近它们中的任何一个。rdtc功能建议使用传统dnn或使用自注意力机制的transformers实现,因为这是一个非线性的函数。[0118]可解释序列脉冲神经网络isnn(interpretablesnn-analogousneuralnetwork)模块,isnn类似于snn,但改变了一部分结构,isnn的结构与功能:[0119]1.isnn中的脉冲神经元使用简化后的lif(leakyintegrate-and-fire)模型。为简化计算及提升可解释性,取消了神经脉冲的传播时延及持续放电的行为。神经元的动作由在电位达到阈值后短时期内放电简化为在电位达到阈值后只放电一瞬间,同时接受神经脉冲的后续神经元的电位不再是持续上升,而是立即上升一个数。2.isnn中部分神经元可以被封锁,以此特性替换生物神经元的不应期。被封锁时,输入突触的电位脉冲将不会对神经元的电位产生影响。isnn神经元的行为是:[0120][0121]u(t dt)=u(t) du(t) cuj·∑j、wj·cj(t)ꢀꢀ式2[0122]s(t)=1,u(t)=ur2ifu(t)≥uth[0123]s(t)=0ifu(t)<uth[0124]式中,t代表时间变量,u(t)为膜电位函数,s(t)为输出的脉冲电位函数;dt代表时间步长,du(t)代表膜电位在一个时间步长内自发改变的值;τ是常数,ur1为静息电位,ur2为重置电位;uth是膜电位阈值;wj为第j个输入突触的权重,cj(t)是第j个输入突触的脉冲电位函数;cuj是第j个输入突触的控制条件,是布尔函数,当电位脉冲传入时,根据具体情况决定cuj取0还是1。cuj将若干个自己或其它神经元的电位是否处于某个范围当作判断条件;其中cj(t)只在离散的点上值为1,t取其余值时为0。这意味着cj(t)的定义域上不存在任何一处连续的部分使cj(t)取值为1。上述参数在每个神经元中都不同。公式表明正常情况下每过dt时间神经元膜电位便会改变du(t),式1给出二者的比例;而当电位脉冲从输入突触传来时,则根据突触是否被封锁来判断决定膜电位受的影响。如果受影响则膜电位立即根据输入突触的权重上升一个常数,否则无变化。当膜电位高于uth时立即释放一次电位脉冲,之后膜电位降为ur2。[0125]构成isnn的基本组件包括推理igear子模块和非脉冲神经元filter子模块。igear(inferencegear:推理组件)子模块,一个igear由四个神经元组成,名称分别为:trigger、upperlimit、lowerlimit、and(触发器、上限、下限、与运算)。其中trigger的输出只连接到upperlimit和lowerlimit,upperlimit和lowerlimit的电位是and的控制条件,upperlimit的电位是trigger的控制条件(此关系用虚线表示)。igear子模块原理图可见图14。[0126]igear的输入包括igearinput1与igearinput2。igearinput1是来自其它igear的输出且其·只作为trigger的输入,而igearinput2则是来自于后文讲述的filter(过滤器)部分的输出,且其只作为and的输入。后文提到将igear1连接到igear2是指将igear1的输出作为igear2的trigger的输入,将filter连接到igear2是指将filter的输出作为igear2的and的输入。igear可抽象成如图15所示的组件。filter是isnn的非脉冲神经元部件,其接受fbr的输入。每个filter监视着一个cluster,现有监视cluster1的filter名为filter1。定义函数ftr(filter1)可求出filter1监视的cluster1的范围。此范围由cluster1的centroid、average、variance计算得到。具体计算方式由使用者给定。落在此范围内的特征值将会被判断为与centroid相近,认定其属于此cluster。若fbr传来的特征值落在ftr(filter1)时filter1便立刻产生一次瞬时的脉冲。[0127]filter输出都与igear相连。filter的实现很简单,少量层数的ann或者其它简易的函数结构即可实现。非脉冲神经元filter子模块原理图可见图16。[0128]isnn由igear与filter构成。一条长期记忆由一个isnn网络构成,其模拟了一类atar。若isnn网络s1模拟了b,那么当b的某个衍生子序列从fbr沿时间依次传入时,s1将会在其传入完毕后产生一个瞬间的脉冲,告诉lbri它识别出了此类atar。现将讲述一个isnn如何进行模拟。[0129]首先讲述相连的igear组成的结构igear链如何模拟a类atar的衍生子排列a。a为cw的一个排列,a各个成员的地位特征值已求出。[0130]任意的tsq可增广为“tsq三元组”。tsq三元组结构为《s,t,p》。其中s为序列本身,t为其时间差向量,p为地位矩阵。对于任意的tsqa,as,at,ap表示a三元组的三个属性。令a的长度为n,则p为posd×n的矩阵。[0131]对于任意的j≤n,p的第j个向量为a的第j成员的地位特征值。利用函数triplize(三元组化)生成tsq的三元组,其中tsq的地位特征值需要提前給出,则a的三元组为triplize(a,ap)。[0132]现利用triplize(a,ap)构建一条属于a的igear链。a为cw的子序列或排列。为as的每一个成员生成一个igear,且对于as中的任意第m位成员,称其igear为第migear。若第m 1与m-1igear存在,将第migear连接到第m 1igear,第m-1连接到第migear。第migear的and神经元还需要连接上与as第m成员cluster的filter。一个filter可以连接多个as成员的igear,只要这些成员同为一个cluster。如此形成按顺序相连的igear链ac,并标记其最后一个igear为输出位。ac可以抽象成一个以igear为元素的tsq。[0133]ac将拥有下述行为。当一个与a结构相似的tsqa’传入时,ac中的igear将按连接顺序依次发出脉冲,最终在a’中与a最后一个成员等价的成员到达后,ac末尾的igear发出ac的输出脉冲。其中,对于任意的m(m》1,m≤n),以等价于a(m)num的a’成员的到达时刻为0时刻,只有在某一时间范围内等价于a(m 1)num的a’成员到达,ac的第m 1igear才会发出脉冲。此时间范围称为容许范围,求法后文给出。构造第m与第m 1个成员的igear结构,如图17所示。[0134]假设第m以及第m 1个成员的容许范围为[start,end],其分别接受filterm与filterm 1的输入。在m的等价成员到达后igearm发出脉冲,igearm 1的trigger将在瞬间接受到脉冲并也立刻发出电位脉冲。(以下提到的igear内部神经元都是igearm 1内部的结构)正常情况下and神经元用于接收filterm 1的输入突触处于封锁状态,即其控制单元函数值为0。在收到了电位脉冲后其在接下来的一段时间范围内由于upperlimit及lowerlimit的电位改变filterm 1的输入突触将处于开放状态,即其控制单元函数值为1(具体实现将后文讲述)。此时间范围即为容许范围[start,open]。这意味着只有在收到igearm传来的脉冲后igearm 1才能从filterm 1处接收脉冲。[0135]upperlimit及lowerlimit的具体实现,令trigger对于upperlimit的输入权重是wu,对于lowerlimit的输入权重是wl。其中wu≥0,wl≤0。在trigger发出脉冲后,受wu及wl取值影响,upperlimit的电位将上升一个常数并随后开始下降,而lowerlimit的电位将下降一个常数并随后开始上升。[0136]对于upperlimit,wu的取值需要满足此条件:[0137]对于lowerlimit,wl的取值需要满足此条件:[0138]其中,τu是upperlimit中的τ参数,τl是lowerlimit中的τ参数,a≈b表明a与b数值极为相近但不一定必须相等,至于a与b之间的差值允许范围由使用者决定。upperlimit和lowerlimit的控制条件无论何时都是1。[0139]and的控制条件cua为:[0140][0141]else,cua=0[0142]trigger的控制条件cut为:[0143][0144][0145]其中uu、ul为upperlimit及lowerlimit的电位,为阈值,应为两个常数,且参数τu、uu、ul、由容许范围[start,end]决定,只要满足上述条件的取值都可以。在获得容许范围后可通过方程求得。[0146]以trigger发出脉冲的瞬间为0时刻,根据上式,upperlimit只有在[0,end]范围的时刻左右内电位才会大于而lowerlimit只有在[start,-∞]范围的时刻左右内电位才会大于这意味着只有在容许范围[start,end]内filterm 1发出的脉冲and神经元才会接收到,且在[0,end]范围内trigger不会接受其它igear发出的脉冲。filterm 1监视ac(m 1)num,所以只有属于ac(m 1)num的特征值从fbr传入时filterm 1才会产生脉冲。[0147]综上所述,在trigger发出脉冲后,只有在范围大约为[start,end]的时刻有属于ac(m 1)num的特征值近从fbr传入时,igearm 1才会产生脉冲。对于a的第一个成员,没有igear与之对应,直接使用filter1连接到igear2的trigger。因为任何一个属于第1成员cluster的特征值都可能被视为近似序列的开始。[0148]现给出容许范围[start,end]的计算方式,定义一个atar数据集为一类或若干类atar衍生子排列的若干tsq三元组的集合。b、c类atar数据集data是指data中所有的tsq都属于b类或c类atar。其它命名以此类推。求得容许范围不止需要triplize(a),还需要a类atar数据集。设现有a类数据集adata,triplize(a,ap)∈adata。设集合md为:所有adata的三元组的序列中,与ac(m 1)num等价(地位特征值近似)的成员的集合。对于md中的任意元素c,计算pred(c)并将其放入时间差集timeset。统计timeset中时间差值的分布,应用统计学方法给出时间差分布最集中的区域。此区域即为求得的容许范围[start,end]。称将一个tsq三元组及其所属的数据集按上述步骤映射到一个igear链的函数为chainize,即:[0149]chainize(triplize(a,ap),adata)=ac[0150]上述igear链可在一定程度上模拟一类atar但只能识别与其结构很相似的序列。其识别范围狭窄,容错率小,无法很好的识别一类atar。isnn网络是一种对igear链的强化学习,极大程度地提升了识别能力,可以更大范围地识别atar。以下是制作isnn的流程。[0151]双次映射生成isnn:现制作isnn网络s1以模拟名为b的一类atar,且现拥有一个b类atar的数据集d。[0152]1.构造集合dtuples。对于d中的任意一个tsq三元组triplize(b,bp),进行如下操作:利用函数chainize构造igear链bc=chainize(triplize(b,bp),d)。利用bc及bp为b构造一个元组《bc,bp》(这种元组命名为单链元组)。令dtuples是d中所有元素生成的单链元组的集合。定义将一个atar数据集映射到单链元组集合的函数为tuplize,即tuplize(d)=dtuples。[0153]2.将dtuples集合使用connect函数映射到一个isnn网络上,connect函数实现如下:1)connect接受单链元组的集合为输入并输出为一个isnn网络。2)设connect函数接受集合tuples,令chains为tuples中所有元组的igear链的集合,tuples中任意的元组a中的igear链和矩阵名为ac、qp。对于a,定义集合eqlna,n=eql(chains,ac(n 1)num)(与ac(n 1)num同属一个等价类的任意igear链上的所有成员)。将ac中任意的第n成员的输出连接到eqlna,n中所有igear的输入上。即对于eqlna,n中任意元素m,都有ac的第n个igear的输出作为m的输入。3)chains中所有链的igear都进行了2)的操作后会相互连接形成isnn网络output,将output作为输出,即connect(tuples)=output。将igear链b0中的b0(n)num连接到所有同b0(n 1)num等价的igear。则connect(dtuples)=s1。如此之后在s1中,每一个子排列的igear不止连接属于自己序列的igear,还连接处于其它子排列的、与自己下一个成员等价的成员的igear。这样的策略会引起igear回路,回路出现是正常的,不应该避免。isnn网络中单个igear的trigger将会连接多个其它的igear,此时trigger的情况就不是收到其中一个igear的脉冲后立刻发出脉冲了。其它igear到trigger的权重是要进行计算的。对于一个trigger,其行为应该是在短时间内有一定数量比例的输入发出脉冲其才输出脉冲。遵循这一原则后按使用场景对所有的igear输出权重进行赋值。[0154]isnn的结构及行为已阐述结束,下面将阐述与isnn有关的biologicalinstinct功能lgen:long-termmemorygenerator。当我们确认cw序列中存在某种未被学习过的atar时,会运行rdtc功能对cw序列进行特征值提取,产生若干类atar以及对于每一类atar的若干个衍生子排列。lgen的功能是把rdtc提取结果转化成isnn网络。lgen只需要给出cw提取结果的isnn网络结构以及里面的参数即可。现给出过程。1.制作atar数据集singles,抽取输出序列中judge位为1的成员并形成排列(称其为regular序列)。对regular序列进行划分,对于regular中任意的head位接近1的第m位成员,搜索在其之后的、离其最近的、head位接近0的第m'位成员,并提取regular的子序列regular'ssm,m',若第m位成员之后并无head位接近0的成员,则不予处理。将所有通过上述方式提取出的子序列集合称为arranges。对于arranges中的任意tsqs,从输出矩阵中提取其地位特征值并按序重新拼接为矩阵sp,使用triplize求出s的三元组triplize(s,sp)。称由arranges得到的所有的三元组的集合为singles,singles即为需要的atar数据集。数据集制作流程如图18所示。2.对singles进行双次映射得到isnn网络union,对singles进行双次映射,即union=connect(tuplize(singles))。3.将union划分为numerous集合:定义separate为将一个isnn映射到一个isnn集合的函数。对于任意isnn,将其抽象为一张图g,igear为g的节点,igear之间只要有连接就将此连接抽象成一条无向边。现将任意输入in映射到输出out,即separate(in)=out,将out中的元素和in抽象成图后,separate函数将求出in中的所有极大联通子图,并将它们对应的isnn子网络形成集合out进行输出。第三步对union进行划分得到isnn集合numerous,numerous中的每一个网络象征着一类atar,numerous=separate(union),设s为numerous中的任意网络。4.设s为numerous中的任意网络,找出里面所有的输出位igear,并将其连接到一个只属于s的输出神经元上。只有在短时间内一定比例的输出igear发出脉冲s的神经元才发出脉冲。根据此限制确定相关参数。5.将numerous中的各个网络加入长期记忆,并整合数据集中的等价类,加入等价类数据池eqlpool中。eqlpool数据池记载着多种等价类,每一类由质心地位特征值及范围等参数表示。利用d中的地位特征值矩阵进行地位特征值聚类,并将新得到的类加入eqlpool。如果新得到的类x和eqlpool中已有的类y大规模重合则将x合并到y并对y进行质心及范围的调整。具体做法参考聚类算法。通过数据集制作长期记忆的流程如图19所示。[0155]长期记忆中输出神经元的输出便是lbri的输出,通过输出所属的不同长期记忆对应的isnn网络来判定传入的特征值中触发了哪一部分回忆。rdtc的detected信号,detected信号是为了发现新的、未被加入长期记忆的atar而设立的。其策略是,定期使用rdtc功能扫描cw序列,收集judge位为1的成员的地位特征值。判断这些特征值在不在eqlpool中的等价类之中。若某一次执行完rdtc后发现大于一定比例的地位特征值不在eqlpool中,那么判定此出现结构迥异的新atar,发出detected信号。[0156]lbri模型总的示意图见图20。[0157]为了更清楚的说明本发明的构思,以人类动作识别为实例做进一步说明:[0158]采用receptor-brainmode,其中由类似于cnn的结构作为receptor,lbri作为brain。receptor以固定周期h不断通过固定的摄像头截取照片并提取特征值,之后将特征值通过fb传给lbri。每过h的时间lbri便会收到一个特征值。每个人不同的姿态应被提取不同的特征值,相近的姿态对应相近的特征值。如举起右手与抬起右脚对应不同的特征值,而举右手到相近高度的两个姿态应对应相近的特征值。摄像头不断拍照,receptor不断处理图片。当某一个人进入视野范围时receptor应注意到他并提取其在每一张照片上姿态的特征值,当视野有很多人时receptor应具有注意力,只连续提取其中一个人的姿态。receptor不属于本发明实现的范畴,在此只提及实现动作识别对receptor的要求作为举例。[0159]brain:lbri模型。每当有特征值从fb传入时,其都会经过rann中drnn的处理,并传入到lbri内部的特征值总线fbr上。经drnn处理后每个特征值将不止代表人当前的姿态,还代表正在进行的动作。如一段将手以速度v举过头顶的动作被拍摄到,这一段动作最后被传入的姿态为手垂直悬于头顶,fb传入的特征值为a1;而在将手以2v的速度举过头顶的动作中,最后被传入的姿态仍是手垂直悬于头顶,fb传入的特征值为a2。因为最后的姿态几乎一样,所以a1与a2极其相近。但drnn处理时不仅考虑此时刻的姿态,因其具有的很短的记忆其还能考虑之前时刻的姿态。所以因为之前传入的特征值不一样,所以a1、a2经加工后得到的特征值b1、b2就不相近了。drnn处理后的特征值代表着一种运动趋势,b1虽与b2对应的姿态相近,但速度不同,运动趋势不同,故二者不相近。同样手做直线运动举过头顶及做曲线运动举过头顶,手位于头顶的姿态虽相同,但drnn结合之前的可以分辨出其运动趋势不同,故给出不同的特征值。其中运动趋势是指人肢体运动的状态,包括但不限于运动速度、直线或曲线运动、运动方向等信息。若人位于不同姿态时drnn提取的特征值一定不相近,人即使处于同一姿态drnn也会因运动趋势的原因得出不同的特征值。只有同一姿态同一运动趋势时drnn才会求出相近的特征值。综上所述,fbr中的特征值是包含了人的姿态和运动趋势信息的特征值,称其象征着“运动姿态”。称fbr中相近的特征值为相同运动姿态,不相近的为不同运动姿态。[0160]当fbr特征值传入时,其会被objectmemory聚类为各种cluster。每一个cluster都代表着不同的运动姿态,之后负责记忆顺序的sequencememory将记住运动姿态出现的顺序。短期记忆如此形成,若一种运动姿态太长时间未出现就会被忘掉。[0161]一开始eqlpool中没有任何地位特征值类。rdtc定期扫描短期记忆,产生地位特征值。若短期记忆中有一段动作反复出现,则在某一次扫描中rdtc将分辨出其属于一类atar。收集此atar的地位特征值后,若发现存在大比例的不属于eqlpool中的地位特征值,则产生detected信号。其它情况下不产生detected信号。detected信号发出说明rdtc发现了新的重复出现的动作。[0162]若detected信号发出则lgen立刻运作,利用让rdtc产生detected的短期记忆制作数据集,并按照专利中给出的方法利用数据集制作isnn网络,形成象征着全新动作的新的长期记忆。[0163]一开始长期记忆模块中没有isnn,lgen在其后的时间里不断产生isnn并放入长期记忆。一条长期记忆对应一个isnn网络,也对应着一种被记忆的、曾经重复出现的动作。当特征值自fbr传来时,若某一个被记住的动作再现,则在其输入完后长期记忆中对应此动作的isnn便将其识别并给出输出。[0164]综上所述,在动作识别中,未见过的动作只要多次出现lbri模型便会将其记住,已记住的动作只要在次出现lbri模型便会将其识别。因此,lbri模型是一种无监督的动作识别方法。[0165]基于同一发明构思,本发明还提供了一种基于无监督神经网络lbri的动作识别系统,用以实现所述基于无监督神经网络lbri的动作识别方法,包括lbri模型,所述lbri模型用以解决动作识别的问题。[0166]需要说明的是,对于前述的实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本技术并不受所描述的动作顺序的限制,因为依据本技术,某一些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例属于优选实施例,所涉及的动作并不一定是本技术所必须的。[0167]上述实施例中,描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。当前第1页12当前第1页12
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。