1.本技术涉及互联网技术及驾驶员识别领域,特别是涉及一种驾驶员识别方法、装置、计算机设备及可读存储介质。
背景技术:
2.随着国民经济水平的不断提升,我国汽车保有量骤增。汽车在带给我们极大便利的同时也制造了很多交通事故,尤其是运输行业。当车辆出现交通事故,往往会造成大面积的伤亡现象。因此,如何实现对驾驶员的严格管理,防止不具备驾驶资格的驾驶员上路、防止驾驶员疲劳驾驶以及防止驾驶员长时间的连续驾驶工作等,便成为汽车行业的重要的研究工作。因此,基于车载行驶数据对驾驶员身份辨识成为一种有效方法。
3.相关技术中,通过车辆自身的控制器局域网络采集行车状态信号,无需安装额外设备。但目前大部分研究工作都是考虑私家车、公交车及短途公共汽车等,这种情况下每辆汽车仅配备一名司机驾驶。鲜少考虑货运汽车因路途较远及行驶时间较长,通常一辆货运汽车配备两名驾驶员轮换驾驶的情况。因此,亟需一种能够适用于货运汽车准确识别驾驶员身份的方法,避免因驾驶员疲劳驾驶而导致的交通事故。
技术实现要素:
4.有鉴于此,本技术提供了一种驾驶员识别方法、装置、计算机设备及可读存储介质,主要目的在于解决目前鲜少考虑货运汽车因路途较远及行驶时间较长,通常一辆货运汽车配备两名驾驶员轮换驾驶的情况,从而导致货运汽车驾驶员识别准确率低的问题。
5.依据本技术第一方面,提供了一种驾驶员识别方法,该方法包括:
6.获取目标车辆的目标采样数据进行数据清洗,得到多个行车事件对应的行车数据,所述行车事件用于指示所述目标车辆从发动到停止的过程;
7.对每个行车事件指示的行车数据进行计算,得到每个所述行车事件对应的指标组,以及采用因子分析对每个指标组进行降维处理,得到所述多个行车事件对应的待聚类数据,所述指标组包括多个维度指标;
8.基于k-means算法,对所述待聚类数据进行聚类运算,得到所述目标车辆对应的驾驶员身份识别聚类结果。
9.可选地,所述获取目标车辆的目标采样数据进行数据清洗,包括:
10.统计前一次获取目标采样数据的历史时间点;
11.确定当前时间点,在当前时间点与所述历史时间点之间的时间间隔等于预设的识别周期时,在数据库中读取当前周期内存储的多个采样数据集作为所述目标采样数据,所述采样数据集为一次行车事件内产生的行车数据;
12.按照时间从前到后的顺序对所述多个采样数据集进行排序;
13.基于自然语言处理技术,对每个采样数据集进行数据识别;
14.若采样数据集中存在第一指定数据值缺失,则确定所述第一指定数据值对应的指
定采样项,基于所述指定采样项对所述第一指定数据值进行补充;和/或,
15.若所述采样数据集中同一采样项存在两个重复值,则删除其中之一。
16.可选地,所述基于所述指定采样项对所述第一指定数据值进行补充,包括:
17.遍历所述采样数据集中所述指定采样项对应的全部数据值,在所述全部数据值中读取所述第一指定数据值前后的第二指定数据值和第三指定数据值;
18.计算所述第二指定数据值和所述第三指定数据值的均值,采用所述均值补充所述第一指定数据值。
19.可选地,所述对每个行车事件指示的行车数据进行计算,得到每个所述行车事件对应的指标组,包括:
20.对于每个行车事件,按照所述指标组中每个维度指标对应的计算规则,对所述行车事件指示的行车数据进行计算,得到所述多个指标值,聚合所述多个指标值,得到所述指标组,所述维度指标包括超速占比、车速平均值、车速标准差、加速度标准差、正加速度平均值、正加速度标准差、负加速度平均值、负加速度标准差、急加速次数、急减速次数、急刹车次数;
21.其中,每个行车事件中的急加速次数、急减速次数和急刹车次数是通过计算当前行车事件对应的加速度和加速度持续时间,分别将所述加速度和所述加速度持续时间与加速度阈值和时间阈值进行比对,根据比对结果确定的。
22.可选地,所述采用因子分析对每个指标组进行降维处理,得到多个行车事件对应的待聚类数据,包括:
23.采用kmo检验法和bartlett球形检验法对多个行车事件对应的多个指标组进行因子可行性验证;
24.在验证通过后,对每个指标组进行因子分析,得到多个影响因子,在所述多个影响因子中提取三个主因子进行分析,得到因子载荷矩阵;
25.采用凯撒正态化最大方差法,对所述因子载荷矩阵进行因子旋转,得到每个行车事件对应的旋转因子载荷矩阵,将多个旋转因子载荷矩阵作为多个样本数据进行聚合,得到所述待聚类数据。
26.可选地,所述基于k-means算法,对所述待聚类数据进行聚类运算,得到所述目标车辆对应的驾驶员身份识别聚类结果,包括:
27.在所述待聚类数据中选取多个初始聚类中心,每个所述初始聚类中心对应一个初始类别组;
28.对于所述待聚类数据中的每个样本数据,计算所述样本数据与每个聚类中心之间的样本距离;
29.按照距离最小原则,对所述待聚类数据中的样本数据进行重新分类,更新每个所述初始聚类中心对应的初始类别组,得到对应的第一目标类别组;
30.计算每个第一目标类别组的第一中心,采用所述第一中心更新对应的初始聚类中心,得到第一目标聚类中心;
31.更新多个所述初始聚类中心,得到多个第一目标聚类中心;
32.若每个第一目标聚类中心均与对应的初始聚类中心一致,则输出所述驾驶员身份识别聚类结果。
33.可选地,所述更新多个所述初始聚类中心,得到多个第一目标聚类中心之后,所述方法还包括:
34.若任意一个第一目标聚类中心与对应的初始聚类中心不一致,则重新计算所述待聚类数据中每个样本数据与每个第一目标聚类中心之间的样本距离;
35.按照距离最小原则,重新对所述待聚类数据中的样本数据进行分类,更新每个所述第一目标聚类中心对应的第一目标类别组,得到第二目标类别组;
36.计算每个第二目标类别组对应的第二中心,采用所述第二中心更新所述第一目标聚类中心,得到第二目标聚类中心;
37.更新多个所述第一目标聚类中心,得到多个第二目标聚类中心;
38.如果每个第二目标聚类中心均与对应的第一目标聚类中心一致,则输出所述驾驶员身份识别聚类结果;
39.如果任意一个第一目标聚类中心与对应的初始聚类中心不一致,则重新计算所述待聚类数据中每个样本数据与每个第二目标聚类中心之间的样本距离,直至计算出的第三目标聚类中心均与对应的第二目标聚类中心一致,输出所述驾驶员身份识别聚类结果。
40.依据本技术第二方面,提供了一种驾驶员识别装置,该装置包括:
41.获取模块,用于获取目标车辆的目标采样数据进行数据清洗,得到多个行车事件对应的行车数据,所述行车事件用于指示所述目标车辆从发动到停止的过程;
42.计算模块,用于对每个行车事件指示的行车数据进行计算,得到每个所述行车事件对应的指标组,以及采用因子分析对每个指标组进行降维处理,得到所述多个行车事件对应的待聚类数据,所述指标组包括多个维度指标;
43.聚类模块,用于基于k-means算法,对所述待聚类数据进行聚类运算,得到所述目标车辆对应的驾驶员身份识别聚类结果。
44.可选地,所述获取模块,用于统计前一次获取目标采样数据的历史时间点;确定当前时间点,在当前时间点与所述历史时间点之间的时间间隔等于预设的识别周期时,在数据库中读取当前周期内存储的多个采样数据集作为所述目标采样数据,所述采样数据集为一次行车事件内产生的行车数据;按照时间从前到后的顺序对所述多个采样数据集进行排序;基于自然语言处理技术,对每个采样数据集进行数据识别;若采样数据集中存在第一指定数据值缺失,则确定所述第一指定数据值对应的指定采样项,基于所述指定采样项对所述第一指定数据值进行补充;和/或,若所述采样数据集中同一采样项存在两个重复值,则删除其中之一。
45.可选地,所述获取模块,用于遍历所述采样数据集中所述指定采样项对应的全部数据值,在所述全部数据值中读取所述第一指定数据值前后的第二指定数据值和第三指定数据值;计算所述第二指定数据值和所述第三指定数据值的均值,采用所述均值补充所述第一指定数据值。
46.可选地,所述计算模块,用于对于每个行车事件,按照所述指标组中每个维度指标对应的计算规则,对所述行车事件指示的行车数据进行计算,得到所述多个指标值,聚合所述多个指标值,得到所述指标组,所述维度指标包括超速占比、车速平均值、车速标准差、加速度标准差、正加速度平均值、正加速度标准差、负加速度平均值、负加速度标准差、急加速次数、急减速次数、急刹车次数;其中,每个行车事件中的急加速次数、急减速次数和急刹车
次数是通过计算当前行车事件对应的加速度和加速度持续时间,分别将所述加速度和所述加速度持续时间与加速度阈值和时间阈值进行比对,根据比对结果确定的。
47.可选地,所述计算模块,用于采用kmo检验法和bartlett球形检验法对多个行车事件对应的多个指标组进行因子可行性验证;在验证通过后,对每个指标组进行因子分析,得到多个影响因子,在所述多个影响因子中提取三个主因子进行分析,得到因子载荷矩阵;采用凯撒正态化最大方差法,对所述因子载荷矩阵进行因子旋转,得到每个行车事件对应的旋转因子载荷矩阵,将多个旋转因子载荷矩阵作为多个样本数据进行聚合,得到所述待聚类数据。
48.可选地,所述聚类模块,用于在所述待聚类数据中选取多个初始聚类中心,每个所述初始聚类中心对应一个初始类别组;对于所述待聚类数据中的每个样本数据,计算所述样本数据与每个聚类中心之间的样本距离;按照距离最小原则,对所述待聚类数据中的样本数据进行重新分类,更新每个所述初始聚类中心对应的初始类别组,得到对应的第一目标类别组;计算每个第一目标类别组的第一中心,采用所述第一中心更新对应的初始聚类中心,得到第一目标聚类中心;更新多个所述初始聚类中心,得到多个第一目标聚类中心;若每个第一目标聚类中心均与对应的初始聚类中心一致,则输出所述驾驶员身份识别聚类结果。
49.可选地,所述聚类模块,还用于若任意一个第一目标聚类中心与对应的初始聚类中心不一致,则重新计算所述待聚类数据中每个样本数据与每个第一目标聚类中心之间的样本距离;按照距离最小原则,重新对所述待聚类数据中的样本数据进行分类,更新每个所述第一目标聚类中心对应的第一目标类别组,得到第二目标类别组;计算每个第二目标类别组对应的第二中心,采用所述第二中心更新所述第一目标聚类中心,得到第二目标聚类中心;更新多个所述第一目标聚类中心,得到多个第二目标聚类中心;如果每个第二目标聚类中心均与对应的第一目标聚类中心一致,则输出所述驾驶员身份识别聚类结果;如果任意一个第一目标聚类中心与对应的初始聚类中心不一致,则重新计算所述待聚类数据中每个样本数据与每个第二目标聚类中心之间的样本距离,直至计算出的第三目标聚类中心均与对应的第二目标聚类中心一致,输出所述驾驶员身份识别聚类结果。
50.依据本技术第三方面,提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述第一方面中任一项所述方法的步骤。
51.依据本技术第四方面,提供了一种可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述第一方面中任一项所述的方法的步骤。
52.借由上述技术方案,本技术提供的一种驾驶员识别方法、装置、计算机设备及可读存储介质,本技术首先获取当前周期内产生的目标车辆的目标采样数据进行数据清洗,以目标车辆从发动到停止的过程为一次行车事件,得到当前周期内多个行车事件对应的行车数据。进一步地,对每个行车事件指示的行车数据进行计算,得到多个维度指标分别对应的指标值,将一次行车事件对应的多个指标值作为一个指标组,计算每个行车事件对应的指标组。接下来,采用因子分析技术对每个指标组进行降维处理,获取多个行车事件对应的待聚类数据。最后,基于k-means算法,对待聚类数据进行聚类运算,得到目标车辆对应的驾驶员身份识别聚类结果。本方法在对每天的行程划分为多次行车事件后,通过对车载数据进
行预处理,利用主成分因子分析对高维数据降维,并利用k-means算法进行聚类,采用机器学习的方法对数据进行处理、分类、决策,识别出每一次行车事件是由哪名司机驾驶,最终实现提高车辆驾驶员身份识别的准确率。
53.上述说明仅是本技术技术方案的概述,为了能够更清楚了解本技术的技术手段,而可依照说明书的内容予以实施,并且为了让本技术的上述和其它目的、特征和优点能够更明显易懂,以下特举本技术的具体实施方式。
附图说明
54.通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本技术的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
55.图1示出了本技术实施例提供的一种驾驶员识别方法流程示意图;
56.图2a示出了本技术实施例提供的一种驾驶员识别方法流程示意图;
57.图2b示出了本技术实施例提供的一种驾驶员识别方法过程示意图;
58.图2c示出了本技术实施例提供的一种驾驶员识别方法流程示意图;
59.图3示出了本技术实施例提供的一种驾驶员识别装置的结构示意图;
60.图4示出了本技术实施例提供的一种计算机设备的装置结构示意图。
具体实施方式
61.下面将参照附图更详细地描述本技术的示例性实施例。虽然附图中显示了本技术的示例性实施例,然而应当理解,可以以各种形式实现本技术而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本技术,并且能够将本技术的范围完整的传达给本领域的技术人员。
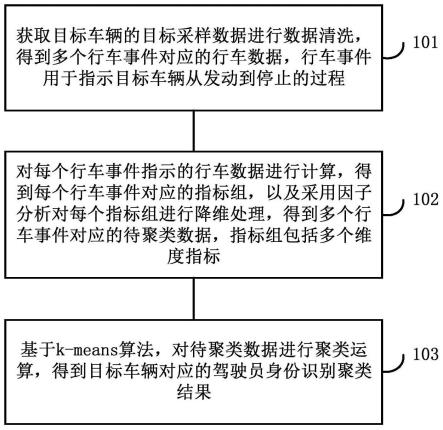
62.本技术实施例提供了一种驾驶员识别方法,如图1所示,该方法包括:
63.101、获取目标车辆的目标采样数据进行数据清洗,得到多个行车事件对应的行车数据,行车事件用于指示目标车辆从发动到停止的过程。
64.102、对每个行车事件指示的行车数据进行计算,得到每个行车事件对应的指标组,以及采用因子分析对每个指标组进行降维处理,得到多个行车事件对应的待聚类数据,指标组包括多个维度指标。
65.103、基于k-means算法,对待聚类数据进行聚类运算,得到目标车辆对应的驾驶员身份识别聚类结果。
66.本技术实施例提供的方法,首先获取当前周期内产生的目标车辆的目标采样数据进行数据清洗,以目标车辆从发动到停止的过程为一次行车事件,得到当前周期内多个行车事件对应的行车数据。进一步地,对每个行车事件指示的行车数据进行计算,得到多个维度指标分别对应的指标值,将一次行车事件对应的多个指标值作为一个指标组,计算每个行车事件对应的指标组。接下来,采用因子分析技术对每个指标组进行降维处理,获取多个行车事件对应的待聚类数据。最后,基于k-means算法,对待聚类数据进行聚类运算,得到目标车辆对应的驾驶员身份识别聚类结果。本方法在对每天的行程划分为多次行车事件后,通过对车载数据进行预处理,利用主成分因子分析对高维数据降维,并利用k-means算法进
行聚类,采用机器学习的方法对数据进行处理、分类、决策,识别出每一次行车事件是由哪名司机驾驶,最终实现提高车辆驾驶员身份识别的准确率。
67.本技术实施例提供了一种驾驶员识别方法,如图2a所示,该方法包括:
68.201、获取目标车辆的目标采样数据进行数据清洗,得到多个行车事件对应的行车数据,行车事件用于指示目标车辆从发动到停止的过程。
69.随着国民经济水平的不断提升,我国汽车保有量骤增。汽车在带给我们极大便利的同时也制造了很多交通事故,尤其是运输行业。当车辆出现交通事故,往往会造成大面积的伤亡现象。因此,如何实现对驾驶员的严格管理,防止不具备驾驶资格的驾驶员上路、防止驾驶员疲劳驾驶以及防止驾驶员长时间的连续驾驶工作等,便成为汽车行业的重要的研究工作。因此,基于车载行驶数据对驾驶员身份辨识成为一种有效方法。通过车辆自身的控制器局域网络采集行车状态信号,无需安装额外设备。但目前大部分研究工作都是考虑私家车、公交车及短途公共汽车等,这种情况下每辆汽车仅配备一名司机驾驶。鲜少考虑货运汽车因路途较远及行驶时间较长,通常一辆货运汽车配备两名驾驶员轮换驾驶的情况。因此,亟需一种能够适用于货运汽车准确识别驾驶员身份的方法,避免因驾驶员疲劳驾驶而导致的交通事故。
70.因此,本技术提供了一种驾驶员识别方法、装置、计算机设备及可读存储介质,本技术首先获取当前周期内产生的目标车辆的目标采样数据进行数据清洗,以目标车辆从发动到停止的过程为一次行车事件,得到当前周期内多个行车事件对应的行车数据。进一步地,对每个行车事件指示的行车数据进行计算,得到多个维度指标分别对应的指标值,将一次行车事件对应的多个指标值作为一个指标组,计算每个行车事件对应的指标组。接下来,采用因子分析技术对每个指标组进行降维处理,获取多个行车事件对应的待聚类数据。最后,基于k-means算法,对待聚类数据进行聚类运算,得到目标车辆对应的驾驶员身份识别聚类结果。本方法在对每天的行程划分为多次行车事件后,通过对车载数据进行预处理,利用主成分因子分析对高维数据降维,并利用k-means算法进行聚类,采用机器学习的方法对数据进行处理、分类、决策,识别出每一次行车事件是由哪名司机驾驶,最终实现提高车辆驾驶员身份识别的准确率。
71.本方法适用于驾驶员身份识别系统,系统获取运营车辆安全监测系统所提供的货运车辆行驶数据,对货运车辆行驶数据进行识别判断。其中,运营车辆安全监测系统设置有多个采样点,每隔采样周期,如2s,就会采集各个采样点的行驶数据存储在文件中,每一行记录一个采样点的信息。采样点的信息主要包括编号、采集时间、总里程、脉冲车速、温度、轮胎转速、发动机扭矩、油门位置、刹车位置、挡位、空调等各类设备、车辆故障信息、车辆地理位置(经度、纬度)、车辆排放信息等字段。进一步地,以一辆目标运营车辆为例进行说明,运营车辆安全监测系统一般会将采集到的原始数据存储至数据库中,以日为单位进行存储。而这样的原始数据无法直接进行后续的分析,所以需要对原始数据进行预处理。数据预处理是一切工作的前提和关键一步,数据处理不准确合理,后期工作也会存在较大偏差。
72.在本技术实施例中,数据预处理的过程主要是将数据进行片段切分,切分的原则是将每日的原始采样数据划分为多次行车事件,也就是将目标车辆对应的原始数据划分为目标采样数据。需要说明的是,行车事件是指驾驶员从车辆发动行驶到车辆停止熄火所经历的驾驶过程,每一次行车事件包括多次怠速、加速、匀速和减速的完整过程。需要说明的
是,考虑到一次正常行车时长不会过短,且驾驶工况在较短时间内变化不会很大,所以提出一次行车时长小于10分钟的短行程事件,如果车辆长时间速度为0也不予采取。例如,在实际运行过程中行车事件小于10分钟,运营车辆安全监测系统采集并记录了这段时间内的原始数据并存储至数据库中,但由于时间过短,不能很好的表征驾驶员的行驶特征,因此本驾驶员身份识别系统不使用本次行车事件对应的行车数据。而车辆长时间速度为0,比如10多分钟甚至半个多小时,相当于停车,因此运营车辆安全监测系统是不记录本次行车事件内采集的数据。
73.进一步地,驾驶员身份识别系统设置有识别周期,每隔识别周期,本系统就会获取目标车辆的目标采样数据进行数据清洗,以得到多个便于后续进行驾驶员身份识别的行车数据。具体地,统计前一次获取目标采样数据的历史时间点。随后,不断确定当前时间点,在当前时间点与历史时间点之间的时间间隔等于预设的识别周期时,在数据库中读取当前周期内存储的多个采样数据集作为目标采样数据,其中,每个采样数据集指示一次行车事件内产生的行车数据。再按照时间从前到后的顺序对多个采样数据集进行排序。
74.接下来,考虑到采集到的数据会存在有缺失值、重复值,所以本技术基于自然语言处理技术,对每个采样数据集进行数据识别。若采样数据集中存在第一指定数据值缺失,则确定第一指定数据值对应的指定采样项,基于指定采样项对第一指定数据值进行补充。具体地,遍历采样数据集中指定采样项对应的全部数据值,在全部数据值中读取第一指定数据值前后的第二指定数据值和第三指定数据值。再计算第二指定数据值和第三指定数据值的均值,采用均值补充第一指定数据值。例如,目标车辆a采集到的速度数据为【20:00:00 58.1km/h】、【20:00:02(缺失)】、【20:00:04 58.5km/h】,则将【20:00:02】缺失的数值作为第一指定数据值,将第一指定数据值前的【20:00:00】对应的数值【58.1km/h】作为第二指定数据值,将第一指定数据值后的【20:00:04】对应的数值【58.5km/h】作为第三指定数据值,计算第二指定数据值和第三指定数据值的均值为【58.3km/h】,采用均值补充第一指定数据值,即【20:00:02 58.3km/h】。和/或,若采样数据集中同一采样项存在两个重复值,则删除其中之一。
75.202、对每个行车事件指示的行车数据进行计算,得到每个行车事件对应的指标组。
76.在本技术实施例中,目标车辆在当前识别周期内可能存在多个行车事件,对于每个行车事件,本驾驶员身份识别系统会按照指标组中每个维度指标对应的计算规则,对行车事件指示的行车数据进行计算,得到多个指标值。具体地维度指标包括超速占比、车速平均值、车速标准差、加速度标准差、正加速度平均值、正加速度标准差、负加速度平均值、负加速度标准差、急加速次数、急减速次数、急刹车次数。最后,聚合多个指标值,得到指标组,也就是说,指标组中存储有一次行车事件内的超速占比值、车速平均值、车速标准差值、加速度标准差值、正加速度平均值、正加速度标准差值、负加速度平均值、负加速度标准差值、急加速次数值、急减速次数值、急刹车次数值。需要说明的是,每个行车事件中的急加速次数、急减速次数和急刹车次数是通过计算当前行车事件对应的加速度和加速度持续时间,分别将加速度和加速度持续时间与加速度阈值和时间阈值进行比对,根据比对结果来确定的。具体计算指标组的过程如下:
77.一、超速占比
78.在本技术实施例中,考虑到营运货车质量大、运输时间长,车速因素对交通安全有较大影响。一般载重货车限速为80km/h,本文载重货车轨迹路径多为国道且运输时间长,故设定车速超过限速80%,即64km/h时,认为驾驶员会有一定的超速倾向。车速超过限速80%(64km/h)的时间比例即为超速占比,具体可以基于下述公式1计算:
[0079][0080]
其中,t为车辆在道路上行驶的总时间,t
l80
为车辆在道路上超过限速80%的时间;η为车辆速度超过限速80%的时间比例。
[0081]
二、车速平均值和车速标准差
[0082]
研究表明,车速平均值越高,发生事故的风险也越大,微小的车速变化会急剧提升发生事故的概率;车速标准差表现为速度离散程度,车速分布得越离散,事故发生率越高。因此车速平均值、标准差是表征驾驶行为特征的重要参数,具体可以基于下述公式2和公式3所示:
[0083]
公式3:
[0084]
公式4:
[0085]
其中,vm为车辆在道路上第m次采集的车速值;n为车辆在道路上采集的车速样本量;va为车辆在道路上的车速平均值;vs为车辆在道路上的车速标准差。
[0086]
三、加速度标准差、正加速度平均值、正加速度标准差
[0087]
加速度反映驾驶人对加速踏板、制动踏板等操纵装置的控制。正加速度是驾驶人操作加速踏板的结果,与交通环境及驾驶行为特征密切相关。因此加速度标准差、正加速度平均值、标准差,可作为驾驶行为特征的重要参数,具体可以基于下述公式5至公式8实现:
[0088]
公式5:
[0089]
公式6:
[0090]
公式7:
[0091]
公式8:
[0092]
其中,am为车辆在道路上第m次采集数据所对应的加速度;aa为车辆在道路上的加速度平均值;as为车辆在道路上的加速度标准差;t数据采集的时间间隔;为车辆在道路上第m次采集数据对应的正加速度;为车辆在道路上的正加速度平均值;为车辆在道路上的正加速度标准差。
[0093]
四、负加速度平均值、负加速度标准差
[0094]
负加速度(减速度)是驾驶人释放加速踏板或操纵制动踏板等操纵装置的结果。减速度越大说明车辆制动越紧急,这会给驾驶人带来不良反应,还会影响货物的安全运输,以
及对车辆装置造成较大磨损。因此减速度平均值、标准差可作为驾驶行为特征的重要参数,具体可以基于下述公式9至公式11进行计算:
[0095]
公式9:
[0096]
公式10:
[0097]
公式11:
[0098]
其中,为车辆在道路上第m次采集数据所对应的负加速度;为车辆在道路上的负加速度平均值;为车辆在道路上的负加速度标准差。
[0099]
五、急加速次数、急减速次数、急刹车次数
[0100]
由于异常驾驶行为数据最直接反映驾驶员的驾驶行为,故选取急加速、急减速、急刹车这些异常行为,因无法直接获取这些数据,需对异常驾驶行为识别,依据原则如下表1所示:
[0101]
表1、异常驾驶行为识别原则
[0102][0103]
综上所述,可以得到一次行车事件中11维指标项分别对应的车辆驾驶行为特征参数数据,也就是本次行车事件对应的指标组内存储的指标值,具体如下表2所示:
[0104]
表2、车辆驾驶行为特征参数数据
[0105][0106]
编号负加速度平负加速度标急加速次数急减速次数急刹车次数均值准差
[0107][0108]
203、采用因子分析对每个指标组进行降维处理,得到多个行车事件对应的待聚类数据,指标组包括多个维度指标。
[0109]
在本技术实施例中,系统需要对11位指标进行指标降维。在实际运行过程中,因子是在尽量不损失原有信息的基础上,若将相同本质的变量归入一个因子,实现指标降维,以简化分析过程。因此,本方法采用因子分析中的主成分分析法提取因子对指标组中的各个指标值进行降维。
[0110]
首先,采用kmo(kaiser-meyer-olkin)检验法和bartlett(bartlett's test ofsphericity)球形检验法对多个行车事件对应的多个指标组进行因子可行性验证。kmo(kaiser-meyer-olkin)检验法用于检验样本数据是否适用因子分析。bartlett球形检验法(bartlett's test of sphericity)用于检验指标间是否独立。检验结果如表3所示,表3中各变量kmo值为0.751(》0.7),表明各指标之间有较好的相关性。样本数据球形假设检验结果显著性水平为0.000,拒绝零假设,表明样本充足,可以对数据进行因子分析。
[0111]
表3、kmo和巴特利特检验结果
[0112][0113]
在验证通过后,对每个指标组进行因子分析,得到多个影响因子,在所述多个影响因子中提取三个主因子进行分析,得到因子载荷矩阵。具体地,采用累计方差贡献率来确定主成分数目,表4为因子分析中各成分解释原有指标总方差情况。
[0114]
表4各因子解释原有指标总方差情况
[0115]
[0116][0117]
碎石图也可用来确定最优主因子数目,横坐标表示因子数目,纵坐标表示特征值,因子特征值的连线陡峭部分,即为应取的主因子数目,特征值碎石图如图2b所示。由图2b可知,前3个主因子的特征值较大,连线较为陡峭。表4中前3个主因子特征值》1,其累计方差贡献率为73.468%,因子分析效果理想,因此,提取3个主因子进行分析。
[0118]
一般情况下,表5中的主成分载荷矩阵无法准确描述3种主因子的现实意义,故需要对3种主因子进行因子旋转。因子旋转的方法很多,本文采用凯撒正态化最大方差法。对所述因子载荷矩阵进行因子旋转,得到每个行车事件对应的旋转因子载荷矩阵,将多个旋转因子载荷矩阵作为多个样本数据进行聚合,得到所述待聚类数据。一次行车事件对应的样本数据如表6所示,表6为因子旋转后的3个主因子在各指标上的载荷,因子旋转后主因子rca1和加速度相关性较高,将其定义为急加减速指标。主因子rca2和速度标准差相关性较大,将其定义为驾驶员变速驾驶行为指标。主因子rca3和超速相关性较大,将其定义为驾驶员超速驾驶行为指标。
[0119]
表5、主成分载荷矩阵
[0120][0121]
[0122]
表6、旋转后的因子载荷矩阵
[0123][0124]
204、基于k-means算法,对待聚类数据进行聚类运算,得到目标车辆对应的驾驶员身份识别聚类结果。
[0125]
在本技术实施例中,采用k-means算法对待聚类数据进行聚类运算,如图2c所示,在待聚类数据中选取多个初始聚类中心,每个初始聚类中心对应一个初始类别组。对于待聚类数据中的每个样本数据,计算样本数据与每个聚类中心之间的样本距离。按照距离最小原则,对待聚类数据中的样本数据进行重新分类,更新每个初始聚类中心对应的初始类别组,得到对应的第一目标类别组。接下来,计算每个第一目标类别组的第一中心,采用第一中心更新对应的初始聚类中心,得到第一目标聚类中心。若每个第一目标聚类中心均与对应的初始聚类中心一致,则输出驾驶员身份识别聚类结果。若任意一个第一目标聚类中心与对应的初始聚类中心不一致,则重新计算待聚类数据中每个样本数据与每个第一目标聚类中心之间的样本距离,对样本数据进行重新分类,更新每个第一目标聚类中心对应的第一目标类别组,得到第二目标类别组。再计算每个第二目标类别组对应的第二中心,采用第二中心更新第一目标聚类中心,得到第二目标聚类中心,如果每个第二目标聚类中心均与对应的第一目标聚类中心一致,则输出驾驶员身份识别聚类结果。如果任意一个第一目标聚类中心与对应的初始聚类中心不一致,则再次计算第三目标聚类中心进行比对,直至新的目标聚类中心与老的目标聚类中心一致,停止聚类算法。
[0126]
综上所述,利用车载行驶数据对驾驶员身份识别研究,即是以驾驶员的行为特征为出发点,在车辆行驶过程中,驾驶员控制方向盘、踩油门等操作会产生大量的车辆传感器数据,利用工具进行数据采集,通过机器学习等技术对数据进行处理、分类、决策,最终达到识别车辆驾驶员身份的目的。本文通过主成分分析和k-means聚类算法结合的方式,对驾驶同一辆车的两名驾驶员进行分类,进而分析出一天中的每段行车事件都是对应哪一名驾驶员所驾驶。本文所用到的聚类方法为k-means算法其原理比较简单,实现也是很容易,收敛
速度快,聚类效果较优,算法的可解释度比较强。
[0127]
本技术实施例提供的方法,首先获取当前周期内产生的目标车辆的目标采样数据进行数据清洗,以目标车辆从发动到停止的过程为一次行车事件,得到当前周期内多个行车事件对应的行车数据。进一步地,对每个行车事件指示的行车数据进行计算,得到多个维度指标分别对应的指标值,将一次行车事件对应的多个指标值作为一个指标组,计算每个行车事件对应的指标组。接下来,采用因子分析技术对每个指标组进行降维处理,获取多个行车事件对应的待聚类数据。最后,基于k-means算法,对待聚类数据进行聚类运算,得到目标车辆对应的驾驶员身份识别聚类结果。本方法在对每天的行程划分为多次行车事件后,通过对车载数据进行预处理,利用主成分因子分析对高维数据降维,并利用k-means算法进行聚类,采用机器学习的方法对数据进行处理、分类、决策,识别出每一次行车事件是由哪名司机驾驶,最终实现提高车辆驾驶员身份识别的准确率。
[0128]
进一步地,作为图1所述方法的具体实现,本技术实施例提供了一种驾驶员识别装置,如图3所示,所述装置包括:获取模块301、计算模块302、聚类模块303。
[0129]
该获取模块301,用于获取目标车辆的目标采样数据进行数据清洗,得到多个行车事件对应的行车数据,所述行车事件用于指示所述目标车辆从发动到停止的过程;
[0130]
该计算模块302,用于对每个行车事件指示的行车数据进行计算,得到每个所述行车事件对应的指标组,以及采用因子分析对每个指标组进行降维处理,得到所述多个行车事件对应的待聚类数据,所述指标组包括多个维度指标;
[0131]
该聚类模块303,用于基于k-means算法,对所述待聚类数据进行聚类运算,得到所述目标车辆对应的驾驶员身份识别聚类结果。
[0132]
在具体的应用场景中,该获取模块301,用于统计前一次获取目标采样数据的历史时间点;确定当前时间点,在当前时间点与所述历史时间点之间的时间间隔等于预设的识别周期时,在数据库中读取当前周期内存储的多个采样数据集作为所述目标采样数据,所述采样数据集为一次行车事件内产生的行车数据;按照时间从前到后的顺序对所述多个采样数据集进行排序;基于自然语言处理技术,对每个采样数据集进行数据识别;若采样数据集中存在第一指定数据值缺失,则确定所述第一指定数据值对应的指定采样项,基于所述指定采样项对所述第一指定数据值进行补充;和/或,若所述采样数据集中同一采样项存在两个重复值,则删除其中之一。
[0133]
在具体的应用场景中,该获取模块301,用于遍历所述采样数据集中所述指定采样项对应的全部数据值,在所述全部数据值中读取所述第一指定数据值前后的第二指定数据值和第三指定数据值;计算所述第二指定数据值和所述第三指定数据值的均值,采用所述均值补充所述第一指定数据值。
[0134]
在具体的应用场景中,该计算模块302,用于对于每个行车事件,按照所述指标组中每个维度指标对应的计算规则,对所述行车事件指示的行车数据进行计算,得到所述多个指标值,聚合所述多个指标值,得到所述指标组,所述维度指标包括超速占比、车速平均值、车速标准差、加速度标准差、正加速度平均值、正加速度标准差、负加速度平均值、负加速度标准差、急加速次数、急减速次数、急刹车次数;其中,每个行车事件中的急加速次数、急减速次数和急刹车次数是通过计算当前行车事件对应的加速度和加速度持续时间,分别将所述加速度和所述加速度持续时间与加速度阈值和时间阈值进行比对,根据比对结果确
定的。
[0135]
在具体的应用场景中,该计算模块302,用于采用kmo检验法和bartlett球形检验法对多个行车事件对应的多个指标组进行因子可行性验证;在验证通过后,对每个指标组进行因子分析,得到多个影响因子,在所述多个影响因子中提取三个主因子进行分析,得到因子载荷矩阵;采用凯撒正态化最大方差法,对所述因子载荷矩阵进行因子旋转,得到每个行车事件对应的旋转因子载荷矩阵,将多个旋转因子载荷矩阵作为多个样本数据进行聚合,得到所述待聚类数据。
[0136]
在具体的应用场景中,该聚类模块303,用于在所述待聚类数据中选取多个初始聚类中心,每个所述初始聚类中心对应一个初始类别组;对于所述待聚类数据中的每个样本数据,计算所述样本数据与每个聚类中心之间的样本距离;按照距离最小原则,对所述待聚类数据中的样本数据进行重新分类,更新每个所述初始聚类中心对应的初始类别组,得到对应的第一目标类别组;计算每个第一目标类别组的第一中心,采用所述第一中心更新对应的初始聚类中心,得到第一目标聚类中心;更新多个所述初始聚类中心,得到多个第一目标聚类中心;若每个第一目标聚类中心均与对应的初始聚类中心一致,则输出所述驾驶员身份识别聚类结果。
[0137]
在具体的应用场景中,该聚类模块303,还用于若任意一个第一目标聚类中心与对应的初始聚类中心不一致,则重新计算所述待聚类数据中每个样本数据与每个第一目标聚类中心之间的样本距离;按照距离最小原则,重新对所述待聚类数据中的样本数据进行分类,更新每个所述第一目标聚类中心对应的第一目标类别组,得到第二目标类别组;计算每个第二目标类别组对应的第二中心,采用所述第二中心更新所述第一目标聚类中心,得到第二目标聚类中心;更新多个所述第一目标聚类中心,得到多个第二目标聚类中心;如果每个第二目标聚类中心均与对应的第一目标聚类中心一致,则输出所述驾驶员身份识别聚类结果;如果任意一个第一目标聚类中心与对应的初始聚类中心不一致,则重新计算所述待聚类数据中每个样本数据与每个第二目标聚类中心之间的样本距离,直至计算出的第三目标聚类中心均与对应的第二目标聚类中心一致,输出所述驾驶员身份识别聚类结果。
[0138]
本技术实施例提供的装置,首先获取当前周期内产生的目标车辆的目标采样数据进行数据清洗,以目标车辆从发动到停止的过程为一次行车事件,得到当前周期内多个行车事件对应的行车数据。进一步地,对每个行车事件指示的行车数据进行计算,得到多个维度指标分别对应的指标值,将一次行车事件对应的多个指标值作为一个指标组,计算每个行车事件对应的指标组。接下来,采用因子分析技术对每个指标组进行降维处理,获取多个行车事件对应的待聚类数据。最后,基于k-means算法,对待聚类数据进行聚类运算,得到目标车辆对应的驾驶员身份识别聚类结果。本方法在对每天的行程划分为多次行车事件后,通过对车载数据进行预处理,利用主成分因子分析对高维数据降维,并利用k-means算法进行聚类,采用机器学习的方法对数据进行处理、分类、决策,识别出每一次行车事件是由哪名司机驾驶,最终实现提高车辆驾驶员身份识别的准确率。
[0139]
需要说明的是,本技术实施例提供的一种驾驶员识别装置所涉及各功能单元的其他相应描述,可以参考图1和图2a至图2c中的对应描述,在此不再赘述。
[0140]
在示例性实施例中,参见图4,还提供了一种设备,该设备包括通信总线、处理器、存储器和通信接口,还可以包括输入输出接口和显示设备,其中,各个功能单元之间可以通
过总线完成相互间的通信。该存储器存储有计算机程序,处理器,用于执行存储器上所存放的程序,执行上述实施例中的驾驶员识别方法。
[0141]
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现所述的驾驶员识别方法的步骤。
[0142]
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到本技术可以通过硬件实现,也可以借助软件加必要的通用硬件平台的方式来实现。基于这样的理解,本技术的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是cd-rom,u盘,移动硬盘等)中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本技术各个实施场景所述的方法。
[0143]
本领域技术人员可以理解附图只是一个优选实施场景的示意图,附图中的模块或流程并不一定是实施本技术所必须的。
[0144]
本领域技术人员可以理解实施场景中的装置中的模块可以按照实施场景描述进行分布于实施场景的装置中,也可以进行相应变化位于不同于本实施场景的一个或多个装置中。上述实施场景的模块可以合并为一个模块,也可以进一步拆分成多个子模块。
[0145]
上述本技术序号仅仅为了描述,不代表实施场景的优劣。
[0146]
以上公开的仅为本技术的几个具体实施场景,但是,本技术并非局限于此,任何本领域的技术人员能思之的变化都应落入本技术的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。