1.本技术涉及文本结构化技术领域,尤其涉及一种文本段落识别方法、装置、设备及存储介质。
背景技术:
2.在文本结构化技术领域,往往需要对文本的段落进行提取,并依据段落中的文本内容提取文本的各元数据,进而可以按照期刊论文标签集(journal publishing tag set,简称jats)的指定格式对文本进行相应处理。可见,文本的段落识别是后续一系列工作的基础。
3.常规的文本段落识别方法多依赖诸如一些表征文本类型的前缀特征进行,例如,对于基金文本而言,诸如“基金项目:、项目来源:、课题来源:、fund programs:、foundings:、foundation item:”等这些文本内容则可以被则为表征文本类型的前缀特征。换言之,基金文本中出现上述这些前缀特征时,这些前缀特征则可以将基金文本进行段落划分,从而识别出基金文本的段落。
4.然而,当基金文本中不存在前缀特征时,可能需要依据基金文本中所包含的一些预设的关键词进行段落识别。这种识别方式虽直观简单,但识别结果准确度较低,存在较大的误识别风险,并且对于大批量的识别而言,识别任务繁重,从而无法满足文本结构化批量处理需求。
技术实现要素:
5.本技术提供一种文本段落识别方法、装置、设备及存储介质,用于针对无前缀特征的基金论文提供一种段落识别方法,避免误识别风险,识别结果准确度较高。
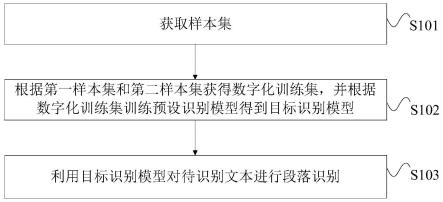
6.第一方面,本技术提供一种文本段落识别方法,包括:
7.获取样本集,所述样本集包括第一样本集和第二样本集,所述第一样本集和所述第二样本集分别包括目标文本类型和非目标文本类型的各文本段落;
8.根据所述第一样本集和所述第二样本集获得数字化训练集,并根据所述数字化训练集训练预设识别模型得到目标识别模型;
9.利用所述目标识别模型对待识别文本进行段落识别,所述待识别文本为不包括前缀特征的目标文本,所述前缀特征用于表征所述目标文本的文本类型为所述目标文本类型。
10.在一种可能的设计中,所述根据所述第一样本集和所述第二样本集获得数字化训练集,包括:
11.分别对所述第一样本集和所述第二样本集的各文本段落进行预处理,并对得到的所述预处理的结果数据进行分词处理;
12.根据预设划分规则将所述分词处理得到的各结果数据中的各词汇划分为词汇组别,形成段落识别特征集;
13.根据所述段落识别特征集获取所述预处理的结果数据所对应的第一特征序列,以根据各第一特征序列形成所述数字化训练集。
14.在一种可能的设计中,所述分别对所述第一样本集和所述第二样本集的各文本段落进行预处理,包括:
15.滤除所述各文本段落中与预设元数据无关的内容以及删除预设连字符,以将经过滤除操作和删除操作后的各文本段落确定为所述预处理的结果数据。
16.在一种可能的设计中,所述对得到的所述预处理的结果数据进行分词处理,包括:
17.通过预设分词模型分别对各第一结果数据和各第二结果数据进行分词处理,以得到对应的各第三结果数据和各第四结果数据;
18.其中,所述预处理的结果数据包括所述各第一结果数据和所述各第二结果数据,所述分词处理得到的各结果数据包括所述各第三结果数据和所述各第四结果数据。
19.在一种可能的设计中,所述根据所述段落识别特征集获取所述预处理的结果数据所对应的第一特征序列,以根据各第一特征序列形成所述数字化训练集,包括:
20.根据所述段落识别特征集获取所述各第一结果数据和所述各第二结果数据各自所包括的所述词汇组别中的词汇的数量,以得到所述各第一结果数据和所述各第二结果数据各自对应的第一特征序列;
21.将所述各第一特征序列确定为所述数字化训练集的各子集,以得到所述数字化训练集。
22.在一种可能的设计中,在所述得到对应的各第三结果数据和各第四结果数据之后,还包括:
23.统计所述各第三结果数据和所述各第四结果数据中各词汇的出现频次,以得到所述各第三结果数据和所述各第四结果数据与各频次之间的映射关系;
24.根据所述映射关系生成所述预设划分规则。
25.在一种可能的设计中,还包括:
26.利用所述目标识别模型对验证样本集中的各验证样本进行段落识别,并确定识别结果是否正确;
27.若否,根据所述识别结果调整所述段落识别特征集中的各词汇组别;
28.根据调整后的所述段落识别特征集获取所述预处理的结果数据所对应的第二特征序列,并根据各第二特征序列形成优化训练集;
29.根据所述优化训练集优化所述目标识别模型,直到预测结果符合预设阈值范围,所述预测结果用于表征优化后的所述目标识别模型的识别结果为正确结果和非正确结果的概率。
30.第二方面,本技术提供一种文本段落识别装置,包括:
31.采样模块,用于获取样本集,所述样本集包括第一样本集和第二样本集,所述第一样本集和所述第二样本集分别包括目标文本类型和非目标文本类型的各文本段落;
32.处理模块,用于根据所述第一样本集和所述第二样本集获得数字化训练集,并根据所述数字化训练集训练预设识别模型得到目标识别模型;
33.识别模块,用于利用所述目标识别模型对待识别文本进行段落识别,所述待识别文本为不包括前缀特征的目标文本,所述前缀特征用于表征所述目标文本的文本类型为所
述目标文本类型。
34.在一种可能的设计中,所述处理模块,包括:
35.第一处理子模块,用于分别对所述第一样本集和所述第二样本集的各文本段落进行预处理,并对得到的所述预处理的结果数据进行分词处理;
36.第二处理子模块,用于根据预设划分规则将所述分词处理得到的各结果数据中的各词汇划分为词汇组别,形成段落识别特征集;
37.第三处理子模块,用于根据所述段落识别特征集获取所述预处理的结果数据所对应的第一特征序列,以根据各第一特征序列形成所述数字化训练集。
38.在一种可能的设计中,所述第一处理子模块,具体用于:
39.滤除所述各文本段落中与预设元数据无关的内容以及删除预设连字符,以将经过滤除操作和删除操作后的各文本段落确定为所述预处理的结果数据。
40.在一种可能的设计中,所述第一处理子模块,还具体用于:
41.通过预设分词模型分别对各第一结果数据和各第二结果数据进行分词处理,以得到对应的各第三结果数据和各第四结果数据;
42.其中,所述预处理的结果数据包括所述各第一结果数据和所述各第二结果数据,所述分词处理得到的各结果数据包括所述各第三结果数据和所述各第四结果数据。
43.在一种可能的设计中,所述第三处理子模块,具体用于:
44.根据所述段落识别特征集获取所述各第一结果数据和所述各第二结果数据各自所包括的所述词汇组别中的词汇的数量,以得到所述各第一结果数据和所述各第二结果数据各自对应的第一特征序列;
45.将所述各第一特征序列确定为所述数字化训练集的各子集,以得到所述数字化训练集。
46.在一种可能的设计中,所述文本段落识别装置,还包括:统计与生成模块;所述统计与生成模块,用于:
47.统计所述各第三结果数据和所述各第四结果数据中各词汇的出现频次,以得到所述各第三结果数据和所述各第四结果数据与各频次之间的映射关系;
48.根据所述映射关系生成所述预设划分规则。
49.在一种可能的设计中,所述文本段落识别装置,还包括:验证与优化模块;所述验证与优化模块,具体用于:
50.利用所述目标识别模型对验证样本集中的各验证样本进行段落识别,并确定识别结果是否正确;
51.若否,根据所述识别结果调整所述段落识别特征集中的各词汇组别;
52.根据调整后的所述段落识别特征集获取所述预处理的结果数据所对应的第二特征序列,并根据各第二特征序列形成优化训练集;
53.根据所述优化训练集优化所述目标识别模型,直到预测结果符合预设阈值范围,所述预测结果用于表征优化后的所述目标识别模型的识别结果为正确结果和非正确结果的概率。
54.第三方面,本技术提供一种电子设备,包括:
55.处理器;以及,
56.存储器,用于存储所述处理器的计算机程序;
57.其中,所述处理器配置为经由执行所述计算机程序来执行第一方面所提供的任意一种可能的文本段落识别方法。
58.第四方面,本技术提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现第一方面所提供的任意一种可能的文本段落识别方法。
59.第五方面,本技术还提供一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现第一方面所提供的任意一种可能的文本段落识别方法。
60.本技术提供一种文本段落识别方法、装置、设备及存储介质。首先获取样本集,其中,样本集包括第一样本集和第二样本集,第一样本集和第二样本集包括目标文本类型和非目标文本类型两种不同文本类型的各文本段落。然后根据第一样本集和第二样本集获得数字化训练集,并根据数字化训练集训练预设识别模型得到目标识别模型。最后利用目标识别模型对待识别文本进行段落识别,待识别文本为不包括前缀特征的目标文本,而前缀特征用于表征目标文本的文本类型。从而为无前缀特征的文本提供了一种文本段落识别的方法,避免误识别风险,并具备较高的识别准确度,满足文本结构化处理需求。
附图说明
61.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
62.图1为本技术实施例提供的一种应用场景示意图;
63.图2为本技术实施例提供的一种文本段落识别方法的流程示意图;
64.图3为本技术实施例提供的另一种文本段落识别方法的流程示意图;
65.图4为本技术实施例提供的再一种文本段落识别方法的流程示意图;
66.图5为本技术实施例提供的又一种文本段落识别方法的流程示意图;
67.图6为本技术实施例提供的一种文本段落识别装置的结构示意图;
68.图7为本技术实施例提供的一种处理模块的结构示意图;
69.图8为本技术提供的一种电子设备的结构示意图。
具体实施方式
70.这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本技术相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本技术的一些方面相一致的方法和装置的例子。
71.本技术的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本技术的实施例例如能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产
品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
72.常规的文本段落识别方法多依赖诸如一些表征文本类型的前缀特征进行,例如,对于基金文本而言,诸如“基金项目:、项目来源:、课题来源:、fund programs:、foundings:、foundation item:”等这些文本内容则可以被则为表征文本类型的前缀特征。换言之,基金文本中出现上述这些前缀特征时,这些前缀特征则可以将基金文本进行段落划分,从而识别出基金文本的段落。而当基金文本中不存在前缀特征时,可能需要依据基金文本中所包含的一些预设的关键词进行段落识别。这种识别方式虽直观简单,但识别结果准确度较低,存在较大的误识别风险,并且对于大批量的识别而言,识别任务繁重,从而无法满足文本结构化批量处理需求。
73.针对现有技术中存在的上述问题,本技术提供一种文本段落识别方法、装置、设备及存储介质。本技术提供的文本段落识别方法的发明构思在于:针对无前缀特征的基金文本,首先获取样本集,该样本集中包括不同文本类型的各文本段落,例如目标文本类型和非目标文本类型的各文本段落。然后基于这些文本段落获得数字化训练集,进而根据数字化训练集训练预设识别模型得到目标识别模型,再利用目标识别模型对待识别文本进行段落识别。从而为无前缀特征的且文本类型为目标文本类型的待识别文本提供了一种段落识别方法,不但可以避免现有技术中对于无前缀特征的这一种类文本的段落误识别,利用模型进行段落识别,有效提升了识别准确率,并且,利用目标识别模型可以进行批量段落识别,满足文本结构化批量处理需求。
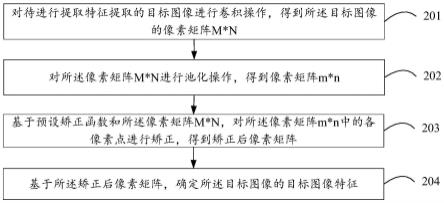
74.以下,对本技术实施例的示例性应用场景进行介绍。
75.图1为本技术实施例提供的一种应用场景示意图,如图1所示,在终端设备11上运行有可以存储待识别文本的相应数据库,电子设备12中的处理器被配置为可以执行本技术实施例提供的文本段落识别方法,通过获取样本集并基于样本集获得数字化训练集,进而根据数字化训练集将预设识别模型训练为目标识别模型,最后则可以利用目标识别模型对终端设备11中存储的各待识别文本进行段落识别。
76.其中,终端设备11可以为计算机、笔记本电脑、服务器、服务器集群等能够运行相应数据库的任意终端,对于终端设备11的类型本实施例不作限定,图1中的终端设备11以计算机为例示出。电子设备12可以为计算机、服务器、服务器集群等可以通过执行相应计算机程序来实现本技术实施例提供的文本段落识别方法的相应设备,对此,本实施不作限定,图1中的电子设备12以计算机为例示出。
77.可以理解的是,终端设备11和终端设备12之间可以通过网络通信连接,通信连接可以为有线、无线等方式。
78.需要说明的是,上述应用场景仅仅是示意性的,本技术实施例提供的文本段落识别方法、装置、设备及存储介质包括但不仅限于上述应用场景。
79.图2为本技术实施例提供的一种文本段落识别方法的流程示意图。如图2所示,本实施例提供的文本段落识别方法,包括:
80.s101:获取样本集。
81.其中,样本集包括第一样本集和第二样本集,第一样本集和第二样本集分别包括目标文本类型和非目标文本类型的各文本段落。
82.获取实际工况中的一些文本段落形成样本集,例如收集文本类型分别为目标文本类型和非目标文本类型的多个文本段落,这些文本段落形成样本集。
83.其中,在本实施例中,将文本类型为目标文本类型的文本定义为基金文本。基金文本的文本段落可以譬如“本文系国家自然科学基金青年科学基金项目“基于深度语义表示和多文档摘要的学术文献自动综述研究”(项目编号:71904058)和中央高校基本科研业务费资助项目“基于动态引文网络的人工智能算法演化路径研究”(项目编号:kj02072020-0200)的研究成果之一”这样的文本。相应地,不是目标文本类型的文本类型即为非目标文本类型,一非目标文本类型的文本段落可以譬如“本项研究受到张三院士主持的“沉积学战略研讨”项目的支持,部分内容在“中国沉积学发展战略国际研讨会”(香山科学会议第571次学术讨论会,北京,2016年9月25—28日)进行了交流。谨此致谢”等。可以理解的是,本实施例中对于目标文本类型和非目标文本类型的各文本段落所要表达的文字内容不作限定。
84.另外,将目标文本类型的每个文本段落作为子集,该各子集形成的集合即为第一样本集。同理,将非目标文本类型的每个文本段落的作为子集,该各子集形成的集合即为第二样本集。
85.s102:根据第一样本集和第二样本集获得数字化训练集,并根据数字化训练集训练预设识别模型得到目标识别模型。
86.获取到样本集之后,进一步根据样本集获得数字化训练集,以利用数字化训练集训练预设识别模型得到目标识别模型。其中,预设识别模型可以为支持向量机(support vector machine,简称svm)模型。将数字训练集中的各子集作为预设识别模型的训练样本,训练后的预设识别模型即为目标识别模型,通过目标识别模型对待识别文本进行段落识别。
87.在一种可能的设计中,本步骤s102可能的实现方式如图3所示。图3为本技术实施例提供的另一种文本段落识别方法的流程示意图。如图3所示,本实施例包括:
88.s1021:分别对第一样本集和第二样本集的各文本段落进行预处理,并对得到的预处理的结果数据进行分词处理。
89.分别对第一样本集和第二样本集各自包括的各文本段落进行预处理,得到各自对应的预处理的结果数据,进而对预处理的结果数据进行分词处理。
90.可选地,分别对第一样本集和第二样本集各自包括的各文本段落进行预处理的可能实现方式可以为:
91.滤除第一样本集和第二样本集各自包括的各文本段落中与预设元数据无关的内容以及删除预设连字符,将经过滤除操作和删除操作后的各文本段落确定为预处理的结果数据。
92.其中,对于基金文本而言,预设元数据可以为基金文本的描述内容或者基金文本的名称或者基金文本的基金编号等。对于非目标类型的文本段落而言,预设元数据可以为描述该文本段落的描述内容、该文本段落中的姓名或者文本段落中的数字编号等。
93.滤除与预设元数据无关的内容可以至少包括以下一种具体的操作方式:
94.(1)、去除文本段落中引号、书名号中的内容;
95.(2)、去除“题目/子题目”等内容;
96.(3)、去除“封一/后插1/负责人”等内容。
97.进一步地,还删除预设连字符。其中,预设连字符可以为文本段落中的小括号、中括号、连词符、斜杠、反斜杠、空格等影响分词处理的各种符号,对此,本实施例不作限定。删除预设连字符即为将被定义的预设连字符进行删除操作。
98.从而,将经过上述滤除操作和删除操作之后的各文本段落确定为预处理的结果数据,完成对第一样本集和第二样本集中包括的各文本段落的预处理。
99.进一步地,对所得到的预处理的结果数据进行分词处理。
100.可选地,分词处理的可能实现方式可以通过运行预设分词模型得以实现。预设分词模型可以为任意进行词汇分割的分词软件,本实施例对于分词软件的具体情况不作限定。
101.具体地,例如将第一样本集包括的各样本段落所对应的预处理的结果数据定义为各第一结果数据,则每个第一结果数据即为对第一样本集中每个样本段落进行预处理后得到的结果数据。相应地,将第二样本集包括的各样本段落所对应的预处理的结果数据定义为各第二结果数据,则每个第二结果数据即为对第二样本集中每个样本段落进行预处理后得到的结果数据。换言之,预处理的结果数据包括各第一结果数据和各第二结果数据。因而,则可以通过预设分词模型分别对各第一结果数据和各第二结果数据进行分词处理,并将各第一结果数据经过分词处理后得到的各结果数据确定为各第三结果数据,而将各第二结果数据经过分词处理后得到的各结果数据确定为各第四结果数据。换言之,经过预设分词模型的分词处理后得到的各结果数据包括各第三结果数据和各第四结果数据。
102.s1022:根据预设划分规则将分词处理得到的各结果数据中的各词汇划分为词汇组别,形成段落识别特征集。
103.经过分词处理得到的各结果数据,也即各第三结果数据和各第四结果数据,依据预设划分规则将各第三结果数据和各第四结果数据中的各词汇进行分组划分,得到多个词汇组别,将各词汇组别形成的集合确定为段落识别特征集。
104.多个词汇组别可以例如如下双引号内的各词汇,其中,每个双引号内的词汇形成一组词汇组别。若将一组词汇组别看作一个子集,则所有组的词汇组别形成的集合为段落识别特征集。
105.例如,由各第三结果数据中的各词汇划分得到的词汇组别可以为“(基金|专项|资助|资金|业务费|经费|计划|课题)”、“(工程|支持|支撑|项目|规划)”、“(科技|科研|科学|技术|应用|创新|研究|研发|开发)”、“(国家|中央|中国)”、“[a-z\d]{7,}”、“(编号|项目号|id)”、(高校|实验室|大学|教育厅|教育部|学校|中心|研究院|学院|公司|工信部)等。
[0106]
例如,由各第四结果数据中的各词汇划分得到的词汇组别可以为“(规定|制定|简介|实验报告|目的|通讯|教授|讲师|结论|要义|意义|测重|效果|结果|影响|出版社|研讨会|会议|邮编|电话|杂志社|生产线|上述|我们|他们)”、“(为了|作为|从中|针对|按照|对于|为例|依据|根据|通过)”、“1[3-9]{1,1}\d{9,9}”等。
[0107]
需要说明的是,各第三结果数据和各第四结果数据中的各词汇不限于文字,还可以为数字,例如编号、手机号码等。
[0108]
通过上述描述可知,对分词处理得到的各结果数据中的各词汇划分为多个词汇组别,其中多个词汇组别的数量假设以n表示,n的取值为大于0的自然数。当n的取值越大,段落识别特征集中子集的数目越多,进而通过训练得到的目标识别模型越精确、识别时间越
长。而若n的取值过大,则易造成目标识别模型的过拟合,影响识别效果。因而,在对各词汇划分为词汇组别时,需依据预设划分规则进行。
[0109]
在一种可能的设计中,在通过预设分词模型进行分词处理,得到各第三结果数据和各第四结果数据之后,还包括如图4所示确定预设划分规则的步骤。图4为本技术实施例提供的再一种文本段落识别方法的流程示意图。如图4所示,本实施例包括:
[0110]
s201:统计各第三结果数据和各第四结果数据中各词汇的出现频次,以得到各第三结果数据和各第四结果数据与各频次之间的映射关系。
[0111]
s202:根据映射关系生成预设划分规则。
[0112]
预设分词模型进行分词处理之后得到的各第三结果数据和各第四结果数据中,会将各第三结果数据和各第四结果数据的中各词汇以及每个词汇的词性均进行确定。因而,可以进一步统计各第三结果数据和各第四结果数据中每个词汇出现的频次,从而得到词汇与该词汇的词性以及对应出现的频次之间的对应关系,换言之通过统计各词汇的出现频次,得到各第三结果数据与各第四结果数据与其中词汇出现的各频次之间相对应的映射关系,从而根据该映射关系生成预设划分规则。
[0113]
其中,在根据映射关系生成预设划分规则时,可以依据各词汇在各第三结果数据或者各第四结果数据中出现的频次以及该词汇的词性生成预设划分规则。例如,当一词汇在各第三结果数据中出现的频次较高,则可以将该词汇以及与该词汇的词性及词义相近的词汇确定为各第三结果数据对应的预设划分规则,比如在基本文本中大概率出现的词汇。相应地,当一词汇在各第四结果数据中出现的频次较高,则可以将该词汇以及与该词汇的词性及词义相近的词汇确定为各第四结果数据对应的预设划分规则,比如在基本文本中大概率不会出现的词汇。
[0114]
在通过上述步骤将分词处理得到的各结果数据中的各词汇划分为词汇组别,形成段落识别特征集之后,则进一步执行步骤s1023。
[0115]
s1023:根据段落识别特征集获取预处理的结果数据所对应的第一特征序列,以根据各第一特征序列形成数字化训练集。
[0116]
在得到段落识别特征集之后,根据段落识别特征集获取预处理的结果数据,即获取各第一结果数据和各第二结果数据所分别对应的第一特征序列,进而根据各第一特征序列形成数字化训练集。
[0117]
例如,根据段落识别特征集首先获取各第一结果数据和各第二结果数据各自所包括的词汇组别中的词汇的数量,将所获取的数量确定为相对应的各第一结果数据和各第二结果数据各自对应的第一特征序列。然后将得到的各第一特征序列确定为数字化训练集的各子集,从而形成数字化训练集。
[0118]
可以理解的是,在本实施例中,根据各第三结果数据进行词汇组别的划分得到各第三结果数据对应的段落识别特征集,相应地,根据该段落识别特征集获取各第一结果数据中所包括的词汇组别中词汇的数量。例如,各第三结果数据中的各词汇划分得到的词汇组别如“(基金|专项|资助|资金|业务费|经费|计划|课题)”、“(工程|支持|支撑|项目|规划)”、“(科技|科研|科学|技术|应用|创新|研究|研发|开发)”、“(国家|中央|中国)”、“[a-z\d]{7,}”、“(编号|项目号|id)”、(高校|实验室|大学|教育厅|教育部|学校|中心|研究院|学院|公司|工信部)这七组,即n的取值为7。假设第一结果数据为“本文系国家自然科学基
金青年科学基金项目(项目编号:71904058)和中央高校基本科研业务费资助项目(项目编号:kj02072020x0200)的研究成果之一”,则该第一结果数据中包含有第一组别“(基金|专项|资助|资金|业务费|经费|计划|课题)”中的词汇分别有“基金、基金、业务费、资助”,词汇的数量为4,若第一组别用0表示,则可以用“0:4”表示第一结果数据中包含的第一词汇组别中词汇的数量为4。相类似地,第二组别“(工程|支持|支撑|项目|规划)”若用1表示,则该第一结果数据中包含有第二组别中的词汇分别有“项目、项目、项目、项目”,词汇的数量为4,则“1:4”表示第一结果数据中包含的第二词汇组别中词汇的数量为4。以此类推,可以得到该第一结果数据中包含有的第三组别、第四组别、第五组别及第六组别中词汇的数量依次为4、2、2、1,因而,依据上述的表示规则,则可以将该第一结果数据中包含的每个词汇组别中词汇的数量分别依次表示为“0:4 1:4 2:4 3:2 4:2 5:2 6:1”这一数字序列,将该数字序列即定义为该第一结果数据所对应的第一特征序列。
[0119]
依据上述实施例的描述可以得到每个第一结果数据和每个第二结果数据各自对应的第一特征序列。再将每个第一特征序列看作一子集,所有第一特征序列形成的集合即被确定为数字化训练集。也即将各第一特征序列确定为数字化训练集的各子集,从而得到数字化训练集。
[0120]
得到数字化训练集之后,将数字化训练集中的各第一特征序列作为训练样本,以对预设识别模型进行训练得到目标识别模型。其中,对于各第一特征数据序列而言,各第一结果数据对应的各第一特征序列为基金文本的训练样本,也可以看作正样本。相应地,各第二结果数据对应的各第一特征序列为不是基金文本的训练样本,可看作负样本。
[0121]
s103:利用目标识别模型对待识别文本进行段落识别。
[0122]
其中,待识别文本为不包括前缀特征的目标文本,前缀特征用于表征目标文本的文本类型为目标文本类型。
[0123]
训练得到目标识别模型之后,则可以利用目标识别模型对待识别文本进行段落识别。待识别文本为没有前缀特征的目标文本,目标文本为基金文本。从而通过目标识别模型对不包括前缀特征的基金文本进行批量的段落识别。
[0124]
本技术实施例提供的文本段落识别方法,首先获取样本集,其中,样本集包括第一样本集和第二样本集,第一样本集和第二样本集包括目标文本类型和非目标文本类型的各文本段落,然后根据第一样本集和第二样本集获得数字化训练集,并根据数字化训练集训练预设识别模型得到目标识别模型。最后利用目标识别模型对待识别文本进行段落识别,待识别文本为不包括前缀特征的目标文本,而前缀特征用于表征目标文本的文本类型。从而为无前缀特征的文本提供了一种文本段落识别的方法,避免误识别风险,并具备较高的识别准确度,满足文本结构化处理需求。
[0125]
在上述实施例的基础上,可选地,图5为本技术实施例提供的又一种文本段落识别方法的流程示意图,本实施例提供了一种对目标识别模型验证及优化的可能实现方式。如图5所示,本实施例包括:
[0126]
s301:利用目标识别模型对验证样本集中的各验证样本进行段落识别,并确定识别结果是否正确。
[0127]
收集大量验证样本形成验证样本集,利用目标识别模型对各验证样本进行段落识别,并确定得到的识别结果是否正确。其中,验证样本包括多个无前缀特征的基金文本段落
或者多个非基金文本段落。
[0128]
s302:若否,根据识别结果调整段落识别特征集中的各词汇组别。
[0129]
若确定识别结果不正确,则需要根据识别结果调整确定目标识别模型所用的段落识别特征集中的各词汇组别中的各词汇。
[0130]
例如,目标识别模型本该为基金文本的验证样本识别为非基金文本,或者将本该为非基金文本的验证样本识别为基金文本,则都表明识别结果不正确。因而需根据识别结果对确定目标识别模型所用的段落识别特征集中各词汇组别中的各词汇进行调整。比如,当将基金文本的验证样本误识别为非基金文本时,则需确定段落识别特征集中的各词汇组别中的各词汇是否未收集到可以表征基金文本特征的相应词汇,以对各词汇组别中的各词汇进行补充。而当将非基金文本的验证样本误识别为基金文本时,则可以获取一些例如特殊符号、电话号码、连词、介词等属于非基金文本的相应符号补充至各词汇组别的词汇中,以对非基金文本的相应特征进行补充。通过上述的补充实现对段落识别特征集中的各词汇组别的调整。
[0131]
通常,对于段落识别特征集中的各词汇组别的调整可以直到使用优化后的目标识别模型得到的预测结果符合预设阈值范围为止。反之,若确定识别结果正确,则可以继续使用目标识别模型对待识别文本进行段落识别。
[0132]
s303:根据调整后的段落识别特征集获取预处理的结果数据所对应的第二特征序列,并根据各第二特征序列形成优化训练集。
[0133]
在对段落识别特征集中的各词汇组别进行调整,以重新获得段落识别特征集之后,使用该调整后的段落识别特征集获取预处理的结果数据所对应的第二特征序列,将获得的各第二特征序列作为子集,以根据各第二特征序列形成优化训练集。
[0134]
其中,本步骤的实现方式与前述步骤s1023的实现方式相类似,在此不再赘述。
[0135]
s304:根据优化训练集优化目标识别模型,直到预测结果符合预设阈值范围。
[0136]
其中,预测结果用于表征优化后的目标识别模型的识别结果为正确结果的概率。
[0137]
将优化训练集中的各第二特征序列作为目标识别模型的训练样本,继续对目标识别模型进行训练,以达到对目标识别模型优化的目的。其中,训练过程中,直到预测结果符合预设阈值范围,则停止优化过程。
[0138]
预测结果用于表征使用优化后的目标识别模型进行段落识别时,所得到的识别结果为正确结果和非正确结果的概率。下述表1和表2分别列举了优化的正样本和优化的负样本的预测结果:
[0139]
表1
[0140]
优化的正样本正确结果的概率非正确结果的概率 10.9731099546898440.0268900453101559 10.9251582465411710.0748417534588287 10.9491765137356740.0508234862643258 10.9987101490314250.0012898509685747 10.9731584428044050.026841557195595 10.9987101490314250.0012898509685747 10.9492121104838840.0507878895161161
10.9906654458407430.00933455415925666 10.9566703453290940.043329654670906
[0141]
表2
[0142]
优化的负样本非正确结果的概率正确结果的概率-10.001921560473953040.998078439526047-11e-070.9999999-10.001274809747028710.998725190252971-10.230481846188870.76951815381113-10.1889623458232490.811037654176751-10.001769271086426510.998230728913573-10.2770191455334320.722980854466568-11e-070.9999999-10.2304522535400890.769547746459911
[0143]
通过表1和表2可知,识别结果为正确结果的数值越大,对于目标识别模型的优化越满意,进而采用优化后的目标识别模型进行段落识别的精确度越高。
[0144]
本技术实施例提供的文本段落识别方法,利用目标识别模型对验证样本集中的各验证样本进行段落识别,并确定识别结果是否正确,若不正确,则进一步根据识别结果调整段落识别特征集中的各词汇组别中的各词汇,以对目标识别模型进行进一步优化,提高目标识别模型的段落识别准确度。本技术实施例提供的文本段落识别方法,不仅为无前缀特征的文本提供了一种文本段落识别的方法,避免误识别风险,还具备较高的识别准确度,满足文本结构化处理需求。并且还易于优化和后期维护,可以在文本结构化技术领域广泛应用。
[0145]
下述为本技术装置实施例,可以用于执行本技术对应的方法实施例。对于本技术装置实施例中未披露的细节,请参照本技术对应的方法实施例。
[0146]
图6为本技术实施例提供的一种文本段落识别装置的结构示意图。如图6所示,本实施例提供的文本段落识别装置400,包括:
[0147]
采样模块401,用于获取样本集。
[0148]
其中,样本集包括第一样本集和第二样本集,第一样本集和第二样本集分别包括目标文本类型和非目标文本类型的各文本段落。
[0149]
处理模块402,用于根据第一样本集和第二样本集获得数字化训练集,并根据数字化训练集训练预设识别模型得到目标识别模型。
[0150]
识别模块403,用于利用目标识别模型对待识别文本进行段落识别。
[0151]
其中,待识别文本为不包括前缀特征的目标文本,前缀特征用于表征目标文本的文本类型为目标文本类型。
[0152]
图7为本技术实施例提供的一种处理模块的结构示意图。如图7所示,本实施例提供的处理模块402,包括:
[0153]
第一处理子模块4021,用于分别对第一样本集和第二样本集的各文本段落进行预处理,并对得到的预处理的结果数据进行分词处理;
[0154]
第二处理子模块4022,用于根据预设划分规则将分词处理得到的各结果数据中的
各词汇划分为词汇组别,形成段落识别特征集;
[0155]
第三处理子模块4023,用于根据段落识别特征集获取预处理的结果数据所对应的第一特征序列,以根据各第一特征序列形成数字化训练集。
[0156]
在一种可能的设计中,第一处理子模块4021,具体用于:
[0157]
滤除各文本段落中与预设元数据无关的内容以及删除预设连字符,以将经过滤除操作和删除操作后的各文本段落确定为预处理的结果数据。
[0158]
在一种可能的设计中,第一处理子模块4021,还具体用于:
[0159]
通过预设分词模型分别对各第一结果数据和各第二结果数据进行分词处理,以得到对应的各第三结果数据和各第四结果数据。
[0160]
其中,预处理的结果数据包括各第一结果数据和各第二结果数据,分词处理得到的各结果数据包括各第三结果数据和各第四结果数据。
[0161]
在一种可能的设计中,第三处理子模块4023,具体用于:
[0162]
根据段落识别特征集获取各第一结果数据和各第二结果数据各自所包括的词汇组别中的词汇的数量,以得到各第一结果数据和各第二结果数据各自对应的第一特征序列;
[0163]
将各第一特征序列确定为数字化训练集的各子集,以得到数字化训练集。
[0164]
在一种可能的设计中,文本段落识别装置400,还包括:统计与生成模块。该统计与生成模块,用于:
[0165]
统计各第三结果数据和各第四结果数据中各词汇的出现频次,以得到各第三结果数据和各第四结果数据与各频次之间的映射关系;
[0166]
根据映射关系生成预设划分规则。
[0167]
在一种可能的设计中,文本段落识别装置400,还包括:验证与优化模块。该验证与优化模块,具体用于:
[0168]
利用目标识别模型对验证样本集中的各验证样本进行段落识别,并确定识别结果是否正确;
[0169]
若否,根据识别结果调整段落识别特征集中的各词汇组别;
[0170]
根据调整后的段落识别特征集获取预处理的结果数据所对应的第二特征序列,并根据各第二特征序列形成优化训练集;
[0171]
根据优化训练集优化目标识别模型,直到预测结果符合预设阈值范围,预测结果用于表征优化后的目标识别模型的识别结果为正确结果和非正确结果的概率。
[0172]
值得说明的,上述图6和图7以及可选的实施例提供的文本段落识别装置,可用于执行上述任一实施例提供的文本段落识别方法的各步骤,具体实现方式和技术效果类似,这里不再赘述。
[0173]
本技术所提供的上述各装置实施例仅仅是示意性的,其中的模块划分仅仅是一种逻辑功能划分,实际实现时可以有另外的划分方式。例如多个模块可以结合或者可以集成到另一个系统。各个模块相互之间的耦合可以是通过一些接口实现,这些接口通常是电性通信接口,但是也不排除可能是机械接口或其它的形式接口。因此,作为分离部件说明的模块可以是或者也可以不是物理上分开的,既可以位于一个地方,也可以分布到同一个或不同设备的不同位置上。
[0174]
图8为本技术提供的一种电子设备的结构示意图。如图8所示,该电子设备500可以包括:至少一个处理器501和存储器502。图8示出的是以一个处理器为例的电子设备。
[0175]
存储器502,用于存放处理器501的计算机程序。具体地,程序可以包括程序代码,程序代码包括计算机操作指令。
[0176]
存储器502可能包含高速ram存储器,也可能还包括非易失性存储器(non-volatile memory),例如至少一个磁盘存储器。
[0177]
处理器501配置为用于执行存储器502存储的计算机程序,以实现以上各方法实施例中文本段落识别方法的各步骤。
[0178]
其中,处理器501可能是一个中央处理器(central processing unit,简称为cpu),或者是特定集成电路(application specific integrated circuit,简称为asic),或者是被配置成实施本技术实施例的一个或多个集成电路。
[0179]
可选地,存储器502既可以是独立的,也可以跟处理器501集成在一起。当存储器502是独立于处理器501之外的器件时,电子设备500,还可以包括:
[0180]
总线503,用于连接处理器501以及存储器502。总线可以是工业标准体系结构(industry standard architecture,简称为isa)总线、外部设备互连(peripheral component,pci)总线或扩展工业标准体系结构(extended industry standard architecture,eisa)总线等。总线可以分为地址总线、数据总线、控制总线等,但并不表示仅有一根总线或一种类型的总线。
[0181]
可选的,在具体实现上,如果存储器502和处理器501集成在一块芯片上实现,则存储器502和处理器501可以通过内部接口完成通信。
[0182]
本技术还提供了一种计算机可读存储介质,该计算机可读存储介质可以包括:u盘、移动硬盘、只读存储器(read-only memory,rom)、随机存取存储器(random access memory,ram)、磁盘或者光盘等各种可以存储程序代码的介质,具体的,该计算机可读存储介质中存储有计算机程序,当电子设备的至少一个处理器执行该计算机程序时,电子设备执行上述的各种实施方式提供的文本段落识别方法的各个步骤。
[0183]
本技术实施例还提供一种计算机程序产品,该计算机程序产品包括计算机程序,该计算机程序存储在可读存储介质中。电子设备的至少一个处理器可以从可读存储介质读取该计算机程序,至少一个处理器执行该计算机程序使得电子设备实施上述的各种实施方式提供的文本段落识别方法的各个步骤。
[0184]
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本技术的其它实施方案。本技术旨在涵盖本技术的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本技术的一般性原理并包括本技术未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本技术的真正范围和精神由权利要求书指出。
[0185]
应当理解的是,本技术并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本技术的范围仅由所附的权利要求书来限制。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。