技术特征:
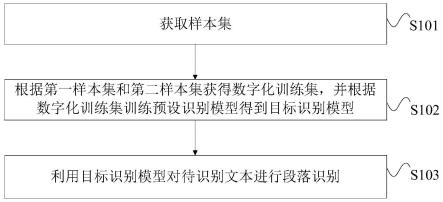
1.一种文本段落识别方法,其特征在于,包括:获取样本集,所述样本集包括第一样本集和第二样本集,所述第一样本集和所述第二样本集分别包括目标文本类型和非目标文本类型的各文本段落;根据所述第一样本集和所述第二样本集获得数字化训练集,并根据所述数字化训练集训练预设识别模型得到目标识别模型;利用所述目标识别模型对待识别文本进行段落识别,所述待识别文本为不包括前缀特征的目标文本,所述前缀特征用于表征所述目标文本的文本类型为所述目标文本类型。2.根据权利要求1所述的文本段落识别方法,其特征在于,所述根据所述第一样本集和所述第二样本集获得数字化训练集,包括:分别对所述第一样本集和所述第二样本集的各文本段落进行预处理,并对得到的所述预处理的结果数据进行分词处理;根据预设划分规则将所述分词处理得到的各结果数据中的各词汇划分为词汇组别,形成段落识别特征集;根据所述段落识别特征集获取所述预处理的结果数据所对应的第一特征序列,以根据各第一特征序列形成所述数字化训练集。3.根据权利要求2所述的文本段落识别方法,其特征在于,所述分别对所述第一样本集和所述第二样本集的各文本段落进行预处理,包括:滤除所述各文本段落中与预设元数据无关的内容以及删除预设连字符,以将经过滤除操作和删除操作后的各文本段落确定为所述预处理的结果数据。4.根据权利要求2所述的文本段落识别方法,其特征在于,所述对得到的所述预处理的结果数据进行分词处理,包括:通过预设分词模型分别对各第一结果数据和各第二结果数据进行分词处理,以得到对应的各第三结果数据和各第四结果数据;其中,所述预处理的结果数据包括所述各第一结果数据和所述各第二结果数据,所述分词处理得到的各结果数据包括所述各第三结果数据和所述各第四结果数据。5.根据权利要求4所述的文本段落识别方法,其特征在于,所述根据所述段落识别特征集获取所述预处理的结果数据所对应的第一特征序列,以根据各第一特征序列形成所述数字化训练集,包括:根据所述段落识别特征集获取所述各第一结果数据和所述各第二结果数据各自所包括的所述词汇组别中的词汇的数量,以得到所述各第一结果数据和所述各第二结果数据各自对应的第一特征序列;将所述各第一特征序列确定为所述数字化训练集的各子集,以得到所述数字化训练集。6.根据权利要求4所述的文本段落识别方法,其特征在于,在所述得到对应的各第三结果数据和各第四结果数据之后,还包括:统计所述各第三结果数据和所述各第四结果数据中各词汇的出现频次,以得到所述各第三结果数据和所述各第四结果数据与各频次之间的映射关系;根据所述映射关系生成所述预设划分规则。7.根据权利要求2-6任一项所述的文本段落识别方法,其特征在于,还包括:
利用所述目标识别模型对验证样本集中的各验证样本进行段落识别,并确定识别结果是否正确;若否,根据所述识别结果调整所述段落识别特征集中的各词汇组别;根据调整后的所述段落识别特征集获取所述预处理的结果数据所对应的第二特征序列,并根据各第二特征序列形成优化训练集;根据所述优化训练集优化所述目标识别模型,直到预测结果符合预设阈值范围,所述预测结果用于表征优化后的所述目标识别模型的识别结果为正确结果和非正确结果的概率。8.一种文本段落识别装置,其特征在于,包括:采样模块,用于获取样本集,所述样本集包括第一样本集和第二样本集,所述第一样本集和所述第二样本集分别包括目标文本类型和非目标文本类型的各文本段落;处理模块,用于根据所述第一样本集和所述第二样本集获得数字化训练集,并根据所述数字化训练集训练预设识别模型得到目标识别模型;识别模块,用于利用所述目标识别模型对待识别文本进行段落识别,所述待识别文本为不包括前缀特征的目标文本,所述前缀特征用于表征所述目标文本的文本类型为所述目标文本类型。9.一种电子设备,其特征在于,包括:处理器;以及,存储器,用于存储所述处理器的计算机程序;其中,所述处理器配置为经由执行所述计算机程序来执行权利要求1至7任一项所述的文本段落识别方法。10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1至7任一项所述的文本段落识别方法。
技术总结
本申请提供一种文本段落识别方法、装置、设备及存储介质。首先获取第一样本集和第二样本集,第一样本集和第二样本集包括目标文本类型和非目标文本类型的各文本段落,然后根据第一样本集和第二样本集获得数字化训练集,并根据数字化训练集训练预设识别模型得到目标识别模型,最后利用目标识别模型对待识别文本进行段落识别,待识别文本为不包括前缀特征的目标文本,而前缀特征用于表征目标文本的文本类型。从而为无前缀特征的文本提供了一种文本段落识别的方法,避免误识别风险,并具备较高的识别准确度,满足文本结构化处理需求。满足文本结构化处理需求。满足文本结构化处理需求。
技术研发人员:关燕妮 王丹
受保护的技术使用者:北大方正集团有限公司 北大方正信息产业集团有限公司
技术研发日:2021.07.16
技术公布日:2023/2/6
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。