1.本发明涉及数据管理技术领域,具体涉及一种基于知识图谱的跨环境元数据匹配方法及系统。
背景技术:
2.对于许多引文数据库(如pubmed),包含超过数千万篇生物学、医学等领域的文章。每天有超过数百万的用户使用引文数据库,为研究人员和学生提供服务。值得一提的是,pubmed是引文数据库,而不是全文文章数据库,因为在pubmed中索引的文章中约有三分之二不提供对全文的访问。当出版商提供免费全文或以开放获取形式发布时,全文将在pubmed central中被索引。因此,pubmed搜索引擎在提供搜索体验时依赖元数据和引文,而不是解析全文文章。文章的元数据在搜索过程中使用的字段中进行索引和解析。元数据字段包括标题、摘要、作者、期刊名称、出版日期、提交日期、相关术语、引文和参考信息、资金资助、项目等信息。
3.引文数据库通常使用一种依赖于模糊字符串匹配的算法,来将查询与相关引文进行匹配。例如,当用户在搜索框中输入作者姓名后跟期刊名称时,将显示该作者在该期刊中发表的所有文章。此外,使用自动术语映射系统也可进行搜索。自动术语映射系统扩展了输入查询,并查找输入查询所期望的字段。使用相关术语、关键字和其他可被视为索引的元数据将扩展查询与最相关的文档进行匹配。然后,使用tf-idf检索最相关的文章,并根据日期或使用标题或作者姓名的字母顺序排列。
4.最近,pubmed提出了相关性排名算法bestmatch。该算法依赖于一种机器学习模型,该模型使用过去几年从pubmed上用户搜索日志中提取的特征进行训练。该系统已被证明优于基于tf-idf的查询搜索系统。但是,bestmatch不考虑系统已经训练过且含义不明的用户查询日志。此外,尽管使用α和β测试方法对系统进行了彻底的评估,并与真实用户一起评估排名质量,但该算法并没有为使用语义模型理解查询意图提供解决方案。例如,用户可以在pubmed搜索框中输入单词“cancer”,“cancer”可能意味着多个意思:(1)他们可能希望在期刊上发表一篇名为“nature:cancer”的文章;(2)他们可能想知道在癌症领域工作和发表文章的作者;(3)他们可能想要所有提及癌症或癌症领域研究的相关文章;(4)他们可能在寻找带有标题或作者姓名、期刊和年份的特定引文。
5.pubmed和google等搜索引擎和信息检索系统依靠客观指标和算法对搜索结果进行排名,但搜索结果的排名不一定反映用户查询的意思。它们仅反映基于输入查询文本的最客观的相关性,这是通过分析文档语料库中输入查询中字符串的频率来完成的。将语义结合到搜索算法和信息检索系统中,尤其是在生物医学文献搜索中,对于解决歧义、理解查询意图和帮助真正的知识发现起到至关重要的作用。
6.近年来,随着web 2.0信息革命,语义web技术激增。语义网络技术旨在通过机器创建可理解和可读的网络。引入图模型,使用资源描述符框架等标准从语义上表示网页中的知识。知识图谱作为一种数据模型诞生,用于在语义上存储信息和数据,知识图谱也已扩展
为用于数据持久性的图数据库,与关系数据模型相比,它可以允许更灵活地表示数据和关系。
7.2012年出现了“知识图谱”来描述一种新的google搜索技术。该术语已扩展为描述使用图结构表示的任何形式的知识库。知识图谱在三元组中表示结构化和非结构化知识的数据模型,三元组表示两个对象之间的语义关系。知识图谱可以表示现实世界实体和关系的相互关联以及语义连接的描述。通过从非结构化文本中提取实体和关系,知识图谱的构建可以从手动到自动管理。知识图谱使用资源描述符框架(resources descriptors framework,rdf),这是一种语义表示语言,具有由万维网联盟定义的图数据模型,关系定义在两个连接的实体或节点之间。rdf标准要求使用唯一资源标识符格式存储节点名称。
8.由于知识图谱在数据建模方面的灵活性,在搜索引擎和推荐系统中非常高效。一些工作对在线搜索引擎中的文章元数据使用图表示学习,使用知识图谱嵌入模型将查询和文章表示为同一向量空间中的向量。在搜索学术文献中使用知识图嵌入可以极大地提高查询结果的相关性,在此过程中依赖于语义和实体匹配。
9.综上所述,现有算法依赖于从文章中提取特征并将先前的用户搜索日志包含到相关性排名预测模型中;然后,该模型会为每个用户找到最相关的个性化结果,但它不考虑任何带有歧义的语义。大多数元数据匹配与检索方法能够完成基本的用户需求,然而系统不能感知用户的意图,无法精准区分查询中的带有歧义的语义。
技术实现要素:
10.本发明的目的在于,提供一种基于知识图谱的跨环境元数据匹配方法,可以有效地区分同一个单词在不同环境下的语义,同时本发明公开基于知识图谱的跨环境元数据匹配方法及系统,在有效区分单词在不同环境下的语义的同时,方便计算并保留知识图谱中的结构信息,提高搜索引擎查询和系统的执行效率。
11.为实现上述技术目的,达到上述技术效果,本发明是通过以下技术方案实现:
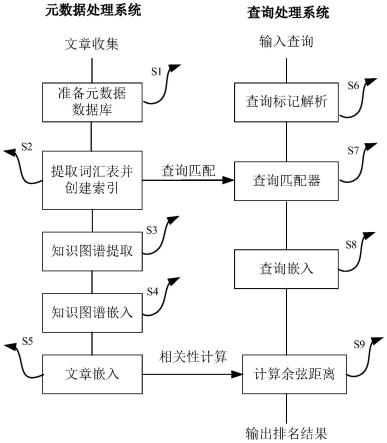
12.一种基于知识图谱的跨环境元数据匹配方法,包括以下步骤:
13.s1、准备元数据数据库;
14.s2、从文档语料库中提取词汇表,并为每个术语创建索引;
15.s3、将元数据的关系数据库转换为互连实体的知识图谱;
16.s4、为知识图谱中的每个节点或实体学习一组特征向量;
17.s5、使用平均池化操作,对连接到一阶邻域中的每篇文章节点的所有类型节点的嵌入向量进行平均;
18.s6、接受用户查询并解析;
19.s7、扩展提取的关键字列表,并将索引与关键字列表进行匹配;
20.s8、查找知识图谱中与匹配结果返回的标识符具有相同标识符的所有节点;
21.s9、计算用户输入和查询结果的余弦距离并输出排名。
22.进一步的,所述步骤s1具体包括:
23.s101、从引文库中的文章摘要提取实体,并消除作者姓名歧义,然后收集作者隶属机构和教育背景来构建引文作者关系知识图谱;
24.s102、根据步骤s101,为消除歧义的作者分配唯一标识符aid;
25.s103、根据步骤s102,选择文章子集,使用图卷积神经网络自适应地提取一阶引文网络,具体如下面公式所示:
[0026][0027]
其中,设中心节点为i,h
il
表示节点i在第l层的特征表达,c
ij
为归一化因子,ni为节点i的邻居,rj为结点j的类型嵌入,w
rj
表示类型为rj节点的变换权重参数,σ表示sigmoid激活函数。
[0028]
进一步的,所述步骤s2中提取词汇表并创建索引具体包括:
[0029]
s201、使用预训练语言模型提取实体的名称;
[0030]
s202、根据步骤s201,除了作为知识图谱的一部分外,为实体名称构建索引,索引将用于匹配输入的用户查询并创建查询向量;
[0031]
s203、根据步骤s202,每篇文章p∈p(p为所有文章)将包含一组实体提及m(entity mentions);每一个提及m'都是一组提及的一部分m'∈m,这些提及用于区分每个单独的实体b∈b,用表示。
[0032]
进一步的,所述步骤s3中知识图谱提取具体包括:
[0033]
s301、提取每一篇文章的所有作者姓名、题目、摘要、关键字、正文和参考文献以及相关术语;
[0034]
s302、使用代表每个实体的唯一标识符创建知识图谱;
[0035]
s303、每篇文章和相关的元数据将被表示为一个迷你知识图谱,对于每篇文章,使用唯一标识符创建迷你知识图谱tiny-kg;所有文章和相关的元数据集合将被表示为一个大知识图谱big-kg,其由若干个迷你知识图谱构成;
[0036]
s304、步骤s103的引文网络提供使用关系“iscitedby/cites”链接大多数文章所需的边集;
[0037]
s305、将知识图谱在语义上进行链接,得到一个语义关联的网络kg-net。
[0038]
进一步的,所述步骤s4中知识图谱嵌入具体包括:
[0039]
s401、使用node2vec提取知识图谱的嵌入表示,执行改良版的随机游走策略,包括参数p和q来控制采样策略,p参数控制游走重新访问节点的可能性,q参数决定搜索是局部约束还是全局约束;给定q》1和初始节点上的随机游走,随机游走对靠近初始节点的节点进行采样;而q《1时,随机游走从初始节点进一步采样;
[0040]
具体如下式所示:
[0041][0042]
其中,参数p和q引导了随机游走,t和x表示节点,α
pq
(t,x)表示节点t到节点x的状态转移概率,d
tx
表示节点t和x之间的最短路径距离;
[0043]
s402、为每个节点构建一个游走语料库;使用skip-gram模型在该语料库上进行训练,为知识图谱中的每个节点生成一个唯一的嵌入向量。
[0044]
进一步的,所述步骤s5具体包括:
[0045]
使用平均池化操作,对连接到其一阶邻域中的每个文章节点对应类型节点的嵌入向量进行平均,如下式所示:
[0046][0047]
其中,ei表示第i个文章节点的嵌入向量,μi表示每个ei的权重,n表示节点数量,e
ave
表示平均后的嵌入向量。
[0048]
进一步的,所述步骤s6具体包括:
[0049]
s601、该模块充当与用户的接口,接受用户查询并解析;
[0050]
s602、输入查询后,在删除标点符号、停用词和动词后分割空格来标记化。
[0051]
进一步的,所述步骤s7具体包括:
[0052]
s701、使用大小为2、3和4的滑动窗口分别自顶向下滑过关键字列表,得到的三组不同的特征向量,然后通过最大池化操作进行特征降采样;滑动窗口函数从初始关键字列表中捕获多个标记,然后大小为2、3和4的滑动窗口滑过关键字列表,得到关键字长度为2、3和4的子关键字列表,将子关键字列表与原始关键字列表合并,得到扩展关键字列表;
[0053]
s702、然后使用levenshtein字符串距离比较器将扩展的关键字列表与索引匹配;
[0054]
s703、对于索引中每篇文章中匹配的提及,将提取每个实体的唯一标识符并传递到下一步;如果在索引中找不到关键字,则退出系统。
[0055]
进一步的,所述步骤s8具体包括:
[0056]
s801、查找知识图谱中与步骤s7查询匹配器返回的标识符具有相同标识符的所有节点;
[0057]
s802、在识别节点后,从步骤s4的知识图谱嵌入中提取节点对应的学习嵌入向量。
[0058]
进一步地,所述步骤s9具体包括:
[0059]
s901、使用步骤s9的查询向量和步骤s6的文章向量,在查询向量和文章向量之间产生与查询向量相关的文章列表;
[0060]
s902、按照余弦分数的排序,将文章按照排名先后列表显示出来;
[0061]
s903、根据步骤s902,在欧几里得空间中,查询向量a和文章向量b之间的角度θ的余弦使用以下公式确定:
[0062][0063]
本发明的基于知识图谱的跨环境元数据匹配方法的有益效果:
[0064]
1、本发明的基于知识图谱的跨环境元数据匹配方法,利用知识图谱在数据建模方面的灵活性,使用知识图谱嵌入模型将查询和文章表示为同一向量空间中的向量,借助于知识图谱的语义和实体匹配,在搜索文献中使用知识图嵌入可以极大地提高返回文档的相关性,进而提高查询结果的准确性;
[0065]
2、现有技术方案大多数元数据匹配和检索方法能够完成基本的用户需求,但是现有技术和系统不能感知用户的意图,无法精准区分查询中带有歧义的语义,本方案可以有效地区分同一个单词在不同环境下的语义,将用户意图信息加入到知识图谱中,提高了查
询结果的准确性。
[0066]
3、本发明的基于知识图谱的跨环境元数据匹配方法,从引文库中文章关键信息(例如:摘要、关键字、正文等)提取实体,可以消除作者姓名歧义,实现快速构建知识图谱、减少后期数据的增、查、删、改操作成本;
[0067]
4、本发明的基于知识图谱的跨环境元数据匹配方法,使用预训练语言模型自动提取实体名称,可以减小人工成本,同时预训练语言模型具有泛化性,后期可以用不同的语言模型进行训练,方便提取词汇表并创建索引;
[0068]
5、本发明的基于知识图谱的跨环境元数据匹配方法,根据提取每一篇文章的所有作者姓名、题目、摘要、关键字、正文和参考文献以及相关术语,可以创建详细的知识图谱,具有丰富的语义信息,方便使用者查阅所需信息;
[0069]
6、本发明使用node2vec提取知识图谱的嵌入表示,可以执行改良版的随机游走策略,为知识图谱的节点生成嵌入向量,方便计算的同时保留知识图谱中的结构信息;skip-gram模型可以在节点构成的游走语料库上继续训练,进一步优化skip-gram模型的训练效率,此外可以提高模型的可靠性和实用性;
[0070]
7、本发明的基于知识图谱的跨环境元数据匹配方法,接收用户查询,方便用户对信息进行检索;并且针对用户查询的行为,可以对执行查询语句的行为进行优化,提高模型的效率和稳定性,方便用户使用。此外,本方案通过扩展提取的关键字列表,将索引与关键字列表进行匹配,有利于提高查询效率,让系统高效运行;
[0071]
8、本发明通过查找知识图谱中与匹配结果返回的标识符具有相同标识符的所有节点,方便系统后期对模型进行优化,加快系统的运行效率,通过计算查询向量和文章向量的余弦距离并输出排名,将排名靠前的结果排在前面,提高查询的准确性和查询结果的精准匹配度。上述两个操作可以优化系统的工作流程,为用户提供更加优质的查询服务。
[0072]
本发明的另一目的在于,提供基于知识图谱的跨环境元数据匹配方法及系统;
[0073]
所述系统包括:元数据采集系统、元数据处理系统和查询处理系统;
[0074]
所述元数据采集系统用于收集的元数据,此例中具体是收集在线文章的元数据,从大量的引文库摘要中提取实体,并消除作者姓名的歧义,然后整合资助数据,收集作者的所属机构和教育背景;
[0075]
所述元数据处理系统用于将收集到的元数据进行处理,具体是从文档语料库中提取词汇表,并为每个术语创建索引。将元数据的关系数据库转换为互连实体的知识图谱,为知识图谱中的每个节点或实体学习一组特征向量。使用平均池化操作,对连接到一阶邻域中的每个文章节点的所有类型节点的嵌入向量进行平均池化操作,从而得到文章的嵌入向量;
[0076]
所述查询处理系统用于处理用户输入的查询,具体是接受用户查询并解析查询,然后扩展提取的关键字列表,并将索引与关键字列表进行匹配。随后查找知识图谱中与匹配结果返回的标识符具有相同标识符的所有节点,最后计算余弦距离并输出排名。
[0077]
本发明的基于知识图谱的跨环境元数据匹配方法及系统的有益效果如下:
[0078]
本发明的基于知识图谱的跨环境元数据匹配方法及系统通过元数据采集系统,元数据处理系统和查询处理系统,收集元数据,整合不同类型数据,将元数据的关系数据库转换为互连实体的知识图谱,并添加特征向量等操作,可以方便计算的同时保留知识图谱中
的结构信息,提高查询和系统的执行效率,系统具有很好的稳定性。
[0079]
当然,实施本发明的任一产品并不一定需要同时达到以上所述的所有优点。
附图说明
[0080]
图1为本发明的基于知识图谱的跨环境元数据匹配方法的流程示意图;
[0081]
图2为本发明的预训练语言模型工作原理图;
[0082]
图3为本发明的基于知识图谱的跨环境元数据匹配系统结构示意图;
具体实施方式
[0083]
为了更清楚地说明本发明实施例的技术方案,下面将结合附图对实施例对本发明进行详细说明。
[0084]
下面结合具体实施例对本发明进行说明:
[0085]
实施例1
[0086]
如图1所示:
[0087]
本实施例提供基于知识图谱的跨环境元数据匹配方法,包括以下步骤s1至s9:
[0088]
s1、准备元数据数据库;
[0089]
本实施例中,步骤s1具体包括:
[0090]
s101、从引文库中的文章摘要提取实体,并消除作者姓名歧义,然后收集作者隶属机构和教育背景来构建知识图谱;
[0091]
s102、根据步骤s101,为消除歧义的作者分配唯一标识符aid;
[0092]
s103、根据步骤s102,选择文章子集,使用图卷积神经网络自适应地提取一阶引文网络,具体如下面公式所示:
[0093][0094]
其中,设中心节点为i,h
il
表示节点i在第l层的特征表达,c
ij
为归一化因子,ni为节点i的邻居,rj为结点j的类型嵌入,w
rj
表示类型为rj节点的变换权重参数,σ表示sigmoid激活函数。
[0095]
本实施例中,周期性的监测各子系统是否出现异常状况,在未监测到异常状态时执行步骤s2;
[0096]
s2、从文档语料库中提取词汇表,并为每个术语创建索引;
[0097]
本实施例中,步骤s2具体包括:
[0098]
s201、使用预训练模型提取实体的名称,如图2所示,选择pubmed和pmc作为医学语料库,分别包含45亿个单词和135亿个单词;对该模型进行参数初始化,然后进行模型预训练,得到每个生物实体的嵌入t;
[0099]
s202、根据步骤s201,除了作为知识图谱的一部分外,为实体名称构建索引,索引将用于匹配输入的用户查询并创建查询向量;
[0100]
s203、根据步骤s202,每篇文章p∈p(p为所有文章)将包含一组实体提及m(entity mentions);每一个提及m'都是一组提及的一部分m'∈m,这些提及用于区分每个单独的实
体b∈b,用表示。
[0101]
本实施例中,按照设定,判断属于创建索引的状况,在未监测到异常状态时执行步骤s3;
[0102]
s3、将元数据的关系数据库转换为互连实体的知识图谱。
[0103]
本实施例中,步骤s3具体包括:
[0104]
s301、提取每一篇文章的所有作者姓名、药物名称、基因、蛋白质、疾病和物种以及相关的生物术语和化学物质等术语;
[0105]
s302、使用代表每个实体的唯一标识符创建知识图谱;
[0106]
s303、每篇文章和相关的元数据将被表示为一个迷你知识图谱,对于每篇文章,使用唯一标识符创建迷你知识图谱tiny-kg;所有文章和相关的元数据集合将被表示为一个大知识图谱big-kg,其由若干个迷你知识图谱构成;
[0107]
s304、步骤s103的引文网络提供使用关系“iscitedby/cites”链接大多数文章所需的边集;
[0108]
s305、链接的知识图谱将在语义上链接,得到最终的知识图谱是一个语义关联的网络;这种知识图谱代表了一类信息,比如此例中包括了文章、作者、资助信息、药物、疾病和基因等。
[0109]
本实施例中,检测文章中提取的信息以及创建的知识图谱,在未检测到异常状态时执行步骤s4;
[0110]
s4、为知识图谱中的每个节点或实体学习一组特征向量;
[0111]
本实施例中,步骤s4具体包括:
[0112]
s401、使用node2vec提取知识图谱的嵌入表示,执行改良版的随机游走策略,包括参数p和q来控制采样策略;p参数控制游走重新访问节点的可能性;q参数决定搜索是局部约束还是全局约束;给定q》1和初始节点上的随机游走,随机游走对靠近初始节点的节点进行采样;而q《1时,随机游走从初始节点进一步采样;
[0113]
具体如下式所示:
[0114][0115]
其中,参数p和q引导了随机游走,t和x表示节点,α
pq
(t,x)表示节点t到节点x的状态转移概率,d
tx
表示节点t和x之间的最短路径距离;
[0116]
s402、为每个节点构建一个游走语料库;使用skip-gram模型在该语料库上进行训练,为知识图谱中的每个节点生成一个唯一的嵌入向量。
[0117]
本实施例中,检测node2vec和skip-gram模型的正确性,在未检测到异常状态时执行步骤s5;
[0118]
s5、使用平均池化操作,对连接到其一阶邻域中的每个文章节点对应类型节点的嵌入向量进行平均,如下式所示。
[0119][0120]
其中,ei表示第i个文章节点的嵌入向量,μi表示每个ei的权重,n表示节点数量,e
ave
表示平均后的嵌入向量。
[0121]
本实施例中,在进行平均池化操作后执行步骤s6;
[0122]
s6、接受用户查询并解析;
[0123]
本实施例中,步骤s6具体包括:
[0124]
s601、该模块充当与用户的接口,接受用户查询并解析;
[0125]
s602、输入查询后,在删除标点符号、停用词和动词后分割空格来标记化。
[0126]
本实施例中,按照设定,检测各个接口状态,在未监测到异常状态时执行步骤s7。
[0127]
s7、扩展提取的关键字列表,并将索引与关键字列表进行匹配;
[0128]
本实施例中,步骤s7具体包括:
[0129]
s701、使用大小为2、3和4的滑动窗口分别自顶向下滑过关键字列表,得到的三组不同的特征向量,然后通过最大池化操作进行特征降采样;滑动窗口函数从初始关键字列表中捕获多个标记,然后大小为2、3和4的滑动窗口滑过关键字列表,得到关键字长度为2、3和4的子关键字列表,将子关键字列表与原始关键字列表合并,得到扩展关键字列表;
[0130]
s702、然后使用levenshtein字符串距离比较器将扩展的关键字列表与索引匹配;
[0131]
s703、对于索引中每篇文章中匹配的提及(mentions),将提取每个生物实体的唯一标识符并传递到下一步;如果使用索引找不到关键字,则退出系统。
[0132]
本实施例中,按照设定,检测索引中的关键字是否异常,在未监测到异常状态时执行步骤s8。
[0133]
s8、查找知识图谱中与匹配结果返回的标识符具有相同标识符的所有节点;
[0134]
本实施例中,步骤s8具体包括:
[0135]
s801、查找知识图谱中与步骤s7查询匹配器返回的标识符具有相同标识符的所有节点;
[0136]
s802、在识别节点后,从步骤s4的知识图谱嵌入中提取节点对应的学习嵌入向量。
[0137]
本实施例中,通过查找知识图谱中与匹配结果返回的标识符具有相同标识符的所有节点,方便系统后期对模型进行优化。
[0138]
本实施例中,检测向量是否有异常情况,在未检测到异常状态时执行步骤s9。
[0139]
s9、计算查询向量和文章向量的余弦距离并输出排名。
[0140]
本实施例中,步骤s9具体包括:
[0141]
s901、使用步骤s9的查询向量和步骤s6的文章向量,在查询向量和文章向量之间产生与查询向量相关的文章列表;
[0142]
s902、按余弦分数排序时,文章列表将显示为排名检索的文章;
[0143]
s903、根据步骤s902,在欧几里得空间中,查询向量a和文章向量b之间的角度θ的余弦使用以下公式确定:
[0144][0145]
本实施例的s1至s9,利用知识图谱在数据建模方面的灵活性,使用知识图谱嵌入模型将查询和文章表示为同一向量空间中的向量,依赖于知识图谱的语义和实体匹配,在搜索文献中使用知识图嵌入可以极大地提高返回文档的相关性;本发明的技术方案,解决了现有技术中大多数元数据匹配与检索方法虽然能够满足用户需求,但是系统不能感知用户意图的问题;此外本发明解决了现有数据检索方法无法精准区分查询中带有歧义的语义信息的不足,本方案可以有效区分同一个单词在不同环境下的语义。
[0146]
实施例2
[0147]
基于上述实施例1,本实施例公开基于知识图谱的跨环境元数据匹配方法及系统;
[0148]
所述系统包括:元数据采集系统、元数据处理系统和查询处理系统;
[0149]
所述元数据采集系统用于收集元数据,方便数据处理,本例中元数据采集系统主要用于在线收集文章的元数据,具体是从大量的引文库摘要中提取实体,并消除作者姓名的歧义,然后整合资助数据,收集作者的所属机构和教育背景;
[0150]
所述元数据处理系统用于将收集到的元数据进行处理,具体是从文档语料库中提取词汇表,并为每个术语创建索引。将元数据的关系数据库转换为互连实体的知识图谱,为知识图谱中的每个节点或实体学习特征向量;
[0151]
所述查询处理系统用于处理用户输入的查询,具体是接受用户查询并解析查询,然后扩展提取的关键字列表,并将索引与关键字列表进行匹配。随后查找知识图谱中与匹配结果返回的标识符具有相同标识符的所有节点,最后计算余弦距离并输出排名。
[0152]
如图3所示,本实施例的元数据采集系统对应元数据的采集,从大量的引文库摘要中提取实体,收集各种元数据,方便后续进行数据处理。
[0153]
元数据处理系统对应元数据的处理,首先从文档语料库中提取词汇表,并为每个术语创建索引,使用特征向量、池化和嵌入向量处理元数据;
[0154]
查询处理系统对应后期对整体系统的优化,输入查询语句,经过解析和处理计算余弦距离输出排名后重新对表进行排序,提高后续查询效率,增加系统的实用性;
[0155]
本实施例通过元数据采集系统,元数据处理系统和查询处理系统,收集元数据,整合资助数据,将元数据的关系数据库转换为互连实体的知识图谱,并添加特征向量等操作,可以方便计算的同时保留知识图谱中的结构信息,提高查询和系统的执行效率,让系统平稳发展。
[0156]
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。