技术特征:
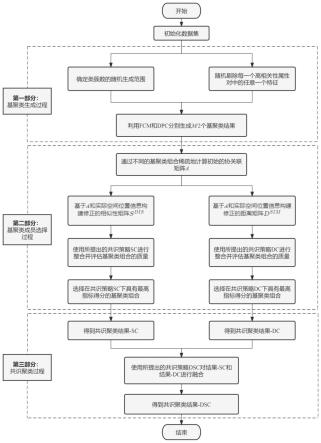
1.一种基于三种共识策略的双粒度聚类集成算法的高熵合金硬度预测方法,其特征在于包括如下步骤:s1、基聚类生成过程;对于高熵合金数据集x={x1,x2,
…
,x
n
}∈r
h
,x为高熵合金样本点,h为每个样本点的特征维度,利用聚类算法生成m个基聚类结果,得到基聚类组合π={π1,π2,
…
,π
m
];s2、基聚类成员子集选择过程;将给定的共识函数嵌入到选择策略,计算给定共识策略下基聚类组合π={π1,π2,
…
,π
m
}的共识结果,并去除基聚类集合中的噪声成员,得到最佳的聚类子集π
*
={π
1*
,π
2*
,
…
,π
l*
},l≤m;s3、共识聚类过程;采用可调ds证据理论,基于s2得到的最佳聚类子集,将各共识函数下得到的最佳共识结果进行融合,得到不同类簇的最终划分结果;s4、将得到的不同类簇各自建立回归模型,进行高熵合金硬度预测计算。2.根据权利要求1所述的方法,其特征在于所述s1包括如下过程:通过密度峰值聚类算法利用局部密度ρ
i
和相对距离δ
i
筛选出可能的候选聚类中心c
p
:将簇数的随机初始化范围设置为其中,|c
p
|为集合c
p
中的元素数量;采用皮尔逊相关系数算法随机删除具有高相关性属性对中的一个,采用剩下的特征生成基聚类结果;采用模糊c均值算法和密度峰值聚类算法分别生成m/2个基聚类结果,得到基聚类组合π={π1,π2,
…
,π
m
]。3.根据权利要求2所述的方法,其特征在于所述s2包括如下过程:s21、基于基聚类组合π={π1,π2,
…
,π
m
},计算给定的共识策略下该基聚类组合的共识结果,计算共识结果的归一化互信息,即nmi值;s22、在基聚类组合π={π1,π2,
…
,π
m
}的基础上,分别独立计算按序去掉一个基聚类构成组合的nmi值,然后选择nmi值达到最优的包含m-1个基聚类的组合;s23、基于得到包含m-1个基聚类的组合,分别独立计算按序去掉一个基聚类构成的组合的nmi值,选择使得nmi值达到最优的包含m-2个基聚类的组合,以此进行迭代计算,至没有可被剔除的基聚类为止;选择nmi值得分最高的基聚类组合π
*
={π
1*
,π
2*
,
…
,π
l*
},l≤m作为在给定共识策略下的最佳基聚类子集。4.根据权利要求3所述的方法,其特征在于s21中所述共识策略包括谱聚类基共识策略和密度峰值聚类基共识策略;所述谱聚类基共识策略以修正的相似性矩阵s
dis
作为输入,构建一个以样本点为节点、修正的相似性矩阵s
dis
为节点之间邻接矩阵的新的无向图为节点之间邻接矩阵的新的无向图其中,v=x为由样本点构成的节点集,为边集;在无向图中,相似性矩阵s
dis
决定边的
权重,对于给定的节点x
i
和x
j
,二者之间的边权重定义为:对无向图的拉普拉斯矩阵进行正则化处理:其中,i为单位矩阵,d∈r
n
×
n
为一个度矩阵,且对角线上的任意一个元素对正则化的进行特征值分解,以得到最小的前c
*
个特征值对应的特征向量;由这c
*
个特征向量按列标准化展开构成一个新的矩阵f∈r
n
×
c*
;最后,在矩阵f的基础上利用k均值聚类算法得到共识聚类结果π
sc
,即:其中,为sc作为共识策略嵌入bcesf算法得到的最优基聚类成员组合。5.根据权利要求4所述的方法,其特征在于所述修正的相似性矩阵s
dis
的建立过程为:的建立过程为:的建立过程为:其中,d
i,j
为样本点x
i
和x
j
之间的欧氏距离,min(d)和max(d)分别是距离中的最小值和最大值。6.根据权利要求4所述的方法,其特征在于s21中所述密度峰值聚类基共识策略以修正的距离矩阵d
sim
作为输入,基于距离矩阵d
sim
计算局部密度ρ
i
:其中,d
c
为截断距离,通常取距离升序排列的1%~2%位置;当x
i
为非最大局部密度点时,其相对距离δ
i
由距离x
i
最近的样本点x
j
确定:当x
i
为最大局部密度点时,其相对距离δ
i
被记作δ
max
,即:δ
max
=max
j
(d
i,j
)
ꢀꢀꢀꢀꢀ
(11)基于上述计算得到的局部密度ρ
i
和相对距离δ
i
,选择前c
*
个具有最大γ
i
=ρ
i
·
δ
i
值的样本点并将其标记为聚类中心,其中局部密度ρ
i
和相对距离δ
i
满足且最后,将剩余的每一个非中心点分配到与其距离最近的点为同一簇,得到共识聚类结果π
dc
,即:其中,为dc作为共识策略嵌入bcesf算法得到的最优基聚类成员组合。
7.根据权利要求6所述的方法,其特征在于所述距离矩阵d
sim
的建立过程为:的建立过程为:8.根据权利要求1所述的方法,其特征在于所述s3的计算过程为:首先计算出每一个样本点x
i
的k近邻nn
k
(x
i
),所述nn
k
(x
i
)的计算公式为:其中,n
k
(x
i
)是样本点x
i
的第k近邻;基于nn
k
(x
i
)和第q个聚类集成算法y
q
,计算样本点x
i
属于簇标签r的基本概率值m
q
(a
r
)的初始值,即:其中,|r(x
j
)|为样本点x
i
的k近邻中属于簇标签r的元素个数;对初始的m
q
(a
r
)进行加权得到)进行加权得到由可调系数w
q
和m
q
(a
r
)确定,即:其中,其中,如等式(20)所示,对q种共识结果进行融合得到融合结果m(a
r
):通过下式计算类簇a
r
的置信度值:最后,根据得到的置信度值结果对样本点所属簇标签进行最终的分配:得到基于共识策略dsc的融合结果π
dsc
,即:π
dsc
=bcesf-dsc(y1,y2,...,y
q
)
ꢀꢀꢀ
(23)。9.根据权利要求1所述的方法,其特征在于s4中所述回归模型为线性svr模型。10.一种基于三种共识策略的双粒度聚类集成算法的高熵合金硬度预测系统,其特征在于该系统具有与上述权利要求1~9任一项权利要求的步骤对应的程序模块,运行时执行上述的基于三种共识策略的双粒度聚类集成算法的高熵合金硬度预测方法中的步骤。
技术总结
本发明提供一种基于三种共识策略的双粒度聚类集成算法的高熵合金硬度预测方法,涉及合金硬度预测技术领域,为解决现有技术中采用单一聚类方法不能同时适用于不同分布特征的数据集,即使在同一种数据分布下往往也不能达到稳定、统一的聚类效果的问题。本发明将高熵合金数据集X={x1,x2,...,x
技术研发人员:李述 单云霄 李帅 崔禹欣 李福祥
受保护的技术使用者:哈尔滨理工大学
技术研发日:2022.11.09
技术公布日:2023/2/3
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。