一种基于ssd改进的配电房异物检测方法
技术领域
1.本发明属于目标检测领域,具体涉及一种基于ssd改进的配电房异物检测方法。
背景技术:
2.配电房是配网中最重要的供电节点。长期以来,配电房管理工作一直是供电系统运行管理的可靠性的薄弱环节之一,配电房关跳闸和配电房环境过热可影响设备运行,还有老鼠、火灾等其他因素导致设备损坏等情况存在,既给供电企业造成财产损失,也容易影响用户正常的用电情况,而这些故障却常常被人们忽视。另外,配电房中设备规模大、分布广、运行环境复杂,现有设备运行状态和环境监测手段仍缺少,仍主要依靠人来进行设备巡检,存在巡检工作效率不高、漏检、问题发现不及时等现象。目前虽然已可以对作业现场进行视频监控,但是视频监控带来的大量视频和图片数据也存在着人工检查困难的问题,而且对于一些误闯入配电房的异物往往在深夜出现,摄像头夜视下图片较为灰暗,工作人员在检查时非常容易产生视觉疲劳,出现漏检情况,难以及时地发现闯入情况。
3.随着图像处理技术的发展,深度学习在目标检测领域取得了不错的进展,目前经典的目标检测算法主要分为单阶段和双阶段两类,单阶段类包括sdd,yolo等,双阶段类包括r cnn,mask r cnn,fast r cnn等。其中单阶段算法ssd算法运行速度较快,准确度也较高,从技术上看,ssd比较适合用于配电房内的异物入侵检测,从硬件设备上看,轻量级的ssd也比较适配嵌入式计算设备能够很好地存放于配电房的环境,但是由于异物目标较小,背景颜色灰暗较相近等问题,识别效果并不太好,所以异物检测仍然存在有待改进的空间。
技术实现要素:
4.本发明的主要目的在于克服现有技术的缺点与不足,提出一种基于ssd改进的配电房异物检测方法,能够对误闯入配电房的异物如老鼠等进行识别,在异物目标较小、背景颜色灰暗较相近情况下,同样能有较好的检测效果。
5.为了达到上述目的,本发明采用以下技术方案:
6.一种基于ssd改进的配电房异物检测方法,包括以下步骤:
7.s1、采集配电房中摄像头拍摄的异物图像,建立图像数据集,并对数据集中图像进行预处理;
8.s2、构建改进ssd模型,包括骨干网络和特征金字塔;
9.s3、对建立的图像数据集,按比例划分为训练集以及测试集;
10.s4、利用训练集对改进ssd模型进行训练;
11.s5、利用训练好的模型对测试集进行检测,对检测结果进行指标评价。
12.进一步的,预处理具体包括:
13.数据增强,包括像素内容变换和空间几何变换,将采集到的异物图像进行随机改变图像亮度,再进行随机扩展。
14.进一步的,改进ssd模型具体包括基础网络层、多尺度网络层、目标检测模块、识别
模块以及非极大值抑制模块;基础网络层为基于vgg的基础网络;
15.改进ssd模型具体为:改进基础网络层,其中conv4_3,conv7,conv8_2,conv9_2,conv10_2,conv11_2不同特征层的特征图数量统一为[6,6,6,6,6,6];
[0016]
增加额外的特征提取层;
[0017]
利用分类网络增加不同层之间的特征图联系,减少重复框的出现,分类网络充分利用特征金字塔中各层之间的关联性,各个预测分支统一成单个分类网络,无需修改检测器的backbone主干网;
[0018]
在输入分类网络前增加特征图的通道数;
[0019]
在特征金字塔,改进特征融合方式,提升原有ssd算法的效果,使其充分利用特征,改进特征融合方式具体为:
[0020]
同时通过池化和逆卷积来融合所有高、低层特征图上的特征,各个检测分支提高了各种目标尺度的能力,最终在低层特征图上,融合了来自高层的高语义信息。
[0021]
进一步的,特征金字塔各层特征图通道数统一为2816,各层通道数相同,因此各个分支后接的分类网络之间同享同一套权重参数;
[0022]
特征融合前,对特征图做一个归一化操作,采用批量归一化;
[0023]
由于网络结构同享先验框,所以在每个特征图上设置的先验框数量统一为6个;
[0024]
改进的ssd模型输出的先验框的个数为11640。
[0025]
进一步的,步骤s3具体为:
[0026]
按照7:3的比例将异物图像数据集划分为训练集和测试集。
[0027]
进一步的,步骤s4包括:
[0028]
把训练集的图像输入改进ssd模型中进行训练,图像进入ssd网络,提取6个特征图,对每个特征图的每个像素设置先验框,编码,选取正负样本,计算损失函数,更新网络权重,在损失函数收敛后保存并输出最佳网络权重。
[0029]
进一步的,步骤s4中,先验框的设计具体为:
[0030]
提取6个特征图,其大小分别为(38,38),(19,19),(10,10),(5,5),(3,3),(1,1),每个特征图上设置的先验框数量统一为6;
[0031]
先验框的设置,包括尺度和长宽比两个方面;对于先验框的尺度,随着特征图大小降低,先验框尺度线性增加:
[0032][0033]
其中,m指特征图个数,sk表示先验框大小相对于图片的比例,s
max
和s
min
表示比例的最小值与最大值,s
min
与s
max
设置为0.15与0.85;
[0034]
设置宽高比ar∈{1/3,1/2,1,2,3},分别计算得到多阶段特征图对应先验框宽高:
[0035][0036][0037]
其中,为第k层特征图的第a个先验框的高与宽;
[0038]
获取预测框坐标并解码:
[0039]
给定预测框坐标为其中g
x
与gy为预测框中心点的x与y坐标,gw与gh为预测框的宽与高;
[0040]
给定先验框坐标为其中p
x
与py为先验框中心点的x与y坐标,pw与ph为先验框的宽与高;
[0041]
改进ssd模型输出坐标编码信息为其中d
x
,dy分别为检测头输出的水平与竖直方向的平移系数,dw,dh为检测头输出的宽、高放缩系数;
[0042]
根据下列公式获取预测框坐标:
[0043][0044][0045][0046][0047]
其中,为输出的最终待检测目标的解码坐标。
[0048]
进一步的,正负样本的选取具体为:
[0049]
正样本选取:
[0050]
在训练过程中,先验框与真实框匹配原则:
[0051]
对于图像中的每个真实框,找到与其iou最大的先验框,该先验框与其匹配,保证每个真实框一定与某个先验框匹配;
[0052]
对于剩余未匹配的先验框,若与某个真实框的iou大于0.5,则先验框与这个真实框匹配;
[0053]
负样本选取:
[0054]
挑选出置信度损失confidence_loss排在前面的一批负样本,负正样本数为3:1。
[0055]
进一步的,改进ssd模型的损失函数依据预测部分的输出结果而设计,包括位置损失和置信度损失,总的目标损失函数为位置损失函数与置信度损失函数的加权和:
[0056][0057]
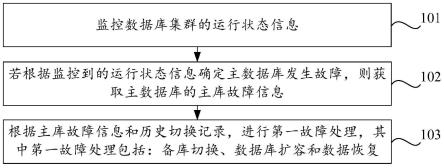
其中,n是先验框的正样本数量;l
conf
(x,c)为置信度损失函数,α为总损失参数,权重系数α通过交叉验证设置为1,x={1,0},代表某个预测框是否匹配真实框,l
loc
(x,l,g)为位置损失函数,l为预测框,c为标签分类,g为真实框;
[0058]
对于l
loc
(x,l,g)位置损失函数,其采用smooth l1 loss,定义如下:
[0059][0060]
其中,pos为样本中的正例,cx、cy为预测框的中心点坐标,w为预测框的宽,h为预测框的高,为类别为k的第i个预测框与第j个真实框是否匹配,为预测框,为真实框,m为产生损失的特征图对应的序号;
[0061]
对于l
conf
(x,c),其采用softmax loss,定义如下:
[0062][0063]
其中,是一个指示器,当时,表示第i个anchor和第j个ground truth相匹配,且ground truth的类别为p,当时,就代表第i个anchor为负样本,没有匹配的真实框。
[0064]
进一步的,步骤s5中,采用交并比,精确率、召回率以及平均精度评价训练好的模型;
[0065]
交并比:iou=tp/(tp fn fp);
[0066]
精确度:precision=tp/(tp fp)=tp/all detections;
[0067]
召回率:recall=tp/(tp fn)=tp/all ground trusts;
[0068]
其中,tp为算法检测框预测正确的区域;fp为算法检测框预测错误的区域;fn为实际标注框正确但算法检测框未预测到的区域;all detections为算法检测检预测的区域;all ground trusts为实际标注框的区域;
[0069]
平均精度:
[0070][0071]
其中,r表示召回率,ρ(r)为召回率r的精度值,ρ
interp
(r
n 1
)为召回率大于等于r时,对应精度值ρ(r)中的最大精度值。
[0072]
本发明与现有技术相比,具有如下优点和有益效果:
[0073]
1、本发明利用分类网络增加不同层之间的特征图特征融合,减少重复框的出现,分类网络能充分利用特征金字塔中各层之间的关联性,各个预测分支统一成单个分类网络,避免了同一个目标被多个分支检测,而彼此间却没有察觉,而且无需修改检测器的主干网,这样使得其具有更好的泛化性能,可以加快训练速度。
[0074]
2、本发明在输入分类网络前增加特征图的通道数,而不是在靠近输入数据端的主干网中增加特征图通道数,各个分类网络间参数共享,需要训练的参数更少,训练速度更快,各个尺度的目标都可以用于更新分类网络的同一套参数,这样分类网络可以获得更多数量、更多尺度的目标的监督信息用于训练,泛化能力更强,且利于数据量不足时的模型训练。
附图说明
[0075]
图1是本发明方法的流程图;
[0076]
图2是改进后ssd模型的结构示意图;
[0077]
图3是训练改进ssd模型的流程图;
[0078]
图4是iou部分的示意图。
具体实施方式
[0079]
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
[0080]
实施例
[0081]
如图1所示,本发明,一种基于ssd改进的配电房异物检测方法,包括以下步骤:
[0082]
s1、采集配电房中摄像头拍摄的异物图像,建立图像数据集,并对数据集中图像进行预处理;在本实施例中,预处理具体包括:
[0083]
数据增强,包括像素内容变换和空间几何变换,将采集到的异物图像进行随机改变图像亮度,再进行随机扩展。
[0084]
s2、构建改进ssd模型,包括骨干网络和特征金字塔;如图2所示,在本实施例中,改进ssd模型具体包括基础网络层、多尺度网络层、目标检测模块、识别模块以及非极大值抑制模块;基础网络层为基于vgg的基础网络;
[0085]
改进ssd模型具体为:改进基础网络层,其中conv4_3,conv7,conv8_2,conv9_2,conv10_2,conv11_2不同特征层的特征图数量统一为[6,6,6,6,6,6];
[0086]
增加额外的特征提取层;
[0087]
利用分类网络增加不同层之间的特征图联系,减少重复框的出现,分类网络充分利用特征金字塔中各层之间的关联性,各个预测分支统一成单个分类网络,无需修改检测器的backbone主干网;
[0088]
在输入分类网络前增加特征图的通道数;
[0089]
在特征金字塔,改进特征融合方式,提升原有ssd算法的效果,使其充分利用特征,改进特征融合方式具体为:
[0090]
同时通过池化和逆卷积来融合所有高、低层特征图上的特征,各个检测分支提高了各种目标尺度的能力,最终在低层特征图上,融合了来自高层的高语义信息。
[0091]
在本实施例中,特征金字塔各层特征图通道数统一为2816,各层通道数相同,因此各个分支后接的分类网络之间同享同一套权重参数;
[0092]
特征融合前,对特征图做一个归一化操作,采用批量归一化;
[0093]
由于网络结构同享先验框,所以在每个特征图上设置的先验框数量统一为6个;
[0094]
改进的ssd模型输出的先验框的个数为11640。
[0095]
s3、对建立的图像数据集,按比例划分为训练集以及测试集;具体为:
[0096]
按照7:3的比例将异物图像数据集划分为训练集和测试集。
[0097]
s4、利用训练集对改进ssd模型进行训练;在本实施例中,包括:
[0098]
把训练集的图像输入改进ssd模型中进行训练,图像进入ssd网络,提取6个特征图,对每个特征图的每个像素设置先验框,编码,选取正负样本,计算损失函数,更新网络权重,在损失函数收敛后保存并输出最佳网络权重。
[0099]
如图3所示,为改进ssd模型训练流程图。
[0100]
其中,先验框的设计具体为:
[0101]
提取6个特征图,其大小分别为(38,38),(19,19),(10,10),(5,5),(3,3),(1,1),每个特征图上设置的先验框数量统一为6;
[0102]
先验框的设置,包括尺度和长宽比两个方面;对于先验框的尺度,随着特征图大小
降低,先验框尺度线性增加:
[0103][0104]
其中,m指特征图个数,sk表示先验框大小相对于图片的比例,s
max
和s
min
表示比例的最小值与最大值,s
min
与s
max
设置为0.15与0.85;
[0105]
设置宽高比ar∈{1/3,1/2,1,2,3},分别计算得到多阶段特征图对应先验框宽高:
[0106][0107][0108]
其中,为第k层特征图的第a个先验框的高与宽;
[0109]
获取预测框坐标并解码:
[0110]
给定预测框坐标为其中g
x
与gy为预测框中心点的x与y坐标,gw与gh为预测框的宽与高;
[0111]
给定先验框坐标为其中p
x
与py为先验框中心点的x与y坐标,pw与ph为先验框的宽与高;
[0112]
改进ssd模型输出坐标编码信息为其中d
x
,dy分别为检测头输出的水平与竖直方向的平移系数,dw,dh为检测头输出的宽、高放缩系数;
[0113]
根据下列公式获取预测框坐标:
[0114][0115][0116][0117][0118]
其中,为输出的最终待检测目标的解码坐标。
[0119]
本实施例中,正负样本的选取具体为:
[0120]
正样本选取:
[0121]
在训练过程中,先验框与真实框匹配原则:
[0122]
对于图像中的每个真实框,找到与其iou最大的先验框,该先验框与其匹配,保证每个真实框一定与某个先验框匹配;
[0123]
对于剩余未匹配的先验框,若与某个真实框的iou大于0.5,则先验框与这个真实框匹配;
[0124]
负样本选取:
[0125]
挑选出置信度损失confidence_loss排在前面的一批负样本,负正样本数为3:1。
[0126]
本实施例中,改进ssd模型的损失函数依据预测部分的输出结果而设计,包括位置损失和置信度损失,总的目标损失函数为位置损失函数与置信度损失函数的加权和:
[0127][0128]
其中,n是先验框的正样本数量;l
conf
(x,c)为置信度损失函数,α为总损失参数,权重系数α通过交叉验证设置为1,x={1,0},代表某个预测框是否匹配真实框,l
loc
(x,l,g)为位置损失函数,l为预测框,c为标签分类,g为真实框。
[0129]
对于l
loc
(x,l,g)位置损失函数,其采用smooth l1 loss,定义如下:
[0130][0131]
其中,pos为样本中的正例,cx、cy为预测框的中心点坐标,w为预测框的宽,h为预测框的高,为类别为k的第i个预测框与第j个真实框是否匹配,为预测框,为真实框,m为产生损失的特征图对应的序号;
[0132]
对于l
conf
(x,c),其采用softmax loss,定义如下:
[0133][0134]
其中,是一个指示器,当时,表示第i个anchor和第j个ground truth相匹配,且ground truth的类别为p,当时,就代表第i个anchor为负样本,没有匹配的真实框。
[0135]
s5、利用训练好的模型对测试集进行检测,对检测结果进行指标评价;在本实施例中,采用交并比,精确率、召回率以及平均精度评价训练好的模型;
[0136]
交并比:iou=tp/(tp fn fp);
[0137]
精确度:precision=tp/(tp fp)=tp/all detections;
[0138]
召回率:recall=tp/(tp fn)=tp/all ground trusts;
[0139]
其中,tp为算法检测框预测正确的区域;fp为算法检测框预测错误的区域;fn为实际标注框正确但算法检测框未预测到的区域;all detections为算法检测检预测的区域;all ground trusts为实际标注框的区域;如图4所示,是iou部分的示意图。
[0140]
平均精度:
[0141][0142]
其中,r表示召回率,ρ(r)为召回率r的精度值,ρ
interp
(r
n 1
)为召回率大于等于r时,对应精度值ρ(r)中的最大精度值。
[0143]
还需要说明的是,在本说明书中,诸如术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
[0144]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。
对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其他实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。