1.本发明涉及雷达信号分析及识别技术领域,具体而言,涉及一种基于簇心特征构建的平台智能识别方法和系统。
背景技术:
2.随着技术的发展,识别针对的各类型目标更新换代迅速,基于精准识别和后期关联分析等需求,需要针对目标类型或者平台类型识别的相关算法进行研究。传统的方法主要采用针对目标特性进行特征提取,如速度、外形、搭载的装备等进行识别,后期演化为信号特征,例如应答模式、辐射源细微特征等参数,但传统方法面临着特征多变以及提取算法困难等问题,导致利用特征进行识别时,特征提取不全或者错误造成识别准确率不高,需要对数据的特征问题寻找新的方法以提升识别准确率。
3.随着智能处理的流行,机器学习等网络不仅能实现一定程度的推理和差异适应性,数据驱动的可动态优化方式也能够逐渐提升识别的准确率,该类型方法通常需要标签信息,通常利用多类型特征来进行标注,在标注研究过程中发现,对于目标特征的提取,除了已知的传统或细微特征外,还可以从侦察信号数据本身着手,不同的个体产生的数据由于生成流程或者机械差异,在数据上会呈现出相应的个体特征,因此可以针对侦察数据本身寻找新的识别特征。
4.因此,我们需要加大研究的力度,尝试从数据本身着手,在传统特征基础上寻找新的个体特征,从更多新的维度寻找可以用于平台识别的方法,开发新的方法步骤,对整个识别领域的发展具有重要作用。
技术实现要素:
5.本发明旨在至少解决现有技术中存在平台识别过程中,因传统特征多变和细微特征提取算法困难所带来的识别失败或准确率不高的技术问题之一。
6.为此,本发明第一方面提供了一种基于簇心特征构建的平台智能识别方法。
7.本发明第二方面提供了一种基于簇心特征构建的平台智能识别系统。
8.本发明提供了一种基于簇心特征构建的平台智能识别方法,包括以下步骤:
9.s1、对数据进行数据均衡处理;
10.s2、进行簇心特征构建,确定每个参数特征下的簇心值和离群高频簇心值,并按照数值大小对每个参数特征下的簇心值和离群高频簇心值进行排序;
11.s3、进行每条数据的综合簇心标签构建,计算每一条数据在每个参数下对应的数值到该参数下的每个簇心的距离,作为该条数据在该参数下的距离特征标签,结合参数列和簇心顺序,形成综合簇心特征标签;
12.s4、对带标签数据进行神经网络训练,进行特征筛选,保留显性个体特征,形成最终的识别网络。
13.根据本发明上述技术方案的基于簇心特征构建的平台智能识别方法,还可以具有
以下附加技术特征:
14.进一步地,s2包括以下步骤:
15.s21、初始簇心数量拟定;根据样本类型数量确定簇心数的初始值,要求初始值大于类别数且为整数倍,将每个参数特征下的初始簇心数定为n;
16.s22、数值范围上的簇心判断;选定一个参数,将所有数据l条汇集后形成参数列,利用聚类的方式在参数列中形成n个簇,取平均值作为簇心值;
17.s23、簇心合并;对形成的n个簇心进行左导数处理和右导数处理,设置门限为m,将左、右求导变化率低于门限m的相邻簇心判断为同一簇心,将同一簇心的数据合并后重新统计平均值获得新的簇心值,原有的2个簇心值丢弃;
18.s24、判断离群高频簇心;统计每个簇数据出现的频次,设置高频偏离门限y1,频次门限f1,筛选出比当前最大的簇心值超过y1门限的数据,统计频次,当频次比所有簇中排序最后1/4处的簇的频次的比例超过f1时,则该部分筛选出的数据形成一个新的簇,统计平均值形成新的离群高频簇心值;
19.s25、对簇心进行排序;统计该参数下所有形成的簇心和离群高频簇心的数量,然后按照数值的大小对簇心和离群高频簇心进行排序;
20.s26、重复s22-s25,对其他参数特征下的簇心进行提取并排序。
21.进一步地,s21中,每个参数特征下的初始簇心数n选为类别数的2倍。
22.进一步地,s24中,统计每个簇数据出现的频次的计算方法为用每个簇的点数除以总的数据点数l。
23.进一步地,s24中,通过设置多个高频偏离门限和频次门限,得到不同的离群高频簇心值。
24.进一步地,s3中用欧式距离或者曼哈顿距离计算方法计算每一条数据在某个参数下对应的数值到该参数下的每个簇心的距离。
25.进一步地,s4中用transformer深度模型对带标签数据进行神经网络训练。
26.进一步地,s1中进行数据均衡处理的方式为进行类别间数据量均衡。
27.本发明还提供了一种基于簇心特征构建的平台智能识别系统,所述系统包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的程序,所述程序被所述处理器执行时实现如上述技术方案中任一项所述的方法的步骤。
28.综上所述,由于采用了上述技术特征,本发明的有益效果是:
29.能够提高识别准确率。本发明通过簇心提取和自有的筛选算法,包括选用适合的transformer深度模型进行神经网络训练,形成的特征更多更准确,剔除了冗余信息,除了标准参数特征外能够根据雷达数据的脉冲描述字参数量进行特征扩充,能够更全面更准确地表征目标平台特征,通过实际工程对比,识别准确率提高50%以上。
30.能够固化算法流程,提升网络优化速度。相比传统利用知识整理的特征识别方法,本方法不局限处理的原始特征数量,且根据技术和后期发展能够随时增加参数列,但是簇心提取等方法依旧通用,流程更加固定,进行标签更新和神经网络训练时不需要经过更多的算法修改,优化速度更快且适应性更高。
31.能够降低系统成本,适合推广。本发明主要是软件算法更新,不需要涉及硬件等内容,能够降低系统的更新成本,且算法流程固定,在现有算法中直接增加参数列,增加循环
处理的次数即可,修改方便,适合推广。
32.本发明的附加方面和优点将在下面的描述部分中变得明显,或通过本发明的实践了解到。
附图说明
33.本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
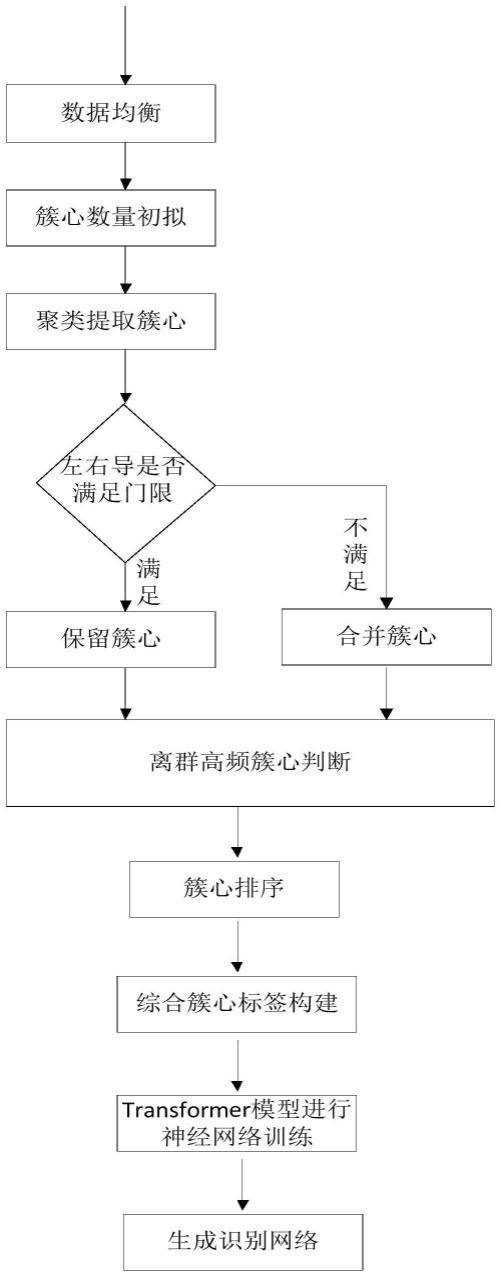
34.图1是本发明一个实施例的基于簇心特征构建的平台智能识别方法的流程图。
具体实施方式
35.为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本技术的实施例及实施例中的特征可以相互组合。
36.在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其它不同于在此描述的方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
37.下面参照图1来描述根据本发明一些实施例提供的基于簇心特征构建的平台智能识别方法和系统。
38.本技术的一些实施例提供了一种基于簇心特征构建的平台智能识别方法。
39.如图1所示,本发明第一个实施例提出了一种基于簇心特征构建的平台智能识别方法,包括以下步骤:
40.s1、对数据进行数据均衡处理;
41.s1中进行数据均衡处理的方式为进行类别间数据量均衡。
42.s2、进行簇心特征构建,确定每个参数特征下的簇心值和离群高频簇心值,并按照数值大小对每个参数特征下的簇心值和离群高频簇心值进行排序;
43.s2包括以下步骤:
44.s21、初始簇心数量拟定;根据样本类型数量确定簇心数的初始值,要求初始值大于类别数且为整数倍,将每个参数特征下的初始簇心数定为n;
45.s21中,每个参数特征下的初始簇心数n选为类别数的2倍。
46.s22、数值范围上的簇心判断;选定一个参数,将所有数据l条汇集后形成参数列,利用聚类的方式在参数列中形成n个簇,取平均值作为簇心值;
47.s23、簇心合并;对形成的n个簇心进行左导数处理和右导数处理,设置门限为m,将左、右求导变化率低于门限m的相邻簇心判断为同一簇心,将同一簇心的数据合并后重新统计平均值获得新的簇心值,原有的2个簇心值丢弃;
48.s24、判断离群高频簇心;统计每个簇数据出现的频次,设置高频偏离门限y1,频次门限f1,筛选出比当前最大的簇心值超过y1门限的数据,统计频次,当频次比所有簇中排序最后1/4处的簇的频次的比例超过f1时,则该部分筛选出的数据形成一个新的簇,统计平均值形成新的离群高频簇心值;
49.s24中,统计每个簇数据出现的频次的计算方法为用每个簇的点数除以总的数据
点数l。
50.通过设置多个高频偏离门限和频次门限,得到不同的离群高频簇心值。
51.s25、对簇心进行排序;统计该参数下所有形成的簇心和离群高频簇心的数量,然后按照数值的大小对簇心和离群高频簇心进行排序;
52.s26、重复s22-s25,对其他参数特征下的簇心进行提取并排序。
53.s3、进行每条数据的综合簇心标签构建,计算每一条数据在每个参数下对应的数值到该参数下的每个簇心的距离,作为该条数据在该参数下的距离特征标签,结合参数列和簇心顺序,形成综合簇心特征标签;
54.s3中用欧式距离或者曼哈顿距离计算方法计算每一条数据在某个参数下对应的数值到该参数下的每个簇心的距离。
55.s4、对带标签数据进行神经网络训练,进行特征筛选,保留显性个体特征,形成最终的识别网络。
56.s4中用transformer深度模型对带标签数据进行神经网络训练。
57.本发明第二个实施例提出了一种基于簇心特征构建的平台智能识别方法,且在第一个实施例的基础上,如图1所示,包括:
58.首先,进行数据均衡处理。对于雷达侦察数据,簇心选取受数据量影响,因此必须做数据均衡,具体均衡方式只要做类别间数据量均衡,对于较少的数据的类的数据进行数据复制,复制的数据需要加扰动误差,按照人工经验,通常叠加5%-10%的随机数值扰动误差。
59.其次,进行簇心特征构建。主要包括六个步骤:
60.第一是初始簇心数量拟定。根据样本类型数量确定簇心数的初始值,要求初始值大于类别数且为整数倍。根据经验可将每个参数特征下的初始簇心数定为n,通常选为类别数的2倍。
61.第二是数值范围上的簇心判断:选定一个参数,将所有数据l条汇集后形成参数列,利用聚类的方式在参数列中形成n个簇,取平均值作为簇心值。
62.第三是簇心合并:对形成的n个簇心进行左导数处理和右导数处理,根据人工经验设置门限为m,将左、右求导变化率低于门限m的相邻簇心判断为同一簇心,将同一簇心的数据合并后重新统计平均值获得新的簇心值,原有的2个簇心值丢弃。
63.第四是对离群高频簇心的判断:对特别出现的一些高频离群数值,它们是因为数据量较小可能在前一步聚类和合同时被掩盖,但由于雷达脉冲的离散性,该部分数据也能够体现数据特征,因此需要对数据聚类后的参数列进行再次处理。具体步骤为:统计每个簇数据出现的频次,计算公式为每个簇的点数除以总的数据点数l。根据人工经验设置高频偏离门限y1,频次门限f1,筛选出比当前最大的簇心值超过y1门限的数据,统计频次,当计算出的频次比所有簇中排序最后1/4处的簇的频次的比例超过f1时,则该部分筛选出的数据形成一个新的簇,统计平均值形成新的离群高频簇心值。同理,设置高频偏离门限y2,频次门限f2筛选出比所有簇中排序最后1/4处的簇的频次的比例超过f2的数据,则该部分筛选出的数据形成一个新的簇,统计平均值形成新的离群高频簇心值。
64.第五是对簇心进行排序:对该参数下所有形成的簇心和离群高频簇心统计数量,然后按照数值的大小对簇心进行排序。
65.第六是对其他参数特征下的簇心按照同样的原理进行提取并排序。
66.其后,进行每条数据的综合簇心标签构建:计算每一条数据在某个参数下对应的数值到该参数下的每个簇心的距离,可以用欧式距离或者曼哈顿等类似距离计算方法,作为该条数据在该参数下的距离特征标签,作为样例本实施例采用的是欧式距离。用同样的方法计算该数据在每一个参数下的距离特征,结合参数列和簇心顺序,形成综合簇心特征标签。
67.最后,对带标签数据进行神经网络训练。对所有数据处理后,由于多参数可能具有关联性而造成综合簇心标签具有一定的冗余性,选用transformer深度模型来进行神经网络训练,内部的注意力机制能够自动进行特征筛选,保留显性个体特征,形成最终的识别网络。
68.本发明第三个实施例提出了一种基于簇心特征构建的平台智能识别系统,且在上述任一实施例的基础上,如图1所示,所述系统包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的程序,所述程序被所述处理器执行时实现如上述任一实施例中所述的方法的步骤。
69.在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或实例。而且,描述的具体特征、结构、材料或特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
70.对于本领域的技术人员来说,本发明可以有各种更改和变化,比如进行簇心值计算的方法除了利用平均值,因为聚类后的数据差异不大,同样也适用最大值、最小值、或者方差等方法,还可以扩展到其他的数据统计方法;在进行距离特征计算时,除了本发明样例中的欧式距离,还可以扩展曼哈顿、切比雪夫距离计算方法;在进行网络训练时,本发明使用的transformer深度模型是经过测试后的最优模型,改换其他lgmb等分类性质的网络也同样适用,只是识别准确率会有所降低。在特征应用时,除了利用智能网络训练的方法,生成的簇心特征同样也可以用作常规识别特征来进行识别。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。