1.本发明涉及地球物理技术领域,尤其涉及一种地震缺失信号的人工智能高效恢复与补全方法。
背景技术:
2.在地震勘探中,对地震数据高效处理和地层信息分析依赖于优质的地震信号。而受景区保护、河流、工厂等阻碍因素的影响,采集到的地震数据经常是不完整的。这些阻碍因素,部分是由于采集区域地势复杂采集设备无法布置,也可能是由于采集设备的损坏等原因,最终导致地震数据缺失部分道集。这种数据的缺失会对后续的地震精确成像、构造、断层、储层等地质数据解释工作产生不利影响。由于缺失道集的位置是随机和普遍的,所以需要对地震数据做检测和缺失部分恢复与补全处理。
3.传统的数据补全方法有低秩基于矩阵的数据补全算法,频域处理,压缩感知,空域插值等。传统方法中每种不同的数据都要经过不同的重构处理,或是欠定方程组优化求解过程,或是频域处理法,或插值法,其过程需要费时做优化,或者无法有效结合周围信号的变化趋势。传统方法中需要人员手动调参过程较多,处理过程和处理结果都会因不同的重构参数、处理人员的主观选择等等可变而异,因此亟需一种地震缺失信号的人工智能高效恢复与补全方法。
技术实现要素:
4.针对现有技术中所存在的不足,本发明提供了一种地震缺失信号的人工智能高效恢复与补全方法,克服了在传统方法中,地震数据补全中需要人员手动调参过程较多,数据多变处理需人为监管,耗时较多等问题。
5.本发明的上述技术目的是通过以下技术方案得以实现的:
6.一种地震缺失信号的人工智能高效恢复与补全方法,包含以下步骤:
7.步骤s1,利用现有的地震数据,做出训练数据集;
8.步骤s2,搭建对像素值处理的transformer网络;
9.步骤s3,利用步骤1中的数据集训练网络,在每个epoch训练完之后输出准确率和相关的评价标准,保存模型更新结果,最终评估模型的效果;
10.步骤s4,将训练好的模型用于缺失数据的补全,补全过程需要将源数据切分成48x48 大小的小块,且最终可以将切分出的数据拼接到原数据的对应位置。
11.本发明进一步设置为:
12.在步骤s1中:
13.先将segy文件用python读取为矩阵,对地震数据做全局归一化处理,每个数据使用统一的缩放比例,全局归一化到0-255;
14.然后将数据矩阵做切块处理,切块在矩阵上步距为块大小的1/2,整个数据作为dataloader;
15.最后在dataloader以batch数量读取时,输出两组矩阵,两组形状大小相同,各维度分别为batch、channel、width、height,第一组是源数据作为标签数据,第二组对源数据做随机道置零,置零的概率为2%-8%,作为缺失道数据。
16.本发明进一步设置为:
17.在步骤s2中:
18.先构建模型的head部分,将输入矩阵使用64个大小为3的卷积核映射出64个features,再将结果矩阵经过两个resblock,经过此模块进行前期的特征变换,将输出的64个矩阵作为多通道的特征;
19.然后构建transformer模块,先将输入的数据用patch_dim参数的核展平成二维数据,接着构建encoder,再构建decoder,之后使用fold将数据转换成原大小;
20.然后构建模型的tail部分,将64个features使用卷积核还原成一个feature,作为最终模型的输出。
21.本发明进一步设置为:
22.在步骤s4中:
23.先将原数据以矩阵形式读入python中;
24.然后将数据使用torch提供的unfold切分成大小为patch的块,切分步距为patch的1/2;
25.然后将所有切分的数据块送入步骤s2搭建的模型中做前向传播,得到模型对所有小块处理的结果,并将数据四边处理的结果和数据中间处理的结果区分开;
26.最后将切分的中间处理结果中所有数据拼接起来,其中拼接时只取处理块的中间部分做拼接,之后将四边处理的结果拼接回对应的位置,从切分数据经网络处理的结果进行拼接后,最终保留的数据为阴影部分。
27.本发明具有以下优点:
28.本发明是一种地震数据智能补全模型,网络是基于attention机制的transformer模型作为骨干网络,训练过程可将不同数据的地震种类的数据集合并在一块,以达到数据特征的多样性,通过大量的数据和若干次迭代训练,最终可得到一个通用性较强的网络模型。
29.在传统数据补全领域,时域补全方式往往根据缺失数据周围的几块数据对确实数据进行预测,这种方法可能无法利用潜伏在较长长距离的趋势信息,在地震信号中数据之间的关联系是比较强的,所以使用transformer方法可来融合缺失数据周围的信息。其次可以使用一种统一的模型对缺失的数据进行补全,省去了传统数据补全中比较繁琐的过程。另外在处理结果中可以对有些部分的信号有额外效果。模型可以提升地震数据质量、减少人工处理环节、优化地震信号,在地震数据处理方面有着重要的作用。
附图说明
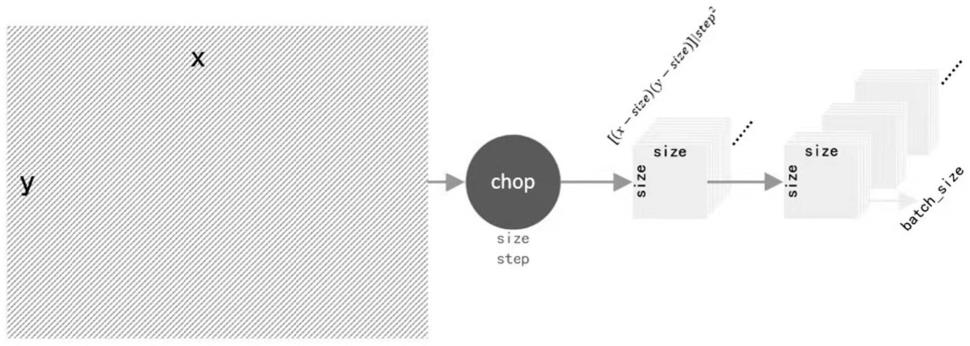
30.图1为数据块切分过程示意图;
31.图2为残缺地震信号智能补全模型的主流程图;
32.图3为header内部结构图;
33.图4为transformer模型图;
34.图5为切分位置与步距示意图;
35.图6为模型处理后拼接示意图;
36.图7为模型处理的部分截图结果,其中(a)是缺失道数据,(b)是模型补全数据,(c) 是原始数据数据;
37.图8为模型处理的另一部分截图结果,其中(a)是缺失道数据,(b)是模型补全数据, (c)是原始数据数据。
具体实施方式
38.下面结合附图及实施例对本发明中的技术方案进一步说明。
39.本发明是一种基于transformer架构的深度学习模型,输入网络和输出网络都使用了自定义的归一化方法,旨在训练一种统一的残缺地震信号智能补全模型,是一种端到端的模型,在不同数据值范围的地震数据都可以使用一种方法进行补全。克服传统方法中地震数据补全中数据多变处理需人为监管,耗时等问题。本方法的主要的流程就是构建训练数据集,数据预处理,训练模型,使用训练好的模型分块推理,将分块数据拼接回原位置。
40.通过搭建transformer网络模型,包含对输入数据的编码,transformer块传播,以及输出解码;训练过程,将现有的地震数据做预处理和块切分,并生成相应的缺失道数据,并将数据组成dataloader数据集格式;训练过程确定归一化方法、学习率、batch_size、 path_size、训练数据集、迭代次数等。接着开始训练,训练过程主要使用标签数据和网络的输出来做模型的参数调整,这样迭代来使transformer网络从数据中学到数据补全行为;推理过程将数据切片成相应大小的patch大小,推理的的步数数据使用半个patch步,并且记录patch位置,在推理完成之后按照相应的位置选取每个patch的中心将结果放回数据的原位置。
41.具体步骤包括:步骤s1.利用现有的地震数据,做出训练数据集,本发明使用 transformer,需要输入数据中的每一块大小一致,遍历全数据。本步骤最终得到一个 dataloader可以输出随机置零的道。
42.本步骤的详细过程如下:
43.步骤11:将segy文件用python读取为矩阵,对地震数据做全局归一化处理,每个数据使用统一的缩放比例,全局归一化到0-255。
44.步骤12:将步骤11的数据矩阵做切块处理,块大小可自定义,一般为48或96,切块在矩阵上步距为块大小的1/2,整个数据作为dataloader,数据准备示意图如图1所示。
45.步骤13:在dataloader以batch数量读取时,输出两组矩阵,两组形状大小相同,各维度分别为batch、channel、width、height,第一组是源数据作为标签数据,第二组对源数据做随机道置零,置零的概率为2%-8%,作为缺失道数据。
46.步骤s2.搭建对像素值处理的transformer网络,确定模型的超参数batch_size、epoch、 lr、patch_size、patch_dim等,模型整体的结构如图2所示。
47.本步骤的详细过程如下:
48.步骤21:构建模型的head部分,如图3所示,将输入矩阵使用64个大小为3的卷积核映射出64个features,再将结果矩阵经过两个resblock。经过此模块进行前期的特征变换,将输出的64个矩阵作为多通道的特征。
49.步骤22:构建transformer模块,先将输入的数据用patch_dim参数的核展平成二维数据,接着构建encoder,如图4左侧数据经过self-attention和全连接层,两个过程都有res 机制,这便是一个encoder块。将此块重叠6次便是eecoder模块。再构建decoder,如图 4右侧数据依次经过self-attention、attention和全连接层,过程中也都存在res机制,将此块重叠6次便是decoder模块。之后使用fold将数据转换成原大小。
50.步骤23:构建模型的tail部分,将64个features使用卷积核还原成一个feature,作为最终模型的输出。
51.步骤s3.用步骤一中准备好的数据集训练网络,在每个epoch训练完之后输出准确率和相关的评价标准,保存模型更新结果。最终评估模型的效果。
52.步骤s4.将训练好的模型用于缺失数据的补全,补全过程需要将源数据切分成48x48 大小的小块,且最终可以将切分出的数据拼接到原数据的对应位置。
53.本步骤的详细过程如下:
54.步骤41:先将原数据以矩阵形式读入python中。
55.步骤42:将数据使用torch提供的unfold切分成大小为patch的块,切分步距为patch 的1/2,需要将数据的四边单独处理一遍,其切分的数据示意图如图5。
56.步骤43:将所有切分的数据块送入步骤2搭建的模型中做前向传播,得到模型对所有小块处理的结果,并将数据四边处理的结果和数据中间处理的结果区分开。
57.步骤44:将切分的中间处理结果中所有数据拼接起来,其中拼接时只取处理块的中间部分做拼接,之后将四边处理的结果拼接回对应的位置,从切分数据经网络处理的结果根据图6所示的拼接方式拼接,最终保留的数据为阴影部分。
58.以上为模型的整个处理过程。模型处理的部分截图结果如图7和图8所示,各图中的 (a)为缺失数据(b)为模型补全数据(c)为无缺失数据。可以看出模型很好的补全了缺失道的数据,并且将原来其他的部分数据高效保留,图7所示数据中对数据除了很好完成数据补全的任务,额外的,模型对数据的嘈杂部分有一些平滑效果。由于此模型使用 transformer模型,能更好的将缺失道周围的数据用attention机制建模起来,预测的效果会更加切合实际信号,如图8中所示的数据的幅值和原数据对比更加清晰,可以看到补全数据有效的综合了周围的其他数据,有更高的可信度。模型的整个流程是将所有数据切成块大小,所以可以适应于任何大小的地震数据,且输入数据经过归一化,可以对不同值域的数据进行处理,可作为一种通用的地震数据缺失道补全方法。此模型作为深度学习模型,在现代gpu等计算架构的支持下可以以更快的速度去实现对数据的补全,可以大大节省地震数据缺失道补全所需时间。
59.最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。