技术特征:
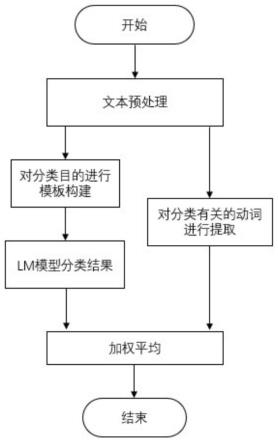
1.一种基于提示学习融合关键词的法律文书分类方法,包括如下步骤:步骤1:对文本数据进行分词、去停用词、裁判文书特有词处理以及句子长度统一;步骤2:根据分类要求设置不同的提示模板,通过预测结果选取最优模板。提示函数能够将输入文本转换为相应的提示,从而对下游任务进行重构;步骤3:根据答案空间以及特征词映射到每个类别;步骤4:通过bert模型预测每个类别的概率,实现分类bert模型的嵌入层包含词嵌入、位置嵌入和句子嵌入。2.如权利要求1所述的一种基于提示学习融合关键词的法律文书分类方法,其特征在于:步骤1具体包括:对文本数据进行分词、去停用词、裁判文书特有词处理以及句子长度统一;文本预处理是将收集到的文本数据进行统一编码,然后用分词程序把文本分成一个个单词;数据以中文形式,因此将中文文本分割成一个个词语,最后利用停用词表去除与文本分类无关的词语;对于中文文本分词,不像英文文本单词之间有天然的空格,中文则需要对每个字进行组合得到正确的词;停用词是一类在文本中普遍出现但又没有具体含义的词语,由于这些词用处很小,去除这些词对文本整体含义几乎不产生影响,反而可以改善模型学习的效果。3.如权利要求1所述的一种基于提示学习融合关键词的法律文书分类方法,其特征在于:步骤2具体包括:根据分类要求设置不同的提示模板,通过预测结果选取最优模板;提示函数能够将输入文本转换为相应的提示,从而对下游任务进行重构;模型不再是预测输入文本对应各个标签的概率来获得输出,而是计算各文本在提示中出现的概率;通过采用手动构建一个模板的方式来确定提示函数;首先对训练集中所有标记出现的次数进行了统计,在对统计结果进行分析之后,选取了一些符合任务目的,并且没有情感倾向的标记组成相应的模板,最后确定提示函数。4.如权利要求1所述的一种基于提示学习融合关键词的法律文书分类方法,其特征在于:步骤3具体包括:根据答案空间以及特征词映射到每个类别;答案空间是提示模型输出的所有答案集合,在答案空间中寻找最有可能的预测结果;收集从[mask]中获取前10个提示字,提示字中不一定都是对分类有增益效果的,有些会带来一定的噪声;将所有提示字进行统计,并对提示词与类别进行相关性分析,可以得到文本最有可能的分类情况。5.如权利要求1所述的一种基于提示学习融合关键词的法律文书分类方法,其特征在于:步骤4具体包括:通过bert模型预测每个类别的概率,实现分类bert模型的嵌入层包含词嵌入、位置嵌入和句子嵌入;训练样本经过预处理后输入到嵌入层中,经过相应的计算得到三个不同的特征向量,再将三个向量的相加之和作为嵌入层输出的特征向量;为了缓解过拟合问题、优化数据分布,模型在嵌入层输出之前,会进行dropout和归一化处理;dropout使得模型按照设定的概率随机丢弃部分特征,使得模型在训练过程成生成不同的网络结构,从而增强模型的泛化能力;归一化是将输出数据归一化为标准正态分布,使得数据保持稳定,避免因训练过程中参数变化而引起的内部协变量偏移问题;transformer层是bert模型的核心,由多个编码器端的transformer块堆叠而成;每个transformer块中包含一个多头注意力机制和
一个前馈网络,并且中间的输出数据同样会经过dropout和层归一化处理来保证数据的稳定;注意力机制是transformer中一个特殊的结构,由“query-key-value”三个矩阵(w
q
,w
k
,wv)组成,用来确定不同位置之间相互影响从而得到输出数据;对于输入的序列x,首先与三个矩阵进行点积运算,得到对应的查询矩阵q、键矩阵k和值矩阵v;其中为输入序列的长度,d
k
表示注意力矩阵的维度,注意力机制的计算过程见公式:为了确定输入数据中所有位置对单个位置的影响,注意力机制将q矩阵中的第i个向量与k矩阵中的所有向量进行点积,得到所有位置对第i个位置影响程度的打分;通过矩阵对q矩阵与k矩阵转置的进行点积,即可快速计算出所有位置之间影响程度的得分;然后将得分除以进行缩放处理,使得梯度稳定;再使用softmax函数计算出各个位置之间影响程度的占比,从而得到注意力矩阵,其计算方式为:softmax([z1,z2,
…
,z
n
])=[q1,q2,
…
,q
n
]
ꢀꢀꢀꢀ
(2)由于在数据预处理过程中,对于长度较小的文本进行了填充处理;为了避免填充位置对结果造成影响,在计算注意力矩阵之前会根据预处理过程中得到的内容序列,将填充位置上的得分设置为负无穷;因为经过softmax函数计算之后其对应位置上的值为0,从而排除填充处理对结果产生影响;最后将得到的注意力矩阵与v矩阵进行点积,从而完成对输入数据的特征提取,得到更高维度的数据特征表示;从注意力机制的计算过程可以看出,注意力矩阵是根据各位置与前后所有位置之间的影响程度得出,因此得到的结果是双向的特征表示;多头注意力机制是将多个注意力机制的输出进行拼接,再使用一个线性层w转换为对应的输出维度;多头注意力机制能够增加transformer中的注意点,有助于网络提取到更丰富的本文特征;掩码语言模型(mask language model,mlm),通常是覆盖句子中固定百分比的词,模型期望通过句子中其它没有覆盖的词得到被覆盖的词;训练出的模型具有理解上下文语义的特性,具有根据出现的词来预测中间词的能力;bert模型利用掩码语言模型进行训练,在句子输入到bert前,有15%的词被[mask]随机替换,其中具体80%的词真正被[mask]替换,10%的词被换成别的词,10%的词不变;加上掩码机制的bert再经过一个全连接层,用嵌入矩阵乘以输出层权重矩阵,得到转换成词汇表维度的结果,再用softmax计算词汇表中每个词的概率;损失计算只考虑预测的[mask],忽略其它没有覆盖的词。
技术总结
一种基于提示学习融合关键词的法律文本分类方法。首先,需要对文本进行分词、去停用词等预处理,通过长截短补的方式将文本进行同一处理;然后,经过构造提示模板,让预测结果映射到类别域中,而类别域为答案空间的设定,通过同义词表查询结果的加权平均得到;同时,利用实体识别的方式将文本中的动词选取出来,一同进行分类结果的判定;最后,数据分为训练集、验证集与测试集,在训练集中利用BERT模型和掩码语言模型进行分类预测,预测结果为最大概率对应类别,考虑关键动词的提取结果,将融合值作为最终的预测结果,并在验证集对训练得到的模型进行验证。本发明节省了模型训练时间,可以直接给一个未知标签的文本进行大致类别分析。直接给一个未知标签的文本进行大致类别分析。直接给一个未知标签的文本进行大致类别分析。
技术研发人员:洪榛 朱琦 刘涛 傅金波 金聪 张明德
受保护的技术使用者:浙江工业大学
技术研发日:2022.11.18
技术公布日:2023/2/3
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。