一种基于yolo的可回收物分类方法、系统及存储介质
技术领域
1.本发明属于人工智能检测技术领域,具体涉及一种基于yolo的可回收物分类方法、系统及储存介质。
背景技术:
2.随着时代的进步和科技的发展,人们的物质生活水平正在朝着高节奏、高质量、高效率的方向前进,但是随之而来的,是人们产生的生活垃圾正以不可忽视的速度威胁着我们赖以生存的地球。在新技术迅速发展的今天,如何精准做到可回收物分类处理,如何高效完成可回收物分拣,如何实现资源合理利用,塑造清洁、绿色、可持续的生活方式是当前亟需解决的问题。
3.近几年,采用机器分拣的方式来处理可回收物,提升了分拣效率,这得益于深度学习目标检测算法的快速迭代升级。2012年,alexnet算法一举拿下当年的imagenet竞赛冠军,这不仅横扫传统的机器学习,也开启了深度学习的大门。随后,vgg-net、googlenet、resnet等网络及变体的出现加快了分类、检测算法的进程。至今为止,目标检测算法主要包括两大类,一是以目标检测开山鼻祖r-cnn为首的两阶段检测算法,包括fast r-cnn、r-fcn,另一类是单阶段检测算法,例如ssd(single shot multibox detector)和yolo。这些经典算法及其变体,在各种领域的目标检测任务中取得了可喜的成果,然而,如果将这些取得优秀成绩的算法直接应用于可回收物的分类,却因检测精度或速度的不足难以取得令人满意的结果。因此,对yolo算法进行有效的改进升级,使其更好适用于可回收物的分类上,是当下亟需实现的任务。
技术实现要素:
4.本发明的目的在于解决上述问题,提出了一种基于yolo的可回收物分类方法、系统及储存介质。
5.为了达到上述目的,本发明解决上述技术问题的技术方案如下:
6.一种基于yolo的可回收物分类方法,包括以下步骤:
7.步骤100.构建分类网络模型;
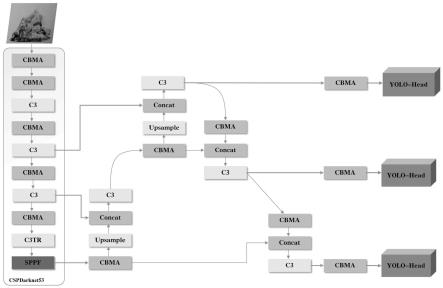
8.所述分类网络模型以yolov5网络作为基础网络,采用cspdarknet53框架,所述cspdarknet53框架包括c3、sppf和cbma中的卷积下采样层,并在其基础上更换损失函数为siou,引入meta-acon激活函数和transformer encode结构,所述激活函数meta-acon与conv2d、batch normalization结合为cbma组件;所述transformer encode结构,在原有c3基础上形成c3tr层;
9.步骤200.对所构建的分类网络模型进行训练,获得训练好的分类网络模型;
10.步骤300.将待测图片或视频流输入到训练好的分类网络模型里,获取检测结果。
11.进一步地,所述步骤100中所述yolov5网络采用cnn对目标进行端到端的检测,输入任意大小的3通道rgb图片,将图像重定义为640*640作为分类网络的输入。
12.进一步地,所述cnn网络将图片切分为s*s个网格,每个网格负责检测中心点落在该网格内的目标,输出3层,分别为20*20、40*40、80*80的特征图,每一层最终预测值为s*s*[b*(5*n)]大小的张量,其中,b为每一个网格对应的检测框数量,5为每一个检测框的坐标信息(x,y,h,w)和物体置信度信息,n为物体种类数;其中,x表示检测框左上角点的x坐标信息;y表示检测框左上角点的y坐标信息;w表示检测框的宽度信息;h表示检测框的高度信息。
[0013]
进一步地,所述预测值通过非极大值抑制筛选出符合要求的检测框,生成最终的检测数据框,包括检测框位置、物体类别信息、物体置信度信息。
[0014]
进一步地,所述步骤200对所构建的分类网络模型进行训练,具体包括以下步骤:
[0015]
步骤201.获取可回收物图像,并对可回收物图像中的物体进行标注;
[0016]
步骤202.对所述数据集进行预处理,将预处理后的数据集划分为训练集和测试集;
[0017]
步骤203.将上述训练集和测试集图片输入到分类网络模型里,进行数据增强和多轮迭代训练,保存最优模型,得到训练好的分类网络模型。
[0018]
进一步地,所述步骤201中对可回收物图像中的物体进行标注,具体包括:对图像进行标注,得到xml格式标签文件,随后利用标签格式转换脚本将其转换为yolo格式的标签文件。
[0019]
进一步地,所述步骤202中对所述数据集进行预处理,包括采用数据增强方法对数据集进行扩充,所述数据增强方法包括但不限于:图片翻转、旋转、缩放、移位、模糊、马赛克、混合增强。
[0020]
本发明还提出了一种基于yolo的可回收物分类系统,包括:数据获取模块、物体检测模块;
[0021]
数据获取模块用于获取待检测图片或视频流;
[0022]
物体检测模块用于将待测图片或视频流输入到训练好的智能分类网络模型里,获取检测结果。
[0023]
进一步地,所述物体检测模块中包括分类网络模型,所述分类网络模型以yolov5网络作为基础网络,采用cspdarknet53框架,在其基础上将原有的损失函数更换为siou;将原有的激活函数更换为meta-acon,激活函数meta-acon与conv2d、batch normalization结合为cbma组件;并引入transformer encode结构,在与原有c3基础上形成c3tr层。
[0024]
本发明还提出了一种计算机可读存储介质,所述计算机可读存储介质被配置成存储程序,所述程序被配置成执行上述所述基于yolo的可回收物分类方法。
[0025]
现有技术相比,本发明具有如下技术效果:
[0026]
(1)本发明损失函数采用siou,充分考虑了真实边界框与预测检测框之间的空间方向因素,可使目标回归框更加稳定,降低预测框“四处游荡”,减少漏检误检情况发生;
[0027]
(2)本发明将激活函数meta-acon架构代替原yolov5的silu激活函数,可以高效实现对神经网络动态的调节及学习线性与非线性,发挥多层网络提取特征的优势,使其更好的适应复杂多变的垃圾形态、遮挡情况;
[0028]
(3)本发明在采用c3完成特征提取基础上,加入transformer encoder模块,形成c3tr结构,增强获取上下文的语义信息和特征提取的能力;且每一个transformer encoder
with 3convolutions(简称:c3)、spatial pyramid pooling-fast(简称:sppf)和cbma中的卷积下采样层,并在其基础上将损失函数更换为scylla-iou(简称:siou),引入meta-activate or not(简称:meta-acon)激活函数结构形成conv2d_batch normalization_meta-acon(简称:cbma),并引入transformer encoder结构形成c3 with transformer encoder(简称:c3tr)层。
[0045]
其中,cspdarknet53框架中c3包括3个标准卷积层和1个bottleneck模块,通过残差结构充分学习图片特征,降低因网络层数过深带来的特征损失影响。sppf是空间金字塔池化的升级版,能将任意大小的特征图转换成固定大小的特征向量,更好地适应多种规格图片输入检测。cbma中的卷积下采样层用来缩小图层大小,一是为了减少计算量,二是为了增大感受野,使后面的卷积层能够学到更加全局的信息。cbma可以高效实现对神经网络动态的调节及学习线性与非线性,发挥多层网络提取特征的优势,使其更好的适应复杂多变的垃圾形态、遮挡情况。c3tr可以进一步捕捉特征之间的关系,增强全局特征性质。
[0046]
在本发明的实施例中,网络入口为任意尺度大小的图片,随后对图片进行尺寸调整操作,分类网络的输出结果为一个张量,维度为:s*s*[b*(5*n)],其中,s为每个图片划分的网格数,b为每一个网格对应的检测框数量,5为每一个检测框的坐标信息(x,y,h,w)和物体置信度,n为物体种类数。在检测框的坐标信息(x,y,h,w)中,x表示检测框左上角点的x坐标信息;y表示检测框左上角点的y坐标信息;w表示检测框的宽度信息;h表示检测框的高度信息。
[0047]
其中,表达式s*s*[b*(5*n)]的含义具体为:
[0048]
(1)每个网格会对应b个不同大小的检测框,用于锁定该中心点落在该网格内的物体。
[0049]
(2)每个检测框都对应一个分值,代表该检测框是否有物体及置信度:
[0050][0051]
其中,bbox
置信度
为该检测框中含有物体的置信度即检测框的预测概率,p(object)为有物体落入网格中的概率1或0,1为落入,0为不落入,iout
prr
uetdh为预框与真实框之间的iou值。
[0052]
(3)每个网格会对应m个概率值p,在其中找出最大概率值对应的类别,就认为网格中包含该物体或者该物体的一部分。
[0053]
在本发明的具体实施例中,yolo算法采用cnn对目标进行端到端的检测,输入任意大小3通道rgb图片,图像调整至640*640作为网络的输入。所述cnn网络图片分为s*s个网格,每个网格负责检测中心点落在该网格内的目标,输出3层,分别为20*20、40*40、80*80的特征图,每一层最终预测值为s*s*[3*(5*n)]大小的张量,其中,3为每一个网格对应的检测框数量,5为每一个检测框的坐标信息(x,y,h,w)和物体置信度,n为物体种类数。在检测框的坐标信息(x,y,h,w)中,x表示检测框左上角点的x坐标信息;y表示检测框左上角点的y坐标信息;w表示检测框的宽度信息;h表示检测框的高度信息。
[0054]
更为具体的,所述预测值通过非极大值抑制筛选出符合要求的检测框,生成最终的检测数据框,包括检测框位置、物体类别信息、物体置信度信息。
[0055]
在判断检测精度时,用到了交并比(intersection over union,简称lou)函数来
评价目标检测算法好坏。交并比函数做的是计算真实边界框和预测检测框交集和并集之比,其计算公式为:
[0056][0057]
该表达式中p代表预测边界框,g代表真实框,area代表两者的面积。但是,常规的iou对目标物体的空间坐标信息不敏感,存在一定的局限性,本实例采用siou考虑到真实边界框与预测检测框之间的空间方向因素,可使目标回归框更加稳定,降低预测框“四处游荡”,减少漏检误检情况发生。
[0058]
在本发明的实施例中,采用siou损失函数,siou损失函数较yolov5使用的complete iou(ciou)增加了角度损失(angle cost),还包括距离损失(distance cost)、形状损失(shape cost)和iou损失(iou cost),其具体公式为:
[0059][0060]
其中,δ为distance cost,具体为预测边界框中心点与真实框中心点的距离;ω为shape cost,具体为预测边界框与真实框形状的相似程度;iou为iou cost,具体为预测边界框与真实框之间的iou值;而δ又包括angle cost,具体为预测边界框中心点与真实框中心点之间的连线和两点高度垂直线形成的角度。
[0061]
使用对比实验进一步验证siou的有效性,如下表:
[0062][0063]
表中的
×
为不添加siou模块,√添加siou模块。map@0.5、map@0.5:0.95、pr、r为评价算法性能指标。
[0064]
其中,pr为精确度(precision,简称:pr),是指分类器判定的正例(包括真正实例tp和误判的假真正实例fp)中真正实例样本(tp)的比重,反应所有检测出目标中检测正确的概率。r为召回率(recall,简称r),又称查全率,是指测试集中所有正样本样例(tp和fn)中,被正确识别为正样本(tp)的比重。map(mean average precision),指的是从类别的维度对所有类别的ap进行平均,因此可以用来评价多分类器的性能。用map@0.5(iou阈值为0.5)和map@0.5:0.95(iou阈值从0.5到0.95,步长为0.05)二者综合来评估模型好坏。其中,ap指的是单一类别下,每个recall对应的precision值求均值,即平均精准度。
[0065]
从上表数据中可以看出,本发明实施例提出的siou替换传统的iou在检测精确度、召回率上都有较大的改进,分别提升了5.4%和5.8%。图2进一步表明,siou相较传统iou而言,漏检情况减少并且检测概率有较大提升。
[0066]
在本发明的实施例中,引入了meta-acon激活函数,与conv2d、batch normalization结合为conv2d_batch normalization_meta-acon(cbma)架构,如图3所示。分类网络模型中使用了激活函数用来决定某个神经元是否被成功激活,即这个神经元接收到的信息是否有用,这一特点使得神经网络具有强大的非线性拟合能力。本实施例中的meta-acon激活函数是在activate or not(简称:acon)系列激活函数上一种改进,通过转
换因子β来控制激活函数的线性/非线性这一特性,其中,β=g(x)。其中,acon激活函数为:
[0067]facon-c
(x)=(p
1-p2)x
·
σ(β(p
1-p2)x) p2x
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0068]
其中,p1和p2使用的是两个可自适应调整的学习参数,σ为sigmoid函数。将激活函数meta-acon架构代替原yolov5的silu激活函数,可以高效实现对神经网络动态的调节及学习线性与非线性,发挥多层网络提取特征的优势,使其更好的适应复杂多变的垃圾形态、遮挡情况。
[0069]
在本发明的实施例中,采用c3完成特征提取基础上,加入transformer encoder模块,形成c3tr结构,增强获取上下文的语义信息和特征提取的能力。如图4所示,transformer encoder模块主要由两部分组成,一部分是多头注意力(mutil-head atteneion)结构,一部分是多层感知机(multilayer perceptron,mlp)结构。对于transformer encoder模块而言,查询的信息q(query)、被查询信息的关键限制向量k(key)、最终查询得到的内容v(value)三个矩阵来自同一输入,对应的就是进入mutil-head atteneion模块的输入矩阵。
[0070]
首先,将q和k进行点乘操作,为了防止结果过大,会除以一个尺度标度其中dk为query和key向量的维度,最后通过softmax将结果归一化,再乘以矩阵v得到权重求和得表示。如下式:
[0071][0072]
具体的,上式中,q指要查询的信息,k指被查询信息的关键限制向量,v指最终查询得到的内容。
[0073]
从图4还可以看出,每一个transformer encoder又都使用了残差结构降低梯度爆炸和梯度消失的问题,进一步解决了网络过深带来的其他负面影响,减少因网络层过深带来的特征丢失负面影响。
[0074]
步骤200.对所构建的分类网络模型进行训练,获得训练好的分类网络模型。
[0075]
图5是根据本发明实施例的分类网络模型训练方法图,包括以下步骤:
[0076]
步骤201.获取可回收物图像,并对可回收物图像中的物体进行标注。
[0077]
在现实生活和网络中采集不同环境、不同尺寸、不同角度下的可回收物图像,包括易拉罐、玻璃瓶、纸张等,并对图像通过标签标注软件进行标注,得到xml格式标签文件,随后利用标签格式转换脚本将其转换为yolo格式的标签文件。如图6所示,子图a为可回收物真实图像,子图b为图像的xml格式标签文件,子图c为图像的yolo格式标签文件。
[0078]
步骤202.对所述数据集进行预处理,将预处理后的数据集划分为训练集和测试集。
[0079]
在本发明的具体实施例中,所述采集图片形成数据集,在智能分类网络中使用数据增强方法对数据集进行扩充,其方法包括:将训练数据集中的图片采用翻转、旋转、缩放、移位、模糊、马赛克、混合增强等方法进行数据集的扩充,如图7所示。
[0080]
在本发明的具体实施例中,所述将数据集图片划分为训练集和测试集的方法包括:将数据集中每一类可回收物按照8:2的比例,划分为训练集和测试集。
[0081]
步骤203.将上述训练集和测试集图片输入到智能分类网络模型里,设置初始学习
率0.01,批样本数24等参数值,进行数据增强和500轮迭代训练,保存最优权重模型,得到训练好的智能分类网络模型。
[0082]
步骤300.将待测图片或视频流输入到训练好的分类网络模型里,获取检测结果。
[0083]
综上所述,本发明实例方法解决了因分类检测网络过深带来的特征损失、语义信息丢失问题,添加了更加适合本研究任务的损失函数和激活函数,降低了密集物体间因重叠区域过大时的漏检和增强了神经网络的非线性拟合能力,提升检测精度,降低漏检率,高效实现了可回收物的分拣。如图8所示,相比于原yolov5网络架构,本发明实施例表现出了更优性能,图8中标注数字为深度学习算法检测该类别物体的概率。
[0084]
本发明实施例还提供了一种基于yolo的可回收物分类系统,包括:数据获取模块、物体检测模块;数据获取模块用于获取待检测图片或视频流;物体检测模块用于将待测图片或视频流输入到训练好的智能分类网络模型里,获取检测结果。
[0085]
具体的,物体检测模块中包括分类网络模型,所述分类网络模型以yolov5网络作为基础网络,采用cspdarknet53框架,在其基础上将原有的损失函数更换为siou;将原有的激活函数更换为meta-acon,激活函数meta-acon与conv2d、batch normalization结合为cbma组件;并引入transformer encode结构,在与原有c3基础上形成c3tr层。
[0086]
在本发明的实施例中,还提供了基于yolo的可回收物分类装置,其包括:包括处理器、存储器以及程序;程序存储在存储器中,处理器调用存储器存储的程序,以执行上述的基于yolo的可回收物分类方法。
[0087]
在上述基于yolo的可回收物分类装置的实现中,存储器和处理器之间直接或间接地电性连接,以实现数据的传输或交互。例如,这些元件相互之间可以通过一条或者多条通信总线或信号线实现电性连接,如可以通过总线连接。存储器中存储有实现数据访问控制方法的计算机执行指令,包括至少一个可以软件或固件的形式存储于存储器中的软件功能模块,处理器通过运行存储在存储器内的软件程序以及模块,从而执行各种功能应用以及数据处理。
[0088]
存储器可以是,但不限于,随机存取存储器(random accessmemory,简称:ram),只读存储器(read only memory,简称:rom),可编程只读存储器(programmable read-onlymemory,简称:prom),可擦除只读存储器(erasable programmable read-onlymemory,简称:eprom),电可擦除只读存储器(electric erasableprogrammableread-onlymemory,简称:eeprom)等。其中,存储器用于存储程序,处理器在接收到执行指令后,执行程序。
[0089]
处理器可以是一种集成电路芯片,具有信号的处理能力。上述的处理器可以是通用处理器,包括中央处理器(centralprocessingunit,简称:cpu)、网络处理器(networkprocessor,简称:np)等。可以实现或者执行本技术实施例中的公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
[0090]
在本发明的实施例中,还提供了一种计算机可读存储介质,计算机可读存储介质被配置成存储程序,程序被配置成执行上述的基于yolo的可回收物分类方法。
[0091]
本领域内的技术人员应明白,本发明实施例的实施例可提供为方法、装置、或计算机程序产品。因此,本发明实施例可采用完全软件实施例的形式。而且,本发明实施例可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质上实施的计算机程序产品的形式。
[0092]
本发明实施例是参照根据本发明实施例的方法、终端设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理终端设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理终端设备的处理器执行的指令产生用于实现在流程图中指定的功能的装置。
[0093]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理终端设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图中指定的功能。
[0094]
这些计算机程序指令也可装载到计算机或其他可编程数据处理终端设备上,使得在计算机或其他可编程终端设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程终端设备上执行的指令提供用于实现在流程图中指定的功能的步骤。
[0095]
以上对本发明所提供的基于yolo的可回收物分类方法、基于yolo的可回收物分类系统和一种计算机可读存储介质的应用进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。