1.本发明实施例涉及图像处理技术领域,尤其涉及一种基于多尺度协作深度学习的无砟轨道板裂缝测量方法。
背景技术:
2.目前,随着高速铁路投入运营时间的增长,受气候、环境、服役时间等影响,无砟轨道板表面逐步出现裂缝并不断生长。裂缝不仅降低了混凝土结构的强度,还缩短了轨道板的使用寿命。当裂缝宽度扩展到一定严重程度时会造成扣件松动和轨道移位,进而导致整个无砟轨道结构的失效,严重威胁高速铁路的运行安全。精准测量无砟轨道板表面裂缝宽度并以此评估其严重程度是高速铁路日常巡检工作的重要内容,也是养护维修决策的关键依据。
3.裂缝边界的检测精度直接决定着其严重程度,即裂缝宽度测量的可靠性。传统的基于图像处理技术的测量方案通过处理巡检图像中的浅层特征(如颜色、灰度、轮廓、边缘和频率)来区分裂缝像素和背景像素。尽管它们结构简单且计算成本较低,但最佳阈值和种子像素的选择需要大量的人工干预和预定义的公式设计,如果裂缝特征或检测背景发生重大变化,就需要调整计算参数甚至重新设计算法,具有高特异性、低泛化性和不确定性,易产生模糊或不连续的裂缝边界(漏检)导致无效的宽度测量。
4.尽管基于深度学习的解决方案相比传统图像处理技术极大地提升了检测精度和效率,但大部分算法仅适用于单调、均一的场景,其共性在于仅通过像素尺度的分析来检测裂缝边界,难以区分裂缝像素以及与裂缝高度相似的噪声、污损等背景像素,对复杂背景状况的适应性差造成的漏检或误检导致裂缝宽度测量严重偏离实际。
5.综上所述,裂缝宽度的精细化测量是高速铁路无砟轨道板裂缝状态刻画和维护决策的关键依据,但现有的基于机器视觉的解决方案仅适用于单调、均一的场景,在复杂背景条件下易产生漏检或误检导致裂缝测量结果偏离真实值。
6.可见,亟需一种适应性和测量精准度高的基于多尺度协作深度学习的无砟轨道板裂缝测量方法。
技术实现要素:
7.有鉴于此,本发明实施例提供一种基于多尺度协作深度学习的无砟轨道板裂缝测量方法,至少部分解决现有技术中存在适应性和测量精准度较差的问题。
8.第一方面,本发明实施例提供了一种基于多尺度协作深度学习的无砟轨道板裂缝测量方法,包括:
9.搭建多尺度协作深度学习的裂缝测量框架,其中,所述裂缝测量框架包括深度目标检测网络、深度语义分割网络和改进的正交投影算法;
10.将多张样本图像分为训练集和验证集,其中,所述样本图像为包含裂缝的无砟轨道板对应的图像;
11.将所述训练集和所述验证集训练所述深度目标检测网络,调整所述深度目标检测网络的超参数并输出所述训练集中每张所述样本图像对应的最优的裂缝区域提取结果;
12.将每张所述裂缝区域提取结果进行边界坐标裁剪,得到裂缝图像并输入所述深度语义分割网络调整所述深度语义分割网络的超参数;
13.根据调整超参数的深度目标检测网络、调整超参数的深度语义分割网络和所述改进的正交投影算法得到裂缝测量模型;
14.将采集到的目标无砟轨道板对应的目标图像输入所述裂缝检测模型,得到所述目标图像中裂缝的连续宽度值。
15.根据本发明实施例的一种具体实现方式,所述将采集到的目标无砟轨道板对应的目标图像输入所述裂缝检测模型,得到所述目标图像中裂缝的连续宽度值的步骤,包括:
16.将所述目标图像输入所述裂缝检测模型,得到所述目标图像对应的裂缝区域提取结果;
17.将所述裂缝区域提取结果进行边界坐标裁剪,得到裁剪图像;
18.根据所述裁剪图像得到裂缝边界像素检测结果,并根据所述改进的正交投影算法计算所述连续宽度值。
19.根据本发明实施例的一种具体实现方式,所述根据所述裁剪图像得到裂缝边界像素检测结果,并根据所述改进的正交投影算法计算所述连续宽度值的步骤,包括:
20.将所述裂缝边界像素检测结果输入所述改进的正交投影算法,提取单像素的裂缝骨架,其中,所述裂缝骨架的方向为由局部相邻骨架点导出的每个骨架点处的切线方向,其中心是骨架点;
21.沿着逆时针方向和八邻域对所述裂缝边界像素检测结果进行跟踪匹配,通过匹配所有的边界像素,将二值边界转换为一个分层序列,得到完整的裂缝轮廓;
22.从每个所述骨架点像素引出正交投影射线作为所述裂缝骨架的法线,将每条所述正交投影射线和裂缝的两条轮廓线两个交点之间的欧几里得距离作为所述连续宽度值。
23.根据本发明实施例的一种具体实现方式,所述深度目标检测网络包括输入端、特征提取模块和坐标预测模块。
24.根据本发明实施例的一种具体实现方式,所述深度语义分割网络包括编码器和解码器。
25.根据本发明实施例的一种具体实现方式,所述将所述训练集和所述验证集训练所述深度目标检测网络,调整所述深度目标检测网络的超参数并输出所述训练集中每张所述样本图像对应的最优的裂缝区域提取结果的步骤之前,所述方法还包括:
26.对每张所述样本图像中的裂缝进行区域标注。
27.根据本发明实施例的一种具体实现方式,所述将所述训练集和所述验证集训练所述深度目标检测网络,调整所述深度目标检测网络的超参数并输出所述训练集中每张所述样本图像对应的最优的裂缝区域提取结果的步骤,包括:
28.将全部所述训练集输入所述深度目标检测网络,得到每张所述样本图像对应的预测边界框;
29.根据每张所述样本图像的预测边界框与标注边界框计算损失函数,并根据所述损失函数调整所述深度目标检测网络的超参数直至与所述验证集验证后的平均精度达到预
设条件,固定所述深度目标检测网络的超参数,并输出所述训练集中每张所述样本图像对应的最优的裂缝区域提取结果。
30.根据本发明实施例的一种具体实现方式,所述将每张所述裂缝区域提取结果进行边界坐标裁剪,得到裂缝图像并输入所述深度语义分割网络调整所述深度语义分割网络的超参数的步骤,包括:
31.将全部所述裂缝图像输入所述深度语义分割网络,得到每张所述样本图像对应的预测像素;
32.根据每张所述样本图像的预测像素与标注像素计算交叉熵损失,并根据所述交叉熵损失调整所述深度目标检测网络的超参数直至与所述验证集验证后的平均精度达到预设条件,固定所述深度目标检测网络的超参数。
33.本发明实施例中的基于多尺度协作深度学习的无砟轨道板裂缝测量方案,包括:搭建多尺度协作深度学习的裂缝测量框架,其中,所述裂缝测量框架包括深度目标检测网络、深度语义分割网络和改进的正交投影算法;将多张样本图像分为训练集和验证集,其中,所述样本图像为包含裂缝的无砟轨道板对应的图像;将所述训练集和所述验证集训练所述深度目标检测网络,调整所述深度目标检测网络的超参数并输出所述训练集中每张所述样本图像对应的最优的裂缝区域提取结果;将每张所述裂缝区域提取结果进行边界坐标裁剪,得到裂缝图像并输入所述深度语义分割网络调整所述深度语义分割网络的超参数;根据调整超参数的深度目标检测网络、调整超参数的深度语义分割网络和所述改进的正交投影算法得到裂缝测量模型;将采集到的目标无砟轨道板对应的目标图像输入所述裂缝检测模型,得到所述目标图像中裂缝的连续宽度值。
34.本发明实施例的有益效果为:通过本发明的方案,协作分析和传递图像—像素—宽度三个尺度的特征,减少了复杂背景导致的像素误判并得到了精细化的裂缝宽度测量值。
附图说明
35.为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
36.图1为本发明实施例提供的一种基于多尺度协作深度学习的无砟轨道板裂缝测量方法的流程示意图;
37.图2为本发明实施例提供的一种多尺度协作深度学习的裂缝测量框架示意图;
38.图3为本发明实施例提供的一种深度目标检测网络的总体框架示意图;
39.图4为本发明实施例提供的一种空洞卷积模块结构示意图;
40.图5为本发明实施例提供的一种无砟轨道板裂缝图像数据采集与标注流程示意图;
41.图6为本发明实施例提供的一种深度目标检测网络的训练结果示意图;
42.图7为本发明实施例提供的一种深度语义分割网络的训练结果示意图;
43.图8为本发明实施例提供的一种改进的基于正交投影的裂缝宽度测量方法的总体框架示意图;
44.图9为本发明实施例提供的一种裂缝骨架提取示意图;
45.图10为本发明实施例提供的一种裂缝骨架方向定义图;
46.图11为本发明实施例提供的一种基于正交投影的裂缝连续宽度计算示意图;
47.图12为本发明实施例提供的一种部分图像的裂缝连续宽度测量值示意图;
48.图13为本发明实施例提供的一种不同深度学习算法在测试集上的裂缝边界检测结果示意图;
49.图14为本发明实施例提供的一种不同深度学习算法对于四张测试图像的裂缝边界检测结果示意图;
50.图15为本发明实施例提供的一种多尺度协作算法和传统正交投影法的裂缝宽度测量结果对比示意图。
具体实施方式
51.下面结合附图对本发明实施例进行详细描述。
52.以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
53.需要说明的是,下文描述在所附权利要求书的范围内的实施例的各种方面。应显而易见,本文中所描述的方面可体现于广泛多种形式中,且本文中所描述的任何特定结构及/或功能仅为说明性的。基于本发明,所属领域的技术人员应了解,本文中所描述的一个方面可与任何其它方面独立地实施,且可以各种方式组合这些方面中的两者或两者以上。举例来说,可使用本文中所阐述的任何数目个方面来实施设备及/或实践方法。另外,可使用除了本文中所阐述的方面中的一或多者之外的其它结构及/或功能性实施此设备及/或实践此方法。
54.还需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
55.另外,在以下描述中,提供具体细节是为了便于透彻理解实例。然而,所属领域的技术人员将理解,可在没有这些特定细节的情况下实践所述方面。
56.本发明实施例提供一种基于多尺度协作深度学习的无砟轨道板裂缝测量方法,所述方法可以应用于铁路巡检场景的裂缝数据测量过程。
57.参见图1,为本发明实施例提供的一种基于多尺度协作深度学习的无砟轨道板裂缝测量方法的流程示意图。如图1所示,所述方法主要包括以下步骤:
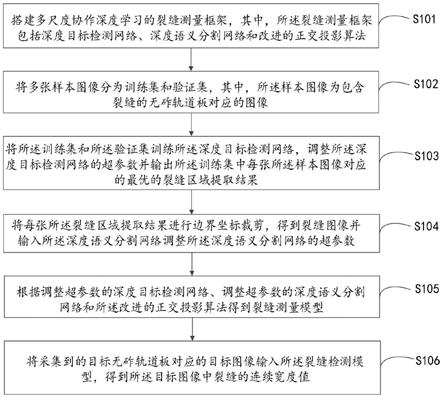
58.s101,搭建多尺度协作深度学习的裂缝测量框架,其中,所述裂缝测量框架包括深度目标检测网络、深度语义分割网络和改进的正交投影算法;
59.可选的,所述深度目标检测网络包括输入端、特征提取模块和坐标预测模块。
60.可选的,所述深度语义分割网络包括编码器和解码器。
61.具体实施时,考虑到裂缝宽度的精细化测量是高速铁路无砟轨道板裂缝状态刻画和维护决策的关键依据,但现有的基于机器视觉的解决方案仅适用于单调、均一的场景,在复杂背景条件下易产生漏检或误检导致裂缝测量结果偏离真实值,则可以建立融合了图像、像素和宽度三个尺度的多尺度协作深度学习的裂缝测量框架如图2所示,包括基于深度目标检测网络的裂缝区域提取、基于深度语义分割网络的裂缝边界检测和基于改进的正交投影法的裂缝宽度测量。输入图像通过图像尺度和像素尺度的协作分析,以及与宽度尺度的特征传递,提升对复杂背景条件的适应性,形成输入巡检图像到输出裂缝连续宽度测量值的精细化映射,从而实现对裂缝严重程度的精准刻画。
62.例如,首先搭建用于裂缝区域提取的深度目标检测网络。本发明所使用的深度目标检测网络由输入端、特征提取模块和坐标预测模块组成,它将区域分类和坐标回归封装到一个网络中,目标在边界框中的置信度和目标所属类别的概率是在一次评估中直接从完整图像中捕获的,以实现实时、高效的端到端检测,如图3所示。
63.多尺度的裂缝图像从输入端进入深度目标检测网络,并以三维张量的形式进行特征提取,其中每个维度分别表示高度、宽度和通道(红色、绿色和蓝色)。输入端将输入图像划分为s
×
s网格。如果对象的中心落入网格单元中,则该网格单元负责检测该对象。
64.深度目标检测网络的特征提取模块采用darknet-53结构(包括第0层到第105层)。其中第0层到第74层中共有53个独立卷积层,剩余皆为残差单元,这些卷积层使用大量不同大小的卷积核(滤波器),如1、3、5,与输入图像的邻域进行卷积运算(权重参数用于与输入图像矩阵局部窗口的数据进行内积),然后以一定的步长从图像的左上方滑向右下方,输出计算整个输入图像的卷积特征图。每个残差单元均包含一个3
×
3和一个1
×
1卷积核,其中每个卷积核包含三个操作层:卷积操作、bn操作和leaky relu激活操作。在每个残差单元的末尾,在输入和输出向量之间执行元素级加法。残差单元简化了深度网络的训练,可以有效解决梯度消失问题。进一步地,75-105层是yolov3网络的特征交互层,分别从三个尺度(32、16和8)获取特征。在每个尺度上,卷积核(3
×
3和1
×
1)在特征图之间实现局部特征交互,全连接层实现全局特征交互。
65.深度目标检测网络的坐标预测模块利用单个分辨率的输入图像构建了一个具有三个尺度特征(32、16和8)的多尺度特征金字塔。金字塔的每一层都可以用于检测不同尺度的物体,其中具有较大步幅的较低分辨率特征图可以产生输入图像的非常粗略的表示,而具有更高分辨率的具有较小步幅的特征图具有更细粒度的特征。进一步地,多尺度特征金字塔在三个不同分辨率的输出特征图上预测每个网格单元的三个预测框。每个预测框均由一个置信变量、四个坐标变量(bx,by,bh,bw)和一个表示类的变量组成。这些预测变量分别转换为对象的置信度、类别概率和位置以生成裂缝区域的预测结果。其中预测框坐标的计算过程如公式1:
[0066][0067]
其中,c
x
和cy表示预测框所属的网格单元坐标,pw和ph表示预测框预定义的高度和权重,t
x
和ty表示深度目标检测网络预测的偏移坐标,tw和th表示该网络预测结果的尺度偏移量。
[0068]
然后进一步建立用于裂缝边界检测的深度语义分割网络。本发明所使用的深度语义分割网络是一种用于语义分割的编码器-解码器架构,如图3所示。在编码器模块(encoder)中,该网络将深度目标检测网络输出的裂缝区域提取结果作为inception-resnet-v2(网络主干)的输入来计算裂缝的深层特征,并使用空洞卷积模块(atrous)在不改变特征图大小的同时控制感受野以提取多尺度的语义信息,然后进入多孔空间金字塔池化模块(aspp)进行筛选并捕获最具辨别力的裂缝特征图。最后,提取到的最具辨别力的整个图像的特征图被输入到解码器模块(decoder)中。解码器模块通过上采样操作对输入的特征图进行解码,并与来自inception-resnet-v2(网络主干)网络的相应低级特征进行融合并恢复到与输入图像一致的空间维度,从而实现对裂缝区域中边界像素的精细化检测。其中编码器模块的具体架构如下:
[0069]
由inception-resnet模块、reduction模块构成的inception-resnet-v2网络作为裂缝像素特征提取的网络主干。inception模块采用并行方式组合卷积层,增加了网络的宽度和结构的非线性,减少了整个网络的参数数量,与传统模型(alexnet、vggnet)的直接串行组合方式相比,可以加快计算速度,挖掘更深层次的图像特征。resnet模块直接连接inception-resnet模块的输入层和输出层,直接学习输入层和输出层的差值,并将差值加入输入层进行输出的结果,可以有效解决网络层数过多造成的梯度消失的问题,提高像素检测的准确性。reduction模块通过数据空间减半并加深通道等方式,将从裂缝图像中提取的特征信息中的有效信息聚合起来。
[0070]
空洞卷积模块(atrous)是编码器模块的关键组成,它可以在不改变特征图大小的同时控制感受野,有利于提取多尺度信息。空洞卷积模块如图4所示,其中采样率控制着感受野的大小,数值越大则感受野越大。本文使用的深度语义分割网络进一步地将空洞卷积模块和深度分离卷积结合,其优点在于:在维持相同性能的情况下,深度分离卷积可以大大减小计算复杂度。
[0071]
编码器采用多孔空间金字塔池化模块(aspp)来进一步提取多尺度信息,其采用不同采样率的空洞卷积来实现这一点。aspp模块主要包含一个1
×
1卷积层,三个3x3的空洞卷积以及一个全局平均池化层得到图像水平的特征,然后送入1x1卷积层,并双线性插值到原始大小,进一步将上述各个卷积层得到的不同尺度的特征组合在一起,然后送入1x1的卷积中进行融合并得到最具辨别力的裂缝特征图。
[0072]
根据上述两个网络综合得到的裂缝边界像素的检测结果,提出了一种改进的基于正交投影的裂缝宽度测量方法。
[0073]
s102,将多张样本图像分为训练集和验证集,其中,所述样本图像为包含裂缝的无
砟轨道板对应的图像;
[0074]
例如,可以通过安装在高速综合轨道巡检车上的高分辨率线阵相机对某高速铁路区段crtsⅲ型无砟轨道板表面进行扫描以获取训练所需的目标数据集。由于高速铁路轨道结构一般处于自然环境中,受自然光照和相机光源的叠加影响,以及巡检车自身振动和噪声等复杂环境条件的干扰,这些采集到的原始图像存在噪声、污损等复杂不规则背景。这些原始图像经过以下步骤处理后进入多尺度协作深度学习的裂缝测量框架中进行分析和计算,如图5所示:
[0075]
(1)采集到的原始巡检图像的像素尺寸为4096像素
×
4096像素,对应的实际物理区域为235.5mm
×
235.5mm。
[0076]
(2)图像被重置为400像素
×
400像素,共3000余张。
[0077]
(3)选取500张含裂缝图像作为本发明的样本数据,每次选取500张图像的10%作为验证集,剩余作为训练集,得到10组《训练集,验证集》,并额外选取30张图像作为测试集。
[0078]
s103,将所述训练集和所述验证集训练所述深度目标检测网络,调整所述深度目标检测网络的超参数并输出所述训练集中每张所述样本图像对应的最优的裂缝区域提取结果;
[0079]
可选的,步骤s103所述的,将所述训练集和所述验证集训练所述深度目标检测网络,调整所述深度目标检测网络的超参数并输出所述训练集中每张所述样本图像对应的最优的裂缝区域提取结果之前,所述方法还包括:
[0080]
对每张所述样本图像中的裂缝进行区域标注。
[0081]
进一步的,步骤s103所述的,将所述训练集和所述验证集训练所述深度目标检测网络,调整所述深度目标检测网络的超参数并输出所述训练集中每张所述样本图像对应的最优的裂缝区域提取结果,包括:
[0082]
将全部所述训练集输入所述深度目标检测网络,得到每张所述样本图像对应的预测边界框;
[0083]
根据每张所述样本图像的预测边界框与标注边界框计算损失函数,并根据所述损失函数调整所述深度目标检测网络的超参数直至与所述验证集验证后的平均精度达到预设条件,固定所述深度目标检测网络的超参数,并输出所述训练集中每张所述样本图像对应的最优的裂缝区域提取结果。
[0084]
例如,可以使用labelme对10组《训练集,验证集》图像中的裂缝进行区域标注(边界框),并以.json文件格式保存,得到深度目标检测网络的参考基准,并进一步对框内的裂缝边界进行逐像素标注以得到深度语义分割网络的参考基准。
[0085]
然后10组经过裂缝区域标注的《训练集,验证集》图像和相应的json文件被输入到深度目标检测网络中进行充分学习和训练,并输出裂缝目标区域的检测结果。本发明以gpu为计算核心(cpu:amd2990wx@3.0ghz,ram=64gb;gpu:nvidia geforce rtx 2080ti),依托facebook开源的深度学习框架pytorch1.2.0,基于10组《训练集,验证集》进行了超参数调整实验,并依据深度目标检测网络的训练集损失函数和性能评估指标确定最优的超参数设置,以输出最优的裂缝区域提取结果。如表1所示:
[0086]
表1
[0087][0088]
所述深度目标检测网络所使用的损失函数(loss)被定义为预测边界框和标注边界框之间的平方误差之和,根据损失函数的数值大小可以校正预测边界框坐标和置信度值,如公式2所示:
[0089][0090]
式中:表示预测框的坐标;(xi,yi,wi,hi,ci,pi)表示标注框的坐标;表示对象是否出现在边界框中,存在则值为1;不存在为0。
[0091]
步骤s103中采用所有类别检测对象的平均精度(average precision,ap)的平均值(mean average precision,map)来评估深度目标检测网络的性能,map的计算步骤如下:
[0092]
(1)第一步计算均交并比(intersection over union,iou),iou被定义为预测区域和标注区域之间的重叠程度,其数学表达式如公式3。
[0093][0094]
(2)第二步根据iou阈值区分阳性样本和阴性样本,并将所有预测的置信度按降序排序。iou的阈值通常是预定义的(一般设置为0.5),当预测边界框和标注边界框之间的iou大于此阈值时,该预测边界框被定义为阳性样本,否则为阴性样本。此外,预测边界框的置信度阈值也被用于区分正预测和负预测。当预测结果的iou大于0.5且预测正确时,表示真阳性(tp),当预测结果的iou小于0.5或预测错误时,表示假阳性(fp),当不存在带有标注边界框的iou时,表示假阴性(fn),这表明模型无法从人工注释中检测到任何对象标签。
[0095]
(3)根据tp,fp和fn计算精准率(precision)和召回率(recall),精准率被定义为正确检测的目标占检测总数的比例,召回率被定义为正确检测的目标占实际目标总数的比例,数学表达式如公式(4)和(5)。进一步计算不同置信度阈值对应的精准率和召回率绘制p-r曲线,map的值通过对p-r曲线进行积分得到,表示p-r曲线与坐标轴围成的面积。
[0096]
[0097][0098]
步骤s103中的深度目标检测网络的训练结果如图6所示,如图中的(a)所示,通过对450张图像1000轮次的充分训练和学习,训练集损失和map均达到了收敛并稳定,此时深度目标检测网络达到了拟合状态。进一步计算基于50张验证集图像绘制出的p-r曲线下的面积,得到深度目标检测网络用于裂缝区域提取的map值为93.36%,如图6中的(b)。
[0099]
s104,将每张所述裂缝区域提取结果进行边界坐标裁剪,得到裂缝图像并输入所述深度语义分割网络调整所述深度语义分割网络的超参数;
[0100]
在上述实施例的基础上,步骤s104所述的,将每张所述裂缝区域提取结果进行边界坐标裁剪,得到裂缝图像并输入所述深度语义分割网络调整所述深度语义分割网络的超参数的步骤,包括:
[0101]
将全部所述裂缝图像输入所述深度语义分割网络,得到每张所述样本图像对应的预测像素;
[0102]
根据每张所述样本图像的预测像素与标注像素计算交叉熵损失,并根据所述交叉熵损失调整所述深度目标检测网络的超参数直至与所述验证集验证后的平均精度达到预设条件,固定所述深度目标检测网络的超参数。
[0103]
具体实施时,在将每张所述裂缝区域提取结果进行边界坐标裁剪,得到裂缝图像后,可以将全部所述裂缝图像作为深度语义分割网络的输入。通过所述深度语义分割网络的编码器模块从输入的裂缝区域中提取具有丰富语义信息的特征图,进一步将提取出的特征图输入到解码器模块并恢复到与步骤s103的输出结果一致的空间维度,输出像素尺度的裂缝边界像素检测结果。所使用的深度语义分割网络在450张训练集图像上的最优超参数设置如表2,并采用交叉熵损失和miou分布评估深度语义分割网络的训练效果和裂缝边界检测性能。
[0104]
表2
[0105][0106][0107]
然后可以采用交叉熵损失定义输出的预测像素和标记像素之间的误差,以评估深度语义分割网络的训练效果,其数学表达式如公式(6)所示:
[0108]
[0109]
式中:loss为deeplabv3 的总损失;y为标签值;为预测值。
[0110]
同时,也可以使用miou评估deeplabv3 等深度语义分割网络的检测性能,miou在本发明中取不同类别对象的iou的平均值,被用于度量属于各个类别的预测裂缝像素和标记的裂缝像素之间的重叠程度,其数学表达式如公式(7):
[0111][0112]
式中:n为检测对象的类别。
[0113]
步骤s104中的深度语义分割网络的训练结果如图7所示,其中,(a)表示通过对450张图像500轮次的充分训练和学习,训练集损失和miou均达到了收敛并稳定,此时深度语义分割网络达到了拟合状态。进一步统计在50张验证集图像上iou的平均值得到deeplabv3 网络的miou为82.99%,如图7的(b)所示。
[0114]
s105,根据调整超参数的深度目标检测网络、调整超参数的深度语义分割网络和所述改进的正交投影算法得到裂缝测量模型;
[0115]
在调整好所述深度目标检测网络和所述深度语义分割网络的超参数后,结合所述改进的正交投影算法得到裂缝测量模型,后续可以通过所述裂缝测量模型对采集到的裂缝图像直接进行测量,输出图像中裂缝的连续宽度值。
[0116]
s106,将采集到的目标无砟轨道板对应的目标图像输入所述裂缝检测模型,得到所述目标图像中裂缝的连续宽度值。
[0117]
在上述实施例的基础上,步骤s106所述的,将采集到的目标无砟轨道板对应的目标图像输入所述裂缝检测模型,得到所述目标图像中裂缝的连续宽度值,包括:
[0118]
将所述目标图像输入所述裂缝检测模型,得到所述目标图像对应的裂缝区域提取结果;
[0119]
将所述裂缝区域提取结果进行边界坐标裁剪,得到裁剪图像;
[0120]
根据所述裁剪图像得到裂缝边界像素检测结果,并根据所述改进的正交投影算法计算所述连续宽度值。
[0121]
进一步的,所述根据所述裁剪图像得到裂缝边界像素检测结果,并根据所述改进的正交投影算法计算所述连续宽度值的步骤,包括:
[0122]
将所述裂缝边界像素检测结果输入所述改进的正交投影算法,提取单像素的裂缝骨架,其中,所述裂缝骨架的方向为由局部相邻骨架点导出的每个骨架点处的切线方向,其中心是骨架点;
[0123]
沿着逆时针方向和八邻域对所述裂缝边界像素检测结果进行跟踪匹配,通过匹配所有的边界像素,将二值边界转换为一个分层序列,得到完整的裂缝轮廓;
[0124]
从每个所述骨架点像素引出正交投影射线作为所述裂缝骨架的法线,将每条所述正交投影射线和裂缝的两条轮廓线两个交点之间的欧几里得距离作为所述连续宽度值。
[0125]
具体实施时,根据上述两个网络综合得到的裂缝边界像素的检测结果,提出了一种改进的基于正交投影的裂缝宽度测量方法。改进的基于正交投影的裂缝测量方法的总体框架如图8所示,具体包括以下步骤:
[0126]
①
第一步是根据深度语义分割网络的裂缝边界像素检测结果定义裂缝块并提取
裂缝轮廓。裂缝块是进行裂缝量化分析的基本单位,定义为表示单个裂缝的一组像素。裂缝块在本质上可以很好的表示裂缝的自然轮廓特征。然而,由于裂缝呈现出非平面、多分支的复杂延伸模式,裂缝之间相互交叉,因此在进行裂缝几何特征分析之前,有必要将相互连接的裂缝分割成单独的裂缝块。本发明对裂缝块进行重新定义:即具有细长特征的非交叉裂缝像素组。根据该定义,每个裂缝块都应该具有两个特征:其一是有两个端点但没有交点;其二是表现出细长的图案布局,以上两点是区分无砟轨道板裂缝与剥落掉块或其他病害的重要特征。根据定义的裂缝块,沿着逆时针方向和八邻域对裂缝块的边缘像素进行跟踪匹配。通过匹配所有的边缘像素,将二值边缘转换为一个分层序列,进而得到完整的裂缝轮廓。
[0127]
②
第二步是根据获得的裂缝骨架信息计算裂缝方向。裂缝骨架是表征裂缝的一种非常重要的几何特征,用于定位每个裂缝块内裂缝的基本结构,也是裂缝智能分析中的重要组成部分。通过骨架提取算法提出的裂缝块骨架即中心白色曲线,并对提取出的骨架进行剪枝处理,如图9所示,其中,(a)为裂缝块骨架,(b)为骨架进行剪枝处理后的图像。
[0128]
③
第三步是确定裂缝骨架的方向并计算骨架的法线,本发明将裂缝骨架的方向定义为由局部相邻骨架点导出的每个骨架点处的切线方向,其中心是骨架点,如图10所示。需要注意的是,定义的裂缝方向不同,裂缝骨架是根据整个裂缝块确定其方向。裂缝骨架中骨架点的性质通常有两种情况,一个是非终结点,另一个是终结点。对于每个非终结点,在以该骨架点为中心的骨架图上构建5
×
5块矩阵,通过矩阵与骨架的重叠区域(图10中的左下方色块)确定骨架方向。而对于骨架结束处的终结点,同样以该终结点为中心在骨架图上构建5
×
5块矩阵,但需要同时向内骨架点构建扩展块(图10中的右上方扩展块)。该矩阵同骨架上的每个点对齐并平行和垂直移动相同的像素单位,进而确定裂缝骨架方向。矩阵移动的像素距离可根据用户输入进行调整。需要采用较小的矩阵确定局部裂缝块方向的变化,因此本发明采用5
×
5块矩阵。通过提取块矩阵内的连通分量,并计算每个像素矩阵的二阶矩确定矩阵θ的方向。如图10中椭圆形的箭头所示。由于每个骨架点的法线方向垂直于取向方向,所以每个骨架点的法线方向为θ π/2。
[0129]
④
第四步是将骨架法线扩展到整个裂缝轮廓进而计算整个裂缝的连续宽度。裂缝两轮廓线之间被标识的裂缝骨架法线部分被定义为该点处的裂缝宽度,如图11中(a)的曲线所示。其中,较细的曲线表示提取的裂缝骨架,较粗的曲线表示每个骨架点像素导出的正交投影射线,每个正交投影射线与裂缝两轮廓线都有两个相交点,即图11中的圆点。因此,可以利用两个交点之间的欧式距离即确定裂缝中某点的连续宽度。
[0130]
具体的,这两个交点之间的欧几里得距离被定义为裂缝内部某点的连续宽度如公式8所示。步骤s5中输出的部分图像的裂缝连续宽度值如图12所示。
[0131]
进一步根据上述步骤输出的裂缝连续宽度的分布计算裂缝严重程度刻画指标,包括最小宽度、最大宽度、平均宽度(公式9)、中值宽度(公式10)和标准差(公式11)以全面、系统地刻画裂缝的严重程度。
[0132][0133]
[0134][0135][0136]
式中:a
ij
是裂缝中某一点的连续宽度;xi,xj∈c∩r;c为裂缝轮廓点集;r为正交投影射线点集;n为裂缝连续宽度测量点集;为裂缝的平均宽度;为裂缝的中值宽度;为标准差。
[0137]
本实施例提供的基于多尺度协作深度学习的无砟轨道板裂缝测量方法,通过协作分析和传递图像—像素—宽度三个尺度的特征,减少了复杂背景导致的像素误判并得到了精细化的裂缝宽度测量值。
[0138]
下面将结合一个具体实施例对本方案进行说明,将本发明搭建的基于多尺度协作深度学习的裂缝测量框架的输出结果与传统解决方案进行对比以评估本发明的裂缝测量性能,包括与单一像素尺度的深度学习算法的对比和与传统正交投影法的对比,具体如下:
[0139]
(1)第一步分别使用本发明搭建的基于多尺度协作深度学习的裂缝测量框架和u-net、deeplabv3 网络处理30张测试集图像,得到相应的裂缝边界检测结果,并从miou、计算成本和检测结果三个方面对比各种解决方案的性能。
[0140]
①
各种解决方案的miou和计算成本。图13给出了本发明与现有两种像素尺度的深度语义分割网络对于30张测试集图像的裂缝边界检测结果,其中u-net网络的计算成本(单张图像处理时间)最低,但在测试集上的miou仅有68.8%,而deeplabv3 网络的miou达到了77.59%,但也带来了更高的计算成本。多尺度协作算法在图像—像素尺度协作分析时的总计算成本由两部分构成:裂缝区域提取(黄色区域)和裂缝边界检测(绿色区域)。与单一像素尺度的deeplabv3 网络相比,尽管多尺度协作算法消耗的总计算成本略高(单张图像处理时间多出0.03s),但其miou提升了近7%,且图像尺度的裂缝区域预提取也使得该算法在像素尺度检测裂缝边界时的计算成本低于deeplabv3 。
[0141]
②
各种解决方案的裂缝边界检测结果。图14进一步对比了本发明与现有两种像素尺度的深度语义分割网络对于四张测试图像的裂缝边界检测结果,u-net网络对于裂缝细节的检测效果不佳,容易产生不连续的裂缝边界,且u-net和deeplabv3 均易将噪声、污损等与裂缝高度相似的背景像素误判为裂缝像素(图13中黄色圆圈所示)。与u-net和deeplabv3 相比,多尺度协作算法在图像尺度提取裂缝区域时有效地消除了目标区域之外的噪声、污损的干扰,对经过坐标裁剪后的裂缝区域进行像素尺度的边界分割能够得到更精细化的检测结果。
[0142]
(2)第二步分别使用本发明搭建的基于多尺度协作深度学习的裂缝测量框架和传统正交投影法处理30张测试集图像,得到相应的裂缝连续宽度测量结果,并对比这两种解决方案输出的裂缝严重程度刻画指标以评估它们的检测性能。图15对比了本发明和传统正
交投影法针对四张测试图像(400像素
×
400像素)的裂缝严重程度量化指标的计算结果,包括最小宽度、最大宽度、平均宽度、中值宽度和标准差。图15中,(a)的直方图所示为传统正交投影法的计算结果,点线图为多尺度协作算法的计算结果。传统正交投影法计算得到的测试图像一和测试图像二的最大宽度值均是多尺度协作算法计算结果的8倍以上,且远大于其平均宽度测量值,说明传统正交投影法易将噪声、污损等与裂缝高度相似的复杂背景误判为裂缝像素,引起骨架变形,从而导致最大宽度测量值出现较大偏差。进一步地,多尺度协作算法可以计算得到四张测试图像的裂缝的最小宽度值,而传统正交投影法计算得到的裂缝的最小宽度值近似为0,这是由于传统正交投影法在裂缝像素轮廓提取阶段采用的canny算子容易产生不连续的裂缝边界,难以获得裂缝真实的最小宽度值。此外,多尺度协作算法计算得到的四张测试图像的裂缝平均宽度和中值宽度的差值均小于0.1mm,而对于传统正交投影法而言这一差值可能达到0.3mm。图15中,(b)进一步对比了两种方法测得的裂缝的连续宽度的标准差,他们在四张测试图像上均测得了超过350个沿裂缝骨架线的连续宽度值,其中多尺度协作算法的裂缝连续宽度测量结果的标准差均在2以下,而传统正交投影法在测试图像二上的标准差一度达到了18,显示出多尺度协作算法具有更加优异的测量稳定性和可靠性。上述对比结果表明多尺度协作算法能够在噪声、污损等复杂背景状况的干扰下实现更实际、更稳定的裂缝严重程度刻画。
[0143]
对比分析结果表明本发明提出的基于多尺度协作的深度学习算法能够解决现有机器视觉方案在复杂背景条件下易漏检或误检导致测量结果偏离真实值的不足,裂缝宽度测量精度高,计算成本低,并对噪声、污损等与裂缝高度相似的复杂背景具有优异的适应性和鲁棒性。
[0144]
可以看出本发明的有益效果包括:
[0145]
1、本发明提出了一种基于多尺度协作的深度学习算法,有效解决了现有单一像素尺度的深度语义分割网络对于高速铁路无砟轨道板表面裂缝的边界检测易受复杂环境条件的干扰导致检测结果严重偏离实际的问题。
[0146]
2、本发明提出的基于多尺度协作的深度学习算法能够去除大部分的噪声、污损导致的像素误判,显示出对与裂缝高度相似的复杂背景条件的良好的适应性。
[0147]
3、本发明提出的基于多尺度协作的深度学习算法计算得到的无砟轨道板表面裂缝严重程度的刻画指标更接近实际情况,且波动(标准差)远低于传统的正交投影法(波幅最高达90%),显示出该算法的裂缝宽度测量性能具有高精度,稳定性和可靠性好的特点。
[0148]
应当理解,本发明的各部分可以用硬件、软件、固件或它们的组合来实现。
[0149]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。