1.本发明涉及网络空间安全技术领域,特别涉及一种模糊测试工具性能综合量化评估方法。
背景技术:
2.网络空间安全领域中,攻击者可利用软件存在的安全漏洞引发网络安全威胁,破坏网络安全。模糊测试是漏洞检测技术中的一种代表性技术,通过使用针对目标程序生成的随机字符流,对目标程序进行多次测试,以检测可能存在的漏洞。模糊测试工具的可用性与提升被测目标安全性有直接关系,针对模糊测试工具的评估有益于发现模糊测试工具的缺陷并启发新模糊测试工具设计,目前尚未形成一个统一且规范的模糊测试工具评估方法。
3.当前针对模糊测试工具的评估方法主要从试验条件和评估指标两方面来考虑。试验条件包括实验平台、基准模糊器、基准测试套件、测试次数、漏洞验证工具、超时时间、实验次数和种子等,评估指标包括代码覆盖率、工具执行速度、cpu资源占用率、崩溃点数量、漏洞数量和覆盖率等。已有的针对模糊测试工具的评估方法多采用对比方法,通过评估特定的基准模糊测试工具和新设计的模糊测试工具的性能,以此来突出新设计的模糊测试工具的先进性。
4.不同模糊测试工具的侧重点可能不同,如:afl是以覆盖率为导向的模糊测试工具,旨在提高被测目标的代码覆盖率;driller利用concolic执行来解析魔法值,以提高漏洞检测数量为目的,相比afl能检测到更多的漏洞。因此,直接使用多个独立的评估指标对应数值作为不同模糊测试工具评估结果,各评估指标建缺乏有效的融合与关联,得到的评估结果无法决策出一个合理的综合量化数值表示模糊测试工具的性能。
技术实现要素:
5.为解决上述问题,本发明提供了一种模糊测试工具性能综合量化评估方法。基于选定设置的实验条件和评估指标,针对各评估指标对被评估模糊测试工具进行多次测试,得到多个各评估指标对应的数值;对数据进行正向化、标准化等预处理后,再通过各评估指标数据值的差异程度确定评估指标的权重值;最后构建综合量化评估计算体系,计算综合评估指标量化评估得分,实现模糊测试工具性能综合评估指标量化的自动化评估计算。
6.本发明提供了一种模糊测试工具性能综合量化评估方法,具体技术方案如下:
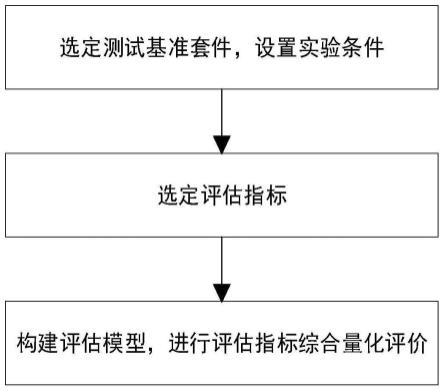
7.s1:选定测试基准套件,设置实验条件;
8.所述实验条件包括测试次数、超时时间、基准模糊测试工具和种子;
9.s2:选定评估指标;
10.所述评估指标包括崩溃点数量、代码覆盖率、暴露崩溃点的平均时间、漏洞数量、高危漏洞数量和资源占用率;
11.s3:构建评估模型,进行评估指标综合量化评价;
12.进一步的,步骤s3中,评估指标综合量化评价过程如下:
13.s301:构建评估指标数值矩阵;
14.s302:对得到的各评估指标对应数值进行数据正向化处理;
15.s303:对正向化数据进行标准化处理;
16.s304:计算各评估指标的权重;
17.s305:计算综合量化评估值。
18.进一步的,步骤s301中,通过针对各所述评估指标,对被测模糊测试工具进行若干次测试,获得各评估指标对应的评估指标数值,构建出所述评估指标数值矩阵,所述评估指标数值矩阵,如下:
19.x=(x
ij
)
(m
×
n)
20.其中,m表示测试次数,n表示评估指标个数。
21.进一步的,步骤s302中,所述数据正向化处理,具体计算如下:
[0022][0023]
其中,表示正向化数据,xj表示某一评估指标对应的数值集合,x
ij
表示需要正向化的数据。
[0024]
进一步的,步骤s303中,所述标准化处理,具体计算如下:
[0025][0026]
其中,y
ij
为标准化数据,表示正向化数据的第j列中的最小值,表示正向化数据的第j列中的最大值,i取值为{1,2,3
…
,m},j取值为{1,2,3
…
,n}。
[0027]
进一步的,步骤s304中,评估指标的权重,包括计算评估指标熵值、计算差异系数和计算权重,具体过程如下:
[0028]
所述评估指标熵值,计算如下:
[0029][0030]
其中,ej表示评估指标熵值,m表示该评估指标对应的数值个数,表示某一评估指标第i个数值占该评估指标所有数值总和的比重;
[0031]
所述差异系数,计算如下:
[0032]gj
=1-ej[0033]
其中,gj表示评估指标的差异系数;
[0034]
所述权重,计算如下:
[0035]
[0036]
其中,wj表示评估指标的权重。
[0037]
进一步的,步骤s305中,综合量化评估值计算,包括:计算加权标准化矩阵;根据所述加权标准化矩阵计算各评估指标的最优解和最劣解;再通过所述加权标准化矩阵、所述最优解和所述最劣解计算各评估指标最优解和最劣解的欧式距离,最后通过得到的欧式距离计算输出被测模糊测试工具的综合量化评估值。
[0038]
进一步的,所述测试基准套件为lava-m标准语料库,所述测试次数为5次,所述超时时间为5h。
[0039]
进一步的,所述基准模糊测试工具为aflfuzz。
[0040]
本发明的有益效果如下:
[0041]
通过计算获取各评估指标的权重,将独立的评估指标关联,实现模糊测试工具性能综合评估指标量化的自动化量化评估,增强了评估结果的可参考性,提高了被测模糊测试工具性能优劣的评估准确性。
附图说明
[0042]
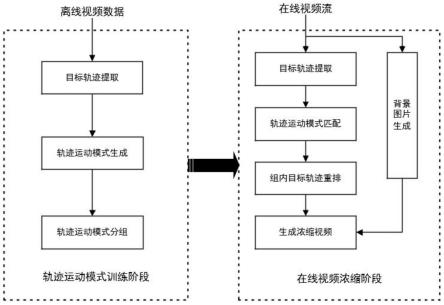
图1是本发明的方法整体流程示意图;
[0043]
图2是本发明的评估指标综合量化评价流程示意图;
[0044]
图3是本发明的综合量化评估值计算流程示意图。
具体实施方式
[0045]
在下面的描述中对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0046]
实施例1
[0047]
本发明的实施例1公开了一种模糊测试工具性能综合量化评估方法,如图1所示,具体步骤流程如下:
[0048]
s1:选定测试基准套件,设置实验条件;
[0049]
所述试验条件包括:测试次数、超时时间、基准模糊测试工具和种子。
[0050]
测试基准套件作为分析目标用于模糊测试,其采用人工编写的代码构建,基准测试套件中包含有一些明确的漏洞,这些漏洞满足下列4点条件:跨越程序的执行生命周期、嵌入有代表性的控制和数据流、提供作为存在证明的输入用例以及列出很小一部分可能的输入用例;
[0051]
本实施例中,测试基准套件选取lava-m标准语料库。lava-m语料库是coretils 8.24版本源代码的四个副本;一个副本在base64中注入了44个错误,并且有44个已知的分别触发这些错误的输入,另一个副本md5sum中有57个漏洞,第三个副本uniq中有28个漏洞。最后,有一个包含2136个漏洞的副本同时存在,并且在who中单独表达。lava-m添加了一种确保每个嵌入漏洞只由一个特定输入触发的机制,即独特的崩溃点中若包含于lava-m列出的输入,则这些崩溃点都由对应的独特的漏洞引发的,这些崩溃点数量代表独特的漏洞数量。
[0052]
本实施例中,所述测试次数设置为5次;
[0053]
本实施例中,所述超时时间设置为5小时,
[0054]
本实施例中,基准模糊测试工具选用aflfuzz。
[0055]
本实施例中,种子采用人工构建方式。采用aflfuzz作为基准模糊测试工具,由于使用时需要手动输入初始测试仪用例,作为初始种子,再通过基于变异的方式生成多个测试用例,采用人工构建的方式可使得被测试工具与aflfuzz工具的测试结果具有可比性。
[0056]
s2:选定评估指标;
[0057]
根据模糊测试工具的输入、输出和中间过程进行确定;
[0058]
本实施例中,所述评估指标包括崩溃点数量、代码覆盖率、暴露崩溃点的平均时间、漏洞数量、高危漏洞的数量和资源(cpu)占用率;
[0059]
崩溃点数量是指模糊测试中引发分析目标产生崩溃的测试用例的个数,需要说明的是,独特的崩溃点是指,导致分析目标崩溃的路径是唯一的情况下的测试用例。
[0060]
代码覆盖率是指模糊测试工具针对分析目标的路径识别能力或代码分片能力衡量评估指标。通常情况下,该评估指标与独特的崩溃点数量成正比关系。
[0061]
暴露崩溃点的平均时间是指模糊测试所用总时长与已发现独特的崩溃点数量之间的比值。
[0062]
漏洞数量是指崩溃点中属于不同类型漏洞的分类数,评估崩溃点由漏洞导致的可能性。崩溃点与漏洞的关系可以为多对一的关系,即多个崩溃点可能是由同一个漏洞导致。统计漏洞数量可通过选择特定的测试基准套件或使用漏洞类型分析工具实现。其中,特定的测试基准套件(如lava-m)需添加一种确保每个嵌入漏洞只由一个特定输入触发的机制,若模糊测试工具输出的崩溃点属于特定输入,则可判定该崩溃点属于该特定输入对应的漏洞类型。本实例中,漏洞数量统计基于测试基准套件,漏洞数量是指模糊测试工具检测出的漏洞中属于基准测试套件中已标记漏洞的数量。
[0063]
高危漏洞数量是指模糊测试工具检测出的漏洞中属于基准测试套件中已标记漏洞且属于高危漏洞的数量。测试基准套件中需预先设置每一类嵌入漏洞的严重等级。
[0064]
资源(cpu)占用率与模糊测试工具产生的测试用例数量成正比关系。基于种子变异的方式产生多个测试用例用于模糊测试,在崩溃点数量一致的情况下,工具若使用更少的测试用例找到一定数量的崩溃点,则表明该模糊测试工具使用的种子变异算法具有优势。
[0065]
s3:构建评估模型,进行评估指标综合量化评价;
[0066]
具体过程如下:
[0067]
s301:基于所述评估指标,针对每个评估指标分别对被测模糊测试工具进行测试,获得各评估指标对应的若干数值,构建评估指标数值矩阵x=(x
ij
)
(m
×
n)
,m为工具试验次数;n为工具评估指标个数,i和j表示数据索引值;
[0068]
s302:对得到的各评估指标对应数值进行数据正向化处理;
[0069]
模糊测试工具评估指标按分析类别可分为两类,一类是数值越小,评估结果越好,如:暴露崩溃点的平均时间和资源(cpu)占用率;另一类是数值越大,评估结果越好,如:崩溃点数量、路径覆盖率、漏洞数量和高危漏洞的数量。
[0070]
本实施例中,为了简化数据分析,将数据进行正向化处理,使得数值越大表示评估
结果越好。
[0071]
具体计算公式如下所示:
[0072][0073]
其中,表示正向化数据,xj表示某一评估指标对应的数值集合,x
ij
表示需要正向化的数据。
[0074]
s303:对正向化数据进行标准化处理;
[0075]
由于每一类评估指标数值都具有不同的量纲,不同评估指标的量纲可能不匹配,会影响综合量化评估结果,如崩溃点数量使用整数计数,数值可能采用“千”为量纲,但资源占用率以百分制表示,取值在[0,100],因而需要对数据进行标准化处理;
[0076]
然而,在实际中,经过正向化处理后的数据,可能存在值为“0”的情况,经典多属性决策方法中的平方和标准化方法会导致负向化评估指标权重与实际观察权重相差较大,且负向化评估指标权重通常大于正向化权重评估指标权重值,不符合实际情况。
[0077]
本实施例中,数据标准化的具体计算公式如下:
[0078][0079]
其中,y
ij
为标准化数据,表示正向化数据,表示正向化数据的第j列中的最小值,表示正向化数据的第j列中的最大值,i取值为{1,2,3
…
,m},j取值为{1,2,3
…
,n}。
[0080]
s304:计算各评估指标的权重;
[0081]
本实施例中,采用加权熵法计算权重,包括熵值计算、差异系数计算以及权重计算;
[0082]
具体过程如下:
[0083]
计算熵值:
[0084][0085]
其中,ej为某一评估指标熵值,m表示该评估指标对应的数值个数,即矩阵行数,表示某一评估指标第i个数值占该评估指标所有数值总和的比重;
[0086]
计算差异系数:
[0087]gj
=1-ej[0088]
其中,gj表示某一项评估指标的差异系数;
[0089]
计算权重:
[0090][0091]
其中,wj表示某一项评估指标的权重。
[0092]
s305:计算综合量化评估值,如下:
[0093]
计算加权标准化矩阵;根据所述加权标准化矩阵计算各评估指标的最优解和最劣解;再通过所述加权标准化矩阵、所述最优解和所述最劣解计算各评估指标最优解和最劣解的欧式距离,最后通过得到的欧式距离计算输出被测模糊测试工具的综合量化评估值。
[0094]
本实施例中,具体计算过程如下:
[0095]
计算加权标准化矩阵z
ij
:
[0096]zij
=wj×yij
[0097]
计算各评估指标最优解和最劣解:
[0098]
bi
j
=max(z
1j
,z
2j
,...,z
mj
)
[0099]
wi
j-=min(z
1j
,z
2j
,...,z
mj
)
[0100]
其中,bi
j
表示各评估指标最优解,wi
j-表示各评估指标最劣解,z
mj
为加权标准化矩阵中的数值,m取值为{1,2,
…
,m}。
[0101]
计算各评估指标最优解和最劣解欧式距离:
[0102][0103][0104]
其中,d
i
表示各评估指标最优解欧式距离,d
i-表示各评估指标最劣解欧式距离,z
ij
为加权标准化矩阵中的数值。
[0105]
计算综合量化评估值:
[0106][0107]
被测模糊测试工具对应的ci值越大,则表示该模糊测试工具综合量化得分越高。
[0108]
本发明并不局限于前述的具体实施方式。本发明扩展到任何在本说明书中披露的新特征或任何新的组合,以及披露的任一新的方法或过程的步骤或任何新的组合。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。