1.本发明属于电力系统负荷预测技术领域,具体涉及基于模式匹配的短期负荷预测方法。
背景技术:
2.负荷预测是制定电力调度计划的关键环节之一。准确的负荷预测,有助于系统合理安排机组的启停,新能源利用率的提高,自动发电控制和安全维护,对系统的安全稳定,经济调度起着重要的作用。随着我国新型电力系统建设的不断深入,用户侧高级量测体系的建立,这一过程中积累大量用户侧的用电数据,但用户集群由于分布较为分散,用电量较少,负荷具有较大波动性和随机性,对用户集群负荷的精准预测是当下的需解决的重要难题。
3.近年来,国内外许多学者对短期负荷预测做了大量研究,提出了许多预测模型和方法,大体可以分为两类,一类为以时间序列法为代表的传统的预测方法,另一类为基于数据驱动的人工智能方法。自回归(auto regression,ar)和自回归移动平均(auto regression moving average,arma)数学模型是时间序列法的常用模型,这两种模型只利用到了历史负荷数据,计算量小,速度快,但没有学习能力,对数据平稳性要求较高。为解决传统预测方法预测精度不高,适应能力较低的问题,基于数据驱动的人工智能方法也越来越多的参与到负荷预测中来,如人工神经网络(artificial neural network,ann),支持向量机(support vector machines,svm),随机森林,深度信念网络等等。现有采用深度信念网络进行变电站负荷预测,并用自适应矩阵估计算法得到网络的最佳参数,实现网络的自适应性,但计算较为复杂。还有的对元胞先进行k-means聚类后构建svm预测模型,实现空间负荷预测,但svm预测模型受核函数相关系数,惩罚系数c,影响较大。还有的提出了一种基于贝叶斯优化的卷积神经网络(convolutional neural network,cnn)双向门控循环网络(bidirectional gate recurrent unit,bigru)短期电力负荷预测方法。但神经网络训练容易出现“过拟合”问题,影响其模型的泛化能力,降低预测精度。还有的利用c均值模糊聚类算法对历史样本进行聚类,后对同类数据构建随机森林回归模型进行预测。但该方法需创建很多决策树,训练时所需要的空间和时间会很大。
4.然而,随着新能源发电系统在用户侧的普及,使得用户集群负荷随机性和波动性增强,应用上述单一的预测方法可能由于随机性而导致泛化性能不佳。
技术实现要素:
5.本发明目的在于提供基于模式匹配的短期负荷预测方法,用于解决上述现有技术中存在的技术问题,实现用户负荷与负荷模式的自适应匹配;也实现负荷模式与最佳预测模型的匹配,充分发挥每个预测模型的优势,可有效提高整体的预测精度。
6.为实现上述目的,本发明的技术方案是:
7.基于模式匹配的短期负荷预测方法,包括以下步骤:
8.s1、采用基于皮尔逊相关系数的层次k-means聚类算法,将用户历史负荷数据最优地划分出多种月负荷模式;
9.s2、针对每一个月负荷模式,从反馈神经网络,支持向量机回归和线性回归中选取验证效果最佳的模式匹配算法;
10.s3、根据用户最新月的负荷数据与月负荷模式的相似度,将用户用电数据与月负荷模式自适应匹配,各个模式预测结果相加便得到总的预测结果。
11.进一步的,步骤s1具体如下:
12.基于皮尔逊相关系数的聚类相似度度量函数:
13.设xi=(x
i1
,x
i2
,
…
,x
in
),xj=(x
j1
,x
j2
,
…
,x
jn
)为两条负荷曲线,其皮尔逊相关系数为:
[0014][0015]
式中:和分别为xi和xj的均值;
[0016]
层次k-means聚类方法原理:
[0017]
重复进行多次相同k值的k-means聚类,记录下每次的聚类中心;
[0018]
对所有记录下的聚类中心,进行层次聚类;
[0019]
以层次聚类得出的聚类中心作为初始聚类中心,再进行一次k-means聚类,得到最终的聚类结果;
[0020]
聚类指标的选取:
[0021]
评价指标为:
[0022][0023]
式中:k为聚类数目,vc为各聚类簇的聚类中心;nk为当前第k类簇包含的样本数。
[0024]
进一步的,步骤s2具体如下:
[0025]
bp神经网络算法机理:
[0026][0027]
其中:p为输入向量,b为偏置常数,w为输入信号到神经元的权值向量,f为激励函数,y为神经元的输出信号;神经元的输出为
[0028]
y=f(wp b) (14)
[0029]
bp神经网络由输入层,隐藏层和输出层三部分组成,每层之间的神经元进行全连接;
[0030]
bp神经网络算法由两部分组成:一是信号的前向传播,二是计算输出值和真实值
的误差,将误差反向传播,通过l-m算法不断修正各个神经元的参数;参数修正完后再次进行训练,直到训练结果达到误差要求或训练最大次数;
[0031]
支持向量机回归算法机理:
[0032]
通过非线性映射将输入向量映射到高维特征空间,通过计算得到一个回归超平面,让集合中所有样本点到该超平面的距离和最小;非线性映射也被称作核函数;设定输入的样本为m={(xi,yi),i=1,2,
…
n},xi∈rd,yi∈r,svr得到的超平面函数表达式为:
[0033]
f(x)=ωφ(x) b (15)
[0034]
式中:φ(
·
)为核函数,b为阈值,ω为权值向量;
[0035]
svr损失函数为:
[0036][0037]
式中:ε为容忍样本点到超平面的的距离,即当样本点距离超平面距离小于或等于ε,损失为0;
[0038]
线性回归算法机理:
[0039]
线性回归是利用回归方程对一个或多个自变量x和因变量y之间关系进行建模的一种分析方式;其模型为:
[0040]
f(x)=w0 w1x1 w2x2 ... wnx
n (17)
[0041]
y=f(x) δ (18)
[0042]
式中:w为权值系数,δ为残差;线性回归的主要目的是求得系数w使对于集合中所有样本点m={(xi,yi),i=1,2,
…
n}离f(x)距离和最近;线性回归采用最小二乘法求出其方程;
[0043][0044]
ω1,...,ωn=(x
t
y)-1
x
t
y (20)
[0045]
利用线性回归做负荷预测计算量小,直接得出输入特征与预测信息的关系。
[0046]
进一步的,步骤s3具体如下:
[0047]
输入特征参数:
[0048]
预测第t时刻的负荷p
t
,需要给模型输入与t时刻负荷相关性很强的特征参数;输入特征参数为:
[0049]
x={p
t-h
,p
t-h-1
,p
t-h-2
,p
t-h 1
,p
t-h 2
,p
t-2h
,p
t-2h-1
,p
t-2h 1
,
[0050]
p
t-3h
,p
t-7h
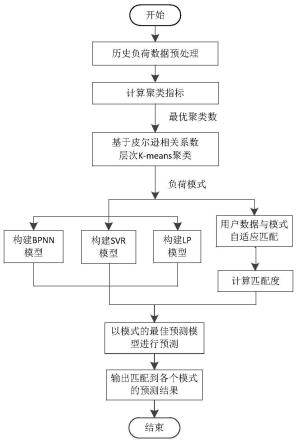
,weekday,hour}
[0051]
式中前7个为历史负荷数据,h为采集负荷数据一天的时刻数,weekday,hour分别表征星期和小时;
[0052]
基于皮尔逊相关系数的用电负荷模式匹配:
[0053]
设定一个月按28计算,在预测某月第q 1(q=0,1,
…
27)天的负荷时,需要选取预测日前28天的负荷数据进行模式匹配,其中包含本月前q天的数据data1,和上一月后28-q的负荷数据data2;为使得模式匹配时间上的一致,将data1数据移到data2之前,拼接成一个用户从月初到月末的完成月负荷数据data3;计算每个用户data3与每个月负荷模式的皮尔逊相关系数,以其最低值将每个用户归类到形态最相似的月负荷模式中;
[0054]
负荷预测总流程:
[0055]
(1)对用户负荷数据进行预处理;
[0056]
(2)以所有用户的一个月的负荷为样本,对样本进行多次基于皮尔逊系数的k-means聚类,计算聚类指标v,得到最佳的聚类数kb;
[0057]
(3)选取聚类数为kb,进行基于皮尔逊相关系数的层次k-means聚类,得到kb类月负荷,以每类月负荷的聚类中心作为月负荷模式;
[0058]
(4)对每个月负荷模式构建bpnn,svr和lr模型;选择测试效果最佳的模型与月负荷模式进行匹配;
[0059]
(5)将每个用户预测日前一个月负荷与与之形态最相似的月负荷相匹配;
[0060]
(6)对匹配到同一模式的用户月负荷求和,计算与月负荷模式的匹配度,即皮尔逊相关系数;
[0061]
(7)以月负荷模式最佳的预测模型进行负荷预测,将每个模式的预测结果相加得到最终的负荷预测结果;
[0062]
(8)在(7)中如果月负荷模式的最佳预测模型是bpnn,且得到的用户负荷数据与月负荷模式的匹配度小于一定的阈值则使用bpnn预测模型,否则使用该月负荷模式的次优预测模型;
[0063]
(9)使用mape和rmse对用户集群预测效果进行评估;
[0064][0065][0066]
式中:e为实际值,o为预测值,n为预测数目。
[0067]
与现有技术相比,本发明所具有的有益效果为:
[0068]
本方案其中一个有益效果在于,首先充分挖掘用户历史负荷数据的形态特征,聚类出波动规律性较强的负荷模式,根据最新的用户负荷数据与负荷模式的相似度,将用户负荷数据与负荷模式相匹配,以将波动规律较为一致的数据自动地归为到一类。针对每类负荷模式从多种预测模型中选取验证效果最佳的预测模型,以提高每类负荷模式的预测精度。以上方法实现了用户负荷与负荷模式的自适应匹配;也实现了负荷模式与最佳预测模型的匹配,充分发挥了每个预测模型的优势,可有效提高整体的预测精度。对用户的用电负荷进行基于皮尔逊相关系数的形态聚类,自适应匹配用户的用电负荷模式。对每个负荷模式采取最佳的预测模型,以获得最优的预测结果。通过算例表明,基于模式自适应匹配的算法能有效提高预测精度。
附图说明
[0069]
图1为本发明中一个具体实施方式的3条负荷曲线形态相似性比较图。
[0070]
图2为本发明中一个具体实施方式的神经元模型图。
[0071]
图3为本发明中一个具体实施方式的三层bp网络结构图。
[0072]
图4为本发明中一个具体实施方式的模式匹配示意图。
[0073]
图5为本发明中一个具体实施方式的预测流程图。
[0074]
图6为本发明中一个具体实施方式的聚类指标图。
[0075]
图7为本发明中一个具体实施方式的月负荷模式图。
[0076]
图8为本发明中一个具体实施方式的用户集群预测结果图。
具体实施方式
[0077]
下面结合本发明的附图1-附图8,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0078]
实施例:
[0079]
提供一种基于模式匹配的短期负荷预测方法。以300户带有光伏发电系统的居民负荷数据为基础,用皮尔逊相关系数度量用户月负荷的形态距离,采用层次k-means聚类方法最优地划分出不同的月负荷模式。针对每个月负荷模式都进行反馈神经网络(back propagation neural network,bpnn),支持向量机回归(support vector regression,svr)和线性回归(linear regression,lr)模型训练、验证。进行负荷预测时,根据预测日前一月的用户用电数据,将所有用户匹配到形态距离最近的负荷模式中,并以上述测试效果最佳的预测模型进行预测。最后使用平均绝对百分误差(mean absolute percentage error,mape)和均方根误差(root mean square error,rmse)作为误差测量,通过比较其他预测方法,验证了所提用户集群预测方法的有效性。
[0080]
一、基于层次k-means聚类算法月负荷模式的划分与匹配
[0081]
层次k-means聚类:
[0082]
聚类分析主要目标是通过比较所有样本的相似度高低,将相似度高的样本划分为一类,将相似度低的样本划分为不同类。常用的样本相似度度量方法是将样本归一化,并计算归一化样本之间的欧氏距离,但是归一化会造成数据信息压缩和丢失,基于欧式距离的度量方法会因距离平方和计算两个样本的总体差异,而忽略了样本形态上的差异,从而导致聚类效果不理想。k-means算法作为经典的聚类算法,广泛应用于电力负荷聚类分析中,但其初始聚类中心是随机的,且聚类数k值需要人为确定,可能导致聚类效果出现偏差。为解决以上问题,采用基于皮尔逊相关系数的层次k-means聚类算法。
[0083]
基于皮尔逊相关系数的聚类相似度度量函数:
[0084]
皮尔逊系数常用于曲线形态相似度的度量。设xi=(x
i1
,x
i2
,
…
,x
in
),xj=(x
j1
,x
j2
,
…
,x
jn
)为两条负荷曲线,其皮尔逊相关系数为:
[0085][0086]
式中:和分别为xi和xj的均值。从式中可以看出,计算时样本减去了样本均值,消除了曲线幅值对相似度的影响。两条曲线形态上越相似,皮尔逊相关系数越低,当两条曲线形态上完全一致时,皮尔逊相关系数为0。如图1所示,图中三条曲线分别为三个用户某天
的用电负荷曲线q1,q2,q3。计算q2、q3与q1的欧式距离d和皮尔逊相关系数r,d(q1,q2)=133.2,d(q2,q3)=346.4,d(q1,q3)=363.7,r(q1,q2)=0.2524,r(q1,q3)=0.2524,r(q2,q3)=0。用欧式距离计算,q1,q2更为接近,但实际上q2,q3形态上完全一致,计算出来的皮尔逊系数为0。除此之外,现有用余弦相似度作为形态相似性度量,但余弦相似度受曲线幅值影响。因此,选用皮尔逊相关系作为负荷曲线形态相似性的度量。
[0087]
层次k-means聚类方法原理:
[0088]
k-means算法作为一种经典划分式算法,其聚类结果取决于初始聚类中心和聚类数k。如果选取不当,会直接导致聚类效果不理想。层次聚类算法可以不用选取初始聚类中心,聚类效果稳定,但其计算复杂度较高,不适用于大规模数据聚类。因此,将二者结合,建立层次k-means聚类算法,可减小计算复杂度,并提高聚类稳定性。层次k-means聚类算法的步骤为:
[0089]
(1)重复进行多次相同k值的k-means聚类,记录下每次的聚类中心;
[0090]
(2)对所有记录下的聚类中心,进行层次聚类;
[0091]
(3)以层次聚类得出的聚类中心作为初始聚类中心,再进行一次k-means聚类,得到最终的聚类结果。
[0092]
该算法可以解决k-means聚类初始聚类中心随机性的问题,但聚类数k仍需人为确定。聚类指标的选取可以确定最优的聚类数。
[0093]
聚类指标的选取:
[0094]
选取合适的聚类质量评价指标,对聚类有效性进行校验,可以确定最优的聚类数k。现有基于图的有效性指标,构建了余弦相似度的聚类评价指标。此方法同样适用于基于皮尔逊相关系数的聚类分析。评价指标为:
[0095][0096]
式中:k为聚类数目,vc为各聚类簇的聚类中心;nk为当前第k类簇包含的样本数。该指标表征各类样本到其相应聚类中心的距离之和,v随着聚类数目的递增而减小,当v值下降趋势趋于平缓时,所对应的聚类数就是最佳聚类数。
[0097]
二、负荷预测方法及流程
[0098]
负荷预测方法:
[0099]
不同的预测方法对不同的负荷模式预测效果不同,为提高预测精度,从bpnn,svr和lr三种预测方法中选取适合负荷模式的最佳预测模型。
[0100]
bp神经网络算法机理:
[0101]
人工神经网络具有自学习、自组织、自适应以及很强的非线性函数逼近能力,拥有强大的容错性。图2为神经元模型结构。
[0102]
图中:p为输入向量,b为偏置常数,w为输入信号到神经元的权值向量,f为激励函数,y为神经元的输出信号。神经元的输出为
[0103]
y=f(wp b) (25)
[0104]
bp神经网络作为常用的人工神经网络,由输入层,隐藏层和输出层三部分组成,每层之间的神经元进行全连接,其结构如图3所示。
[0105]
bp神经网络算法主要由两部分组成:一是信号的前向传播,二是计算输出值和真
实值的误差,将误差反向传播,通过l-m(levenberg-marquardt)算法不断修正各个神经元的参数。参数修正完后再次进行训练,直到训练结果达到误差要求或训练最大次数。bp神经网络模型没有具体的数学表达式,其模型完全由网络结构和参数表征。
[0106]
支持向量机回归算法机理:
[0107]
支持向量回归是支持向量机(support vector machine,svm)的重要应用分支。其是通过非线性映射将输入向量映射到高维特征空间,通过计算得到一个回归超平面,让集合中所有样本点到该超平面的距离和最小。非线性映射也被称作核函数,常用的核函数有线性函数,多项式函数,高斯函数,径向基函数等。设定输入的样本为m={(xi,yi),i=1,2,
…
n},xi∈rd,yi∈r,svr得到的超平面函数表达式为:
[0108]
f(x)=ωφ(x) b (26)
[0109]
式中:φ(
·
)为核函数,b为阈值,ω为权值向量。
[0110]
svr损失函数为:
[0111][0112]
式中:ε为可以容忍样本点到超平面的的距离,即当样本点距离超平面距离小于等于ε,损失为0。模型得求解很多现有技术已有叙述,这里就不在赘述。
[0113]
线性回归算法机理:
[0114]
线性回归(linear regression,lr)是利用回归方程(函数)对一个或多个自变量x和因变量y之间关系进行建模的一种分析方式。其模型为:
[0115]
f(x)=w0 w1x1 w2x2 ... wnx
n (28)
[0116]
y=f(x) δ (29)
[0117]
式中:w为权值系数,δ为残差。线性回归的主要目的是求得系数w使对于集合中所有样本点m={(xi,yi),i=1,2,n}离f(x)距离和最近。线性回归一般采用最小二乘法求出其方程。
[0118][0119]
ω1,...,ωn=(x
t
y)-1
x
t
y (31)
[0120]
利用线性回归做负荷预测计算量小,直接得出输入特征与预测信息的关系,可解释性好。
[0121]
三、基于模式匹配的负荷预测流程
[0122]
输入特征参数部分:
[0123]
预测第t时刻的负荷pt,需要给模型输入与t时刻负荷相关性很强的特征参数。历史负荷,工作日,周末以及每天所处的时刻对用电负荷影响较大,选择的输入特征参数为:
[0124]
x={p
t-h
,p
t-h-1
,p
t-h-2
,p
t-h 1
,p
t-h 2,
p
t-2h
,p
t-2h-1
,p
t-2h 1
,
[0125]
p
t-3h
,p
t-7h
,weekday,hour}
[0126]
式中前7个为历史负荷数据,h为采集负荷数据一天的时刻数,weekday,hour分别表征星期和小时。
[0127]
基于皮尔逊相关系数的用电负荷模式匹配部分:
[0128]
设定一个月按28计算(下同),在预测某月第q 1(q=0,1,
…
27)天的负荷时,需要
选取预测日前28天的负荷数据进行模式匹配,其中包含本月前q天的数据data1,和上一月后28-q的负荷数据data2。为使得模式匹配时间上的一致,将data1数据移到data2之前,拼接成一个用户从月初到月末的完成月负荷数据data3。计算每个用户data3与每个月负荷模式的皮尔逊相关系数,以其最低值将每个用户归类到形态最相似的月负荷模式中。模式匹配如图4所示。
[0129]
负荷预测总流程部分:
[0130]
所提出的基于模式自适应匹配的用户集群预测方法的总流程如图5所示,其具体步骤为:
[0131]
(1)对用户负荷数据进行预处理。
[0132]
(2)以所有用户的一个月(按28天计算)的负荷为样本,对样本进行多次基于皮尔逊系数的k-means聚类,计算聚类指标v,得到最佳的聚类数kb。
[0133]
(3)选取聚类数为kb,进行基于皮尔逊相关系数的层次k-means聚类,得到kb类月负荷,以每类月负荷的聚类中心作为月负荷模式。
[0134]
(4)对每个月负荷模式构建bpnn,svr和lr模型。选择测试效果最佳的模型与月负荷模式进行匹配。
[0135]
(5)将每个用户预测日前一个月负荷与与之形态最相似的月负荷相匹配。
[0136]
(6)对匹配到同一模式的用户月负荷求和,计算与月负荷模式的匹配度,即皮尔逊相关系数。
[0137]
(7)以月负荷模式最佳的预测模型进行负荷预测,将每个模式的预测结果相加得到最终的负荷预测结果。
[0138]
(8)在步骤(7)中如果月负荷模式的最佳预测模型是bpnn,且得到的用户负荷数据与月负荷模式的匹配度小于一定的阈值(设),方可使用bpnn预测模型,否则使用该月负荷模式的次优预测模型,以解决bpnn模型训练时出现的“过拟合”,导致泛化能力差,预测结果不好的问题。
[0139]
(9)使用mape和rmse对用户集群预测效果进行评估。
[0140][0141][0142]
式中:e为实际值,o为预测值,n为预测数目。
[0143]
算例分析:
[0144]
选取澳大利亚300户带有光伏发电系统居民用户的电网侧用电数据进行分析。数据长度从2010年7月1日到2011年6月30日。时间分辨率为30分钟。
[0145]
月负荷划分结果:
[0146]
选取300户居民2010年7月1日开始前10月的数据,共计3000个月负荷数据样本。按照上述步骤(2),得到聚类指标如图6所示。
[0147]
从图中可以看出,k值在9~12之间,评价指标v下降趋势趋缓,选择kb=9为最佳聚类数。再进行层次k-means聚类,得到9类月负荷模式。如图7所示。
[0148]
从图中可以看出,9类月负荷模式波动模式都不相同,第1,2,3,5,8,9类模式每天
负荷波动较为平稳,规律性强。第4类模式每天负荷幅值有增大的趋势。第6,7类模式的负荷波动较随机。
[0149]
月负荷模式共计有1344个点,如果月负荷模式的数据首尾相接,即可以用月负荷末端的数据预测月负荷首端负荷,可以构建1344个训练样本,从中均匀、有放回的选出1344个样本进行预测模型预测训练,大约有63%的样本用于训练,剩下没有被抽取到的样本用于测试,得到的测试效果如下表1所示。
[0150]
表1各类月负荷模式不同模型测试误差mape
[0151]
tab 1mape of different model test errors for various monthly load patterns
[0152][0153]
表中加粗标注字体的是适合该类月负荷模式的最佳模型的测试误差。例如:第1类月负荷模式选用svr预测模型效果最好,测试误差为0.087。
[0154]
实验对象设置和结果分析:
[0155]
为了验证所提方法的有效性,设置以下4个方案进行负荷预测。
[0156]
方案一,不进行模式划分,使用bpnn直接预测。
[0157]
方案二,不进行模式划分,使用svr直接预测。
[0158]
方案三,不进行模式划分,使用lr直接预测。
[0159]
方案四,进行模式划分和匹配,每个模式按最佳预测方法进行预测。
[0160]
对11月前7日进行负荷预测,得到的预测结果如图8和表2所示:
[0161]
表2不同实验方案用户集群预测结果
[0162]
tab 2consumer cluster prediction results of different experimental schemes
[0163][0164]
对比以上结果发现,相较于其他使用单一模型的方法,所提的自适应模式匹配预测方法能达到最佳的预测效果,能够提升约0.6%的预测精度
[0165]
选取第11月第7日模式匹配结果如下表3所示:
[0166]
表3 11月第7日模式匹配结果
[0167]
tab 3pattern matching results on november 7
[0168][0169]
从表3中可以得出,模型匹配到的用户数越少,匹配度越高,即用户负荷数据与月负荷模式形态相似度越低,这在一定程度上会使预测效果变差,但因为用户数较少,对整体负荷预测的影响较小。
[0170]
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。