技术特征:
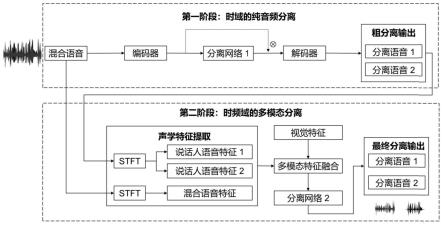
1.一种基于视觉导引的两阶段语音分离方法,其特征是,包括以下步骤:在第一阶段,对获取的混合语音在时域上进行分离,获得粗分离的说话人语音;在第二阶段,首先对第一阶段的粗分离语音提取具有说话人身份信息的独立声音特征,然后挖掘视觉和音频两种模态之间的潜在相关特征和互补特征,其次进行视觉特征和语音时频域特征两种模态的融合后再分离,对两个阶段动态调整权重后最终得到分离后的目标语音。2.如权利要求1所述的一种基于视觉导引的两阶段语音分离方法,其特征是,所述第一阶段,具体过程包括:利用编码器对获取的混合语音进行编码,提取混合语音特征;利用第一分离网络对混合语音特征进行分离,得到目标语音的掩码,掩码与混合语音特征相乘后再进行解码,获得目标语音的时域信号。3.如权利要求2所述的一种基于视觉导引的两阶段语音分离方法,其特征是,第一阶段对混合语音特征进行分离的具体过程包括,利用第一分离网络,处理混合语音特征,所述第一分离网络为时间卷积网络结构,包括一个归一化层,多个相同的栈模块,其中每个栈模块由全卷积、膨胀卷积和残差模块构成,最后一个栈模块的输出经过卷积层和prelu激活层得到分离后的目标掩码;或,所述目标语音特征为混合语音特征和目标语音的掩码相乘计算得到,目标语音特征经过解码后得到目标语音的时域信号。4.如权利要求1所述的一种基于视觉导引的两阶段语音分离方法,其特征是,所述第二阶段,具体过程包括:对混合语音进行变换,得到混合语音的复谱图,根据其获取真实纯净语音的复谱掩码;对第一阶段获取的目标语音的时域信号进行转换,得到分离后的各个说话人的复谱图,并提取各个说话人的独立语音特征;获取与混合语音时间同步的说话人的视觉信息并进行预处理,对预处理后的视觉图像分别提取静态视觉特征和动态视觉特征。对混合语音复谱图的时频域信息提取混合语音特征并进行多模态特征融合,并分离所述多模态特征,得到分离后的目标语音的掩码,将所述掩码和混合语音的复谱图相乘后进行逆变换,得到目标说话人的纯净语音信号。5.如权利要求4所述的一种基于视觉导引的两阶段语音分离方法,其特征是,对第一阶段获取的目标语音的时域信号进行转换的具体过程包括:首先粗分离语音进行时频域转换得到复谱图;然后使用独立语音特征提取网络resnet-18对各个说话人的复谱图提取独立语音特征;接着对独立语音特征进行时间维度转换以实现音频和视频两种模态特征的维度一致性。6.如权利要求4所述的一种基于视觉导引的两阶段语音分离方法,其特征是,获取与混合语音时间同步的说话人的视觉信息并进行预处理的具体过程包括读取视频文件,截取设定长度视频获取多帧图像序列,随机选择一帧面部图像作为静态视觉信息;然后对各帧图像序列进行裁剪,选取大小设定的唇部区域,生成唇部序列的文件,作为动态视觉信息。7.如权利要求6所述的一种基于视觉导引的两阶段语音分离方法,其特征是,提取视觉特征的具体过程包括对唇部图像进行归一化和数据填充,预处理后的唇部数据依次经过一
个3d卷积层、shufflenet v2网络,再经过时间卷积网络结构来提取时间序列特征,最后获得的动态视觉特征,动态视觉特征包含了语音的内容信息;对面部图像进行标准化和大小处理,经过一个残差网络resnet-18提取静态视觉特征,其中静态视觉特征包含了具有区分性的说话人的身份信息;对静态视觉特征进行转换,使其和动态的视觉序列特征具有相同的时间维度。8.如权利要求4所述的一种基于视觉导引的两阶段语音分离方法,其特征是,进行多模态特征融合的具体过程包括首先混合声音复谱图经过u-net下采样网络层得到混合语音特征,然后对说话人的视觉特征、独立语音特征和混合声音特征做级联拼接,最后得到融合的多模态特征;或,利用第二分离网络分离所述多模态特征,所述第二分离网络为u-net的上采样网络层。9.如权利要求1所述的一种基于视觉导引的两阶段语音分离方法,其特征是,对于两阶段的语音分离的损失函数权重进行动态调整,以最大程度的利用第一阶段的独立语音特征来辅助第二阶段的分离。10.一种基于视觉导引的两阶段语音分离系统,其特征是,包括:第一分离模块,被配置为在第一阶段,对获取的混合语音在时域上进行分离,获得独立的说话人语音;第二分离模块,被配置为在第二阶段,借助第一阶段的纯音频分离结果提取具有说话人信息的独立语音特征,同时挖掘视觉和音频两种模态之间的潜在相关特征和互补特征,进行视觉特征和语音时频域特征两种模态的融合后再分离,最终得到分离后的目标语音;动态调整权重模块,根据两个阶段的分离模型性能,动态调整其权重,以最大程度的利用第一阶段提取的独立语音特征来辅助第二阶段,实现纯净的目标说话人语音分离。
技术总结
本发明提供了一种基于视觉导引的两阶段语音分离方法及系统,在第一阶段,对获取的混合语音在时域上分获得说话人语音;在第二阶段,借助第一阶段的粗分离语音提取具有说话人信息的独立语音特征,同时挖掘视觉和音频模态之间的潜在相关特征和互补特征并进行多模态特征的融合与分离,最终得到纯净的目标语音。本发明利用第一阶段提取说话人的独立语音特征,避免引入纯净的参考声音,通过视觉导引的语音分离性能和鲁棒性得到提升,同时解决了标签排列问题。本发明通过动态调整两阶段模型的权重以进一步提升语音分离质量,所公开的语音分离系统适用于大多数应用场景。分离系统适用于大多数应用场景。分离系统适用于大多数应用场景。
技术研发人员:魏莹 邓媛洁 张寒冰
受保护的技术使用者:山东大学
技术研发日:2022.10.26
技术公布日:2023/2/3
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。