1.本发明涉及一种基于强化学习的航空器滑出时间预测方法,属于机场场面态势感知技术领域。
背景技术:
2.随着航空运输业的蓬勃发展,航班需求量持续增加。当需求接近或超出可利用容量时,地面管制员的协调能力受到考验。尤其是在大型繁忙机场,由场面拥堵导致飞机在滑行阶段的延误现象频发[1]。此外,约60%的飞行延误是由场面滑行延误引起的[2],因此准确预测滑行时间重中之重。微观层面上,准确的滑行时间有利于更好地估计离港航班的起飞时间和进港航班的上轮挡时间,进而提高场面交通的可预测性;宏观层面上,有利于更好地感知场面整体的交通态势和周转效率。
[0003]
在现有的滑行时间预测研究中,最常见的是队列模型[3]和线性回归方法[4]。本质上,这些方法更适用于识别不同影响因素的重要程度,在预测精度上往往无法达到实际要求。为了提高模型的预测能力,更多先进的机器学习模型被尝试[5-6],如支持向量机、随机森林等,但这些方法主要面向个体航空器,只能对各个航班的滑行时间进行预测,无法在整体层面上感知机场滑行态势。此外,大多数方法忽略了各个航班之间的时序特性,在趋势预测方面无法得到满意的结果。
[0004]
因此,为了科学有效地把握机场场面交通运行状况,有力地支撑场面活动的精细化管理,亟需对机场场面滑行过程进行建模,实现个体航空器滑行时间的精准预测和整体机场场面滑行态势的动态评估。
[0005]
[1]roosens p.congestion and air transport:a challenging phenomenon[j].european journal of transport and infrastructure research,2008,8(2).
[0006]
[2]laskey k b,xu n,chen c h.propagation of delays in the national airspace system[c]//proceedings of the twenty-second conference on uncertainty in artificial intelligence.2006:265-272.
[0007]
[3]idris,h.,clarke,j.p.,bhuva,r.,kang,l.,2002.queuing model for taxi-out time estimation.air traffic control quarterly 10,1
–
22.
[0008]
[4]ravizza,s.,atkin,j.a.,maathuis,m.h.,burke,e.k.,2013.a combined statistical approach and ground movement model for improving taxi time estimations at airports.journal of the operational research society 64,1347
–
1360.
[0009]
[5]ravizza s,chen j,atkin j a d,et al.aircraft taxi time prediction:comparisons and insights[j].applied soft computing,2014,14:397-406.
[0010]
[6]wang x,brownlee a e i,woodward j r,et al.aircraft taxi time prediction:feature importance and their implications[j].transportation research part c:emerging technologies,2021,124:102892.
技术实现要素:
[0011]
本发明的目的是提供一种基于强化学习的航空器滑出时间预测方法,以在复杂机场场面环境中准确高效地预测航空器滑出时间,评估场面整体滑行态势,提高机场场面的智能化管理能力。
[0012]
为实现上述目的,本发明采用如下技术方案:
[0013]
一种基于强化学习的航空器滑出时间预测方法,包括以下步骤:
[0014]
步骤1,对获取到的机场场面运行数据进行预处理,并构建影响航空器滑出时间的特征集;
[0015]
步骤2,定义马尔可夫决策过程的五元组,离散化系统的状态和动作并初始化累计奖赏;
[0016]
步骤3,利用探索过程和学习过程进行动作选择,确定下一个系统状态并更新累计奖赏;
[0017]
步骤4,设置预定义的停止条件,迭代训练强化学习算法得到最优累计奖赏;
[0018]
步骤5,利用最优累计奖赏对个体航空器滑出时间进行预测,对机场场面整体滑行态势进行评估。
[0019]
所述步骤1中,通过机场监测系统记录的航空器实时数据,得到机场场面运行情况的实测数据,然后提取计划和实际的推出时间、起飞时间,从交通状态和时序特性角度构建影响航空器滑出时间的特征集。
[0020]
所述影响航空器滑出时间的特征集包括:
[0021]
离港瞬时流量:在计划推出时刻处于滑出阶段的航班数量;
[0022]
离港累计流量:在计划推出时刻和计划起飞时刻之间活动的离港航班数量;
[0023]
离港队列长度:在计划推出时刻和计划起飞时刻之间内预计起飞的航班数量;
[0024]
离港资源需求:在计划推出时刻前后15分钟的区间内预计推出的航班数量;
[0025]
前30分钟平均滑出时间:在计划推出时刻前30分钟内活动的离港航班的平均滑出时间;
[0026]
当前时间索引:计划推出时刻对应的小时索引。
[0027]
所述步骤2中,用马尔可夫决策过程的五元组建模航空器滑出时间预测问题,确定系统状态、动作、奖赏函数和折扣系数;然后分别对状态和动作进行离散化处理,并对状态、动作的各种组合初始化累计奖赏。具体为:由步骤1的特征集中的特征构成状态集合s,所有可能的滑出时间构成动作集合a,根据如下公式定义奖赏函数:
[0028]
r(s,a,s')=-|t
actual-t
predicted
|
[0029]
该式表明从状态s采取动作a转移到状态s'得到的回报,其中t
actual
为真实滑出时间,t
predicted
为预测的滑出时间;接着根据各个特征和滑出时间的取值范围,相应地将状态空间s和动作空间a进行离散化处理,并对任意的状态s和动作a,用0初始化r(s,a)。
[0030]
所述步骤3中,根据迭代次数确定进入探索过程或者学习过程,选择对应动作得到预测的滑出时间;然后计算并且更新奖赏函数,进入下一个系统状态。具体为:设置总迭代次数,当前迭代次数小于总迭代次数时,进行探索过程,以概率p选择贪婪动作1-p选择随机动作,进而得到预测的滑出时间,计算r(s,a,s')并更新累计奖赏r(s,a),进入下一个系统状态s';当前迭代次数达到总迭代次数时,进入学习过程,直接选择贪婪动作得到预测的滑
出时间,计算r(s,a,s')并更新累计奖赏r(s,a),进入下一个系统状态s';其中,使用近似动态规划更新累计奖赏,如下所示:
[0031][0032]
其中,α为学习参数,n为迭代次数。
[0033]
所述步骤4中,设置预测稳定的停止条件为|r
n 1
(s,a)-rn(s,a)|≤ε,其中ε为一个很小的正数;当达到该条件时表示训练完成,得到最优累计奖赏r
optimal
(s,a)。
[0034]
所述步骤5中,利用训练好的强化学习模型得到最优累计奖赏,计算各航空器的状态并将该状态下的最优动作视为预测的滑出时间;然后计算各个时间片下航空器预测滑出时间的均值,并将其视为该时间片机场整体的滑行态势。具体为:利用训练好的强化学习模型得到最优累计奖赏r
optimal
(s,a),对计划在t时刻推出的航空器而言,首先计算该航班的机场系统状态s,然后将该状态下的最优动作视为预测的滑出时间,计算公式如下:
[0035][0036]
当获得了所有航班预测的滑出时间,以15分钟为单位,统计一天内各时间片预测的航空器滑出时间的均值,并将其作为机场场面滑行态势的度量值以此评估一天的滑行态势变化情况。
[0037]
有益效果:相比于现有技术,本发明具有以下优点:
[0038]
1、本发明具有智能学习能力,预测所需的机场场面运行数据样本集易于获取。
[0039]
2、以多个视角构建影响航空器滑出时间的特征集,利用马尔可夫决策过程建模航空器滑出时间预测问题。
[0040]
3、利用强化学习模型实现马尔可夫决策过程的训练,通过探索过程和学习过程对环境进行感知,能够有效地处理动态变化环境中的序列决策问题。
[0041]
4、本发明在复杂的机场场面环境中,能准确地预测航空器滑出时间,评估场面整体的滑行态势,为智慧机场的建设提供新思路。
附图说明
[0042]
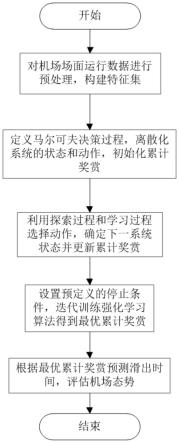
图1为本发明的方法流程图。
具体实施方式
[0043]
下面结合附图对本发明做更进一步的解释。
[0044]
如图1所示,本发明的一种基于强化学习的航空器滑出时间预测方法,包括以下步骤:
[0045]
步骤1,通过机场监测系统记录的航空器实时数据,得到机场场面运行情况的实测数据,然后提取计划和实际的推出时间、起飞时间,从交通状态和时序特性角度构建影响航空器滑出时间的特征集,分别为:离港瞬时流量、离港累计流量、离港队列长度以及离港资源需求、前30分钟平均滑出时间和当前时间索引。给定一架离港航空器的计划推出时间和计划起飞时间,各个特征的定义如下:
[0046]
1)离港瞬时流量:在计划推出时刻处于滑出阶段的航班数量。
[0047]
2)离港累计流量:在计划推出时刻和计划起飞时刻之间活动的离港航班数量。
[0048]
3)离港队列长度:在计划推出时刻和计划起飞时刻之间内预计起飞的航班数量。
[0049]
4)离港资源需求:在计划推出时刻前后15分钟的区间内预计推出的航班数量。
[0050]
5)前30分钟平均滑出时间:在计划推出时刻前30分钟内活动的离港航班的平均滑出时间
[0051]
6)当前时间索引:计划推出时刻对应的小时索引。
[0052]
步骤2,定义马尔可夫决策过程的五元组,离散化系统的状态和动作并初始化累计奖赏;
[0053]
用马尔可夫决策过程的五元组建模航空器滑出时间预测问题,确定系统状态、动作、奖赏函数和折扣系数;然后分别对状态和动作进行离散化处理,并对状态、动作的各种组合初始化累计奖赏。
[0054]
由步骤1的特征集中的六个特征构成状态集合s,所有可能的滑出时间构成动作集合a,根据如下公式定义奖赏函数:
[0055]
r(s,a,s')=-|t
actual-t
predicted
|
[0056]
该式表明从状态s采取动作a转移到状态s'得到的回报,其中t
actual
为真实滑出时间,t
predicted
为预测的滑出时间;接着根据各个特征和滑出时间的取值范围,相应地将状态空间s和动作空间a进行离散化处理,并对任意的状态s和动作a,用0初始化r(s,a)。
[0057]
步骤3,利用探索过程和学习过程进行动作选择,确定下一个系统状态并更新累计奖赏;
[0058]
根据迭代次数确定进入探索过程或者学习过程,选择对应动作得到预测的滑出时间;然后计算并且更新奖赏函数,进入下一个系统状态。具体为:设置总迭代次数,当前迭代次数小于总迭代次数时,进行探索过程,以概率p选择贪婪动作1-p选择随机动作,进而得到预测的滑出时间,计算r(s,a,s')并更新累计奖赏r(s,a),进入下一个系统状态s';当前迭代次数达到总迭代次数时,进入学习过程,直接选择贪婪动作得到预测的滑出时间,计算r(s,a,s')并更新累计奖赏r(s,a),进入下一个系统状态s';其中,使用近似动态规划更新累计奖赏,如下所示:
[0059][0060]
其中,α为学习参数,n为迭代次数。
[0061]
步骤4,设置预定义的停止条件,迭代训练强化学习算法得到最优累计奖赏;
[0062]
设置预测稳定的停止条件为|r
n 1
(s,a)-rn(s,a)|≤ε,其中ε为一个很小的正数。当达到该条件时表示训练完成,得到最优累计奖赏r
optimal
(s,a)。
[0063]
步骤5,利用最优累计奖赏对个体航空器滑出时间进行预测,对机场场面整体滑行态势进行评估;
[0064]
利用训练好的强化学习模型得到最优累计奖赏,计算各航空器的状态并将该状态下的最优动作视为预测的滑出时间;然后计算各个时间片下航空器预测滑出时间的均值,并将其视为该时间片机场整体的滑行态势。具体为:利用训练好的强化学习模型得到最优累计奖赏r
optimal
(s,a),对计划在t时刻推出的航空器而言,首先计算该航班的机场系统状态s,然后将该状态下的最优动作视为预测的滑出时间,计算公式如下:
[0065]
[0066]
当获得了所有航班预测的滑出时间,以15分钟为单位,统计一天内各时间片预测的航空器滑出时间的均值,并将其作为机场场面滑行态势的度量值以此评估一天的滑行态势变化情况。
[0067]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。