1.本发明涉及风火互补系统,特别是一种基于深度强化学习的风火互补系统智能紧平衡处置方法。
背景技术:
2.风能作为一种具有储量大、成本低、绿色环保的可再生能源,风能的开发利用既有利于保障全球能源供给,又可减少温室气体的排放,对促进全球能源结构转型具有重要的推动作用。近年来,风电新增装机规模迅速扩大,风电渗透率不断提高。
3.风电渗透率的不断提高虽然可以降低系统的运行成本,但也给维持系统功率平衡带来了挑战。同时,随着负荷需求的不断增长以及负荷侧电动汽车、储能、分布式发电装置的快速发展,也增加了负荷侧的不确定性。这种源荷不确定性的增加给电网的安全稳定运行带了极大的挑战。在负荷和风电出力具有较大的波动时,系统的功率平衡难以保持,亟需通过增加常规机组的备用容量、快速启动机组等方法来维持系统功率平衡,但这些方式会增加机组运营成本,降低系统运行经济性。柔性爬坡容量的供给可以为风火互补系统提供柔性紧平衡处置容量,通过预留一定的灵活调节空间来应对预测误差,增加系统的灵活性,稳定系统输出功率。
4.目前柔性爬坡容量主要依靠常规机组提供,随着柔性爬坡容量需求的增长,不断增加系统的运行成本。短期的风电功率可以精准预测,可提供一定的柔性爬坡容量。现有研究缺乏考虑风电提供柔性爬坡容量来帮助风火互补系统处置紧平衡,降低处置成本。其次,目前风火互补系统研究中,广泛使用的算法有线性规划、进化算法、群体算法、混合算法等。这些优化算法具有计算复杂、易陷入局部最优、无法根据输入数据实时更新最优方案等缺陷,难以快速获得风火互补系统紧平衡处置方案。
技术实现要素:
5.发明目的:本发明的目的是提供一种基于深度强化学习的风火互补系统智能紧平衡处置方法,从而考虑风电提供柔性爬坡容量以帮助风火互补系统处置紧平衡,降低紧平衡处置成本,并通过ddpg算法实现风火互补系统智能紧平衡处置,降低紧平衡处置时间。
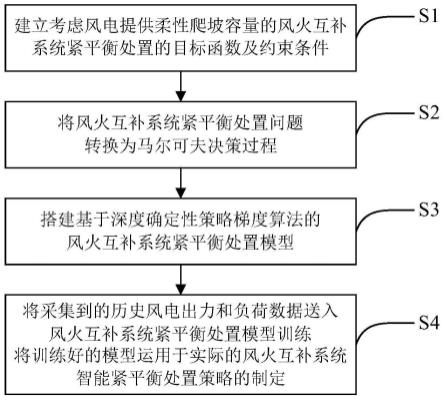
6.技术方案:本发明所述的一种基于深度强化学习的风火互补系统智能紧平衡处置方法,包括以下步骤:
7.(1)建立考虑风电提供柔性爬坡容量的风火互补系统紧平衡处置的目标函数及约束条件;
8.(2)根据步骤(1)建立的目标函数和约束条件,将风火互补系统紧平衡处置问题转换为马尔可夫决策过程;
9.(3)搭建基于深度确定性策略梯度(deep deterministic policy gradient, ddpg)算法的风火互补系统紧平衡处置模型;
10.(4)将采集到的历史风电出力和负荷数据送入风火互补系统紧平衡处置模型训
练,将训练好的模型运用于实际的风火互补系统智能紧平衡处置策略的制定。
11.步骤(1)中,所述的目标函数为:
[0012][0013][0014][0015][0016]
式中,c
op,t
为火电机组运行成本;c
re,t
为备用容量成本;c
fr,t
为柔性爬坡容量成本;n
t
为紧平衡处置总时段;p
g,i,t
为第i个机组在t时段的出力;ai、bi、 ci为机组i运行成本系数;ng为火电机组总个数;sp
i,t
为第i个机组在t时段的旋转备用容量;是第i个机组的旋转备用容量成本系数;fr
u,i,t
、fr
d,i,t
分别为第i机组在t时段的向上柔性爬坡容量和向下柔性爬坡容量;分别为第i个机组的向上柔性爬坡容量成本系数和向下柔性爬坡容量成本系数;
[0017]
所述的约束条件包括:
[0018]
系统功率平衡约束:
[0019][0020]
式中,p
w,j,t
为第j个风电场在t时段的输出功率;p
l,t
为t时段系统负荷;nw为风电场总个数;
[0021]
火电机组出力约束:
[0022][0023][0024]
式中,为第i个火电机组的最大输出功率;为第i个火电机组的最小输出功率;
[0025]
火电机组爬坡约束:
[0026][0027][0028]
式中,为火电机组在时间段内最大向上爬坡量;为火电机组在时间段内最大向下爬坡量;
[0029]
柔性爬坡容量需求量约束:
[0030][0031][0032]
wf
u,j,t
=max(p
w,j,t 1-p
w,j,t
,0)
[0033]
wf
d,j,t
=max(p
w,j,t-p
w,j,t 1
,0)
[0034]
式中,wf
u,j,t
为第j个风电场在t时段提供的向上柔性爬坡容量;wf
d,j,t
为第j个风电场在t时段提供的向下柔性爬坡容量;f
tu
为系统在t时段的向上柔性爬坡容量需求量;f
td
为系统在t时段的向下柔性爬坡容量需求量。
[0035]
步骤(2)中,所述的马尔可夫决策过程包括状态空间s、动作空间a和奖励函数r,具体为:
[0036]
状态空间s是n
t
个状态s
t
的集合,包括对紧平衡处置产生影响的相关因素, t时刻的状态s
t
包括风电出力、负荷、向上柔性爬坡容量需求量、向下柔性爬坡容量需求量、风电提供的向上柔性爬坡容量、风电提供的向下柔性爬坡容量和紧平衡处置时刻:
[0037]st
={p
w,t
,p
l,t
,f
tu
,f
td
,wf
u,t
,wf
d,t
,t}
[0038]
式中,p
w,t
为nw个风电场出力集合;wf
u,t
为nw个风电场提供的向上柔性爬坡容量集合;wf
d,t
为nw个风电场提供的向下柔性爬坡容量集合;
[0039]
动作空间a是n
t
个动作a
t
的集合,包括紧平衡处置的相关决策变量,t时刻的动作a
t
包括火电机组出力、火电机组向上柔性爬坡容量、火电机组向下柔性爬坡容量:
[0040]at
={p
g,t
,fr
u,t
,fr
d,t
}
[0041]
式中,p
g,t
为ng台火电机组出力集合;fr
u,t
为ng台火电机组向上柔性爬坡容量集合;fr
d,t
为ng台火电机组向下柔性爬坡容量集合;
[0042]
奖励函数r为各个时刻状态下执行动作获得的回报r
t
的加权和,t时刻的奖励r
t
包括火电机组运行成本、备用容量成本、柔性爬坡容量成本和违反约束条件的惩罚φ:
[0043]rt
=-[(c
op,t
c
re,t
c
fr,t
) φ]
[0044]
式中,c
op,t
为火电机组运行成本;c
re,t
为备用容量成本;c
fr,t
为柔性爬坡容量成本;φ为违反约束条件的惩罚。
[0045]
步骤(3)中,所述的风火互补系统紧平衡处置模型包括两组不同的神经网络,具体为:
[0046]
第一组网络:包括两个结构相同的网络,分别为:具有参数θ
μ
的actor网络μ(s
t
|θ
μ
)、具有参数θ
μ
′
的actor目标网络μ
′
(s
t
|θ
μ
′
);
[0047]
第二组网络:包括两个结构相同的网络,分别为:具有参数θq的critic网络 q(s
t
,a
t
|θq)、具有参数θq′
的critic目标网络q
′
(s
t
,a
t
′
|θq′
)。
[0048]
步骤(4)中,所述的风火互补系统紧平衡处置模型训练步骤如下:
[0049]
(4.1)设置基于ddpg算法的风火互补系统紧平衡处置模型的总迭代次数 n,确定紧平衡处置周期长度t;
[0050]
(4.2)初始化actor网络和critic网络参数θ
μ
和θq,令目标网络参数θ
μ
′
=θ
μ
,θq′
=θq;初始化经验回放池,设置经验回放池容量m,设置当前迭代次数n=1;
[0051]
(4.3)判断n是否到达所设定的总迭代次数,若已达到总迭代次数,则结束训练,否则设置当前时段t=1,初始化状态s
t
;
[0052]
(4.4)判断t是否小于t,若t大于t,则返回步骤(4.3),否则将s
t
输入到actor网络,并叠加ornstein-uhlenbeck噪声输出动作a
t
;
[0053]
(4.5)由输出的动作a
t
与紧平衡处置环境进行交互,计算即时奖励r
t
,并获取下一时段状态s
t 1
;
[0054]
(4.6)将t时段经验(s
t
,a
t
,r
t
,s
t 1
)存放到经验回放池中;
[0055]
(4.7)判断经验回放池是否存满,若未存满,则令t=t 1,返回步骤(4.4),否则从经验回放池中选择k组(s
t
,a
t
,r
t
,s
t 1
),更新actor网络和critic网络参数,采用软更新的方式更新actor和critic目标网络参数,令t=t 1,返回步骤(4.4)。
[0056]
步骤(4.7)中所述的更新critic网络参数,指通过最小化损失函数loss更新网络参数:
[0057][0058]
yk=rk γq
′
(s
k 1
,μ
′
(s
k 1
|θ
μ
′
)|θq′
)
[0059]
式中,yk为累积奖励,γ为折扣因子;
[0060]
步骤(4.7)中所述的更新actor和critic目标网络参数,指采用软更新的方式对critic和actor目标网络参数进行更新:
[0061][0062]
式中,τ为更新系数。
[0063]
一种基于深度强化学习的风火互补系统智能紧平衡处置系统,所述系统采用了上述的基于深度强化学习的风火互补系统智能紧平衡处置方法,包括以下模块:
[0064]
第一处理模块:用于建立考虑风电提供柔性爬坡容量的风火互补系统紧平衡处置的目标函数及约束条件;
[0065]
第二处理模块:用于将风火互补系统紧平衡处置问题转换为马尔可夫决策过程;
[0066]
第三处理模块:用于搭建基于深度确定性策略梯度算法的风火互补系统紧平衡处置模型;
[0067]
第四处理模块:用于将采集到的历史风电出力和负荷数据送入风火互补系统紧平衡处置模型训练,并将训练好的模型运用于实际的风火互补系统智能紧平衡处置策略的制定。
[0068]
一种计算机存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述的一种基于深度强化学习的风火互补系统智能紧平衡处置方法。
[0069]
一种计算机设备,包括储存器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述的一种基于深度强化学习的风火互补系统智能紧平衡处置方法。
[0070]
有益效果:与现有技术相比,本发明具有如下优点:
[0071]
1、本发明考虑风电提供柔性爬坡容量后,有效降低了火电机组提供柔性爬坡容量
的成本和风火互补系统紧平衡处置总成本,增加了系统的灵活性;
[0072]
2、本发明相比于传统的粒子群算法(pso)算法具有耗时短的优点,能够应用于风火互补系统实时紧平衡处置决策。
附图说明
[0073]
图1是风火互补系统的框图;
[0074]
图2是本发明的步骤示意图;
[0075]
图3是ddpg网络结构示意图;
[0076]
图4是风火互补系统紧平衡处置模型的训练流程图;
[0077]
图5是系统向上柔性爬坡容量结果图;
[0078]
图6是系统向下柔性爬坡容量结果图。
具体实施方式
[0079]
下面结合附图对本发明的技术方案作进一步说明。
[0080]
在本实施例中,如图1所示,风火互补系统由风电场和火电机组构成;
[0081]
其中,该系统含有5条传输线路,包括5台火电机组(g1-g5)和1个风电场。风电场接在节点1,g1和g2机组接在节点1,g3、g4、g5机组分别接在节点3、4、5,负荷主要分布在节点2、3、4。
[0082]
下面结合图1对本发明一种基于深度强化学习的风火互补系统智能紧平衡处置方法进行详细说明。
[0083]
在本实施例中,如图2所示,一种基于深度强化学习的风火互补系统智能紧平衡处置方法,包括以下步骤:
[0084]
(1)建立考虑风电提供柔性爬坡容量的风火互补系统紧平衡处置的目标函数及约束条件;
[0085]
考虑到火电机组运行成本、备用容量成本、柔性爬坡容量成本,构建风火互补系统紧平衡处置目标函数:
[0086][0087][0088][0089][0090]
式中,c
op,t
为火电机组运行成本;c
re,t
为备用容量成本;c
fr,t
为柔性爬坡容量成本;n
t
为紧平衡处置总时段;p
g,i,t
为第i个机组在t时段的出力;ai、bi、 ci为机组i运行成本系数;ng为火电机组总个数;sp
i,t
为第i个机组在t时段的旋转备用容量;是第i个机组的旋
转备用容量成本系数;fr
u,i,t
、fr
d,i,t
分别为第i机组在t时段的向上柔性爬坡容量和向下柔性爬坡容量;分别为第i个机组的向上柔性爬坡容量成本系数和向下柔性爬坡容量成本系数。
[0091]
为了保证系统正常运行,需要满足一些约束条件,包括:系统功率平衡约束、火电机组出力约束、火电机组爬坡约束、柔性爬坡容量需求量约束,具体如下:
[0092]
系统功率平衡约束:
[0093][0094]
式中,p
w,j,t
为第j个风电场在t时段的输出功率;p
l,t
为t时段系统负荷;nw为风电场总个数。
[0095]
火电机组出力约束:
[0096][0097][0098]
式中,为第i个火电机组的最大输出功率;为第i个火电机组的最小输出功率。
[0099]
火电机组爬坡约束:
[0100][0101][0102]
式中,r
iu
为火电机组在时间段内最大向上爬坡量;r
id
为火电机组在时间段内最大向下爬坡量。
[0103]
柔性爬坡容量需求量约束:
[0104][0105][0106]
wf
u,j,t
=max(p
w,j,t 1-p
w,j,t
,0)
[0107]
wf
d,j,t
=max(p
w,j,t-p
w,j,t 1
,0)
[0108]
式中,wf
u,j,t
为第j个风电场在t时段提供的向上柔性爬坡容量;wf
d,j,t
为第j个风电场在t时段提供的向下柔性爬坡容量;f
tu
为系统在t时段的向上柔性爬坡容量需求量;f
td
为系统在t时段的向下柔性爬坡容量需求量。
[0109]
(2)根据步骤(1)建立的目标函数和约束条件,将风火互补系统紧平衡处置问题转换为马尔可夫决策过程,马尔可夫决策过程包括状态空间s、动作空间 a和奖励函数r,具体如下:
[0110]
状态空间s包括对紧平衡处置产生影响的相关因素,t时刻的状态s
t
包括风电出
力、负荷、向上柔性爬坡容量需求量、向下柔性爬坡容量需求量、风电提供的向上柔性爬坡容量、风电提供的向下柔性爬坡容量和紧平衡处置时刻:
[0111]st
={p
w,t
,p
l,t
,f
tu
,f
td
,wf
u,t
,wf
d,t
,t}
[0112]
式中,p
w,t
为nw个风电场出力集合;wf
u,t
为nw个风电场提供的向上柔性爬坡容量集合;wf
d,t
为nw个风电场提供的向下柔性爬坡容量集合。
[0113]
动作空间a包括紧平衡处置的相关决策变量,t时刻的动作a
t
包括火电机组出力、火电机组向上柔性爬坡容量、火电机组向下柔性爬坡容量:
[0114]at
={p
g,t
,fr
u,t
,fr
d,t
}
[0115]
式中,p
g,t
为ng台火电机组出力集合;fr
u,t
为ng台火电机组向上柔性爬坡容量集合;fr
d,t
为ng台火电机组向下柔性爬坡容量集合。
[0116]
奖励函数r为状态下执行动作获得的回报,t时刻的奖励r
t
包括火电机组运行成本、备用容量成本、柔性爬坡容量成本和违反约束条件的惩罚φ:
[0117]rt
=-[(c
op,t
c
re,t
c
fr,t
) φ]
[0118]
(3)搭建基于深度确定性策略梯度(deep deterministic policy gradient, ddpg)算法的风火互补系统紧平衡处置模型,该模型由ddpg算法实现,如图 3所示,ddpg算法采用深度强化学习actor-critic框架,在确定性策略梯度方法基础上采用经验回放和双网络的方式改进actor-critic算法难收敛的缺点。构成 ddpg算法的两组不同神经网络具体为:
[0119]
第一组网络:包括两个结构相同的网络,分别为:具有参数θ
μ
的actor网络μ(s
t
|θ
μ
)、具有参数θ
μ
′
的actor目标网络μ
′
(s
t
|θ
μ
′
)。
[0120]
第二组网络:包括两个结构相同的网络,分别为:具有参数θq的critic网络 q(s
t
,a
t
|θq)、具有参数θq′
的critic目标网络q
′
(s
t
,a
t
′
|θq′
)。
[0121]
(4)将采集到的历史风电出力和负荷数据送入风火互补系统紧平衡处置模型训练,以1小时为一个紧平衡处置时段,一天24小时为一个紧平衡处置周期,获取365天风电出力和负荷数据训练风火互补系统紧平衡处置模型。将训练好的模型运用于实际的风火互补系统智能紧平衡处置策略的制定。如图4所示,风火互补系统紧平衡处置模型训练步骤如下:
[0122]
(4.1)设置基于ddpg算法的风火互补系统紧平衡处置模型的总迭代次数 n,确定紧平衡处置周期长度t;
[0123]
(4.2)初始化actor网络和critic网络参数θ
μ
和θq,令目标网络参数θ
μ
′
=θ
μ
,θq′
=θq;初始化经验回放池,设置经验回放池容量m,设置当前迭代次数n=1;
[0124]
(4.3)判断n是否到达所设定的总迭代次数,若已达到总迭代次数,则结束训练,否则设置当前时段t=1,初始化状态s
t
;
[0125]
(4.4)判断t是否小于t,若t大于t,则返回步骤(4.3),否则将s
t
输入到actor网络,并叠加ornstein-uhlenbeck噪声输出动作a
t
;
[0126]
(4.5)由输出的动作a
t
与紧平衡处置环境进行交互,计算即时奖励r
t
,并获取下一时段状态s
t 1
;
[0127]
(4.6)将t时段经验(s
t
,a
t
,r
t
,s
t 1
)存放到经验回放池中;
[0128]
(4.7)判断经验回放池是否存满,若未存满,则令t=t 1,返回步骤(4.4),否则从
经验回放池中选择k组(s
t
,a
t
,r
t
,s
t 1
),更新actor网络和critic网络参数,采用软更新的方式更新actor和critic目标网络参数,令t=t 1,返回步骤(4.4)。
[0129]
步骤(4.7)中的actor网络参数更新,通过梯度下降法更新网络参数,梯度计算如下:
[0130][0131]
式中,为梯度算子,表示对策略j求参数θ
μ
的梯度。
[0132]
步骤(4.7)中的critic网络参数更新,通过最小化损失函数loss更新网络参数:
[0133][0134]
yk=rk γq
′
(s
k 1
,μ
′
(s
k 1
|θ
μ
′
)|θq′
)
[0135]
式中,yk为累积奖励,γ为折扣因子。
[0136]
步骤(4.7)中的actor和critic目标网络参数更新,采用软更新的方式对critic 和actor目标网络参数进行更新:
[0137][0138]
式中,τ为更新系数。
[0139]
为验证本发明所提出的方法,从测试集中选取某一天进行测试,紧平衡处置模型根据输入数据进行紧平衡处置决策,输出一天的机组出力结果和机组提供的柔性爬坡容量,系统总的向上、向下柔性爬坡容量结果如图5和图6所示。
[0140]
系统的柔性爬坡容量需求主要由风电和具有较大出力范围的g3、g5机组提供。在图5、图6中,黑色表示风电提供的柔性爬坡容量,灰色和白色分别表示机组g3、g5提供的柔性爬坡容量。由于g5提供柔性爬坡容量的成本低于g3 机组,除了风电提供的柔性爬坡容量以外,系统的柔性爬坡需求主要由g5机组提供。
[0141]
传统的柔性爬坡容量主要由火电机组提供,本发明考虑风电提供柔性爬坡容量后,可有效节省火电机组提供的柔性爬坡容量。针对系统向上柔性爬坡容量的需求,风电在一天内共提供29.83mw,节省的柔性爬坡容量占比约为3.85%。针对系统向下柔性爬坡容量的需求,风电在一天内共提供91.71mw,节省的柔性爬坡容量占比约为9.62%。在风电的参与下,火电机组提供柔性爬坡容量的成本有效减少,同时降低了机组出力的限制,部分低发电成本的机组可以增加出力,降低了发电成本,增加了系统的灵活性。
[0142]
为验证本发明所提方法的有效性,另采用粒子群算法对考虑风电提供柔性爬坡容量的风火互补系统紧平衡处置问题进行求解,对比结果如表1所示。
[0143]
表1两种方法对比结果
[0144]
方法ddpgpso紧平衡处置成本($)318332318024求解时间(s)0.0645704.4447
[0145]
在紧平衡处置成本方面,基于ddpg算法的紧平衡处置成本为318332$,基于pso算法的紧平衡处置成本为318024$,两种算法紧平衡处置成本相差不大。因此,本发明能有效实现风火互补系统紧平衡处置,降低紧平衡处置成本。在决策时间方面,ddpg算法针对历史数据通过13小时的离线训练,学到历史经验分布,在线决策仅花费0.0645s,相比于pso算法决策时间有了大幅提升。ddpg 算法主要是基于历史数据在离线阶段花费大量时间训练模型,训练好的模型可用于在线决策,可以根据输入数据,快速输出紧平衡处置结果,当日的数据也可以加入历史数据,离线训练智能体,不断优化决策模型,实现智能紧平衡处置。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。