技术特征:
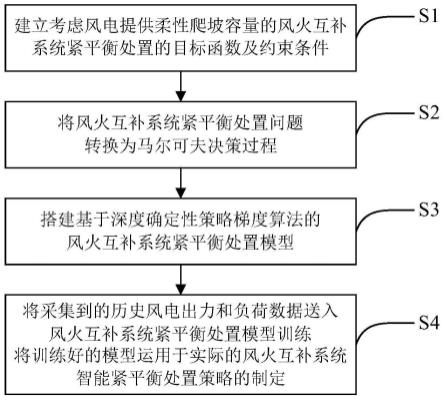
1.一种基于深度强化学习的风火互补系统智能紧平衡处置方法,其特征在于,包括以下步骤:(1)建立考虑风电提供柔性爬坡容量的风火互补系统紧平衡处置的目标函数及约束条件;(2)根据步骤(1)建立的目标函数和约束条件,将风火互补系统紧平衡处置问题转换为马尔可夫决策过程;(3)搭建基于深度确定性策略梯度算法的风火互补系统紧平衡处置模型;(4)将采集到的历史风电出力和负荷数据送入风火互补系统紧平衡处置模型训练,将训练好的模型运用于实际的风火互补系统智能紧平衡处置策略的制定。2.根据权利要求1所述的一种基于深度强化学习的风火互补系统智能紧平衡处置方法,其特征在于,步骤(1)中,所述的目标函数为:所述的目标函数为:所述的目标函数为:所述的目标函数为:式中,c
op,t
为火电机组运行成本;c
re,t
为备用容量成本;c
fr,t
为柔性爬坡容量成本;n
t
为紧平衡处置总时段;p
g,i,t
为第i个机组在t时段的出力;a
i
、b
i
、c
i
为机组i运行成本系数;n
g
为火电机组总个数;sp
i,t
为第i个机组在t时段的旋转备用容量;是第i个机组的旋转备用容量成本系数;fr
u,i,t
、fr
d,i,t
分别为第i机组在t时段的向上柔性爬坡容量和向下柔性爬坡容量;分别为第i个机组的向上柔性爬坡容量成本系数和向下柔性爬坡容量成本系数;所述的约束条件包括:系统功率平衡约束:式中,p
w,j,t
为第j个风电场在t时段的输出功率;p
l,t
为t时段系统负荷;n
w
为风电场总个数;火电机组出力约束:p
g,i,t
sp
i,t
fr
u,i,t
≤p
imax
p
g,i,t-fr
d,i,t
≥p
imin
式中,p
imax
为第i个火电机组的最大输出功率;p
imin
为第i个火电机组的最小输出功率;火电机组爬坡约束:
式中,为火电机组在时间段内最大向上爬坡量;为火电机组在时间段内最大向下爬坡量;柔性爬坡容量需求量约束:性爬坡容量需求量约束:wf
u,j,t
=max(p
w,j,t 1-p
w,j,t
,0)wf
d,j,t
=max(p
w,j,t-p
w,j,t 1
,0)式中,wf
u,j,t
为第j个风电场在t时段提供的向上柔性爬坡容量;wf
d,j,t
为第j个风电场在t时段提供的向下柔性爬坡容量;f
tu
为系统在t时段的向上柔性爬坡容量需求量;f
td
为系统在t时段的向下柔性爬坡容量需求量。3.根据权利要求1所述的一种基于深度强化学习的风火互补系统智能紧平衡处置方法,其特征在于,步骤(2)中,所述的马尔可夫决策过程包括状态空间s、动作空间a和奖励函数r,具体为:状态空间s是n
t
个状态s
t
的集合,包括对紧平衡处置产生影响的相关因素,t时刻的状态s
t
包括风电出力、负荷、向上柔性爬坡容量需求量、向下柔性爬坡容量需求量、风电提供的向上柔性爬坡容量、风电提供的向下柔性爬坡容量和紧平衡处置时刻:s
t
={p
w,t
,p
l,t
,f
tu
,f
td
,wf
u,t
,wf
d,t
,t}式中,p
w,t
为n
w
个风电场出力集合;wf
u,t
为n
w
个风电场提供的向上柔性爬坡容量集合;wf
d,t
为n
w
个风电场提供的向下柔性爬坡容量集合;动作空间a是n
t
个动作a
t
的集合,包括紧平衡处置的相关决策变量,t时刻的动作a
t
包括火电机组出力、火电机组向上柔性爬坡容量、火电机组向下柔性爬坡容量:a
t
={p
g,t
,fr
u,t
,fr
d,t
}式中,p
g,t
为n
g
台火电机组出力集合;fr
u,t
为n
g
台火电机组向上柔性爬坡容量集合;fr
d,t
为n
g
台火电机组向下柔性爬坡容量集合;奖励函数r为各个时刻状态下执行动作获得的回报r
t
的加权和,t时刻的奖励r
t
包括火电机组运行成本、备用容量成本、柔性爬坡容量成本和违反约束条件的惩罚φ:r
t
=-[(c
op,t
c
re,t
c
fr,t
) φ]式中,c
op,t
为火电机组运行成本;c
re,t
为备用容量成本;c
fr,t
为柔性爬坡容量成本;φ为违反约束条件的惩罚。4.根据权利要求1所述的一种基于深度强化学习的风火互补系统智能紧平衡处置方法,其特征在于,步骤(3)中,所述的风火互补系统紧平衡处置模型包括两组不同的神经网络,具体为:第一组网络:包括两个结构相同的网络,分别为:具有参数θ
μ
的actor网络μ(s
t
|θ
μ
)、具
有参数θ
μ
′
的actor目标网络μ
′
(s
t
|θ
μ
′
);第二组网络:包括两个结构相同的网络,分别为:具有参数θ
q
的critic网络q(s
t
,a
t
|θ
q
)、具有参数θ
q
′
的critic目标网络q
′
(s
t
,a
t
′
|θ
q
′
)。5.根据权利要求1所述的一种基于深度强化学习的风火互补系统智能紧平衡处置方法,其特征在于,步骤(4)中,所述的风火互补系统紧平衡处置模型训练步骤如下:(4.1)设置基于ddpg算法的风火互补系统紧平衡处置模型的总迭代次数n,确定紧平衡处置周期长度t;(4.2)初始化actor网络和critic网络参数θ
μ
和θ
q
,令目标网络参数θ
μ
′
=θ
μ
,θ
q
′
=θ
q
;初始化经验回放池,设置经验回放池容量m,设置当前迭代次数n=1;(4.3)判断n是否到达所设定的总迭代次数,若已达到总迭代次数,则结束训练,否则设置当前时段t=1,初始化状态s
t
;(4.4)判断t是否小于t,若t大于t,则返回步骤(4.3),否则将s
t
输入到actor网络,并叠加ornstein-uhlenbeck噪声输出动作a
t
;(4.5)由输出的动作a
t
与紧平衡处置环境进行交互,计算即时奖励r
t
,并获取下一时段状态s
t 1
;(4.6)将t时段经验(s
t
,a
t
,r
t
,s
t 1
)存放到经验回放池中;(4.7)判断经验回放池是否存满,若未存满,则令t=t 1,返回步骤(4.4),否则从经验回放池中选择k组(s
t
,a
t
,r
t
,s
t 1
),更新actor网络和critic网络参数,采用软更新的方式更新actor和critic目标网络参数,令t=t 1,返回步骤(4.4)。6.根据权利要求5所述的一种基于深度强化学习的风火互补系统智能紧平衡处置方法,其特征在于,步骤(4.7)中所述的更新critic网络参数,指通过最小化损失函数loss更新网络参数:y
k
=r
k
γq
′
(s
k 1
,μ
′
(s
k 1
|θ
μ
′
)|θ
q
′
)式中,y
k
为累积奖励,γ为折扣因子;步骤(4.7)中所述的更新actor和critic目标网络参数,指采用软更新的方式对critic和actor目标网络参数进行更新:式中,τ为更新系数。7.一种基于深度强化学习的风火互补系统智能紧平衡处置系统,所述系统采用如权利要求1-6中任一项所述的一种基于深度强化学习的风火互补系统智能紧平衡处置方法,其特征在于,包括以下模块:第一处理模块:用于建立考虑风电提供柔性爬坡容量的风火互补系统紧平衡处置的目标函数及约束条件;第二处理模块:用于将风火互补系统紧平衡处置问题转换为马尔可夫决策过程;第三处理模块:用于搭建基于深度确定性策略梯度算法的风火互补系统紧平衡处置模
型;第四处理模块:用于将采集到的历史风电出力和负荷数据送入风火互补系统紧平衡处置模型训练,并将训练好的模型运用于实际的风火互补系统智能紧平衡处置策略的制定。8.一种计算机存储介质,其上存储有计算机程序,其特征在于,该计算机程序被处理器执行时实现如权利要求1-6中任一项所述的一种基于深度强化学习的风火互补系统智能紧平衡处置方法。9.一种计算机设备,包括储存器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1-6中任一项所述的一种基于深度强化学习的风火互补系统智能紧平衡处置方法。
技术总结
本发明公开了一种基于深度强化学习的风火互补系统智能紧平衡处置方法,步骤如下:建立考虑风电提供柔性爬坡容量的风火互补系统紧平衡处置的目标函数及约束条件;根据所建立的目标函数和约束条件,将风火互补系统紧平衡处置问题转换为马尔可夫决策过程;搭建基于深度确定性策略梯度算法的风火互补系统紧平衡处置模型;采用历史风电出力和负荷数据训练风火互补系统紧平衡处置模型,将训练好的模型运用于实际的风火互补系统智能紧平衡处置策略的制定。本发明提出的方法有效降低了风火互补系统紧平衡处置成本,增加了系统的灵活性,且本发明提出的方法决策时间短,可应用于风火互补系统实时紧平衡处置决策。补系统实时紧平衡处置决策。补系统实时紧平衡处置决策。
技术研发人员:葛远裕 谢俊 仇晨光 熊浩 闫朝阳 丁超杰 杨胜春 吕建虎 刘建涛 王礼文
受保护的技术使用者:国网江苏省电力有限公司 中国电力科学研究院有限公司 国家电网有限公司
技术研发日:2022.10.26
技术公布日:2023/2/3
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。