面向用户的电子表格编程语言
1.优先权要求
2.本技术要求于2020年5月29日提交的新加坡专利申请第10202005091r号的优先权。
技术领域
3.本发明总体上涉及计算机电子表格系统,并且更具体地涉及用于面向用户的电子表格编程语言的方法和系统。
背景技术:
4.目前许多专业程序员使用的主流语言,例如c、c 、java和python,都是基于纯文本的线性流。这些语言的核心目标是支持以类似的方式构建应用程序,其中功能不是从头开始构建,而是从现有库中组装而成,通常是以函数和类的形式。不同的库可以共存和协作,程序员的主要工作仅是定制和编排这些逻辑块。当今的语言已被证明是极其通用的,并且在很大程度上实现了这一目标。不幸的是,它们也被证明对大多数非程序员来说过于抽象,导致程序员和非程序员之间的巨大鸿沟,并导致非程序员沦为技术的被动消费者。
5.在鸿沟的另一侧是电子表格,其基于二维(2d)网格结构而不是纯文本。诸如microsoft excel和google sheet等电子表格系统是仅有的一些实际可访问的系统,非程序员用户可以在该系统中表达重要的逻辑以供计算机执行。然而,当被视为开发环境时,电子表格缺乏被认为是主流编程语言必不可少的基本功能,例如以函数和类的形式重用代码的能力、单元测试的能力以及导入预构建的第三方电子表格的能力。因此,实践中的电子表格经常会发现有大量重复代码和错误,从而导致电子表格随着需求变得越来越复杂而迅速变得难以管理的环境。此外,没有从电子表格到技术更完善的解决方案的升级路径。用户要么求助于visual basics for applications(vba)程序员来构建更复杂的功能(其中vba是一种传统的基于纯文本的语言),要么更常见的是完全丢弃电子表格并用主流语言完全重新实现逻辑。
6.因此,需要一种健壮的面向用户的电子表格编程语言,其克服了现有电子表格启用的编程的缺点并提供了一种简单、灵活和通用的向后兼容的电子表格友好型解决方案。此外,结合随附附图和本公开的此背景,从随后的详细描述和所附权利要求中,其他期望的特征和特性将变得显而易见。
技术实现要素:
7.根据本实施例的至少一个方面,提供了一种用于电子表格编程的方法。该方法包括将标签分配给电子表格的单元格,每个标签分配给用于与变量的多个值相对应的数据的多个相邻变量值单元格之一。多个相邻变量值单元格是用户通过指示多个相邻变量值单元格的单元格范围的开始和结束的一对标签定义的。该方法进一步包括定义溢出区域,数据可以响应于表达式从其中定义有所述表达式的单元格流入该溢出区域,所述表达式包括由
变量的多个值定义的变量范围。溢出区域的大小自动调整为与变量的多个值相对应的多个表达式的解。
8.根据本实施例的另一方面,提供了一种用于电子表格编程的附加方法。该方法包括:响应于包括函数调用和/或远程回调的电子表格中的单元格的单元格值,而将另一项目替换到电子表格中。
9.根据本实施例的另一方面,提供了电子表格。电子表格包括以二维阵列排列的多个单元格。多个单元格中的一个或多个单元格包括用于将另一项目替换到电子表格中的单元格值,单元格值包括函数调用和/或远程回调。
10.根据本实施例的另一个方面,提供了电子表格。电子表格包括以二维阵列排列的多个单元格。多个单元格中的一个或多个单元格包括用于与变量的多个值相对应的数据的多个相邻变量值单元格。多个相邻变量值单元格是用户通过指示多个相邻变量值单元格的单元格范围的开始和结束的一对单元格值定义的。多个单元格还包括溢出区域,数据可以响应于表达式从其中定义有该表达式的单元格流入溢出区域,该表达式包括由变量的多个值定义的变量范围。溢出区域的大小自动调整为与变量的多个值相对应的多个表达式的解。
11.根据本实施例的又一方面,提供了一种用于呈现动态网站的方法。该方法包括:响应于单个电子表格文档而生成动态网站的呈现,该单个电子表格文档包括数据和业务逻辑,以及动态网站的呈现响应于单个电子表格文档的数据和业务逻辑而生成。
12.根据本实施例的又一方面,提供了电子表格。电子表格包括以二维阵列排列的多个单元格。多个单元格中的一个或多个单元格包括设计成评估为非错误和非假值的用户指定约束。
13.根据本实施例的又一方面,提供了一种用于电子表格编程的方法。该方法包括用户指定电子表格的一个或多个单元格以包括设计成评估为非错误和非假值的约束。该方法还包括对电子表格的一个或多个单元格中的至少一个单元格执行动作,响应于动作导致约束中的至少一个失败而拒绝该动作,以及响应于动作导致约束中的该至少一个失败,将电子表格恢复到动作被执行之前的状态。
14.根据本实施例的另一方面,提供了一种加速在电子表格的任意单元格块中搜索值的方法。该方法包括利用空间索引和定义可能的单元格值的总顺序。
15.根据本实施例的最后一个方面,提供了电子表格。电子表格包括排列成由多行和多列定义的二维阵列的多个单元格。多行中的每一行由大数(bignum)行号标识,并且多列中的每一列由大数(bignum)列号标识。每个bignum行号和每个bignum列号都包含一个能够在其二进制表示中具有任意高的有限精度的数字。
附图说明
16.随附附图用于说明各种实施例并解释根据本实施例的各种原理和优点,其中相同的附图标记在各个单独的视图中指代相同或功能相似的元件,并且与下面的详细描述一起被并入并形成说明书的一部分。
17.图1是根据本实施例的示例性电子表格溢出(spill)的图示。
18.图2包括图2a到图2d,描绘了根据本实施例的电子表格振荡溢出区域的图示,其中
图2a描绘了潜在的振荡溢出区域,图2b描绘了振荡溢出区域的第一状态,图2c描绘了振荡溢出区域的第二状态,而图2d描绘了振荡溢出区域的稳定的最终状态。
19.图3包括图3a、图3b和图3c,描绘了根据本实施例的通过替换的重用逻辑,其中图3a描绘了示例性税收计算工作表,图3b描绘了图3a的就有定义的可替换的单元格的示例性税收计算工作表,图3c描绘了在替换图3b的示例性税收计算工作表中的值之后的示例性工作表税。
20.图4包括图4a、图4b和图4c,描绘了根据本实施例的示例说明用于简单替换和嵌套替换的规则的工作表,其中,图4a描绘了在图4b和图4c中的替换示例中使用的第一工作表,图4b是简单的替换,并且图4c是嵌套替换。
21.图5包括图5a到图5d,描绘了根据本实施例的示例说明回调规则的工作表,其中图5a描绘了带标签的工作表,图5b描绘了对图5a的工作表的回调,图5c描绘了带标签的工作表,并且图5d描绘了对图5c的工作表的thunk回调。
22.图6包括图6a和图6b,描绘了根据本实施例的用于溢出屏障的规则的操作,其中,图6a是定义了溢出屏障的工作表,图6b是替代工作表,其中溢出屏障自动在弹性行中创建单元格以适应附加值。
23.图7描绘了根据本实施例的标签位置表达的使用。
24.图8包括图8a、图8b和图8c,描述了根据本实施例的样式区域的规则的操作,其中,图8a描绘了样式表,图8b描绘了具有由图8a的样式表格定义的样式区域的工作表,图8c描绘了为电子表格的三行/两列部分编程的样式区域的表格。
25.图9包括图9a和图9b,描绘了根据本实施例的表中表(twit)规则的操作,其中图9a描绘了在标题单元格下方具有令人不快的宽单元格的工作表,图9b描绘了图9a的具有定义的twit以提供更好的视觉外观的工作表的内容。
26.图10包括图10a和图10b,描述了根据本实施例的类作为目录的操作,其中图10a描述了矩形类的表格的创建,并且图10b描绘了矩形面积的计算。
27.图11描绘了根据本实施例的在某个节点处导入图10a和10b所描述的文档的电子表格。
28.图12包括图12a和图12b,描绘了根据本实施例的定义动态调查网站的电子表格的示意图,其中图12a描绘了在输入调查答案之前的电子表格,并且图12b描绘了在输入一个调查答案之后的电子表格。
29.图13包括图13a和图13b,描绘了根据本实施例在用户界面层的入口点处执行“索引”宏之后渲染的电子表格,其中图13a描绘了当由表达式“joe_id-|(answer:last_answer):”指示的矩形区域不包含空格时渲染的电子表格,并且图13b描绘了当由表达式“joe_id-|(answer:last_answer):”指示的矩形区域包含空格时渲染的电子表格。
30.图14描绘了根据本实施例的包括购买数据的电子表格,可以通过使用空间索引来加速对该购买数据的查询。
31.并且图15,包括图15a、图15b和图15c,描绘了根据本实施例的具有表中表(twit)的电子表格。
32.本领域技术人员将理解,图中的元件是为了简单和清楚而示出的,并且不必按比例描绘。
具体实施方式
33.下面的详细描述本质上仅仅是示例性的并且不旨在限制本发明或本发明的应用和用途。此外,无意受本发明的前述背景或以下详细描述中提出的任何理论的约束。本实施例的目的是呈现一种面向用户的基于电子表格的编程语言,该语言允许用户构建、测试和重用逻辑块,构建动态网站,以及构建大规模共享电子表格,同时保持完全在二维(2d)电子表格的约束范围内。其目的是进一步将2d电子表格与当今的通用编程语言置于同等地位。
34.许多视觉语言是为了追求将通用编程带给大众而发明的,但是在屏幕上拖动小形状被证明过于繁琐,表达能力非常有限。一些视觉语言可以很好地映射到图形表示的领域,例如用于信号处理的matlab simulink和用于编写游戏玩法元素脚本的unreal游戏引擎蓝图,但没有一种被认为是可行的通用编程环境。
35.回顾具有二维单元格阵列的二维电子表格的视觉环境,在当今的传统电子表格中为单个单元格定义表达式是相当简单的。可以通过它们的坐标(如a1)或通过分配标签来引用单元格。根据本实施例,分配标签的方法专门用于引用单元格。
36.在传统的电子表格中,填充区域基本上依赖于复制和粘贴表达式。当在中间插入一行或用户更改其中一个表达式时,单元格的行为方式很难确定。新行是否应该自动填充当前模式?是否应该将相同的表达式更改应用于从中粘贴的单元格?歧义本身是危险的,但更重要的是,歧义阻碍了以任何确定性重新使用电子表格逻辑的努力。
37.一些当前的电子表格系统具有数组表达式来缓解该问题。但是,用户必须明确指定一个单元格范围以应用表达式,并且当输入范围改变大小时会发生什么仍不清楚。认识到复制逻辑的这种脆弱性和其他常规电子表格问题,定义了根据本实施例的多个电子表格编程规则以克服当前常规电子表格程序的缺点。
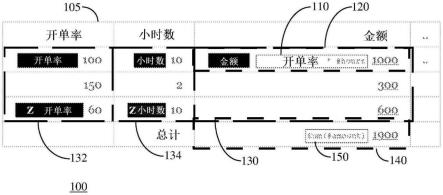
38.根据本实施例的第一方面,单元格溢出区域被定义用于电子表格中单元格范围的稳健和有利的自动填充。参考图1,图示100描绘了根据本实施例的示例性电子表格105中的电子表格溢出。用户仅在区域130的左上角单元格120中定义单个表达式110,而不必指定大小。头部120将表达式110评估不一定是单个值,但根据本实施例,可以将表达式110评估为值的矩形表格。然后这些值会溢出到右侧的单元格,并根据需要使用表达式溢出到单元格的底部。如果溢出区域中的任何单元格已经具有值集,或者也从另一个单元格溢出,则报告溢出冲突,如下文所述。
39.在表达式110中,#billing_rate是billing_rate:zbilling_rate的简写变量,它是用户定义的标签对,其表示从具有标签billing_rate的单元格到具有标签zbilling_rate的单元格的相邻变量值单元格的矩形区域,两者都是包含性的,其中包含数据100\\150\\60,对应于变量#billing_rate的多个值。同样,#hours表示从小时(hour)到周(zhour)的相邻变量值单元格的矩形区域。在示例性电子表格105中,单元格120的表达式110#billing_rate*#hours将两个表格,即区域132的100\\150\\60和区域134的10\\2\\10,相乘,以产生3行和1列的表格1000\\300\\600。由于该表格不能包含在单元格120本身中,因此它溢出到下面的两个单元格中,形成单元格120的溢出区域130。随后,在表达式150中,没有在工作表105中定义显式标签zamount,#amount表示单元格120的溢出区域130数量,包括单元格数量本身。因此,单元格140中的整个表达式sum(#amount)150计算单元格120的溢出区域130数量的总和,1000 300 600=1900。
40.特别值得注意的是振荡溢出区域的问题。接下来参考图2a、2b、2c和2d,图示200、220、240、260描绘了根据本实施例的示例说明问题的电子表格。在图示200中,函数zeros(a,a)205响应于单元格215a中的a设置为等于“2”,生成大小为a乘a的表格210,该表格210用零填充。
41.如果用户将值a更改为“3”,如电子表格220的单元格215b中所示,则电子表格将在两种状态之间振荡:图示220(图2b)中所示的状态一,其中我们已将左上单元格225a的溢出区域扩大到3x3,导致单元格215b报告溢出冲突,从而导致单元格225a的未决重新评估;以及图示240(图2c)中所示的状态二,其中左上单元格225b具有错误值并且因此没有超出其自身的溢出区域,并且单元格215c具有值“3”而没有溢出冲突。
42.为了解决振荡溢出区域的问题并且根据本实施例的一个方面,溢出区域规则被定义为溢出区域是非收缩的,即它们只能在随后的用户输入之前放大。遵循该溢出区域规则,即使在状态二中,左上单元格的溢出区域仍保持为3
×
3溢出区域265,从而导致图示260(图2d)中所示的稳定最终状态。
43.根据本实施例,该溢出区域规则将有利地在没有新用户输入的情况下总是导致稳定的最终状态。直观地说,相互冲突的溢出区域对的数量受定义的表达式对的限制。如果溢出区域不能缩小,那么这种关系的数量必须收敛到稳定的值。一旦溢出区域冲突关系稳定下来,可以明确计算单元格值;否则,它是可以很容易地检测和报告的依赖循环的一部分。
44.传统电子表格的另一个问题是重用在另一个电子表格中定义的逻辑具有挑战性。参考图3a,图示300描绘了被定义为计算个体应缴的假设税款的工作表310。即使逻辑被清楚地写出,传统的电子表格也没有提供将工作表310中定义的逻辑应用于另一个体的税的适当方式。重新定义收入(income)的输入值、或孩子的数量(即,nb_children)等,从而破坏当前计算的值,或者必须将逻辑复制到另一张工作表中并在那里修改,即使通常在编程中非常不鼓励复制代码。
45.为了克服传统电子表格中的这一缺陷,根据本实施例定义替换规则以支持通过替换的逻辑重用。参考图3b,图示330描绘了具有定义的可替换单元格342、344、346、348(以x开始的那些标签)的工作表335。使用工作表335,可以将单元格340定义为税的返回值,即计算税的逻辑。例如,代码可以写成tax(income=106000,nb_children=2,donations=1000\\2000\\3000)来计算另一个假设人的税收。这个代码代表了有一些修改的替换的税工作表,如图3c所示,并将替换的工作表中#return的值作为其值。如果定义了如x0、x1等标签,则支持工作表335中的位置输入。
46.参考图3c,图示360描绘了由代码tax(income=106000,nb_children=2,donations=1000\\2000\\3000)表示的工作表365。工作表365是从工作表335tax复制而来的,其中单元格xincome 370替换为代码106000 372,单元格xnb_children 374替换为代码2 376,单元格xdonations 378替换为代码1000\\20000\\3000 380。xdonations:zxdonations范围内其他单元格的代码集也被删除,即工作表335中的zxdonations=200被删除。通过删除标签zxdonations,由代码1000\\20000\\3000 380定义的xdonations 378的值有利地被允许成功地溢出到它下面的单元格中,而#xdonations的含义仍然很好地定义并符合用户的期望。
47.使用模式x0、x1的标签支持位置输入。例如,代码tax(106000,2,donations=
1000\\2000)将构成用代码106000替换x0,用代码2替换x1,并且如前所述替换命名输入xdonations。
48.如上定义的替换问题是嵌套替换。参考图4a和4b,图示400、430描绘了工作表410add和440square_add。当我们希望计算square_add(20)时,就会产生歧义。明确的是square_add.x0应该替换为20,这反过来会导致square_add.return请求add(400)。此外,在工作表410add中,明确的是x0应该替换为400,但在add.return中,不清楚square_add.x0应该是什么。有两种可能的解释。第一种解释是square_add.x0应该是10,因为在替换add(400)中,square_add.x0没有被替换。第一种解释被称为简单替换,并且由于替换较少,因此性能更高,但它可能有点令人惊讶。第二种解释是square_add.x0应该是20,因为add(400)嵌套在替换square_add(20)中,其中square_add.x0被替换为20。第二种解释称为嵌套替换,计算成本更高。
49.由于两种解释都有它们的用途,因此使用双括号来表示第二种解释以区别于第一种解释来区分地指定它。因此,参考图4c的图示460中的工作表470,如果需要第二种解释,则用双括号写入工作表square_add的返回单元格475。
50.如上定义的替换的另一个问题是,通常许多单元格不打算用表格替换。例如,税工作表在设计时并未考虑替换nb_children=1\\3,因此最好生成错误。因此,根据本实施例,替换值的形状必须与原始形状一致。也就是说,由于原始税表中的#xnb_children是单个单元格,因此其替换值也必须是单个单元格。同样,由于#xdonations最初是一列,因此它的替换也必须是一列。单个单元格被认为是列的特殊情况,因此在这里它也是可接受的替换。区分了四种形状:单个单元格、行(也允许单个单元格)、列(也允许单个单元格)和完整的表格(允许所有前面的三个形状)。使用此功能,tax(nb_children=1\\3)会生成“形状不匹配”错误。
51.现在已经示出了根据本实施例的电子表格如何可以类似于传统编程语言中的功能起作用。类似地,电子表格可以部分地与参数绑定,就像传统的函数一样。根据本实施例,工作表名称连同可能为空的一组标签对值的替换被称为thunk。可以为单元格分配一个thunk作为其值。根据本实施例的另一方面,可以将thunk作为函数参数传入,从而能够使用回调和/或高阶函数。参考图5a和5b,图示500、520描绘了根据本实施例的名为add1的工作表505,以及示例说明用于回调的规则的工作表525。工作表525将回调add1传递给对map的调用,map是内置函数。
52.对于上述示例,我们注意到必须为每个n定义一个addn是不切实际的。参考图5c和5d,图示540、560描绘了示例说明根据本实施例的用于部分绑定的thunk回调的规则的工作表545、565。在工作表545被命名为add的情况下,表达式add{1}570表示工作表545add的部分绑定,产生在功能上等同于add1 505的thunk。thunk还可以进行更多替换,从而创建更多的thunk。例如,以下都是等价的:(a)add(1,2),(b)#add{1,2}.return,(c)add{1,2}(),(d)add{1}(2)和(e)add{1}{2}()。
53.类似于上文讨论的简单替换()与嵌套替换和(())的区别,thunk替换可以是简单的或嵌套的,分别由{}和{{}}表示。
54.由于允许范围替换,所以无论单元格块放置多远,都不能避免所有可能的溢出冲突。参考电子表格360(图3c),如果有人捐赠超过四次,则返回单元格将发生溢出冲突。因
此,根据本实施例定义了用于溢出屏障的规则。参考图6a和6b,图示600、650描绘了根据本实施例的溢出屏障规则的操作。图示600描绘了根据本实施例的具有限定为对溢出区域建立弹性限制的溢出屏障620的税(tax)工作表640。溢出不能跨越屏障;相反,屏障会根据需要创建弹性溢出区域以包含溢出值。弹性溢出区域中的单元格不能有用户定义的标签或表达式。在图示650中的替代tax工作表660中,溢出屏障620能够在弹性溢出区域中自动创建行670中的单元格,以便容纳否则会导致溢出冲突的额外捐赠值。
55.参考图7,图示700描绘了电子表格710。假设用户希望表达表示工作表的所有内容的范围。注意,xbilling_rate和xhours都是可替代的,因此可以有任何高度,用户可以使用标签位置表达式(label position expression)来精确描述所需的逻辑。标签位置表达式是对标签坐标进行操作的表达式,而不是被标签引用的值。示例有:(a)xbilling_rate^^1指标签xbilling_rate上方一排单元格的坐标;(b)z(xbilling_rate)指单元格xbilling_rate的溢出区域的右下角,即值为60的单元格;(c)bottomright(z(xbilling_rate),last_remark)是指最左上角的单元格,它位于z(xbilling_rate)和last_remark的底部、右侧或右下角,即last_remark下面的空单元格。通过这些定义,用户可以用表达式xbilling_rate^^1:bottomright(z(xbilling_rate),last_remark)优雅地表达“工作表上的所有内容”的概念,而不管xbilling_rate和xhours被替换为什么值。
56.设置电子表格样式的常用方式是手动选择区域,然后选择要应用的样式。面对溢出和替换,这会崩溃。因此,根据本实施例,用户可以为每个工作表定义多个样式区域,按优先级排列。与溢出区域不同,样式区域可以重叠。重叠区域中的单元格会累积来自所有覆盖区域的样式说明符。如果指定的样式有冲突,则优先级较高的样式有效。每个样式说明符本身都是普通表达式,计算结果为2d表格,并被平铺以填充整个区域。例如,我们为图8b中的工作表835指定以下样式区域,从高优先级到低优先级:(a)从billing_rate^^1到amount^^1,样式“font-weight(字体浓淡)”&“bold(粗体)”,(b)从amount到z(amount),样式“font-size(字体大小)”&where(#amount》500,“large(大)”,“normal(正常)”),以及(c)从billing_rate^^1到z(amount),样式“background-color(背景颜色)”&(“lightgray(浅灰色)”\\“white(白色)”)\\“font-size(字体大小)”和“small(小)”。样式定义对图8a中的表格800求值,其中第一行805和第二行810将背景颜色定义为在浅灰色和白色之间交替,并且第三行815将字体大小定义为小。
57.参考图8b,图示830描绘了结合了如先前定义的样式定义(a)到(c)的工作表835。请注意,第二条规则(b)的字体大小说明符覆盖表格800的第三行815的字体颜色说明符。
58.可替代地,用户也可以将to标签留空,并在样式中指定“span”&3&2以将样式应用到从from标签开始的三行两列的区域。一旦定义,区域的样式就可以通过编程方式访问。例如,style(a,b)检索从单元格a到b的范围的样式。参考图8c,表格860描绘了style(hours,z(amount))将如何评估工作表835。注意在表格860中,style()调用自动生成行865“span”&3&2。这允许通过将style(#source)分配给目标单元格,可以轻松地将一个区域的样式复制到另一个区域。
59.当单元格变得非常宽时,它迫使下面的语义上不相关的单元格变得令人不快地宽。参考图9a,图示900描绘了在标题单元格下方具有令人不快的宽单元格的表格905。传统的电子表格允许合并单元格以缓解这个问题。但是,单元格合并违反了严格的2d网格,并且
难以与诸如溢出和样式区域之类的其他特征相协调。因此,根据本实施例定义用于表中表(twit)的规则以隔离宽行和高列。
60.用户可以指定twit,其中区域被渲染为更大表格内的小型表格,通常是整个工作表的表格。保留了行数、列数和占用的总面积,但单独的行高和列宽可以根据单元格的内容自由调整。根据本实施例,可以在工作表905中定义从title(标题)到title(标题)》》2的twit。图9b的图示910描绘了结合了以上定义的twit的工作表915,从而有利地提供了更好的视觉外观。
61.twit可以嵌套但不能相交。也就是说,两个twit要么完全不相交,要么一个完全包含在另一个中,但它们的边界不能相交。忽略相交的twit,相交的twit定义为具有相交边界的twit。
62.一行工作表难以组织:传统电子表格没有层次结构,因为所有工作表都排成一行。为了克服传统电子表格程序中的这一缺陷,根据本实施例的另一方面使电子表格分层。每个工作表都可以有子工作表,就像文件夹可以包含文件和更多文件夹一样,除了工作表既充当文件夹又充当文件。除了层次更合乎逻辑之外,根据本实施例使工作表分层有几个好处。例如,在将电子表格文档导出为网站时,层次结构很容易映射到url。此外,将元数据(例如读/写权限)分配给一组工作表比将元数据逐个单独地分配给工作表更容易。此外,层次结构形成了定义类的基础,如下所述。
63.大多数传统的主流编程语言以某种形式支持类,这些类首先近似为一束数据和相关联的函数。例如,调用a.area()根据值a所属的类执行不同的代码。根据本实施例的另一方面,可以响应于电子表格中单元格的单元格值将动态指定的电子表格引用替换到电子表格中,其中动态指定的电子表格引用包括动态指定的目录引用和另一个电子表格的电子表格名称。因此,类的行为由在电子表格的上下文中可以理解的动态目录引用来模拟。
64.如果表格的第一行是“类(classs)”&“对目录的引用(reference-to-directory)”,则该表格被认为是所述目录的类。关键字classs被故意拼错以最小化随机表格具有正确关键字的机会,尽管实际关键字的选择在本发明的上下文中不是必需的。然后将特殊语法a-》area()转换为调用directory.area(a)。表达式directory.area是动态工作表引用,由动态目录引用和工作表名称组成。作为一个示例,图10a和10b描绘了rectangle(矩形)类如何工作的图示1000、1050。图示1000中的create(创建)工作表1010用作在给定宽度和高度的情况下创建rectangle(矩形)类的新表格的函数,而图示1050中的区域工作表1060计算矩形的面积。这些定义允许很好地定义如下代码:rectangle.create(width=3,height=3)-》area()。请注意circle.create(radius=3)-》area()将如何调用工作表circle.area。语法#x0["width"]表示在给定表格#x0的第一列中搜索字符串"width",并将其右边的值作为表达式的值。
[0065]
导入第三方电子表格将允许与其他用户共享函数和类。因此,我们的发明允许将电子表格文档作为工作表树中的节点导入。参考图11,图示1100描绘了在某个节点处导入由工作表1010、1060描述的文档的电子表格。导入的文档的目录结构被保留。
[0066]
如上所述,第三方电子表格文档的完整源代码被导入,然后在与文档的其余部分相同的计算机上执行。有时希望导入的电子表格保留在第三方计算机上并在该计算机上执行,并且只通知用户结果。这可能有几个原因。例如,第三方工作表是专有的,作者不希望分
发源代码。或者,执行是资源密集型的或需要专门的硬件,最好由第三方执行。
[0067]
根据本实施例,我们允许驻留在不同计算机上的多个工作表形成一个逻辑分布式文档。这类系统的主要挑战是循环检测,其中驻留在计算机a上的某个单元格a依赖于驻留在计算机b上的某个单元格b,而驻留在计算机b上的某个单元格b又依赖于驻留在计算机c上的某个单元格c,而驻留在计算机c上的某个单元格c又依赖于单元格a。在一个完全通用的系统中,任何单元格都可以引用任何可能的远程单元格,如本示例中,依赖性检测是一个难题。因此,本发明提出了一种有限的星形形式,该形式更易于使用,同时保持有用。
[0068]
只有一台计算机被认为是文档的中心(hub),并且可以根据需要引用任何远程工作表。其他计算机,称为库,不能引用回中心或任何其他计算机,除非通过中心作为参数传入的远程thunk。例如,有人将工单管理系统开发为他们不想为其发布源代码的工作表的集合,因此工单管理系统作为库在开发人员的计算机上运行。然后,用户可以将此库合并为远程工作表。但是,库本身并不知道哪些用户可以登录或可以访问哪些工单,这本质上是用户必须设置的策略。因此,作为配置,用户通过经过身份验证(authenticated)的thunk和授权(authorized)的thunk来分别定义密码验证和访问控制的规则。这些thunk保留在用户的计算机上,只有thunk id被传递到运行库的计算机。当库需要执行thunk并意识到thunk id在本地不可用时,第三方系统会将订阅请求发送回用户的计算机(也称为中心)。
[0069]
根据本实施例的依赖性循环检测通过保持星形依赖性这一事实而变得更简单。由中心引用的两个库不能直接相互通信;它们只能与文档的中心对话。当库将单元格值更新发布到中心时,它们还会列出中心上用于计算此值的所有值。这样,只要存在依赖循环,中心就可以轻松检测到它并将相关单元格设置为具有依赖循环错误。请注意,一个库可以自由地充当其他库的中心,只要这些其他库对其中心不可见。因此,工单管理库本身可以导入其他库,但对用户而言,它仍会显示为一个整体。根据本实施例的循环检测算法与工单管理库的内部实现无关。
[0070]
根据本实施例,提供了协作工作表。在最简单的情况下,协作工作表只是连接到同一个后端的多个ui,每个ui都发送设置单元格代码和设置水平屏障等命令,并从后端接收单元格更新。
[0071]
当启用访问控制时,事情变得更加有趣。传统的协作电子表格系统具有非常粗略的访问控制。例如,google工作表对整个文档的每个用户都有多个权限位,例如用户是否可以编辑文档,用户是否可以阅读文档,或者用户是否可以评论文档。然而,这样一个简单的模型通常是不够的。
[0072]
例如,公司可能希望将其所有管理和操作数据放入一个巨大的文档中。人力资源数据位于一个子树中,包括敏感信息,例如每个人的工资,这些信息必须只对人力资源人员可见。客户支持数据位于另一个子树中。在这个子树中,客户支持团队计划构建工单管理系统。他们希望使用关于谁在哪个部门的hr记录,而不是敏感信息,在他们的工单管理系统中分配角色。由于他们不应该直接访问hr数据,因此hr中的某个人需要提取部门信息并专门授予权限,以便客户支持团队可以读取该数据。
[0073]
显然,传统系统中的粗略访问控制在这种情况下是不够的。然而,一种简单地定义谁可以读写每个工作表的幼稚方法很容易被规避。例如,假设工作表secret只能被hr访问,而工作表public是每个人都可以读写的。任何用户都可以轻松地将工作表public中的单元
格x设置为具有代码secret.everyones_salary并阅读工作表public中的单元格x。
[0074]
根据本实施例的操作定义了每个工作表的所有者和阅读者。每个工作表的所有者和阅读者包括作为实际用户的具体用户和作为某些用户集的共同特性的抽象用户。具体用户和抽象用户一起是用户。每个用户都可以充当一组其他用户。例如,一家假设的公司有以下用户:(a)任何人:系统中的任何用户(始终存在,任何人都可以充当任何人),(b)人力资源人员(例如,在hr工作的某人且可以充当任何人),(c)客户支持人员(例如,从事客户支持工作的某人),(d)经理(例如,任何经理),(e)人力资源经理(例如,可以充当人力资源人员和经理),(f)国际象棋俱乐部人员,(g)tyrion(例如可以充当人力资源经理和国际象棋俱乐部人员),以及(h)samwell(可以充当客户支持人员和国际象棋俱乐部人员)。
[0075]
充当关系是可传递的,因此,例如,tyrion也可以充当人力资源人员。
[0076]
根据本实施例,每个工作表具有一个用户作为其所有者,其必须静态分配,即不是计算的。工作表中的所有表达式始终在所有者的许可下执行,无论谁在查看工作表。这样,每个人都获得相同的值,包括权限被拒绝错误。
[0077]
根据本实施例,每个工作表可以具有零个或多个用户作为其阅读者。该列表可以被计算,并且可以依赖于可替换的单元格值,因此例如,显示个人信息的工作表具有取决于显示谁的信息的阅读者列表。这对于让人们阅读自己的信息而不是其他人的信息很有用。如果用户可以充当所有者或至少一个阅读者,则用户可以阅读工作表。
[0078]
根据本实施例,如果用户可以充当所有者,则用户可以编辑工作表,包括阅读者列表。要更改工作表的所有者,登录用户必须能够同时充当旧所有者和新所有者。由于一个人只能在他可以充当所有者的情况下编辑工作表,并且在所有者的许可下评估工作表,因此不能通过在单元格中写入表达式来获得特权升级。
[0079]
如果不需要细粒度的许可,则将每个工作表的所有者设置为任何人。这也是默认设置。
[0080]
根据本实施例,可以为每个工作表允许多个所有者。然后以全部的所有者的共同特性执行工作表中的内容。也就是说,为了能够从另一个工作表中阅读单元格,全部的所有者都必须能够。随后,用户可以编辑工作表,包括添加新的所有者,如果他们可以充当任何所有者的话。本质上,有一个未命名的单一所有者,它是全部的所有者的共同特性。
[0081]
虽然电子表格的概念早已证明是普通计算机用户可访问的唯一编程环境,但围绕电子表格的概念构建多层的即使简单的动态网站也还没有实现。根据本实施例,单个连贯的电子表格文档能够服务于整个crud网站。即使在一个简单的crud(创建/检索/更新/删除)web应用程序中,开发人员也需要多个层的不同技术。例如,使用诸如html、javascript或级联样式表(css)等前端技术向最终用户呈现用户界面,使用诸如php(超文本预处理器,它是一种开源通用脚本语言)、java或许多其他选择中的任何一种之类的业务逻辑层编程语言将最终用户查询和动作转换为数据库查询和动作(通常转换为结构化查询语言(sql)),并且数据库查询语言,通常也在sql中,用于控制实际托管数据的数据库。
[0082]
鉴于在每一层可用的编程语言、框架、范例和产品的多种选择,从业者通常将选择用于构建功能性产品的技术称为“技术栈”。例如,mean技术栈在数据库层使用mongodb,在业务逻辑层使用express.js(构建在javascript中的node.js之上),在用户界面层使用angularjs javascript框架,因此缩写为mean。
[0083]
技术栈具有很高的进入门槛(即,陡峭的学习曲线),因为对于没有先前编程经验的人,甚至是不精通相关技术的程序员来说,即使学习简单技术栈的基础知识也可能需要数月的艰苦努力。对于专业的web开发人员来说,切换到不同的技术栈仍然是一项艰巨的任务。
[0084]
无论人们是否正在构建下一个facebook或简单的web调查,都存在这种基本结构和相关联的进入门槛。虽然前一种情况的复杂性是合理的,但后一种情况却过于复杂,这使得看似简单的事情对任何人来说都是完全不可能的,专业人士除外。
[0085]
目前可以将电子表格保存为html页面以显示为静态网站。但是对于动态网站则不能这样说,其内容是通过查询数据源和进行计算而动态生成的,即使在电子表格中已经定义了逻辑和布局。目前这样的网站必须从头开始重新实现,以电子表格作为参考,但实际的代码重用是不可能的。
[0086]
参考图12a,图表1200描绘了用于定义动态网站的文档调查的工作表1205,其中,根据本实施例,文档包含所有数据、业务逻辑和呈现编码。图表1200表示的示例描绘了调查网站,其中教师希望从一个班级的四个学生那里收集三个反馈问题的答案。教师不必创建和管理数据库,而是在电子表格文档调查中创建工作表数据1205以保存相关数据。这类似于前面描述的数据库层。方括号中的文本表示分配给单元格的标签。
[0087]
接下来,教师建立在收到提交时记录调查结果的业务逻辑。具体来说,老师制作了一个名为on_student_submit的宏,包含以下内容:
[0088]
pastecell!(locate(xstudent,student_id:last_student)-|answer)》》
[0089]
xqid,xanswer;index!;(1)
[0090]
宏模拟用户动作,就像在传统电子表格中一样。假设提交是:
[0091]
student=joe@sch.edu
[0092]
qid=1
[0093]
answer=9(2)
[0094]
其中xstudent是指提交中的学生字段,即要在区域1210中查找的joe@sch.edu。
[0095]
在宏(2)中,“locate(xstudent,student_id:last_student)”将具有内容joe@sch.edu的单元格1215定位在区域1210中从student_id到last_student的单元格范围内。在此示例中,这将是具有标签joe_id的单元格1215。
[0096]
在宏(2)中,“locate(xstudent,student_id:last_student)-|answers”是指在行“locate(xstudent,student_id:last_student)”(即,包括单元格1215的行1225)和列“answers”(即,列1230)的交叉处的单元格1220,这将是包括图表1200中的标签[a]的单元格1220。
[0097]
在宏(2)中,“》》xqid”表示向右移动xqid单元格。请注意,问题id是从0开始的,其中问题id0是指问题“你喜欢鲨鱼宝宝”1240,问题id1是指问题“你喜欢鲨鱼妈妈”1245。整个表达式“(locate(xstudent,student_id:last_student)-|answer)》》xqid”是指包括标签[b]的单元格1250。
[0098]“pastecell!b,xanswer;”将提交的答案字段的内容粘贴到包括标签[b]的单元格1250,就好像用户已将此类内容粘贴到单元格1250中一样。并且“index!;”调用名为“index”的宏,如下所述。
目标on_student_submit 数据qid0 答案8
[0113]
表2
[0114]
因此,当点击提交按钮时,“on_student_submit”宏由电子表格引擎根据上面所示的提交(5)执行并且字段xqid和xanswer填充了提交的值。
[0115]
由根据本实施例的电子表格渲染的调查网站的生命周期如下发生。首先,当学生有未回答的问题时,我们会渲染“show_answer_form”工作表以征求答案。接下来,当提交答案时,将调用“on_student_submit”宏来更新数据表。然后,当学生回答完所有问题后,会渲染“show_completed_answers”电子表格以显示他们的所有答案。此后,教师可以对数据表中收集的数据使用通常的电子表格公式而提交的答案进行任何分析。
[0116]
通常,动态网页可以在用户提交的查询参数所指示的替换之后从电子表格渲染。当请求url时,服务器可能会在请求url之后的电子表格文档中从根(root)工作表开始遍历路径。例如,响应于请求:
[0117]
http://doc.abc.com/demo/ticketmanager/ticket?id=123(5)
[0118]
服务器可能会查看文档根目录并找到电子表格文件demo/ticket_manager。根据本实施例,它打开文件并在root.ticket处定位工作表。它将xid替换为123并将工作表root.ticket渲染为html。替换过程与函数调用中的工作表替换基本相同,包括x前缀,不同之处在于将整个替换的工作表渲染为结果。
[0119]
约束是sql数据库中的中心概念。它们是实施数据一致性的关键。有经验的数据库管理员知道,在没有约束的情况下,最终坏数据将潜入。根据本实施例,用户可以将某些单元格和/或公式指定为“约束”,从而为电子表格带来约束。此类单元格和公式必须始终评估为非错误、非错值。如果某个动作(例如更改某些单元格的内容)导致一个或多个约束失败,则该动作将被拒绝,并且电子表格文档将恢复到尝试该动作之前的状态。请特别注意,将单元格或公式指定为约束的动作本身受此动作检查的约束。因此,如果一个单元格当前处于错误状态,那么将其指定为约束将失败。
[0120]
一旦定义了约束,数据所有者就可以保证这些重要的不变量将得到支持。一个示例是检查id列是否包含唯一值,例如在约束“allunique(#id)”中。这里“#id”指的是id列,并且“allunique()”当且仅当其参数(例如,id列)不包含重复项时才评估为真(true)。
[0121]
另一个示例是检查sku单元格是指实际存在的库存单位(sku)产品代码,并且不是“未知”,例如在下面的表达式(6)中:
[0122]
locate(sku,#all_skus))&&sku!="unknown"(6)
[0123]
其中
‘
#all_skus’指的是持有所有sku产品代码的区域,
‘
locate()’查找其第一个参数在指定为其第二个参数的区域中的位置。如果查找失败,则返回错误。
[0124]
如果违反了诸如表达式(6)的不变量,则可以使业务数据不可用。通过定义约束提供的保证对于业务应用程序尤其重要,这是电子表格用户的主要用例。
[0125]
在某些情况下,必须首先暂时打破约束,然后仅在多次用户动作之后才恢复。例如,要更正前面的示例中sku单元格中的拼写,必须同时更正“#all_skus”和“sku”中的相关拼写,并且当仅更正一个时违反了约束。因此,用户可以暂时禁用约束。禁用的约束只是非
约束,带有视觉提醒,即它应该在某个时候恢复。
[0126]
考虑用于在列中查找id的通用表达式。在上文呈现的图12a和图12b的示例的上下文中,通用表达式将是下面的表达式(7):
[0127]
locate(xstudent,student_id:last_student)(7)一个简单的实现会按顺序扫描表格“student_id:last_student”以查找“xstudent”的值。这在数据库文献中通常被称为线性扫描,并且可能是一种资源昂贵的操作。为了避免这种昂贵的操作,数据库构建索引以实现快速查找。但是数据库索引依赖于用户来提供预定义的数据模式,并提供在这种模式上构建的索引。这对于电子表格显然是不可行的。例如,用户应该能够高效地“locate()”任何区域中的任何值。因此,根据本实施例,提出了一种使用空间索引(spatialindices)对电子表格中的单元格值进行索引以加速在电子表格中的任意单元格块中搜索值的新方法。
[0128]
首先,我们定义可能的单元格值的总顺序(totalorder)。例如,我们任意定义整数小于浮点数,而浮点数又小于字符串,而字符串又小于空白值。在每种数据类型中,应用通常的排序。随后,电子表格的状态可以编码为三维点云(pointcloud),其中单元格y行x列处的z值由(x,y,z)处的点表示。
[0129]
查询“locate(value,start:end)”因此是在三维空间中的搜索以定位电子表格的点云和由以下限制的长方体的交点:
[0130]
column(start)《=x《=column(end),row(start)《=y《=row(end),并且
[0131]
value《=z《=value(8)
[0132]
这种搜索可以通过空间索引来加速,其中最著名的是r树索引。以下讨论将使用r树索引,但可以理解,根据本实施例,也可以使用大多数其他空间索引,几乎没有修改。
[0133]
r树递归地将点云c划分为两个集合(c1和c2)并记录每个集合的边界框。这些集合被选择为尽可能平衡、紧凑和不相交。搜索r树是一个普通的递归函数,在r树中添加点、删除点、移动点对于本领域技术人员来说是众所周知的。
[0134]
可以通过空间索引加速的一些其他表达式是:
[0135]
minstring(start:end)及类同者(9)allsame(start:end)可以简单地加速为min(start:end)==max(start:end)(10)
[0136]
start:end《5(11)
[0137]
特殊注意事项适用于&&查询。参考图14,电子表格1400描绘了儿童1420购买的零食1410的长记录和购买日期1430的场景。根据如上所述的本实施例,可以通过空间索引来加速电子表格上的查询。查询(12)返回一个子项的日期在短范围内的记录的索引:
[0138]
between(date:zdate,'2020-01-20','2020-01-21')&&person:zperson=="luke"(12)
[0139]
第一子表达式是稀疏的,仅匹配少数记录。但是,第二个子表达式是密集的。在对两个子表达式求值然后找到它们的并集的幼稚策略中,将浪费很多时间来评估布尔向量“person:zperson=="luke"”,而仅为把其大部分扔掉。
[0140]
为了解决这个问题,当查询被分而治之时,两个约束同时被考虑。在每一步中,根据第一子表达式或第二子表达式划分剩余的搜索区域,并选择具有较高信息量的子表达式。由于日期更具歧视性,因此更有可能选择根据日期分割搜索区域,从而快速修剪掉工作
表的点云。
[0141]
尽管诸如通用r树索引之类的空间索引可以用于加速许多类型的查询,但其他查询仍然受益于专门的数据结构。让我们考虑一个通常用作约束的单元格:“colsorted(a:b)”。当且仅当指定范围内的每一列都已排序时,约束评估为真,即每个单元格不大于下面的单元格。
[0142]
有时我们希望在电子表格中定义分层区域。一个示例是表中表(twit),它是电子表格中的一个区域,其行高和列宽的确定独立于上面讨论的较大电子表格的行高和列宽。参考图15a、图15b和图15c,电子表格1500、1530、1570描绘了根据本实施例的twits的使用。
[0143]
电子表格1500中的表1505的呈现可以通过几种方式来改进。首先,id列1510太宽,因为它被工作表的位于表外的部分拉伸。此外,可以更简洁地显示受让人的姓名1515。为了改进表现,整个表1505可以渲染为大twit1535,并且每一行的名字和姓氏单元格渲染为小的twit1540、1545、1550,如电子表格1530中所示。
[0144]
定义twit的直接方式是给每对开始/结束单元格一个唯一的twitid,以便明确地识别twit区域。但是,当我们需要大量生成(可能未知的)一数量的twit(例如名称twit)时,这可能会很麻烦。
[0145]
相反,根据本实施例使用户能够定义哪些单元格是开始单元格和结束单元格,并且系统可以自动匹配开始和结束单元格以形成不相交的区域。在电子表格1530所示的示例中,用户可以输入以下定义:
[0146]
`id:twitbegin(13)
[0147]
gose(`id):twitend(14)
[0148]
grows(`assigneevv1):twitbegin(15)
[0149]
grows(`assignee_|1):twitend(16)
[0150]
表达式`id定位包含字符串“id”的单元格。“grows(a)”从仅包含单元格a的区域开始,并不断向下扩展,直到其下方的单元格全部为空白。因此,“grows(`assigneevv1)”从包含字符串“assignee(受让人)”的单元格下方开始向下扩展,直到遇到第一个空白单元格。类似地,“growse(a)”从包含单元格a的区域开始,并不断将该区域向右和向下扩展,直到它成长为一个表,该表完全由紧邻右侧的空白包围,一直到紧邻底部,并且到紧邻右下角。“gose(a)”是“growse(a)”的右下角。这些是标签位置表达式的示例。
[0151]“grows(`assigneevv1):twitbegin”的定义(15)将assignee(受让人)单元格下方的每个单元格标记为twitbegin单元格。“grows(`assignee_|1):twitend的定义(16)将assignee(受让人)单元格下方最后一列中的每个单元格标记为twitend。定义(13)、(14)、(15)和(16)的分配结果在表1570(图15c)的表1575中示出。
[0152]
进一步根据本实施例,非相交区域可以被定义为完全不相交的区域或完全包含在另一个区域内以使得它们的边界不相交的区域。可以证明,一组起始单元格和结束单元格最多可以接受一个与非相交区域对应的匹配,并且可以在“o(nlogn)”时间内找到这样的匹配,其中n是起始单元格的数量。因此,我们总是可以从这些twitbegin和twitend标记符中恢复用户的预期twit。
[0153]
可替代地,twitbegin或twitend标记符中的一些可以增加id。一对twitbegin和twitend标记符必须各自具有相同的id。这使用户可以明确说明配对。但是,使用自动匹配
算法,这样的id不需要是唯一的。因此,根据本实施例,通过指示哪些单元格具有开始标记符以及哪些单元格具有结束标记符,可以在平面2d电子表格结构中创建分层区域,但是没有开始单元格和结束单元格的明确和精确的匹配,因此系统相应地挑选生成不相交区域集合的唯一的开始标记符和结束标记符配对。
[0154]
当工作表包含大量行时,插入和删除行会变得非常昂贵,因为它会影响其下方的每一行。通过引入bignum行号来缓解问题,可以减轻行和列的有效插入和删除。bignums是具有任意高精度的数字,因此它们可以精确地表示所有可以用二进制精确表示的数字。
[0155]
根据本实施例,行号不一定是连续的,而是可以是小数,并且可以跳过整数。例如,从第1、2、3、4、5行开始,用户删除第3行并在第1行和第2行之间插入另一行,行号现在是1、1.5、2、4、5。这样,删除一行是一种廉价的操作,不会不必要地影响它下面的行。
[0156]
使用bignum行,虽然仍然可以确定两行的顺序,但确定某一行的前一行或下一行不再是微不足道的。需要一个索引来帮助回答这两个查询:(i)行r上方或下方的第n行是什么?(ii)行r1和行r2之间的距离是多少?
[0157]
索引应该允许人们有效地回答这样的查询,而且索引应该被分解成小的信息片段,以便在计算单元格期间,可以完成对使用了哪些信息片段的记录。然后,当某些信息片段发生变化时,人们就会了解要重新计算哪些单元格。此外,当插入/删除一行时,只有少量的此类信息片段会发生变化,并且此类信息片段的列表很容易定位。随后,理想情况下,只有那些真正需要重新计算的单元格才会被重新计算。
[0158]
为此,根据本实施例使用类似跳过列表(skip-list)的结构。具体来说,当创建一个新行时,它会被随机分配一个级别(level)。一行处于第1级的概率为0.5,处于第2级的概率为0.25,依此类推。行号的级别永远不会改变。此外,每个第1级节点记录下一个第1级节点;每个第2级节点记录下一个第1级节点和下一个第2级节点。此外,一般来说,第n级节点记录从第1级到第n级的n个下一个节点。最后,一个特殊的、不可见的顶行被分配行号
“‑
inf”,并被认为在所有级别中。
[0159]
因此,第1级形成所有行的链表。更高的级别是快速通道(express lane),允许搜索在更大的跨度上进行得更快。有了适当位置的这个索引,可以使用“o(log(n))”信息片段来回答类似“r行上方/下方的第n行是什么?”之类的问题。此外,可以使用“o(log(n))”信息片段来回答诸如“行r1和r2之间的距离是多少?”之类的问题。
[0160]
因此,可以看出,根据本实施例,当插入或删除一行时,它在每个级别中最多影响2个链接。因此,行的插入或删除最多会破坏“o(级数)”信息片段。
[0161]
为了呈现给用户,我们可以选择不显示bignum行号,可能不直接显示,而是显示到第一行的距离,以便用户仍然会看到连续的整数。如上所述,可以使用跳过列表有效地计算两行之间的距离。
[0162]
因此,可以看出,本实施例提供了增强电子表格的利用和操作的健壮的面向用户的电子表格编程语言。根据本实施例,已经定义了溢出、作为函数调用的工作表替换、作为单元格值和回调参数的工作表替换(thunk)、屏障、编程样式定义、twit、类、标签位置表达式、作为远程回调的工作表替换(thunk)、协作文档的细粒度权限、使用工作表替换的网页、由单个电子表格定义的动态网页、用户指定的约束、空间索引、持久索引和增量更新单元格、bignum行和列号以及行和列索引,来提供一个简单、灵活和通用的向后兼容的电子表格
友好型解决方案。
[0163]
尽管在本实施例的前述详细描述中已经呈现了示例性实施例,但是应当意识到,存在大量的变化。还应意识到,示例性实施例仅是示例,并不旨在以任何方式限制本发明的范围、适用性、操作或配置。相反,前面的详细描述将为本领域技术人员提供用于实施本发明的示例性实施例的方便路线图,应当理解,可以对示例性的实施例中描述的步骤以及操作方法的功能和布置进行各种改变,而不背离如所附权利要求中阐述的本发明的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。