一种基于双层pso的模块化神经网络出水氨氮浓度多步预测方法
技术领域:
1.本发明涉及人工智能技术领域,更具体地,涉及一种基于双层粒子群的模块化神经网络出水氨氮软测量方法。实现氨氮浓度的多步预测是先进制造技术领域的重要分支,既属于控制领域,又属于水处理领域。
背景技术:
:
2.随着社会城市化和工业化进程的加快,水资源的污染也随之增加,这对人类的生存和发展以及社会的生态平衡产生了巨大的影响。在城市污水处理行业领域,废水中的氨氮是水体中可导致富营养化的营养物质,随着污水处理厂建设和运行规模的逐步扩大,污水处理厂承担着降低自然界氨氮总量的重要任务。因此,严格限制氨氮的排放可以有效地解决这个问题。通过提前预测氨氮的浓度,可以有效提高氨氮的去除效率,改善出水氨氮超标的现象,从而带动水质实时控制水平和环境效益的提高。
3.为了解决这一难题,污水处理厂采用软测量方法对出水氨氮进行预测。但是出水氨氮的单步预测无法为未来趋势提供信息,而掌握污水处理过程中出水氨氮的变化趋势,可以让污水处理厂制定详细的控制策略。因此,实现出水氨氮趋势变化的检测对污水处理厂具有重要意义。针对这一问题,提出了一种基于双层粒子群的模块化神经网络出水氨氮软测量模型,用于污水处理厂的多步预测。
技术实现要素:
4.本发明获得了一种基于双层粒子群pso的模块化神经网络出水氨氮多步预测方法,根据污水处理过程采集的数据实现了出水氨氮的多步测量,解决了难以掌握污水处理过程出水氨氮浓度变化趋势的问题,提高了城市污水处理厂控制决策的灵活性。
5.一种基于双层粒子群的模块化神经网络出水氨氮多步预测方法,其特征在于,包括以下步骤:
6.步骤1:选取出水氨氮历史数据,生成预测样本;
7.获取污水处理厂获得的氨氮历史数据y=[y1,
…
,y
l
]
t
,对其进行重建,生成m步预测的样本a;
[0008][0009]
其中y是时间序列数据,l是历史数据y的长度,d是最大的输入维度;ai和ao是预测模型的输入和输出矩阵;
[0010]
步骤2:设计模块化神经网络模型;
[0011]
根据“分而治之”原则,将一个多步预测任务划分为多个较为简单的子任务,各子
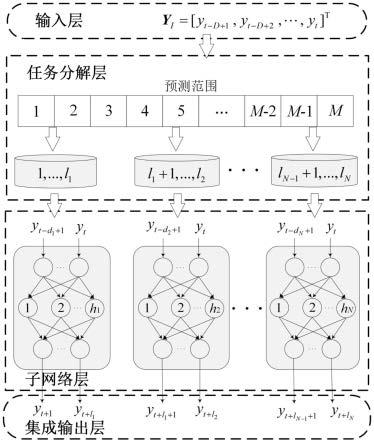
任务分别计算;根据“合作共赢”原则,将各子任务的计算结果进行整合,还原整个任务的输出;由此构建一个模块化神经网络;它由四层组成:输入层、任务分解层、子网层和集成输出层;
[0012]
各层的计算功能如下:
[0013]
①
输入层:输入层将当前和历史时间序列导入模型;该层共有d个神经元,代表输入的维数为d,输入层的输入为yi(t)=[y
t-d 1
,y
t-d 2
,
…
,y
t
]
t
,其中y
t
代表当前时刻;
[0014]
②
任务分解层:该层将多步预测的任务分解为几个独立的子任务;对于m步时间序列预测,它生成n个子任务,其中sn表示第n个子任务的预测范围数;因此,第n个子任务的预测范围来自l
n-1
1到ln,其中这里l0=0;
[0015]
③
子网络层:子网络层由几个模块组成,每个模块处理一个子任务,因此子网络的数量等于子任务的数量;使用径向基神经网络神经网络作为每个子网络的模型;对于第n个子网络,假设它预测sn,则第n个径向基神经网络神经的输出神经元数相应设置为
[0016]
④
集成输出层:这一层集成了每个子网络的输出,以获得m步预测结果,即其中yo为模型的输出;
[0017]
步骤3:设计用于模块化神经网络的双层粒子群优化算法;
[0018]
步骤3.1:双层粒子群算法的外层算法;
[0019]
①
初始化;初始化参数,包括惯性权重w
ext
、两个加速度系数和种群大小q
ext
和最大迭代次数k
ext
;设置初始迭代次数k
ext
=1;所有粒子的位置x
ext
随机生成,相应的速度v
ext
限制在[-4,4];
[0020][0021]
其中至是随机生成的0或1;
[0022]
②
解码二进制粒子;将代表m步预测任务的二进制粒子转换成个n个子任务;将其分给子网络进行学习;
[0023]
③
计算适应度函数;根据子网络分别计算输出,根据公式(3),计算m步预测范围内的平均均方根误差rmse计算所有粒子的适应值;
[0024][0025]
其中,y
t m
和是第m个预测范围的期望输出值和预测输出值,这里1≤m≤m;p是训练样本数;第n个子网络预测范围内的rmse之和表示为:
[0026][0027]
由此,可将适应度函数f重写为:
[0028][0029]
其中n是模块化神经网络中的子网络数量;
[0030]
适应度值由子网络的预测精度决定;每个粒子第一代位置为个体最佳位置粒子下一代的适应度值比当前对应的适应度值小,则将当前粒子的x
ext
作为该粒子新的在计算每一代中所有粒子的适应度值后,适应度值最小的粒子对应的为群体最佳位置如果满足终止条件:适应度函数小于期望值或k
ext
达到k
ext
,则输出否则,设置k
ext
=k
ext
1,并转至步骤
④
;
[0031]
④
更新;首先根据(6)更新每个粒子的速度,然后使用sigmoid函数映射到[0,1]的区间
[0032][0033][0034]
其中k
ext
是迭代次数,w
ext
∈[0,1]是惯性重量;和是两个加速度系数;和是均匀分布在[0,1]内的随机数;是第q个粒子的第k
ext
代的速度向量;是第q个粒子的第k
ext
1代的速度向量;是第q个粒子的位置向量;是第k
ext
代的个体最佳位置;是第k
ext
代的群体最佳位置;v
q,j
是速度向量的第j个分量的值;s是sigmoid函数;这里v
q,j
被限制在[-v
max
,v
max
]之间,通过如下公式:
[0035][0036]
这里,v
max
是一个常数值,设置为4;随后,第q个粒子的第j个分量的位置为:
[0037][0038]
其中ζ是随机生成的实数,均匀分布在0和1之间;然后返回步骤
②
;
[0039]
通过迭代执行上述步骤,最终输出一个最优二进制粒子它表示多步预测的最优任务分解;然后,通过将模块化神经网络中n个子网络的输出集成,可以生成m步提前预测值;
[0040]
步骤3.2:双层粒子群算法的内层算法;
[0041]
①
初始化;初始化超参数,包括惯性权重w
int
、两个加速度系数和种群大小q
int
和最大迭代次数k
int
;将初始迭代次数k
int
=1和初始pareto解集a设置为空集;子网络中
的最大隐藏神经元数设置为h
max
,分别在[-6,6]和[-1,1]范围内随机初始化粒子在活动空间中的位置和相应的速度
[0042]
②
对于第n个子网络n∈[1,2,
…
,n],基于两个目标函数g
n,1
和g
n,2
评估种群中的粒子,并根据每个粒子的最佳非支配解更新然后,对所有粒子的进行非支配排序,并将非支配解存储在pareto解集a中;然后从a中随机选择一个粒子作为如果满足终止条件(k
int
达到k
int
),则输出否则,设置k
int
=k
int
1,并转至步骤
③
;
[0043]
目标函数g
n,1
为子网络在预测范围内的平均预测精度,其计算公式如下:
[0044][0045]
其中,fn由(4)定义,sn是第n个子网络的预测范围;
[0046]
目标函数g
n,2
为子网络的复杂度:
[0047]gn,2
=hn*snꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0048]
其中,hn和sn分别表示第n个子网络中隐藏层神经元和输出层神经元的数量;
[0049]
③
更新;粒子的更新包括hn的变化以及粒子位置xq(k)和速度vq(k)的更新;
[0050]
粒子的位置x
int
的定义如下:
[0051][0052]
其中分别代表x中各个隐含层节点的向量;ci,σi,ωi分别代表第i个隐含层节点的中心宽度和与输出层的权值;
[0053]
子网络隐含层大小h的更新公式:
[0054][0055]
其中hq(k
int
)是第q个粒子第k
int
代对应的子网络隐含层大小;hq(k
int
1)是第q个粒子第k
int
1代对应的子网络隐含层大小;h
best
(k
int
)是第k
int
代中最佳粒子的对应的子网络隐含层大小;
[0056]
位置和速度更新;对于第q个粒子,根据(14)和(15)更新;然后返回步骤
②
;
[0057][0058][0059]
步骤3.3:输入训练样本数据,根据步骤3.2中的公式(3)-(15)更新内外层粒子的值,选择满足终止条件时的的值作为模型的参数设定;
[0060]
步骤4:出水氨氮多步预测;
[0061]
将测试样本数据作为训练好的模块化神经网络的输入,得到神经网络的输出后将其反归一化,得到出水氨氮的多步预测值。
[0062]
本发明与现有技术相比,具有以下明显的优势和有益效果:
[0063]
(1)本发明针对当前污水处理过程中的关键水质参数氨氮测量周期长,数学模型不易确定的问题,提出了基于双层粒子群的模块化神经网络模型,实现出水氨氮多步预测,具有预测范围大、预测精度高、泛化能力强的特点;
[0064]
(2)本发明针对传统多步预测的任务划分不灵活的问题,采用二进制编码的粒子群算法将多步预测任务进行划分;做到了预测任务的合理划分,提高了多步预测的灵活性和泛化性;
[0065]
(2)本发明针对传统模块化神经网络的子网络结构通常比较大且固定,容易引起结构过大和耗时的问题,采用多目标粒子群算法,在保证子网络预测精度的前提下,自适应确定子网络的结构,避免网络规模过大需要更多的计算时间和存储空间;同时提高了多步预测的精度。
附图说明
[0066]
图1是本发明的基于双层粒子群的模块化神经网络结构拓扑图;
[0067]
图2是本发明的基于双层粒子群的模块化神经网络流程图;
[0068]
图3是本发明的模块化神经网络的子网络结构拓扑图;
[0069]
图4是本发明的出水氨氮浓度多步预测结果图;
具体实施方式
[0070]
本发明获得了一种基于双层粒子群的模块化神经网络出水氨氮多步预测方法,该软测量方法的结构拓扑图如图1所示,流程图如图2所示。根据污水处理过程采集的数据实现了氨氮浓度的多步测量,解决了污水处理过程出水氨氮浓度变化趋势难以掌握的问题,提高了城市污水处理厂决策的灵活性;
[0071]
实验数据来自某污水处理厂2014年09月16日到09月22日水质分析数据,共有1036个出水氨氮浓度样本,数据重构后选前600个数据作为训练样本,剩余400个数据作为测试样本;
[0072]
一种基于双层粒子群的模块化神经网络出水氨氮浓度多步预测方法,其特征在于,包括以下步骤:
[0073]
步骤1:选取出水氨氮历史数据,生成预测样本;
[0074]
获取污水处理厂获得的生化需氧量bod的历史数据y=[y1,
…
,y
l
]
t
,对其进行重建,生成m步预测的样本a,这里m为18,a的大小为36*1000;
[0075][0076]
其中y是时间序列数据;l是历史数据y的长度,在这里为1036;d是最大的输入维度为18;ai和ao是预测模型的输入和输出矩阵,大小为18*1000;
[0077]
步骤2:设计模块化神经网络模型;
[0078]
根据“分而治之”原则,将一个多步预测任务划分为多个较为简单的子任务,各子任务分别计算;根据“合作共赢”原则,将各子任务的计算结果进行整合,还原整个任务的输出;由此构建一个模块化神经网络;它由四层组成:输入层、任务分解层、子网层和集成输出层;
[0079]
各层的计算功能如下:
[0080]
①
输入层:输入层将当前和历史时间序列导入模型;该层共有d个神经元,代表输入的维数为d,输入层的输入为yi(t)=[y
t-d 1
,y
t-d 2
,
…
,y
t
]
t
,其中y
t
代表当前时刻;这里d为18;
[0081]
②
任务分解层:该层将多步预测的任务分解为几个独立的子任务;对于m=18步时间序列预测,它生成n个子任务,其中sn表示第n个子任务的预测范围数;因此,第n个子任务的预测范围来自l
n-1
1到ln,其中这里l0=0;
[0082]
③
子网络层:根据任务分解层生成的n个子任务生成n个子网络,每个模块处理一个子任务;使用径向基神经网络rbf神经网络作为每个子网络的模型,径向基神经网络rbf的结构图如图3所示;对于第n个子网络,预测范围是sn,则第n个径向基神经网络rbf神经的输出神经元数相应设置为
[0083]
④
集成输出层:这一层集成了每个子网络的输出,以获得18步预测结果,即其中yo为模型的输出;
[0084]
步骤3:设计用于模块化神经网络的双层粒子群优化算法;
[0085]
步骤3.1:双层粒子群算法的外层算法;
[0086]
①
初始化;初始化参数,包括惯性权重w
ext
、两个加速度系数和种群大小q
ext
和最大迭代次数k
ext
;设置初始迭代次数k
ext
=1;所有粒子的位置x
ext
为随机生成的0和1,相应的速度v
ext
在[-4,4]之间随机选取;w
ext
通常取值0.4~2,这里w
ext
为0.8;和通常取值为0~4,这里取0.49;q
ext
通常取值20~40,这里取20;k
ext
通常取值50~100,这里取50;
[0087][0088]
其中至是随机生成的0或1;
[0089]
②
解码二进制粒子;将代表m=18步预测任务的二进制粒子转换成个n个子任务;将其分给子网络进行学习;这里给定一个粒子为x
ext
=[1 0 0 1 1 0 1 1 1 0 0 1 0 1 1 0 0 0],规定若相邻的x相同则划分在同一个子任务,因此m=18的预测任务划分为n=10个子任务,任务集合为s=[1,2,2,1,3,2,1,1,2,3];
[0090]
③
计算适应度函数;根据子网络分别计算输出,根据公式(3),计算18步预测范围内的平均均方根误差rmse计算所有粒子的适应值;
[0091][0092]
其中,m是第几个预测的步长1≤m≤m,y
t m
和是第m个预测范围的期望输出值和预测输出值,p是训练样本数;第n个子网络预测范围内的rmse之和表示为:
[0093][0094]
由此,可将适应度函数f重写为:
[0095][0096]
其中n是模块化神经网络mnn中的子网络数量;
[0097]
适应度值由子网络的预测精度决定;在计算每一代中所有粒子的适应度值后,得到群体最佳位置和个体最佳位置如果满足终止条件:k
ext
达到k
ext
或者适应度函数f《0.035,则输出否则,设置k
ext
=k
ext
1,并转至步骤
④
;通常情况下,真实数据集的目标f取值范围在0.001~0.1,本次实验取0.035;
[0098]
④
更新;首先根据(6)更新每个粒子的速度,然后使用sigmoid函数映射到[0,1]的区间
[0099][0100][0101]
其中k
ext
是迭代次数,w
ext
是惯性重量,这里取0.8;和是两个加速度系数,这里取0.49;和是均匀分布在[0,1]内的随机数;是第q个粒子的第k
ext
代的速度向量;是第q个粒子的第k
ext
1代的速度向量;是第q个粒子的位置向量;是第k
ext
代的个体最佳位置;是第k
ext
代的群体最佳位置;v
q,j
是速度向量的第j个分量的值;s是sigmoid函数;这里v
q,j
被限制在[-v
max
,v
max
]之间,通过如下公式:
[0102][0103]
这里,v
max
是一个常数值,设置为4;随后,第q个粒子的第j个分量的位置为:
[0104][0105]
其中ζ是随机生成的实数,均匀分布在0和1之间;然后返回步骤
②
;
[0106]
通过迭代执行上述步骤,最终输出一个最优二进制粒子它表示多步预测的最优任务分解;然后,通过将模块化神经网络中n个子网络的输出集成,可以生成18步提前预测值;
[0107]
步骤3.2:双层粒子群算法的内层算法;
[0108]
①
初始化;初始化超参数,包括惯性权重w
int
通常取值0.4~2,这里设置为0.8;两个加速度系数和通常取值为0~4,这里设置为0.49;种群大小q
int
通常取值20~40,这里设置为40;最大迭代次数k
int
通常取值50~100,这里设置为100;将初始迭代次数k
int
=1和初始pareto解集a设置为空集;子网络中的最大隐藏神经元数为h
max
通常取值5~20,这里设置为10,分别在[-6,6]和[-1,1]范围内随机初始化粒子在活动空间中的位置和相应的速度
[0109]
②
对于第n个子网络n∈[1,2,
…
,n],基于两个目标函数g
n,1
和g
n,2
评估种群中的粒子,并根据每个粒子的最佳非支配解更新然后,对所有粒子的进行非支配排序,并将非支配解存储在pareto解集a中;然后从a中随机选择一个粒子作为如果满足终止条件g
n,1
《0.03或者k
int
达到k
int
,则输出g
best
;否则,设置k
int
=k
int
1,并转至步骤
③
;通常情况下,真实数据集的目标g
n,1
取值范围在0.001~0.1,本次实验取0.03;
[0110]
目标函数g
n,1
为子网络在预测范围内的平均预测精度,其计算公式如下:
[0111][0112]
其中,fn由(4)定义,sn是第n个子网络的预测范围;
[0113]
目标函数g
n,2
为子网络的复杂度:
[0114]gn,2
=hn*snꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0115]
其中,hn和sn分别表示第n个子网络中隐藏层神经元和输出层神经元的数量;
[0116]
③
更新;粒子的更新包括对应子网络隐含层大小hn的变化以及粒子位置和速度的更新;
[0117]
粒子的位置的定义如下:
[0118][0119]
其中分别代表x中各个隐含层节点的向量;ci,σi,ωi分别代表第i个隐含层节点的中心、宽度和与输出层的权值;
[0120]
子网络隐含层大小h的更新公式:
[0121][0122]
其中hq(k
int
)是第q个粒子第k
int
代对应的子网络隐含层大小;hq(k
int
1)是第q个粒
子第k
int
1代对应的子网络隐含层大小;h
best
(k
int
)是第k
int
代中最佳粒子的对应的子网络隐含层大小;
[0123]
位置和速度更新;对于第q个粒子,根据(14)和(15)然后返回步骤
②
;
[0124][0125][0126]
步骤3.3:输入训练样本数据,根据步骤3.2中的公式(3)-(15)更新内外层粒子的值,选择满足终止条件时的作为模型的参数设定;这里最佳粒子为:
[0127]gbest
=[3.5207-0.9387 2.0006 2.4295 4.4633 1.2507 1.2692 1.6715 0.2895 4.2812
ꢀ‑
1.7025 0.4006
ꢀ‑
0.4628
ꢀ‑
2.2762
ꢀ‑
0.7256 0.0914 0.1715
ꢀ‑
0.2189
ꢀ‑
0.0284
ꢀ‑
0.1560 0.4650];最佳结构h
best
为7;
[0128]
步骤4:出水氨氮多步预测;
[0129]
将测试样本数据作为训练好的模块化神经网络的输入,得到神经网络的输出后将其反归一化,得到出水氨氮的多步预测值;
[0130]
在本实施例中,基于双层粒子群算法的模块化神经网络模型对出水氨氮浓度预测结果图如图4所示,子图分别为多步预测的第1,4,7,12,14,18步结果;x轴:测试样本,单位是个;y轴:出水氨氮浓度预测值,单位为mg/l,实线为出水氨氮浓度实测值,虚线为出水氨氮浓度预测值;结果表明基于双层粒子群算法的模块化神经网络的出水氨氮软测量方法的有效性;
[0131]
训练样本:
[0132]
表1.出水氨氮浓度,单位为mg/l
[0133]
[0134]
[0135][0136]
测试样本:
[0137]
表2.出水氨氮浓度,单位为mg/l
[0138]
[0139][0140]
表3.模型测试输出出水氨氮浓度,单位为mg/l
[0141]
[0142]
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。