1.本发明属于计算机应用技术领域,尤其涉及一种基于日志数据的云系统故障诊断方法。
背景技术:
2.随着云计算新技术包括sdn(software defined network)、高可用性部署(high availability)、监控和审计技术地不断发展,云计算在企业和个人的日常运转过程中正发挥很大的正向优势。由于云系统的广泛使用,工业界和学术界对云系统的稳定性和可靠性提出了一定的要求。因此,如何对云系统进行精确的故障诊断和定位成为了重要的研究课题。这不仅可以帮助维护人员快速定位导致云系统出错的模块,也可以结合自动故障恢复工具,保证云系统在发生故障时快速进行恢复,提高用户体验。
3.云系统运行过程中会产生海量的监控数据,包括监控指标数据、日志数据和服务调用轨迹数据等,使得运维人员难以实时发现系统故障,并寻找出导致系统故障的模块或运行节点。为了应对上述问题,许多研究者提出了基于系统监控数据的故障诊断方法,来快速发现系统中存在的故障或寻找故障根因,保障云系统的可靠性和稳定性。
4.针对云系统故障诊断的工作,目前研究学者已经提出了众多方法,文献“cloudseer:using logs to detect errors in the cloud infrastructure(us2016179600a1)”致力于解决云系统中任务的运行错误,当任务出现错误时实现快速、准确的故障位置诊断与定位。cloudseer首先从日志中为云系统中的每个任务提取其工作流。工作流时该任务执行的过程中,各个服务进程打印的日志按时间顺序组成的日志序列。以任务的工作流为输入,cloudseer为每个任务构建相应的自动机模型。通过任务自动机的匹配过程实现故障诊断。但cloudseer工作流提取限制在了串行的环境下,这使得其工作流在并行的环境下缺乏普适性。文献“基于工作流的云系统任务运行故障诊断方法与系统(cn110489317a)”提出了logchain,在cloudseer的基础上改进了工作流提取方法,使其适用于并行环境,并提出了一种基于相似性计算的工作流标记算法,解决现有工作在构建参照的过程中,存在的需要过多的人工干预或是对于构建的环境要求严苛的问题。以上工作均以“属于同一工作流的日志包含公共变量”为前提提取工作流,但云系统实际运行过程中,由于程序设计或系统配置等问题,部分同属于一个工作流的日志并不包含公共变量,或当前日志与此前的工作流日志序列不存在公共变量,但与此后的日志序列存在公共变量,从而导致工作流提取不完整的情况;以及在线诊断过程中,大量无关的背景日志数据会给诊断过程带来额外的开销。因此,如何构造一种适合云系统的在线故障诊断方法仍是云计算智能运维的一项挑战。
技术实现要素:
5.本发明的目的在于克服上述现有技术的不足,提供一种基于日志数据的云系统故障诊断方法,用以利用云系统中的日志数据,提取云系统中的工作流,并通过与参照工作流
自动机进行匹配,从而实现故障诊断,及时发现导致云系统运行故障的模块或原因,从而提高云系统的可靠性和稳定性。
6.本发明的目的至少通过如下技术方案之一实现。
7.一种基于日志数据的云系统故障诊断方法,包括以下步骤:
8.s1、分布式云系统包括多个节点,集合节点中各模块的日志,得到日志集合,对日志集合中的日志数据进行预处理,得到预处理后的日志数据,其中,日志集合中的每一条日志经过预处理转化成对应的由日志模板、时间戳和指纹集构成的元组;
9.s2、将预处理后的日志数据添加至缓存队列中,并按元组中的时间戳进行排序,获取队首日志作为当前日志,并从队列剩余日志中提取当前日志的额外指纹集;
10.s3、根据步骤s2中获取的当前日志及其额外指纹集,判断是否有与该当前日志匹配的待测工作流,若有,则将当前日志添加到匹配的待测工作流的末端,否则新建待测工作流,将该当前日志作为新建待测工作流的首条日志条目;
11.s4、通过多次运行指定的任务类型,得到多个属于相同任务类型的工作流,保留工作流中共有部分,得到具有任务类型标识的参照工作流,根据待测工作流和参照工作流的相似性,确定待测工作流所属的任务类型;
12.s5、为每个待测工作流构建其对应的有限状态自动机,合并拥有相同开始状态的有限状态自动机;
13.s6、根据步骤s1中获取的预处理后的日志数据,提取其中出现过的所有日志模板,对每个日志模板计算其词频-逆文件频率值,得到日志模板词频-逆文件频率字典;
14.s7、根据步骤s6获取的日志模板词频-逆文件频率字典,根据步骤s5的获取有限状态自动机,进行在线故障诊断,将实时输入的日志数据处理成由日志模板、时间戳和指纹集构成的日志元组,通过词频-逆文件频率字典决定丢弃或保留日志元组,保留的日志元组输入到后续的有限状态自动机进行匹配识别,从而完成故障的诊断和定位。
15.进一步地,步骤s1中,所述预处理指通过正则表达式从日志条目中获取符合相应匹配规则的日志组成部分,包括时间戳、日志模板和指纹集;
16.所述时间戳指日志生成时的系统时间;所述日志模板指日志内容中的非变量部分;所述指纹集指日志条目中一个或多个变量的集合。
17.进一步地,步骤s2中,预处理后的日志数据,每个日志条目生成一个由日志模板、指纹集和时间戳构成的元组;每个生成的元组添加至缓存队列中按元组的时间戳进行排序形成有序队列,直至队首和队尾的元组其时间戳间隔大于给定阈值;
18.获取队首日志元组作为当前日志元组,并搜索剩余缓存队列中与当前日志元组中的指纹集有公共元素的日志元组,获取搜索得到的日志元组的指纹集作为当前日志元组的额外指纹集,额外指纹集并入当前日志元组的指纹集中。
19.进一步地,步骤s3中,当前日志与待测工作流的匹配过程具体如下:
20.根据步骤s2中获取的当前日志的日志元组,若当前日志元组的指纹集与待测工作流的指纹集有公共元素,且待测工作流指纹集中的公共元素其更新时间与当前日志元组的时间戳具有最小时间间隔,则当前日志与待测工作流匹配。
21.进一步地,步骤s4包括以下步骤:
22.s4.1、注入指定类型故障并运行指定的任务类型,收集任务开始时间和结束时间
之间的时间窗口内的日志序列作为该类型任务的工作流,并为该工作流赋予故障和任务类型标签;
23.s4.2、已赋予故障和任务类型标签的工作流经过预处理、缓存排序以及工作流挖掘,过滤多余的背景日志,背景日志的指纹集与工作流中其他日志的指纹集不存在公共变量,得到具有任务类型标识的工作流日志模板序列,保留多个属于相同任务类型的工作流日志模板序列中的共有部分,得到参照工作流日志模板序列;
24.s4.3、根据步骤s3中获取的待测工作流日志序列,提取其中每条日志的日志模板,得到待测工作流日志模板序列,根据待测工作流日志模板序列和参照工作流日志模板序列的相似性,确定待测工作流的任务类型。
25.进一步地,步骤s4.3中待测工作流日志模板序列和参照工作流日志模板序列的相似性计算过程具体如下:
26.计算待测工作流日志模板序列和参照工作流日志模板序列中,公共元素的占比commrate,具体如下:
[0027][0028]
其中,ls_l表示待测工作流日志模板序列所包括的元素个数,rs_l表示参照工作流日志模板序列所包括的元素个数,l表示待测工作流日志模板序列和参照工作流日志模板序列中公共元素的个数;
[0029]
计算待测工作流日志模板序列与各个参照工作流日志模板序列之间的公共元素的占比commrate,获取公共元素的占比commrate大于给定阈值的参照工作流日志模板序列,得到多个相似参照工作流日志模板序列;
[0030]
通过计算待测工作流日志模板序列和相似参照工作流日志模板序列的最长公共子序列占比subseqrate,确定待测工作流的任务类型,具体如下:
[0031][0032]
其中,ls_l表示待测工作流日志模板序列所包括的元素个数,rs_l表示参照工作流日志模板序列所包括的元素个数,sub_l表示待测工作流日志模板序列和参照工作流日志模板序列的最长公共子序列中的元素个数;
[0033]
计算待测工作流日志模板序列与各个相似参照工作流日志模板序列之间的最长公共子序列占比subseqrate,获取最长公共子序列占比subseqrate值最大且大于给定阈值的相似参照工作流日志模板序列,根据该参照工作流的任务类型标识确定待测工作流的任务类型。
[0034]
进一步地,步骤s5中,根据获取的带标签的待测工作流日志模板序列,为每个待测工作流构建其对应的有限状态自动机,构建过程具体如下:
[0035]
为待测工作流中的第i条日志创建一个新状态,新状态与自动机最后一个状态增加一条唯一的连接边,该连接边的值为第i条日志的日志模板;
[0036]
合并拥有相同开始状态的自动机。
[0037]
进一步地,合并过程具体如下:
[0038]
选取两个拥有相同开始状态的自动机,同时对两个自动机进行遍历直至遇到状态不相等的分歧点,将其中一个自动机分歧点后的状态序列拼接到另一个自动机分歧点后。
[0039]
进一步地,步骤s6中,所述词频-逆文件频率值的计算过程如下:
[0040]
根据获取到的包括所有日志模板的日志模板集合,对于其中的日志模板j,其词频值计算具体如下:
[0041][0042]
其中,tfj为日志模板j的词频值,frequencyj为日志模板j在训练数据集中的出现次数,∑frequencyj为所有日志模板在训练数据集中的出现次数;
[0043]
对于日志模板j,其逆文件频率值计算具体如下:
[0044][0045]
其中,idfj为日志模板j的逆文件频率值,wfnum为待测工作流的数量,wflogtj为包括日志模板j的待测工作流的数量;
[0046]
对于日志模板j,其词频-逆文件频率值tfidfj计算具体如下:
[0047]
tfidfj=tfj·
idfj[0048]
(5)
[0049]
保存每个日志模板与其词频-逆文件频率值的对应关系,得到日志模板词频-逆文件频率值字典。
[0050]
进一步地,步骤s7具体包括以下步骤:
[0051]
s7.1、对于输入的实时日志数据,首先进行预处理将原始日志处理成包括时间戳、指纹集和日志模板的日志元组;
[0052]
s7.2、根据步骤s6中获取的日志模板词频-逆文件频率值字典,通过日志模板和词频-逆文件频率值的对应关系找到当前日志条目的日志模板的词频-逆文件频率值,若当前日志条目的日志模板的词频-逆文件频率值小于给定阈值,则将当前日志的日志元组输入到后续诊断步骤,否则,丢弃当前日志条目;
[0053]
s7.3、根据步骤s7.2中获取的当前日志的日志元组,将该日志元组添加至缓存队列中并按时间戳进行排序,当缓存队列增长至队尾与队首的日志元组其时间戳差值大于给定阈值时,获取队首日志元组作为当前日志元组,并从缓存队列剩余日志元组中获取当前日志元组的额外指纹集,添加到当前日志元组的指纹集中;
[0054]
s7.4、根据步骤s7.3中获取的当前日志元组,判断诊断自动机集合中是否存在一个自动机,该自动机当前状态到下一个状态的连接边的值与当前日志元组其日志模板相同,且该自动机的指纹集和当前日志元组其指纹集有公共元素,且自动机其指纹集中公共元素的更新时间与当前日志元组其指纹集中公共元素的时间戳具有最小时间间隔;若存在,则该自动机跳转到下一个状态,并且更新自动机的指纹集,否则,获取初始状态匹配当前日志元组其日志模板的自动机,添加到诊断状态机集合中;
[0055]
检查产生状态转移后的自动机是否到达最后一个状态,若自动机达到了最后一个状态,则输出该自动机的工作流故障和任务类型标签作为诊断结果,此时完成一次云系统
故障诊断。
[0056]
与现有技术相比,本发明具有如下的优点与技术成果:
[0057]
1、提供了一种通过日志额外变量进行工作流提取,能够过滤无关背景日志数据的基于日志数据的云系统故障诊断方法。此前的故障诊断方法依赖于当前日志自身的变量进行工作流提取,且在线诊断过程中无关的背景日志会输入到故障诊断算法中。
[0058]
2、所提出的通过日志额外公共变量进行工作流提取的方法,其基于局部性原理,缓存当前日志生成时间之后给定时间窗口内的日志数据,根据是否存在公共变量获取与当前日志属于同一工作流的日志序列,并提取其变量作为当前日志的额外变量,用于工作流提取。该方法能够解决实际云系统日志中,当前日志与此前工作流不存在公共变量导致的工作流提取不完整的问题。
[0059]
3、所提出的无关背景日志过滤方法,通过从训练集中获取的日志模板和其tf-idf值之间的对应关系,在在线故障诊断阶段通过查询输入的实时日志其日志模板的tf-idf值,并过滤不符合阈值要求的日志数据,从而实现无关背景日志的过滤,提高在线故障诊断的效率。
附图说明
[0060]
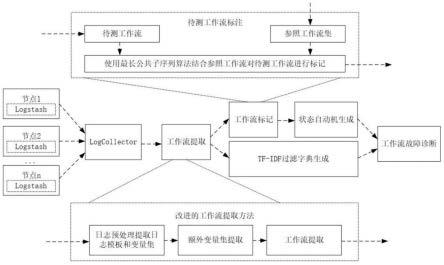
图1为本发明方法具体实施例中基于日志数据的云系统故障诊断方法的流程示意图。
[0061]
图2为本发明方法具体实施例中日志预处理示意图。
[0062]
图3为本发明方法具体实施例中额外指纹集提取算法图。
[0063]
图4为本发明方法具体实施例中当前日志与待测工作流匹配算法图。
具体实施方式
[0064]
为了使本发明的技术方案及优点更加清楚明白,以下结合附图,进行进一步的详细说明,但本发明的实施和保护不限于此。
[0065]
实施例:
[0066]
一种基于日志数据的云系统故障诊断方法,如图1所示,包括以下步骤:
[0067]
s1、分布式云系统包括多个节点,集合节点中各模块的日志,通过logstash等日志收集工具将分布在各个物理机上的云系统各服务模块产生的日志进行收集汇总,得到日志集合,对日志集合中的日志数据进行预处理,得到预处理后的日志数据,其中,日志集合中的每一条日志经过预处理转化成对应的由日志模板、时间戳和指纹集构成的元组;
[0068]
所述预处理指通过正则表达式从日志条目中获取符合相应匹配规则的日志组成部分,包括时间戳、日志模板和指纹集;
[0069]
如图2所示,所述时间戳指日志生成时的系统时间,由日期date和具体时分秒time组成;所述指纹集指日志条目中一个或多个变量的集合,如图2中所示的网络地址ip1、通用唯一识别码uuidi以及各种数字变量numi,都是日志条目中的变量,通过正则表达式算法从日志数据中提取生成指纹集;所述日志模板指日志内容中的非变量部分,为日志条目提取完变量后剩余的部分。
[0070]
s2、将预处理后的日志数据添加至缓存队列中,并按元组中的时间戳进行排序,获
取队首日志作为当前日志,并从队列剩余日志中提取当前日志的额外指纹集;
[0071]
预处理后的日志数据,每个日志条目生成一个由日志模板、指纹集和时间戳构成的元组;每个生成的元组添加至缓存队列中按元组的时间戳进行排序形成有序队列,直至队首和队尾的元组的时间戳间隔大于给定阈值;
[0072]
获取队首日志元组作为当前日志元组,并搜索剩余缓存队列中与当前日志元组中的指纹集有公共元素的日志元组,获取搜索得到的日志元组的指纹集作为当前日志元组的额外指纹集,额外指纹集并入当前日志元组的指纹集中。
[0073]
工作流提取过程中,最新获取的日志条目会首先添加到缓存队列中,并按日志条目中的时间戳进行排序形成有序队列,直至缓存队列增长至队首和队尾日志条目其时间戳差值大于给定阈值,此时获取队首日志条目作为当前日志条目进行待测工作流匹配;
[0074]
在进行待测工作流匹配之前,首先提取当前日志条目的额外指纹集,其具体过程如图3所示:额外指纹集extrafins初始为空集,对于日志条目log
curr
提取其指纹集fins
curr
,对于缓存队列logbuffer中的每个日志条目log提取其指纹集fins,若fins与fins
curr
存在交集,即commonsize(fins
curr
,fins)》0,则将fins合并到extrafins中,直至遍历完缓存队列logbuffer中的每一个元素。
[0075]
s3、根据步骤s2中获取的当前日志及其额外指纹集,判断是否有与该当前日志匹配的待测工作流,若有,则将当前日志添加到匹配的待测工作流的末端,否则新建待测工作流,将该当前日志作为新建待测工作流的首条日志条目;
[0076]
当前日志与待测工作流的匹配过程具体如下:
[0077]
根据步骤s2中获取的当前日志的日志元组,若当前日志元组的指纹集与待测工作流的指纹集有公共元素,且待测工作流指纹集中的公共元素其更新时间与当前日志元组的时间戳具有最小时间间隔,则当前日志与待测工作流匹配。
[0078]
如图4所示,提取当前日志条目的额外指纹集并添加至其指纹集后,根据更新的指纹集和时间戳为当前日志条目匹配待测工作流,具体过程为:对于待测工作流集合wfs中的每个待测工作流wf,获取其指纹集wfingp,判断wfingp与当前日志条目的指纹集fingp是否存在交集,若不存在,则继续遍历待测工作流集合的下一个元素,若存在,即commonsize(wfingp,fingp)》0,则获取wfingp和fingp中的元素其最小时间间隔min_tmp,若min_tmp小于当前最小时间间隔interval
min
,则将interval
min
设置为min_tmp,目标待测工作流target设置为当前待测工作流wf。
[0079]
若存在最匹配的待测工作流,即target不为null,则将当前日志条目其日志模板添加到最匹配待测工作流其日志队列尾部,并将当前日志条目其指纹集合并到待测工作流的指纹集中,更新指纹集中相应的变量其时间戳为当前日志条目的时间戳;
[0080]
若不存在最匹配的待测工作流,即target等于null,则新构建一个待测工作流,该待测工作流其日志队列第一条日志为当前日志条目其日志模板,待测工作流其指纹集为当前日志条目其指纹集,指纹集中相应变量的时间戳为当前日志条目的时间戳,并将该新构建待测工作流添加至待测工作流集合中。
[0081]
s4、通过多次运行指定的任务类型,得到多个属于相同任务类型的工作流,保留工作流中共有部分,得到具有任务类型标识的参照工作流,根据待测工作流和参照工作流的相似性,确定待测工作流所属的任务类型,包括以下步骤:
[0082]
s4.1、注入指定类型故障并运行指定的任务类型,收集任务开始时间和结束时间之间的时间窗口内的日志序列作为该类型任务的工作流,并为该工作流赋予故障和任务类型标签;
[0083]
s4.2、已赋予故障和任务类型标签的工作流经过预处理、缓存排序以及工作流挖掘,过滤多余的背景日志,背景日志的指纹集与工作流中其他日志的指纹集不存在公共变量,得到具有任务类型标识的工作流日志模板序列,保留多个属于相同任务类型的工作流日志模板序列中的共有部分,得到参照工作流日志模板序列;
[0084]
s4.3、根据步骤s3中获取的待测工作流日志序列,提取其中每条日志的日志模板,得到待测工作流日志模板序列,根据待测工作流日志模板序列和参照工作流日志模板序列的相似性,确定待测工作流的任务类型,具体如下:
[0085]
计算待测工作流日志模板序列和参照工作流日志模板序列中,公共元素的占比commrate,具体如下:
[0086][0087]
其中,ls_l表示待测工作流日志模板序列所包括的元素个数,rs_l表示参照工作流日志模板序列所包括的元素个数,l表示待测工作流日志模板序列和参照工作流日志模板序列中公共元素的个数;
[0088]
计算待测工作流日志模板序列与各个参照工作流日志模板序列之间的公共元素的占比commrate,获取公共元素的占比commrate大于给定阈值的参照工作流日志模板序列,得到多个相似参照工作流日志模板序列;
[0089]
通过计算待测工作流日志模板序列和相似参照工作流日志模板序列的最长公共子序列占比subseqrate,确定待测工作流的任务类型,具体如下:
[0090][0091]
其中,ls_l表示待测工作流日志模板序列所包括的元素个数,rs_l表示参照工作流日志模板序列所包括的元素个数,sub_l表示待测工作流日志模板序列和参照工作流日志模板序列的最长公共子序列中的元素个数;
[0092]
计算待测工作流日志模板序列与各个相似参照工作流日志模板序列之间的最长公共子序列占比subseqrate,获取最长公共子序列占比subseqrate值最大且大于给定阈值的相似参照工作流日志模板序列,根据该参照工作流的任务类型标识确定待测工作流的任务类型。
[0093]
s5、为每个待测工作流构建其对应的有限状态自动机,合并拥有相同开始状态的有限状态自动机;
[0094]
根据获取的带标签的待测工作流日志模板序列,为每个待测工作流构建其对应的有限状态自动机,构建过程具体如下:
[0095]
为待测工作流中的第i条日志创建一个新状态,新状态与自动机最后一个状态增加一条唯一的连接边,该连接边的值为第i条日志的日志模板;
[0096]
合并拥有相同开始状态的自动机,合并过程具体如下:
[0097]
选取两个拥有相同开始状态的自动机,同时对两个自动机进行遍历直至遇到状态不相等的分歧点,将其中一个自动机分歧点后的状态序列拼接到另一个自动机分歧点后。
[0098]
s6、根据步骤s1中获取的预处理后的日志数据,提取其中出现过的所有日志模板,对每个日志模板计算其词频-逆文件频率值,得到日志模板词频-逆文件频率值字典;
[0099]
所述词频-逆文件频率值的计算过程如下:
[0100]
根据获取到的包含所有日志模板的日志模板集合,对于其中的日志模板j,,其词频值计算具体如下:
[0101][0102]
其中,tfj为日志模板j的词频值,frequencyj为日志模板j在训练数据集中的出现次数,∑frequencyj为所有日志模板在训练数据集中的出现次数;
[0103]
对于日志模板j,其逆文件频率值计算具体如下:
[0104][0105]
其中,idfj为日志模板j的逆文件频率值,wfnum为待测工作流的数量,wflogtj为包括日志模板j的待测工作流的数量;
[0106]
对于日志模板j,其词频-逆文件频率值tfidfj计算具体如下:
[0107]
tfidfj=tfj·
idfj[0108]
(5)
[0109]
保存每个日志模板与其词频-逆文件频率值的对应关系,得到日志模板词频-逆文件频率值字典。
[0110]
s7、根据步骤s6获取的日志模板词频-逆文件频率字典,根据步骤s5获取的有限状态自动机,进行在线故障诊断,将实时输入的日志数据处理成由日志模板、时间戳和指纹集构成的日志元组,通过词频-逆文件频率字典决定丢弃或保留日志元组,保留的日志元组输入到后续的有限状态自动机进行匹配识别,从而完成故障的诊断和定位,如图1所示,具体包括以下步骤:
[0111]
s7.1、对于输入的实时日志数据,首先进行预处理将原始日志处理成包括时间戳、指纹集和日志模板的日志元组;
[0112]
s7.2、根据步骤s6中获取的日志模板词频-逆文件频率值字典,通过日志模板和词频-逆文件频率值的对应关系找到当前日志条目的日志模板的词频-逆文件频率值,若当前日志条目的日志模板的词频-逆文件频率值小于给定阈值,则将当前日志的日志元组输入到后续诊断步骤,否则,丢弃当前日志条目;
[0113]
s7.3、根据步骤s7.2中获取的当前日志的日志元组,将该日志元组添加至缓存队列中并按时间戳进行排序,当缓存队列增长至队尾与队首的日志元组其时间戳差值大于给定阈值时,获取队首日志元组作为当前日志元组,并从缓存队列剩余日志元组中获取当前日志元组的额外指纹集,添加到当前日志元组的指纹集中;
[0114]
s7.4、根据步骤s7.3中获取的当前日志元组,判断诊断自动机集合中是否存在一个自动机,该自动机当前状态到下一个状态的连接边的值与当前日志元组其日志模板相
同,且该自动机的指纹集和当前日志元组其指纹集有公共元素,且自动机其指纹集中公共元素的更新时间与当前日志元组其指纹集中公共元素的时间戳具有最小时间间隔;若存在,则该自动机跳转到下一个状态,并且更新自动机的指纹集,否则,获取初始状态匹配当前日志元组其日志模板的自动机,添加到诊断状态机集合中;
[0115]
本实施例中,诊断过程具体为:
[0116]
遍历当前的待测自动机集合,查找能接受当前日志条目其日志模板并进行状态迁移的待测自动机,将其添加到待匹配自动机集合中;自动机可以接受当前日志条目其日志模板,并从状态a跳转到状态b,当且仅当状态a到状态b所代表的迁移边其代表的日志模板与当前日志条目其日志模板相同;
[0117]
遍历待匹配自动机集合得到最匹配自动机,该最佳匹配自动机其指纹集和当前日志条目其指纹集有公共元素,且自动机其指纹集中公共元素的更新时间与当前日志元组其指纹集中公共元素的时间戳差值最小;若存在最佳匹配自动机,则该自动机跳转到下一个状态,并且更新自动机的指纹集以及相应变量的时间戳,否则,从工作流自动机集合中获取新的待测自动机,该自动机的初始状态能接受当前日志条目其日志模板并进行状态迁移,将当前日志条目其指纹集添加到新待测自动机指纹集中,新待测自动机指纹集中的相应变量更新为当前日志条目其时间戳,并将新待测自动机添加到待测自动机集合中;
[0118]
检查产生状态转移后的自动机是否到达最后一个状态,若自动机达到了最后一个状态,则输出该自动机的工作流故障和任务类型标签作为诊断结果,此时完成一次云系统故障诊断。
[0119]
本实施例中,本发明在开源的云操作系统openstack上进行了实验。实验通过将云系统openstack的各个部署在拥有5台服务器的集群上,通过脚本模拟用户请求生成负载,同时通过脚本控制故障注入模拟云系统故障场景,再通过logstash日志收集工具对分布在各个服务器上的各系统服务模块产生的日志数据进行采集。使用正则表达式对日志数据进行预处理,提取其时间戳、变量集合以及日志模板等信息,预处理后的日志数据通过工作流提取、工作流标记、工作流自动机生成以及过滤字典提取等步骤,生成可用于在线故障诊断的过滤字典和工作流诊断自动机集合。通过工作流诊断自动机匹配当前实时日志数据中存在的工作流,根据匹配到的工作流自动机的标识,来表明云系统是否存在故障,以及故障的类型。
[0120]
实施例2:
[0121]
相比于实施例1,本实施例在开源数据集hdfs上进行了实验。hdfs数据集通过在私有云系统上运行标准工作负载生成,并人工标记异常数据。实验将hdfs数据集分成训练集和验证集,其中训练集用于诊断方法模型的训练,验证集用于诊断方法模型的精度验证。本实施例在开源数据集hdfs上实现了较好的故障诊断精度。
[0122]
实施例3:
[0123]
相比于实施例1,本实施例在开源数据集hadoop上进行了实验。hadoop数据集从hadoop集群中产生,该hadoop集群分布在5台服务器主机上,通过运行wordcount和pagerank模拟任务负载,通过故障注入模拟生产环境中的服务故障。与实施例2类似,本实施例将hadoop数据集划分成训练集和验证集,并在hadoop数据集上实现了较好的故障诊断精度。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。