1.本发明涉及生物信息的数据处理与分析领域,具体是一种通用的生物序列顺式作用调控元件在线预测网站构建方法。
背景技术:
2.随着人工智能技术的不断发展,越来越多的机器学习算法和模型被提出,并且能够成功应用于多个领域。特别地,在当前各学科高度交叉与融合的发展趋势下,尤其对生物信息学,科研人员构建了大量的预测模型,以便推动各类研究问题的发展。例如,在生物研究领域中,科学家通过对基因组数据进行注释以完善基因的结构信息,或者对一些特定的蛋白质进行预测以探索细菌、病毒等致病机理。尽管大量的预测模型已经被构建出来,但它们却很少能够发挥实际的应用价值,原因在于这些论文模型对于普通的从业人员而言较难应用;另一方面,随着计算机不断涌入人们的生活和工作中,大量的网站被构建出来,满足人们的各种需要。
3.因此,构建用户友好且简单易用的在线预测网站,能尽可能地发挥论文模型的实用性。
技术实现要素:
4.基于上述现有技术中指出的问题,本发明提供了一种基于生物序列顺式作用调控元件的在线预测网站构建方法,该方法针对生物序列,并利用网站设计的多项技术,提高论文模型的可用性。
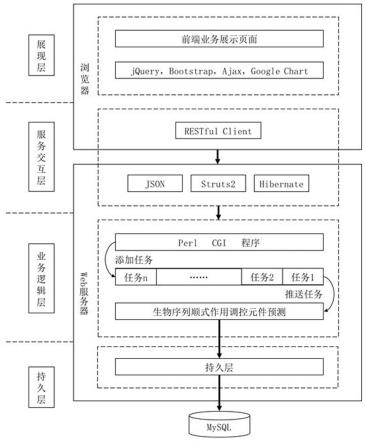
5.实现本发明目的的技术方案是:基于生物序列顺式作用调控元件的在线预测网站构建方法,包括:(1)数据预处理:根据模型对输入数据文件进行预处理;(2)构建网站主体展现层:根据网站的具体应用场景和用户原型,进行各前端页面的ui设计;(3)构建网站主体服务交互层:通过java数据端与前端页面进行数据交互,并将用户提交的请求任务传递到perl计算端,利用struts2框架,将步骤(2)构建的前端页面与java数据端进行连接,将预处理的数据封装成json格式传递至perl计算端;同时,利用hibernate框架将java数据端的dao层变量与数据库字段进行映射,将java端数据库的活动连接进行封装,将数据模型转换成存储模型,进行数据持久化;(4)构建网站主体业务逻辑层:通过java数据端对前端页面提交的数据进行处理后,调用perl脚本,利用机器学习模型进行顺式作用调控元件的预测;采用分布式任务分发框架gearman进行任务调度,当接收到步骤(3)中java数据端传递过来的请求任务后,gearman将数据添加到任务池中,依次执行;当提交的请求任务数量超过worker值时,多出的任务进行等待区,直到执行中的某个任务结束时才开启计算;(5)构建网站主体持久层:当步骤(4)的业务逻辑层执行完成计算任务时,将预测
结果写入mysql数据库中,为结果输出做准备;(6)输出预测结果:java数据端从数据库中获取数据,并在前端页面显示。
6.进一步的,步骤(1)所述数据文件包括fasta和fastq两种格式,用于存储dna、rna和蛋白质序列。
7.进一步的,步骤(2)所述前端页面的ui设计包括页面的整体风格、页面元素、操作控件以及用户指引等。
8.本发明的有益效果是:通过对常见的测序数据文件进行处理,借助主流的b/s(浏览器和服务器)架构模式开发技术,将传统机器学习或深度学习训练出的模型构建成用户友好且简单易用的在线预测网站,提高论文模型的可用性,从而服务相关领域从业人员的研究工作。
附图说明
9.图1为本发明实施例在线预测网站构建模型图。
具体实施方式
10.下面结合附图和实施例对本发明作进一步的阐述,但不是对本发明内容的限定。
11.实施例:一种通用的生物序列顺式作用调控元件在线预测网站构建方法,包括以下三大部分:1)数据预处理:常见的测序文件格式包括fasta和fastq两种格式,二者区别在于后者比前者多了测序质量。在该部分里,需要根据模型对输入数据的要求进行必要的预处理工作。如:对于dna和rna序列,可以采用4位的one-hot编码方式,则长度为n的序列将被编码为n
×
4的二维矩阵;对于蛋白质序列,可能还需要选择合适的编码方式;2)网站主体分为展现层、服务交互层、业务逻辑层和持久层,如图1所示。每一层的构建,包括如下步骤:展现层:2-1):根据网站的具体应用场景和用户原型,进行各前端页面的ui设计,包括整体风格、页面元素、操作控件以及用户指引等。该步骤中需要涉及到jquery,bootstrap,ajax和google chart等多项技术框架。如:对于一个rna剪接位点预测网站,其前端页面可能包含数据导入按钮(fasta文件)或长文本框(序列片段),还可能因为多物种预测模型的需要而有选择列表(多物种及供、受体),以及根据用户是否可自定义预测阈值而添加数值输入框。此外,还可以设计模型介绍、用户帮助以及数据下载等页面,提高网站的可用性;服务交互层:2-2):java数据端负责与前端页面进行数据交互,并将用户提交的请求任务传递到perl计算端。该步骤中使用struts2框架将步骤2-1)中的前端页面与java数据端进行连接,将预处理的数据封装成json格式传递到perl计算端。此外,利用hibernate框架将java数据端的dao(data access object,数据访问对象)层变量与数据库字段进行映射,对java端数据库的活动连接进行封装,方便增删改查等功能的实现。基于hibernate框架,mysql数据库能够将数据模型转换为存储模型,进行数据持久化。以linux的ubuntu操作系统为例,
该过程的环境搭建具体步骤为:s01:java安装在oracle官网下载兼容版本的jdk(java development kit,java软件开发工具包),解压到系统的/usr/lib/jvm/路径下,修改~/.bashrc文件,配置java环境变量;s02:tomcat的安装tomcat是一款免费的web服务器软件,可执行sudo apt-get install tomcatx命令安装,其中x表示tomcat的版本号。安装完成后根据预期的网站访问量,修改配置文件的内存分配量;s03:php和apache的安装二者安装顺序必须是先php后apache,分别执行sudo apt-get install phpx和sudo apt-get install apachey命令安装php和apache,其中x和y分别表示php和apache的版本号;s04:设置apache反向代理执行sudo vim /etc/apache2/apache2.conf命令修改重定向信息,随后执行sudo a2enmod proxy_http命令保证修改信息生效;s05:mysql数据库的安装执行sudo apt-get install mysql-server命令安装,根据需要修改数据库的登录密码;s06:phpmyadmin的安装执行sudo apt-get install phpmyadmin命令安装;业务逻辑层:2-3):java端对前端页面提交的数据进行处理后,调用perl脚本,利用机器学习模型进行顺式作用调控元件的预测。该步骤通常对资源和时间消耗巨大,为了保证预测网站能够在多个任务提交的情况下保证服务器的负载均衡,该层中采用分布式任务分发框架gearman进行任务调度。当接收到步骤2-2)中java端传递过来的请求任务之后,gearman将它们添加到任务池中,依次执行。此外,服务器可以设置worker进程数量,即同时处理的计算任务数量。当提交的请求任务数量超过worker值时,多出的任务进入等待区,直到执行中的某个任务结束时才开启计算。以linux的ubuntu操作系统为例,该过程的环境搭建具体步骤为:s01:设置apache cgi执行sudo cpan命令打开cpan(comprehensive perl archive network,perl综合档案网或perl程序库),然后执行install cgi安装cgi(common gateway interface,通用网关接口)模块,而后修改cgi程序的根目录,通过执行sudo vim /etc/apache2/apache2.conf命令进行修改,随后进行页面测试;s02:perl相关模块安装在cpan下安装三个模块:install storableinstall dbiinstall io::all
执行命令:sudo apt-get install libgd-devsudo apt-get install libxml-xpath-perl在cpan下安装八个模块:install bio::seqioinstall bio::seqinstall capture::tinyinstall soap::transport::httpinstall mime::liteinstall mail::sendmailinstall email::mimeinstall email::sender::simples03:gearman消息队列安装先安装以下的gearman依赖包:sudo apt-get install libboost-devsudo apt-get install libboost-all-devsudo apt-get install gperfsudo apt-get install libevent-devsudo apt-get install uuid-devsudo apt-get install libssl-dev下载并安装gearman:cd ~wget https://launchpad.net/gearmand/1.2/1.1.12/ download/gearmand-1.1.12.tar.gztar zxvf gearmand-1.1.12.tar.gzcd gearmand-1.1.12/sudo make clean./configuresudo makesudo make install下载并安装gearman的job server:sudo apt-get install gearman-job-server在cpan下安装三个模块:install net::ssleayinstall io::socket::sslinstall gearman::utils04:安装perl连接mysql的模块sudo cpaninstall dbd::mysql
s05:python相关安装sudo apt-get install python-scipysudo apt-get install python-devsudo apt-get install python-numpysudo apt-get install python-matplotlibsudo apt-get install python-pandassudo apt-get install python-sklearns06:r语言安装sudo apt-get install r-basesudo r持久层:2-4):当业务逻辑层步骤2-3)中有计算任务执行完成时,预测结果被写入mysql数据库中,为结果输出做准备;3)预测结果输出:java数据端从数据库获取数据并在前端显示。如:对于一个rna剪接位点预测网站,如果模型用于预测经典的剪接位点(供体为gt,受体为ag),其输出结果应给出有效序列区域内特征位点的预测值,用户可根据自定义的阈值进行筛选。
12.以上所述仅是本发明的优选实施方式,应当理解本发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
