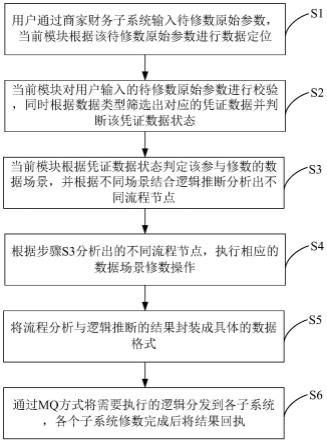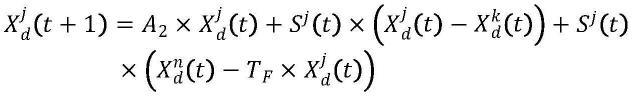
1.本发明涉及一种进化优化算法,特别是处理高维优化问题。
背景技术:
2.进化算法在解决不同类型的基准测试和工程优化问题中有着广泛的应用。一些实际问题有着大量的决策变量,这些问题被称为高维问题。解决它们的难度随决策变量的增大而指数级增长,传统的进化算法不能很好的解决高维问题因为这些策略无法很好的覆盖高维搜索空间。此外,在高维问题中适应度评价需要耗费很多计算资源。因此,传统进化算法通常需要大量的计算资源以产生令人满意的解。
3.在面对高维问题时,一般有两种解决办法。第一种是对高维的搜索空间进行降维,在低维的搜索空间中进化算法有较好的寻优表现。但将搜索空间压缩会丢失部分地形信息,若压缩不当则会影响最终寻优结果的准确性。第二种方法是使用代理模型,代理模型替代了部分的真实模型对个体进行适应度评价以节省计算资源,这些节省的计算资源可以供进化算法继续寻优。但引入代理模型同时也引入了额外的模型训练时间,这会增加额外的计算负担。此外,不精准的代理模型会使个体的适应度评价有较大误差,这会误导寻优方向。基于以上想法,将二者结合会使进化算法在高维问题中有更好的表现。
技术实现要素:
4.针对以上现有技术的不足,本发明提供一种sae和irbf辅助的stlbo以解决高维优化问题。该框架将总种群分成两个子种群并列的进行个体进化,其中子种群由sae 辅助以在低维空间中更快的找到有希望的区域。另一个子种群在高维空间中正常迭代(可能被irbf辅助)。在每次迭代后两个子种群最终合并为一个总种群进行下一次迭代。
附图说明
5.图1 stora方法组成示意图;
6.图2 sae结构示意图;
7.图3 irbf构建过程示意图;
8.图4 stora框架示意图。
具体实施方式
9.下面将详细描述本发明各个方面的特征和示例性实施例。下面的描述涵盖了许多具体细节,以便提供对本发明的全面理解。但是,对于本领域技术人员来说显而易见的是,本发明可以在不需要这些具体细节中的一些细节的情况下实施。下面对实施例的描述仅仅是为了通过示出本发明的示例来提供对本发明更清楚的理解。本发明绝不限于下面所提出的任何具体配置和算法,而是在不脱离本发明的精神的前提下覆盖了相关元素、部件和算
法的任何修改、替换和改进。
10.1.stlbo,其具体改进如下:
11.1)教学因子tf根据迭代次数进行动态调整。具体来说,tf会随着迭代线性减少,在算法的早期,tf会被赋予一个更大的值,以增强搜索能力。相反,为了在后期获得高精度的解,会降低tf的值,以提高其探索能力。tf将具体调整如下:
[0012][0013]
公式中,表示stlbo最大迭代次数,t1表示当前迭代次数。
[0014]
2)学生会根据自己当前的知识水平向老师调整学习进度。当学习者与教师之间的水平差距较大时,学习者在学习后会取得较大的进步。当学习者水平与其教师接近时,进步就会慢下来。学习者步长定义如下:
[0015][0016]
公式中,xn(t)表示第t次迭代的教师,xj(t)表示第t次迭代的第j个个体。n表示种群大小。
[0017]
3)学习者在学习过程中所学到的知识有部分是错误的,如果学习者完全相信所掌握的知识是正确的,则算法的寻优方向会被影响且容易陷入局部最优,因此引入学习掌握因子(a)来解决这一问题。学习者是否掌握该知识由a来控制。在教与学阶段,a会有两个不同的值a1和a2。而且a1比a2大,因为老师传授的知识的准确性要高于学生间相互学习到的知识准确性。
[0018]
4)教师的知识水平是非常重要的,因为其他学习者会不断靠近教师。一旦教师(当前最佳解)陷入局部最优,其他解也很容易陷入局部最优。因此,在优化过程的中后期,对教师进行扰动,以防止其陷入局部最优。对教师扰动定义如下:
[0019][0020]
公式中表示教师在第t次迭代的第d维,同理表示第r个个体在第t 次迭代的第d维。
[0021]
5)在学习阶段,学习者除了互相学习之外,还可以通过老师的建议进行学习。这样学习者就会在同伴和老师的指导下共同进步,从而进一步加快优化速度。因此,在学习阶段给出两个个体xj和xk,若个体j的适应度好于个体k的则更新如下:
[0022][0023]
否则,更新如下:
[0024][0025]
1.参照附图2描述sae使用原因及其结构。
[0026]
采用自编码器将高维空间压缩以加快进化算法的寻优速度。随着训练自编码器的数据在不断靠近全局最优,训练后的自编码器可以提取到重要的地形信息以对搜索空间进行压缩降维。sae是一种通过抑制隐藏层神经元来达到稀疏效果的自编码器。由于该问题的训练数据为种群在决策空间中的位置信息,且数据量较大。因此通过抑制部分隐藏层神经元对大量样本进行特征提取具有较好的性能。通过这种方式,可以对搜索空间进行降维。sae的损失函数如下:
[0027][0028]
公式中q表示表示训练sae的样本点个数。第一项是平均平方和误差,其描述训练数据的差异。第二项是正则化项,其中λ是权系数。第三项是稀疏惩罚项,其中ρ是稀疏参数,一般接近于零。β是[0,1]中的一个随机数,用来控制稀疏惩罚的权重。h是隐藏神经元的数量。表示所有隐藏层神经元的平均激活值。为了保证稀疏性,它向ρ靠近。kl 表示两个不同分布的kl散度,如果则
[0029]
2.参照附图3描述irbf改进原因及具体构造步骤。
[0030]
传统代理模型在大量高维训练数据训练时有较长的训练时间,这会极大的浪费计算资源并使其失去使用意义。此外,过于复杂的网络结构会使模型出现过拟合现象导致降低其预测准确性,irbf利用k均值聚类(k-means)算法将训练数据聚类以减少irbf基函数中心点数量,这会使网络结构简化以减少其训练时间。此外聚类后的基函数中心位于输入数据的重要区域,这会增强神经网络的预测能力。但是k-means聚类的结果易受到其初始中心点的影响,本发明利用遗传学习粒子群算法(glpso)以确定k-means初始中心点。irbf具体构造步骤如下:
[0031]
1)将irbf激活前所积累的个体位置信息作为初始化种群并执行glpso迭代次。
[0032]
2)将glpso的全局最优结果作为k-means的初始聚类中心。
[0033]
3)执行k-means并在次迭代后得到最终聚类结果。
[0034]
4)将聚类结果作为基函数中心并构造rbf模型。
[0035]
将glpso简介如下:
[0036]
该算法通过串联的方式将粒子群算法(pso)与遗传算法(ga)相结合,其避免了 ga的过早收敛,并且提高了pso的探索能力。由于ga的选择操作,存活的粒子质量较高。它们可以对其他粒子的搜索进行引导,提高粒子群的搜索速度。另一方面,pso的搜索经验为ga提供了有用的地形信息,这将有助于ga进一步产生更好的解。
[0037]
给定两个粒子pi和pk,如果pi的适应度评价好于pk,则ga操作的后代更新如下:
[0038]oi,d
=rd×
p
i,d
(1-rd)
×
gd[0039]
否则更新如下:o
i,d
=p
k,d
[0040]
公式中p
i,d
表示粒子i的局部最优解的d维,gd表示全局最优解的d维。
[0041]
pso操作中后代的速度和位置更新如下:
[0042]vi,d
=ω
×vi,d
c
×
rd×
(e
i,d-x
i,d
)
[0043]
x
i,d
=x
i,d
v
i,d
[0044]
公式中ω表示惯性权重,c表示加速系数。
[0045]
3.参照附图4描述stora具体步骤。
[0046]
1)在算法开始时,种群在决策空间中随机初始化,然后通过stlbo进行次迭代以收集足够的数据样本进行sae训练。一旦迭代次数达到就会根据累积的数据构造 sae。之后根据种群动态分配策略将种群分为两个子种群p1和p2。因此,种群以并行的方式进行协同进化以确保种群多样性,其中p1由sae辅助以快速找到有希望的区域,p2在原始空间中由stlbo(可能在irbf辅助下)进化。种群的多样性有助于算法跳出局部最优,这对优化过程至关重要。
[0047]
2)在sae辅助stlbo的过程中,经过训练的sae会先将p1编码到一个更低维的空间,而后stlbo在此空间中生成后代。个体在相对低维的空间中更有可能找到有优秀的后代,从而加快优化的速度。由于维数不匹配,低维空间无法进行适应度评价。经过sae的解码阶后,种群处于原始空间,种群可以进行适应度评价。最后,选择新的子种群作为p1并更新到下一代。在irbf辅助stlbo的过程中,为了保证代理模型的准确性,irbf的训练只有在收集到足够的样本后才会被激活。在此之前,产生后代的位置和相对应的适应度值存储在数据库中。一旦满足激活条件,就会用此数据库中数据对irbf进行训练。在接下来的优化过程中,训练后的irbf将用于预筛选个体。其中,stlbo生成的后代位置作为irbf的输入,irbf将输出这些个体的预测适应度值。但是为了保证结果的准确性,仍然需要选择一些个体进行真实的适应度评价。在stora中,个体将根据其预测适应度值进行排序,前m个个体会进行真实的适应度评价,因为预测适应度值好的个体,其有更高概率继续进化得到好的个体。整个过程结束后,选择新的子种群作为p2并更新到下一代。p1和p2将合并为一个种群p并进行下一次迭代。整个过程将不断重复直到算法迭代到次。
[0048]
4.种群动态分配策略
[0049]
该策略将种群按个体适应度值和迭代次数动态分配给各个子种群。在算法前期,希望快速定位到有希望的区域,因此重点放在空间的搜索上上,利用sae辅助的子种群p1在低维空间中更有利于实现上述目标。因此,p1在开始时应该分配给更多的个体。此外,随着有区域的逐步探索,进一步压缩到低维空间可能会丢失重要的区域信息而影响优化精度。因此p2应分配更多个体。最后,个体会根据适应度值进行排序,较差的个体被分配到p1,因为他们在高维环境下很难向有希望的方向进化。相反,可能有更高的可能性在低维的空间中产生更好的后代。种群动态调整如下:
[0050][0051]
p2=p-p1。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。