1.本发明涉及人工智能技术领域,具体涉及一种文字识别方法、装置及设备。
背景技术:
2.文字识别,是利用计算机自动识别字符的技术,是人工智能的一个重要领域。人们在生产和生活中,要处理大量的文字。通过文字识别技术,可以减轻人们的劳动,提高处理效率。
3.目前的文字识别算法一般直接根据文字图片,经过卷积神经网络等模型进行分类,并且卷积神经网络等模型一般采用分类的损失函数。如果仅含有分类的损失函数,卷积神经网络等模型容易关注文字的局部信息,在训练样本较少的时候容易出现过拟合的问题,从而导致文字识别的准确度较低。
技术实现要素:
4.本发明实施例提供一种文字识别方法、装置及设备,用以提高文字识别的准确度。
5.根据第一方面,一种实施例中提供一种文字识别方法,所述方法包括:
6.获取待识别的单个文字的图片;
7.将所述图片输入至预先训练好的目标识别模型中,得到所述待识别的单个文字与文字库中的各个文字的相似度;
8.将所述待识别的单个文字确定为最大相似度所对应的文字;
9.其中,训练所述目标识别模型,包括:
10.获取多个样本图片,其中,每个样本图片包括单个文字;
11.将所述每个样本图片输入至初始识别模型中,得到所述每个样本图片包括的单个文字的第一特征向量;
12.通过余弦距离公式,根据所述第一特征向量,计算任意两个所述单个文字的相似度,并对得到的多个相似度进行求和运算,得到第一字形相似度信息;
13.通过预设算法得到第二字形相似度信息,并根据所述第一字形相似度信息和所述第二字形相似度信息,得到相似度损失;
14.根据所述相似度损失和分类损失,确定组合损失,其中,所述分类损失通过预设分类损失函数得到;
15.根据所述组合损失,对所述初始识别模型的参数进行调整,以得到更新的识别模型;
16.针对所述更新的识别模型,迭代上述训练过程,直至所述组合损失小于第一预设阈值或者迭代次数大于预设训练迭代次数,并将所述组合损失小于第一预设阈值或者迭代次数大于预设训练迭代次数所对应的识别模型作为所述目标识别模型。
17.可选的,所述通过预设算法得到第二字形相似度信息,包括:
18.分别将任意两个样本图片缩放至预设尺寸;
19.分别对缩放后的样本图片进行划分,得到每个样本图片包括的单个文字的第二特征向量;
20.通过余弦距离公式,根据所述第二特征向量,计算任意两个所述单个文字的相似度,并对得到的多个相似度进行求和运算,得到第二字形相似度信息。
21.可选的,在所述分别将任意两个样本图片缩放至预设尺寸之前,所述方法还包括:
22.分别对任一样本图片进行裁切,以使所述单个文字与裁切后的样本图片边框的距离小于第二预设阈值。
23.可选的,所述相似度损失通过下述公式得到:
[0024][0025]
其中,n为样本图片的数量,loss_sim为所述相似度损失,sim
gt
为所述第二字形相似度信息,sim_pd为所述第一字形相似度信息。
[0026]
可选的,所述组合损失通过下述公式得到:
[0027][0028]
其中,loss为所述组合损失,loss_cls为所述分类损失。
[0029]
可选的,所述预设分类损失函数为交叉熵损失函数。
[0030]
根据第二方面,一种实施例中提供一种文字识别装置,所述装置包括:
[0031]
第一获取模块,用于获取待识别的单个文字的图片;
[0032]
第二获取模块,用于将所述图片输入至预先训练好的目标识别模型中,得到所述待识别的单个文字与文字库中的各个文字的相似度;
[0033]
确定模块,用于将所述待识别的单个文字确定为最大相似度所对应的文字;
[0034]
训练模块,用于获取多个样本图片,其中,每个样本图片包括单个文字;将所述每个样本图片输入至初始识别模型中,得到所述每个样本图片包括的单个文字的第一特征向量;通过余弦距离公式,根据所述第一特征向量,计算任意两个所述单个文字的相似度,并对得到的多个相似度进行求和运算,得到第一字形相似度信息;通过预设算法得到第二字形相似度信息,并根据所述第一字形相似度信息和所述第二字形相似度信息,得到相似度损失;根据所述相似度损失和分类损失,确定组合损失,其中,所述分类损失通过预设分类损失函数得到;根据所述组合损失,对所述初始识别模型的参数进行调整,以得到更新的识别模型;针对所述更新的识别模型,迭代上述训练过程,直至所述组合损失小于第一预设阈值或者迭代次数大于预设训练迭代次数,并将所述组合损失小于第一预设阈值或者迭代次数大于预设训练迭代次数所对应的识别模型作为所述目标识别模型。
[0035]
可选的,所述训练模块,具体用于分别将任意两个样本图片缩放至预设尺寸;分别对缩放后的样本图片进行划分,得到每个样本图片包括的单个文字的第二特征向量;通过余弦距离公式,根据所述第二特征向量,计算任意两个所述单个文字的相似度,并对得到的多个相似度进行求和运算,得到第二字形相似度信息。
[0036]
可选的,所述训练模块,还用于分别对任一样本图片进行裁切,以使所述单个文字与裁切后的样本图片边框的距离小于第二预设阈值。
[0037]
可选的,所述相似度损失通过下述公式得到:
[0038][0039]
其中,n为样本图片的数量,loss_sim为所述相似度损失,sim
gt
为所述第二字形相似度信息,sim_pd为所述第一字形相似度信息。
[0040]
可选的,所述组合损失通过下述公式得到:
[0041][0042]
其中,loss为所述组合损失,loss_cls为所述分类损失。
[0043]
可选的,所述预设分类损失函数为交叉熵损失函数。
[0044]
根据第三方面,一种实施例中提供一种电子设备,包括:存储器,用于存储程序;处理器,用于通过执行所述存储器存储的程序以实现上述第一方面中任一项所述的文字识别方法。
[0045]
根据第四方面,一种实施例中提供一种计算机可读存储介质,所述介质上存储有程序,所述程序能够被处理器执行以实现上述第一方面中任一项所述的文字识别方法。
[0046]
本发明实施例提供一种文字识别方法、装置及设备,通过获取待识别的单个文字的图片;将图片输入至预先训练好的目标识别模型中,得到待识别的单个文字与文字库中的各个文字的相似度,其中,在对目标识别模型进行训练时,采用相似度损失和分类损失确定目标识别模型是否收敛,相似度损失根据第一字形相似度信息和第二字形相似度信息确定,第一字形相似度信息通过目标识别模型得到,第二字形相似度信息通过预设算法得到,分类损失通过预设分类损失函数得到;将待识别的单个文字确定为最大相似度所对应的文字。由于本发明的损失函数由两部分构成,一部分为通过预设分类损失函数得到的分类损失,另一部分为判定两个字之间相似度的相似度损失,而相似度损失可以使目标识别模型关注文字的整体结构,从而提高了文字识别的准确度。
附图说明
[0047]
图1为本发明实施例提供的一种目标识别模型的训练方法的流程示意图;
[0048]
图2为本发明实施例提供的一种文字识别方法的流程示意图;
[0049]
图3为本发明实施例提供的一种得到第二字形相似度信息的流程示意图;
[0050]
图4为本发明实施例提供的一种划分后的文字图片的示意图;
[0051]
图5为本发明实施例提供的一种文字识别装置的结构示意图。
具体实施方式
[0052]
下面通过具体实施方式结合附图对本发明作进一步详细说明。其中不同实施方式中类似元件采用了相关联的类似的元件标号。在以下的实施方式中,很多细节描述是为了使得本技术能被更好的理解。然而,本领域技术人员可以毫不费力的认识到,其中部分特征在不同情况下是可以省略的,或者可以由其他元件、材料、方法所替代。在某些情况下,本技术相关的一些操作并没有在说明书中显示或者描述,这是为了避免本技术的核心部分被过
多的描述所淹没,而对于本领域技术人员而言,详细描述这些相关操作并不是必要的,他们根据说明书中的描述以及本领域的一般技术知识即可完整了解相关操作。
[0053]
另外,说明书中所描述的特点、操作或者特征可以以任意适当的方式结合形成各种实施方式。同时,方法描述中的各步骤或者动作也可以按照本领域技术人员所能显而易见的方式进行顺序调换或调整。因此,说明书和附图中的各种顺序只是为了清楚描述某一个实施例,并不意味着是必须的顺序,除非另有说明其中某个顺序是必须遵循的。
[0054]
本文中为部件所编序号本身,例如“第一”、“第二”等,仅用于区分所描述的对象,不具有任何顺序或技术含义。而本技术所说“连接”、“联接”,如无特别说明,均包括直接和间接连接(联接)。
[0055]
由于目前的文字识别算法一般直接根据文字图片,经过卷积神经网络等模型进行分类,并且卷积神经网络等模型一般采用分类的损失函数,如果仅含有分类的损失函数,卷积神经网络等模型容易关注文字的局部信息,在训练样本较少的时候容易出现过拟合的问题,从而导致文字识别的准确度较低。为了提高文字识别的准确度,本发明实施例提供了一种文字识别方法、装置及设备,以下分别进行详细说明。并且,下述各方法的执行主体可以为任意具有处理能力的设备。
[0056]
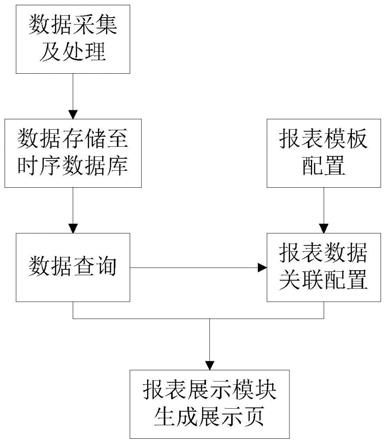
在介绍本发明实施例提供的文字识别方法之前,先对目标识别模型的训练方法进行说明。图1为本发明实施例提供的一种目标识别模型的训练方法的流程示意图,如图1所示,本发明实施例的方法可以包括:
[0057]
s101,获取多个样本图片。
[0058]
其中,每个样本图片仅包括单个文字。
[0059]
s102,将每个样本图片输入至初始识别模型中,得到每个样本图片包括的单个文字的第一特征向量。
[0060]
在每一次的模型训练中,识别模型的最后一个隐藏层的输出向量即为第一特征向量。
[0061]
s103,通过余弦距离公式,根据第一特征向量,计算任意两个单个文字的相似度,并对得到的多个相似度进行求和运算,得到第一字形相似度信息。
[0062]
此时,已经通过识别模型得到了所有样本图片对应的单个文字的第一特征向量,并且,两两经过余弦距离公式计算字形相似度,并进行求和运算,得到第一字形相似度信息。
[0063]
s104,通过预设算法得到第二字形相似度信息,并根据第一字形相似度信息和第二字形相似度信息,得到相似度损失。
[0064]
具体的,相似度损失可以通过下述公式(1)得到:
[0065][0066]
其中,n为样本图片的数量,loss_sim为相似度损失,sim_gt为第二字形相似度信息,sim_pd为第一字形相似度信息。
[0067]
s105,根据相似度损失和分类损失,确定组合损失。
[0068]
具体的,分类损失可以通过预设分类损失函数得到,例如,预设分类损失函数可以为交叉熵损失函数。那么,分类损失可以通过下述公式(2)得到:
[0069][0070]
其中,loss_cls为分类损失,y为样本的真实值,为样本的预测值。
[0071]
具体的,组合损失即为上述提到的损失函数,组合损失可以通过下述公式(3)得到:
[0072][0073]
其中,loss为组合损失。
[0074]
s106,根据组合损失,对初始识别模型的参数进行调整,以得到更新的识别模型。
[0075]
s107,针对更新的识别模型,迭代上述训练过程,直至组合损失小于第一预设阈值或者迭代次数大于预设训练迭代次数,并将组合损失小于第一预设阈值或者迭代次数大于预设训练迭代次数所对应的识别模型作为目标识别模型。
[0076]
本发明实施例提供的目标识别模型的训练方法,由于本发明的组合损失由两部分构成,一部分为通过预设分类损失函数得到的分类损失,另一部分为判定两个字之间相似度的相似度损失,而相似度损失可以使目标识别模型关注文字的整体结构,从而提高了目标识别模型识别文字的准确度。
[0077]
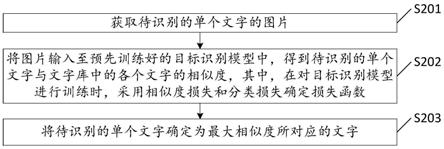
图2为本发明实施例提供的一种文字识别方法的流程示意图,如图2所示,本实施例提供的文字识别方法可以包括:
[0078]
s201,获取待识别的单个文字的图片。
[0079]
可选的,可以利用字体文件,生成预设格式的仅包括单个字的图片,其中,预设格式需要可以明显区分图片中的背景和文字,例如预设格式可以为“白底黑字”。
[0080]
可选的,针对现有的通过手写或者拍摄得到的文字图片,也可以提取该类文字图片的图片背景,并将图片背景设置为可以与文字明显区分的格式,例如,当前文字为黑色,那么可以将背景设置为白色。
[0081]
s202,将图片输入至预先训练好的目标识别模型中,得到待识别的单个文字与文字库中的各个文字的相似度,其中,在对目标识别模型进行训练时,采用相似度损失和分类损失确定损失函数。
[0082]
具体的,通过上述图1所示的模型训练方法就可以得到本实施例的目标识别模型。该目标识别模型的输出层可以输出待识别的单个文字与文字库中的各个文字的相似度。
[0083]
s203,将待识别的单个文字确定为最大相似度所对应的文字。
[0084]
例如,假设文字库中包括20000个文字,当前待识别的单个文字与文字库中的文字“土”的相似度最大,那么可以确定当前待识别的单个文字为“土”。
[0085]
本发明实施例提供的文字识别方法,通过获取待识别的单个文字的图片;将图片输入至预先训练好的目标识别模型中,得到待识别的单个文字与文字库中的各个文字的相似度,其中,在对目标识别模型进行训练时,采用相似度损失和分类损失确定目标识别模型是否收敛,相似度损失根据第一字形相似度信息和第二字形相似度信息确定,第一字形相似度信息通过目标识别模型得到,第二字形相似度信息通过预设算法得到,分类损失通过预设分类损失函数得到;将待识别的单个文字确定为最大相似度所对应的文字。由于本发明的损失函数由两部分构成,一部分为通过预设分类损失函数得到的分类损失,另一部分
为判定两个字之间相似度的相似度损失,而相似度损失可以使目标识别模型关注文字的整体结构,从而提高了文字识别的准确度。
[0086]
图3为本发明实施例提供的一种得到第二字形相似度信息的流程示意图,如图3所示,包括:
[0087]
s301,分别将同一个训练批次内的任意两个样本图片缩放至预设尺寸。
[0088]
上述同一个训练批次指的是在每一次模型训练的过程中,图1对应的实施例的样本图片与本实施的样本图片是相同的。即,在每一次模型训练的过程中,可以通过识别模型,对同一训练批次的样本图片进行处理,得到第一字形相似度信息;同时,也可以通过预设算法,对同一训练批次的样本图片进行处理,得到第二字形相似度信息。
[0089]
由于获取到的各个样本图片的像素可能是不同的,因此需要将矩形文字图片缩放为a乘b像素的文字图片。其中,a、b可根据实际情况设置,需保证通过缩放后的图片可以识别该文字,比如a、b都取100。
[0090]
s302,分别对缩放后的样本图片进行划分,得到每个样本图片包括的单个文字的第二特征向量。
[0091]
具体实现时,可以将文字图片划分为c乘d的格子。其中,可以根据需要识别的精度来设置c和d。c和d设置越大,相似度计算越精确,但是计算所需时间越多,因此可以根据实际情况调整,比如c,d都取10,从而将文字图片划分为100个格子。并且,若格子内包含非白色的像素,则该格子为“1”,否则为“0”,从而生成了文字对应的向量。如图4所示,图4为划分后的“大”、“太”和“士”分别对应的文字图片的示意图。通过上述划分,可以得到“大”字对应的第二特征向量为:0000110000000011000000001100111111111111000011000000001110000001111000000110110000100001111100000011;“太”字对应的第二特征向量为:0000110000000011000000001100111111111111000011100000001110000001101100000111111000101101111100000011;“士”字对应的第二特征向量为:0000110000000011000000001100000000110011111111111100001100000000110000000011000000001101100111111111。
[0092]
s303,通过余弦距离公式,根据第二特征向量,计算任意两个单个文字的相似度,并对得到的多个相似度进行求和运算,得到第二字形相似度信息。
[0093]
此时,已经通过上述预设算法得到了所有样本图片对应的单个文字的第二特征向量,并且,两两经过余弦距离公式计算字形相似度,并进行求和运算,得到第二字形相似度信息。例如,将文字图片划分为100个格子后生成了文字对应的100维度的第二特征向量,通过余弦距离公式计算两个字x和y的相似度,如下述公式(4)所示:
[0094][0095]
例如,通过上述公式(4)可以得到:“大”和“太”的相似度为0.917;“大”和“士”的相似度为0.564。
[0096]
可选的,在上述s301之前,上述文字识别方法还可以包括:分别对任一样本图片进行裁切,以使单个文字与裁切后的样本图片边框的距离小于第二预设阈值。例如,假设样本图片为白底黑字的图片,可以对图片四周的白边进行裁切,从而有助于去除图片中多余的背景元素。
[0097]
图5为本发明实施例提供的一种文字识别装置的结构示意图,如图5所示,该文字
识别装置50可以包括:
[0098]
第一获取模块510,可以用于获取待识别的单个文字的图片。
[0099]
第二获取模块520,可以用于将图片输入至预先训练好的目标识别模型中,得到待识别的单个文字与文字库中的各个文字的相似度。
[0100]
确定模块530,可以用于将待识别的单个文字确定为最大相似度所对应的文字。
[0101]
训练模块540,可以用于获取多个样本图片,其中,每个样本图片包括单个文字;将每个样本图片输入至初始识别模型中,得到每个样本图片包括的单个文字的第一特征向量;通过余弦距离公式,根据第一特征向量,计算任意两个单个文字的相似度,并对得到的多个相似度进行求和运算,得到第一字形相似度信息;通过预设算法得到第二字形相似度信息,并根据第一字形相似度信息和第二字形相似度信息,得到相似度损失;根据相似度损失和分类损失,确定组合损失,其中,分类损失通过预设分类损失函数得到;根据组合损失,对初始识别模型的参数进行调整,以得到更新的识别模型;针对更新的识别模型,迭代上述训练过程,直至组合损失小于第一预设阈值或者迭代次数大于预设训练迭代次数,并将组合损失小于第一预设阈值或者迭代次数大于预设训练迭代次数所对应的识别模型作为目标识别模型。
[0102]
本发明实施例提供的文字识别装置,通过第一获取模块,获取待识别的单个文字的图片;通过训练模块,得到训练好的目标识别模型,其中,在对目标识别模型进行训练时,采用相似度损失和分类损失确定目标识别模型是否收敛,相似度损失根据第一字形相似度信息和第二字形相似度信息确定,第一字形相似度信息通过目标识别模型得到,第二字形相似度信息通过预设算法得到,分类损失通过预设分类损失函数得到;通过第二获取模块,将图片输入至预先训练好的目标识别模型中,得到待识别的单个文字与文字库中的各个文字的相似度;通过确定模块,将待识别的单个文字确定为最大相似度所对应的文字。由于本发明的损失函数由两部分构成,一部分为通过预设分类损失函数得到的分类损失,另一部分为判定两个字之间相似度的相似度损失,而相似度损失可以使目标识别模型关注文字的整体结构,从而提高了文字识别的准确度。
[0103]
可选的,上述训练模块540,可以具体用于分别将任意两个样本图片缩放至预设尺寸;分别对缩放后的样本图片进行划分,得到每个样本图片包括的单个文字的第二特征向量;通过余弦距离公式,根据第二特征向量,计算任意两个单个文字的相似度,并对得到的多个相似度进行求和运算,得到第二字形相似度信息。
[0104]
可选的,上述训练模块540,还可以用于分别对任一样本图片进行裁切,以使单个文字与裁切后的样本图片边框的距离小于第二预设阈值。
[0105]
可选的,预设分类损失函数可以为交叉熵损失函数。
[0106]
另外,相应于上述实施例所提供的文字识别方法,本发明实施例还提供了一种电子设备,该电子设备可以包括:存储器,用于存储程序;处理器,用于通过执行存储器存储的程序以实现本发明实施例提供的文字识别方法的所有步骤。
[0107]
另外,相应于上述实施例所提供的文字识别方法,本发明实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令,所述计算机执行指令被处理器执行时实现本发明实施例的文字识别方法的所有步骤。
[0108]
本领域技术人员可以理解,上述实施方式中各种方法的全部或部分功能可以通过
硬件的方式实现,也可以通过计算机程序的方式实现。当上述实施方式中全部或部分功能通过计算机程序的方式实现时,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器、随机存储器、磁盘、光盘、硬盘等,通过计算机执行该程序以实现上述功能。例如,将程序存储在设备的存储器中,当通过处理器执行存储器中程序,即可实现上述全部或部分功能。另外,当上述实施方式中全部或部分功能通过计算机程序的方式实现时,该程序也可以存储在服务器、另一计算机、磁盘、光盘、闪存盘或移动硬盘等存储介质中,通过下载或复制保存到本地设备的存储器中,或对本地设备的系统进行版本更新,当通过处理器执行存储器中的程序时,即可实现上述实施方式中全部或部分功能。
[0109]
以上应用了具体个例对本发明进行阐述,只是用于帮助理解本发明,并不用以限制本发明。对于本发明所属技术领域的技术人员,依据本发明的思想,还可以做出若干简单推演、变形或替换。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。