1.本发明涉及教育技术领域,更具体地说,特别涉及一种学习时长计算方法及系统。
背景技术:
2.学习时长是在线教育中一个重要的指标,用于反映用户在某些学习资源上停留时间的长短,如何准确、简单、高效地计算出学习者的学习时长也成为众多在线教育平台面临的困难之一。通过研究发现,现有的适用于在线教育平台的学习时长计算方法包括:(1)通过登录时间差来计算在线时长:用户登录网站时,网站服务器获取用户的登录状态并记下获取时刻;在用户退出网站时,网站服务器获取用户的登出状态并记下获取时刻;通过计算获取用户登录态和登出状态分别对应的两次时刻之间的差值,将该差值作为用户的在线时长。此方法的缺陷是:误差大;无法统计某个单页面的停留时长;不能统计游客状态的在线时长。(2)在上述方法的基础上,引入监听路由,通过判断监听路由变化、判断变化的url是否为不同页面来监控用户在某个单页面上的停留时长。主要监控状态分为“进入”、“活跃状态切换”、“离开”三种类型,然后在对应触发的事件中记录时间戳,比如要统计活跃停留时长就把“活跃状态”区间相加,总时长即tn-t0。此方法的缺陷是:过于依赖于打点开发,比如对于常规页面的首次加载、页面关闭、刷新等操作需要通过window.onload和window.onbeforeunload事件来监听页面进入和离开;不同渠道的产品打点开发技术并不一致,开发工作量大;事件日志与产品深度绑定,统计算法的调整依赖于产品发版。(3)针对不同的产品渠道来源,直接使用第三方统计工具,如国内常用的统计工具有cnzz、百度统计等。此方法的缺陷是:不同产品渠道数据是分离的,不能合并处理,对于用户同时使用多个渠道的产品时,会有产生大量的重复数据;不同渠道的产品均需要在产品中嵌入第三方统计工具。(4)使用预测模型来预测学习时长:采集用户学习数据,包括用户其余已学完资源的平均用时、学习资源被掌握率、学习资源被其余用户学完的平均用时以及用户的学习模式;对所获得的数据进行数据预处理;构建预测回归模型,基于预处后的数据,采用线性回归的方法,得出预测回归模型中的参数;进行模型诊断;基于使用所获参数的预测回归模型,获得用户预测学习时长。此方法的缺陷是:完全基于模型进行预测,误差较大。
3.随着电子产品和终端操作系统的多样化,在线教育产品也必然出现多源的趋势。所谓多源,即同一个在线教育平台为了满足学习者不同场景的学习需求,往往需要开发适配不同终端、不同操作系统的产品。如既有web端,又有移动端;移动端又分为ios操作系统、android操作系统、华为鸿蒙操作系统、移动浏览器、微信端(包含服务号、公众号、小程序)等。由此导致用户的学习数据也是多源的,当平台给用户计算在线学习时长时,需要对不同的产品分别进行打点、采集数据、计算,再根据用户账号信息进行汇总、去重。该方法的缺点如下:(1)开发工作量大:每个渠道产品均需要进行数据打点开发,部署数据采集、清洗、统计系统;(2)计算方式复杂:当对多源数据进行合并统计时,需要根据每个用户的账号信息进行数据合并、去重。对于用户量过百万级的系统,要做到实时进行数据合并计算,计算量巨大;(3)更新困难:打点系统的更新依赖于产品的发版,尤其是app端、微信端的发版均需
要各终端应用市场和微信端的审核,发版尤其困难; (4)难以统一:当算法出现调整时,需要对不同产品的打点系统、算法都进行调整和发版,才能做到多源数据的统计。因此,为了解决当前学习时长统计方法中存在的缺陷,有必要提供的是一种学习时长计算方法及系统,
技术实现要素:
4.本发明的目的在于提供一种学习时长计算方法及系统,以克服现有技术所存在的缺陷。
5.为了达到上述目的,本发明采用的技术方案如下:
6.一种学习时长计算方法,包括以下步骤:
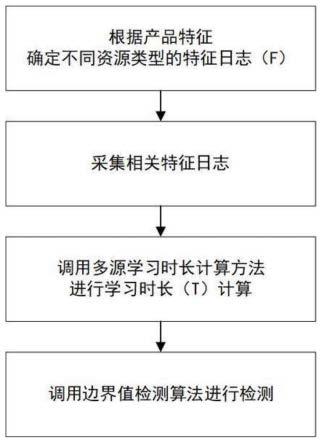
7.s1、根据不同在线教育产品的资源类型定义特征日志,形成特征日志集合;
8.s2、采集所述特征日志集合中的特征日志,将所述特征日志进行存储和清洗;
9.s3、根据用户行为日志数据判断资源类型,并根据所述资源类型从用户行为日志数据中提取特征日志以形成事件对,计算两个事件对之间的时间差;
10.s4、比较所述时间差与学习时长边界值的大小,若所述时间差大于所述学习时长边界值,则获取当前资源访问日志之后的特定接口请求,并计算该特定接口请求时刻与当前资源的访问时刻之差值,将该差值与学习时长边界值进行比较,若该差值大于学习时长边界值,则采用资源本身的时长与之前的时刻之差进行比较,选择最小的值,作为用户当前学习资源的学习时长,并根据资源学习时长累计值,获得用户的在线学习时长数据。
11.进一步地,所述步骤s1具体包括:
12.s10、将所述不同在线教育产品的资源类型分为a类资源和b类资源,所述a类资源包括播放、暂停、结束行为打点的课程或者微课资源,所述b类资源为除a类资源以外的资源;;
13.s11、将所述a类资源中的开始播放日志p、暂停或结束日志q定义为a类资源特征日志,将所述b类资源中的点击资源的日志m、下一个资源的请求日志n以及返回页面请求日志y定义为b类资源特征日志;
14.s12、将所述a类资源特征日志和b类资源特征日志集合形成特征日志集合 f={p,q,m,n,y}。
15.进一步地,所述步骤s3具体包括:
16.s30、从用户行为日志数据中过滤出用户学习过的资源的请求日志以及特定接口日志集中的日志数据作为候选集,进行日志的初次筛选;
17.s31、判断资源类型,若为a类资源,记录开始播放日志p对应的时刻t1、暂停或结束日志q对应的时刻t2,按时间先后顺序排序形成事件对(p1,q1),(p2,q2),
…
,(pn,qn);若为 b类资源,记录用户点击资源的日志m对应的时刻t
11
、下一个资源的请求日志n对应的时刻t
21
;
18.s32、计算a类资源事件对之间的时间差validation1=t
2-t1和b类资源事件对之间的时间差validation2=t
21-t
11
。
19.进一步地,所述步骤s4还包括对不同的资源类型赋予不同的初始学习时长边界值,所述a类资源的学习时长边界值为ta0,所述b类资源的学习时长边界值为tb0,所述步骤
s4具体为:
20.在资源类型为a类资源时,判断时间差validation1与学习时长边界值ta0的大小,若validation1《=ta0,则资源学习时长若若 validation1》ta0,则资源学习时长t=validation1=ta0;
21.在资源类型为b类资源时,判断时间差validation2与学习时长边界值tb0的大小,若validation2《=tb0,则资源学习时长t=validation2,
22.若validation2》tb0,则抽取y集合中的日志,该日志对应时刻记为t3,将时间差 validation2中超过上限的日志和指定的一些其他用户点击日志融合后,再进行一次差值计算得到第二次有效时长validation3=t
3-t1={vc0,vc1,vc2...},再比较第二次有效时长 validation3与学习时长边界值tb0的差值大小,若validation3《=tb0,则资源学习时长t= validation3,若validation3》tb0,采用validation3中计算出的超过上限的时长与validation2 中超过上限的时长比较后取得较小的时长e={e0,e1,e2...},再将时长e中的资源与数据库中相应的资源自身时长进行匹配,如能查询到则取时长e与资源时长中的较小时长记为 validation4={vd0,vd1,vd2...},如无法查到则默认给tb0,资源学习时长t= validation4=min(tb0,v2,v3,v4);
23.计算用户的在线学习时长数据为t
总
=validation1 validation2 validation3 validation4。
24.本发明还提供一种根据上述的学习时长计算方法的系统,包括:
25.定义模块,用于根据不同在线教育产品的资源类型定义特征日志,形成特征日志集合;
26.采集模块,用于采集所述特征日志集合中的特征日志,将所述特征日志进行存储和清洗;
27.时间差计算模块,用于根据用户行为日志数据判断资源类型,并根据所述资源类型从用户行为日志数据中提取特征日志以形成事件对,计算两个事件对之间的时间差;
28.学习时长计算模块,用于比较所述时间差与学习时长边界值的大小,若所述时间差大于所述学习时长边界值,则获取当前资源访问日志之后的特定接口请求,并计算该特定接口请求时刻与当前资源的访问时刻之差值,将该差值与学习时长边界值进行比较,若该差值大于学习时长边界值,则采用资源本身的时长与之前的时刻之差进行比较,选择最小的值,作为用户当前学习资源的学习时长,并根据资源学习时长累计值,获得用户的在线学习时长数据。
29.与现有技术相比,本发明的优点在于:本发明提供的一种学习时长计算方法及系统,使用用户的接口访问日志(服务端)来计算学习时长,无须专门打点,减少开发工作量,且无论用户使用的是哪个来源渠道的产品,都会在服务器端统一记录访问日志,以此实现多源产品用户学习数据的唯一性,无须再通过账号进行不同来源数据的合并、去重,计算方法简化。
附图说明
30.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本
发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
31.图1是本发明学习时长计算方法的流程图。
32.图2是本发明中步骤s3的流程图。
33.图3是本发明中步骤s4的流程图。
34.图4是本发明学习时长计算系统的框架图。
35.图5是本发明实施例中用户资源的请求日志以及特定接口数据图。
36.图6是本发明实施例中用户慕课请求日志以及特定接口数据图。
37.图7是本发明实施例中用户文章、电子书、音频请求日志以及特定接口数据图。
38.图8是本发明实施例中用户文章、电子书、音频学习时间间隔图。
39.图9是本发明实施例中资源时长信息图。
40.图10是本发明实施例中v1-v4计算结果存储图。
具体实施方式
41.下面结合附图对本发明的优选实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
42.参阅图1所示,本实施例公开了一种学习时长计算方法,包括以下步骤:
43.步骤s1、根据不同在线教育产品的资源类型(比如文章、电子书、音频等等,每种资源请求日志是不一样的,因此我们需要定义特征日志,过滤出资源的请求日志)定义特征日志,形成特征日志集合。
44.具体的,不同的产品在资源学习交互流程上并不一致,需要各平台根据自身产品的学习交互流程进行定义,步骤s1具体包括:
45.步骤s10、目前典型在线教育资源包括慕课、电子书、百科、期刊、文章、微课(或知识点)、音频专辑、音频单条8大类。根据这些资源本身的特点,可以将不同在线教育产品的资源类型分为a类资源和b类资源,a类资源包括播放、暂停、结束行为打点的课程或者微课资源,包括一系列视频和音频合集的学习资源,如慕课(一系列视频资源的集合)、音频专辑(一系列音频资源的集合)等,即a类资源针对课程类资源在app或者h5上加了一些播放、暂停、结束的行为打点,通过播放-暂停,播放-结束,播放-播放几段,来计算更为准确的学习时长。b类资源是没有上面这种具体行为打点的课程(像 web端、微信端)、文章、电子书、期刊、音频单条类的资源等。
46.步骤s11、将a类资源中的开始播放日志p、暂停或结束日志q定义为a类资源特征日志,将b类资源中的点击资源的日志m、下一个资源的请求日志n以及返回页面请求日志y定义为b类资源特征日志。
47.具体的,a类资源一般会有开始学习的行为日志,如“开始播放”日志,记为p,也有结束的行为日志,如“暂停”、“结束”,记为q。同时,有的产品视频/音频播放器有自动续播功能,有的没有自动续播功能,对于有自动续播功能的产品,需要设计确认弹窗功能,以减少算法误差,具体为:当用户开始播放后,在视频/音频播放页面每隔该资源有效学习时长(t0)时间弹出确认弹窗,同时暂停播放(记为q),用户可在弹窗上点击“继续学习”按钮重新开始播放视频/音频(记为p)。因此,a类资源主要为p、q两种特征日志。 b类资源一般会有点
击资源的日志(记为m),下一个资源的请求日志(记为n),n之后返回的页面请求日志(记为y,y是根据产品交互流程定义的系列页面特征接口, y={y1,y1,
…
,yn})。
48.b类资源一般都是形成事件对(m,n)时间差(tn-tm),作为资源m的学习时长,本实施例认为资源的学习过程是连续的,但是当用户上午学了一门资源,下午学了一门资源,这时候n-m的时间超过设定的阈值了,因此再去找m,n资源中间的返回页面的请求日志,这样学习时长y-m比n-m的统计更为准确。
49.步骤s12、将a类资源特征日志和b类资源特征日志集合形成特征日志集合 f={p,q,m,n,y}。
50.步骤s2、采集所述特征日志集合中的特征日志,不同来源的产品日志记录在统一的大数据服务器上,将特征日志进行存储和清洗。
51.步骤s3、根据用户行为日志数据判断资源类型,并根据所述资源类型从用户行为日志数据中提取特征日志以形成事件对,计算两个事件对之间的时间差。
52.如图2所示,步骤s3具体包括:
53.步骤s30、当计算方式开始运行时,从用户行为日志数据中过滤出用户学习过的资源的请求日志以及特定接口日志集中的日志数据作为候选集,进行日志的初次筛选。
54.步骤s31、提取特征事件对并计算学习时间差,先判断资源类型。
55.若为a类资源,记录开始播放日志p对应的时刻t1、暂停或结束日志q对应的时刻 t2,按时间先后顺序排序形成事件对(p1,q1),(p2,q2),
…
,(pn,qn),事件对包括播放-暂停、播放-结束、播放-弹框、继续学习-暂停、继续学习-结束等事件对。
56.若为b类资源,记录用户点击资源的日志m对应的时刻t
11
、下一个资源的请求日志 n对应的时刻t
21
,即当用户进入某条学习资源时,向服务器发送资源访问请求,日志记录为m,该请求时刻记为t
11
;t
11
之后下一条资源访问请求日志n,记为t
21
。
57.步骤s32、计算事件对之间的时间差。
58.a类资源事件对之间的时间差validation1=t
2-t1,validation1={va0,va1,va2...}。
59.b类资源事件对之间的时间差validation2=t
21-t
11
,validation2={vb0,vb1,vb2...}。
60.步骤s4、调用边界值检测算法进行检测。
61.具体的,比较时间差与学习时长边界值的大小,若所述时间差大于所述学习时长边界值,则获取当前资源访问日志之后的特定接口请求,并计算该特定接口请求时刻与当前资源的访问时刻之差值,将该差值与学习时长边界值进行比较,若该差值大于学习时长边界值,则采用资源本身的时长与之前的时刻之差进行比较,选择最小的值,作为用户当前学习资源的学习时长,并根据资源学习时长累计值,获得用户的在线学习时长数据。
62.步骤s4还包括对不同的资源类型赋予不同的(比如课程、音频单条、微课/知识点、自建音频默认边界值是30分钟。文章、电子书、期刊、音频专辑默认边界值是10分钟) 初始学习时长边界值,由于初始启用本算法时,若无历史参考数据,可根据不同类型的资源特点,赋予不同的初始学习时长边界值(记为t0)。a类资源t0值记为ta0,b类资源t0值记为tb0,在有数据累积后,可对ta0、tb0值进行调整,调整为平台用户该类型资源的平均学习时长。随着数据累积的增加,t0的误差会越来越小。
63.参阅图3所示,步骤s4的边界值检测算法的具体步骤为:
64.在资源类型为a类资源时,判断时间差validation1与学习时长边界值ta0的大小,若validation1《=ta0,则资源学习时长若若 validation1》ta0,则资源学习时长t=validation1=ta0。
65.在资源类型为b类资源时,判断时间差validation2与学习时长边界值tb0的大小,若validation2《=tb0,则资源学习时长t=validation2,若validation2》tb0,则抽取y集合中的日志,该日志对应时刻记为t3,将时间差validation2中超过上限的日志和指定的一些其他用户点击日志(t21-t11》tb0,就会把m,n资源的请求日志跟y集合请求日志融合在一起,所以会形成m,y,n的日志顺序,对应的时间为t11,t3,t21,所以这一步取的学习时长值t3-t11)融合后,再进行一次差值计算得到第二次有效时长validation3= t
3-t1={vc0,vc1,vc2...},再比较第二次有效时长validation3与学习时长边界值tb0的差值大小。
66.若validation3《=tb0,则资源学习时长t=validation3,若validation3》tb0,采用 validation3中计算出的超过上限的日志(这里的条件先是validation2大于tb0,然后计算 validation3也大于tb0,这里就是取这两个值里较小的值,一般取的是validation3,但用户如果没有返回页面事件,一直在某个页面没动,那么取的就是validation2,这个值再跟资源时长再比较)与validation2中超过上限的时长比较后取得较小的时长e={e0,e1,e2...},再将时长e中的资源与数据库中相应的资源自身时长(比如音频这类资源就有自身的时长信息,而电子书、文章这类就没有时长信息,所以针对部分能够获取时长信息的资源,我们会再做一次比较,取validation2,validation3,资源时长里最小的值当做validation4) 进行匹配,如能查询到则取时长e与资源时长中的较小时长记为 validation4={vd0,vd1,vd2...},如无法查到则默认给tb0(如果能查询到时长信息,那么 validation4=validation2,validation3,时长信息里最小的值;如果查询不到, validation4=tb0),资源学习时长t=validation4=min(tb0,validation2,validation3, validation4)。
67.计算用户的在线学习时长数据为t
总
=validation1 validation2 validation3 validation4,此时就可以计算出每个用户某天的学习时长。
68.本实施例采用按日统计,每日凌晨统计前一天的数据。为了保证数据的完整性,会取一天 1小时的方式,假设需要计算2022-02-07日用户的推算学习时长,那么代码会拉取 2022-02-07 00:00:00~24:00:00和2022-02-08 00:00:00~01:00:00的数据,这是为了尽量保证用户在2022-02-07 23:58:00进入学习资源2022-02-08 00:05:00退出资源情况的时长完整性。
69.参阅图4所示,本发明还提供一种根据上述的学习时长计算方法的系统,包括:定义模块1,用于根据不同在线教育产品的资源类型定义特征日志,形成特征日志集合;采集模块2,用于采集所述特征日志集合中的特征日志,将所述特征日志进行存储和清洗;时间差计算模块3,用于根据用户行为日志数据判断资源类型,并根据所述资源类型从用户行为日志数据中提取特征日志以形成事件对,计算两个事件对之间的时间差;学习时长计算模块4,用于比较所述时间差与学习时长边界值的大小,若所述时间差大于所述学习时长边界值,则获取当前资源访问日志之后的特定接口请求,并计算该特定接口请求时刻与当前资源的访问时刻之差值,将该差值与学习时长边界值进行比较,若该差值大于学习时长边界
值,则采用资源本身的时长与之前的时刻之差进行比较,选择最小的值,作为用户当前学习资源的学习时长,并根据资源学习时长累计值,获得用户的在线学习时长数据。
70.本发明使用用户的接口访问日志(服务端)来计算学习时长,无须专门打点,减少开发工作量,且无论用户使用的是哪个来源渠道的产品,都会在服务器端统一记录访问日志,以此实现多源产品用户学习数据的唯一性,无须再通过账号进行不同来源数据的合并、去重,计算方法简化。本发明弥补了现有计算方法中多源产品需要分别开发、采集数据的问题,也弥补了现有计算方式中不同来源渠道的学习数据需要去重计算的问题。
71.下面通过具体实施例对本发明作进一步介绍。
72.以军职在线(军事职业教育互联网服务平台,服务于)为例,取一个用户某一天(用户id为5732484,日期为2022年2月14号)的日志作为样例,来实施上述算法过程:
73.第一步:确定不同资源类型的特征日志(记为f),并过滤出用户资源的请求日志以及特定接口数据作为候选集,如图5所示。
74.过滤得出f={p,q,m,n,y}={包含join、alert_message、special medal、today、search、 recommend、user_rank、student、user、study、everyday、normal、score字段的接口}。
75.第二步:采集f集合中所有相关的特征日志
76.第三步:调用多源学习时长计算方法计算学习时长
77.(1)a类资源的计算逻辑:根据资源类型行为筛选提取用户a类资源(在此为慕课) 相关行为数据:包括播放、暂停/结束、弹框提示、弹框后点击继续学习、弹框后点击休息等日志,如图6所示。
78.从上面按时间排序的日志中,取出播放-暂停、播放-结束、播放-弹框、继续学习-暂停、继续学习-结束等事件组合对,并计算出点击时间的时间间隔;基于规则,取出 2022-02-14 18:35:13的1001事件类型play播放点,以及2022-02-14 18:40:06的1002事件类型的播放结束点,时间间隔v1=293秒(4.883分钟)。
79.(2)b类资源计算逻辑:根据资源类型,过滤出b类资源(在此为文章、电子书、音频,其中1517为专题,不在定义的资源范围内)详细点击行为的日志,如图7所示。
80.按时间排序计算相邻两条资源点击时间间隔,并过滤掉慕课资源类型2的计算(灰色记录,慕课资源不在b类资源范围之类),如图8所示。
81.因此,v2={1.083,0.133,0.067,∞}。
82.第四步:调用边界值检测算法进行检测
83.依次对第三步中计算出的时长值进行边界值检测,判断是否超过默认值:
84.(1)a类资源:v1=4.883分钟《=30分钟(用户5732484学习资源类型2课程6991
‑ꢀ
班级21831,学习时间4.883分钟,小于默认值30分钟),记录有效;而后面两个相邻日志1002播放结束-1002播放结束,不符合我们的取出规则,所以过滤掉;最后的课程状态为播放结束行为,不需要补充时间计算,整个过程结束。
85.(2)b类资源:
86.①
v2={1.083,0.133,0.067}《=10分钟(用户5732484学习资源类型14文章11581,学习时间1.083分钟,小于默认值10分钟,记录有效;用户5732484学习资源类型5电子书619,学习时间0.133分钟,小于默认值10分钟,记录有效;用户5732484学习资源类型21
音频专辑20385914,学习时间0.067分钟,小于默认值10分钟),记录有效;
87.②
v2={∞}》10分钟(用户5732484学习资源类型22音频单条149541298,学习时间分钟∞),大于默认值30分钟上限,需要进行下一步推算计算:
88.●
将最后一条超过上限的资源点击日志与特定接口数据合并后再进行一次计算,但在该资源学习后,无其他日志行为,因此时间间隔v2依然为∞,超过默认值30 分钟上限;需要根据音频自身时长进行补充;
89.●
在数据库中进行资源查找发现,有该资源的时长信息,时长为636秒=10.6分钟 (如图9所示),小于默认值30分钟,v4=min(∞,∞,10.6)=10.6分钟,记录有效。
90.即用户5732484学习资源类型22音频单条149541298,学习时间分钟10.6分钟。
91.最终,将validation1、validation2、validation3、validation4所有计算结果保留至库中 (其中v3无数据),如图10所示。
92.5.计算用户当天学习时长
93.按技术方案中的算法,将validation1、validation2、validation3、validation4值求和,得到用户当天的学习时长数据。即用户(id为5732484)2022年2月14号的学习时长t=v1 v2 v4=4.883分钟 1.083分钟 0.133分钟 0.067分钟 10.6分钟=16.766分钟。
94.虽然结合附图描述了本发明的实施方式,但是专利所有者可以在所附权利要求的范围之内做出各种变形或修改,只要不超过本发明的权利要求所描述的保护范围,都应当在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。